核心监控指标:性能、内存、连接、持久化、集群状态监控
Redis 作为内存型数据库,监控围绕性能吞吐、内存使用、客户端连接、持久化、集群状态 五大核心维度展开,是故障预警、性能调优、容量规划的关键依据。下文结合 Redis 原生 info 指令字段、计算规则、健康阈值、异常场景、排查方向逐一说明,同时区分单机、主从 + 哨兵、Redis Cluster三种主流架构。
前置说明:
- 所有原生指标通过
redis-cli执行info [模块名]获取;- Redis 6.0+ 术语变更:
slave统一改为replica(从节点);- 主流监控方案:
Prometheus + Redis Exporter + Grafana、Zabbix、Redis Insight、云厂商自研监控。
一、性能指标(核心:吞吐、延迟、CPU、缓存命中率)
性能指标直接反映 Redis 服务处理能力、响应速度,单线程模型 是 Redis 性能特点(命令处理主线程单 CPU 核运行)。指标来源:info stats、info cpu、slowlog、redis-cli --latency
吞吐量(QPS)
核心字段 & 计算
instantaneous_ops_per_sec:实时每秒命令执行数(瞬时 QPS),最直观的吞吐指标。total_commands_processed:累计执行总命令数,可计算平均 QPS:

total_net_input_bytes/total_net_output_bytes:网络入 / 出流量,衡量网络吞吐。
健康阈值 & 异常分析
- 阈值:结合业务压测基线,瞬时 QPS 持续突降 / 突增 50%+ 告警;
- 异常:QPS 骤降 → 节点阻塞、慢命令堆积、网络中断;QPS 暴涨 → 流量突增、爬虫 / 恶意请求。
缓存命中率(重中之重)
缓存命中率是判断缓存架构合理性的核心指标。
字段 & 公式
keyspace_hits:缓存命中次数keyspace_misses:缓存未命中次数
健康阈值 & 异常分析
- 优秀:≥95%;正常:90%~95%;预警:80%~90%;严重:<80%
- 命中率过低常见原因:
- 缓存穿透(大量查询不存在的 Key);
- Key 过期策略不合理、冷热数据混杂;
- 缓存雪崩(批量 Key 同时过期);
- 业务侧未合理设计缓存逻辑。
慢查询 & 命令延迟
Redis 延迟过高会直接影响业务响应耗时。
- 整体延迟 执行
redis-cli --latency查看平均 / 最大延迟,正常单机延迟应 <1ms;延迟>5ms 视为卡顿。 - 慢日志指标 (
slowlog)
slowlog-log-slower-than:慢命令阈值(单位:微秒);- 慢日志条数、慢命令内容:高频出现
KEYS、HGETALL、LUA复杂脚本、超大集合遍历,均为高危操作。
延迟高根因
大 Key、慢命令、持久化 Fork 阻塞、磁盘 IO 打满、网络抖动、客户端缓冲区堆积。
CPU 使用率
Redis 命令处理由单主线程 完成,仅关注单个 CPU 核使用率。
字段(info cpu)
used_cpu_user:用户态 CPU 累计耗时(命令处理);used_cpu_sys:内核态 CPU 累计耗时(系统调用、磁盘读写)。
健康阈值
- 单核 CPU 使用率 <70%:健康;
- 70%~85%:预警,压力偏高;
- >85%:严重告警,主线程接近打满,必然延迟升高。
异常场景
CPU 打满 → 大量慢命令、热 Key 打爆、恶意命令(KEYS *)、Lua 死循环脚本。
阻塞客户端
字段:blocked_clients(info clients)代表被阻塞命令(BLPOP/BRPOP 等阻塞队列)挂起的客户端数量,持续上涨说明队列消费能力不足。
二、内存指标(Redis 核心,内存数据库生命线)
Redis 数据全存内存,内存溢出、碎片过高、Key 泛滥、内存淘汰都会引发故障。指标来源:info memory、info keyspace
基础内存占用
|------------------|--------------------|--------------------------------------------|
| 字段 | 含义 | 说明 |
| used_memory | Redis 实际数据占用内存(字节) | 仅统计数据、编码、元数据,Redis 视角内存 |
| used_memory_rss | 操作系统视角进程内存(RSS) | 包含数据、内存碎片、动态库、栈内存等 |
| used_memory_peak | 历史内存使用峰值 | 判断历史最大压力,用于容量规划 |
| maxmemory | 配置的最大内存上限 | 内存满后触发淘汰策略 |
| maxmemory_policy | 内存淘汰策略 | noeviction(不淘汰)、allkeys-lru、volatile-lru 等 |
内存碎片率(核心指标)
内存碎片是 Redis 高频问题,由频繁增删改、大 Key 拆分 / 删除导致。
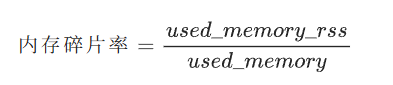
阈值 & 优化
- 健康:1.0 ~ 1.5;
- 预警:1.5 ~ 2.0(碎片偏高);
- 严重:>2.0(严重碎片,内存利用率极低)。
- 优化:Redis 4.0+ 开启主动碎片整理
activedefrag yes;极端场景重启节点。
内存淘汰 & Key 过期
evicted_keys:因内存达到maxmemory被主动淘汰的 Key 数
- 持续增长 → 内存容量不足,需扩容或优化 Key 生命周期。
expired_keys:因 TTL 过期被删除的 Key 数
- 短时间突增 → 批量 Key 集中过期,易引发缓存雪崩、瞬时 CPU / 内存抖动。
