LangChain调用向量模型,存入向量数据库
很多入门 AI、RAG 检索、智能问答的开发者,都会被向量、Embedding、语义向量等概念困扰。其实向量技术底层逻辑并不复杂。
本文从通俗原理 入手,结合阿里云百炼向量模型做全流程实操,包含文本向量、余弦相似度计算、本地向量库闭环、多模态向量四大核心场景,提供多套生产级可运行代码、场景选型与避坑规则,零基础也能直接上手落地。
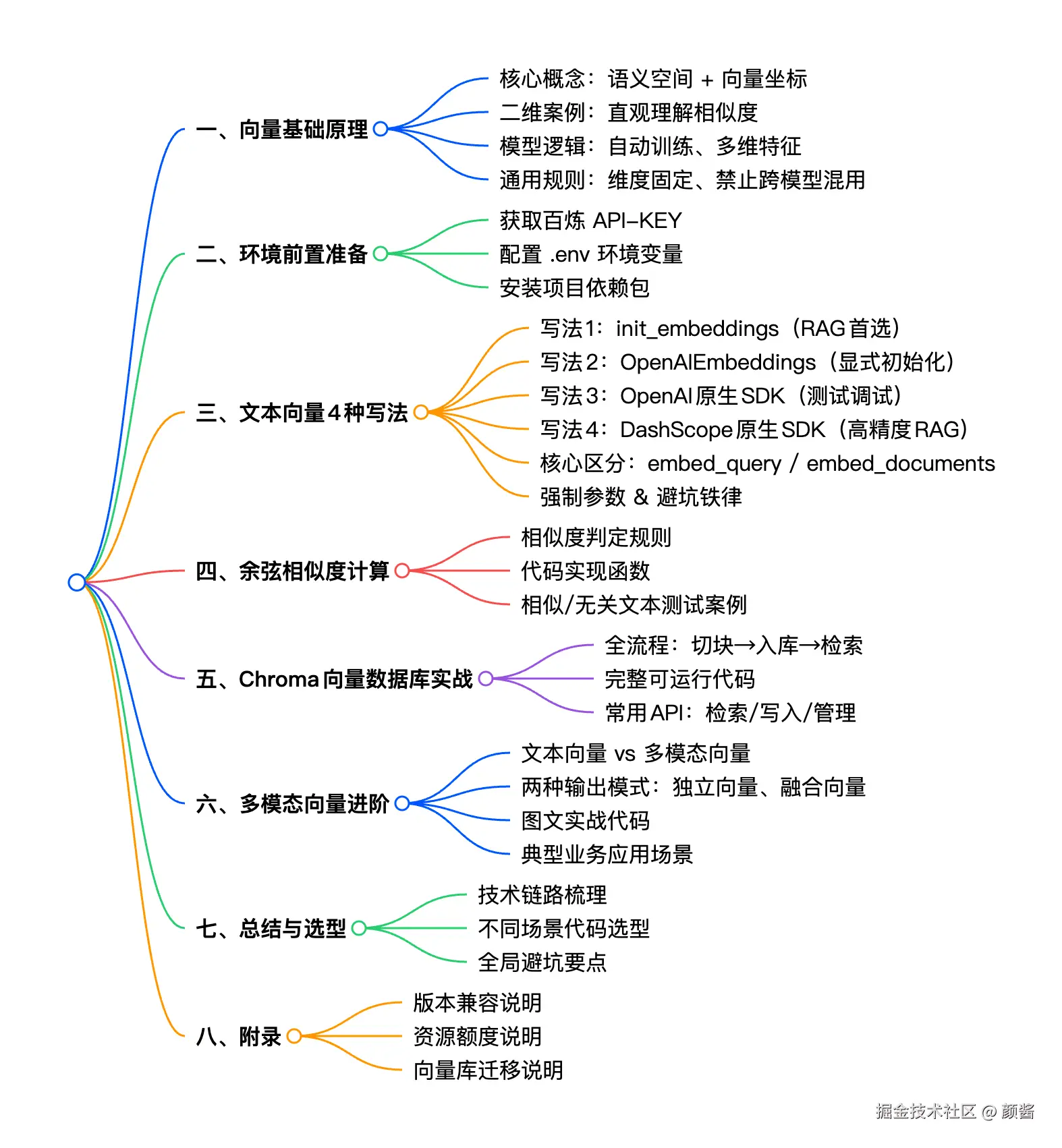
一、核心原理:读懂向量与文本向量化
1.1 通俗理解:语义多维空间
我们可以把人类所有文本语义 想象成一个超大的多维空间:
-
每一段文字、一句话,都是空间里一个独立的坐标点;
-
向量 就是描述这个坐标点的一组数字,格式形如
[0.12, 0.87, -0.33, ...]。
计算机无法理解文字含义,只能通过这组数字判断文本之间的语义关系。
1.2 二维极简示例(直观感受向量相似度)
为了降低理解门槛,我们将语义空间简化为2个维度 ,数值范围限定在 -1 ~ 1:
-
维度1:可爱程度
-
维度2:动物属性
| 文本 | 可爱程度 | 动物属性 | 对应向量 |
|---|---|---|---|
| 小猫 | 0.85 | 0.90 | [0.85, 0.90] |
| 猫咪 | 0.83 | 0.91 | [0.83, 0.91] |
| 汽车 | -0.20 | -0.85 | [-0.20, -0.85] |
结论:语义相近的文本,向量数字高度重合;语义差异大的文本,向量差距明显,这也是语义检索的核心依据。
1.3 真实向量模型工作逻辑
工业级向量模型并非只有2维,通常为512/768/1024/1536维,每一维对应一个抽象语义特征(生物属性、情感倾向、物体特征、场景属性等)。
三个核心知识点必须掌握:
-
单维数字无独立含义 :单独的
0.12、-0.33不代表任何语义,整组数字组合才是文本的完整语义表征。 -
向量由模型自动学习生成:无需人工手动赋值。模型基于海量公开文本数据训练,自主总结语义关联规则,最终为每段文本生成专属向量。
-
语义相似度 = 向量空间距离:
-
向量数值越接近 → 空间距离越小 → 语义越相似
-
向量数值差距越大 → 空间距离越大 → 语义无关
-
1.4 向量通用核心规则(全局避坑)
这是所有向量项目的通用准则,违规会直接导致检索失效:
-
维度固定:模型训练完成后,向量维度不可动态变更,不同模型默认维度不同。
-
维度不可人工释义:无法逐个解读每一维代表的特征,模型依靠整体数组区分语义。
-
禁止跨模型/跨维度混用:同一段文本,不同模型生成的向量完全不同,不能交叉比对、混合入库。
-
同模型一致性:使用同一个向量模型,相同文本生成的向量维度、特征规则完全统一。
二、前置准备:阿里云百炼环境配置
本文所有实操基于阿里云百炼向量模型(免费试用、兼容 OpenAI 接口、支持文本/多模态),请按以下步骤完成环境搭建。
2.1 获取 API-KEY
-
登录阿里云官网,搜索进入「百炼 Model Studio」;
-
点击右上角头像,进入「API-KEY 管理」;
-
创建密钥(以
sk-开头),密钥仅展示一次,务必提前复制保存。
2.2 配置环境变量
项目根目录新建 .env 文件,统一存放接口地址与密钥,避免硬编码泄露密钥:
Shell
DASHSCOPE_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
DASHSCOPE_API_KEY="sk-你的百炼密钥"2.3 安装依赖包
执行命令安装本次实战所需全部第三方库:
Shell
pip install python-dotenv langchain openai dashscope numpy三、核心实战:文本向量 4 种主流写法
本次使用百炼文本向量模型 text-embedding-v4,整理4种工业级写法 ,按新手推荐优先级排序,覆盖调试、RAG 开发、高精度检索等全场景。
阿里云百炼的文本向量模型参考
通用方法区分(LangChain 必记)
LangChain 向量模型提供两个核心方法,严禁混用,否则检索精度大幅下降:
