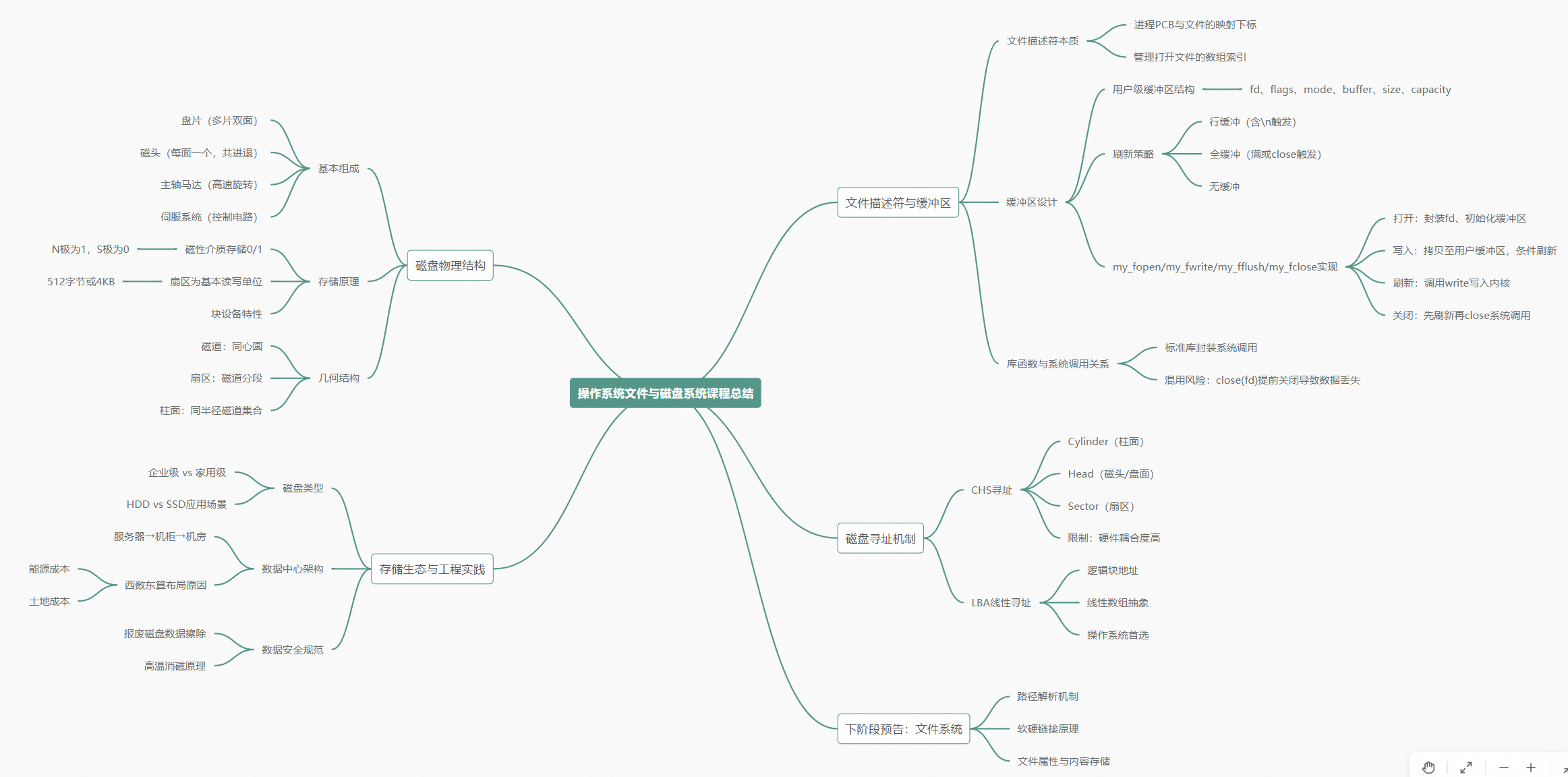
你把数据写到文件里了------但你写到哪里去了?
