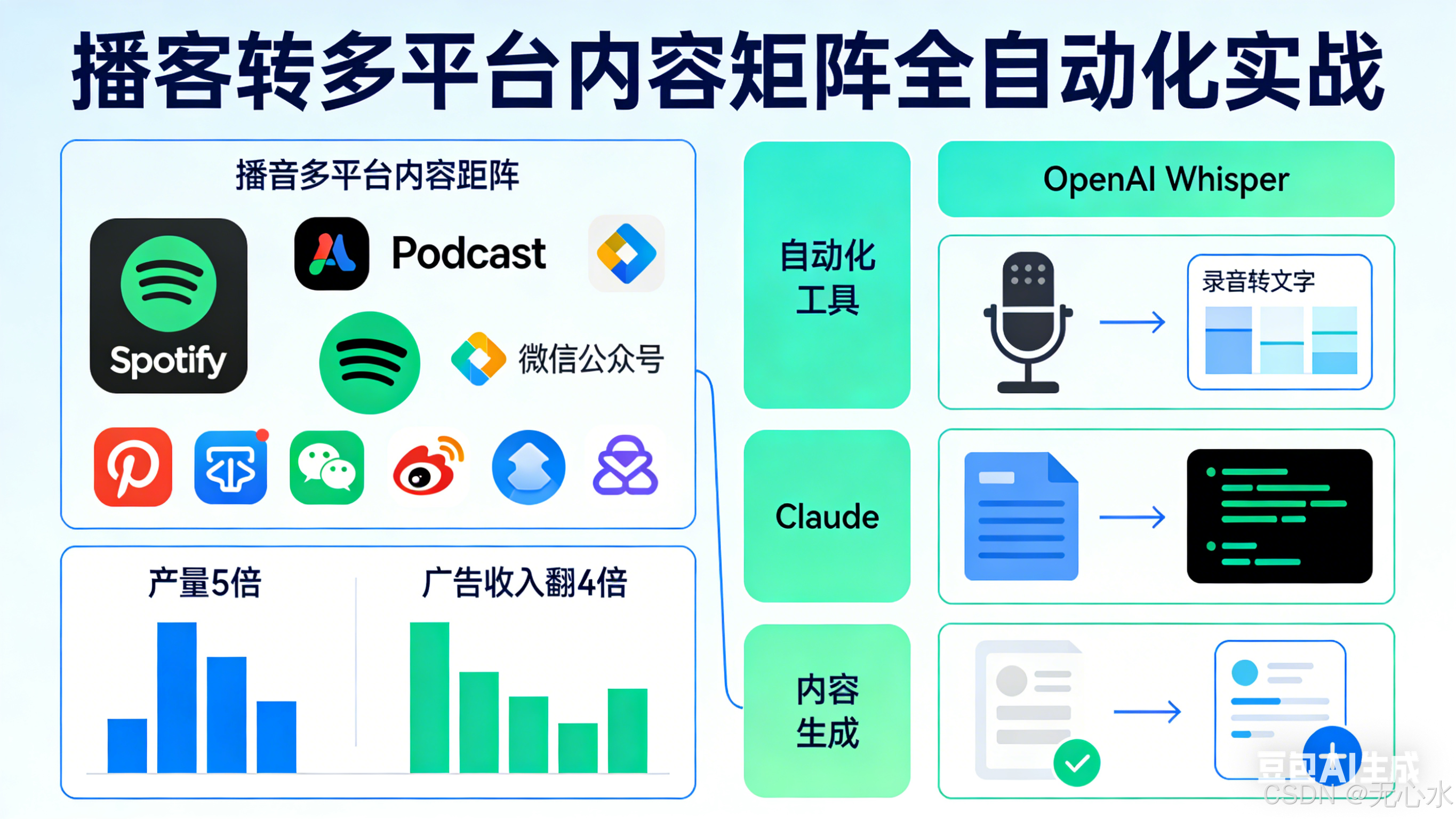
内容产量5倍、广告收入翻4倍:播客转多平台内容矩阵全自动化实战(OpenAI Whisper + Claude)
本文拆解内容创业者社区真实案例:用AI自动化将单期播客拆解为跨平台内容矩阵,内容产量提升5倍,广告月收入从¥8,000暴涨至¥35,000。从音频转写、内容提炼到多平台草稿生成,手把手教你打造高效内容分发流水线。
一、案例背景:内容创作者的效率革命
1.1 核心数据与业务本质
一位科技类播客主通过AI自动化内容矩阵系统,实现了内容生产与商业收入的双重飞跃:
| 核心指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 单期内容产量 | 1期播客 | 1套完整内容矩阵(6类内容) | +500% |
| 周更新频率 | 1次/周 | 5次/周 | +400% |
| 月广告收入 | ¥8,000 | ¥35,000 | +337.5% |
| 内容生产耗时 | 8小时/期 | 1小时/期 | -87.5% |
| 平台覆盖 | 仅播客 | 播客+公众号+小红书+微博+LinkedIn+短视频 | +500% |
业务本质 :
播客是「高信息密度、低分发效率」的内容形态,单期1小时音频只能触达播客平台用户,无法复用至其他渠道。本系统通过OpenAI Whisper + Claude Sonnet实现「音频转写→内容提炼→多平台适配生成」全流程自动化,将1期播客拆解为适配不同平台的内容矩阵,最大化内容复用价值,同时提升曝光与广告收入。
1.2 传统内容创作痛点与AI解决方案
传统创作痛点
- 内容复用率低:1小时播客只能在单一平台分发,信息密度高但传播范围窄
- 多平台适配繁琐:手动为公众号、小红书、微博等平台改写内容,耗时4-6小时
- 更新频率受限:每周仅能产出1期播客,无法满足多平台高频更新需求
- 商业变现弱:曝光量不足,广告收入天花板低
AI自动化解决方案
通过AI将单期播客拆解为6类跨平台内容,实现「一次创作、多平台分发」,将内容生产效率提升8倍以上,同时扩大曝光范围,提升广告收入。
二、内容矩阵生产全流程:从音频到多平台草稿
2.1 完整流程总览(Mermaid流程图)
#mermaid-svg-HjZirYXtR6CEuKiT{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-HjZirYXtR6CEuKiT .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-HjZirYXtR6CEuKiT .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-HjZirYXtR6CEuKiT .error-icon{fill:#552222;}#mermaid-svg-HjZirYXtR6CEuKiT .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-HjZirYXtR6CEuKiT .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-HjZirYXtR6CEuKiT .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-HjZirYXtR6CEuKiT .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-HjZirYXtR6CEuKiT .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-HjZirYXtR6CEuKiT .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-HjZirYXtR6CEuKiT .