| 方法名 | 输入格式 | 适用场景 |
|---|---|---|
embed_query |
单条文本字符串 | 用户提问、检索关键词 |
embed_documents |
文本字符串列表 | 知识库文档批量向量化、向量库入库 |
核心强制参数:对接百炼兼容接口时,必须配置
check_embedding_ctx_length=False
写法一:init_embeddings(首选|RAG 标准写法)
适用场景:正式 LangChain RAG 项目、统一代码规范、快速对接各类向量数据库。 核心思路:将百炼接口映射为 OpenAI 环境变量,适配 LangChain 生态。
Python
import os
from dotenv import load_dotenv
from langchain.embeddings import init_embeddings
# 加载环境变量
load_dotenv()
# 映射OpenAI标准环境变量,适配LangChain
os.environ["OPENAI_API_KEY"] = os.getenv("DASHSCOPE_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("DASHSCOPE_BASE_URL")
# 初始化向量模型
text_embedding = init_embeddings(
"openai:text-embedding-v4",
dimensions=1024,
check_embedding_ctx_length=False, # 百炼必填参数
)
# 1. 单条文本(用户检索提问)
query_vec = text_embedding.embed_query("小猫喜欢吃鱼")
print(f"单条向量维度:{len(query_vec)}")
print(f"向量前5位数值:{query_vec[:5]}\n")
# 2. 批量文本(知识库文档入库)
doc_list = [
"小猫是一种肉食动物,喜欢吃鱼和老鼠。",
"狗是杂食动物,也吃狗粮。",
"鱼富含蛋白质和牛磺酸。",
]
docs_vec = text_embedding.embed_documents(doc_list)
print(f"批量向量总数:{len(docs_vec)}")
print(f"单条文档向量维度:{len(docs_vec[0])}")
print(f"第一条文档向量前5位:{docs_vec[0][:5]}")写法二:OpenAIEmbeddings(显式初始化|自定义参数)
适用场景 :需要精细化调整模型参数、代码可读性要求高的场景,是 init_embeddings 的底层实现。
Python
import os
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings
load_dotenv()
# 显式初始化向量模型
embedding = OpenAIEmbeddings(
model="text-embedding-v4",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url=os.getenv("DASHSCOPE_BASE_URL"),
dimensions=1024,
check_embedding_ctx_length=False,
)
vec = embedding.embed_query("小猫喜欢吃鱼")
print(f"向量维度:{len(vec)}")写法三:OpenAI 原生 SDK(极简|测试调试)
适用场景:临时测试、接口调试、对照官方文档,代码最简洁,不依赖 LangChain。
Python
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
# 初始化客户端
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url=os.getenv("DASHSCOPE_BASE_URL"),
