一、整体框架
1.1、字节Deer-Flow架构
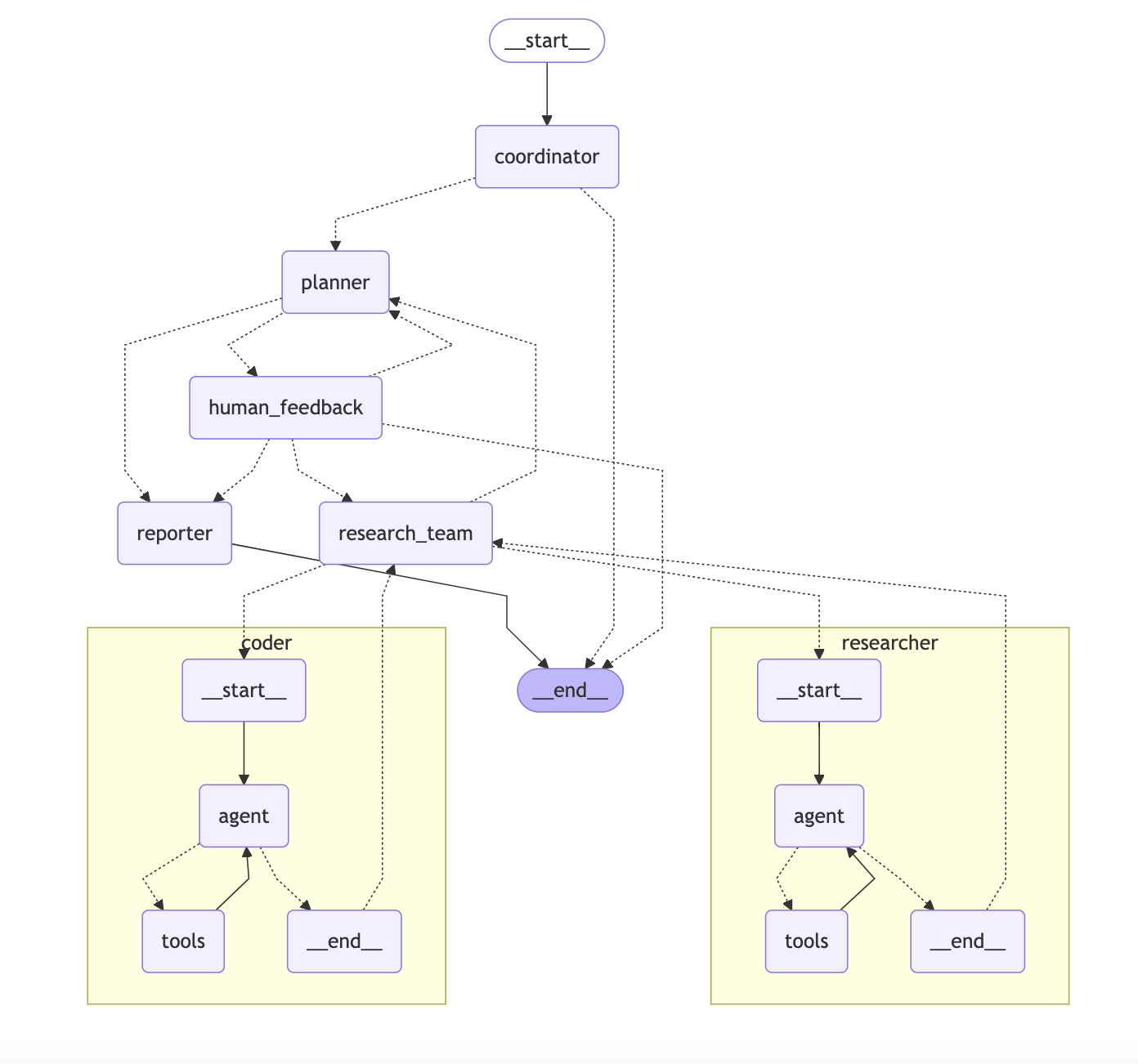
DeerFlow 采用模块化多智能体架构,基于 LangGraph 框架构建了灵活的状态驱动工作流。各组件通过定义清晰的消息传递系统实现协同,形成从用户输入到最终报告的完整闭环。系统核心架构包含五大组件:Coordinator(协调器)、Planner(规划器)、Research Team(研究团队)、Reporter(报告生成器)、Analyst(结果分析器)以及 Human-in-the-loop(人工介入层),共同构成了自动化研究与代码分析的完整解决方案。
核心工作流遵循 "规划 - 研究 - 处理 - 分析 - 报告" 的流水线模式:
- 协调智能体 :Coordinator意图澄清与分发
- 规划智能体 :Planner 创建研究计划
- 研究智能体 :Researcher 调用工具并分析
- 代码智能体 :Coder 分析数据 / 代码
- 分析智能体: Analyst分析验证研究结果
- 报告智能体 :Reporter 综合研究结果
- 后处理 :可选的播客 / PPT 生成(扩展功能)
https://github.com/bytedance/deer-flow
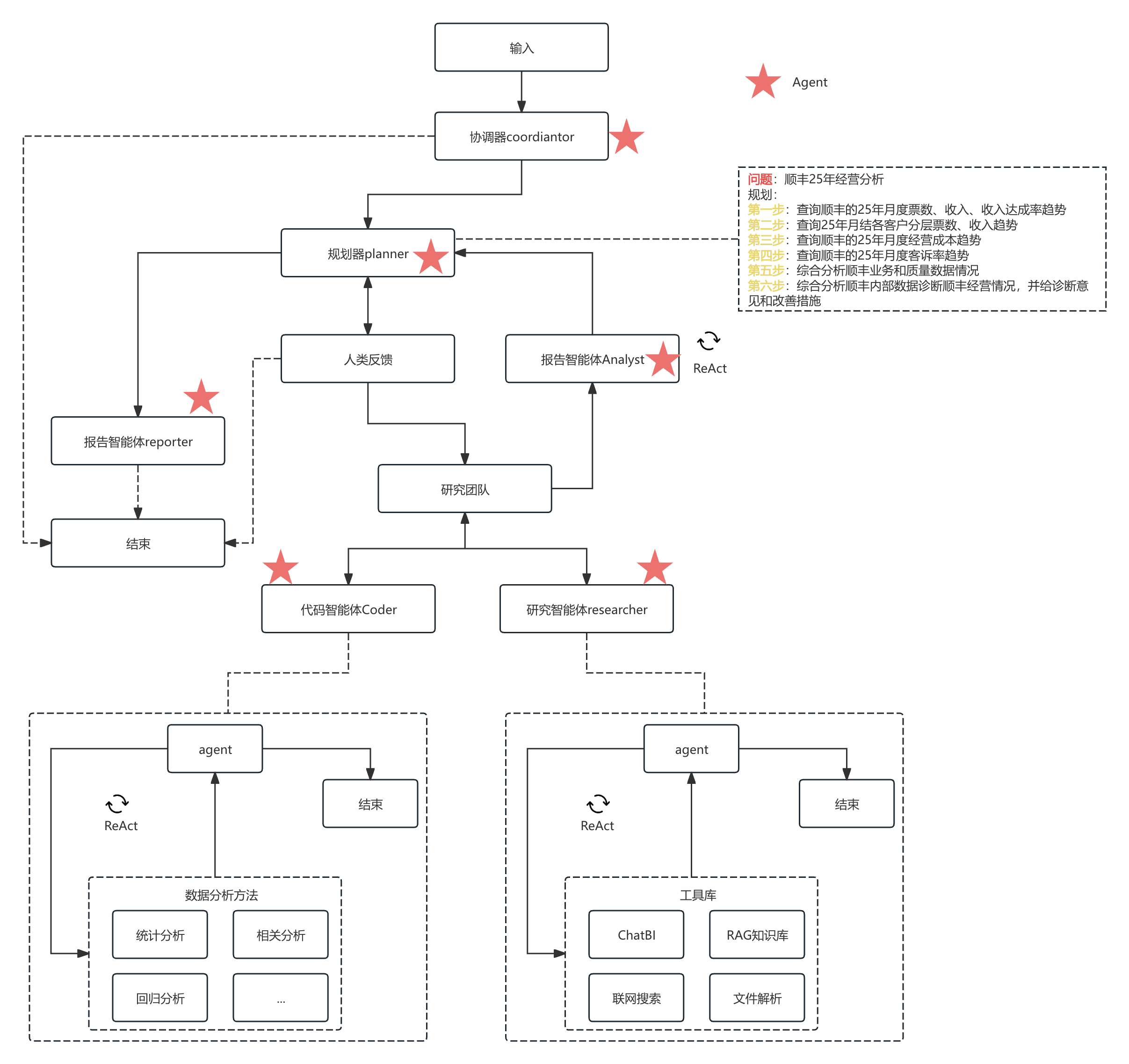
1.2、数据分析架构
二、 端到端Agent RL
2.1、训练架构
