5.14 DeepSeek-V3 核心利器:MTP (多 Token 预测)
在传统的大模型(LLM)训练和推理中,我们一直遵循着一个"铁律":一次只预测下一个 Token。也就是说,模型吐出"我"之后,再根据"我"吐出"爱",接着再吐出"你"。这种"挤牙膏"式的生成方式,效率存在天然的天花板。
DeepSeek-V3 引入了一项重磅创新------MTP (Multi-Token Prediction,多 Token 预测) 。它的核心思想简单直接:与其一次只预测一个,不如让模型"看得更远",在一步计算中预测未来连续的多个 Token。
一、 MTP 是怎么设计的?
MTP 通过在主模型之外增加额外的"MTP 模块"来实现多重预测。
模型结构图解
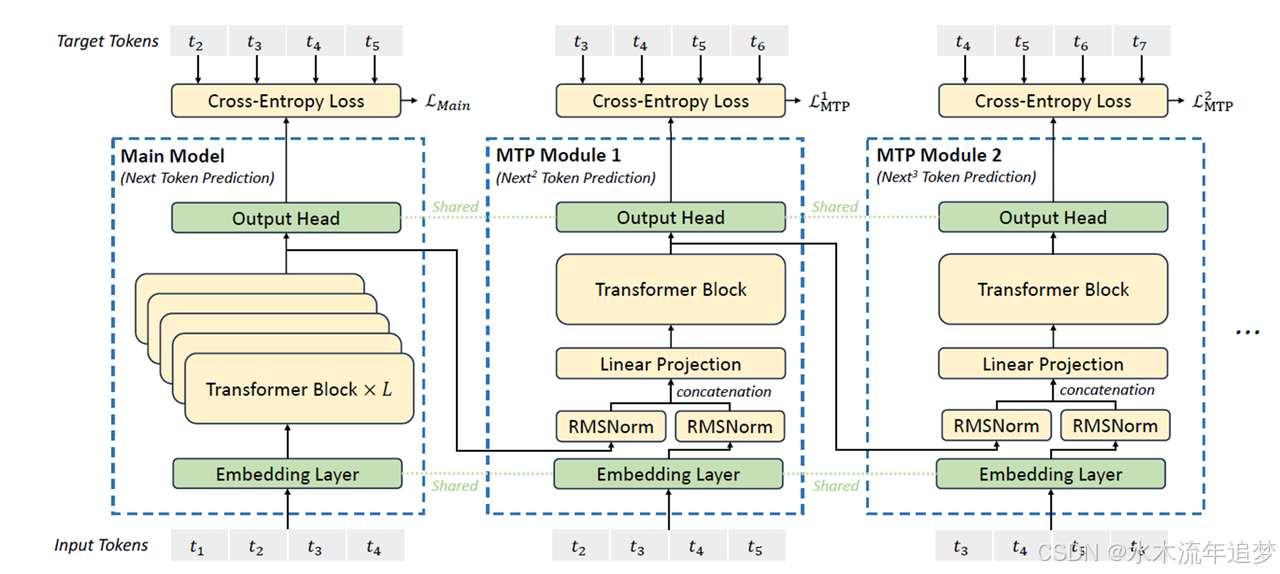
模型结构看起来像是一个"四层叠罗汉":
- 共享嵌入层: 最底层的词向量输入(Shared Embedding)。
- 归一化 + FNN 层: 每层都有独立的归一化和处理逻辑。
- 独立的 Transformer 块: 这是 MTP 的灵魂,每个 MTP 模块都有自己独立的 Transformer 层,专门用于处理不同深度的预测任务。
- 共享输出头: 最后通过共享的 FFN 和 Softmax 层得到 Token 的概率。
二、 MTP 是如何训练的?