Key 统计(info keyspace)
dbX:keys:对应数据库下总 Key 数量;dbX:expires:带过期时间的 Key 数量;dbX:avg_ttl:Key 平均剩余过期时间。
衍生监控:大 Key
大 Key(超大字符串、哈希、列表)会造成命令卡顿、内存不均、集群迁移失败。排查命令:redis-cli --bigkeys,需常态化监控大 Key 数量与分布。
缓冲区内存(高危隐患)
- 客户端输入 / 输出缓冲区、主从复制缓冲区溢出,会导致客户端断连、主从同步中断。监控字段:
client_longest_output_list、client_biggest_input_buf,数值持续变大立即排查。
三、连接指标(客户端、复制连接,防连接打满、连接泄漏)
监控客户端连接数、连接状态、拒绝连接、缓冲区堆积,指标来源:info clients
核心连接指标
表格
|----------------------|------------|--------------------------|
| 字段 | 含义 | 告警规则 |
| connected_clients | 当前活跃客户端连接数 | 持续上涨、突增、接近上限均告警 |
| maxclients | 最大连接数配置 | 业务连接数不能长期接近该值 |
| rejected_connections | 被拒绝的新连接数 | 大于 0 立即告警(连接数打满,新业务无法接入) |
| blocked_clients | 阻塞客户端数 | 前文性能模块已说明 |
常见异常场景
- 连接泄漏 :
connected_clients只涨不跌 → 业务代码未正常关闭连接、连接池配置不合理; - 短连接风暴:连接数频繁波动 → 业务大量创建 / 销毁短连接,消耗 Redis 资源;
- 恶意连接:连接数瞬间暴涨 → 外网攻击、爬虫。
复制连接(主从架构)
connected_replicas:当前已连接的从节点数量,和预期副本数不一致则告警。
四、持久化指标(RDB + AOF,保障数据落地磁盘)
Redis 持久化分 RDB(快照) 和 AOF(日志追加) ,持久化失败、IO 过高会造成数据丢失、节点卡顿。指标来源:info persistence
RDB 快照监控
RDB 是全量二进制快照,触发方式:手动 bgsave、配置 save 规则。
rdb_bgsave_in_progress:是否正在执行 RDB(1 = 执行中,0 = 空闲);rdb_last_bgsave_status:上次 RDB 执行状态 (ok/err),err代表快照失败,高危;rdb_last_bgsave_time_sec:上次 RDB 耗时,耗时过长说明数据量大、磁盘慢;rdb_changes_since_last_save:上一次 RDB 后数据变更量,判断 RDB 触发频率是否合理。
风险点:RDB 执行会
fork 子进程,触发写时复制,瞬时内存占用可能翻倍,内存不足会直接 Fork 失败。
AOF 日志监控
AOF 记录每条写命令,支持实时落盘、重写压缩,主流架构AOF 必开。
aof_enabled:是否开启 AOF;aof_rewrite_in_progress:是否正在 AOF 重写(bgrewriteaof),重写会产生大量磁盘 IO;aof_last_rewrite_status/aof_last_write_status:AOF 重写 / 写入状态,失败立即告警;aof_current_size:当前 AOF 文件大小,持续膨胀说明重写策略不合理;aof_delayed_fsync:AOF 刷盘延迟次数(核心)
- 主流策略
appendfsync everysec,该值>0 代表磁盘 IO 跟不上,刷盘阻塞,业务延迟升高。
持久化配套监控
额外监控磁盘使用率、磁盘 IO 利用率、磁盘延迟:
- 磁盘使用率>85% 预警,>90% 严重(持久化无法写入,数据丢失);
- 磁盘 IO 打满 → RDB/AOF 频繁执行、磁盘性能不足。
五、集群状态监控(分两种架构:主从 + 哨兵、Redis Cluster)
Redis 生产环境几乎都是集群架构,分传统主从 + 哨兵(高可用) 和 Redis Cluster 分片集群(分布式) 两类。
架构一:主从复制 + 哨兵(Sentinel)
适用于读写分离、单分片高可用场景,指标分为主从复制 和哨兵两部分。
主从复制指标(info replication)
role:节点角色(master/replica);master_link_status:从库与主库连接状态(up/down),down代表同步中断;master_link_down_since_seconds:断连时长,越长风险越高;full_sync:全量同步次数,频繁增长为严重故障(网络差、复制缓冲区过小);partial_sync_ok:增量同步成功次数,增量同步正常代表集群稳定;replication_backlog_size:复制积压缓冲区大小,缓冲区溢出会触发全量同步。
哨兵 Sentinel 监控
哨兵负责主节点故障自动转移,建议至少 3 个奇数节点:
- 在线哨兵节点数:少于半数则集群失去故障转移能力;
- 主观下线 (SDOWN) / 客观下线 (ODOWN):主库被客观下线后会触发切换;
- 故障转移次数:短时间多次转移 → 节点不稳定、网络抖动。
架构二:Redis Cluster 官方分片集群(16384 哈希槽)
分布式分片集群,支持横向扩容,核心监控槽位、节点、集群整体状态 ,指令:cluster info、cluster nodes
集群整体状态(cluster info)
cluster_state:集群总状态(ok/fail)
fail:集群不可用(槽位缺失、节点故障),最高级别告警;