阿里Agent RL完整训练架构

数据分析Agent RL训练整体架构(省略PT和CPT)
Tongyi-DeepResearch-30B-A3B 原生内置Agentic能力,无需进行Agentic CPT,可直接使用业务数据完成后阶段微调与对齐。
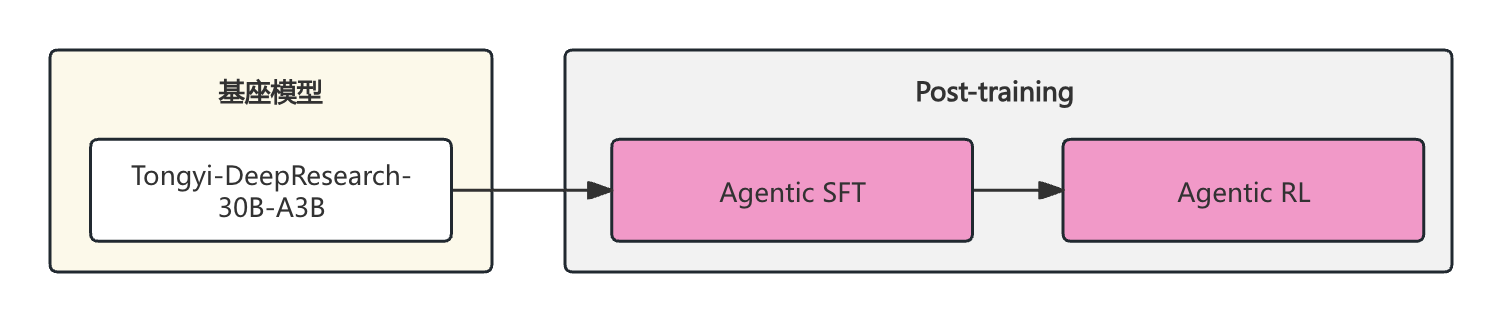
2.1.1、SFT训练架构图
混合训练范式,结合ReAct模式和上下文管理模式
上下文管理模式:加强了Agent的状态分析和策略决策能力,因为其要求Agent将复杂的观察结果综合成连贯的总结,同时保持当前任务轨迹,比起单纯的ReAct模式,能够实现更加深思熟虑的推理表现
2.1.1.1 上下文管理模式
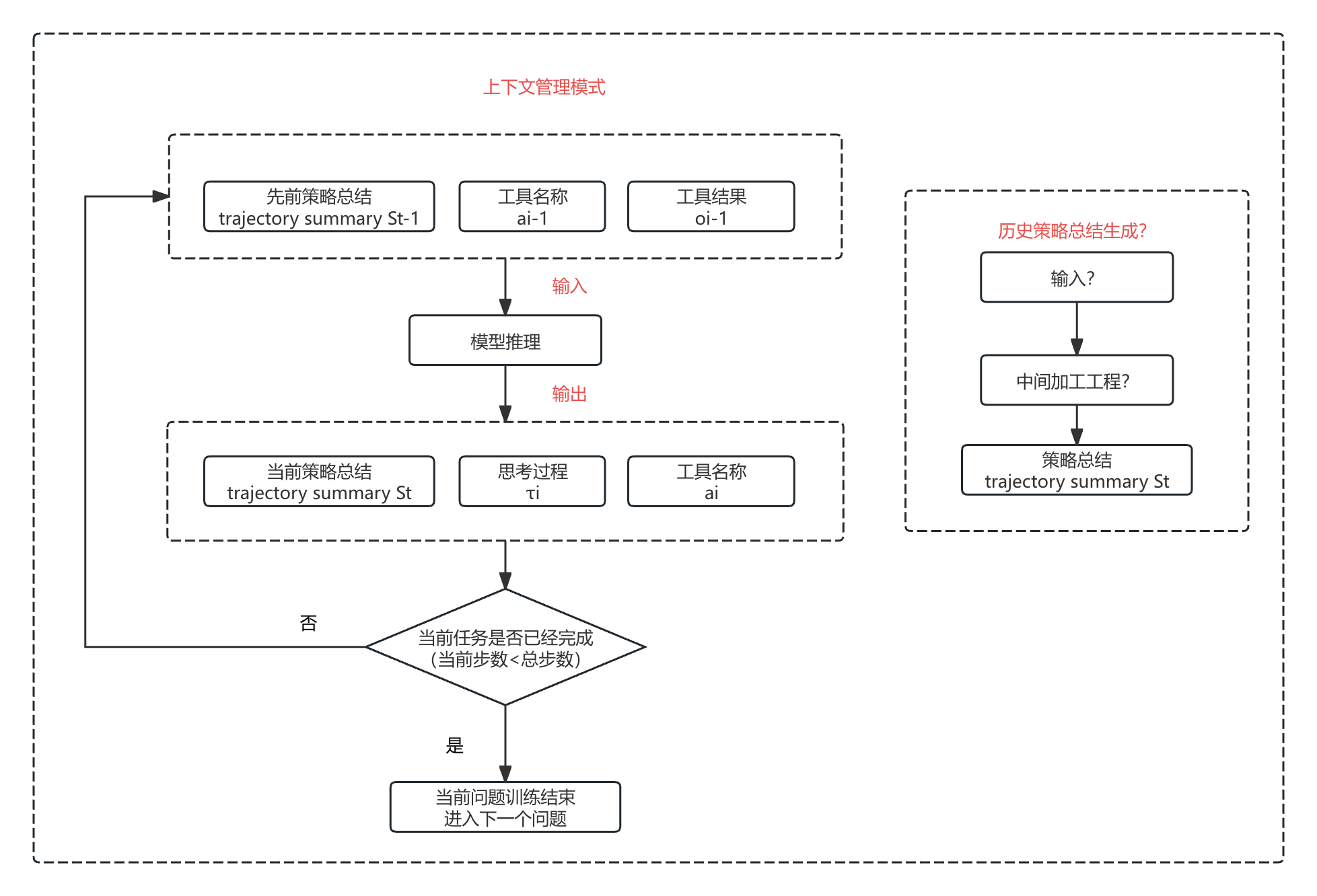
上下文工程具体如何实现,暂未明确
损失函数

2.1.1.2 ReAct模式
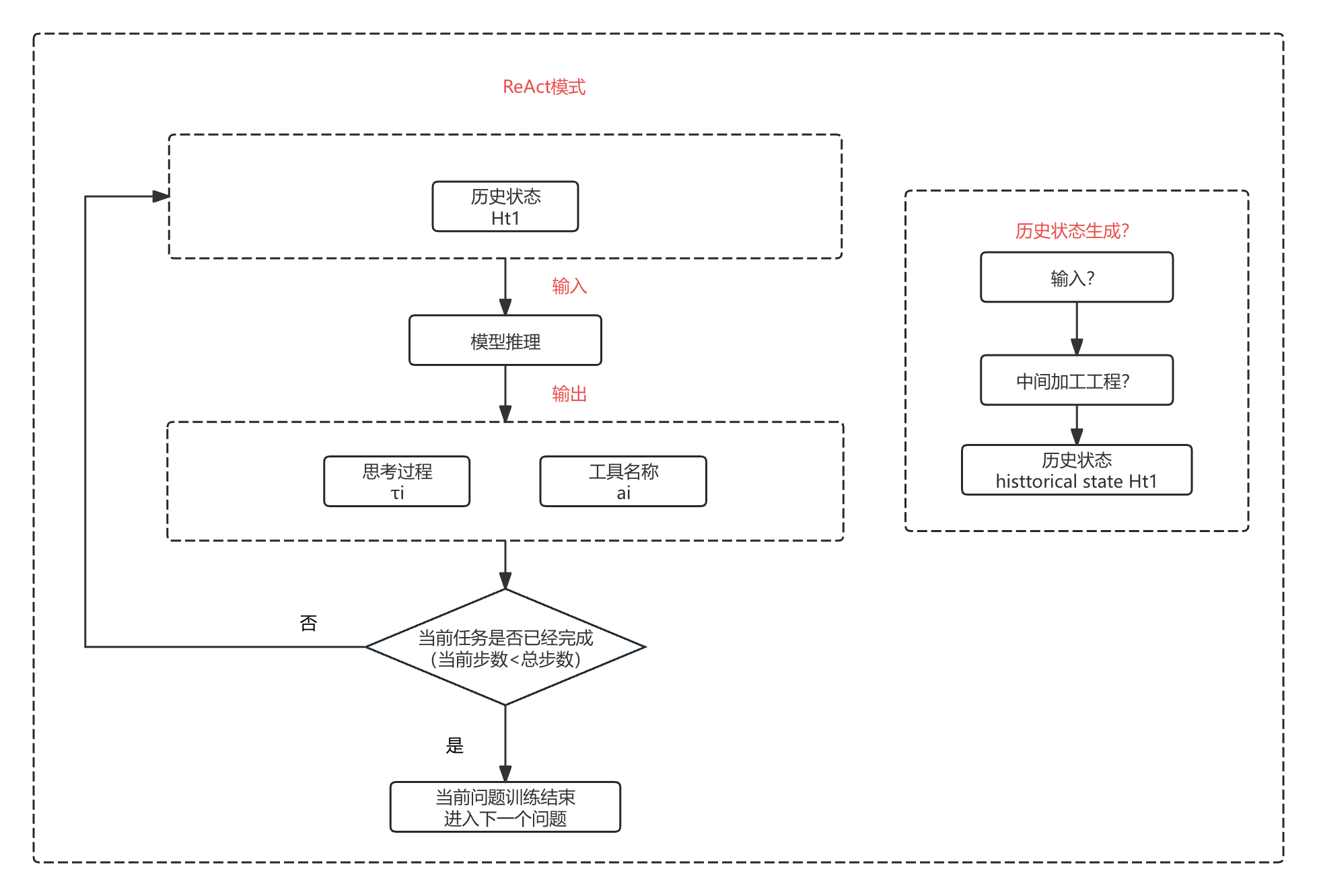
历史状态具体是什么,中间加工工程是什么,暂未明确
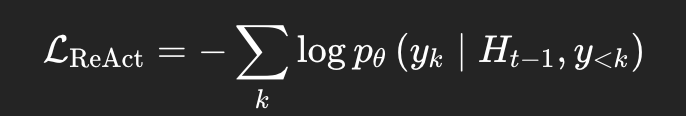
训练代码
https://github.com/NVIDIA/Megatron-LM
https://github.com/rllm-org/rllm
2.1.2、RL架构图
训练架构图
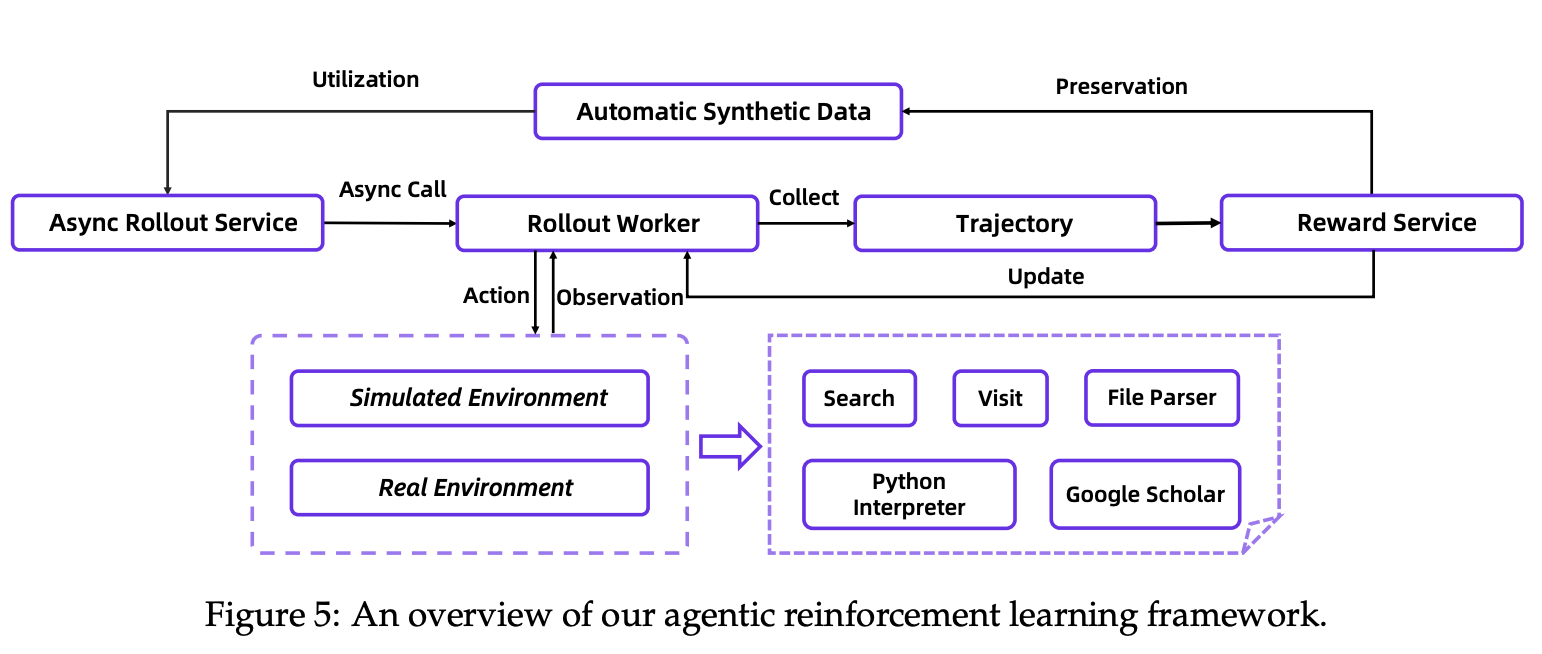
