英伟达CEO黄仁勋与SK海力士宣布多年期技术合作,共同开发下一代AI内存。SK海力士到2030年将晶圆产能翻倍,但黄仁勋说还不够。
这背后反映的,是AI算力瓶颈从芯片转向内存的技术趋势。HBM(高带宽内存)已经成为AI训练的关键瓶颈,下一代技术路线怎么走?
一、HBM的技术演进
HBM从第一代发展到现在的HBM3E,每一代都在提升带宽和容量:
- HBM1,128GB/s带宽,2015年量产
- HBM2,256GB/s带宽,2016年量产
- HBM2E,307GB/s带宽,2020年量产
- HBM3,819GB/s带宽,2022年量产
- HBM3E,1.2TB/s带宽,2024年量产
带宽提升的背后,是堆叠层数的增加和接口速度的提升。HBM3E已经堆叠到12层,接口速度达到9.6Gbps。
但问题是,这种提升方式已经接近物理极限。
二、下一代AI内存的技术挑战
下一代AI模型,参数规模从千亿级向万亿级演进,训练数据从TB级向PB级演进。对内存带宽的要求,呈指数级增长。
现有的技术路线,面临几个瓶颈:
1. 堆叠层数限制
硅通孔(TSV)技术是目前HBM堆叠的核心。但层数越多,TSV的制造难度越大,良率越低,成本越高。12层已经接近当前工艺的极限,再往上堆,性价比急剧下降。
2. 接口速度瓶颈
HBM3E的接口速度是9.6Gbps,下一代目标可能是12Gbps或更高。但信号完整性、功耗、散热,都是挑战。频率越高,信号衰减越严重,误码率越高。
3. 容量与带宽的匹配
GPU的算力增长速度快于内存带宽的增长速度。这意味着,GPU越来越"饥饿",内存越来越"喂不饱"。这种不平衡,限制了整体算力效率。
三、可能的技术方向
英伟达和SK海力士的合作,目标可能是以下几个方向:
1. HBM4架构重构
从目前的2.5D封装,转向3D封装。把逻辑层和存储层垂直堆叠,而不是水平并排。这样可以进一步缩短信号传输距离,提升带宽。