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-HjZirYXtR6CEuKiT .marker{fill:#333333;stroke:#333333;}#mermaid-svg-HjZirYXtR6CEuKiT .marker.cross{stroke:#333333;}#mermaid-svg-HjZirYXtR6CEuKiT svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-HjZirYXtR6CEuKiT p{margin:0;}#mermaid-svg-HjZirYXtR6CEuKiT .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-HjZirYXtR6CEuKiT .cluster-label text{fill:#333;}#mermaid-svg-HjZirYXtR6CEuKiT .cluster-label span{color:#333;}#mermaid-svg-HjZirYXtR6CEuKiT .cluster-label span p{background-color:transparent;}#mermaid-svg-HjZirYXtR6CEuKiT .label text,#mermaid-svg-HjZirYXtR6CEuKiT span{fill:#333;color:#333;}#mermaid-svg-HjZirYXtR6CEuKiT .node rect,#mermaid-svg-HjZirYXtR6CEuKiT .node circle,#mermaid-svg-HjZirYXtR6CEuKiT .node ellipse,#mermaid-svg-HjZirYXtR6CEuKiT .node polygon,#mermaid-svg-HjZirYXtR6CEuKiT .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-HjZirYXtR6CEuKiT .rough-node .label text,#mermaid-svg-HjZirYXtR6CEuKiT .node .label text,#mermaid-svg-HjZirYXtR6CEuKiT .image-shape .label,#mermaid-svg-HjZirYXtR6CEuKiT .icon-shape .label{text-anchor:middle;}#mermaid-svg-HjZirYXtR6CEuKiT .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-HjZirYXtR6CEuKiT .rough-node .label,#mermaid-svg-HjZirYXtR6CEuKiT .node .label,#mermaid-svg-HjZirYXtR6CEuKiT .image-shape .label,#mermaid-svg-HjZirYXtR6CEuKiT .icon-shape .label{text-align:center;}#mermaid-svg-HjZirYXtR6CEuKiT .node.clickable{cursor:pointer;}#mermaid-svg-HjZirYXtR6CEuKiT .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-HjZirYXtR6CEuKiT .arrowheadPath{fill:#333333;}#mermaid-svg-HjZirYXtR6CEuKiT .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-HjZirYXtR6CEuKiT .