我们先做个实验。
打开一个文件,每隔两秒往里写一行 hello world\n,同时在另一个终端盯着这个文件看。你会看到什么?
文件内容一行一行地长出来。每两秒多一行。很正常,对吧?
现在把那个 \n 去掉。再跑一次。盯着文件看。
这次你发现了:文件一直是空的。20秒过去了,什么都没有。然后程序退出------哗,所有内容一次性全出来了。
数据没丢。它只是没在你以为的地方。
它在你写的那个库函数的肚子里。
自己动手:一个最小 libc 文件库
我们先把标准库那套东西扔一边。自己写一个。
你需要什么
源码里实际的结构体:
c
// my_stdio.h
#pragma once
typedef struct
{
int fd;
int flags;
int mode; // 刷新策略
char outbuffer[1024];
int cap;
int size;
} My_FILE;
#define NONE_CACHE 1
#define LINE_CACHE 2
#define FULL_CACHE 4
My_FILE *Myfopen(const char *pathname, const char *mode); // r w a
int Myfwrite(const char *message, int size, int num, My_FILE *fp);
void Myfflush(My_FILE *fp);
void Myfclose(My_FILE *fp);就这么点东西。标准库里那个比这个复杂得多,但骨架就是这个。
三个刷新策略是位标志------1、2、4,不是连续的 0、1、2。这样检测时用按位与 mode & LINE_CACHE 就能判断。将来可以组合多个策略。
打开文件
c
有件事得说清楚。为什么返回指针而不返回结构体?
结构体返回会发生拷贝。大结构体拷贝很贵。而且,如果在函数内部定义结构体变量,它活在栈上------函数一返回,栈帧就没了,你拿到的就是野指针。所以堆上 malloc,然后返回指针。这是 C 语言的基本功。
源码里还有一个课堂小技巧:static mode_t gmode = 0666------用静态全局变量保存默认权限。umask(0) 在打开前清零掩码,这样后面新建文件的权限就完全按 gmode 来,不会被进程的 umask 意外掩掉。open 有两参版和三参版------只有带 O_CREAT 时才需要第三个参数传权限。
搞清楚一件事:Myfopen 本质上就是在内部用不同的 flag 组合调用 open 系统调用,然后把打开得到的一切信息------文件描述符、打开选项、缓冲区------全部塞进一个 My_FILE 结构体里,然后把指针还给上层。
另外源码里还配了一个 my_string 模块------my_strlen 函数。因为既然自己封装 libc,字符串处理函数也应该自带,而不是依赖 <string.h> 的标准 strlen。
写入
现在来看写入。什么叫 "写入"?
Myfwrite 的签名是 Myfwrite(message, size, num, fp)------size 是每个元素的大小,num 是要写多少个元素,message 是要写入的数据(源码里直接用 const char * 而非 const void *,因为这个 demo 按字符串处理)。返回值------成功时返回 num,失败时返回 -1。
c
int Myfwrite(const char *message, int size, int num, My_FILE *fp)
{
if (message == NULL || fp == NULL)
return -1;
// 向 C 文件里面写,本质是向缓冲区写
int total = size * num;
if (total + fp->size > fp->cap - 1)
return -1;
// 写入------就是拷贝
memcpy(fp->outbuffer + fp->size, message, total);
fp->size += total;
fp->outbuffer[fp->size] = 0; // 保持字符串结尾
// 刷新条件检测
if (fp->outbuffer[fp->size - 1] == '\n' && (fp->mode & LINE_CACHE))
Myfflush(fp);
return num;
}所以 fwrite 90% 的情况下不是一个 I/O 函数。它是一个拷贝函数。
它做的事就是把你的数据从用户空间拷贝到 My_FILE 的 outbuffer 里。仅此而已。
然后它检查:最后那个字符是不是 \n?如果是,而且我配置的是行缓冲,那就调用 Myfflush。
没碰到 \n?那就直接返回。数据躺在缓冲区里,哪也没去。
刷新
c
void Myfflush(My_FILE *fp)
{
if (!fp)
return;
// 判断是否刷新, 这不就是刷新吗!!!
