原作者:Linux教程
原文地址:从内核视角,看Linux文件读写过程
今天咱们来聊一个「看似简单、实则硬核」的------Linux 文件读写全过程。
我们每天敲 cat file.txt、用 fread() 读文件、或者 fwrite() 写日志,有没有思考过为什么读写这么快?为什么改了文件不立刻落盘?
很多朋友觉得读写过程难搞懂,什么"系统调用"、"虚拟文件系统"、"页缓存"听着就头大,其实只要顺着"用户操作→内核响应→硬件执行"的逻辑拆解,就能轻松搞懂文件读写的底层原理。
今天我们从内核文件系统的角度,拆解文件读写过程,搞懂"我们写的内容,到底是怎么存到磁盘里的"。
Part1 程序为啥不能直接操作文件?
我们先复盘下操作系统的核心作用------"保护硬件"和"给应用程序提供接口"。
电脑的硬件资源(磁盘、内存、CPU)是有限的,要是每个应用程序都能直接操作硬件,很容易出现冲突(比如两个程序同时写一个文件,会导致内容错乱)。
为了防止普通程序搞崩系统,CPU 设计了两种运行模式::
- 用户模式:应用程序(比如记事本、浏览器)运行的模式,权限很低,不能直接操作硬件(比如读磁盘、写磁盘);
- 内核模式:操作系统内核运行的模式,权限最高,能直接操作所有硬件,处理所有危险操作(比如I/O读写、修改内存地址)。
系统调用(syscall) 就是连接两者的唯一合法通道。
进程的虚拟地址空间划分为「用户空间」和「内核空间」。用户空间存的是我们写的应用程序代码(比如记事本的代码)和数据(比如我们编辑的文本),内核空间存的是操作系统内核的代码和数据。两者都是"虚拟地址",最终都会映射到实际的物理内存(相当于"虚拟门牌号"对应"实际住址")。
而我们今天的核心------文件读写,就是最典型的"系统调用场景":应用程序(用户态)发起读写请求,内核(内核态)帮忙完成实际的磁盘操作,再把结果返回给应用程序。
Part2 虚拟文件系统(VFS)
Linux 支持 NTFS、ext4、FAT、Btrfs 等各种文件系统。假如每个文件系统都长得不一样,用户态程序岂不是要写一堆适配代码?------这显然不现实。
