π0.5 论文翻译与学习笔记
论文标题 : π0.5: A Vision-Language-Action Model with Open-World Generalization
核心主题: 开放世界泛化 --- 让机器人在从未见过的全新家庭环境中执行长程灵巧操控任务
一、核心摘要

为了让机器人真正具备实用价值,它们必须能够在实验室之外的真实世界中执行具有实际意义的任务。尽管视觉-语言-动作(VLA)模型在端到端机器人控制方面已经取得了令人瞩目的成果,但在野外(复杂现实)环境中,此类模型的泛化能力究竟能达到何种程度,仍然是一个悬而未决的问题。
在本文中,我们介绍了 π0.5\pi_{0.5}π0.5 ------ 一款基于 π0\pi_0π0 打造的新型模型,它通过在异构任务上进行联合训练(co-training)来实现广泛的泛化能力。π0.5\pi_{0.5}π0.5 融合了来自多种机器人平台的数据、高层语义预测、网络数据以及其他多源信息,从而实现了具备广泛泛化性的现实世界机器人操控。我们的系统结合使用了联合训练与混合多模态样本,这些样本将图像观测、语言指令、物体检测、语义子任务预测以及底层动作紧密结合在一起。
实验结果表明,这种知识迁移对于实现有效的泛化至关重要。同时,我们首次证明了基于端到端学习的机器人系统,能够在完全陌生的全新家庭环境中,执行诸如打扫厨房或卧室等长程且灵巧的操控技能。

图 2:π0.5 清洁新厨房。机器人被赋予清洁一个未包含在训练数据集中的家庭厨房的任务。模型被赋予通用任务(关上橱柜、将物品放入抽屉、擦拭溢出的液体、将碗碟放入水槽),它通过预测要完成的子任务(例如,拿起盘子)并发出底层动作来完成这些任务。
开放世界泛化是物理智能领域最大的未解难题之一:诸如机械臂、人形机器人和自动驾驶车辆等具身系统,只有当它们能够走出实验室,应对现实世界中出现的各种情况和突发事件时,才能真正发挥作用。基于学习的系统为实现广泛的泛化提供了一条途径,尤其是在近年来,从自然语言处理到计算机视觉等领域,可扩展的学习系统取得了显著进展。然而,机器人在现实世界中可能遇到的各种情况,需要的不仅仅是规模:我们需要设计训练方案,使其能够获得足够广博的知识,从而在多个抽象层次上进行泛化。
例如,如果让移动机器人清理一个它从未见过的厨房,有些行为如果能在足够多的场景和物体数据中得到充分体现,就能很容易地泛化(例如,拿起刀或盘子);有些行为可能需要调整或修改现有技能,才能以新的方式或新的顺序使用;还有一些行为可能需要基于先验知识理解场景的语义(例如,打开哪个抽屉,或者台面上哪个物体最可能是晾衣架)。我们如何为机器人学习系统构建一个训练方案,使其能够实现这种灵活的泛化能力呢?
人们可以凭借毕生经验,综合运用各种方法,为应对这些挑战找到合适的解决方案。这些经验并非全部来自亲身经历,也并非全部来自机械练习------例如,我们可能会结合他人告知或书籍中的知识,以及在不同情境下完成其他任务所获得的洞见,并结合目标领域的直接经验。类似地,我们可以假设,通用的机器人学习系统必须能够从各种信息源迁移经验和知识。其中一些信息源是与当前任务直接相关的第一手经验,一些需要从其他机器人形态、环境或领域迁移,另一些则代表完全不同的数据类型,例如口头指令、基于网络数据的感知任务或对高级语义指令的预测。这些不同数据源的异质性构成了一个主要障碍,但幸运的是,视觉-语言-动作(VLA)模型的最新进展为我们提供了一个工具包,使之成为可能:通过将不同的模态纳入同一序列建模框架,VLA 可以进行调整,以在机器人数据、语言数据、计算机视觉任务以及上述数据的组合上进行训练。
本文利用这一观察结果,设计了一个用于 VLA 的协同训练框架,该框架能够利用异构且多样化的知识源,从而实现广泛的泛化能力。在 π0\pi_0π0 VLA 的基础上,我们提出纳入一系列不同的数据源,以创建 π0.5\pi_{0.5}π0.5 模型("pi oh five"),该模型能够控制移动机械臂执行各种家务任务,即使在训练期间从未见过的家庭环境中也能胜任。π0.5\pi_{0.5}π0.5 借鉴了多方面的经验:
- 除了在各种真实家庭环境中直接使用移动机械臂收集的中等规模数据集(约 400 小时)外
- π0.5\pi_{0.5}π0.5 还使用了来自其他非移动机器人的数据
- 在实验室条件下收集的相关任务数据
- 需要基于机器人观察预测"高级"语义任务的训练示例
- 人类监督员向机器人提供的口头指令
- 从网络数据创建的各种多模态示例,例如图像描述、问答和物体定位
提供给 π0.5\pi_{0.5}π0.5 的绝大多数训练样本(第一阶段训练的 97.6%)并非来自执行家务的移动机械臂,而是来自其他来源,例如其他机器人或网络数据。尽管如此,π0.5\pi_{0.5}π0.5 仍能在训练期间未曾见过的全新住宅中控制移动机械臂,执行诸如悬挂毛巾或铺床等复杂任务,并能执行长达 10 至 15 分钟的远距离操作,仅凭一个概括性的指令即可清洁整个厨房或卧室。
π0.5\pi_{0.5}π0.5 的设计遵循一个简单的层级架构:我们首先在异构混合训练任务上预训练模型,然后针对移动操作进行专门的微调,同时使用低级动作示例和高级"语义"动作,这些高级动作对应于预测诸如"拿起砧板"或"重新摆放枕头"之类的子任务标签。在运行时,推理的每个步骤中,模型首先预测语义子任务,根据任务结构和场景语义推断下一步应该执行的行为,然后基于该子任务预测低级机器人动作块。
这种简单的架构既能够推理长周期多阶段任务,又能利用不同的知识来源来处理两个层级:底层动作推理过程可以很容易地从其他机器人(包括其他环境中的简单静态机器人)收集的动作数据中获益;而高层推理过程则可以从网络上的语义示例、高层标注预测,甚至人类"监督员"向机器人提供的口头指令中获益。这些监督员会引导机器人逐步完成复杂的任务,并像指导人一样,指示机器人执行哪些子任务来完成诸如清洁房间之类的复杂任务。
我们的核心贡献在于开发了一个用于训练高泛化能力 VLA π0.5\pi_{0.5}π0.5 的系统,并验证了当该模型在适当多样化的数据上训练时,其泛化能力得以实现。我们对 π0.5\pi_{0.5}π0.5 的泛化能力以及不同协同训练要素的相关性进行了详细的实证评估。据我们所知,我们的工作首次展示了一个端到端的学习型机器人系统,该系统能够在全新的住宅中执行长时程且灵巧的操作,例如清洁厨房或卧室。我们的实验和对比进一步表明,该系统能够实现这一目标,得益于从其他机器人迁移知识、进行高级语义预测、提供人类监督员的口头指令、收集网络数据以及其他来源的信息。
二、相关工作
通用机器人操作策略。 近期研究表明,将机器人操作策略的训练数据分布从狭窄的单任务数据集扩展到涵盖多种场景和任务的多样化数据集,不仅能够使生成的策略开箱即用地解决更广泛的任务,还能提高其对新场景和任务的泛化能力。训练这种通用策略需要新的建模方法,以处理通常涵盖数百个不同任务和场景的数据集的规模和多样性。
视觉语言动作模型(VLA)提供了一种极具吸引力的解决方案:通过微调用于机器人控制的预训练视觉语言模型,VLA 可以利用从网络规模预训练中获取的语义知识,并将其应用于机器人问题。当与诸如流匹配、扩散或高级动作标记化方案等高表达力的动作解码机制相结合时,VLA 可以在现实世界中执行各种复杂的操控任务。
然而,尽管 VLA 展现出令人印象深刻的语言跟随能力,但其评估环境通常仍与其训练数据高度匹配。一些研究表明,诸如拾取物体或打开抽屉之类的简单技能可以通过在更广泛的环境中收集机器人数据来泛化,但将相同的方法应用于更复杂、更长期的任务(例如清洁厨房)则极具挑战性,因为通过蛮力扩展机器人数据收集来覆盖所有可能的场景是不可行的。
在我们的实验中,我们在全新的场景(例如训练中未出现过的全新厨房和卧室)中评估了 π0.5\pi_{0.5}π0.5,结果表明,我们的 VLA 不仅能够利用目标移动机械臂平台上的直接第一手经验,还能利用来自其他数据源的信息,从而泛化到全新的场景。这些数据源包括来自其他(非移动)机器人的数据、高级语义子任务预测以及来自网络的数据。
非机器人数据协同训练。 许多先前的研究工作都试图利用各种非机器人数据来提高机器人策略的泛化能力。以往的方法探索了从计算机视觉数据集初始化视觉编码器,或利用现成的任务规划器。VLA 策略通常从预训练的视觉-语言模型初始化,该模型已接触过大量的互联网视觉和语言数据。
值得注意的是,VLA 架构具有灵活性,允许在多模态的视觉、语言和动作标记的输入和输出序列之间进行映射。因此,VLA 通过支持在单一统一架构上进行协同训练,不仅支持在机器人动作模仿数据上进行训练,还支持在任何交错包含上述一种或多种模态的数据集上进行训练,从而扩展了可能的迁移方法的设计空间,使其不再局限于简单的权重初始化。