if (fp->size > 0)
{
// 系统调用
// 从用户缓冲区拷贝到内核, WB, Write Back
write(fp->fd, fp->outbuffer, fp->size);
fp->size = 0; // 清空缓冲区
// WT, Write Through
// 不仅仅要写入到内核缓冲区,必须给我写到对应的硬件上
fsync(fp->fd);
}
}注意源码里 Myfflush 不仅调了 write,还调了 fsync。也就是说这个 demo 默认用的是 write-through ------数据进内核之后立刻要求刷到磁盘。这是为了在课堂上让现象更直观。真实的 C 标准库里,fflush 只做 write,不附带 fsync。
刷新 = 把用户缓冲区里的数据拷贝到内核。 不是什么 "写到磁盘"。写到磁盘是 fsync 的事。
换个问法:去掉 "刷新"、"缓冲区"、"内核" 这些词,还能说清楚发生了什么吗?
能。你有两个水桶。一个是你手里的,一个是操作系统的。你把水倒进自己桶里(fwrite),攒够了,或者看到换行符了,就把整桶水倒进操作系统的桶里(fflush)。操作系统自己决定什么时候把水浇到地里(磁盘)。
两种写模式
把数据拷到内核就返回------这叫 write-back (回写模式)。写了就回,爽快。标准库的 fflush 只到这步。
不仅要拷到内核,还必须立刻让操作系统写到硬件上------这叫 write-through (写透模式)。用 fsync 可以做到。我们这个 demo 的 Myfflush 默认走了写透------因为演示需要让现象立即可见。
关闭文件
c
void Myfclose(My_FILE *fp)
{
if (!fp)
return;
Myfflush(fp); // 先把缓冲区里的东西全刷出去
close(fp->fd); // 再关文件描述符
// 注意:源码没有 free(fp),生产环境应该补上
}先刷新,再关闭。先刷新,再关闭。先刷新,再关闭。
顺序错了会怎样?我们马上说。
跑起来看看
接口写好了,写个测试。源码仓库里 user/main.c 是个最小样例------打开、什么也不写、直接关。课堂上实际跑的测试是这样的:
c
#include "my_stdio.h"
#include "my_string.h" // 自带的 my_strlen
#include <unistd.h>
int main() {
My_FILE *fp = Myfopen("./log.txt", "a");
if (!fp) return 1;
const char *message = "hello world\n";
while (1) {
Myfwrite(message, 1, my_strlen(message), fp);
sleep(2);
}
Myfclose(fp);
return 0;
}编译运行。同时在另一个终端里跑个监控:
bash
while :; do cat log.txt; echo "---"; sleep 1; done你看到了:log.txt 每隔两秒多一行。每条消息带着 \n,我的 Myfwrite 检测到行缓冲条件满足,自动调了 Myfflush,数据立刻刷新到内核。这就是行缓冲的行为。
现在把 \n 去掉:
c
const char *message = "hello world"; // 没有 \n重新编译运行。盯着监控。20 秒过去了------log.txt 一直是空的。程序退出(Ctrl+C 或者循环结束)------哗,所有消息一次性全部出现。
在你程序运行的 20 秒里,数据一直在 My_FILE.outbuffer 里躺着。每次 Myfwrite 都只是往缓冲区后面追加字符串,然后检查最后一个字符是不是 \n------不是,好,返回。直到 Myfclose 被调用(或者进程退出),Myfflush 才无脑把整桶水倒出去。
这就是全缓冲。
第三个实验:我在每次 Myfwrite 之后手动调 Myfflush(fp)。虽然没 \n,但每次写都强制刷新------数据又一行一行地出来了。这就相当于模拟了无缓冲模式。
C 标准库的规定是这样的:stdout 指向显示器时默认行缓冲,指向普通文件时默认全缓冲。 所以你的 printf 如果在终端里跑,碰到 \n 就刷;如果被重定向到文件,就攒满了再刷------或者等程序退出才刷。我们上面自己写的代码,Myfopen 默认把 mode 设成了 LINE_CACHE,所以对 log.txt 也是行缓冲。真实的标准库里,打开 log.txt 应该设成全缓冲------除非你手动判断目标是不是终端。
代码里的刷新策略用的是位标志(1、2、4),不是连续的 0/1/2。这样在检测时用按位与
mode & LINE_CACHE比mode == LINE_CACHE更灵活------未来可以组合多个策略。标准库里也是这么干的。
那个让我踩了一下午坑的 bug
先看一段代码:
c
// 关掉标准输出(fd=1)
close(1);
// 打开一个文件------它会被分配到 fd=1
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
// 打印
printf("hello world\n");
// 这里要不要 close(fd)?