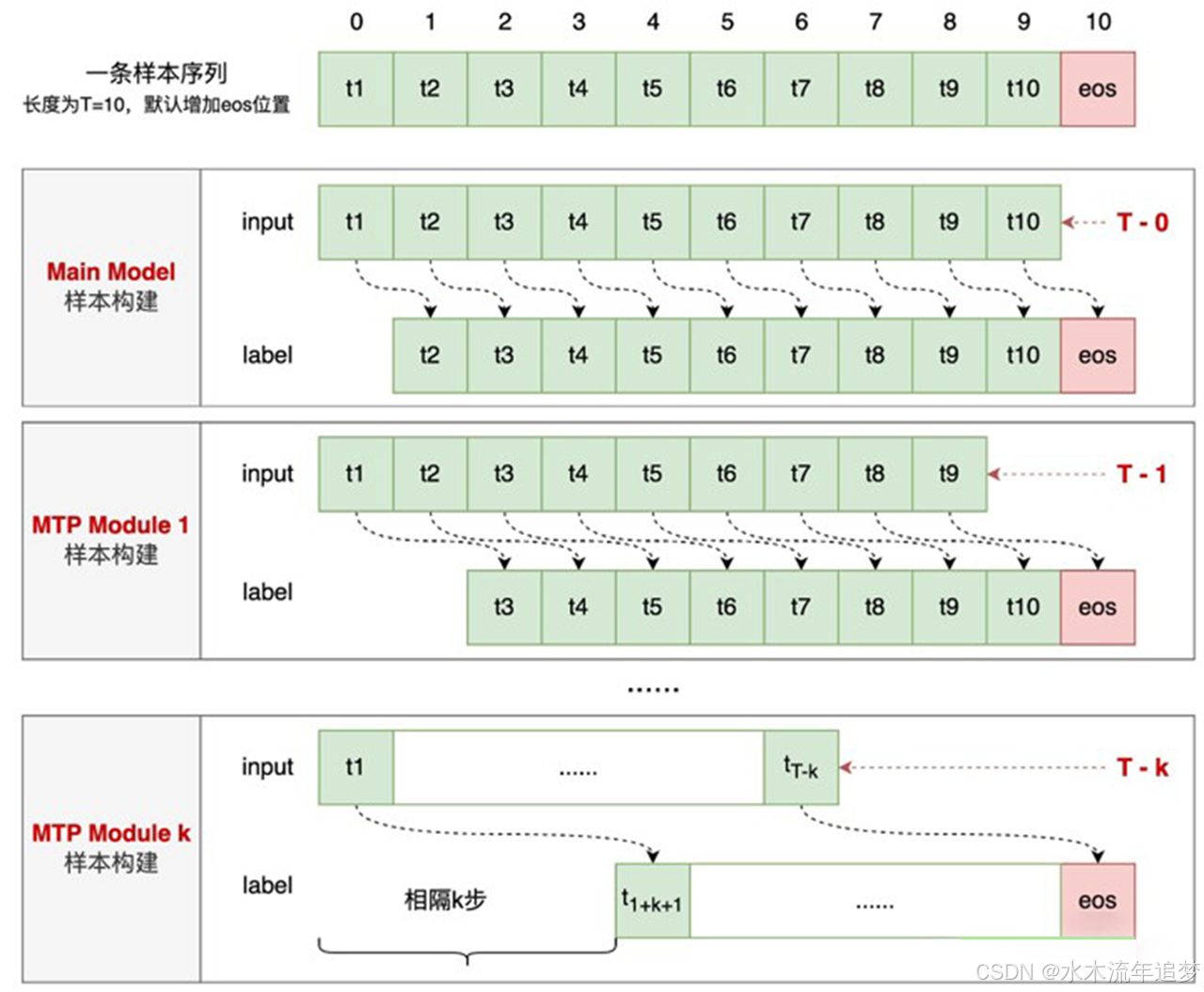
传统模型训练时,输入是"中国的首都",目标标签(Label)是"是";接着输入"中国的首都是",标签是"北"。
MTP 的训练方式则更加"贪婪":
在训练时,模型会构建多个并行的预测分支:
- 主模型分支: 预测下一个 Token t 2 t_2 t2。
- MTP 模块 1: 预测未来第 2 个 Token t 3 t_3 t3。
- MTP 模块 k: 预测未来第 k k k 个 Token。
通过这种方式,模型在一次训练中学习到了更长远的上下文依赖关系,极大地提升了模型的逻辑一致性和数据利用效率。
三、 核心大招:MTP 如何加速推理?
大家可能有个疑问:训练时预测多个 Token,推理时也要一次全吐出来吗?
