一、引言
Hudi 提供两种表类型,让用户根据自身的 SLA 要求在「写入放大」与「读取放大」之间做出显式权衡,它们的本质区别在于 数据写入时是否立即合并更新到基础文件(Base File)。

二.Copy-on-Write(COW)表
COW 表在每次写入(Insert/Update/Delete)时,会将受影响的文件进行原地重写,即找到包含目标记录的 Parquet 文件,将新数据与旧数据合并后,生成一个新版本的 Parquet 文件。
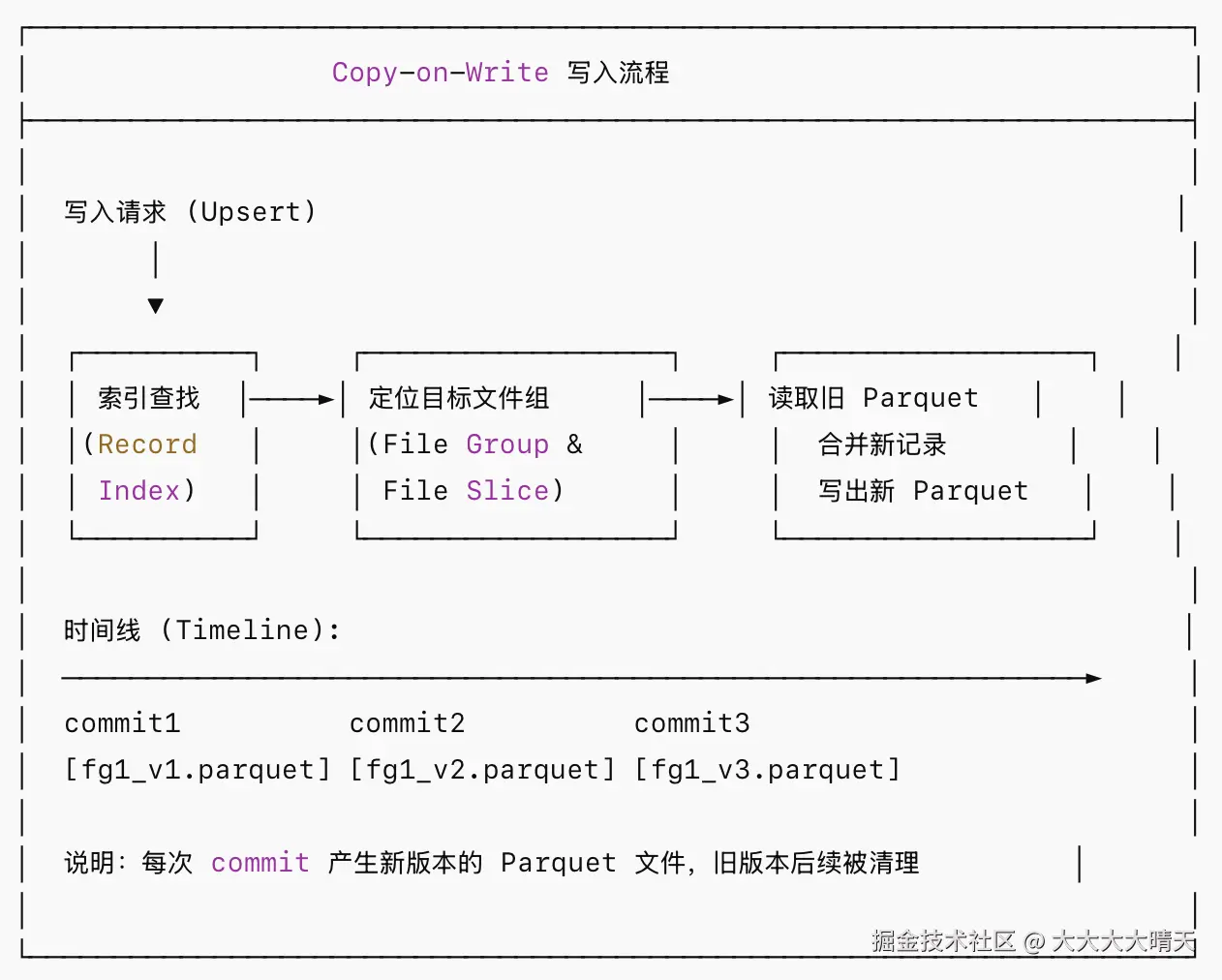
文件布局:
ini
table_path/
├── .hoodie/ # 元数据目录(Timeline)
│ ├── 20240101120000.commit # 已完成的提交
│ ├── 20240101130000.commit
│ └── ...