先前的研究表明,将用于 VLA 训练的数据混合用于 VLM 训练,可以提高其泛化能力,例如在与新物体或未见过的场景背景交互时。本文超越了 VLM 数据的协同训练,设计了一个系统,用于将 VLA 与更广泛的机器人相关监督数据源协同训练,这些数据源包括来自其他机器人的数据、高级语义子任务预测以及语言指令。
虽然多任务训练和协同训练并非新概念,但我们证明,我们系统中特定的数据源组合能够使移动机器人在全新的环境中执行复杂且持续时间长的行为。我们相信,这种泛化能力,尤其是在考虑到任务复杂性的情况下,显著超越了以往研究的成果。
机器人运用语言进行推理和规划。 先前的多项研究表明,利用高层推理增强端到端策略可以显著提升长时程任务的性能,尤其是在高层子任务推理能够受益于大型预训练的 LLM 和 VLM 时。我们的方法也采用了两阶段推理过程,首先推理一个高层语义子任务(例如,"拿起盘子"),然后基于该子任务预测动作。
先前的许多方法为此采用了两个独立的模型,其中一个 VLM 预测语义步骤,另一个独立的底层策略执行这些步骤。我们的方法对高层推理和底层推理都使用完全相同的模型,其方法更接近于思维链或测试时计算方法,但与具身思维链方法不同的是,高层推理过程的运行频率仍然低于底层动作推理。
具有开放世界泛化的机器人学习系统。 虽然大多数机器人学习系统都在与训练数据高度匹配的环境中进行评估,但一些先前的研究已经探索了更广泛的开放世界泛化能力。当机器人的任务被限制在一组更窄的基本原语中,例如拾取物体时,允许特定任务假设的方法(例如,抓取预测或结合基于模型的规划和控制)已被证明具有广泛的泛化能力,甚至可以扩展到全新的环境。然而,这些方法并不容易泛化到通用机器人可能需要执行的所有任务。
最近,跨多个领域收集的大规模数据集已被证明能够将简单但端到端学习的任务泛化到新的环境中。然而,这些演示中的任务仍然相对简单,通常持续时间不到一分钟,且成功率往往较低。我们证明 π0.5\pi_{0.5}π0.5 可以执行耗时较长的多阶段任务,例如将所有碗碟放入水槽或从新卧室的地板上捡起所有衣物,并且能够泛化到全新的房屋环境中。
三、预备工作
视觉-语言-动作模型(VLA)通常通过模仿学习在各种机器人演示数据集 D\mathcal{D}D 上进行训练,其目标是最大化给定观测数据 ot\mathbf{o}_tot 和自然语言任务指令 ℓ\ellℓ 时动作 at\mathbf{a}tat(或更一般地,动作块 at:t+H\mathbf{a}{t:t+H}at:t+H)的对数似然值:
maxθE(at:t+H,ot,ℓ)∼Dlog(πθ(at:t+H∣ot,ℓ))\max_\theta \mathbb{E}{(\mathbf{a}{t:t+H},\mathbf{o}t,\ell)\sim\mathcal{D}} \log(\pi\theta(\mathbf{a}_{t:t+H}|\mathbf{o}_t,\ell))θmaxE(at:t+H,ot,ℓ)∼Dlog(πθ(at:t+H∣ot,ℓ))
观测数据通常包含一张或多张图像 It1,...,Itn\mathbf{I}_t^1,\ldots,\mathbf{I}_t^nIt1,...,Itn 以及本体感觉状态 qt\mathbf{q}_tqt,后者用于捕捉机器人关节的位置。VLA 架构遵循现代语言和视觉-语言模型的设计,包含特定模态的标记器,用于将输入和输出映射到离散的("硬")或连续的("软")标记表示,以及一个大型的自回归 Transformer 骨干网络,用于将输入标记映射到输出标记。
这些模型的权重由预训练的视觉-语言模型初始化。通过将策略输入和输出编码为分词表示,上述模仿学习问题可以转化为一个简单的下一词预测问题,该问题基于一系列观察、指令和动作词元,并且我们可以利用现代机器学习的可扩展工具对其进行优化。
在实践中,图像和文本输入的分词器选择遵循现代视觉语言模型的做法。对于动作,先前的工作已经开发出有效的、基于压缩的分词方法,我们在预训练阶段使用了这些方法。一些最新的视觉语言模型也提出通过扩散或流匹配来表示动作分布,从而为连续值动作块提供更具表现力的表示。
在模型的后训练阶段,我们将基于 π0\pi_0π0 模型的设计,该模型通过流匹配来表示动作分布。在该设计中,与动作对应的词元接收来自前一步骤流匹配的部分去噪动作作为输入,并输出流匹配向量场。这些词元还使用一组不同的模型权重,我们称之为"动作专家",类似于混合专家架构。该动作专家可以专门用于基于流匹配的动作生成,并且可以比 LLM 主干网络的其余部分小得多。
【学习笔记】1. 什么是"类似于混合专家架构(MoE)"?
在目前主流的大模型(如 DeepSeek、GPT-4)中,有一种很火的架构叫 MoE(Mixture of Experts,混合专家)。它的核心思想是:模型里有很多个"小专家"(通常是一堆不同的前馈网络权重),当模型处理数学题时,就激活"数学专家"那部分的权重;写作文时,就激活"语文专家"。
π0.5\pi_{0.5}π0.5 借用了这个思想。右边那个 300M 的"动作专家",它不是一个独立的模型文件,而是大模型内部的一组"特殊权重"。
- 模型在"说话/拆解任务"时,用的是大模型通用的权重。
- 一旦模型发现现在要"控制机械臂"了,这组专门的"动作专家权重"就会被激活。
2. 动词是怎么变成动作的?("与动作对应的词元接收...作为输入")
在传统的语言模型里,文字是串行输入的。比如输入:"我想吃",模型预测下一个词(Token)是"苹果"。而在 π0.5\pi_{0.5}π0.5 里面,它创造了一种特殊的词元,叫 Action Tokens(动作词元)。
大模型在输出完
"pick up the pillow"(拿起枕头)之后,后面会紧跟几个空的"动作词元"。此时,底层控制算法 Flow Matching(流匹配) 登场了。流匹配和生成 AI 绘画的 Diffusion(扩散模型)很像,它的动作不是一蹴而就的,而是通过很多步"去噪(Denoising)"慢慢试探出来的:
- 动作专家先瞎猜一个带有很多噪声的模糊动作。
- "接收来自前一步骤...的部分去噪动作作为输入":动作专家看一眼自己上一步猜出来的半成品动作。
- "并输出流匹配向量场":动作专家根据这个半成品,结合眼前的图像,计算出一个"修正方向"(这就是向量场),告诉机械臂:"你应该往左偏一点,往上抬一点"。
- 经过几次这样的循环修正,原本是一团随机噪声的信号,就被精准地"洗"成了丝滑的连续机械臂动作。
3. 为什么"可以比 LLM 主干网络小得多"?
大语言模型(LLM)的主干网络之所以要做到几个 B(几十亿参数)甚至更大,是因为它要背诵全网的知识,理解复杂的语言逻辑。但是,机械臂的物理控制(把手往前伸 5 厘米、抓紧、抬起),需要的并不是"博古通今的知识",而是"精细的物理几何直觉"。
因此,论文的设计非常聪明:
- 复杂的视觉理解、家务常识、任务拆解,全部由 2.6B 的 Gemma 大脑搞定。
- 只有在最末端、最需要精细控手的那一步,才交给这个 300M 的轻量级"动作专家权重"去用流匹配算法疯狂计算动作。
四、模型和训练方案
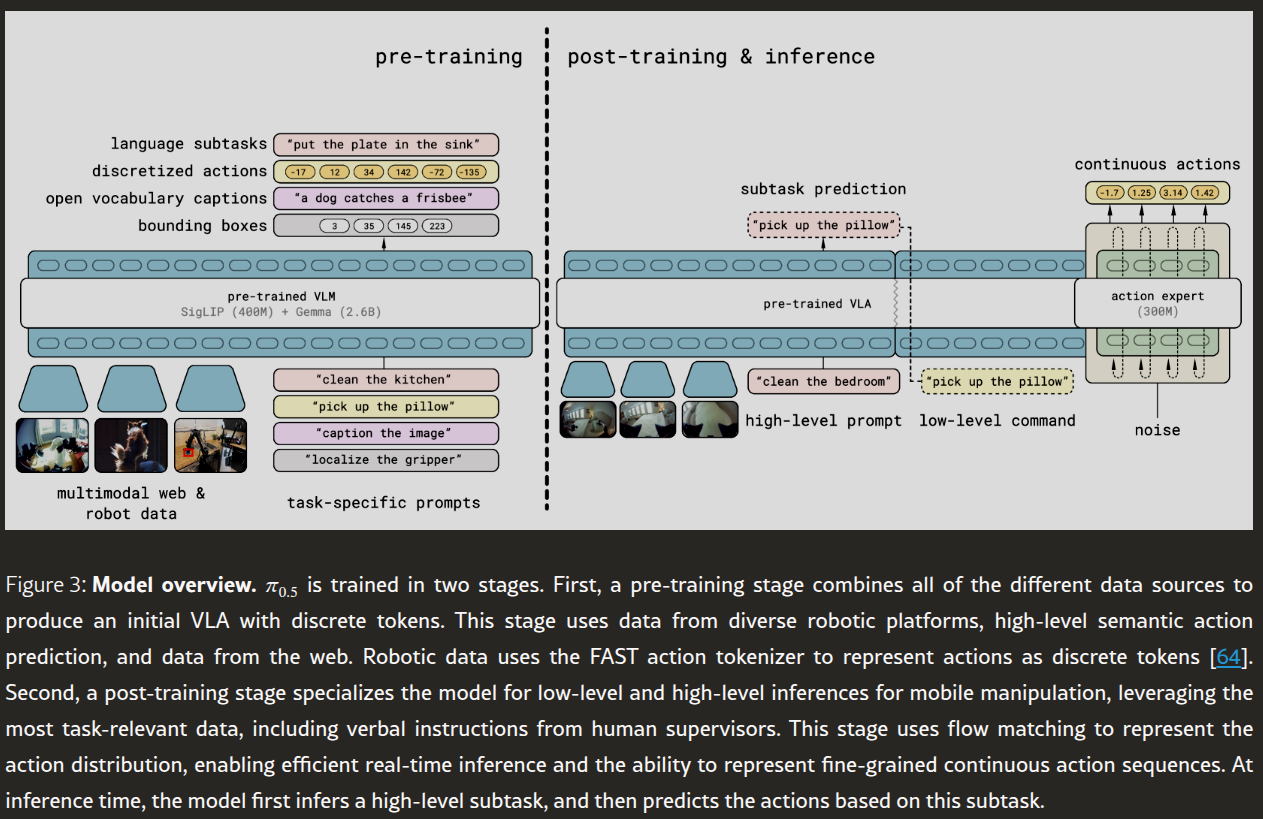
图 3:模型概述。π0.5\pi_{0.5}π0.5 的训练分为两个阶段。首先,预训练阶段整合所有不同的数据源,生成一个初始的离散标记 VLA。该阶段使用来自不同机器人平台的数据、高级语义动作预测以及网络数据。机器人数据使用 FAST 动作标记器将动作表示为离散标记。其次,后训练阶段针对移动操作的低级和高级推理对模型进行专门化,利用与任务最相关的数据,包括来自人类主管的口头指令。该阶段使用流匹配来表示动作分布,从而实现高效的实时推理并能够表示细粒度的连续动作序列。在推理阶段,模型首先推理一个高级子任务,然后基于该子任务预测动作。
【学习笔记】1. 喂的"材料"是什么?(输入端的多样性)传统的机器人模型只吃"机器人操作数据"。但 π0.5\pi_{0.5}π0.5 为了获得像 GPT 那样的泛化能力,在左边疯狂塞入了三种完全不同的"语料材料":
- 纯互联网图文(Web Data): 比如一张狗接飞盘的图。这部分数据完全没有机器人动作,纯粹是为了让大模型建立对物理世界的常识认知(知道什么是盘子,什么是厨房,什么是卧室)。
- 其他机器人的历史数据(Cross-Embodiment Data): 比如别的实验室里,单臂固定机器人在桌子上捡垃圾的数据。这些机器人的形态和自家的双臂移动机器人完全不一样。
- 任务提示词(Task-specific Prompts): 也就是各种各样的"指令文本",比如
"clean the kitchen"、"pick up the pillow"。模型把这些图像和文本通过特殊的 Tokenizer 全部打碎,像大模型拼接网页文本一样,强行缝合在同一个输入序列里。
