目录
🚩二维卷积的理解(torch.nn.functional))
[❗ ceil_mode](#❗ ceil_mode)
二维卷积 简单说就是:用一个小的模板(卷积核)在大的图像上滑动,每个位置都计算模板和下面图像的对应点相乘再求和。核心的操作就是滑动点积。
(俗话就是 想象你在用一个3×3的放大镜 扫描一张5×5的照片)
二维卷积是在高度和宽度两个维度上进行的滑动窗口计算,是处理图像数据的核心操作
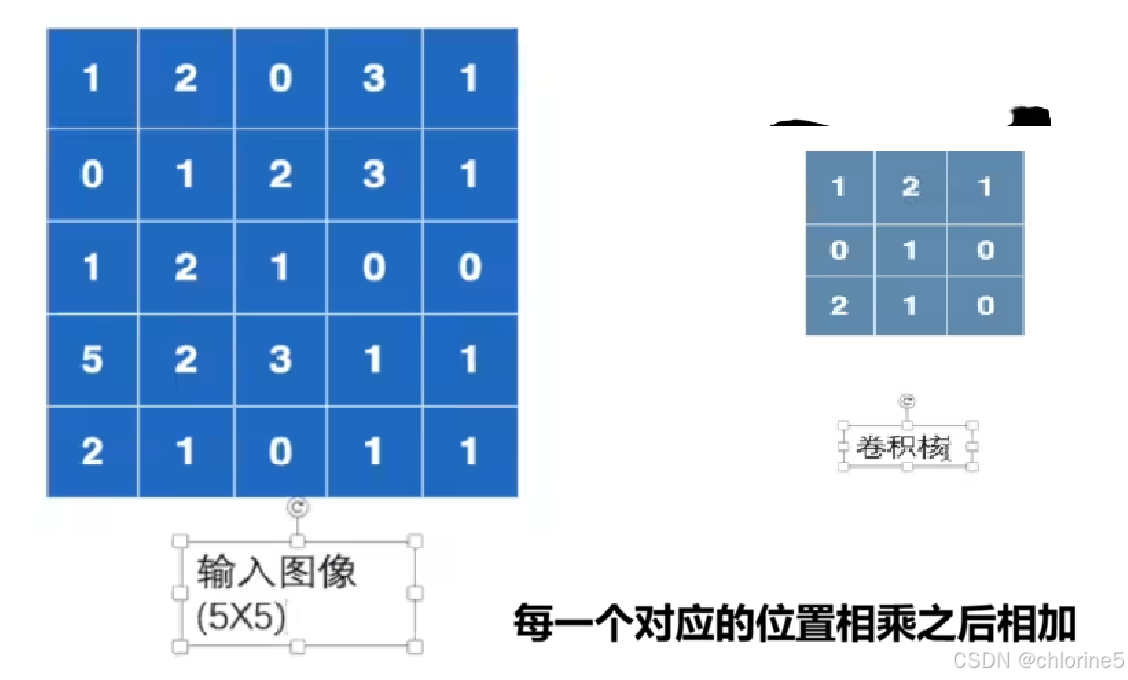
用3×3的卷积核在5×5的图像上滑动,计算每个位置的点积,最终输出3×3的特征图。
这是CNN最基础也最重要的操作!以下就是代码实现的步骤。

📝构建输入和卷积核
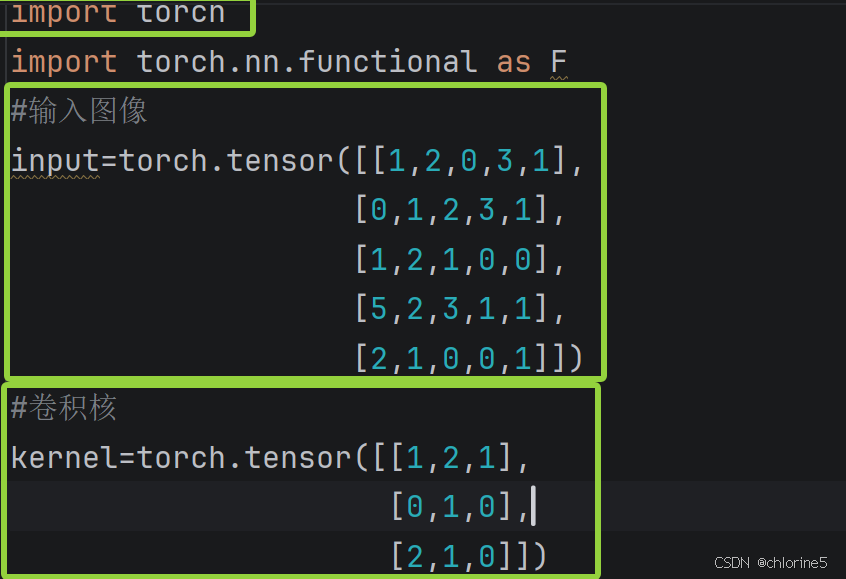
上面输入的是一个 5×5 的矩阵,模拟一张灰度图像的像素值。而下面是一个 3×3 的卷积核,用于提取图像特征。