)
# 生成文本向量
response = client.embeddings.create(
model="text-embedding-v4",
input="衣服的质量很好,款式美观",
dimensions=1024,
encoding_format="float",
)
vec = response.data[0].embedding
print(f"向量维度:{len(vec)}")
print(f"向量前5位数值:{vec[:5]}")写法四:DashScope 原生 SDK(高精度|专业 RAG)
适用场景 :追求检索精度的生产级 RAG 项目。支持通过 text_type 区分检索问句(query)和知识库文档(document),是兼容接口不具备的高阶能力。
Python
import os
from http import HTTPStatus
from dashscope import TextEmbedding
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("DASHSCOPE_API_KEY")
# 1. 用户提问:text_type="query"
query_resp = TextEmbedding.call(
model="text-embedding-v4",
input="小猫喜欢吃什么?",
text_type="query",
dimension=1024,
api_key=api_key,
)
# 2. 知识库文档:text_type="document"
doc_resp = TextEmbedding.call(
model="text-embedding-v4",
input=[
"小猫是一种肉食动物,喜欢吃鱼和老鼠。",
"狗是杂食动物,也吃狗粮。",
"鱼富含蛋白质和牛磺酸。",
],
text_type="document",
dimension=1024,
api_key=api_key,
)
# 校验接口返回状态
for resp in (query_resp, doc_resp):
if resp.status_code != HTTPStatus.OK:
raise RuntimeError(f"接口请求失败:{resp.message}")
print(f"向量维度:{len(resp.output['embeddings'][0]['embedding'])}")文本向量三大铁律(必看避坑)
-
维度统一 :向量库入库、检索必须使用同一模型+同一维度;
-
参数必加 :LangChain 对接百炼,强制开启
check_embedding_ctx_length=False; -
模型不混用:更换向量模型后,必须全量重新生成向量库。
四、核心计算:余弦相似度(判断语义相似性)
向量生成后,通过余弦相似度计算两段文本的语义相似度,这是 AI 检索、智能匹配的底层计算逻辑。
4.1 相似度判定规则
-
数值趋近于
1:语义高度相似; -
数值趋近于
0:语义完全无关; -
数值趋近于
-1:语义完全相反。
4.2 可运行代码实现
Python
import numpy as np
import os
from dotenv import load_dotenv
from langchain.embeddings import init_embeddings
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("DASHSCOPE_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("DASHSCOPE_BASE_URL")
# 初始化向量模型
embedding = init_embeddings(
"openai:text-embedding-v4",
dimensions=1024,
check_embedding_ctx_length=False,
)
# 余弦相似度计算函数
def cosine_similarity(vec_a, vec_b):