cluster_slots_assigned:已分配哈希槽总数,正常必须 = 16384,缺失槽位直接读写失败;cluster_slots_fail:故障槽位数量,>0 立即告警;cluster_known_nodes:集群已知节点数,和规划节点数对比,节点失联则异常。
节点与槽位迁移
cluster_slots_migrating/cluster_slots_importing:槽位迁出 / 迁入,正常扩容缩容短时出现,长时间停留为异常;cluster nodes:查看所有节点角色(主 / 从)、连接状态、槽位归属,存在disconnected节点告警。
集群异常表现
- 大量
MOVED/ASK重定向:槽位迁移未完成、客户端未开启集群模式; - 分片无从节点:单主节点存在单点故障风险;
- 频繁主从切换:节点宕机、内网网络不稳定。
六、汇总:常用原生监控命令 + 通用告警阈值
高频监控命令
Crystal
# 全量指标
redis-cli info
# 分模块查看
redis-cli info stats # 性能、吞吐
redis-cli info memory # 内存
redis-cli info clients # 连接
redis-cli info persistence # 持久化
redis-cli info replication # 主从复制
redis-cli info keyspace # Key统计
redis-cli cluster info # Cluster集群状态
redis-cli slowlog get 10 # 查看慢日志
redis-cli --latency # 实时延迟
redis-cli --bigkeys # 扫描大Key通用核心告警阈值参考
|--------------|---------------|----------|--------|
| 监控维度 | 指标 | 预警阈值 | 严重阈值 |
| 性能 | 缓存命中率 | 80%~90% | <80% |
| 性能 | 单核 CPU 使用率 | 70%~85% | >85% |
| 性能 | 平均延迟 | 3~5ms | >5ms |
| 内存 | 内存碎片率 | 1.5~2.0 | >2.0 |
| 内存 | 内存使用率 | 80%~85% | >85% |
| 连接 | 拒绝连接数 | >0 | 持续增长 |
| 持久化 | RDB/AOF 执行状态 | 执行失败 1 次 | 连续多次失败 |
| 磁盘 | 磁盘使用率 | 85%~90% | >90% |
| 集群 (Cluster) | cluster_state | - | fail |
| 主从复制 | 主从连接状态 | down | 断连>30s |
七、排障简易思路
- 业务卡顿:先查延迟、CPU、慢日志 → 定位慢命令 / 大 Key;
- 服务不可用:先查连接数、拒绝连接、集群状态;
- 内存飙升:查内存碎片、Key 数量、大 Key、内存淘汰次数;
- 数据丢失风险:优先检查 RDB/AOF 状态、磁盘空间;
- 集群频繁切换:检查内网网络、节点负载、哨兵 / 集群节点在线数。
Prometheus+Grafana搭建Redis可视化监控平台
本文基于 Linux 服务器 (CentOS 7+/Ubuntu 18+),手把手带你搭建Redis Exporter + Prometheus + Grafana 监控架构,实现 Redis 指标的采集、存储和可视化展示。
一、整体架构
核心三个组件,分工明确:
- Redis Exporter:采集 Redis 运行指标,暴露 HTTP 接口供 Prometheus 拉取(端口:9121);
- Prometheus:定时拉取 Exporter 指标,存储到时序数据库(端口:9090);
- Grafana:对接 Prometheus 数据源,制作可视化监控大盘(端口:3000)。
二、前置准备
- 服务器已安装 Redis 并正常运行(默认端口 6379);
- 开放防火墙端口:9121、9090、3000;
- 拥有服务器
root/sudo权限。
三、步骤 1:安装 Redis Exporter(指标采集)
Prometheus 无法直接监控 Redis,需要通过 Redis Exporter 暴露标准监控指标。
下载并安装
Crystal
# 下载最新版 Redis Exporter(github官方)
wget https://github.com/oliver006/redis_exporter/releases/download/v1.54.0/redis_exporter-v1.54.0.linux-amd64.tar.gz
# 解压
tar -zxvf redis_exporter-v1.54.0.linux-amd64.tar.gz
# 移动到系统可执行目录
mv redis_exporter-v1.54.0.linux-amd64/redis_exporter /usr/local/bin/启动并验证
Crystal
# 重载服务配置
systemctl daemon-reload
# 开机自启
systemctl enable redis_exporter
# 启动服务
systemctl start redis_exporter
# 查看状态(显示active即成功)
systemctl status redis_exporter验证指标暴露
访问地址(服务器 IP:9121),看到 Redis 指标即正常:
Crystal
http://你的服务器IP:9121/metrics四、步骤 2:安装并配置 Prometheus(指标存储)
下载安装 Prometheus
Crystal