close(fd);第一个版本:把最后的 close(fd) 注释掉。运行。log.txt 里出现了 hello world。
很正常。printf 往 stdout 写,stdout 底层是 fd=1,fd=1 现在指向 log.txt。进程退出时,C 运行时自动刷新了 stdout 的缓冲区。消息落进去了。
第二个版本:把 close(fd) 打开。运行。log.txt 是空的。
见鬼。消息去哪了?
printf 把数据写到了 stdout 对应的用户级缓冲区里。stdout 本来是行缓冲的------碰到 \n 就刷新。但你把 fd=1 关掉又打开了一个普通文件,现在 stdout 指向的是一个普通文件。C 标准库的规定是:普通文件用全缓冲。所以 \n 也不会触发刷新。
然后你调了 close(fd)------这是一个系统调用。它直接把文件描述符关掉了。
进程退出时,C 运行时想刷新 stdout 的缓冲区。它去调用 write(1, ...)。fd=1 已经关了。write 失败。缓冲区里的数据永远丢了。
close(fd) 的本质是关闭刷新通道。你把水管拔了,还指望水流过去?
怎么证明?在 close(fd) 之前加一行 fflush(stdout)。消息就出来了。
教训:不要混用系统调用和库函数。 你当了军长,就指挥师长。不要去教团长怎么放枪。C 标准库已经给你做了封装,你不清楚它的内部缓冲策略,就别直接去捅系统调用的底。
我是搞错了这个概念之后才真正理解的。之前写代码时打开文件后再也不敢
close,因为知道关了就会出问题,但不清楚为什么。现在清楚了。
所以缓冲到底解决了什么问题
三个层面。
第一,响应速度。 用户调 fwrite 时,数据拷到用户缓冲区就返回了。快。如果每次都调 write 系统调用------系统调用要切到内核态,要经过各种安全检查------那慢得多。站在 C 语言用户的角度,他把数据交到缓冲区,函数就返回了。对用户来说,I/O 响应极快。
第二,系统调用效率。 你连续调了五次 fprintf,可能只有最后一次触发了刷新------或者一次都没有,等缓冲区满了才刷。那五次用户写入变成了一次系统调用。系统调用的次数从 5 降到了 1(甚至 0)。
第三,块设备对齐。 磁盘的读写基本单位是扇区------512 字节。你写 20 个字节,操作系统也得读或写至少 512 字节。缓冲区的存在让操作系统可以把多次小写入攒成一次大写入,按扇区对齐地写到磁盘上。
你去寄快递,一架货机一次能拉一万个包裹。你非要拿一个包裹就让飞机起飞------飞一次的成本是一样的,拉一个和拉一万个花的油钱差不多。所以快递公司会把包裹攒一攒再发。
缓冲区就是操作系统和磁盘之间的那个快递集散中心。
磁盘到底是个什么东西
小时候见过光盘没有?就是那种亮闪闪的圆片,放进 VCD/DVD 机里能放电影、放歌、打游戏的那种。
光盘的光滑面------就是那面亮晶晶的、像镜子一样的面------上面存着数据。你要是把光盘刮花了,放进机器里就会卡。卡的本质是什么?数据丢了。读到刮花的地方,光头读不出数据,画面就马赛克,声音就断。
磁盘的逻辑跟光盘几乎一样。只不过光盘用激光读写,磁盘用磁头读写。