但3D封装的散热问题更严峻。存储层和逻辑层叠在一起,热量集中,需要全新的散热方案。
2. 新型存储介质
探索除了DRAM之外的新型存储介质。比如MRAM(磁阻RAM)、ReRAM(阻变RAM)、PCM(相变存储器)。这些新型存储器,理论上可以实现更高的密度和更低的功耗。
但问题是,这些技术还不够成熟,离量产还有距离。而且与现有生态的兼容性,需要重新建立。
3. 近存计算架构
把计算单元和存储单元更紧密地集成。不是CPU-内存分离的架构,是计算在存储附近完成。这样可以大幅减少数据搬运,提升能效。
SK海力士提出的Processing-in-Memory(PIM)概念,就是这个方向。在内存芯片内部集成简单的计算单元,完成一些基本的AI运算。
四、对开发者的影响
AI内存技术迭代加速,信息密度爆炸。开发者每天要看大量的技术论文、专利、发布会视频、行业分析。
我跟踪这些动态,用Ai好记辅助信息处理。把技术研讨会视频丢进去,自动转录成文字,生成沉浸式阅读笔记,自动截取PPT画面。转录完成后,搜索关键词定位到技术路线。
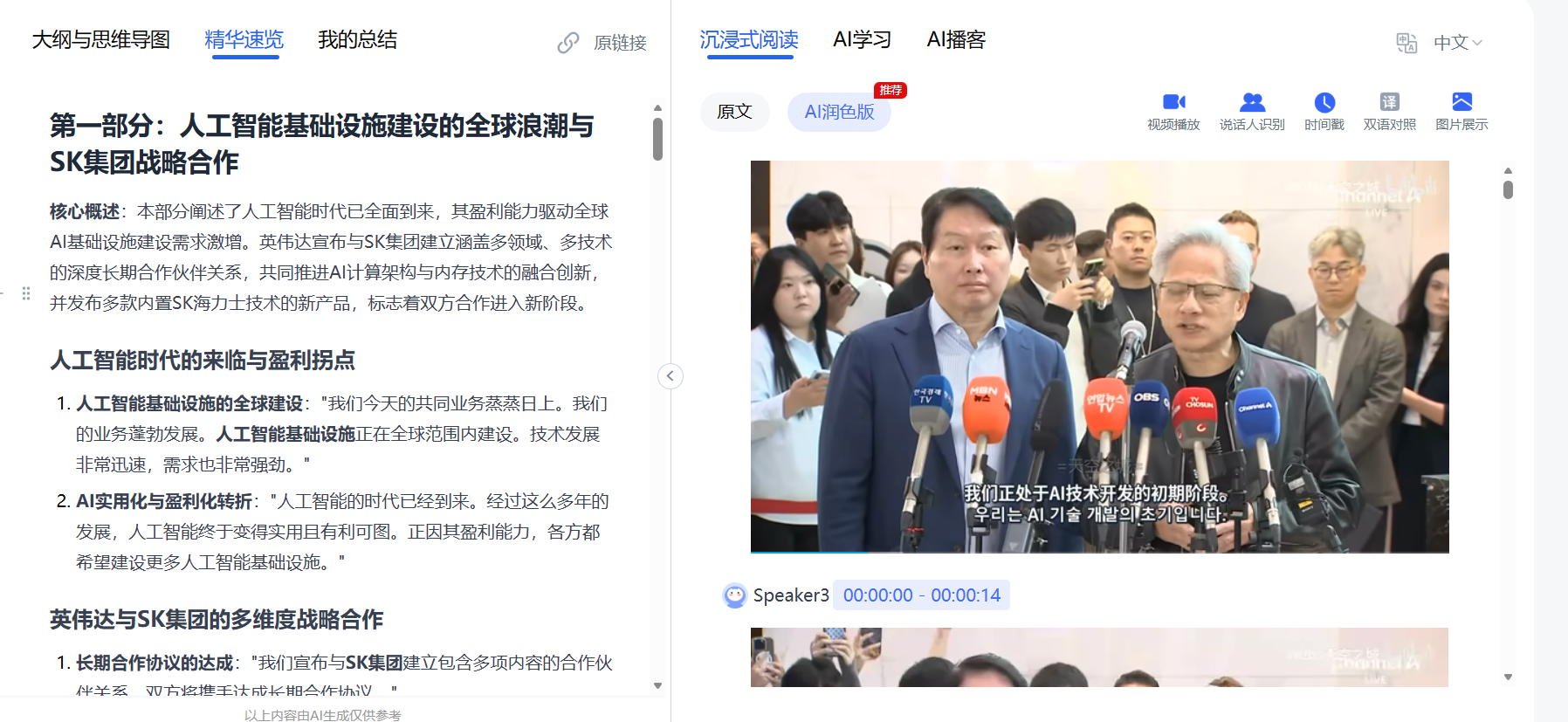
精华速览功能,AI几秒提炼核心要点。一场复杂的技术研讨会,几分钟抓住核心框架。
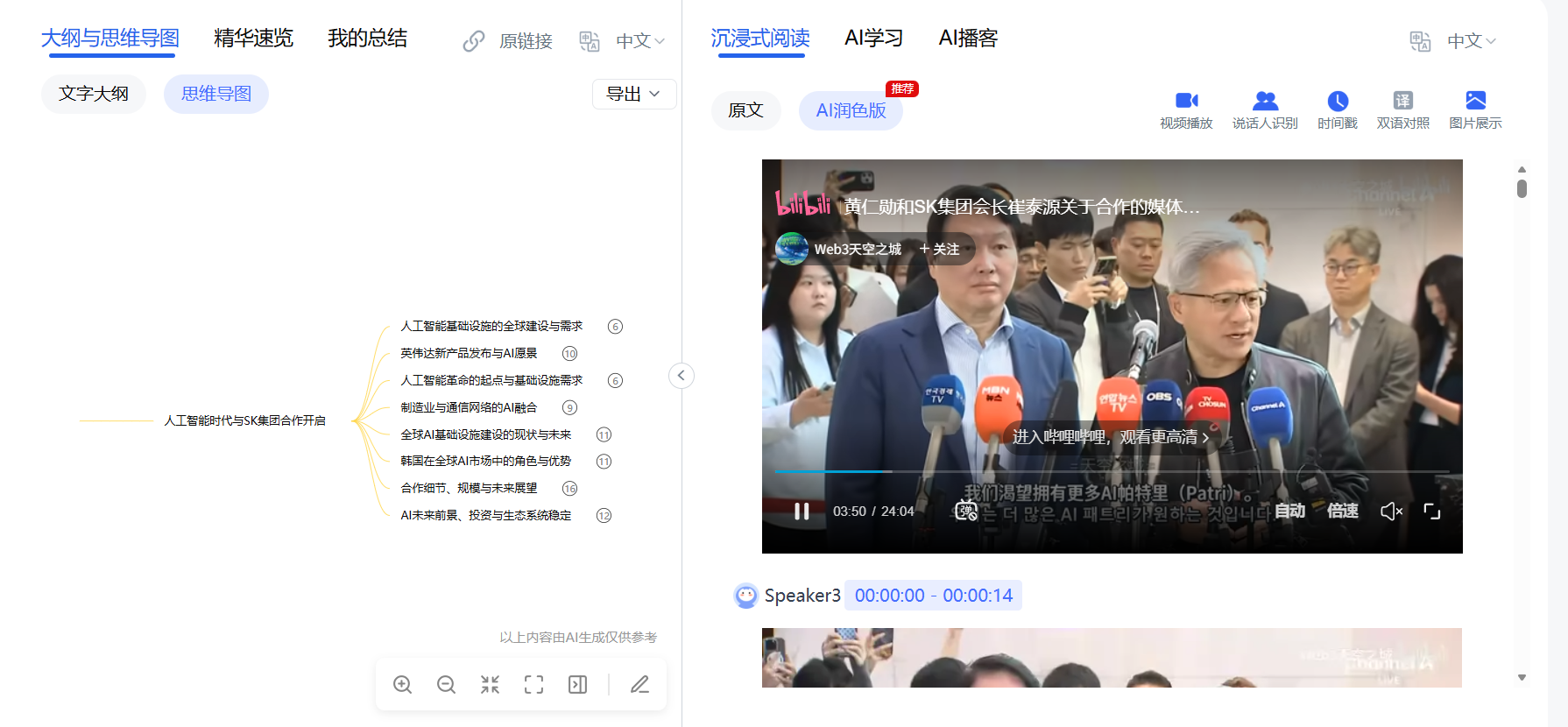
思维导图大纲功能,自动生成多层级思维导图,节点可跳转对应内容。复杂的技术架构,几分钟理清脉络。
支持22国语言翻译,外文技术视频也能处理。双语对照润色翻译,准确度比市场平均水平高2-4倍。
导出Markdown、Xmind、PDF等格式,方便进不同笔记系统。
处理速度取决于视频长度,偶尔超过1.5小时的视频会慢一点。但结构化深度比较高,可能这就是取舍。
写在最后
英伟达和SK海力士的合作,标志着AI内存技术进入新阶段。HBM4、3D封装、新型存储介质、近存计算,都是可能的方向。
2026年,AI内存技术迭代加速。开发者现在关注技术路线,不算早。