# 下载
wget https://github.com/prometheus/prometheus/releases/download/v2.47.0/prometheus-2.47.0.linux-amd64.tar.gz
# 解压
tar -zxvf prometheus-2.47.0.linux-amd64.tar.gz
# 移动到安装目录
mv prometheus-2.47.0.linux-amd64 /usr/local/prometheus
# 创建数据存储目录
mkdir -p /usr/local/prometheus/data配置 Redis 监控任务
修改 Prometheus 核心配置文件:
Crystal
vim /usr/local/prometheus/prometheus.yml追加 Redis 监控配置 (保留原有配置,在 scrape_configs 下添加):
yaml
Crystal
scrape_configs:# 原有prometheus自身监控(保留)
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
# ✅ 新增:Redis 监控任务
- job_name: "redis"
scrape_interval: 5s
# 5秒拉取一次指标
static_configs:
- targets: ["localhost:9121"] # 指向Redis Exporter地址配置系统服务
Crystal
vim /etc/systemd/system/prometheus.service写入配置:
Crystal
[Unit]
Description=Prometheus
After=network.target
[Service]
User=root
ExecStart=/usr/local/prometheus/prometheus \
--config.file=/usr/local/prometheus/prometheus.yml \
--storage.tsdb.path=/usr/local/prometheus/data \
--storage.tsdb.retention.time=15d
# 数据保留15天
Restart=on-failure
[Install]
WantedBy=multi-user.target启动并验证
Crystal
systemctl daemon-reload
systemctl enable prometheus
systemctl start prometheus
systemctl status prometheus访问 Prometheus UI 验证监控目标:
Crystal
http://你的服务器IP:9090进入 Status → Targets,看到 redis 状态为 UP 即配置成功。
五、步骤 3:安装并配置 Grafana(可视化展示)
安装 Grafana
CentOS 系统
Crystal
wget https://dl.grafana.com/oss/release/grafana-10.1.0-1.x86_64.rpm
yum install -y grafana-10.1.0-1.x86_64.rpmUbuntu 系统
Crystal
wget https://dl.grafana.com/oss/release/grafana_10.1.0_amd64.deb
dpkg -i grafana_10.1.0_amd64.deb
apt install -f -y启动 Grafana
Crystal
systemctl daemon-reload
systemctl enable grafana-server
systemctl start grafana-server
systemctl status grafana-server登录 Grafana
访问地址:
Crystal
http://你的服务器IP:3000默认账号密码:admin/admin,首次登录需修改密码。
六、步骤 4:Grafana 配置 Prometheus 数据源
- 左侧菜单 → Connections → Data sources → Add data source;
- 选择 Prometheus;
- 配置
Connection→URL:http://localhost:9090; - 拉到最下方 → 点击 Save & test ,提示
Data source is working即成功。
七、步骤 5:导入 Redis 官方监控仪表盘
无需手动画图,直接导入开源 Redis 监控仪表盘(推荐 ID:11833):
- 左侧菜单 → Dashboards → Import;
- 在
Import via grafana.com输入仪表盘 ID:11833 → 点击Load; - 下方选择数据源:
Prometheus→ 点击Import;
✅ 完成!立即看到 Redis 完整可视化监控:
- Redis 内存使用、命中率、连接数
- 键值数量、命中率、慢查询
- CPU、内存、网络流量
- 主从复制状态
八、常见问题排查
- Prometheus Targets 显示 DOWN
- 检查 Redis Exporter 状态:
systemctl status redis_exporter - 检查端口 9121 是否开放:
firewall-cmd --query-port=9121/tcp
- Exporter 无法连接 Redis
- 确认 Redis 地址、密码正确
- 重启 Exporter:
systemctl restart redis_exporter
- Grafana 无数据
- 检查 Prometheus 数据源连接是否正常