把一块机械硬盘拆开。你会看到:
- 盘片:铝合金的,表面极其光滑,正反两面都能存数据。一个硬盘里不止一片,可能三片六面。
- 磁头 :每个盘面一个磁头。所有磁头连在同一个传动臂上------共进退。一个磁头移动到某个位置,所有磁头都在相同的位置。
- 主轴马达:让盘片高速旋转。低端盘一秒钟 7000 到 9000 转,高端盘能到一万五甚至两三万转------你一眨眼的功夫,盘片已经转了几百圈。
- 伺服系统:一块电路板,接收指令,控制磁头怎么摆、盘片转多快。磁盘背面就是这块电路板,上面有针脚------SATA 或 IDE 或 SCSI 接口------通过总线直接连到主板上,和内存、CPU 通上话。
磁头和盘片不挨着。它们之间悬浮着一层空气------距离大概相当于一架波音 747 离地一米在飞行。所以磁盘内部必须是真空无尘的。一颗灰尘进去了,高速旋转的盘片撞上它,产生高温,数据就完了。
磁盘是计算机里唯一一个真正的机械设备。 CPU 是电子的,内存是电子的,总线是电子的。磁盘------有马达,有传动臂,有旋转的盘片。物理上真在动的东西。
因为它是机械设备,所以它慢。但它便宜。几百块钱能买 1TB 的磁盘,同样的钱只够买几 GB 的内存条。所以服务器领域,磁盘仍然是主力。
磁盘怎么存 0 和 1
磁盘表面看起来光滑,在高倍显微镜下不是。它是密密麻麻的小磁铁。
每个小磁铁有南极和北极。制造商规定:北极朝上代表 1,南极朝上代表 0。
磁头里有线圈。通电产生磁场,磁场改变小磁铁的南北极方向。改变一个方向,就是向磁盘的一个位置写了一个 0 或 1。
所以磁盘叫 "磁" 盘------因为它靠磁极方向来记录数据。把一块磁铁放在那里,放一年,放十年,它还有磁性。这就是永久存储的原理。
注意:同样的 0 和 1,在不同硬件上的物理含义完全不一样。
- 磁盘上:南北极方向
- 内存里:电容的充放电状态(高低电平)
- 光纤里:光信号的有无
- 无线电里:波峰波谷的疏密
但到了软件层面,全都是 0 和 1。底层差异被硬件和驱动给屏蔽掉了。你把一个文件从硬盘拷到内存,磁盘上的南北极被解释成电信号,内存按自己的方式重新表示这些 0 和 1。上层不用管这些。
磁盘的物理结构:磁道、扇区、柱面
盘片一面拆开看,不是光滑的------它由无数个同心圆组成。
每个同心圆叫一个磁道。跟地球的赤道一样,一圈一圈的。
一个磁道不是连续的。它被切成一截一截的小段,每一段叫一个扇区。扇区与扇区之间有间隙隔开。
为什么叫 "扇区"?因为外圈半径大,内圈半径小,切出来的每一段看起来像扇子------外宽内窄。美国人叫它 sector,没什么文化。中国人一看,这玩意儿像扇子,就翻译成 "扇区"。浪漫。
扇区是磁盘读写的基本单位------512 字节。 你要读 1 个字节?磁盘给你读 512 个,你自己从那 512 个里挑你要的那 1 个。你要写 1 个字节?磁盘写 512 个。这就是为什么磁盘叫 "块设备"------一次最少 512 字节。显示器你打一个字符就显示一个字符,所以显示器叫 "字符设备"。
不过你可能已经想到了一个问题:外圈的扇区物理面积大,内圈的扇区物理面积小------凭什么都存 512 字节?