👩🏻💻改变形状的原因
input=torch.reshape(input,(1,1,5,5))
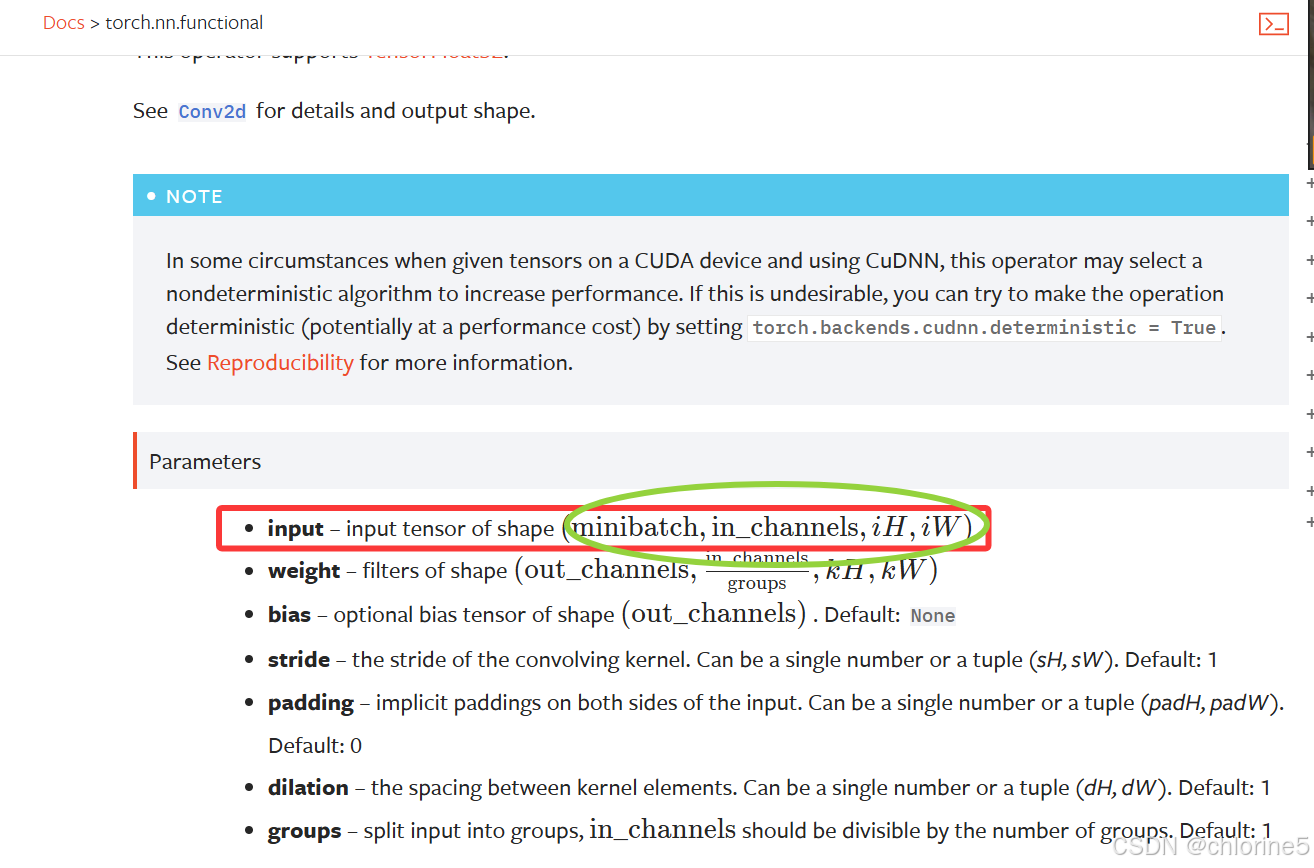
kernel=torch.reshape(kernel,(1,1,3,3))改变形状(由2维转为4维)原因:input和kernel原先只是已知高宽两种属性,由官方文档可知:
conv2d这个函数强制要求输入必须是四维,否则直接报错无法运行。四维提供了"批量大小"和"通道数"这两个关键信息,而2维数据天然缺失这些信息。
转成四维之后就会知道图片的具体信息。

📝执行了二维卷积运算
👩🏻💻stride=1
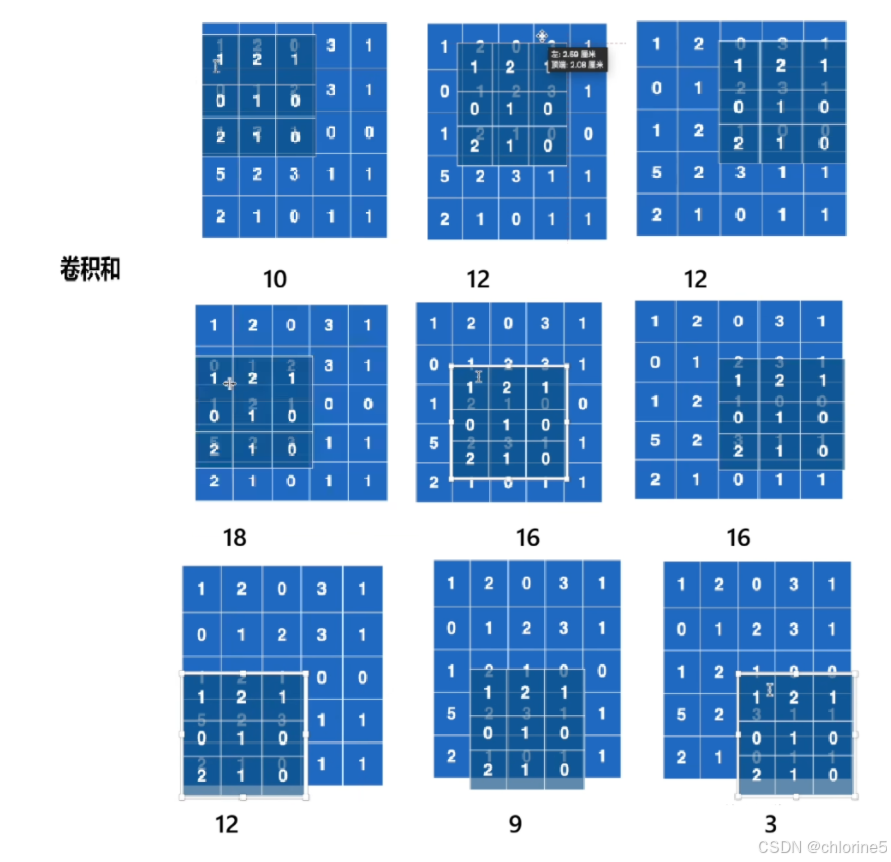
stride=1 意味着每次移动1步,卷积核在输入图像上滑动,计算每个位置的对应元素相乘再求和.