├── partition=2024-01-01/
│ ├── file_group_1/
│ │ └── base_file_v3.parquet # 仅保留最新的 base file
│ ├── file_group_2/
│ │ └── base_file_v2.parquet
│ └── ...
└── ...特性表现:
| 维度 | 表现 |
|---|---|
| 写入放大 | 高 --- 每次更新需重写整个 Parquet 文件 |
| 读取放大 | 低 --- 读取时无需合并,直接扫描 Parquet |
| 查询延迟 | 低 --- 数据已预合并,等同于纯 Parquet 扫描 |
| 写入延迟 | 高 --- 需要读取-合并-重写的完整流程 |
| 存储效率 | 中等 --- 无额外 log 文件开销 |
三.Merge-on-Read(MOR)表
MOR 表将写入操作分为两个阶段:
- 写入阶段:增量更新以 日志文件(Log File) 的形式追加写入,不修改已有的 Base File
- 压缩阶段(Compaction):后台异步(或同步)将 Log File 与 Base File 合并,生成新的 Base File
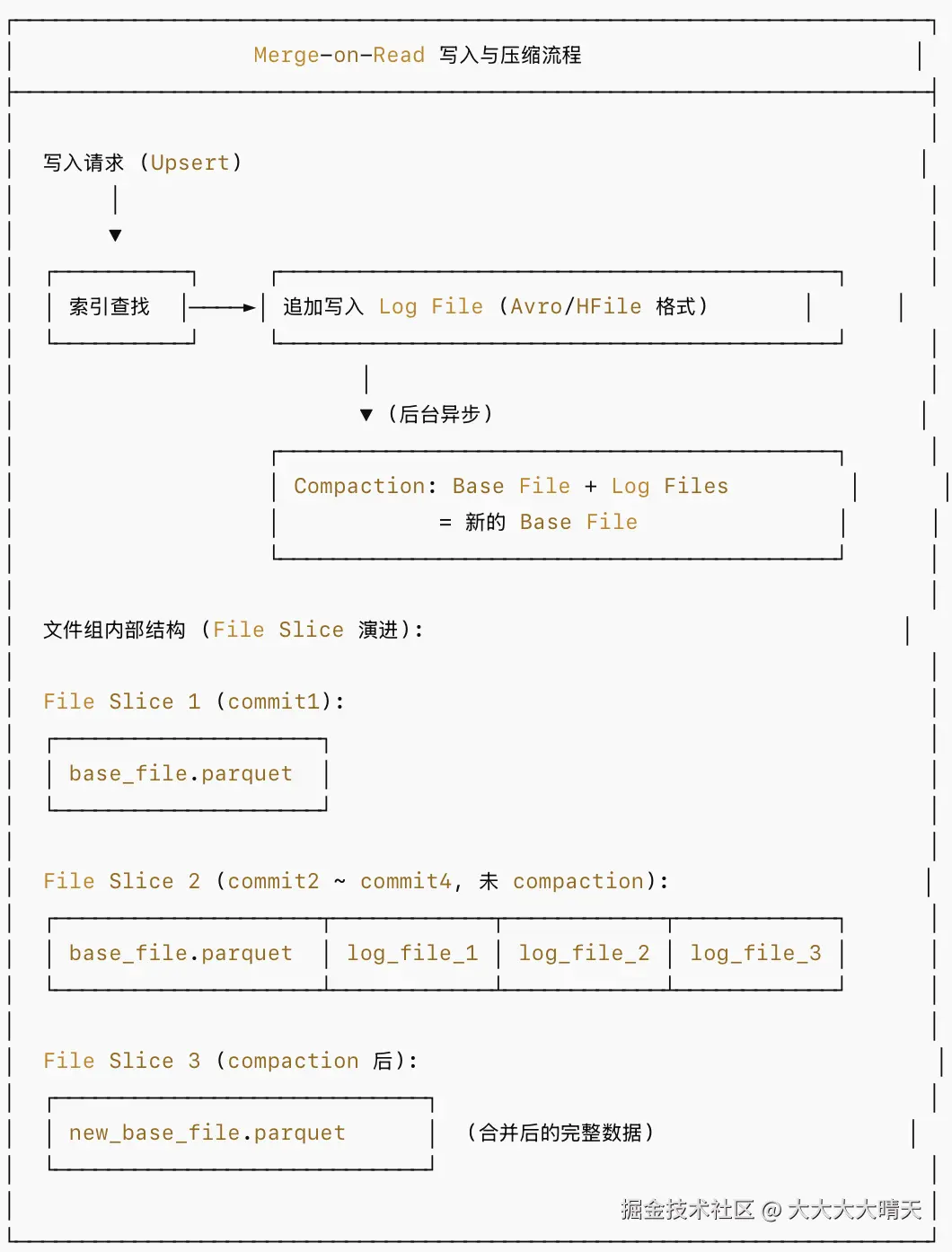
文件布局:
ini
table_path/
├── .hoodie/
│ ├── 20240101120000.deltacommit # deltacommit 表示 MOR 的增量提交
│ ├── 20240101130000.deltacommit
│ ├── 20240101140000.commit # compaction 完成后的 commit
│ └── ...