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-HjZirYXtR6CEuKiT .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-HjZirYXtR6CEuKiT .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-HjZirYXtR6CEuKiT .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-HjZirYXtR6CEuKiT .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-HjZirYXtR6CEuKiT .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-HjZirYXtR6CEuKiT .cluster text{fill:#333;}#mermaid-svg-HjZirYXtR6CEuKiT .cluster span{color:#333;}#mermaid-svg-HjZirYXtR6CEuKiT div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-HjZirYXtR6CEuKiT .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-HjZirYXtR6CEuKiT rect.text{fill:none;stroke-width:0;}#mermaid-svg-HjZirYXtR6CEuKiT .icon-shape,#mermaid-svg-HjZirYXtR6CEuKiT .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-HjZirYXtR6CEuKiT .icon-shape p,#mermaid-svg-HjZirYXtR6CEuKiT .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-HjZirYXtR6CEuKiT .icon-shape .label rect,#mermaid-svg-HjZirYXtR6CEuKiT .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-HjZirYXtR6CEuKiT .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-HjZirYXtR6CEuKiT .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-HjZirYXtR6CEuKiT :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 多平台内容
完整整理稿(5000字,带时间戳)
精华摘要(800字,公众号版)
小红书×10(200字/条+配图提示)
微博×5(140字/条)
LinkedIn英文文章(1500字)
Shorts脚本×3(30秒金句片段)
上传播客音频文件
OpenAI Whisper Skill转写
自动断句+说话人识别+时间戳
Claude Sonnet内容理解与提炼
生成完整内容矩阵
存入对应平台草稿箱
人工审核后发布
2.2 Step 1:音频转写------OpenAI Whisper Skill
核心能力:
- 自动将播客音频(MP3/WAV/M4A)转写为完整文本
- 自动断句、识别说话人(区分主播/嘉宾)
- 生成带时间戳的文稿(便于定位音频片段)
- 支持中英文混合识别,准确率>95%
输出格式:
[00:00:00] 主播:大家好,欢迎来到本期播客...
[00:01:23] 嘉宾:我认为AI的核心价值在于...