答案是:内外圈扇区的比特密度不同。内圈数据挤得更紧,外圈数据更疏松。这样每个扇区的大小就被拉平了------都是 512 字节。在现代磁盘里,这个密度的控制更精细,甚至外圈一个扇区的物理位置能塞下三个内圈扇区的数据量,但逻辑上大家都统一成 512 字节(或 4KB)。底层固件帮你做了转换,上层不用管。
也有磁盘的扇区大小是 4KB 的,叫 4K native。但最通用的还是 512 字节。
盘片不止一面,也不止一片。三片六面的硬盘,就有六个磁头。所有磁头连在同一个传动臂上,共进退。当传动臂把磁头推到某个半径位置时,所有磁头都在各自盘面的相同半径处。
相同半径处的所有磁道(六个面各一条,共六条),在逻辑上聚在一起,叫一个柱面。
为什么单独给个名字?因为这六条磁道是同时被访问的------磁头共进退,你没法让一号磁头在读外圈的同时让二号磁头读内圈。它们在物理上就是一体的。所以寻址时我们不太说 "磁道",我们说 "柱面"。
CHS 寻址:三个数字定位一个扇区
要找到磁盘上的一个扇区,你需要三个参数:
- C(Cylinder,柱面):传动臂把磁头推到哪个柱面
- H(Head,磁头):选哪个磁头------也就是选哪一面
- S(Sector,扇区):等盘片转到哪个扇区
真实顺序是 C → H → S。磁头先摆动到目标柱面(寻道),然后选定磁头,然后盘片旋转把目标扇区送到磁头正下方。
磁盘的两种机械运动,对应了两步寻址:
- 磁头左右摆动 → 寻道(找柱面)
- 盘片高速旋转 → 寻扇区(等目标扇区转过来)
磁盘就是一个三维数组。 C 是第一维,H 是第二维,S 是第三维。三个下标就能定位任意一个元素------任意一个扇区。
每个维度都有自己的编号。磁头从 0 开始,柱面从 0 开始(外圈是 0 号),扇区从 1 开始(没有 0 号扇区)。
整个磁盘的第一个扇区叫 (0, 0, 1)------零号柱面、零号磁头、一号扇区。
为什么操作系统不直接用 CHS
老式磁盘就是用 CHS 的。操作系统得知道磁盘有多少个磁头、多少柱面、每柱面多少扇区。用 8 位存磁头号,10 位存柱面号,6 位存扇区号------总共 24 位,能寻址的磁盘容量才 8GB 左右。
更大的问题是:操作系统和硬件耦合太紧了。如果你的存储设备从机械硬盘换成了 SSD 或者 U 盘------它们的物理结构跟磁盘完全不一样,哪来的磁头和柱面?操作系统就得改代码。
操作系统不愿意干这个。 软件不应该因为硬件变了就得重写。
所以磁盘内部自己做了抽象。磁盘的固件把 CHS 三个数字映射成一个线性的数字------扇区的数组下标。这个线性地址叫 LBA(Logical Block Address,逻辑块地址)。
操作系统只需要知道两个东西:磁盘总共有多少扇区,每个扇区是 512 字节。有了总扇区数,就有了数组的范围。每个扇区有一个下标,从 0 开始。
磁盘对操作系统来说,就是一个巨大的扇区数组。
顺手看一眼你自己的磁盘:
bash
sudo fdisk -l输出里你能看到磁盘名称(物理服务器上一般是 sda、sdb,云服务器上虚拟盘叫 vda)、总扇区数、扇区大小(512 字节)、分区信息。一块 42GB 的云盘,fdisk 告诉你它有多少扇区,乘上 512 就是总容量。倒着算也行:每磁道多少扇区 × 每面多少磁道 × 多少面 × 512。
磁带类比:把圆的拉成直的
小时候玩过磁带没有?就是那个左边一个圈右边一个圈、中间拉出一条塑料带子的东西。
磁带的本质是什么?是一长条塑料带子,上面涂了磁性材料。它被卷起来是圆的,但你把它拉出来------它就是一长条线。