是的!MTP 开启了 Self-Speculative Decoding(自投机解码) 模式,这是它实现加速的关键。
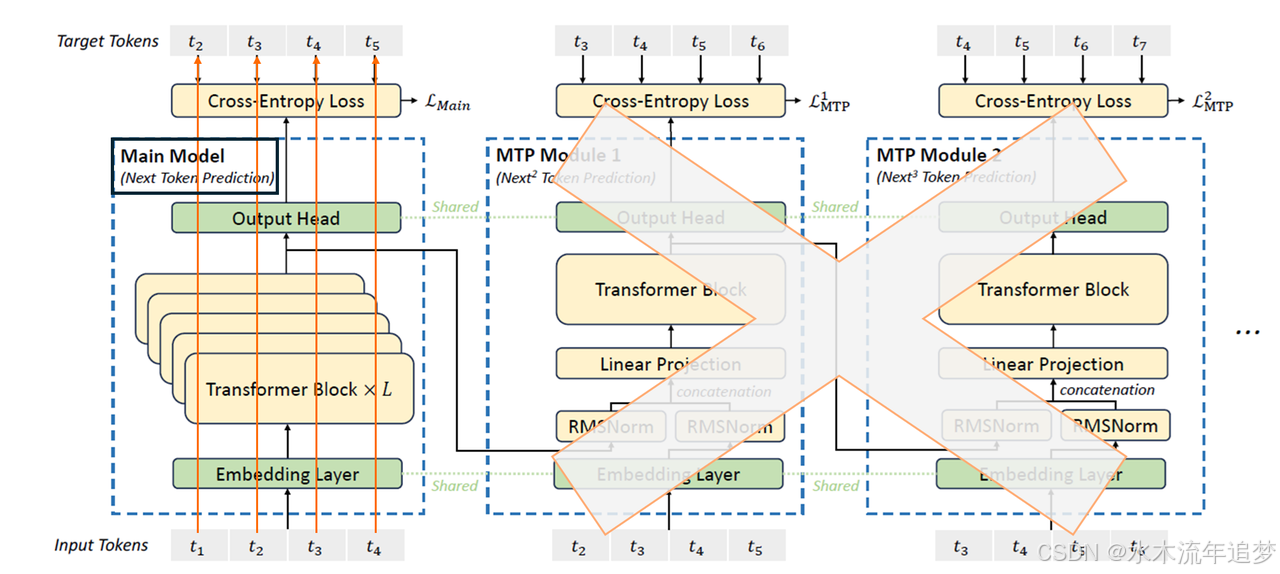
推理的三步走策略:
- Predict (预测): 利用训练好的 MTP 模块,一次性并行生成未来 k k k 个 Token。
- Verify (验证): 这是一个"自检"过程。将生成的 Token 拼回原序列,用主模型(Main Model)进行一次并行计算。如果主模型算出的结果和 MTP 刚才吐出来的结果完全一致,说明模型预测对了!
- Accept (采纳): 如果验证通过,我们可以一次性采纳这 k k k 个 Token,直接跳过 k k k 步繁琐的单字生成。
提速效率有多高?
假设并行预测 4 个 Token(即 k = 4 k=4 k=4),推理流程由"生成+校验"两个步骤组成。因为校验阶段通过矩阵并行计算可以瞬间完成,理论上推理速度可以提速接近 1 倍!
四、 总结:为什么要引入 MTP?
| 特性 | 传统 LLM | DeepSeek MTP |
|---|---|---|
| 预测模式 | Token-by-Token(一步一步挤牙膏) | Multi-Token(一次跨步多格) |
| 数据利用 | 仅利用当前上下文预测下一个 | 学习未来多个位置的依赖 |
| 推理速度 | 较慢,受制于串行延迟 | 极快,通过投机验证机制实现并行化 |
入门人员避坑指南:
- 不要混淆: 在推理时,如果你把 MTP 模块直接丢弃,模型其实还是可以运行的,只不过退化成了普通的"单 Token 预测"模型,没有任何加速效果。
- 本质优势: MTP 并不是简单地堆砌参数,而是通过"提前看未来"的训练方式,强制模型在处理单个 Token 时具备了更全局的视角,从而在推理阶段实现了"小步快跑"的加速效果。
DeepSeek-V3 的这一设计,堪称将大模型的性能压榨到了极致,为我们展示了"模型架构设计"与"系统级推理优化"紧密结合的未来方向!