于是Linux内核搞了个"中间层"------虚拟文件系统(VFS),它的作用就像"翻译官":一边给应用程序提供"统一的文件操作接口"(不管你是哪种文件系统,应用程序都用一套方法操作),另一边对接不同的底层文件系统,把应用程序的请求"翻译"成底层文件系统能听懂的指令。
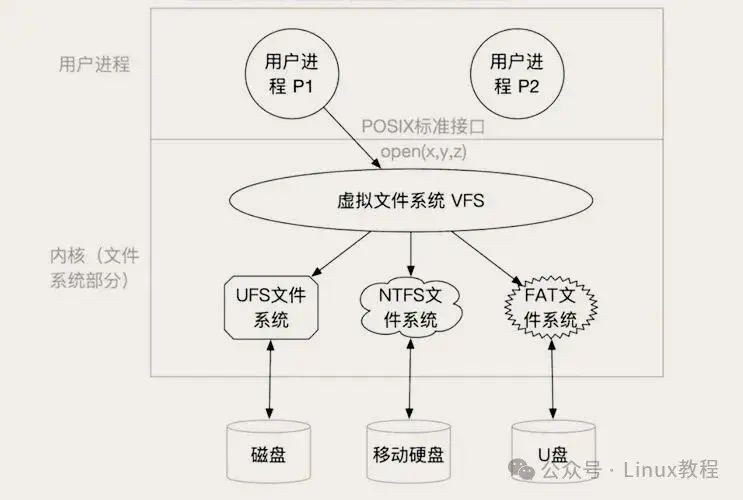
简单说,应用程序操作文件时,不用管底层是NTFS还是ext4,只需要找VFS;VFS再根据底层文件系统的类型,调用对应的逻辑完成操作------这就是"统一文件系统视图"的核心。
它在用户进程和具体文件系统之间加了一层抽象层 ,给所有人提供一套统一的接口(open/read/write/mmap 等),底层再自动适配不同的文件系统。
VFS 主要由以下6个核心模块组成(超级实用,建议记下来):
- 超级块(super_block):相当于某个文件系统的"身份证+说明书",记录着这个文件系统的所有核心信息(比如文件系统大小、类型、挂载点),是VFS操作该文件系统的"基础参考"。任何对文件系统的元数据修改(比如创建文件、删除文件),都会同步更新超级块,而且超级块会常驻内存,避免频繁读磁盘。
- 目录项模块:负责"解析文件路径"。比如我们要找 /home/foo/hello.txt,目录项模块就会从根目录(/)开始,一步步解析"home""foo"这两个目录,最后定位到"hello.txt"这个文件。它的内部是树形结构,就像我们电脑里的"文件夹层级",操作系统找文件,本质就是遍历这个目录树。
- inode模块:文件的"唯一身份证",一个文件对应一个inode。它记录着文件的核心信息(比如文件大小、创建时间、权限),最关键的是------通过inode能找到文件在磁盘扇区的具体位置(相当于"文件的实际住址")。另外,inode还能关联到后面要讲的address_space模块,快速判断文件数据是否已经缓存到内存。
- 打开文件列表模块:记录内核中所有已经打开的文件。我们用"打开文件"操作时,内核会创建一个"文件句柄"(struct file结构体),这个结构体就存在这个列表里,记录着文件的打开状态(比如只读、可写)、当前读写位置等参数。
- file_operations模块:相当于"文件操作工具箱",里面存着所有能对文件执行的系统调用函数(比如open、read、write、close)。每个打开的文件(打开文件列表里的一个项),都会关联这个模块,从而实现对文件的各种操作。