#卷积后的输出 output=F.conv2d(input,kernel,stride=1)这行代码做的事情就是:
将3×3的卷积核在5×5的输入上滑动
每个位置做对应元素相乘后求和
生成3×3的输出特征图
stride=1控制每次移动1个像素这就是卷积神经网络最基本、最核心的运算!
import torch
import torch.nn.functional as F
#输入图像
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,0,1]])
#卷积核
kernel=torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input=torch.reshape(input,(1,1,5,5))
kernel=torch.reshape(kernel,(1,1,3,3))
print(input.shape)
print(kernel.shape)
#卷积后的输出
output=F.conv2d(input,kernel,stride=1)
print(output)
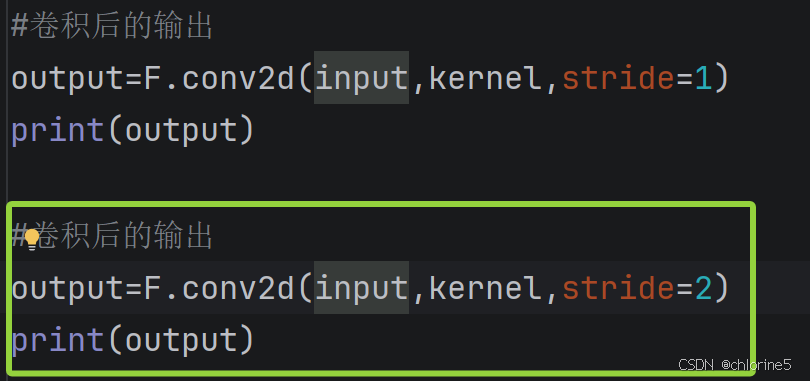
stride=2的时候
stride=2每次移动2步
👩🏻💻padding=1
Padding(填充) 是在输入图像的四周补零,用来控制输出尺寸。

如果根据上述的输入图像,设置padding=1(上下左右各补1圈0)
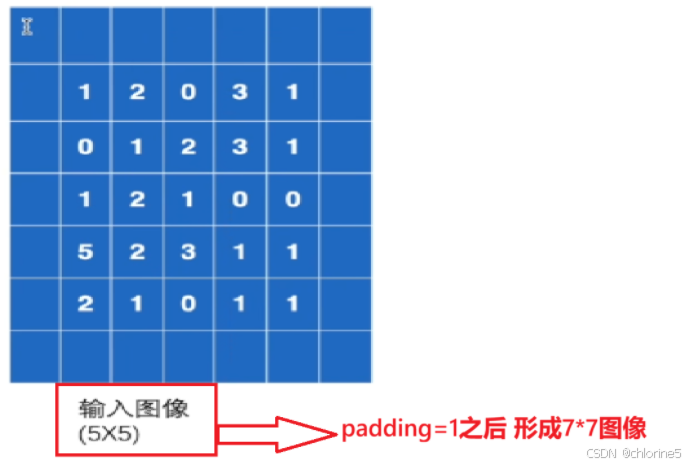 空的方格默认是设置为0.
空的方格默认是设置为0.