├── partition=2024-01-01/
│ ├── file_group_1/
│ │ ├── base_file.parquet # 基础文件
│ │ ├── .log_file_1 # 增量日志
│ │ ├── .log_file_2 # 增量日志
│ │ └── ...
│ └── ...
└── ...特性表现:
| 维度 | 表现 |
|---|---|
| 写入放大 | 低 --- 仅追加写 Log File |
| 读取放大 | 可变 --- 取决于查询类型和 compaction 频率 |
| 写入延迟 | 低 --- 追加写,无需重写 base file |
| 查询延迟 | Snapshot Query 较高(需实时合并),Read Optimized Query 低 |
| 存储效率 | 有额外 log 文件开销,compaction 后恢复 |
四.COW vs MOR 对比总览
sql
┌──────────────────────────────────────────────────────────────────┐
│ COW vs MOR 核心对比 │
├────────────────┬──────────────────────┬──────────────────────────┤
│ 维度 │ Copy-on-Write │ Merge-on-Read │
├────────────────┼──────────────────────┼──────────────────────────┤
│ 数据写入方式 │ 同步重写 Base File │ 追加 Log File │
│ 数据读取方式 │ 直接读 Base File │ Base + Log 实时合并 │
│ 写入延迟 │ 较高 │ 较低 │
│ 查询性能 │ 最优(无合并开销) │ Snapshot较慢/RO Query快 │
│ 适用写入模式 │ 批量写入/低频更新 │ 高频更新/流式写入 │
│ Compaction │ 不需要 │ 需要(异步/同步) │
│ 文件类型 │ 仅 Parquet │ Parquet + Log (Avro等) │
│ Timeline 标记 │ commit │ deltacommit + commit │
└──────────────────────────────────────────────────────────────────┘五、最佳实践
1.COW 表最佳实践
ini
// Hudi 1.x 配置示例 - COW 表
hoodie.table.type = COPY_ON_WRITE
// 文件大小控制 - 避免小文件问题
hoodie.parquet.max.file.size = 128MB
hoodie.parquet.small.file.limit = 100MB