[00:05:45] 主播:我们来聊聊具体的落地案例...2.3 Step 2:内容提炼------Claude Sonnet
核心能力:
- 理解播客核心主题、论点、案例、金句
- 区分核心信息与冗余内容,提炼精华
- 按不同平台的内容规范,生成适配版本
- 保留播客的口语化风格,同时符合书面表达要求
2.4 Step 3:多平台内容矩阵生成
| 内容类型 | 字数/规格 | 平台 | 核心用途 |
|---|---|---|---|
| 完整整理稿 | 5000字,带时间戳 | 播客简介、知识库 | 供深度用户查阅,留存核心信息 |
| 精华摘要 | 800字 | 公众号 | 适合长阅读,传递核心观点 |
| 小红书笔记 | 10条×200字 + 配图提示 | 小红书 | 抓眼球、引流量,适合碎片化阅读 |
| 微博短文 | 5条×140字 | 微博 | 快速传播观点,引发讨论 |
| LinkedIn文章 | 1500字(英文) | 面向职场/海外用户,提升专业影响力 | |
| Shorts脚本 | 3条×30秒 | 抖音/YouTube Shorts | 提取金句片段,适配短视频传播 |
2.5 Step 4:草稿箱同步
- 自动将生成的内容存入对应平台草稿箱(如公众号草稿、小红书草稿、LinkedIn draft)
- 等待人工审核、调整配图/排版后发布
- 保留人工干预入口,保证内容质量与品牌一致性
三、系统架构:OpenAI + Claude 驱动的内容流水线
3.1 整体架构图(Mermaid)
#mermaid-svg-PY0cYGWO0m0pK11K{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-PY0cYGWO0m0pK11K .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-PY0cYGWO0m0pK11K .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-PY0cYGWO0m0pK11K .error-icon{fill:#552222;}#mermaid-svg-PY0cYGWO0m0pK11K .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-PY0cYGWO0m0pK11K .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-PY0cYGWO0m0pK11K .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-PY0cYGWO0m0pK11K .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-PY0cYGWO0m0pK11K .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-PY0cYGWO0m0pK11K .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-PY0cYGWO0m0pK11K .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-PY0cYGWO0m0pK11K .marker{fill:#333333;stroke:#333333;}#mermaid-svg-PY0cYGWO0m0pK11K .marker.cross{stroke:#333333;}#mermaid-svg-PY0cYGWO0m0pK11K svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-PY0cYGWO0m0pK11K p{margin:0;}#mermaid-svg-PY0cYGWO0m0pK11K .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-PY0cYGWO0m0pK11K .cluster-label text{fill:#333;}#mermaid-svg-PY0cYGWO0m0pK11K .cluster-label span{color:#333;}#mermaid-svg-PY0cYGWO0m0pK11K .cluster-label span p{background-color:transparent;}#mermaid-svg-PY0cYGWO0m0pK11K .label text,#mermaid-svg-PY0cYGWO0m0pK11K span{fill:#333;color:#333;}#mermaid-svg-PY0cYGWO0m0pK11K .node rect,#mermaid-svg-PY0cYGWO0m0pK11K .node circle,#mermaid-svg-PY0cYGWO0m0pK11K .node ellipse,#mermaid-svg-PY0cYGWO0m0pK11K .node polygon,#mermaid-svg-PY0cYGWO0m0pK11K .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-PY0cYGWO0m0pK11K .rough-node .label text,#mermaid-svg-PY0cYGWO0m0pK11K .node .label text,#mermaid-svg-PY0cYGWO0m0pK11K .image-shape .label,#mermaid-svg-PY0cYGWO0m0pK11K .icon-shape .label{text-anchor:middle;}#mermaid-svg-PY0cYGWO0m0pK11K .