dot_product = np.dot(vec_a, vec_b)
norm_a = np.linalg.norm(vec_a)
norm_b = np.linalg.norm(vec_b)
return float(dot_product / (norm_a * norm_b))
# 测试文本
text1 = "小猫喜欢吃鱼"
text2 = "猫咪爱吃鱼"
text3 = "今天股市大涨"
# 生成向量
v1 = embedding.embed_query(text1)
v2 = embedding.embed_query(text2)
v3 = embedding.embed_query(text3)
# 计算并打印结果
print(f"相似文本相似度:{cosine_similarity(v1, v2):.2f}") # 约 0.85
print(f"无关文本相似度:{cosine_similarity(v1, v3):.2f}") # 约 0.13五、完整 RAG 闭环:Chroma 本地向量数据库实战
向量的最终落地场景是向量数据库 。本节使用轻量本地向量库 Chroma(无需部署、文件持久化、零成本),实现文本切块 → 向量化入库 → 语义检索全流程,该逻辑适用于所有向量数据库。
5.1 整体流程
-
文本切块(Chunk):拆分长文本,避免语义稀释;
-
向量化入库:文本+向量+元数据持久化到向量库;
-
提问向量化:用户检索词生成向量;
-
相似度匹配:数据库召回相似度最高的内容。
5.2 安装依赖
Shell
pip install chromadb langchain-chroma5.3 全流程代码
Python
import os
import shutil
from dotenv import load_dotenv
from langchain.embeddings import init_embeddings
from langchain_chroma import Chroma
from langchain_text_splitters import CharacterTextSplitter
# 加载环境变量 & 初始化向量模型
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("DASHSCOPE_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("DASHSCOPE_BASE_URL")
embedding = init_embeddings(
"openai:text-embedding-v4",
dimensions=1024,
check_embedding_ctx_length=False,
)
# 1. 原始知识库文本
origin_docs = [
"小猫是典型的肉食动物,日常喜欢吃鱼和老鼠,体内需要牛磺酸维持视力。",
"猫是喜欢吃鱼和老鼠",
"猫咪属于家养宠物,性格温顺,喜欢晒太阳、睡觉,睡眠时间占全天大部分时间。",
"狗狗是杂食动物,忠诚度高,常作为伴侣宠物,适合陪伴人类。"
]
# 2. 文本切块(分割长文本,chunk_overlap 保留上下文)
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)
split_docs = text_splitter.create_documents(origin_docs)
# 3. 初始化向量库(清空历史数据,避免重复)
CHROMA_DIR = "./chroma_db"
if os.path.isdir(CHROMA_DIR):
shutil.rmtree(CHROMA_DIR)
vector_db = Chroma.from_documents(
documents=split_docs,
embedding=embedding,
persist_directory=CHROMA_DIR,
)
print("✅ 资料向量已成功入库!\n")
# 4. 语义检索(k=2:返回相似度最高的2条结果)
query = "小猫喜欢吃什么?"