- 确认仪表盘 ID 正确(推荐 11833)
- 防火墙端口未开放
- bash
- 运行
Crystal
# CentOS 开放端口
firewall-cmd --add-port=9121/tcp --permanent
firewall-cmd --add-port=9090/tcp --permanent
firewall-cmd --add-port=3000/tcp --permanent
firewall-cmd --reload总结
- 核心流程:Redis Exporter 采集 → Prometheus 存储 → Grafana 展示;
- 关键端口:9121 (Exporter)、9090 (Prometheus)、3000 (Grafana);
- 一键复用:Grafana 仪表盘 ID
11833是 Redis 监控最佳实践; - 支持密码 Redis、集群 Redis,仅需修改 Exporter 启动参数即可。
日志分析、慢查询排查、性能溯源方法
Redis 性能问题是缓存服务的核心痛点,日志分析 定位基础异常、慢查询 锁定命令瓶颈、性能溯源 全维度排查根因,三者结合是生产环境 Redis 运维的标准流程。本文全部为可直接复制执行的命令、配置和排查步骤,覆盖单机 / 主从 / 集群场景。
一、Redis 日志分析(基础异常排查)
Redis 运行日志是排查启动失败、持久化异常、网络错误、内存溢出的核心依据,慢查询属于独立日志模块。
日志核心配置
编辑 redis.conf 开启文件日志(生产必配):
ini
Crystal
# 日志文件路径(需确保Redis有写入权限)
logfile "/var/log/redis/redis-server.log"
# 日志级别:生产推荐 notice/warning,测试用 verbose/debug
loglevel notice
# 关闭系统日志,避免污染
syslog-enabled no临时生效(重启失效):
Crystal
redis-cli config set logfile "/var/log/redis/redis-server.log"
redis-cli config set loglevel notice日志级别说明
表格
|---------|--------|-----|
| 级别 | 适用场景 | 日志量 |
| warning | 生产极简日志 | 最少 |
| notice | 生产标准级别 | 适中 |
| verbose | 测试调试 | 较多 |
| debug | 开发调试 | 极多 |
日志分析实操命令
Crystal
# 1. 筛选错误/警告/失败日志
grep -i "error\|warning\|fail\|denied" /var/log/redis/redis-server.log
# 2. 查看近1小时异常日志
grep "$(date -d '1 hour ago' +'%Y-%m-%d %H')" /var/log/redis/redis-server.log
# 3. 统计异常类型(定位高频问题)
awk '/error|Warning|Fail/{print $0}' /var/log/redis/redis-server.log | sort | uniq -c常见日志异常与解决方案
|-----------------------------|-----------------|----------------------|
| 日志关键字 | 问题原因 | 解决方案 |
| Failed opening the RDB file | 磁盘权限不足 / 磁盘满 | 授权 Redis 目录、清理磁盘 |
| OOM command not allowed | 达到 maxmemory 上限 | 调整内存、配置淘汰策略、删除无用 key |
| Connection reset by peer | 客户端断开连接 / 网络故障 | 检查客户端连接池、网络连通性 |
| High memory fragmentation | 内存碎片过高 | 开启自动碎片整理 |
| RDB: fork failed | 内存不足导致 fork 阻塞 | 降低内存使用、优化持久化策略 |
二、Redis 慢查询排查(核心性能瓶颈)
Redis 是单线程模型,慢查询会直接阻塞所有请求,是性能卡顿的首要排查对象。
重要:慢查询仅记录命令执行时间,不包含网络传输、命令排队时间!
慢查询原理与配置
慢查询记录执行耗时超过阈值的命令,存储在内存队列中(循环覆盖)。
永久配置(redis.conf)
Crystal
# 阈值:10000微秒 = 10毫秒(超过则记录)
slowlog-log-slower-than 10000
# 慢查询队列最大长度(最多存储1000条)
slowlog-max-len 1000临时配置(生产快速排查)
Crystal
# 设置阈值为10ms
redis-cli config set slowlog-log-slower-than 10000# 设置队列长度
redis-cli config set slowlog-max-len 1000# 验证配置
redis-cli config get slowlog*慢查询核心操作命令
Crystal
# 1. 查看所有慢查询
redis-cli slowlog get
# 2. 查看最近10条慢查询(推荐)
redis-cli slowlog get 10# 3. 查看慢查询总数量
redis-cli slowlog len
# 4. 清空慢查询日志(优化后执行)
redis-cli slowlog reset慢查询日志字段解析
Crystal
1) (integer) 1234 # 慢查询唯一ID