https://www.arxiv.org/pdf/2510.24701
verl:
- agent loop训练架构图
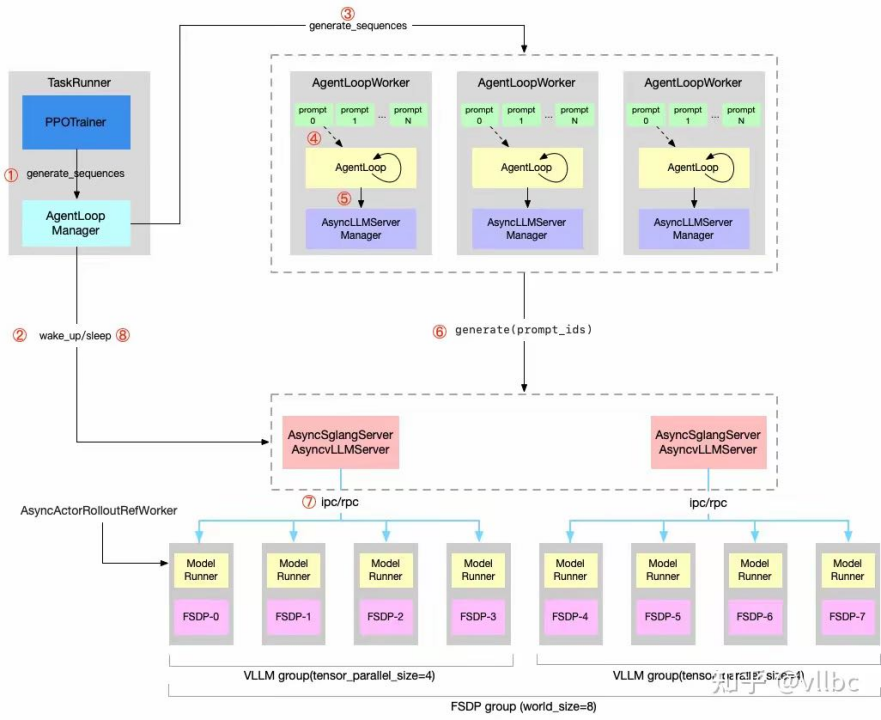
- prompt、response mask生成
Case 1: initial chat completion: system, human -> system, human
Case 2: follow up chat completion with tool/human response: system, human, ai, human|tool -> system, human, ai, human|tool
最后的prompt ids只包含开始的system和human,剩下的模型回答和工具调用结果都在respsonse_ids(后续只有tool_response和模型response,没有human)
造一批问题,基于deer-flow rollout,拿到每一步的输入输出,并设计奖励
|------|------------------------------------------------------------------------------------------------------------------------------------------------|----------|-------|---------|