2. 怎么"像大模型一样"训练?(输出端的离散化)
传统的机器人控制输出的是连续的电压或关节角度数字(如
0.5234弧度)。但大模型不认识连续的浮点数,它只认识"词表里的 Token"。所以,左边预训练的核心科技是:把一切输出都强行"文本化(Tokenize)"。
- 如果输入的材料是互联网图片: 训练目标就是像大模型看图说话(Image Captioning)一样,自回归预测下一个词:
"a","dog","catches"...- 如果输入的材料是物体定位: 训练目标就是输出边界框的数字 Token。
- 如果是机器人操作数据: 论文里提到他们用了一个叫 FAST action tokenizer 的工具。这个工具把机械臂连续的关节动作(比如旋转 15.5 度),像大模型编码文字一样,编码成词表里对应的一个整数 Token(比如
ID: 142)。
【学习笔记】推理流程三步走第一步:接收宏观任务与视觉输入(最下方)
- 输入: 机器人站在卧室里,相机拍下当前床铺杂乱的画面。
- 人类指令: 语音或文本输入宏观任务
"clean the bedroom"(打扫卧室)。第二步:大脑生成语义子任务(Subtask Prediction)
- 数据流进入中间的
[pre-trained VLA]。由于这个大模型在左边预训练时背过海量的"家务常识",它看了一眼乱七八糟的床和"打扫卧室"的命令,立刻做出了高层推理。- 输出: 预测吐出了一个低层文本指令(Low-level command):
"pick up the pillow"(捡起枕头)。- 这个吐出来的词,连同大模型大脑此时此刻沉淀下来的所有视觉、上下文特征(Hidden States),像流水线一样直接平移灌入到了最右边的绿色方块里。
第三步:动作专家与流匹配"洗"出丝滑轨迹(最右侧)
- 数据流来到了最硬核的绿色大方块 ------ Action Expert(动作专家)。
- 吃进条件(Condition): 动作专家接过了左边传过来的超级融合向量(包含图像、宏观任务"打扫"、自己刚说的"捡枕头")。
- 引入噪声(Noise): 算法在动作坑位里初始化了纯随机噪声。
- 流匹配迭代: 动作专家在绿色方块内部,利用流匹配算法对这噪声坑位进行了几轮极其快速的去噪修正。
- 喷涌动作(Continuous Actions): 仅仅经过 3、4 步内部计算,噪声被彻底洗掉。最上方吐出了高精度的连续物理浮点数 (例如:
[-1.7, 1.25, 3.14, 1.42])。隐藏细节:数据是怎么灌进去的?
在训练(Post-training)时:人类教练在带机器人做家务时,会一边操作一边用麦克风说话录音("我现在要把枕头捡起来")。PI 团队把人类说的这些口头指令(Verbal Instructions)也做成了标签。训练时,高层提示、人类口头命令、以及最终的丝滑动作是同时喂给模型吃的,强迫模型把"人类的口头意图"和"动作专家的肌肉记忆"焊死在一起。
在推理(Inference)时:人类不说话了,只给一个总目标
"clean the bedroom"。模型自己当自己的导师,自发地在中间预测出"pick up the pillow"。因为训练时这两者是焊死的,所以它自己吐出这句话后,右边的动作专家就能完美无缝地执行对应的动作。
五、模型架构
π0.5\pi_{0.5}π0.5 架构能够灵活地表示动作块分布和分词后的文本输出,后者既可用于协同训练任务(例如问答),也可用于在分层推理过程中输出高层子任务预测。模型捕获的分布可以表示为 πθ(at:t+H,ℓ^∣ot,ℓ)\pi_\theta(\mathbf{a}_{t:t+H},\hat{\ell}|\mathbf{o}_t,\ell)πθ(at:t+H,ℓ^∣ot,ℓ),其中 ot=It1,...,Itn,qt\mathbf{o}t = \\mathbf{I}_t\^1,\\ldots,\\mathbf{I}_t\^n,\\mathbf{q}_tot=It1,...,Itn,qt 包含所有摄像头拍摄的图像以及机器人的配置信息(关节角度、夹爪姿态、躯干抬升姿态和基座速度),ℓ\ellℓ 是总体任务提示(例如"收拾碗筷"),ℓ^\hat{\ell}ℓ^ 表示模型的(分词后的)文本输出,它可以是预测的高层子任务(例如"拿起盘子"),也可以是对网络数据中视觉语言提示的回答,at:t+H\mathbf{a}{t:t+H}at:t+H 是预测的动作块。
我们将分布分解为:
πθ(at:t+H,ℓ^∣ot,ℓ)=πθ(ℓ^∣ot,ℓ)⋅πθ(at:t+H∣ot,ℓ^)\pi_\theta(\mathbf{a}{t:t+H},\hat{\ell}|\mathbf{o}t,\ell) = \pi\theta(\hat{\ell}|\mathbf{o}t,\ell) \cdot \pi\theta(\mathbf{a}{t:t+H}|\mathbf{o}_t,\hat{\ell})πθ(at:t+H,ℓ^∣ot,ℓ)=πθ(ℓ^∣ot,ℓ)⋅πθ(at:t+H∣ot,ℓ^)
其中动作分布不依赖于 ℓ\ellℓ,而只依赖于 ℓ^\hat{\ell}ℓ^。因此,高层推理捕捉 πθ(ℓ^∣ot,ℓ)\pi_\theta(\hat{\ell}|\mathbf{o}t,\ell)πθ(ℓ^∣ot,ℓ),低层推理捕捉 πθ(at:t+H∣ot,ℓ^)\pi\theta(\mathbf{a}_{t:t+H}|\mathbf{o}_t,\hat{\ell})πθ(at:t+H∣ot,ℓ^),两种分布都由同一个模型表示。
该模型对应于一个 Transformer,它接收 NNN 个多模态输入标记 x1:Nx_{1:N}x1:N(这里我们对"标记"一词的使用较为宽泛,既指离散输入也指连续输入),并生成一系列多模态输出 y1:Ny_{1:N}y1:N,我们可以将其表示为 y1:N=f(x1:N,A(x1:N),ρ(x1:N))y_{1:N} = f(x_{1:N}, A(x_{1:N}), \rho(x_{1:N}))y1:N=f(x1:N,A(x1:N),ρ(x1:N))。每个 xix_ixi 可以是文本标记(xiw∈Nx_i^w \in \mathbb{N}xiw∈N)、图像块(xiI∈Rp×p×3x_i^I \in \mathbb{R}^{p\times p\times 3}xiI∈Rp×p×3)或流匹配中机器人动作的中间去噪值(xia∈Rdx_i^a \in \mathbb{R}^dxia∈Rd)。观测值 ot\mathbf{o}tot 和 ℓ\ellℓ 构成 x1:Nx{1:N}x1:N 的前缀部分。
根据标记类型(如 ρ(xi)\rho(x_i)ρ(xi) 所示),每个标记不仅可以由不同的编码器处理,还可以由 Transformer 内部不同的专家权重处理。例如,图像块通过视觉编码器进行处理,文本标记则通过嵌入矩阵进行嵌入。参考 π0\pi_0π0,我们将动作标记 xiax_i^axia 线性投影到 Transformer 嵌入空间,并在 Transformer 中使用不同的专家权重来处理这些动作标记。注意力矩阵 A(x1:N)∈0,1N×NA(x_{1:N}) \in 0,1^{N\times N}A(x1:N)∈0,1N×N 指示一个标记是否可以关注另一个标记。与 LLM 中的标准因果注意力相比,图像块、文本提示和连续动作标记使用双向注意力。
由于我们希望模型能够输出文本(用于回答关于场景的问题或输出接下来要完成的任务)和动作(用于在世界中执行操作),因此输出 fff 被拆分为文本标记逻辑值和动作输出标记,分别记为 (y1:Mℓ,y1:Ha)(y_{1:M}^\ell, y_{1:H}^a)(y1:Mℓ,y1:Ha)。前 MMM 对应于可用于采样 ℓ^\hat{\ell}ℓ^ 的文本标记逻辑值,而后面的 HHH 个标记则由一个独立的动作专家生成,如 π0\pi_0π0 所示,并通过线性映射投影到连续输出,用于获得 at:t+H\mathbf{a}_{t:t+H}at:t+H。请注意 M+H≤NM+H \leq NM+H≤N,即并非所有输出都与损失相关联。机器人本体感受状态被离散化,并以文本标记的形式输入到模型中。
5.1 结合离散和连续动作表征
与 π0\pi_0π0 类似,我们在最终模型中使用流匹配来预测连续动作。给定 at:t+Hτ,ω=τat:t+H+(1−τ)ω\mathbf{a}{t:t+H}^{\tau,\omega} = \tau\mathbf{a}{t:t+H} + (1-\tau)\omegaat:t+Hτ,ω=τat:t+H+(1−τ)ω 和 ω∼N(0,I)\omega \sim \mathcal{N}(0, \mathbf{I})ω∼N(0,I),其中 τ∈0,1\tau \in 0,1τ∈0,1 是流匹配时间索引,模型被训练来预测流向量场 ω−at\omega - \mathbf{a}_tω−at。