5.15 DCA 双块注意力:打破长文本推理的"外推魔咒"
论文地址: https://arxiv.org/pdf/2402.17463
在大模型开发中,我们常听到"长文本外推"这个术语。简单来说,就是想让一个在 4K 长度文本上训练的模型,去处理 10K 甚至更长的文本。
目前主流的方案如 RoPE(旋转位置编码) 在短文本下表现优异,但一旦超过预训练长度,模型就会出现"断崖式"的性能崩塌。虽然 PI、NTK、YaRN 等技术可以通过拉伸位置编码来缓解,但它们往往需要额外的微调(Fine-tuning)。而 DCA (Dual Chunk Attention,双块注意力) 的出现,为我们提供了一个无需额外训练、甚至无需微调就能大幅提升窗口窗口的"神操作"。
一、 为什么 RoPE 很难"直接外推"?
为了理解 DCA,我们先看 RoPE 的缺陷:
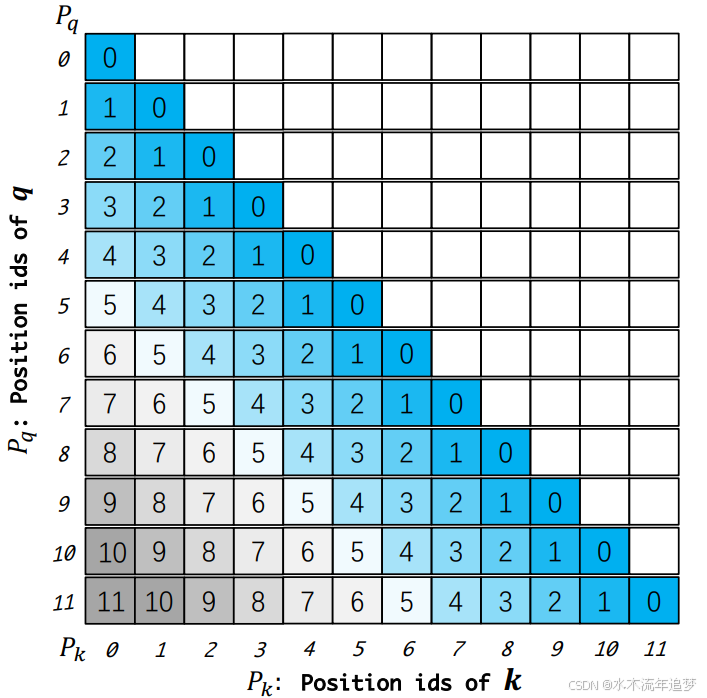
- 相对位置矩阵的混乱: RoPE 的本质是基于相对位置的旋转。当输入长度超过预训练上限时,模型在计算"注意力分数矩阵"时,会因为从未见过这些超大位置差,导致计算出的矩阵值乱码,注意力机制彻底失效。
- 位置编码差值问题: DCA 的核心贡献在于它非常巧妙地处理了 RoPE 中相对位置编码的"差值矩阵"问题。
二、 DCA 的核心脑洞:长序列"分块作战"
DCA 的思路非常"工程化":既然长序列计算太痛苦,那我就把它切碎。
DCA 将超长序列分割成多个小的"块(Chunk)",然后通过三层逻辑来计算注意力,这三层就像是处理信息的三个层级:
1. 块内注意力 (Intra-Chunk Attention)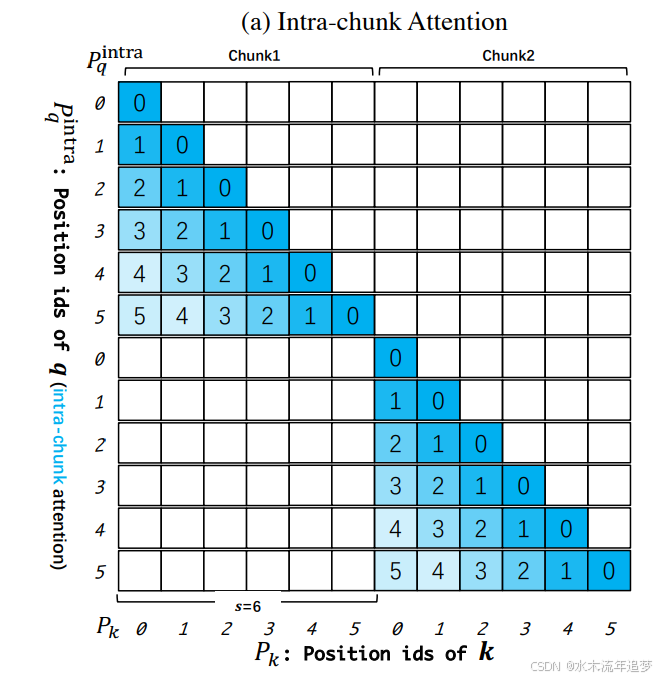
- 目标: 捕捉局部最紧密的联系。
- 做法: 每个 Token 只看自己所在的那个小块里的兄弟。就像一个教室里,大家只关注自己组内的小伙伴,互不越界。