| 奖励定义 | 类型 | reporter | coder | planner |
| 定性 | 1. 异常挖掘、分析(有GT,主动构造异常数据源,给出异常标签) 2. 洞察能力评判(无GT) 数据分析报告总结能力模型评测 | ✅ | ✅ | ❌ |
| 定量 | 1. 关键词匹配(同环比、相关系数) 2. 报告美化(图表生成(有无),且是否相关) | ✅ | ✅ | ❌ |
| | | | | |
奖励函数设计
模式1 - 过程奖励求和`
`reward = 任务执行顺序奖励 + 规划智能体奖励 + 代码智能体奖励 + 研究智能体奖励 + 分析智能体奖励 + 报告智能体奖励`
`模式2 - 只有结果奖励`
`reward = 最终报告质量奖励`
`2.2、数据构造
2.3、实验与评测 
https://www.arxiv.org/pdf/2510.24701
评测集指标定义
|-------|-------------------|------------|
| 评测指标 | 指标说明 | 数据样例(输入输出) |
| 数据准确性 | 生成数据结果是否遵守原文,幻觉表现 | |
| | | |
评测数据集
数据集地址`
`评测代码
代码地址`
`评测结果
|-----------------------------------|-------|--------|--------|-------|-------|
| | 数据准确性 | 数据洞察深度 | 数据洞察广度 | 报告完整性 | 报告逻辑性 |