然而,当动作由离散标记表示时,VLA 训练速度会快得多,尤其是在使用能够有效压缩动作块的标记化方案(例如 FAST)时。遗憾的是,这种离散表示不太适合实时推理,因为它们需要昂贵的自回归解码来进行推理。因此,理想的模型设计应该在离散化动作上进行训练,但仍然允许使用流匹配在推理时生成连续动作。
因此,我们的模型通过对词元进行自回归采样(使用 FAST 分词器)以及对流场进行迭代积分来预测动作,从而结合了两者的优势。我们使用注意力矩阵来确保不同的动作表示之间互不干扰。我们的模型经过优化,旨在最小化组合损失:
L=H(x1:M,y1:Mℓ)+α⋅Lflow(at:t+H,y1:Ha)\mathcal{L} = H(x_{1:M}, y_{1:M}^\ell) + \alpha \cdot \mathcal{L}{\text{flow}}(\mathbf{a}{t:t+H}, y_{1:H}^a)L=H(x1:M,y1:Mℓ)+α⋅Lflow(at:t+H,y1:Ha)
其中,H(x1:M,y1:Mℓ)H(x_{1:M}, y_{1:M}^\ell)H(x1:M,y1:Mℓ) 表示文本标记与预测 logits(包括 FAST 编码的动作标记)之间的交叉熵损失,y1:Ha=fθa(at:t+Hτ,ω,ot,ℓ)y_{1:H}^a = f_\theta^a(\mathbf{a}_{t:t+H}^{\tau,\omega}, \mathbf{o}_t, \ell)y1:Ha=fθa(at:t+Hτ,ω,ot,ℓ) 表示(较小规模的)动作专家模型的输出,α∈R\alpha \in \mathbb{R}α∈R 表示权衡参数。
该方案使我们能够首先通过将动作映射到文本标记(α=0\alpha=0α=0)来预训练模型,使其成为标准的 VLM Transformer 模型,然后在后训练阶段以非自回归的方式添加额外的动作专家权重,以预测连续的动作标记,从而实现快速推理。我们发现,遵循此流程能够使 VLA 模型获得稳定的预训练和出色的语言跟随能力。在推理阶段,我们对文本标记进行标准的自回归解码(ℓ^\hat{\ell}ℓ^),然后进行 10 次去噪步骤,以文本标记为条件,生成动作(at:t+H\mathbf{a}_{t:t+H}at:t+H)。
5.2 预训练

在第一训练阶段,π0.5\pi_{0.5}π0.5 使用广泛的机器人和非机器人数据进行训练,我们在下面进行了总结,并在图 4 中进行了说明。它作为标准的自回归转换器进行训练,执行文本、对象位置和 FAST 编码的动作标记的下一个标记预测。
多样化的移动机械臂数据(MM)。 我们使用了约 400 小时的移动机械臂数据,这些数据记录了它们在约 100 种不同的家庭环境中执行家务任务的过程。这部分训练集与我们的评估任务最为直接相关,我们的评估任务包括在全新的、未曾见过的家庭环境中执行类似的清洁和整理任务。
多环境非移动机器人数据(ME)。 我们还收集了多种环境下的非移动机器人数据,这些机器人配备单臂或双臂,并在各种家庭环境中运行。这些机械臂固定在表面或安装平台上,由于它们重量更轻、更易于运输,因此我们能够利用它们在更广泛的家庭环境中收集到更多样化的数据集。然而,这些 ME 数据与移动机器人的数据来自不同的设备。
跨具身实验室数据(CE)。 我们在实验室中收集了各种任务(例如,收拾餐桌、折叠衬衫)的数据,这些任务的桌面环境较为简单,且使用了多种类型的机器人。其中一些任务与我们的评估高度相关(例如,将餐具放入垃圾桶),而另一些则不然(例如,研磨咖啡豆)。这些数据包括单臂和双臂机械臂,以及静态和移动底座。我们还包含了开源的 OXE 数据集。该数据集是 π0\pi_0π0 所用数据集的扩展版本。
高级子任务预测(HL)。 将诸如"打扫卧室"之类的高级任务指令分解为诸如"调整毯子"和"捡起枕头"之类的更短的子任务,类似于语言模型的思维链提示,可以帮助训练好的策略更好地理解当前场景并确定下一步动作。对于 MM、ME 和 CE 中的机器人数据,由于任务涉及多个子任务,我们手动标注所有数据,添加子任务的语义描述,并训练模型 π0.5\pi_{0.5}π0.5,使其能够基于当前观察结果和高级指令,联合预测子任务标签(文本形式)以及动作(以子任务标签为条件)。这自然而然地产生了一个既可以作为高级策略(输出子任务)又可以作为低级策略(执行这些子任务的动作)的模型。我们还标注了当前观察结果中显示的相关边界框,并训练模型 π0.5\pi_{0.5}π0.5,使其能够在预测子任务之前预测这些边界框。
多模态网络数据(WD)。 最后,我们在预训练中纳入了一系列多样化的网络数据,包括图像描述(CapsFusion、COCO)、问答(Cambrian-7M、PixMo、VQAv2)和目标定位。对于目标定位,我们进一步扩展了标准数据集,加入了带有边界框标注的室内场景和家用物品的网络数据。
对于所有动作数据,我们训练模型来预测目标关节和末端执行器的位姿。为了区分两者,我们在文本提示中添加了 <控制模式> 关节/末端执行器 <控制模式>。所有动作数据均使用各个数据集中每个动作维度的 1% 和 99% 分位数进行归一化,得到 −1,1-1,1−1,1。我们将动作的维度 a\mathbf{a}a 设置为一个固定值,以容纳所有数据集中最大的动作空间。对于配置和动作空间维度较低的机器人,我们对动作向量进行零填充。
5.3 后训练
在用离散标记对模型进行 28 万个梯度步骤的预训练后,我们执行第二阶段的训练,我们称之为后训练。此阶段的目的在于使模型适应我们的用例(家庭中的移动设备操作),并添加一个动作专家,该专家可以通过流匹配生成连续的动作块。此阶段与下一个标记预测联合训练,以保留文本预测能力,并为动作专家进行流匹配(该专家在后训练开始时使用随机权重初始化)。我们对公式中的目标函数进行优化,并在 8 万步内使用 α=10.0\alpha=10.0α=10.0 进行额外迭代。
训练后的动作数据集包含 MM 和 ME 机器人数据,并筛选出长度低于固定阈值的成功回合。我们纳入了网络数据(WD)以保留模型的语义和视觉能力,以及与多环境数据集对应的 HL 数据切片。此外,为了提高模型预测合适的高级子任务的能力,我们收集了由专家用户提供的"语言演示"的语音指令演示(VI)。这些演示选择合适的子任务指令,逐步指挥机器人执行移动操作任务。这些示例是通过实时"远程操控"机器人,使其使用学习到的底层策略执行任务而收集的,本质上是为训练好的策略提供良好的高级子任务输出的演示。
5.4 机器人系统详情
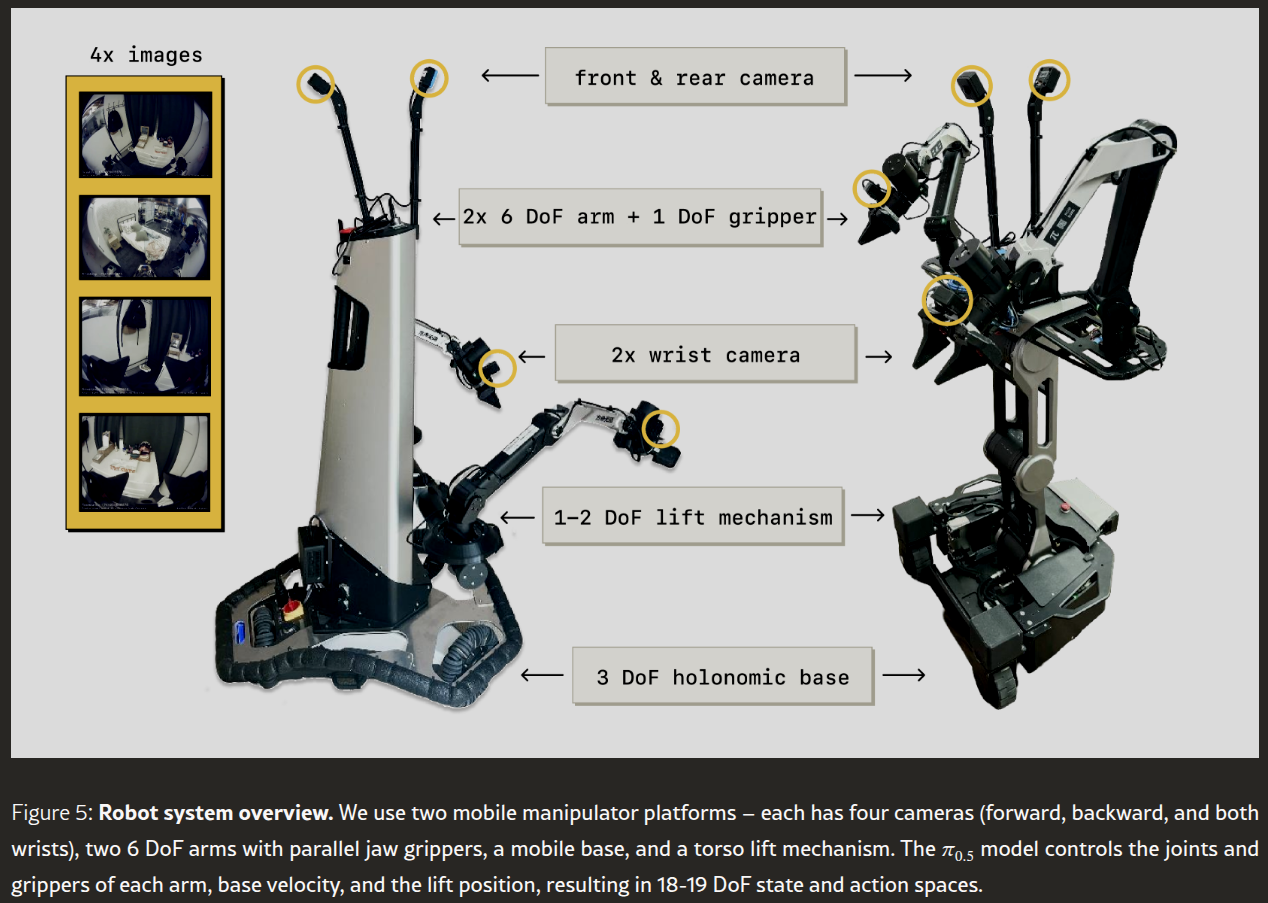
图 5:机器人系统概览。我们使用两个移动机械臂平台------每个平台配备四个摄像头(前视、后视和双腕)、两条带有平行爪夹持器的六自由度机械臂、一个移动底座和一个躯干升降机构。π0.5\pi_{0.5}π0.5 模型控制每条机械臂的关节和夹持器、底座速度以及升降机构的位置,从而形成 18-19 个自由度的状态和动作空间。
我们使用两种类型的移动机械臂进行了所有实验。两种平台均配备两条 6 自由度机械臂,机械臂带有平行爪夹持器和腕部单目 RGB 摄像头、一个轮式全向基座和一个躯干升降机构。基座的状态空间和动作空间分别对应于线速度(二维)和角速度(一维),而躯干升降机构可以是一维(上下)或二维(上下和前后)。除了两个腕部摄像头外,机器人还在机械臂之间安装了前视摄像头和后视摄像头。我们使用所有四个摄像头进行高级推理,而使用腕部摄像头和前视摄像头进行低级推理。状态空间和动作空间的总维度为 18 或 19,具体取决于平台。
控制系统非常简单:π0.5\pi_{0.5}π0.5 模型直接以 50 Hz 的频率(采用动作分块)控制机械臂、机械爪和躯干升降的目标姿态以及目标基座速度。这些目标由简单的 PD 控制器跟踪,无需任何额外的轨迹规划或碰撞检测。所有操作和导航控制都是完全端到端的。
六、实验评估
图 6:评估环境。我们在全新的厨房和卧室环境中评估 π0.5\pi_{0.5}π0.5,这些环境在训练过程中从未出现过,并包含全新的物品、背景和布局。我们使用一组模拟房间进行可控的、可重复的定量比较(左图),并使用真实住宅进行更贴近实际的最终评估(右图)。
π0.5\pi_{0.5}π0.5 模型旨在广泛泛化到新的环境中。虽然通常会在与训练数据相匹配的环境中评估 VLA,但我们所有的实验都在训练集中未出现过的新环境中进行。为了进行定量比较,我们使用一组模拟家庭环境来提供一个可控且可复现的设置,而最接近实际情况的最终评估则是在三个未包含在训练集中的真实家庭中进行的(见图 6)。
我们的实验主要关注以下问题:
- π0.5\pi_{0.5}π0.5 能否有效地泛化到全新住宅中的复杂多阶段任务?