磁盘的磁道是一圈一圈的同心圆。但你把其中一圈剪开拉直------它不也就是一长条吗?每一截是一个扇区,连在一起就是连续的扇区序列。
一面盘片上有很多个同心磁道。把每个磁道都剪开拉直,再按顺序拼起来,你就得到了一个一维的扇区数组。每个扇区对应一个下标。
一面是一个一维数组。整个磁盘有很多面------很多个一维数组摞在一起,就是一个二维数组。
但别忘了柱面。所有面在相同半径处的磁道构成柱面。柱面有很多个------很多个二维数组摞在一起,就是三维数组。
磁盘是一个三维数组。三个下标就是 CHS。一个下标就是 LBA。
从 LBA 转换到 CHS 的过程就是除法取模:
C = LBA / (每柱面扇区数)
H = (LBA % 每柱面扇区数) / 每磁道扇区数
S = (LBA % 每磁道扇区数) + 1 // 扇区从 1 开始磁盘的固件会做这个转换。操作系统只跟 LBA 打交道。
一段生态:从磁盘到机房
磁盘制造商世界范围内主要就那几家------西数、希捷、东芝。磁盘的制造工艺极其精密,需要无尘环境,而且磁头悬浮的技术精度极高。21 世纪初,这种制造能力基本属于西方国家。现在国产固态硬盘已经很好了,但机械硬盘还是那几家为主。
一块企业级磁盘,4TB、8TB,造价高的四五千,便宜的两三千。家用的一般几百到一两千。
一块盘装进服务器。一台服务器就是一个扁平的铁盒子------把它想象成你的台式机机箱,但没有显示器,没有键盘。服务器不需要这些------它通过网络跟你通信。背面全是网线插口(RJ45),插着蓝色的双绞线。内部有 24 个抽屉式卡槽,每个卡槽塞一块盘。24 块盘 × 4TB = 一台服务器能存将近 100TB。而你笔记本里最多塞一两块盘。
一个机柜塞 8 到 10 台服务器。240 块盘。按 4TB 算,将近 1PB。
很多个机柜组成一个机房。机房里除了服务器本身,还有空调(几百台机器一起散热,没空调直接就烧了)、防震设计(磁盘震动会让磁头撞上盘片)、灯光照明,还有------地皮。建一个机房,技术难度高,成本极高。没有几个亿别想。
所以中小企业不可能自建机房。这就催生了云服务------阿里、腾讯、华为建好机房,把算力和存储能力打包卖给企业。
机房往哪建?离能源近、地价便宜的地方。西部------内蒙古的风力发电,贵州的水电,新疆的太阳能。数据通过光纤传输比煤炭运输容易得多。西电东输,西数东算。
还有一件事。磁盘报废时,上面的数据必须彻底擦除。你删文件只是删了文件系统的记录,数据还在磁盘上。要把数据真正清除------最简单的物理方式是什么?
扔进火里。 磁盘靠磁性记录数据,高温可以退磁。以前销毁硬盘确实这么干。但现在有更优雅的方式:磁盘固件支持安全擦除指令。操作系统发一条命令,磁盘自己把所有扇区写 0 或写随机数,然后再返厂。
互联网公司和磁盘厂商是战略合作伙伴关系。互联网公司把故障盘的数据擦干净后返给厂商分析,厂商根据故障率改进工艺,互联网公司根据各厂商的故障率决定下一批采购谁的多、谁的少。
所以一台计算机背后,是产业链,是供应链。你的笔记本里有 CPU(英特尔或 AMD 或 ARM)、内存条(国产或国外)、主板、网卡、显卡、铝合金外壳、甚至一颗螺丝------每一个零件背后都是一家工厂、一群工人、一批工程师。计算机行业不是一个 "高科技" 的名词,它是一大片真实的制造业和就业。我们得用产业的视角看它。
最后回到文件系统。一个系统里有十万个文件,内存里被打开的也就几百几千个。那剩下的几十万个没被打开的文件呢?它们在磁盘上怎么组织?文件的属性和内容放在磁盘的什么位置?哪些文件存在、哪些被删了?怎么快速找到某个路径对应的文件?