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-PY0cYGWO0m0pK11K .rough-node .label,#mermaid-svg-PY0cYGWO0m0pK11K .node .label,#mermaid-svg-PY0cYGWO0m0pK11K .image-shape .label,#mermaid-svg-PY0cYGWO0m0pK11K .icon-shape .label{text-align:center;}#mermaid-svg-PY0cYGWO0m0pK11K .node.clickable{cursor:pointer;}#mermaid-svg-PY0cYGWO0m0pK11K .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-PY0cYGWO0m0pK11K .arrowheadPath{fill:#333333;}#mermaid-svg-PY0cYGWO0m0pK11K .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-PY0cYGWO0m0pK11K .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-PY0cYGWO0m0pK11K .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-PY0cYGWO0m0pK11K .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-PY0cYGWO0m0pK11K .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-PY0cYGWO0m0pK11K .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-PY0cYGWO0m0pK11K .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-PY0cYGWO0m0pK11K .cluster text{fill:#333;}#mermaid-svg-PY0cYGWO0m0pK11K .cluster span{color:#333;}#mermaid-svg-PY0cYGWO0m0pK11K div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-PY0cYGWO0m0pK11K .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-PY0cYGWO0m0pK11K rect.text{fill:none;stroke-width:0;}#mermaid-svg-PY0cYGWO0m0pK11K .icon-shape,#mermaid-svg-PY0cYGWO0m0pK11K .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-PY0cYGWO0m0pK11K .icon-shape p,#mermaid-svg-PY0cYGWO0m0pK11K .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-PY0cYGWO0m0pK11K .icon-shape .label rect,#mermaid-svg-PY0cYGWO0m0pK11K .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-PY0cYGWO0m0pK11K .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-PY0cYGWO0m0pK11K .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-PY0cYGWO0m0pK11K :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 输出层
生成层
提炼层
转写层
输入层
播客音频文件(MP3/WAV/M4A)
OpenAI Whisper API
自动断句+说话人识别+时间戳
Claude Sonnet API
主题理解+精华提取+结构重组
完整整理稿生成
公众号摘要生成
小红书笔记生成
微博短文生成
LinkedIn英文文章生成
Shorts脚本生成
公众号草稿箱
小红书草稿箱
微博草稿箱
LinkedIn草稿
短视频脚本库
知识库文档
3.2 OpenClaw 核心配置:SOUL.md 模板
markdown
# Soul
你是专业的播客内容矩阵生成AI Agent,名叫「内容矩阵助手」。你的核心目标是将单期播客音频自动化拆解为跨平台内容矩阵,提升内容复用率与分发效率,帮助创作者扩大曝光与商业收入。
## 核心能力
### 1. 音频转写能力
- 调用OpenAI Whisper API,将播客音频转写为带时间戳的文本
- 自动识别说话人(主播/嘉宾),断句清晰,便于后续处理
- 支持中英文混合识别,保证转写准确率
### 2. 内容提炼能力
- 调用Claude Sonnet API,理解播客核心主题、论点、案例、金句
- 区分核心信息与冗余内容,提炼精华,保留口语化风格
- 按不同平台的内容规范,重组内容结构,适配平台用户偏好
### 3. 多平台内容生成能力
- **完整整理稿**:5000字,带时间戳,保留完整对话逻辑
- **公众号精华摘要**:800字,结构清晰,适合长阅读,突出核心观点
- **小红书笔记**:10条×200字,每条突出1个金句/案例,配配图提示(场景化、视觉化)
- **微博短文**:5条×140字,简洁有力,适合快速传播,带话题标签
- **LinkedIn英文文章**:1500字,专业严谨,面向职场/海外用户
- **Shorts脚本**:3条×30秒,提取最具传播力的金句片段,标注画面/字幕提示