| 其他对比模型 | | | | | |
| 微调前模型 Tongyi-DeepResearch-30B-A3B | | | | | |
| 微调后模型 Tongyi-DeepResearch-30B-A3B | | | | | |
三、分离式Agent RL
3.1 训练架构
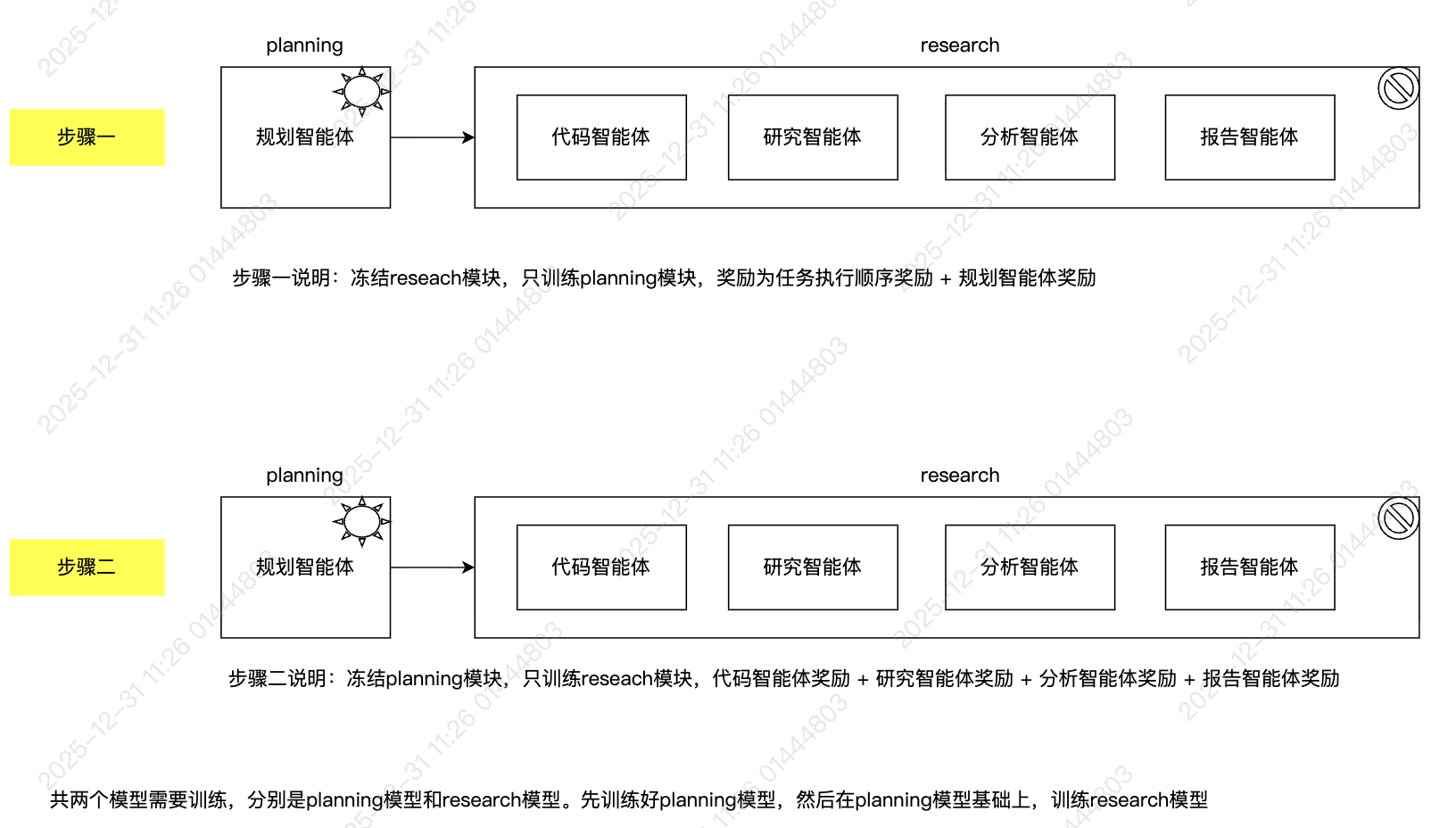
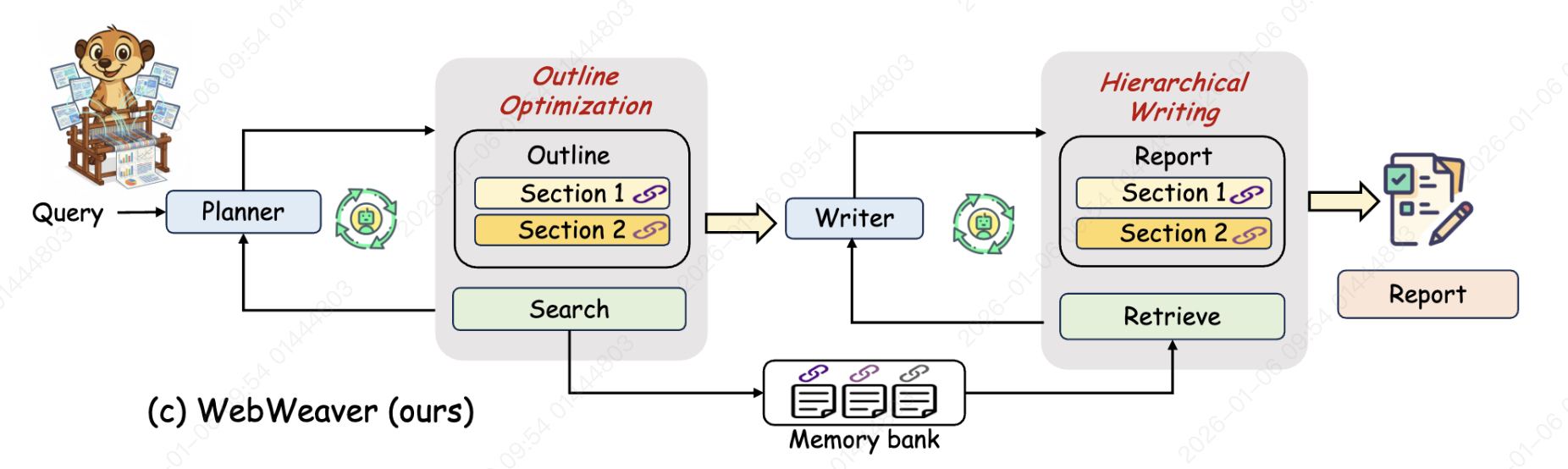
参考阿里的WebWeaver架构,是先训练好planning,再训练research(write)的。
然后在训练planning或research,内部再采用类似react的方式来训练。
下面给出分离式版本一和版本二的区别,两者在于一个轨迹是否要按span拆分成多条数据,如果按span拆分多条数据时,奖励是只能看到即时奖励,如果不拆分,一个轨迹一条数据,则轨迹中每个token(只包括thinking和action,observe屏蔽)共享一个奖励,该奖励为所有span奖励之和。
3.2 版本一
按span拆分多条数据时,奖励是只能看到即时奖励
3.2.1、数据构造示意图
planning模块:
{`
` input:25年经营分析`
` output:"[`
` "第一步:查询25年度月度票数",`
` "第二步:研究25年月度经营成本趋势",`
` "第三步:综合分析内部数据诊断顺丰经营情况",`