2) (integer) 1718987654 # 执行时间戳
3) (integer) 15000 # 执行耗时(微秒:15ms)
4) 1) "KEYS" # 执行的命令
2) "*"
5) "192.168.1.100:6379" # 客户端IP:端口(Redis4.0+)慢查询标准排查步骤
- 确认配置生效 :
config get slowlog* - 拉取慢查询 :定位高频、高耗时命令
- 关联业务:确认命令使用场景(是否滥用)
- 优化落地:修改命令 / 拆分数据 / 调整架构
高频慢查询原因 + 最优优化方案
|----------------|----------------|----------------------------------|
| 慢查询命令 | 问题根源 | 优化方案 |
| KEYS * | 全量扫描 key,阻塞主线程 | 用 SCAN 迭代命令替代 |
| HGETALL/LRANGE | 大 Key 全量获取 | 拆分大 Key、分页获取(HSCAN/LRANGE 0 100) |
| SORT/SUNION | 集合复杂计算 | 简化逻辑、提前计算结果缓存 |
| 批量MSET/MGET | 无节制批量操作 | 控制批量大小(≤100) |
| 复杂 LUA 脚本 | 脚本逻辑过重 | 拆分脚本、避免循环操作 |
三、Redis 性能溯源(全维度根因定位)
慢查询仅覆盖命令耗时 问题,而 CPU 100%、内存暴涨、连接超时、QPS 下跌、主从延迟 等问题,需要全维度性能溯源。
核心原生排查命令(必掌握)
Redis 自带的 info 命令是性能溯源的万能工具,分模块查看核心指标:
(1)全能 info 命令
Crystal
# 核心统计:QPS、缓存命中率、命令执行量
redis-cli info stats
# CPU使用:定位CPU瓶颈
redis-cli info cpu
# 内存使用:大Key、内存碎片、溢出
redis-cli info memory
# 客户端:连接数、阻塞客户端
redis-cli info clients
# 持久化:RDB/AOF状态、fork阻塞
redis-cli info persistence
# 主从同步:延迟、偏移量
redis-cli info replication关键指标阈值:
- 缓存命中率:
keyspace_hits/(hits+misses) > 99%(低于 95% 异常) - 内存碎片率:
mem_fragmentation_ratio < 1.5(高于 2.0 需整理) - 阻塞客户端:
blocked_clients = 0(>0 表示有阻塞命令) - QPS:
instantaneous_ops_per_sec业务正常值波动
(2)实时状态监控
Crystal
# 实时刷新QPS、内存、连接数(每秒刷新)
redis-cli --stat -i 1(3)大 Key 排查(Redis 性能第一杀手)
Crystal
# 自动扫描所有大Key,降低扫描压力(生产必用)
redis-cli --bigkeys -i 0.01大 Key 定义:String > 10KB、Hash/List > 5000 个元素,会导致主线程阻塞、网络拥堵。
(4)热 Key 排查(Redis 4.0+)
Crystal
# 扫描高并发访问的热Key
redis-cli --hotkeys(5)慎用命令:monitor
Crystal
# 实时打印所有执行命令,生产仅短时间使用(会压垮Redis)
redis-cli monitor | grep -i "keys\|hgetall"全维度性能溯源流程(生产标准)
场景 1:CPU 使用率 100%
- 查慢查询:
slowlog get→ 定位高耗时命令 - 查热 Key:
--hotkeys→ 单 Key 高并发 - 查持久化:
info persistence→ 频繁 RDB/AOF 重写 - 解决:优化命令、拆分热 Key、低峰期持久化
场景 2:内存暴涨 / 溢出
- 查内存:
info memory→ 看峰值、碎片率 - 查大 Key:
--bigkeys→ 定位超大数据 - 查过期:
info stats→ key 过期策略失效 - 解决:删除无用大 Key、开启内存碎片整理、扩容内存
场景 3:客户端超时 / 连接爆高
- 查客户端:
info clients→blocked_clients>0、连接数超限 - 查网络:
netstat -an | grep 6379→ TCP 队列满 - 解决:优化连接池、处理阻塞命令(BLPOP)、调大
tcp-backlog
场景 4:持久化导致卡顿
- 查日志:
grep fork redis.log→ fork 耗时过长 - 查配置:AOF
fsync策略、RDB 频率 - 解决:AOF 设为
everysec、无盘复制、低峰期执行持久化
场景 5:主从同步延迟
- 查主从:
info replication→ 偏移量差值 - 查网络:主从网络带宽、延迟
- 解决:调大
repl-backlog-size、降低主库写压力
生产级监控工具
- 可视化:Redis Insight(官方免费)
- 监控告警:Prometheus + Redis Exporter + Grafana
- 日志分析:ELK/Loki
- 压测工具:
redis-benchmark
四、生产快速排查总结(5 分钟定位问题)
- 第一步:查慢查询
redis-cli slowlog get 10→ 锁定高耗时命令 - 第二步:查核心指标
redis-cli info stats cpu memory→ 看命中率、CPU、内存 - 第三步:查数据问题