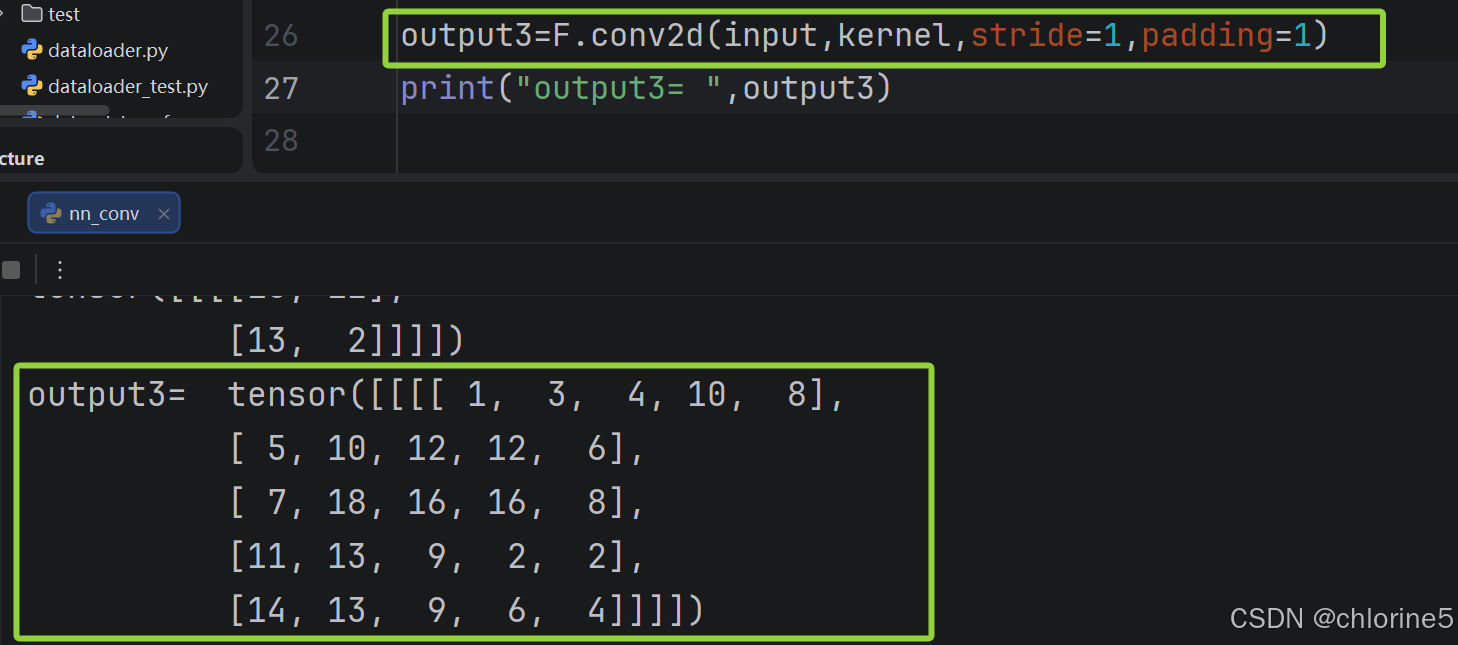
将卷积核3*3放到7*7的上面,卷积后的输出是5*5的图像。
🚩卷积层

📝PyTorch构建的极简卷积神经网络
使用PyTorch构建的极简卷积神经网络,用于处理CIFAR-10图像数据.
整体的构建:数据准备 → 数据加载 → 网络定义 → 前向传播 → 输出结果
❗第一部分:数据准备
dataset = torchvision.datasets.CIFAR10(
"./dataset", # 下载到当前目录下的dataset文件夹
train=False, # 使用测试集(False=测试集,True=训练集)
transform=torchvision.transforms.ToTensor(), # 将PIL图像转为张量
download=True # 如果本地没有,自动下载
)❗第二部分:数据加载器
#数据加载器 每次批量处理64个数据
dataloader=DataLoader(dataset,batch_size=64)❗第三部分:网络定义
class Tudui(nn.Module): # 继承nn.Module基类
def __init__(self):
super(Tudui, self).__init__() # 调用父类初始化
self.conv1 = Conv2d(
in_channels=3, # 输入通道数:RGB彩色图像有3个通道
out_channels=6, # 输出通道数:生成6个特征图
kernel_size=3, # 卷积核大小:3×3像素
stride=1, # 步长:每次移动1个像素
padding=0 # 填充:不填充边缘
)❗第四部分:前向传播
def forward(self, x):
x = self.conv1(x) # 数据流过卷积层
return x # 返回处理结果
输入x = [64, 3, 32, 32] # 原始图片 ↓ x = self.conv1(x) # 卷积处理 ↓ 输出x = [64, 6, 30, 30] # 特征图 ↓ return x # 返回给调用者
❗第五部分:创建网络
tudui = Tudui() # 实例化网络对象
# 此时网络结构:
# Tudui(
# (conv1): Conv2d(3, 6, kernel_size=(3,3), stride=(1,1))
# )❗第六部分:数据处理循环
for data in dataloader: # 迭代157次(每次批量处理64)
imgs, targets = data # 解包批次数据
output = tudui(imgs) # 前向传播
print(imgs.shape) # 打印输入形状
print(output.shape) # 打印输出形状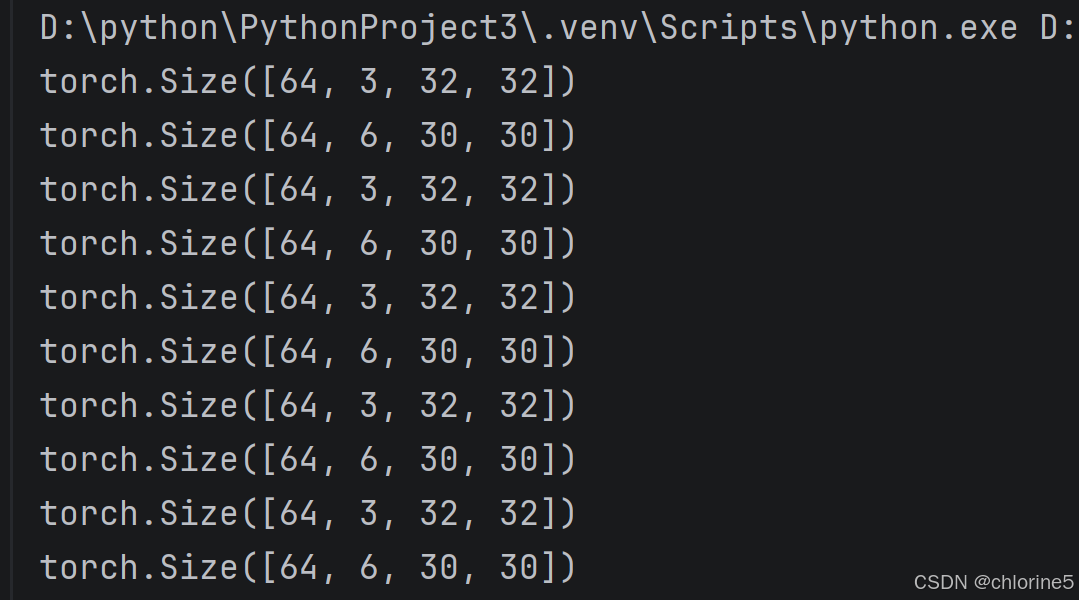 输出结果.