- address_space模块:VFS和页缓存的"桥梁",记录着一个文件在内存中已经缓存的物理页。简单说,它就是"文件数据在内存中的索引",后面讲页缓存时会重点说,这里先记住:它关联着文件(inode)和内存缓存(页)。
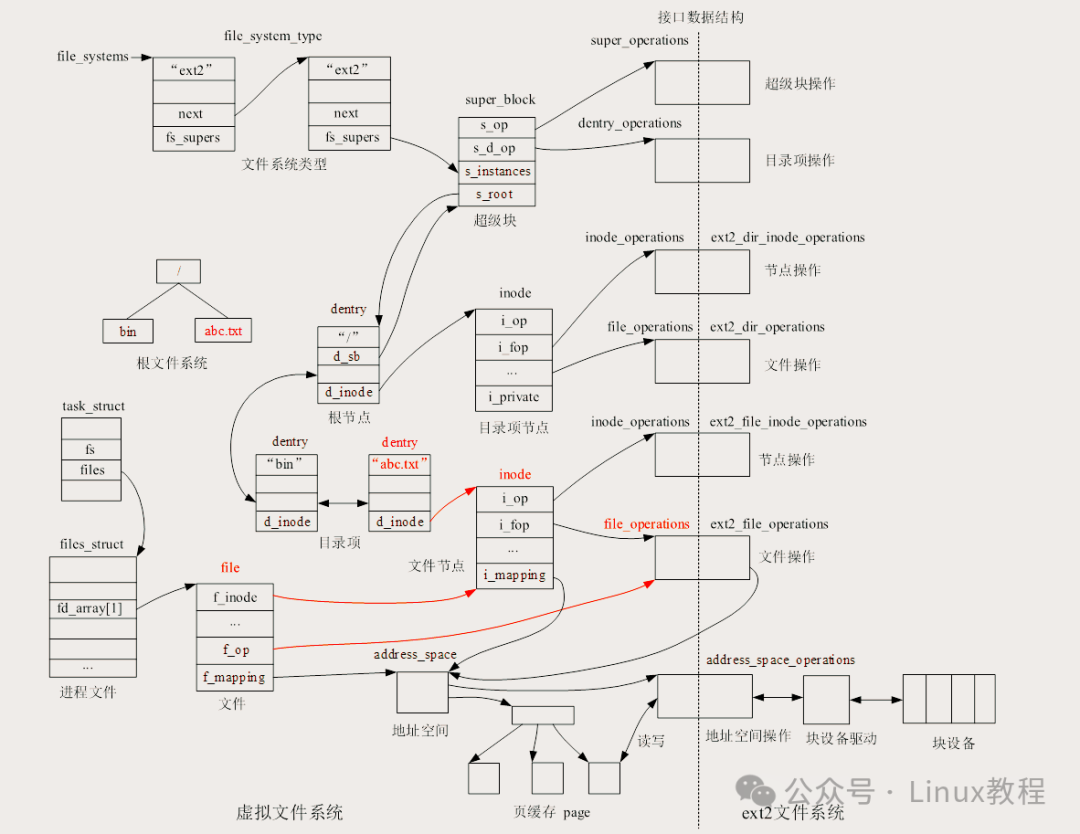
这些模块之间通过各种指针互相链接,形成一张"关系网"。进程通过文件描述符(fd)找到 struct file,再顺着指针找到 dentry → inode → address_space,最终完成操作。
我们的应用程序(进程),其实是通过"文件描述符"和VFS打交道的:
- 每个进程都有一个"进程描述符"(task_struct),里面有一个指针指向"文件描述符表"(files_struct);
- 文件描述符表,本质是一个"指针列表",每个指针都指向VFS打开文件列表里的一个文件(file结构体)------我们平时说的"文件描述符0(标准输入)、1(标准输出)、2(标准错误)",就是这个列表的索引;
- 进程要操作文件时,只需要通过文件描述符,找到对应的file结构体,再调用file_operations里的函数,就能完成读写操作。
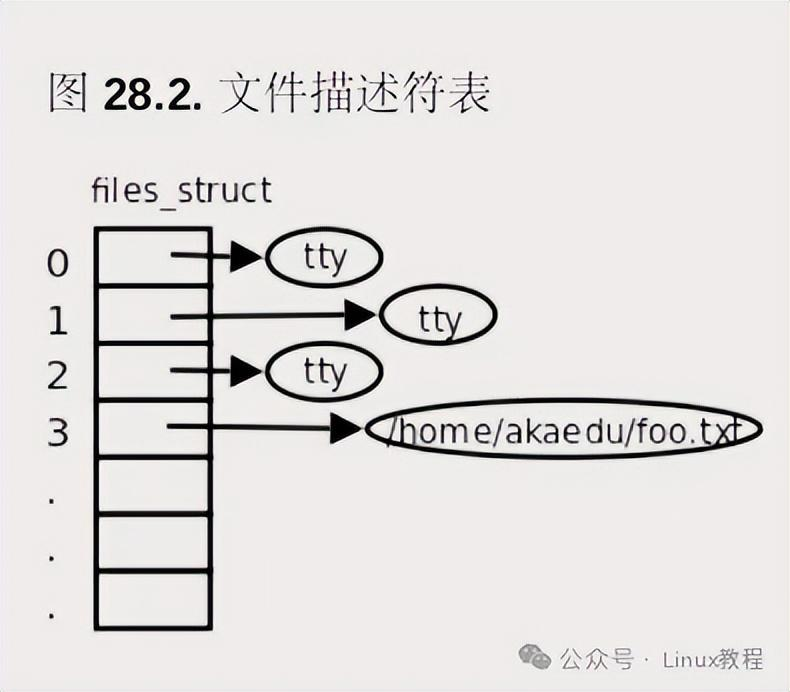
这儿再唠两个关键细节:① 多个进程可以共享同一个打开的文件(比如父进程和子进程),它们的文件描述符会指向同一个file结构体;② 一个进程可以多次打开同一个文件,生成多个文件描述符,每个描述符对应不同的file结构体,但这些结构体最终都会指向同一个inode(因为是同一个文件,inode唯一)。
Part3 提速关键:I/O缓冲区
磁盘的读写速度,比内存慢好几个数量级(内存读写毫秒级,磁盘读写秒级)。如果每次读写都直接访问磁盘,程序早就卡死了。------这就是"缓冲区"存在的意义,把经常用的数据提前缓存在内存里。
注意两个容易混淆的概念:
- Cache(高速缓存):CPU 和内存之间的缓冲,加速"读";
- Buffer(I/O 缓冲):内存和磁盘之间的缓冲,既缓冲"读",也缓冲"写"。