// 索引选择 - 影响 upsert 性能
hoodie.index.type = BUCKET // 大表推荐 Bucket Index
// hoodie.index.type = BLOOM // 中小表可用 Bloom Index
// 合理设置并行度
hoodie.upsert.shuffle.parallelism = 200
hoodie.insert.shuffle.parallelism = 200
// Clustering 优化读取性能
hoodie.clustering.inline = true
hoodie.clustering.inline.max.commits = 4- 控制写入批次大小,避免过于频繁的小批次写入导致大量文件重写
- 使用 Clustering 定期整理文件布局,优化查询时的数据局部性
- 选择合适的索引类型,Bucket Index 对大表性能更稳定
- 合理设置文件大小,过小导致文件过多,过大导致单次重写代价高
2.MOR 表最佳实践
ini
// Hudi 1.x 配置示例 - MOR 表
hoodie.table.type = MERGE_ON_READ
// Log 文件控制
hoodie.logfile.max.size = 1GB
hoodie.logfile.data.block.max.size = 256MB
// Compaction 策略 - 核心配置
hoodie.compact.inline = false // 生产环境建议异步 compaction
hoodie.compact.inline.max.delta.commits = 5 // 每 5 次 delta commit 触发
// Compaction 策略选择
hoodie.compaction.strategy = org.apache.hudi.table.action.compact.strategy.BoundedIOCompactionStrategy
hoodie.compaction.target.io = 512000 // 限制单次 compaction IO
// 索引选择
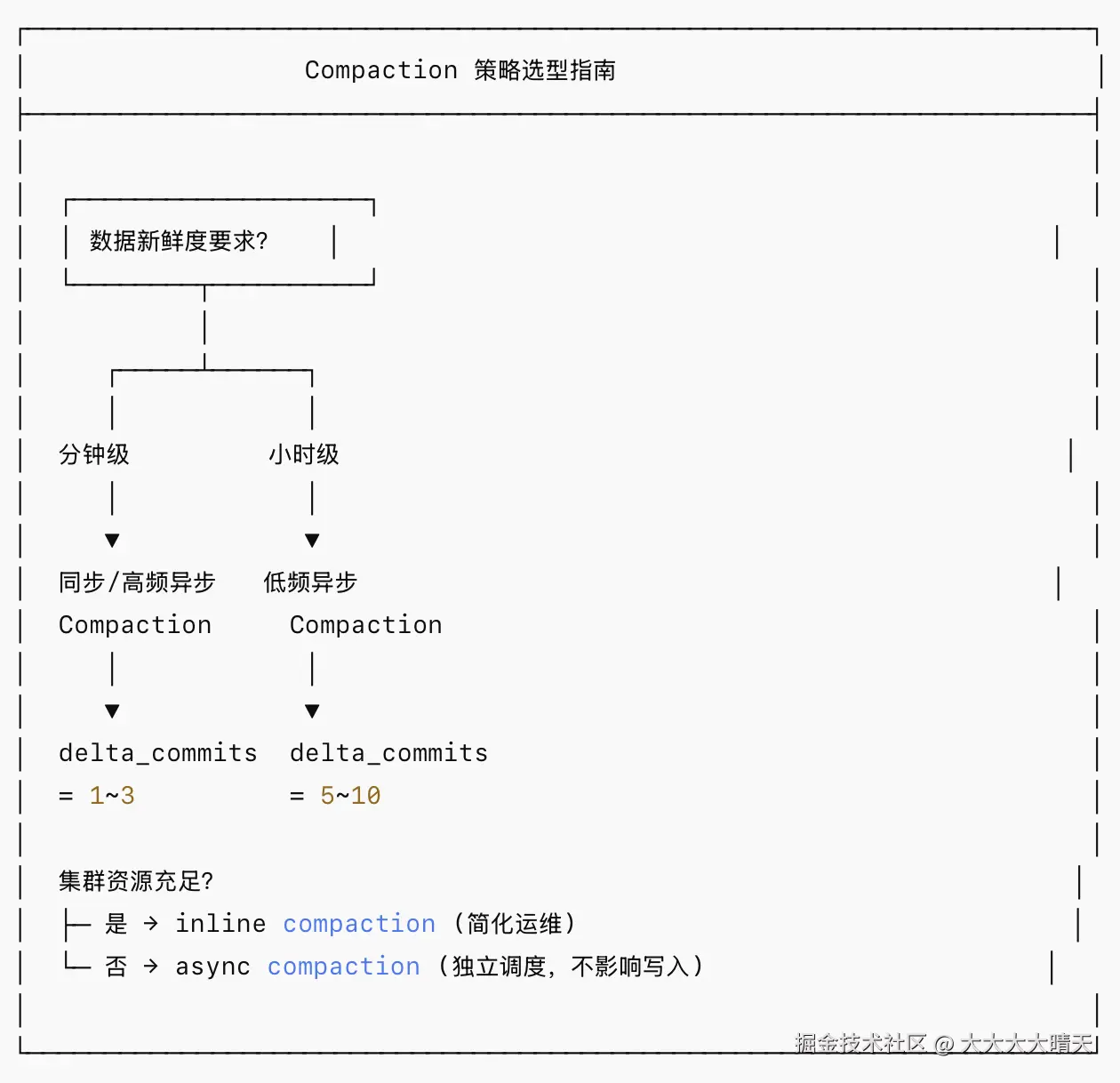
hoodie.index.type = BUCKET- Compaction 策略是 MOR 表的核心:需要根据数据新鲜度需求和集群资源合理调度
- 生产环境建议使用 异步 Compaction,避免阻塞写入流程
- 监控 Log File 积压情况,过多未 compact 的 log 会严重影响 Snapshot Query 性能
- 对于 Read Optimized Query 的场景,确保 Compaction 频率满足数据新鲜度 SLA
3.Compaction 调优策略