输出结果.
❗使用tensorboard
想要直观的检测用tensorboard来查看。
step=0
writer=SummaryWriter("./put")
for data in dataloader: # 从数据加载器中取出一批数据
imgs,targets=data # 解包:分为图片和标签
output=tudui(imgs) # 将图片送入模型,得到输出
print(imgs.shape)
print(output.shape)
#torch.Size([64, 3, 32, 32])输入的大小
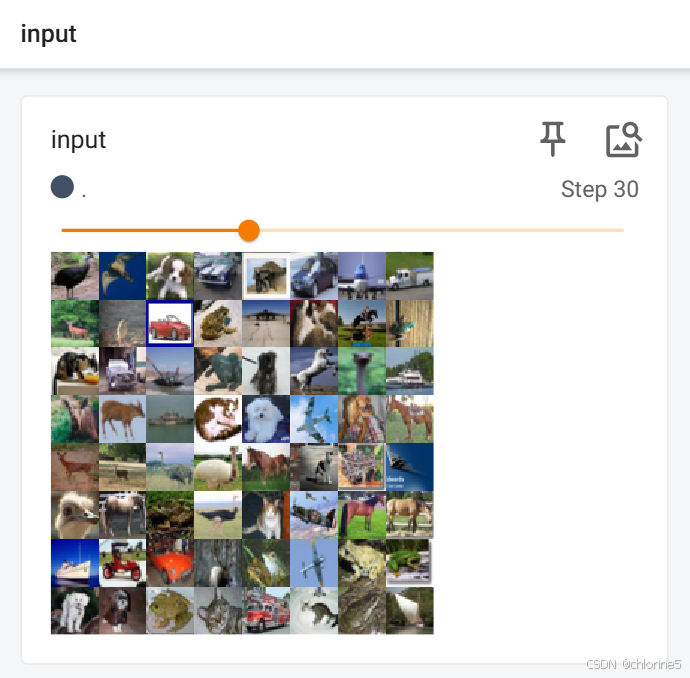
writer.add_images("input",imgs,step)
#torch.Size([64, 6, 30, 30])卷积之后输出的大小
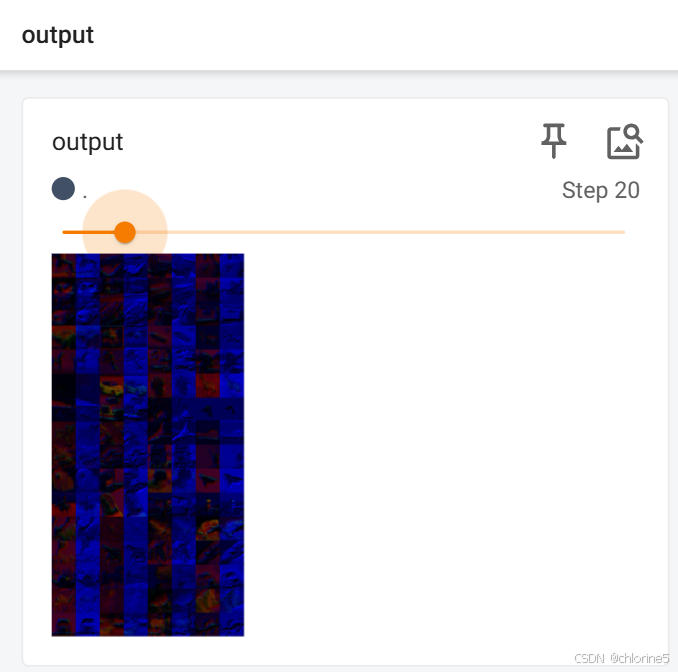
writer.add_images("output",output,step)
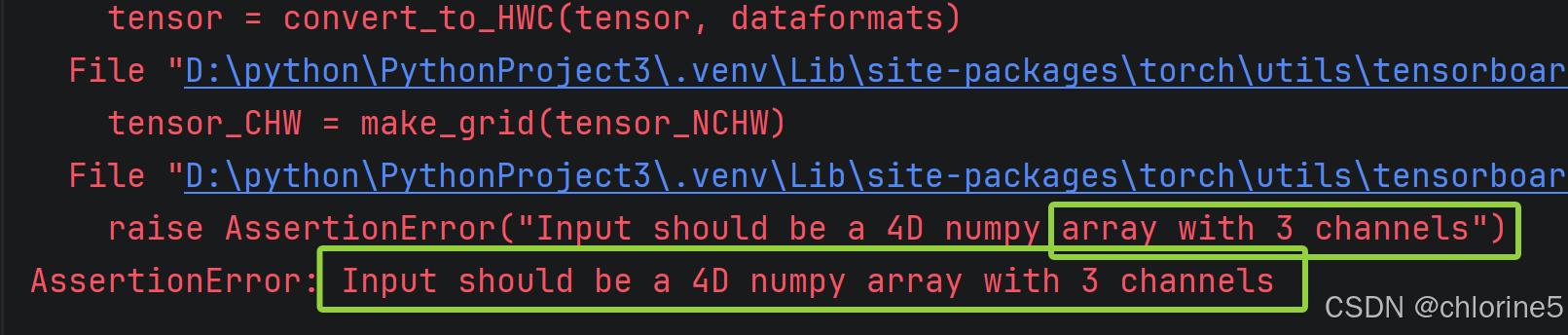
step+=1报错的原因是: TensorBoard 的
add_images方法要求输入必须是 3 通道的 RGB 图像 ,但你的output是 6 个通道的特征图,解决方法:torch.reshape方法,将通道从6改为3即可。
input属于卷积前,output属于卷积后。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#数据准备 dataset测试集,正确加载了CIFAR-10数据,转为tensor类型
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#数据加载器 每次批量处理64个数据
dataloader=DataLoader(dataset,batch_size=64)
#定义简单神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
#卷积