search_result = vector_db.similarity_search(query, k=2)
# 打印检索结果
print("🔍 检索召回内容:")
for idx, doc in enumerate(search_result, 1):
print(f"{idx}. {doc.page_content}")5.4 Chroma 常用核心方法(开发必备)
1. 检索类(RAG 核心)
| 方法 | 作用 |
|---|---|
similarity_search(query, k) |
基础语义检索,返回文档列表 |
similarity_search_with_score(query, k) |
检索 + 返回距离分数 |
max_marginal_relevance_search(query, k) |
MMR 检索,优化结果多样性 |
as_retriever() |
转为检索器,对接 LangChain Chain |
2. 写入/更新类
-
add_documents(docs):增量追加文档 -
add_texts(texts):直接追加纯文本
3. 数据管理类
-
get():查询库内全部数据 -
delete(ids):按 ID 删除指定数据 -
delete_collection():清空整个向量库
4. 进阶检索
-
元数据过滤:
similarity_search(query, k, filter={"key":"value"}) -
向量直搜:
similarity_search_by_vector(vec, k)
六、进阶实战:多模态向量(文本/图片/视频统一向量化)
文本向量仅支持文字输入,多模态向量模型 可将文本、图片、视频映射到同一个语义空间,实现以文搜图、以图搜图、图文融合检索。
6.1 文本向量 vs 多模态向量
| 对比项 | 文本向量 | 多模态向量 |
|---|---|---|
| 支持输入 | 仅文本 | 文本、图片、视频 |
| 主流接入方式 | LangChain / OpenAI 兼容接口 | DashScope 原生 SDK |
| LangChain 支持 | 完全支持 | 不支持,必须原生调用 |
6.2 两种向量输出模式
-
独立向量:每个输入(文本/图片)单独生成向量,适用于以图搜图、图文对比;
-
融合向量 :多个输入融合为一个向量,适用于商品图文整体表征、综合内容检索。
6.3 多模态代码实战
阿里云百炼的多模态向量模型
模式1:独立向量(图文分别生成向量)
使用模型:tongyi-embedding-vision-plus
Python
import os
from http import HTTPStatus
from dashscope import MultiModalEmbedding
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("DASHSCOPE_API_KEY")
resp = MultiModalEmbedding.call(
model="tongyi-embedding-vision-plus",
api_key=api_key,
input=[
{"text": "一只橘猫在晒太阳"},
{"image": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/256_1.png"},
],
dimension=1024,
)
if resp.status_code != HTTPStatus.OK:
raise RuntimeError(f"请求失败:{resp.code} {resp.message}")
# 遍历输出向量
for idx, item in enumerate(resp.output["embeddings"]):
print(f"第{idx}个向量维度:{len(item['embedding'])}")模式2:图文融合向量(多内容合并为一个向量)
使用模型:qwen3-vl-embedding,开启 enable_fusion=True 实现融合
Python
import os
from http import HTTPStatus
from dashscope import MultiModalEmbedding
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("DASHSCOPE_API_KEY")
resp = MultiModalEmbedding.call(
model="qwen3-vl-embedding",
api_key=api_key,
input=[
{"text": "一只橘猫在晒太阳"},
{"image": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/256_1.png"},
],
enable_fusion=True, # 开启图文融合
dimension=1024,
)
if resp.status_code != HTTPStatus.OK:
raise RuntimeError(f"请求失败:{resp.code} {resp.message}")
# 融合后仅输出1个向量
fusion_vec = resp.output["embeddings"][0]["embedding"]
print(f"融合向量维度:{len(fusion_vec)}")
print(f"向量前5位:{fusion_vec[:5]}")6.4 多模态向量典型应用场景
-
图文检索:文字搜图、相似图片匹配;
-
电商业务:商品图片+标题融合检索,提升匹配精度;
-
视频处理:视频帧向量化,实现视频分类、相似视频推荐。
七、全文总结 & 场景选型建议
7.1 核心技术链路
-
文本向量链路
文本→ 文本Embedding模型 → 向量 → 相似度计算/向量库入库 → RAG 检索/智能问答 -
多模态向量链路
文本/图片/视频→ 多模态Embedding模型 → 独立/融合向量 → 跨模态检索
7.2 新手场景选型指南
-
常规文本 RAG 项目 :优先
init_embeddings,生态完善、对接简单; -
临时测试/接口调试:使用 OpenAI 原生 SDK,代码极简;
-
高精度生产级 RAG:使用 DashScope 原生文本向量 SDK,区分 query/document;
-
图文/视频跨模态场景:固定使用 DashScope 多模态原生 SDK;
-
本地轻量存储:选择 Chroma;线上生产可迁移 Redis、PGVector 等向量库。
7.3 通用避坑总结
-
全链路模型、维度必须统一,这是向量项目的第一准则;
-
长文本务必做切块处理,防止语义丢失;
-
对接阿里云百炼+LangChain 时,务必开启
check_embedding_ctx_length=False。
八、附录:补充说明
-
本文所有代码基于 Python 3.8+ 开发,依赖库版本建议使用最新稳定版;
-
阿里云百炼免费额度可满足学习、测试需求,正式上线需根据流量扩容;
-
所有向量数据库(Redis、PGVector、Milvus 等)接口逻辑与 Chroma 基本一致,学会一套即可快速迁移。