- π0.5\pi_{0.5}π0.5 的泛化能力如何随训练数据中不同环境的数量而变化?
- π0.5\pi_{0.5}π0.5 训练混合物中的各个协同训练成分如何对其最终表现做出贡献?
- π0.5\pi_{0.5}π0.5 与 π0\pi_0π0 VLA 相比如何?
- π0.5\pi_{0.5}π0.5 的高级推理组件有多重要?它与扁平的、低级推理以及 Oracle 高级基线相比如何?
6.1 在真实家庭环境是否 work

为了回答问题 (1),我们使用两种类型的机器人,在三个未包含在训练集中的真实家庭环境中对 π0.5\pi_{0.5}π0.5 进行了评估。在每个家庭中,我们指示机器人执行卧室和厨房的清洁任务。每个任务的评估标准大致对应于每个任务中成功完成的步骤百分比(例如,将一半的碗碟放入水槽大约相当于 50%)。
结果表明,π0.5\pi_{0.5}π0.5 在每个家庭中都能稳定地成功完成各种任务(此外,我们注意到,该模型能够执行的任务远不止我们定量评估中使用的那些)。许多任务包含多个阶段(例如,移动多个物体),持续时间约为 2 到 5 分钟。在这些试验中,我们向模型提供一个简单的高级指令(例如,"将碗碟放入水槽"),然后高级推理过程会自主确定相应的步骤(例如,"拿起杯子")。这种实际应用的泛化能力显著超越了以往视觉-语言-动作模型所展现的结果,无论是在模型必须处理的新颖程度,还是在任务持续时间和复杂性方面。
【学习笔记】图 7 解读
绿色柱子(Real Home 1 & Real Home 2): 这是在真实的、没见过的家庭厨房 里做的测试。包含的任务有:把厨房用品收进抽屉(items in drawer)、把脏衣服放进篮子(laundry basket)、把碗碟收进水槽(dishes in sink)。结果: 任务进度平均达到了 80% 到 95% 的超高水准。这说明在陌生的复杂光照和真实布局下,模型的视觉常识和流匹配控手配合得极好。
灰色柱子(Real Home 3): 这是在第三个真实家庭 里的测试。结果: 这里的进度条出现了明显的下滑(约 65% 到 70%)。原因分析: 不同家庭的环境复杂度不同(比如 Home 3 的卧室可能特别狭窄,或者床单颜色和衣服太接近导致视觉混淆,或者是移动底盘在某些地毯上移动受阻)。这反映了真实世界泛化的残酷性。
黄色柱子(Mock Environments): 这是在实验室搭建的模拟/伪真实环境 (训练集中见过的类似场景)中作为基准对比。结果: 分数普遍非常高且稳定(接近 90% 以上)。
6.2 泛化能力如何随场景数量而变化?
在接下来的实验中,我们旨在衡量模型的泛化能力如何随训练数据中环境数量的增加而扩展。我们改变移动操作数据中的环境数量,并通过使用来自 3、12、22、53、82 和 104 个位置的数据进行训练,来衡量其对泛化能力的影响。由于对每个数据集应用完整的预训练和后训练流程计算量过大,因此在这些实验中,我们首先在不包含移动操作数据的机器人动作预测混合数据集上进行预训练,然后比较在包含不同数量移动操作数据的数据集上进行后训练的模型。虽然按位置划分的数据集在理论上大小不同,但实际上,我们选择的训练步数(4 万步)使得每个模型都能看到相同数量的独特数据样本,这使我们能够在后训练实验中改变位置数量时控制数据集的大小。
每个模型都在图 6 所示的模拟环境中进行评估,这些环境在训练过程中并未出现。我们进行了两种类型的评估。首先,为了评估模型在多阶段任务上的整体性能,我们使用标准评分标准和模拟测试环境,评估每个模型在将碗碟放入水槽、将物品放入抽屉、整理衣物和铺床等任务中的端到端性能。其次,我们对每个模型执行语言指令和与新物体交互的能力进行更精细的评估,其中机器人必须根据语言指令从厨房台面上拾取特定物体。这些实验既使用了与训练数据中物体类别相似的分布内物体(但为新实例),也使用了来自未见过类别的分布外物体。后者要求模型具备广泛的语义泛化能力。
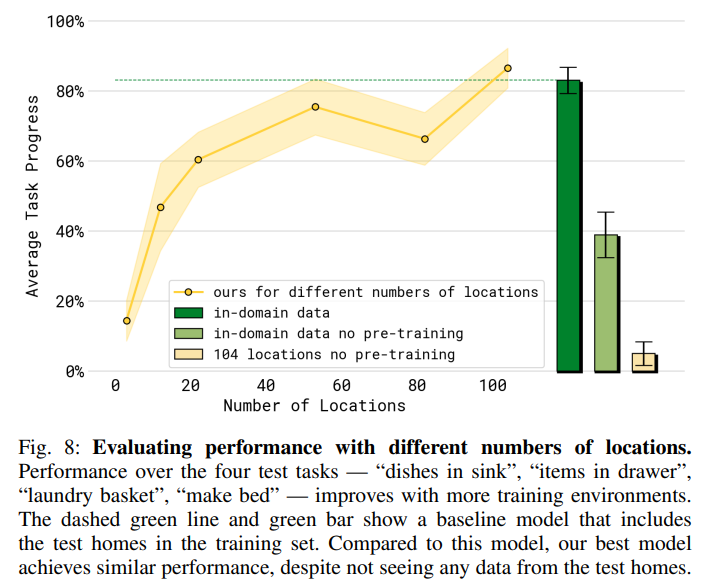
图 8:评估不同训练地点数量的端到端任务性能。
总体而言,随着训练地点数量的增加,各项任务的平均性能有所提升。为了量化最终模型(包含 104 个地点)在泛化能力方面的提升程度,我们设置了一个对照组(绿色),该对照组直接使用来自测试家庭的数据进行训练。该对照组的性能与最终的 104 地点模型相近,表明我们的协同训练方案有效地实现了广泛的泛化,达到了与在测试环境中训练的模型相似的性能。
为了验证这种泛化性能是否需要我们完整的协同训练方案,我们还设置了两个基线组,它们在预训练阶段不使用任何其他协同训练任务,而是直接使用来自测试环境的数据(浅绿色)或来自 104 个训练地点的移动操作数据(浅黄色)进行训练。这两个基线组的性能明显更差------这表明,即使策略已经接触过来自测试家庭的机器人数据,我们完整训练方案所利用的其他数据源对于良好的泛化能力仍然至关重要。当不使用来自测试家庭的数据时,使用我们的配方进行预训练尤为重要,如图 8 中绿色条和浅黄色条之间的巨大差距所示。
【学习笔记】图 8 解读
深绿色柱子(基准线/虚线)------
in-domain data: 这是直接拿测试目标家庭的数据 去喂给模型训(相当于考试前直接透题,作弊看答案)。成功率在 80% 多(这就是虚线的位置)。亮点: 你看那条黄色的折线终点(100 个地点),在完全没作弊的情况下,泛化性能竟然追平、甚至略微超越了直接在目标家庭训练的模型!浅绿色柱子 ------
in-domain data no pre-training: 同样是在目标家庭的数据上训,但是砍掉了左边的预训练阶段(不吃网络图文和跨具身大杂烩数据) 。性能直接腰斩(跌到 40%)。证明了: 哪怕你拿到了目标家庭的数据,如果不进行大规模预训练,模型缺少通用物理常识,动作依然非常容易崩溃。淡黄色柱子(全场最惨) ------
104 locations no pre-training: 有 104 个地点的机器人数据,但是完全不给它吃互联网图文、高层语义预测等协同训练数据(Co-training) ,只给它硬啃机器人的动作轨迹。成功率无限趋近于 0%(直接挂科)。证明了: 光靠堆机器人的动作数据是没用的。 如果不和互联网海量的多模态常识进行联合训练,机器人换个新环境依然是个"盲人",根本无法泛化。总结: 堆纯机器人数据是死路一条。只有把大约 100 个地点的机器人操控数据,混着全网的互联网图文常识一起大锅炖(Pre-training),机器人才能真正获得走入陌生家庭的"开放世界泛化能力"。
图 9:评估不同训练地点数量的语言跟随性能。我们评估了语言跟随率和拾取用户指定物品并将其放入抽屉或水槽的成功率,分别对已见物品类别("分布内")和未见物品类别("分布外")取平均值。随着训练地点数量的增加,性能稳步提升。
第二个实验(语言跟随)的结果如图 9 所示。我们报告了语言跟随率和成功率。语言跟随率衡量机器人选择语言指令中指定物体的频率,而成功率衡量机器人成功将该物体放置在正确位置(抽屉内或水槽内,取决于测试场景)的频率。我们分别测量了训练集中出现过的物体类别(但为新实例)和未出现过的物体类别("分布外")的性能。
图 9 显示,随着训练数据中位置数量的增加,语言跟随性能和成功率均有所提高。正如预期的那样,分布内物体的性能提升速度快于分布外物体。随着每个新环境引入新的家居用品,模型总体上变得更加稳健,并开始泛化到训练数据中未出现的任务类别。
【学习笔记】图 9 解读
⚪ 灰色线(In-Distribution,分布内/ID): 指的是测试时让机器人拿的物体,属于训练集里出现过的类别 (比如训练时抓过陶瓷盘,现在抓塑料盘)。
🟡 黄色线(Out-of-Distribution,分布外/OOD): 真正的地狱难度。指的是测试时用的物体类别,在之前的机器人训练集里压根就没出现过(全新物体的语义与视觉双重泛化)。
左图:语言跟随率(Follow Rate)------ 衡量的是机器人的"理解力"。即人类说去拿 A,机器人是不是真的把手伸向了 A,而不是指鹿为马去拿 B。无论是见过的物体(灰线)还是没见过的全新物体(黄线),随着训练地点从 20 增加到 100,机器人的理解正确率都在稳步飙升 。最终,在场景达到 100 个以上时,哪怕面对完全没见过的物体,机器人听懂并找对物体的概率(黄线终点)直接冲到了 70% 接近 80%!