self.conv1=Conv2d( in_channels=3, # 输入通道:RGB彩色(3通道)
out_channels=6, # 输出通道:6个特征图
kernel_size=3, # 卷积核大小:3×3
stride=1, # 步长:每次移动1像素
padding=0 ) # 不填充
#网络中有一个卷积层(上层代码显示)
#如何使用这个卷积层
def forward(self,x):
x=self.conv1(x) #把输入的x送到卷积层
return x #返回卷积层
tudui=Tudui() # 创建网络
step=0
writer=SummaryWriter("./put")
for data in dataloader: # 从数据加载器中取出一批数据
imgs,targets=data # 解包:分为图片和标签
output=tudui(imgs) # 将图片送入模型,得到输出
print(imgs.shape)
print(output.shape)
#torch.Size([64, 3, 32, 32])输入的大小
writer.add_images("input",imgs,step)
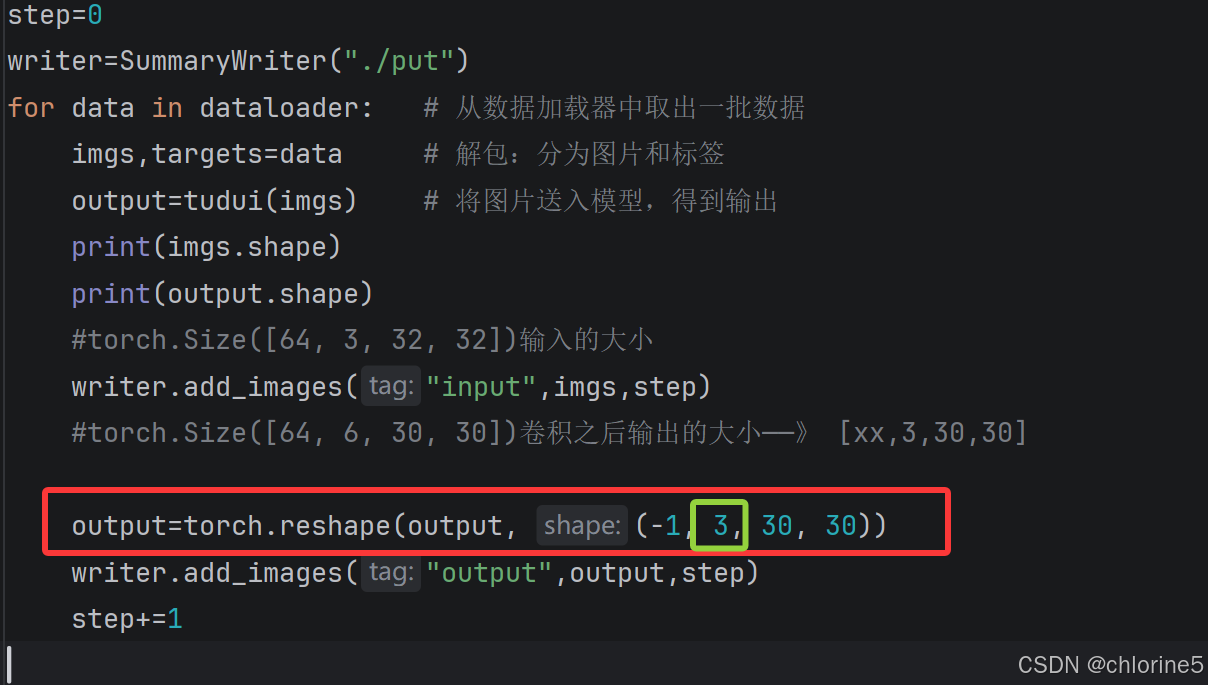
#torch.Size([64, 6, 30, 30])卷积之后输出的大小------》 [xx,3,30,30]
output=torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output",output,step)
step+=1🚩池化层
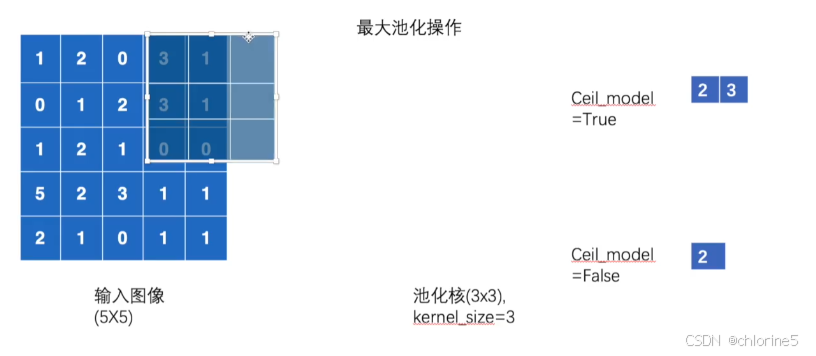
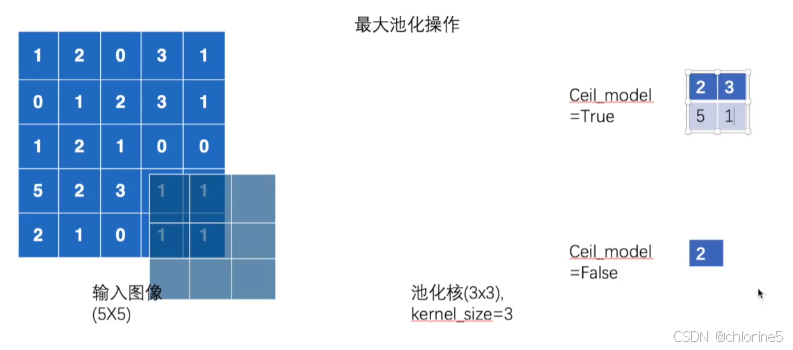
📝最大池化操作
最大池化是一种下采样 操作,它的作用是在一个区域内只保留最大值,从而缩小特征图的尺寸。
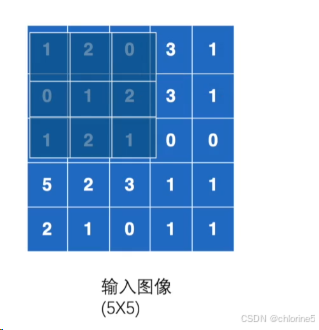

我们看到3*3放在输入图像中,哪一个区域最大值就是2,所以输出2.