这些------就是文件系统要回答的问题。我们已经搞清楚了磁盘的物理结构和寻址方式,下一步,就是在上面搭逻辑结构。
下节课预览:分区和格式化到底是在干什么?路径解析是怎么回事?Linux 的目录为什么是树形结构------这个 "树" 在磁盘上到底长什么样?以及面试常考题------软链接和硬链接。顺便说一下,链接文件也是文件类型的一种:Linux 里普通文件是 - 开头,目录是 d,链接是 l,块设备是 b,字符设备是 c。今天讲清楚了块设备和字符设备的区别,链接文件的事,等下节课讲完文件系统才能真正说清楚。
回到最开始的问题
你往文件里写数据。fprintf、fwrite、fputs------这些函数在底层做的事都一样:把数据拷贝到 FILE 结构体的缓冲区里,然后检查刷新条件。条件满足了就调 write 系统调用,把用户缓冲区数据搬到内核缓冲区。操作系统在它认为合适的时候把内核缓冲区数据写到磁盘。
所以 "我写完了" 这句话有三个不同的含义:
- 数据到了用户缓冲区 ------你的
fprintf返回了 - 数据到了内核缓冲区 ------
write系统调用返回了 - 数据到了磁盘上 ------
fsync返回了
平时你写代码,"写完" 通常指第 1 种。你多数时候不用关心第 2 和第 3 种。但当你遇到 "关了文件描述符数据就丢了" 这种 bug 时------你就知道是卡在 1 和 2 之间了。
就这么回事。
不把话说完
今天写的这个 my_stdio 库,跟 glibc 的标准实现比差得远。标准库里考虑了线程安全、各种边界条件、输入缓冲区、编码转换......一大堆我们没碰的东西。
但它回答了一个问题:fwrite 底层到底在干什么。 不是 "它调用 write 系统调用" 这种只有名字没有理解的回答。是具体的:数据走了哪条路径,什么时候触发搬运,为什么有时候写进去了有时候没写进去。
磁盘也一样。知道它叫 "块设备" 是一回事。知道它的盘片在转、磁头在摆、数据存在磁极的南北方向上,扇区是 512 字节的基本单元,CHS 是三个维度的下标------这是另一回事。
命名不等于理解。知道 "扇区" 这个词不等于理解为什么磁盘读写最小单位是 512 字节。知道 "缓冲区" 这个词不等于理解为什么
fwrite返回了但数据还没到磁盘。
到目前为止,基础 I/O 这块我们搞定了这些事:
- C 语言的系统调用和库函数接口 ------
open/close/read/write和fopen/fclose/fread/fwrite,它们之间的关系和区别 - 文件描述符的本质------进程 PCB 和被打开文件之间的映射表的数组下标
- 重定向的核心原理------关掉一个 fd 再打开新文件,新文件自动占据那个 fd 位置
- fd、系统调用、库函数的三角关系------以及为什么不能混用
- 缓冲区的三层层级 ------用户级(C 语言
FILE里的 buffer)、语言级(printf/fwrite自带的缓冲策略)、内核级(操作系统的 page cache) - 自己封装了一个简单的文件库------能看到缓冲行为是怎么工作的
所有这些,回答的是一个核心问题:一个文件被打开了,进程怎么操作它。
但系统里有十万个文件,被打开的也就几百几千个。剩下的呢?它们躺在磁盘上,从来没被 open 过。文件系统要回答的是另一组问题:它们在哪、占哪些扇区、属性和内容分别放哪、怎么快速找到、怎么删除、目录的树形结构在磁盘上到底是什么样子。
下节课------把磁盘的这个三维数组模型再精化,然后开始往上面搭文件系统。分区、格式化、路径解析、软硬链接,全部排上。