2. 块间注意力 (Inter-Chunk Attention)
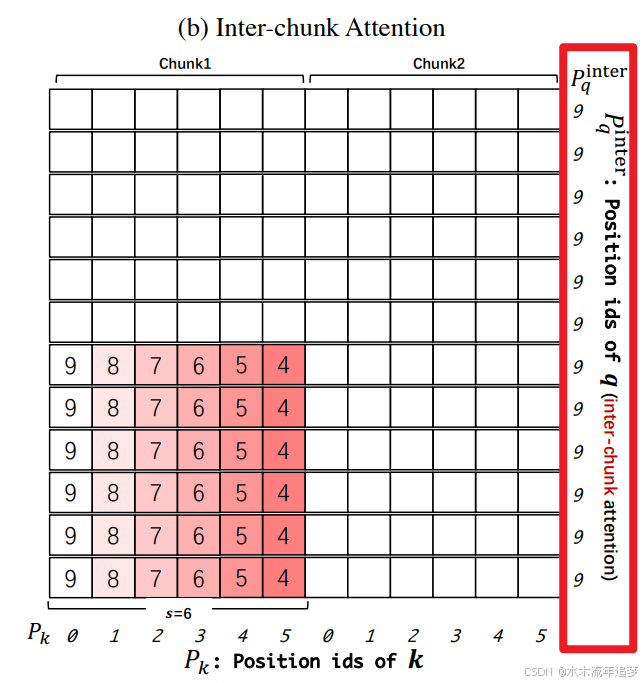
- 目标: 捕捉全局的长距离依赖。
- 做法: 每个块都可以与其他所有块进行"远距离对话"。这确保了模型不会因为分块而丢失全局语境。
3. 相邻块注意力 (Successive-Chunk Attention)
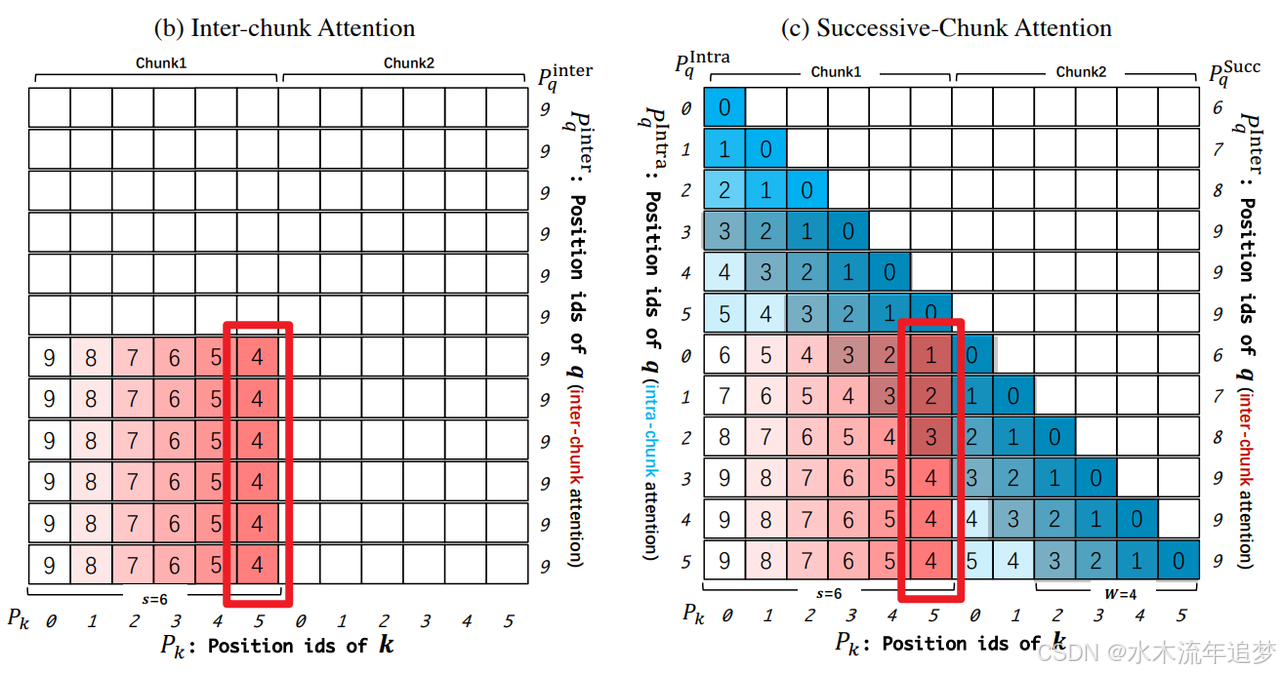
- 目标: 加强衔接处的平滑过渡。
- 做法: 特别关注"左右邻居"块。因为在分块的边缘处,两个 Token 虽然属于不同块,但它们在逻辑上其实非常靠近。通过这种方式,DCA 保证了长序列在拼接处的平滑衔接。
三、 DCA 的运行机制:它是如何巧妙避开"外推限制"的?
DCA 最天才的地方在于它对 位置 ID 的重映射:
- 块内重映射: 对于块内注意力,它将相对距离限定在块的长度范围内(例如 6),无论序列多长,它永远只需要处理 0, 5 的距离。
- 块间重映射: 当两个块交互时,它通过设定一个偏移量(Offset),让远处的块映射回模型熟悉的"预训练距离范围"内。
这就好比你做一套试卷,不管试卷有 100 页还是 1000 页,DCA 总能通过一种"页码折叠"算法,让你每次只需要处理相邻的几页,从而避免了让模型处理它从未见过的"超远距离"位置标签。
四、 核心代码拆解
DCA 的核心逻辑在于如何切块并计算跨块注意力。以下代码展示了 DCA 的跨块注意力计算逻辑:
python
def cross_block_attention(self, Q_chunks, K_chunks, V_chunks):
batch_size, num_chunks, chunk_size, embed_size = Q_chunks.shape