### 4. 草稿同步能力
- 自动将生成的内容存入对应平台草稿箱(公众号/小红书/微博/LinkedIn)
- 生成内容时保留平台专属格式(如公众号小标题、小红书表情、微博话题)
- 等待人工审核后发布,保证内容质量与品牌一致性
## 触发规则
- 当上传播客音频文件时,自动触发「转写→提炼→生成→同步」全流程
- 手动指令「重新生成」时,可针对某类内容重新生成
- 手动指令「同步草稿」时,将已生成内容同步至对应平台
## 内容生成规范
### 完整整理稿规范
- 格式:`[时间戳] 说话人:内容`
- 字数:约5000字(根据播客时长调整)
- 保留完整对话逻辑,便于用户查阅
### 公众号摘要规范
- 结构:开头引入→核心论点→案例支撑→总结行动建议
- 字数:800字左右
- 风格:专业、清晰,适合长阅读,带小标题
### 小红书笔记规范
- 每条200字左右,突出1个核心金句/案例
- 开头用表情/钩子吸引眼球,结尾带话题标签(如#AI #播客 #内容创业)
- 配图提示:场景化、视觉化,如「金句文字+播客封面图」
### 微博短文规范
- 每条140字以内,简洁有力,突出核心观点
- 带相关话题标签(如#AI自动化 #内容矩阵)
- 适合快速传播,引发讨论
### LinkedIn英文文章规范
- 字数:1500字左右
- 风格:专业、严谨,面向职场/海外用户
- 结构:Abstract → Key Insights → Case Study → Conclusion
### Shorts脚本规范
- 每条30秒左右,提取最具传播力的金句片段
- 标注:音频台词、画面提示、字幕内容
- 适合抖音/YouTube Shorts竖屏短视频
## 环境变量
- OPENAI_API_KEY: OpenAI API密钥
- CLAUDE_API_KEY: Anthropic Claude API密钥
- WECHAT_OFFICIAL_ACCOUNT_TOKEN: 公众号草稿箱同步令牌
- XIAOHONGSHU_API_KEY: 小红书草稿箱同步令牌
- WEIBO_API_KEY: 微博API密钥
- LINKEDIN_API_KEY: LinkedIn API密钥3.3 openclaw.json:调度与成本配置
json
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-3-5-sonnet-20241022",
"fallbacks": ["openai/gpt-4o"],
"temperature": 0.2,
"maxTokens": 16384
},
"budget": {
"maxCostPerDay": 10.00,
"maxCostPerMonth": 300.00,
"alertThreshold": 0.8
},
"resources": {
"maxMemory": "8GB",
"maxCPU": "4 cores",
"timeout": 300s
},
"logging": {
"level": "info",
"file": "logs/podcast-content-matrix-{date}.log",
"enableTelemetry": false
}
},
"transcriber": {
"inherit": "defaults",
"model": {
"primary": "openai/whisper-1",
"temperature": 0.0,
"maxTokens": 8192
},
"budget": {
"maxCostPerDay": 5.00
}
},
"content_extractor": {
"inherit": "defaults",
"model": {
"temperature": 0.1,
"maxTokens": 8192
},
"budget": {
"maxCostPerDay": 3.00
}
},
"matrix_generator": {
"inherit": "defaults",
"model": {
"temperature": 0.3,
"maxTokens": 16384
},
"budget": {
"maxCostPerDay": 2.00
}
}
},
"schedules": [
{
"task": "transcribe_audio",
"interval": "manual",
"agent": "transcriber"
},
{
"task": "extract_content",
"interval": "manual",
"agent": "content_extractor"
},
{
"task": "generate_content_matrix",
"interval": "manual",
"agent": "matrix_generator"
}
],
"apiKeys": {
"openai": "${OPENAI_API_KEY}",
"claude": "${CLAUDE_API_KEY}",
"wechat": "${WECHAT_OFFICIAL_ACCOUNT_TOKEN}",
"xiaohongshu": "${XIAOHONGSHU_API_KEY}",
"weibo": "${WEIBO_API_KEY}",
"linkedin": "${LINKEDIN_API_KEY}"
}
}配置核心要点:
- 模型选择:Whisper负责转写,Claude Sonnet负责内容提炼与生成,保证质量与效率
- 任务拆分:转写、提炼、生成拆分为独立Agent,便于调试与扩展
- 成本控制:每日预算10,月预算300,控制AI调用成本
- 手动触发:所有任务手动触发,便于创作者掌控流程与内容质量
四、核心代码实现:从音频到内容矩阵全流程
4.1 环境准备与依赖安装
bash
# 创建虚拟环境
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# 安装核心依赖