右图:任务成功率(Success Rate)------ 衡量的是机器人的"硬实力"。不仅要找对物体,还要稳稳地把它抓起来,并精准地放进抽屉或水槽里,中间不能掉落、不能失误。灰线(见过相同品类)表现很好,场景多了之后,成功率一路上扬到了 60% 以上。黄线(全新物体种类)在训练地点小于 80 个的时候,一直被灰线死死地压在下方(在 20%~30% 的低位痛苦挣扎)。神转折: 只有当训练地点冲破 80、达到 100 个以上 时,黄线才像开窍了一样,出现了一个非常陡峭的爆发式上扬,成功率直接从 30% 暴崩到接近 55%!
总结:
- 脑子(理解力)往往比身体(操控力)先开窍: 对比左右两图可以发现,机器人在 40 个地点时就能很好地"找对物体"(左图黄线 40%),但由于没抓过这类新型物理几何体,它"抓不稳、放不好"(右图黄线才 20%)。
- 具身智能的"涌现临界点"(Emergent Property): 右图的黄线大拐弯无情地揭示了一个真理------对于全新物体的操作泛化,存在一个数据的数量临界值(Gate)。在环境跨度达到 100 个场景之前,模型面对新物体基本处于"抓瞎"状态;而一旦突破 100 个场景这个质变点,大模型内部的通用空间几何直觉就会产生"涌现",操控新物体的成功率直接翻倍。
6.3 协同训练方案的每个部分有多重要?
为了研究问题 (3),我们将完整的 π0.5\pi_{0.5}π0.5 模型与其他训练混合模型进行比较,以研究每个混合成分的重要性,同样使用模拟家庭环境中的端到端任务性能以及语言跟随评估。作为回顾,我们的完整模型使用了:
- 多种环境下的移动机械臂(MM)
- 多种环境下的静态机械臂(ME)
- 在实验室环境中收集的各种跨具身数据(CE)
- 预测结果对应于高级语言指令的高级数据(HL)
- 对应于图像描述、视频问答和物体定位任务的网络数据(WD)
- 训练后还使用了口头指令数据(VI)
在这些实验中,我们消融了混合模型的不同部分:
- 无 WD: 此消融不包括网络数据。
- 无 ME: 此消融不包括多环境非移动数据。
- 无 CE: 此消融不包括实验室交叉嵌入数据。
- 无 ME 或 CE: 此消融排除了来自其他机器人的两种数据源,因此模型仅使用来自目标移动机械臂平台的数据以及网络数据进行训练。
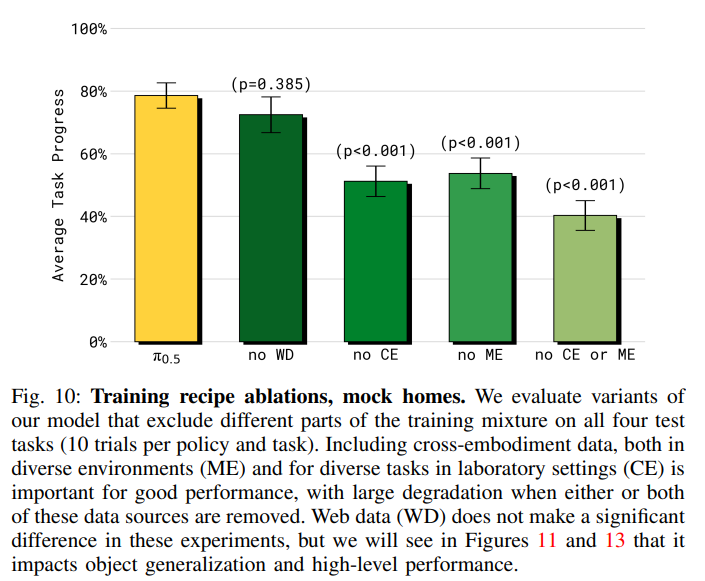
图 10:训练配方消融,端到端任务性能。
结果显示,排除两个跨具身数据源(ME 和 CE)中的任何一个都会显著降低表现,这表明 π0.5\pi_{0.5}π0.5 能从跨具身迁移中获益匪浅,无论是来自其他环境(ME)还是其他任务(CE)。排除这两个数据源会进一步损害表现。有趣的是,在本实验中,不进行 WD 消融处理后的表现差异并不具有统计学意义,尽管我们稍后会证明,网络数据对语言跟随和高阶子任务推理有很大影响。
【学习笔记】图 10 解读
完整版 π0.5\pi_{0.5}π0.5(约 78%): 所有的材料全给齐(包含网络图文 WD、多环境静态臂 ME、实验室跨具身数据 CE、以及自家的移动家务数据 MM)。拿到接近 78% 的最高分。
扣掉网络图文
no WD(约 72%): 在预训练时,不给模型看互联网上的常识图文 ,只用纯机器人的动作数据来训。进度条略微掉了一点(到 72% 左右),p=0.385p=0.385p=0.385。含义: 在统计学上,这个掉落不具备显著性差异 (在这个特定的、比较常规的实验室模拟家庭任务里,看不看互联网图片对纯动作的影响没有想象中那么大)。不过论文下方也补充解释了,网络数据在处理更高级的"物种泛化(物体泛化)"和"复杂高阶推理"时依然必不可少。扣掉实验室跨具身数据
no CE(暴跌到 50%): 不给模型吃别的实验室里、各种奇形怪状机器人做多样化任务的数据(CE) 。性能发生惨烈的断崖式暴跌 ,直接掉到了 50% ,p<0.001p<0.001p<0.001(代表统计学上的绝对显著,属于毁灭性打击)。含义: CE 数据是真正的"神仙解药"! 哪怕那是别人家的机器人、干的也是完全不一样的任务,但大模型正是通过看别人家机器人是怎么跟各种各样的物体交互的,才真正开窍、学会了通用物理几何直觉。扣掉多环境非移动数据
no ME(暴跌到 52%): 不给模型吃那些在很多个不同环境里、但身体固定不动的静态机械臂数据(ME) 。同样发生暴跌,掉到了 52% 左右,同样是 p<0.001p<0.001p<0.001 极度显著。含义: ME 数据也是核心支柱! 模型必须在预训练时见过"大量的、不同的环境背景图"(哪怕机械臂是固定的),它才能在后训练时快速适应各种家庭不同色调、不同光照的厨房和卧室。裸奔版:CE 和 ME 全扣掉
no CE or ME(跌到 40%): 既不给看别人家的机器人(无 CE),也不给看多环境静态臂(无 ME)。模型只能孤独地啃着自家移动机器人那点极其可怜的家务数据。全场最惨,直接跌到 40% 临界点。含义: 缺少了外界大杂烩数据的滋养,大模型(VLA)直接退化成了普通的、没有灵魂的小模型,失去了泛化能力。总结:在预训练阶段,对机器人大模型泛化性帮助最大、最不可或缺的,并不是互联网图文(WD),而是"别人家机器人千奇百怪的交互动作(CE)"以及"在成百上千个不同环境里的静态机械臂动作(ME)"。 这种"跨机器人、跨环境的联合大协同训练(Cross-Embodiment Co-training)",才是 π0.5\pi_{0.5}π0.5 能够从一众机器人模型中脱颖而出、变得极具灵性的根本原因。
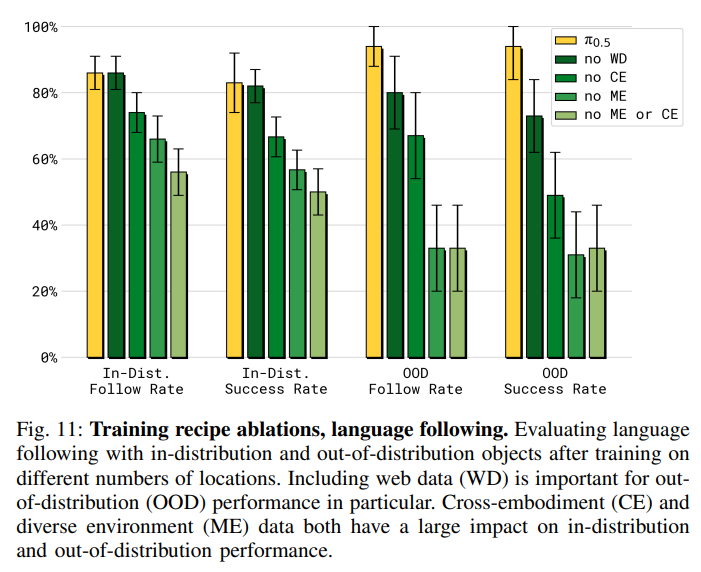
图 11:训练配方消融,语言跟随。在不同数量的位置进行训练后,评估分布内和分布外对象的语言跟随性能。纳入网络数据(WD)对分布外(OOD)的性能尤为重要。跨具身(CE)和多样化环境(ME)数据均对分布内和分布外的性能有显著影响。
图 11 所示的语言跟随实验结果与图 10 的趋势相似------排除 ME 或/和 CE 数据会导致性能显著下降。不同之处在于,移除网络数据(无 WD )会导致分布外(OOD)对象的性能显著恶化------我们推测,使用包含非常广泛的物理对象知识的网络数据进行训练,能够使模型理解并跟随涉及未见过对象类别的语言指令。