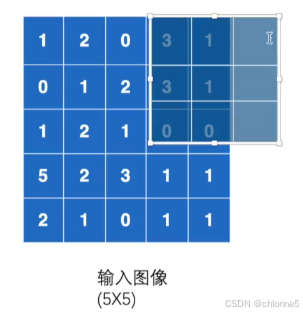
❗ ceil_mode
如果出现以上的情况,超出了图像的范围,ceil_mode会解决这个问题。
ceil_mode决定池化层计算输出尺寸时,如何处理边界情况(当输入尺寸不能被池化窗口整除时)。ceil_mode = False(默认)丢弃边缘多出的行和列。
这里的2(对应的是左上角3*3占用的最大值)
ceil_mode = True 保留边缘多出的行和列。
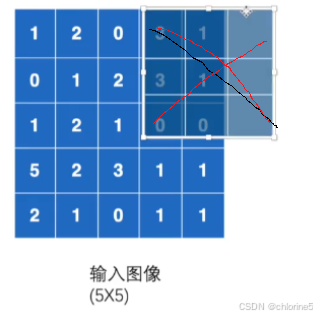
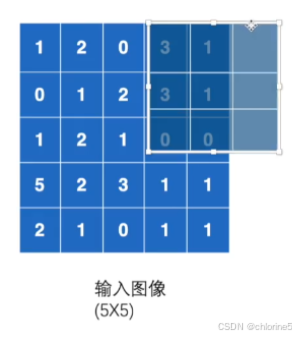
最后的结果是ceil_mode为true的结果有四个,而ceil_mode为false的结果有一个。
以下如图所示:


以下为代码显示:
演示了如何手动创建一个 5x5 的张量,并用
MaxPool2d(kernel_size=3, ceil_mode=True)进行池化。
import torch
from torch import nn
from torch.nn import MaxPool2d
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32)
#如果不reshape的话就会是二维形式。[5,5]形式
input=torch.reshape(input,(-1,1,5,5))
#reshape之后就是 [1,1,5,5]四维形式
print(input.shape)
#神经网络的搭建
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self, input):
output=self.maxpool1(input)
return output
#创建神经网络
tudui=Tudui()
output=tudui(input)
print(output)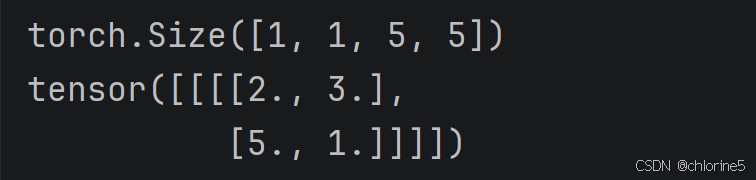

显示在tensorboard上的模板代码:
使用 CIFAR-10 数据集 ,通过 DataLoader 加载图片,经过池化层,并用 TensorBoard 可视化输入和输出。
import torch import torchvision.datasets from torch import nn from torch.nn import MaxPool2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter #准备测试数据集以及加载数据 dataset=torchvision.datasets.CIFAR10(root='./data',train=False, download=True,transform=torchvision.transforms.ToTensor()) dataloader=DataLoader(dataset=dataset,batch_size=64) #神经网络的搭建 class Tudui(nn.Module): def __init__(self): super(Tudui, self).__init__() self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True) def forward(self, input): output=self.maxpool1(input) return output #创建神经网络 tudui=Tudui() #显示在tensorboard上 writer=SummaryWriter("logs_maxpool") step=0 for data in dataloader: imgs,targets=data writer.add_images('input',imgs,step) output = tudui(imgs) writer.add_images('output',output,step) step = step + 1 writer.close()
池化(Pooling) 是一种下采样 操作,目的是缩小图片尺寸、减少计算量、提取主要特征。
我们看到池化后的output就是模糊的画面,但是也能看到轮廓的样子。
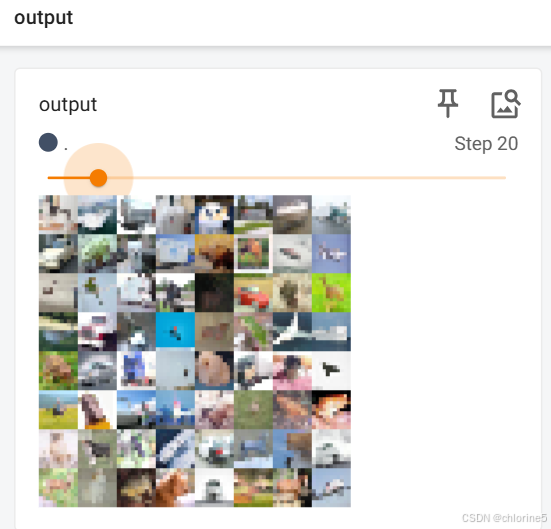
🚩非线性激活