` "第四步:生成25年经营分析报告",`
` ]",`
` # reward: 当前步奖励`
`}`
`{`
` input:25年经营分析+"[`
` "第一步:查询25年度月度票数",`
` "第二步:研究25年月度经营成本趋势",`
` "第三步:综合分析内部数据诊断顺丰经营情况",`
` "第四步:生成25年经营分析报告",`
` ]"`
` output:"[`
` "第一步:查询25年度月度票数new",`
` "第二步:研究25年月度经营成本趋势new",`
` "第三步:综合分析内部数据诊断顺丰经营情况new",`
` "第四步:生成25年经营分析报告new",`
` ]"`
` # reward: 当前步奖励`
`}`
`数据示例:
(1)query = planning1
(2)query+planning1 = planning2
research模块:
# 代码智能体`
`{`
` input:25年经营分析`
` output:sql查询语句`
`}`
`# reward: 当前步奖励,即代码智能体奖励`
`# 研究智能体`
`{`
` input:25年经营分析+sql查询语句+研究25年月度经营成本趋势`
` output:研究结果`
`}`
`# reward: 当前步奖励,即研究智能体奖励`
`# 分析智能体`
`{`
` input:25年经营分析+sql查询语句+研究25年月度经营成本趋势+研究结果+综合分析内部数据诊断顺丰经营情况势`