【学习笔记】图 11 解读
这张图把考试分成了左边两组和右边两组:
- 左边两组(In-Dist. 分布内): 测试见过的物体类别。
Follow Rate(听懂人话去拿对物体的概率)、Success Rate(不仅拿对,还要操作成功的概率)- 右边两组(OOD 分布外): 地狱难度,测试完全没见过的全新物体 。
Follow Rate(面对没见过的物体,能不能听懂人话找对它)、Success Rate(面对没见过的物体,能不能完成高精度抓取放好)抓内鬼环节:看黑色柱子(no WD)的离奇反转
在左边"见过的物体"(In-Dist.)考试中:黄色柱子(全给齐)和黑色柱子(扣掉 WD)几乎是一样高 的(都在 80% 多)。含义: 如果只是操作训练集里见过的日常物体,机器人不需要互联网知识,光靠平时练的肌肉记忆就能干得很好。所以不喂 WD 数据,性能几乎不掉。
在右边"没见过的全新物体"(OOD)考试中,反转来了!一旦遇到完全没见过的东西:
- 听懂人话(Follow Rate): 黄色柱子在 90% 以上,而一旦扣掉网络数据(no WD),直接掉到了 80%。
- 物理搞定(Success Rate): 黄色柱子在 90% 以上,扣掉网络数据(no WD),暴跌到了 70% 出头。
含义: 只要不给机器人看互联网上的图文,当听到一个陌生名词(比如某种新型工具)时,它在现场就会开始懵圈。要么找错东西(Follow Rate 下降),要么因为不知道这个东西的物理材质和常识,抓的时候直接抓瞎(Success Rate 暴跌)。
再往右看每组中剩下的几个浅绿色柱子(
no CE扣掉跨具身、no ME扣掉多环境):在右边两组 OOD(全新物体)的考试中,一旦扣掉了别的实验室机器人数据(no CE)或者环境数据(no ME),机器人的性能直接从 90% 跌到了 20%~30% 。这证明了: 面对全新的物体,如果大模型没有在预训练时通过 CE 和 ME 练就一身"看遍天下各种奇葩物体和千奇百怪环境"的泛化几何直觉,机器人在陌生环境下面对陌生物体直接等同于"瘫痪"。
6.4 π0.5\pi_{0.5}π0.5 与其他 VLA 相比如何?
我们将 π0.5\pi_{0.5}π0.5 与原始的 π0\pi_0π0 VLA 以及 π0\pi_0π0 的改进版本 π0\pi_0π0-FAST+Flow 进行比较。该版本通过联合扩散和 FAST 动作预测公式进行训练,但仅使用动作数据,不使用 HL 或 WD 数据集。这些模型提供了强有力的比较基准,因为 π0\pi_0π0 已被证明在复杂灵巧的移动操作任务中表现出色,而 π0\pi_0π0-FAST+Flow 的改进使其尽可能接近 π0.5\pi_{0.5}π0.5。π0.5\pi_{0.5}π0.5 在这些模型的基础上,结合了协同训练任务。
为了公平比较,所有模型都使用相同的跨具身机器人训练集,并训练相当数量的步骤。因此,它们之间的区别在于:
- π0.5\pi_{0.5}π0.5 额外使用了 HL 和 WD 数据
- π0.5\pi_{0.5}π0.5 采用混合训练方法,在预训练阶段进行离散标记化训练,在后训练阶段仅使用流匹配动作专家进行训练,而 π0\pi_0π0 始终使用动作专家
- π0\pi_0π0-FAST+Flow 遵循混合训练方法,但仅使用包含机器人动作的数据进行训练,因此无法执行高级推理
图 12 的结果表明,π0.5\pi_{0.5}π0.5 的性能显著优于 π0\pi_0π0 和我们改进的版本。即使我们将训练时间延长至 π0\pi_0π0 的 30 万个训练步,该结果仍然成立,这证实了使用 FAST 标记进行训练在计算效率方面比纯粹基于扩散的训练更有效。
【学习笔记】图 12 解读
认识竞技场上的四个选手:
- 🟡 π0.5\pi_{0.5}π0.5(黄色柱子): 完整完全体。预训练吃了海量大杂烩(含 HL 子任务和 WD 网络图文),后训练用了动作专家和流匹配。
- ⚪ π0\pi_0π0-FAST + Flow (no HL)(灰色柱子): 没有"脑子"的肌肉男。同样使用了先进的 FAST 动作标记器和流匹配,但训练时故意不加 HL(高级子任务数据)和 WD(网络图文)。它不懂得自言自语拆解任务,只会看图生硬地死磕动作。
- 🌲 π0\pi_0π0 300k 步训练(深绿色柱子): 大名鼎鼎的前作老大哥,用传统的纯扩散模型(Diffusion)死磕了 30 万步。
- 🌱 π0\pi_0π0 80k 步训练(浅绿色柱子): 破产版老大哥,只训练了 8 万步。
战况盘点:
第一回合:洗碗与收纳(极度依赖物理控制和常识)------ π0.5\pi_{0.5}π0.5 的成功率直接冲到了 85% ~ 90% 的神级水平。而前作老大哥 π0\pi_0π0 甚至连 40% 都到不了。在收纳任务(items in drawer)中,如果没有预训练的底子(π0\pi_0π0 80k),成功率直接跌到了接近 0%。
第二回合:最难的"叠被子"(make bed,布料类软体操作)------ 叠被子需要极强的空间推理和漫长的长程规划。所有模型的分数都整体掉了一大截。但哪怕大家都在挨打,π0.5\pi_{0.5}π0.5 依然顽强地顶在了 60% 的及格线以上,而纯靠动作死磕的前作们(两个绿色柱子)直接全军覆没,跌到了 10% ~ 20% 的瘫痪状态。
这张图揭示的两个重要结论:
结论一:FAST + 流匹配(Flow)确实比传统扩散(Diffusion)强得多。 灰色柱子(π0\pi_0π0-FAST + Flow)虽然没有看互联网图文、也没有子任务大脑,但它靠着"流匹配直线去噪"的超强物理直觉,在洗碗和收衣服任务里,硬生生把成功率拉到了 60% ~ 70% ,完爆了训练了 30 万步的初代老大哥 π0\pi_0π0(深绿柱子)。在控手算法上,流匹配对传统扩散模型完成了降维打击,效率和精度都更高。
结论二:光有强壮的身体不够,必须有"自言自语"的大脑(HL)。 灰色选手虽然控手很丝滑,但在面对复杂的"叠被子(make bed)"和"洗碗(dishes)"时,因为缺乏 HL(高级子任务语义引导),它不知道每一步之间的逻辑衔接,性能还是被黄色死死压制。
6.5 高级推理有多重要?