redis-cli --bigkeys --hotkeys→ 定位大 Key / 热 Key - 第四步:查客户端 / 持久化
info clients persistence→ 排除阻塞、持久化故障 - 第五步:查系统日志
grep error redis.log→ 定位系统级异常
总结
- 日志分析:聚焦错误 / 警告,解决启动、持久化、网络等基础异常;
- 慢查询 :核心排查命令瓶颈,禁止 KEYS/FLUSHALL、拆分大 Key 是关键;
- 性能溯源 :依托
info/bigkeys/hotkeys,从 CPU、内存、客户端、持久化全维度定位,Redis 单线程主线程阻塞是所有严重性能问题的根因。
自动化备份、故障告警、日常运维规范
生产环境 Redis 运维的核心目标:数据不丢失、服务不中断、操作无风险 。本文从自动化备份(防数据丢失) 、故障告警(防服务不可用) 、日常运维规范(防人为故障) 三个维度,提供可直接落地的方案。
适用场景:单机 / 主从 / 哨兵 / Redis Cluster 架构,Linux 环境。
一、Redis 自动化备份方案
备份是 Redis 数据安全的最后防线,必须做到自动化、定时化、可清理、可恢复。
生产备份最佳策略
- 持久化配置(基础)
- 开启 RDB+AOF 混合持久化(Redis 4.0+),兼顾全量备份速度和增量数据安全性;
- 主节点禁用
SAVE阻塞式备份,仅使用BGSAVE后台备份。
- 备份频率
- 全量备份:每天凌晨低峰期执行 1 次(RDB 文件);
- 增量备份:AOF 文件实时持久化,定期归档;
- 备份存储
- 本地保留 7 天备份,异地备份(跨服务器 / 云存储)保留 30 天;
- 禁止将备份文件与 Redis 数据文件存放在同一块磁盘。
自动化备份脚本(Shell)
支持:自动备份、压缩、过期清理、异地同步、日志记录
Crystal
#!/bin/bash
# Redis 自动备份脚本 redis_backup.sh
########################### 配置项 ###########################
REDIS_PORT=6379REDIS_PASS="your_redis_password"
# 无密码留空
REDIS_CLI="/usr/local/bin/redis-cli"
BACKUP_DIR="/data/redis/backup"
# 本地备份目录
REMOTE_BACKUP="root@192.168.1.100:/data/redis/remote_backup"
# 异地备份服务器
KEEP_DAYS=7
# 本地保留天数
DATE=$(date +%Y%m%d_%H%M%S)
LOG_FILE="/var/log/redis_backup.log"
############################################################### 创建备份目录
mkdir -p $BACKUP_DIR
# 日志函数
log() {echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" >> $LOG_FILE}# 1. 执行后台备份(不阻塞Redis)if [ -n "$REDIS_PASS" ]; then$REDIS_CLI -p $REDIS_PORT -a $REDIS_PASS --no-auth-warning bgsave
else$REDIS_CLI -p $REDIS_PORT bgsave
fi
# 等待备份完成
sleep 10
# 2. 查找最新的RDB文件(默认路径:/var/lib/redis/dump.rdb)
RDB_FILE=$(find /var/lib/redis -name "dump.rdb" -type f -mmin -5 | head -1)
if [ ! -f "$RDB_FILE" ]; then
log "ERROR: RDB备份文件生成失败!"exit 1
fi
# 3. 复制并压缩备份文件
BACKUP_NAME="redis_${REDIS_PORT}_${DATE}.rdb"
cp $RDB_FILE $BACKUP_DIR/$BACKUP_NAMEgzip $BACKUP_DIR/$BACKUP_NAME
log "SUCCESS: 备份完成 -> $BACKUP_DIR/$BACKUP_NAME.gz"
# 4. 清理过期备份
find $BACKUP_DIR -name "redis_${REDIS_PORT}_*.rdb.gz" -mtime +$KEEP_DAYS -delete
log "SUCCESS: 清理${KEEP_DAYS}天前备份完成"
# 5. 异地同步备份(免密登录前提:配置ssh密钥)
rsync -az $BACKUP_DIR/ $REMOTE_BACKUP
log "SUCCESS: 异地备份同步完成"定时任务配置(crontab)
每天凌晨 2 点执行备份(低峰期)
Crystal
# 添加执行权限
chmod +x /data/redis/redis_backup.sh
# 编辑定时任务
crontab -e
# 新增:每天2:00执行
0 2 * * * /data/redis/redis_backup.sh备份恢复验证(强制要求)
每月必须做一次恢复测试,防止备份文件损坏:
- 停止测试 Redis 实例;
- 将备份的
dump.rdb.gz解压后覆盖数据目录; - 启动 Redis,验证数据完整性。
备份注意事项
- 优先在从节点执行备份,不影响主节点性能;
- 禁止在业务高峰期执行
BGSAVE; - 备份文件权限设置为
600,防止泄露。
二、Redis 故障告警方案