` output:分析结果`
`}`
`# reward: 当前步奖励,即分析智能体奖励`
`# 报告智能体`
`{`
` input:25年经营分析+sql查询语句+研究25年月度经营成本趋势+研究结果+综合分析内部数据诊断顺丰经营情况势+分析结果+生成顺丰25年经营分析报告`
` output:报告结果`
`}`
`# reward: 当前步奖励,即报告智能体奖励`
`数据示例:
query = planning
planning = code agent
planning + code agent = research agent
planning + code agent + research agent = analyse agent
planning + code agent + research agent +analyse agent = report agent
3.3 版本二
不拆分,一个轨迹一条数据,则轨迹中每个token(只包括thinking和action,observe屏蔽)共享一个奖励,该奖励为所有span奖励之和。
3.3.1、数据构造示意图
planning模块:
{`
` input:25年经营分析+"[`
` "第一步:查询25年度月度票数",`
` "第二步:研究25年月度经营成本趋势",`
` "第三步:综合分析内部数据诊断顺丰经营情况",`
` "第四步:生成25年经营分析报告",`
` ]"`
` output:"[`
` "第一步:查询25年度月度票数new",`
` "第二步:研究25年月度经营成本趋势new",`
` "第三步:综合分析内部数据诊断顺丰经营情况new",`
` "第四步:生成25年经营分析报告new",`
` ]"`
` # reward: 每一步规划奖励`
`}`
`数据示例:
(1)query = planning1+planning2
research模块:
{`
` input:planning+25年经营分析+sql查询语句+研究25年月度经营成本趋势+研究结果+综合分析`
`}`
`# reward: 代码智能体奖励+研究智能体奖励+分析智能体奖励`
`+报告智能体奖励`
`数据示例:
query = planning+code agent + research agent +analyse agent+report agent
3. 4 、实验与评测
|-----------------------------------|-------|--------|--------|-------|-------|
| | 数据准确性 | 数据洞察深度 | 数据洞察广度 | 报告完整性 | 报告逻辑性 |
| 其他对比模型 | | | | | |
| 微调前模型 Tongyi-DeepResearch-30B-A3B | | | | | |
| 微调后模型 Tongyi-DeepResearch-30B-A3B | | | | | |