最后,我们评估了高层推理的重要性,并比较了几种不同的高层推理方法的性能。π0.5\pi_{0.5}π0.5 中的高层推理机制接收一个高层命令(例如,"打扫卧室"),并输出要完成的子任务(例如,"捡起枕头"),然后将其用作推断底层操作的上下文,类似于思维链推理。π0.5\pi_{0.5}π0.5 使用统一的架构,其中同一个模型执行高层和底层推理,但我们也可以构建基线方法,这些方法要么放弃高层推理过程,直接将任务提示输入到底层系统中(这在标准 VLA 模型中很常见),要么使用另一个模型进行高层推理,以消除不同数据集组件对高层策略的影响。
我们考虑以下方法和消融,所有这些方法和消融都使用完整的 π0.5\pi_{0.5}π0.5 底层推理过程,但采用不同的高层策略:
- π0.5\pi_{0.5}π0.5 模型用于高级和低级推理。
- 无 WD: 对 π0.5\pi_{0.5}π0.5 进行消融,排除网络数据。
- 无 VI: π0.5\pi_{0.5}π0.5 的消融,排除口头指导(VI)数据。
- 隐式 HL: 运行时不进行高级推理,但在训练中包含高级数据,这可能会隐式地教会模型有关子任务的信息。
- 无 HL: 没有高级推理,训练中也完全没有高级数据。
- GPT-4: 使用 GPT-4 作为高层策略,评估在机器人数据上训练该高层策略的重要性。为了使模型与我们的领域相匹配,我们向 GPT-4 提供任务描述和常用标签列表供其选择。
- 人类高级策略: 使用专家作为"先知"高级策略,为绩效提供上限。
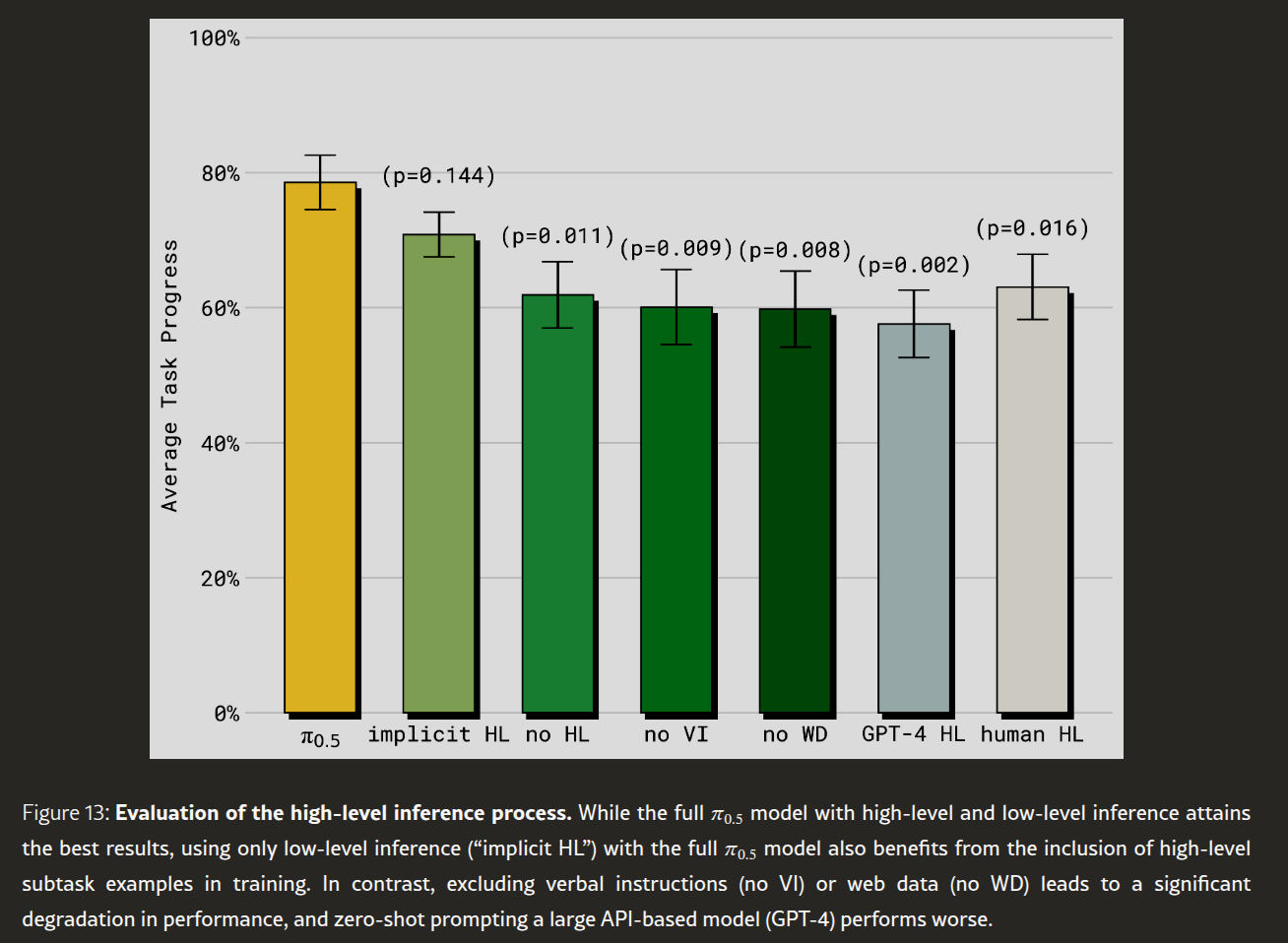
图 13:高层推理过程的评估。虽然包含高层和低层推理的完整模型取得了最佳结果,但仅使用低层推理("隐式 HL")的完整模型也能受益于训练中包含的高层子任务示例。相反,排除口头指令(无 VI)或网络数据(无 WD)会导致性能显著下降,而对大型基于 API 的模型(GPT-4)进行零样本提示则表现更差。
这些实验结果如图 13 所示。完整的 π0.5\pi_{0.5}π0.5 模型表现最佳,甚至优于人类高阶"预言机"基线模型。或许令人惊讶的是,表现第二好的模型是隐式高阶消融模型,该模型不进行任何高阶推理,但在训练中包含了完整的混合数据,即子任务预测。这有力地表明了我们模型所采用的协同训练方法的重要性:虽然显式推理高阶子任务有一定好处,但仅仅将子任务预测数据包含在训练混合数据中,就能获得相当一部分好处。
不包含高阶任务(即使在训练中也排除高阶任务)的消融模型表现明显更差。结果还表明,相对较小的口头指令数据集(仅占高阶移动操作示例的约 11%)对于获得优异的性能至关重要,因为不包含口头指令的消融模型性能明显较弱。无 WD 消融实验的结果也明显更差,这表明网络数据的大部分优势(或许并不令人意外)在于改进高层策略。最后,零样本 GPT-4 消融实验的性能最差,这表明利用机器人数据来调整 VLM 的重要性。
【学习笔记】图 13 解读
完全体 π0.5\pi_{0.5}π0.5(约 78%): 完整标准流程:输入宏观任务 → 经过预训练 VLA 显式输出(Explicitly predicts) 文本子任务
"pick up the pillow"→ 灌入绿色动作专家执行。依旧是全场最高分。隐式高层推理
implicit HL(约 72%): 在推理时,强行把大模型的"嘴巴"闭上,不让它把子任务文本字面吐出来 ,而是直接利用大模型内部的隐藏状态(Hidden States)去驱动右边的动作专家。性能掉到了 72% 左右。含义: 让大模型把任务用人类语言"大声说出来(显式文本 Token)"作为跳板,比让它闷在心里(隐式特征)直接做动作,在逻辑上更不容易出错。这就是大模型在具身智能里的思维链(Chain of Thought)效应。完全没有高层推理
no HL(掉到 62%): 彻底砍掉子任务拆解。输入宏观任务后,直接硬核去卡动作。性能明显滑落。扣掉口头指令数据
no VI(约 60%):VI代表 Verbal Instructions(人类教练带训时的口头旁白)。如果在后训练时,不把人类现场说的口头命令跟动作焊死,成功率直接暴跌。这证明了人类的口头常识数据是高层逻辑和低层肌肉记忆之间最好的"粘合剂"。扣掉网络数据
no WD(约 60%): 再次呼应了前面的结论,不给看互联网图文,大模型的大脑推理就会变成"无源之水"。呼叫外援 GPT-4
GPT-4 HL(跌到 58%): 这个最绝。很多人会想,既然 π0.5\pi_{0.5}π0.5 的大脑只有 2.6B(Gemma),那如果我们在推理时,把当前的画面和任务扔给市面上最聪明的 GPT-4(或者 GPT-4V 视觉版) ,让 GPT-4 帮机器人写出子任务拆解"pick up the pillow",然后再传给 π0.5\pi_{0.5}π0.5 的动作专家去执行,会不会更牛?结果:啪啪打脸,成功率跌到了 58% 的低谷。为什么? 因为 GPT-4 虽然绝顶聪明,但它是零样本提示(Zero-shot Prompting)的空头司令。它根本不知道当前这个机器人的硬件底盘长啥样、手臂有多长、当前的运动极限在哪里。它拆解出来的动作往往是"正确的废话",或者是物理上无法执行的空中楼阁 。而 π0.5\pi_{0.5}π0.5 自己预测的子任务是在预训练里和自己的身体数据一起滚出来的,更懂自己"能不能做到"。
纯人类远程实时拆解
human HL(约 63%): 机器人不动脑子,每走一步,都由一个真正的人类 在后台看着监控,手动敲键盘给机器人下达最精准的下一步子任务文本命令。令人震惊的是,纯人类在线当导师,最终的总成功率(63%)竟然也大幅度落后于 π0.5\pi_{0.5}π0.5 自己的完全体(78%)!为什么? 因为人类下达指令存在严重的传输延迟和人机对齐时滞 。当人类看到画面、脑子里想好、再把
"pick up the pillow"传输过去的时候,机器人的位置和周围的物理环境在实时闭环中可能已经发生了微小的漂移,导致动作衔接卡顿、错位。终极核心暴论:在控制具身智能机器人时,大模型的大脑(高层推理)和身体(底座动作)必须同气连枝、在同一个模型内部(End-to-End Co-design)闭环自回归输出。任何试图通过呼叫外部最强外援(如 GPT-4)或者引入人类实时远程干预(Human-in-the-loop)来指导动作的做法,都会因为"丧失物理具身感知"和"延迟错位",被模型自己的眼口手合一完爆。
这也是为什么 Physical Intelligence 坚定不移地要走"把 VLA 彻底熔炼成一个统一体"这条路的核心底气所在。
七、讨论与未来工作
我们描述了 π0.5\pi_{0.5}π0.5,这是一个基于 π0\pi_0π0 VLA 的协同训练模型,它整合了多种数据源,并能够泛化到新的环境中。π0.5\pi_{0.5}π0.5 VLA 可以控制移动机械臂在家庭环境中执行训练数据中从未出现过的任务,例如清洁厨房和卧室、铺床、晾晒毛巾以及其他多阶段灵巧操作。π0.5\pi_{0.5}π0.5 使用约 400 小时的移动操作数据进行训练,但包含了来自其他机器人的大量数据,包括不同环境中的非移动机械臂以及在实验室条件下收集的数据。它还与来自网络的数据以及用于根据机器人观察输出语言命令的高级预测数据进行联合训练。π0.5\pi_{0.5}π0.5 的泛化能力表明,这种协同训练方法能够有效促进迁移,仅使用中等规模的移动操作数据集即可实现对移动机械臂的高度泛化控制。
π0.5\pi_{0.5}π0.5 并非完美无缺。虽然我们的 VLA 模型展现出广泛的泛化能力,但它仍然会犯错:
- 某些环境会带来持续的挑战(例如,不熟悉的抽屉把手,或机器人难以打开的橱柜)
- 某些行为会因部分可观察性而带来挑战(例如,机械臂遮挡了需要擦拭的污渍)
- 在某些情况下,高层子任务推理很容易受到干扰(例如,在收纳物品时多次开关抽屉)
通过更好的协同训练、迁移学习和更大的数据集来解决这些挑战,是未来研究的一个有前景的方向。
其他未来的研究方向可以着重解决我们方法的技术限制。虽然 π0.5\pi_{0.5}π0.5 可以执行各种行为来清洁厨房和卧室,但它处理的指令相对简单。模型能够处理的指令的复杂程度取决于训练数据,而更复杂的偏好和指令可以通过生成更复杂、更多样化的标注来实现,这些标注可以通过人工标注或合成标注的方式获得。
该模型目前使用的上下文信息相对有限,如果能整合更丰富的上下文信息和记忆,则可以显著提升模型在可观测性不完全的场景下的性能,例如需要在不同房间之间导航或记住物品存放位置的任务。
更广泛地说,π0.5\pi_{0.5}π0.5 探索了异构数据源的特定组合,但具体的数据源还可以进一步拓展。例如,我们的系统能够从口头指令中学习,这提供了一种强大的新型监督方式,未来的工作可以探索这种方式以及其他人们可以为机器人提供额外上下文知识的方法。
我们希望我们的工作能够为新一代 VLA 奠定基础,使其能够广泛适用于各种现实世界环境。
参考:
Gemini