cross_attn_out = []
for i in range(num_chunks):
q_chunk = Q_chunks[:, i, :, :]
# 计算当前块与所有其他块的分数
attn_scores = torch.matmul(q_chunk, K_chunks.transpose(2, 3)) / (self.embed_size ** 0.5)
# 核心:相邻块增强
# 如果不是第一个块,给前一个块加个 bias,强化联系
if i > 0:
attn_scores[:, :, i-1] += self.adjacent_bias
# 如果不是最后一个块,给后一个块加个 bias
if i < num_chunks - 1:
attn_scores[:, :, i+1] += self.adjacent_bias
attn_probs = torch.nn.functional.softmax(attn_scores, dim=-1)
cross_attn_out.append(torch.matmul(attn_probs, V_chunks[:, i, :, :]))
return torch.cat(cross_attn_out, dim=1)五、 总结与展望
DCA 提供了一个极具启发性的方向:不需要通过复杂的训练去"强行修正"模型的位置编码,而是通过巧妙的"分块策略"和"距离映射",让模型始终在它最擅长的短序列范围内工作。
DCA 的核心亮点:
- 无需微调: 开箱即用,直接扩展上下文窗口。
- 兼容性强: 可以与 Flash Attention 等各种底层计算优化无缝集成。
- 逻辑清晰: 通过块内、块间、相邻块三种机制,覆盖了"局部"、"全局"和"衔接"三个维度,逻辑非常严密。
如果你正在进行长文本相关的推理任务,且受限于显存无法微调模型,DCA 绝对是一个值得尝试的"黑科技"方向。