Linux 2.6 之后,Page Cache(页缓存) 彻底取代了老的 Buffer Cache,成为主流。它以**内存页(4KB)**为单位管理,比老的"块"粒度更细、性能更高:
- Buffer Cache(块缓存):以"文件系统块"为单位缓存(比如ext4的块大小通常是4KB),主要用于"块设备"的I/O操作(比如直接读写磁盘块);
- Page Cache(页缓存):以"内存页"为单位缓存(Linux中内存页大小通常是4KB,和块大小一致,但逻辑上更高层),主要用于"文件"的I/O操作,是目前Linux内核中最核心的缓存机制。
对进程来说,不管是Buffer Cache还是Page Cache,都是"透明的"------进程不需要关心数据是存在哪个缓存里,只需要发起读写请求,内核会自动处理缓存逻辑。
Part4 核心缓存:Page Cache
前面提到,Page Cache(页缓存) 是文件和内存之间的缓冲区。核心逻辑是通过3个关键结构,将"文件"映射到"内存页":
- struct page:表示一个物理内存页,相当于"内存中的一个存储单元"。它有3个关键参数:① flags(标志位):记录这个页是否被修改(脏页)、是否正在写回磁盘;② mapping:指向address_space,说明这个页是某个文件的缓存页;③ index:记录这个页在文件中的偏移量(相当于"这个页对应文件的哪一部分内容")。
- inode:前面说过,inode记录着文件的所有块号,通过文件的读写偏移量,就能快速定位到对应的磁盘块号和扇区号;同时,inode还关联着address_space,能快速找到文件的缓存页。
- address_space:作为"桥梁",一边关联inode(找文件),一边关联Page Cache的基数树(找缓存页)。通过它,内核能快速实现"文件偏移量→内存页→磁盘块"的映射。
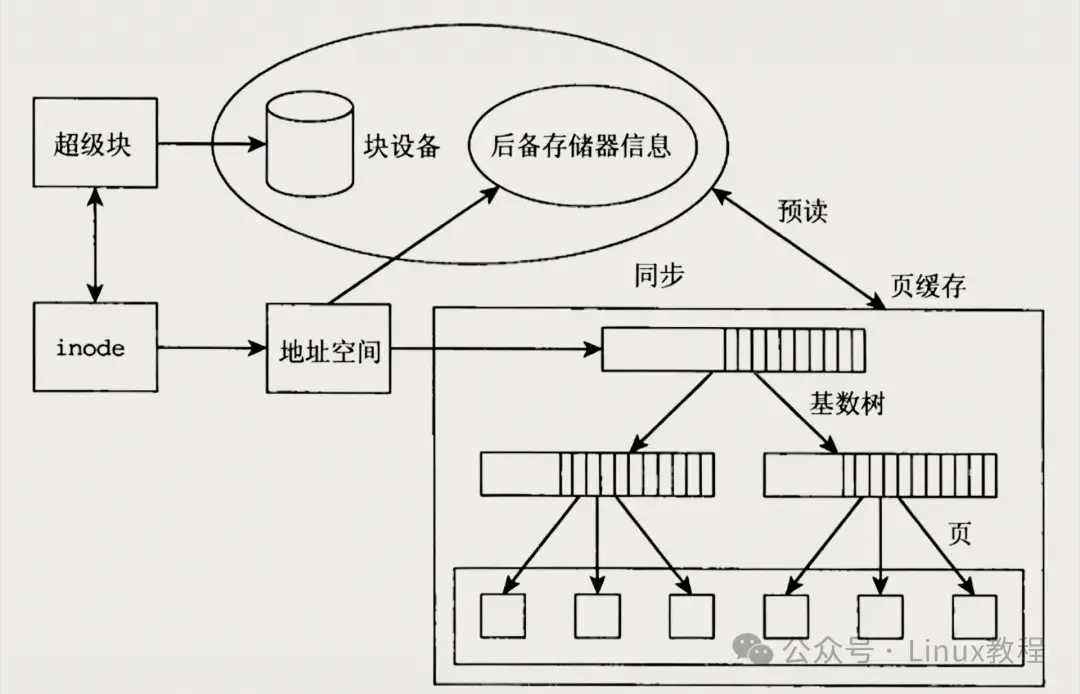
一个文件对应一个 inode → 一个 address_space → 一棵页缓存树。通过 offset → 页偏移 → 文件块号 → 磁盘扇区 这条路径,内核能极快定位数据在不在内存。
Part5 文件读写的完整流程拆解
我们点击"打开文件""保存文件"时,内核到底在做什么?