pip install python-dotenv openai anthropic requests pandas openpyxl4.2 音频转写模块(OpenAI Whisper)
python
# transcriber.py
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def transcribe_podcast(audio_path):
"""转写播客音频为带时间戳+说话人的文本"""
with open(audio_path, "rb") as f:
transcript = client.audio.transcriptions.create(
file=f,
model="whisper-1",
response_format="verbose_json",
timestamp_granularities=["segment"],
language="zh"
)
# 格式化输出:[时间戳] 说话人:内容
formatted = []
for seg in transcript.segments:
start = f"{int(seg.start//3600):02d}:{int(seg.start%3600//60):02d}:{int(seg.start%60):02d}"
# 简化说话人识别(可根据实际需求优化)
speaker = "主播" if seg.id % 2 == 0 else "嘉宾"
formatted.append(f"[{start}] {speaker}:{seg.text}")
return "\n".join(formatted)
if __name__ == "__main__":
transcript = transcribe_podcast("podcast.mp3")
with open("transcript.txt", "w", encoding="utf-8") as f:
f.write(transcript)
print("✅ 转写完成,已保存到transcript.txt")4.3 内容提炼与矩阵生成模块(Claude Sonnet)
python
# content_generator.py
import os
import json
from dotenv import load_dotenv
from anthropic import Anthropic
load_dotenv()
client = Anthropic(api_key=os.getenv("CLAUDE_API_KEY"))
def load_transcript():
"""加载转写文本"""
with open("transcript.txt", "r", encoding="utf-8") as f:
return f.read()
def generate_content_matrix(transcript):
"""生成多平台内容矩阵"""
prompt = f"""
请根据以下播客转写文本,生成完整内容矩阵:
1. 完整整理稿(5000字,带时间戳)
2. 公众号精华摘要(800字,结构清晰)
3. 小红书笔记×10(200字/条+配图提示)
4. 微博短文×5(140字/条+话题)
5. LinkedIn英文文章(1500字)
6. Shorts脚本×3(30秒金句片段+画面提示)
播客转写:
{transcript}
输出JSON格式,每个内容类型为一个key:
{{
"full_script": "...",
"wechat_article": "...",
"xiaohongshu_notes": ["...", ...],
"weibo_posts": ["...", ...],
"linkedin_article": "...",
"shorts_scripts": ["...", ...]
}}
"""
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=16384,
messages=[{"role": "user", "content": prompt}]
)
return json.loads(response.content[0].text)
if __name__ == "__main__":
transcript = load_transcript()
matrix = generate_content_matrix(transcript)
with open("content_matrix.json", "w", encoding="utf-8") as f:
json.dump(matrix, f, ensure_ascii=False, indent=2)
print("✅ 内容矩阵生成完成,已保存到content_matrix.json")4.4 草稿箱同步模块
python
# draft_syncer.py
import os
import json
import requests
from dotenv import load_dotenv
load_dotenv()
def sync_to_wechat(article):
"""同步到公众号草稿箱"""
url = "https://api.weixin.qq.com/cgi-bin/draft/add"
params = {"access_token": os.getenv("WECHAT_OFFICIAL_ACCOUNT_TOKEN")}
data = {
"articles": [{
"title": "播客精华摘要",
"content": article,
"thumb_media_id": "..."
}]
}
requests.post(url, params=params, json=data)
print("📝 已同步到公众号草稿箱")
def sync_to_xiaohongshu(notes):
"""同步到小红书草稿箱"""
url = "https://api.xiaohongshu.com/api/sns/v2/note/draft"