核心:早发现、早处理,覆盖服务存活、性能、容量、主从同步四大类故障。
核心监控告警指标
|------|-------------------------|---------------------|------|
| 告警类型 | 监控指标 | 告警阈值 | 告警级别 |
| 服务存活 | Redis 端口 / 进程 / PING 响应 | 端口不通、PING 非 PONG | 紧急 |
| 内存告警 | used_memory | 超过 maxmemory 的 90% | 重要 |
| 连接数 | connected_clients | 超过 maxclients 的 80% | 重要 |
| 主从同步 | 主从断开、复制延迟 | link_down=1 | 紧急 |
| 持久化 | RDB/AOF 生成失败 | 持久化状态异常 | 重要 |
| 慢查询 | slowlog | 超过 100ms / 累计 100 条 | 一般 |
| 阻塞风险 | latest_fork_usec | fork 耗时超过 500ms | 一般 |
简易告警实现(零依赖:Shell + 钉钉机器人)
适合中小团队,无需部署监控系统,直接检测 Redis 状态并发送告警。
Crystal
#!/bin/bash
# Redis 存活告警脚本 redis_alert.sh
REDIS_PORT=6379REDIS_CLI="/usr/local/bin/redis-cli"
DING_WEBHOOK="https://oapi.dingtalk.com/robot/send?access_token=你的钉钉机器人token"
# 检测Redis是否存活
if $REDIS_CLI -p $REDIS_PORT ping | grep -q PONG; then
exit 0
else
# 发送钉钉告警
curl -s $DING_WEBHOOK \
-H "Content-Type: application/json" \
-d '{"msgtype":"text","text":{"content":"【Redis告警】端口'$REDIS_PORT' 服务宕机!"}}'
fi定时任务:每分钟检测一次
* * * * * /data/redis/redis_alert.sh企业级监控告警(推荐)
大型集群使用 Prometheus + redis_exporter + Grafana + Alertmanager 方案:
redis_exporter:采集 Redis 监控指标;Prometheus:存储指标、配置告警规则;Grafana:可视化大盘;Alertmanager:推送告警到钉钉 / 企业微信 / 邮件。
告警分级处理流程
- 紧急告警(服务宕机、主从断开):电话 + 短信通知,5 分钟内响应;
- 重要告警(内存 / 连接满、持久化失败):钉钉通知,30 分钟内处理;
- 一般告警(慢查询、fork 阻塞):工作日处理,优化配置 / 业务。
三、Redis 日常运维规范
从配置、部署、操作、巡检、安全、故障六个维度,制定标准化规范,杜绝人为故障。
配置安全规范(禁止裸奔)
- 必配密码 :
requirepass your_strong_password,密码复杂度≥16 位; - 网络限制 :
bind 127.0.0.1 内网IP,禁止绑定 0.0.0.0 对外暴露; - 禁用危险命令:
- ini
Crystal
rename-command KEYS ""
rename-command FLUSHDB ""
rename-command FLUSHALL ""
rename-command CONFIG ""- 内存限制 :
maxmemory 10G(按服务器配置)+maxmemory-policy allkeys-lru; - 开启保护模式 :
protected-mode yes。
部署架构规范
- 单机:仅用于测试环境;
- 生产:主从 + 哨兵 (高可用)或 Redis Cluster(分布式);
- 主从分离:主节点写、从节点读,备份在从节点执行;
- 资源隔离:Redis 独占 CPU / 内存,不与其他服务混部。
日常操作规范(红线禁令)
- 禁止线上执行 :
KEYS *、FLUSHDB、FLUSHALL、CONFIG等命令; - 禁止直接修改配置:修改前备份配置,测试环境验证后再上线;
- 禁止暴力重启 :重启前执行
BGSAVE,避免数据丢失; - 禁止 root 运行 :使用专用用户
redis运行服务。
定期巡检规范
|------|-----------------------|
| 巡检频率 | 巡检内容 |
| 每日 | 服务存活、内存使用率、连接数、主从同步状态 |
| 每周 | 备份文件有效性、慢查询日志、错误日志 |
| 每月 | 性能瓶颈分析、容量规划、密码轮换、配置审计 |
权限与安全规范
- 端口
6379不对外开放,仅内网访问; - 定期(3 个月)轮换 Redis 密码;
- 开启 Redis 日志:
logfile /var/log/redis/redis-server.log; - 日志保留 180 天,用于安全审计。
故障处理规范
- 先恢复,后排查:服务宕机优先启动实例 / 主从切换,再定位根因;
- 禁止盲目操作 :故障时不随意执行
FLUSH、重启等操作; - 故障复盘:所有 P0/P1 故障必须记录报告,优化预案。
总结
- 备份 :用 Shell 脚本实现定时全量备份 + 异地存储,必须定期验证恢复;
- 告警:简易场景用 Shell + 钉钉,企业级用 Prometheus 栈,覆盖核心故障指标;
- 运维:严格遵守配置、操作、巡检规范,从根源避免数据丢失和服务故障。
按照这套方案落地,可满足 99% 的生产环境 Redis 运维需求。