分"读文件"和"写文件"两步。
5.1、读文件流程
以"打开hello.txt"为例:
- 应用程序(比如记事本)调用库函数(比如fopen),向内核发起"读文件"请求;
- 内核通过"文件描述符",定位到VFS中对应的"打开文件列表项"(file结构体);
- 调用file_operations里的read()函数,开始处理读请求;
- read()函数通过file结构体,找到对应的目录项,解析文件路径,最终找到文件的inode;
- 根据我们要读取的"文件偏移量"(比如从第0个字节开始读),计算出需要读取的内存页;
- 通过inode找到对应的address_space,访问Page Cache的基数树,查找对应的缓存页:
- 【缓存命中】:如果缓存页存在,直接从内存中读取数据,返回给应用程序,读操作结束(这就是第二次打开文件更快的原因);
- 【缓存缺失】:如果缓存页不存在,内核会产生"页缺失异常",创建一个新的缓存页,然后通过inode找到文件对应页的磁盘地址,从磁盘读取数据,填充到缓存页;之后再重新查找缓存页(此时命中),返回数据。
- 应用程序拿到数据,显示在界面上,读文件流程完成。
5.2、写文件流程
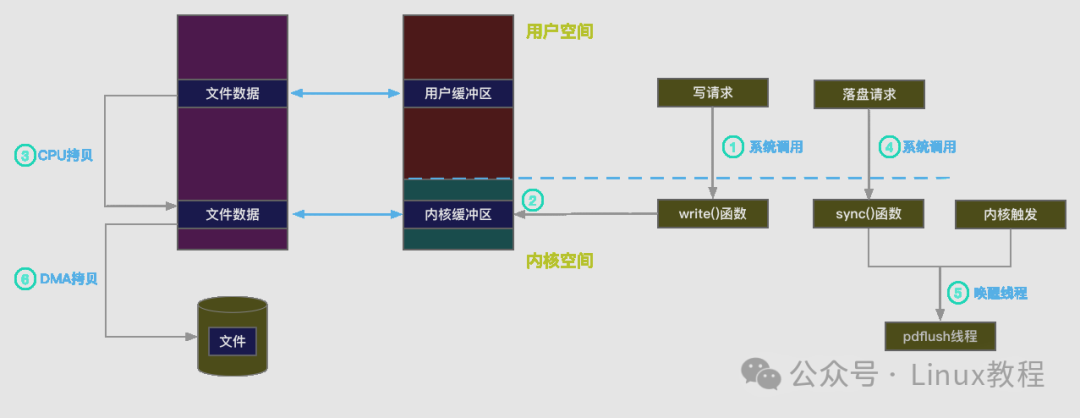
以"修改hello.txt并保存"为例,写文件的前5步,和读文件完全一致,重点差异在"缓存处理"和"脏页写回":
- 前5步(发起请求→定位file结构体→调用write()→找到inode→计算偏移量),和读文件一致;
- 通过address_space查找对应的缓存页:
- 【缓存命中】:直接将修改后的内容,写入到缓存页中,写操作暂时结束(注意:此时数据只在内存缓存中,还没写到磁盘);
- 【缓存缺失】:产生页缺失异常,创建缓存页,从磁盘读取对应页的数据填充缓存,然后再将修改后的内容写入缓存页。
- 被修改的缓存页,会被标记为"脏页"(相当于"待写入磁盘的临时数据");
- 脏页需要写回磁盘,有两种方式:
- 手动触发:调用sync()或fsync()系统调用,强制将脏页写回磁盘(比如我们手动点击"保存",本质就是触发了fsync());
- 自动触发:内核的pdflush进程(或类似进程)会定时扫描脏页,将其写回磁盘,避免缓存占满内存。
- 注意:脏页在写回磁盘期间,会被"上锁",其他写请求会被阻塞,直到写回完成、锁释放------这就是为什么有时候保存文件后,立刻拔掉U盘会提示"文件正在使用"。
看到这儿,想必你已经明白文件读写的核心逻辑,简单来说其实就是"三层联动":
-
应用程序(用户态)发起请求,通过系统调用"求助"内核;
-
内核通过VFS,统一处理不同文件系统的请求,找到文件对应的inode和缓存;
-
通过Page Cache缓存数据,减少磁盘I/O,提升速度,最终完成读写操作。