headers = {"Authorization": f"Bearer {os.getenv('XIAOHONGSHU_API_KEY')}"}
for note in notes:
data = {"content": note, "type": "normal"}
requests.post(url, headers=headers, json=data)
print("📝 已同步到小红书草稿箱")
def sync_all(matrix):
"""同步所有内容到对应平台草稿箱"""
sync_to_wechat(matrix["wechat_article"])
sync_to_xiaohongshu(matrix["xiaohongshu_notes"])
print("✅ 所有内容同步完成")
if __name__ == "__main__":
with open("content_matrix.json", "r", encoding="utf-8") as f:
matrix = json.load(f)
sync_all(matrix)五、收益与效率分析:从¥8k到¥35k的增长密码
5.1 效率提升对比
| 环节 | 传统人工 | AI自动化 | 效率提升 |
|---|---|---|---|
| 音频转写 | 2小时/小时音频 | 5分钟/小时音频 | -96% |
| 内容改写 | 6小时/期 | 30分钟/期 | -92% |
| 多平台适配 | 4小时/期 | 10分钟/期 | -96% |
| 总耗时 | 12小时/期 | 45分钟/期 | -94% |
| 内容产量 | 1期/周 | 5套/周 | +400% |
5.2 收入增长拆解
- 曝光量提升:多平台分发,总曝光量从10万/月 → 50万/月
- 广告收入:从¥8,000/月 → ¥35,000/月,增长337.5%
- 商业拓展:更多曝光带来品牌合作、付费社群等额外收入
- 长期价值:内容矩阵沉淀为知识库,提升个人品牌与专业影响力
5.3 成本与ROI分析
| 成本项 | 金额 | 说明 |
|---|---|---|
| AI模型成本 | ~¥200/月 | Whisper + Claude 调用费用 |
| 服务器成本 | ~¥100/月 | 云服务器运行脚本 |
| API同步成本 | ~¥50/月 | 多平台草稿箱同步 |
| 月总成本 | ~¥350/月 | 总计:¥200+¥100+¥50 |
| 月收入增长 | ¥27,000 | 从¥8k到¥35k的增量 |
| 月ROI | 7614% | (27000-350)/350 ≈ 76.14 |
核心结论:极低的运营成本,极高的投资回报率,AI内容矩阵是内容创作者的「收入放大器」。
六、风险控制与长期优化
6.1 核心风险与规避
- 内容质量风险
- 风险:AI生成内容可能存在逻辑偏差、风格不一致
- 规避:保留人工审核环节,建立内容质量标准,持续优化Prompt
- 平台合规风险
- 风险:多平台内容可能违反平台规范,导致限流/封号
- 规避:生成内容时遵循各平台规则,避免敏感内容,保留人工调整空间
- 依赖风险
- 风险:过度依赖OpenAI/Claude API,服务中断
- 规避:多模型 fallback,本地备份转写文本,定期导出内容矩阵
- 版权风险
- 风险:播客内容可能涉及版权问题
- 规避:仅处理自有版权或授权的播客内容,避免侵权
6.2 长期优化方向
- 模型迭代:基于历史内容数据,优化Prompt,提升内容质量与平台适配性
- 功能拓展 :
- 自动生成封面图/配图(对接AI绘图工具)
- 自动添加话题标签、关键词
- 支持更多平台(如抖音、B站、知乎)
- 产品化 :
- 开发SaaS网页端,支持创作者自助上传音频、管理内容矩阵
- 推出API服务,供其他内容工具集成
- 建立按内容量/平台数计费的商业模式
- 品牌建设 :
- 分享内容创业案例,打造个人品牌
- 与其他创作者合作,互相推广,扩大影响力
七、总结与行动建议
7.1 核心总结
本文拆解了一个内容产量5倍、广告收入翻4倍的播客转内容矩阵案例,核心结论是:
- 复用是核心:将高信息密度的播客内容拆解为多平台适配的内容矩阵,最大化内容价值
- 效率是关键:AI自动化将生产时间压缩94%,实现高频更新与多平台分发
- 分发是收入:多平台曝光带来广告收入暴涨,突破单一平台天花板
- 可复制是优势:标准化流程可快速复制到任何播客/音频内容创作者
7.2 行动建议
如果你是播客/音频内容创作者,建议按以下步骤行动:
- 最小可行产品:先实现「音频转写→公众号摘要+小红书笔记」核心功能,验证效率提升
- 小范围测试:选择1期播客,生成内容矩阵并发布,收集数据与反馈
- 逐步扩展:逐步添加微博、LinkedIn、Shorts等平台内容
- 产品化:开发简单的管理界面,实现自助上传与管理
- 商业化:尝试为其他创作者提供服务,拓展收入来源
7.3 最后提醒
AI是「效率放大器」,不是「替代者」。内容的核心永远是创作者的观点、洞察与人格魅力,AI只是帮你把更多时间留给内容创作本身,而不是消耗在重复的改写与分发上。
八、附录:资源与参考
8.1 开源资源
- OpenAI Whisper文档:https://platform.openai.com/docs/guides/speech-to-text
- Anthropic Claude文档:https://docs.anthropic.com/claude/
- 微信公众号API文档:https://developers.weixin.qq.com/doc/offiaccount/Getting_Started/Overview.html
- 小红书开放平台文档:https://open.xiaohongshu.com/
8.2 参考资料
- 内容创业者社区案例原文:https://example.com/podcast-content-matrix
- 《内容创业:从0到1打造个人品牌》
- 《AI驱动的内容生产与分发》