ReLU(Rectified Linear Unit)是一种激活函数,不改变图片尺寸,只改变数值
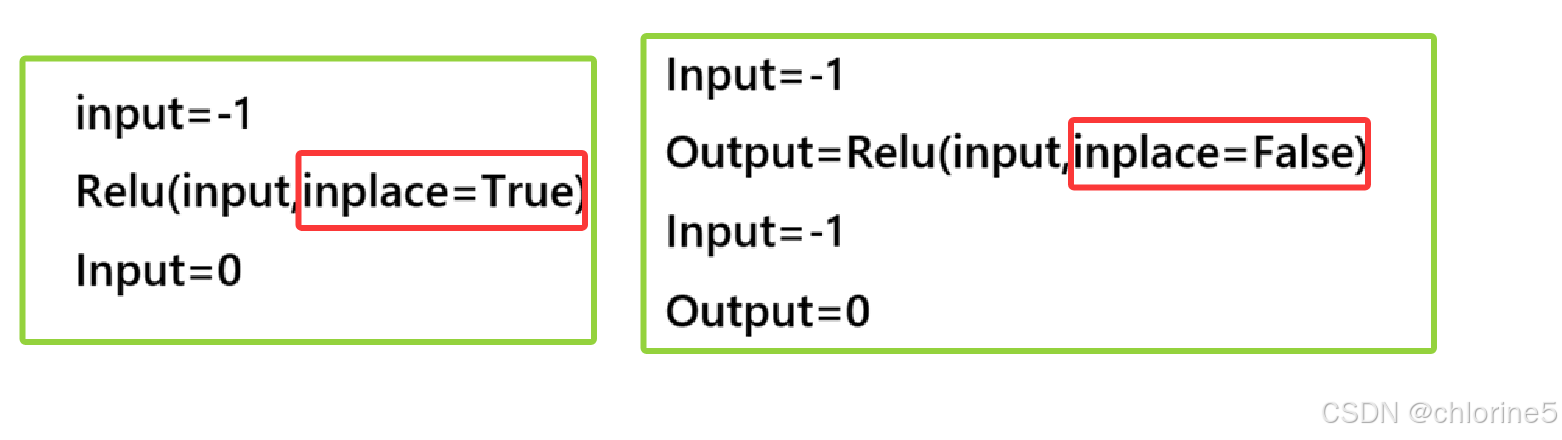
❗inplace
是否覆盖input.如果为true则覆盖,否则不覆盖.保留原始的数据,不被丢失。
📝Sigmoid激活函数
ReLU 和 Sigmoid 激活函数的作用,以下代码可以展示:
可视化 Sigmoid 激活函数对图片的影响,通过 TensorBoard 对比输入和输出图片。
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.tensorboard import SummaryWriter
input=torch.tensor([[1,-0.5],
[-1,3]])
input=torch.reshape(input,(-1,1,2,2))
print(input.shape)
#加载数据,准备数据集,每64个数据进行准备
dataset= torchvision.datasets.CIFAR10(root='data',train=False,download=True,
transform=torchvision.transforms.ToTensor())
dataloader = torch.utils.data.DataLoader(dataset=dataset,batch_size=64)
#神经网络的搭建
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1=ReLU() # ReLU 激活函数
self.sigmoid1=Sigmoid() # Sigmoid 激活函数
def forward(self,input):
output=self.sigmoid1(input) #Sigmoid():f(x) = 1/(1+e^(-x)) 激活该函数
return output #返回处理后的结果
#创建神经网络
tudui=Tudui()
step=0
writer=SummaryWriter("logs_relu")
for data in dataloader:
imgs,targets=data
writer.add_images("input",imgs,global_step=step)
output=tudui(imgs)
writer.add_images("output",output,global_step=step)
step=step+1
writer.close()🚩线性层
❗第一部分:数据准备及加载
#准备数据
dataset=torchvision.datasets.CIFAR10(root='./data',train=False,
download=True,transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset=dataset,batch_size=64)❗第二部分:网络定义
#神经网络的搭建
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
# 全连接层:196608 输入特征 → 10 输出特征
self.linear1=Linear(in_features=196608,out_features=10)
输入:一个196608维的向量
输出:一个10维的向量
作用:将高维特征映射到10个类别分数
这是一个数学上的线性变换,类似 y = Wx + b,其中W是10×196608的矩阵。
❗第三部分:前向传播
def forward(self,input):
output=self.linear1(input)
return output❗第四部分:创建网络
#创建神经网络
tudui=Tudui()❗第五部分:数据处理循环
for data in dataloader:
imgs,targets=data
print(imgs.shape) #torch.Size([64, 3, 32, 32])
output=torch.reshape(imgs,(1,1,1,-1)) # [1, 1, 1, 196608]
output=torch.flatten(imgs) #将张量完全展平成一维 # [196608]
print(output.shape)
output=tudui(output)
print(output.shape) #torch.Size([1, 1, 1, 10])