0、介绍
2021 年,北京邮电大学的研究团队发布了LLVIP 数据集,首次为低光照下的可见光-红外多模态任务提供了大规模、高精度的统一基准。

基本信息:
- 总样本量:15488对严格对齐的图像(共30976张)
- 分辨率:可见光 1920×1080,红外 1280×720(统一裁剪为 1080×720)
- 场景:26 个不同城市街道场景,全部拍摄于傍晚 6 点至 10 点的极暗环境
- 标注:所有图像均包含行人边界框标注(person)
- 官方划分 :训练集(12025 对)+ 测试集(3463对);测试集需自己从训练集中划分!
- 数据集下载地址 :https://bupt-ai-cz.github.io/LLVIP/
- 论文链接: LLVIP: A Visible-infrared Paired Dataset for Low-light Vision | IEEE Conference Publication | IEEE Xplore
为什么需要 LLVIP?
- TNO 数据集:仅 261 对图像,样本量太小,完全不适合深度学习
- KAIST/FLIR 数据集:面向自动驾驶,驾驶视角且夜间图像亮度仍较高
- OSU 数据集:全部采集于白天,红外图像完全没有优势
- CVC-14 数据集:图像时间不对齐,无法用于图像融合任务
与主流数据集对比:
| 数据集 | 样本量 | 是否对齐 | 场景 | 视角 | 低光照程度 | 行人标注 |
|---|---|---|---|---|---|---|
| TNO | 261 对 | √ | 军事 | 地面 | 中等 | 无 |
| KAIST | 4750 对 | √ | 交通 | 驾驶 | 弱 | 有 |
| FLIR | 5258 对 | × | 交通 | 驾驶 | 弱 | 有 |
| CVC-14 | 849 对 | × | 交通 | 驾驶 | 弱 | 有 |
| LLVIP | 16836 对 | √ | 街道 | 监控 | 极暗 | 有 |
优势:
- 时空严格对齐:采用双目相机同步采集,经过半手动配准,像素级对齐,完美支持图像融合和有监督图像翻译
- 纯低光照场景:绝大多数图像拍摄于无路灯或极弱光照的环境,红外图像的互补作用极其明显
- 高精度行人标注:首创 "红外标注反向映射" 方法,解决了低光照可见光图像标注难的问题
- 大规模高质量:1.6 万对样本是当时同领域最大的数据集,且图像质量远高于其他数据集
图例:

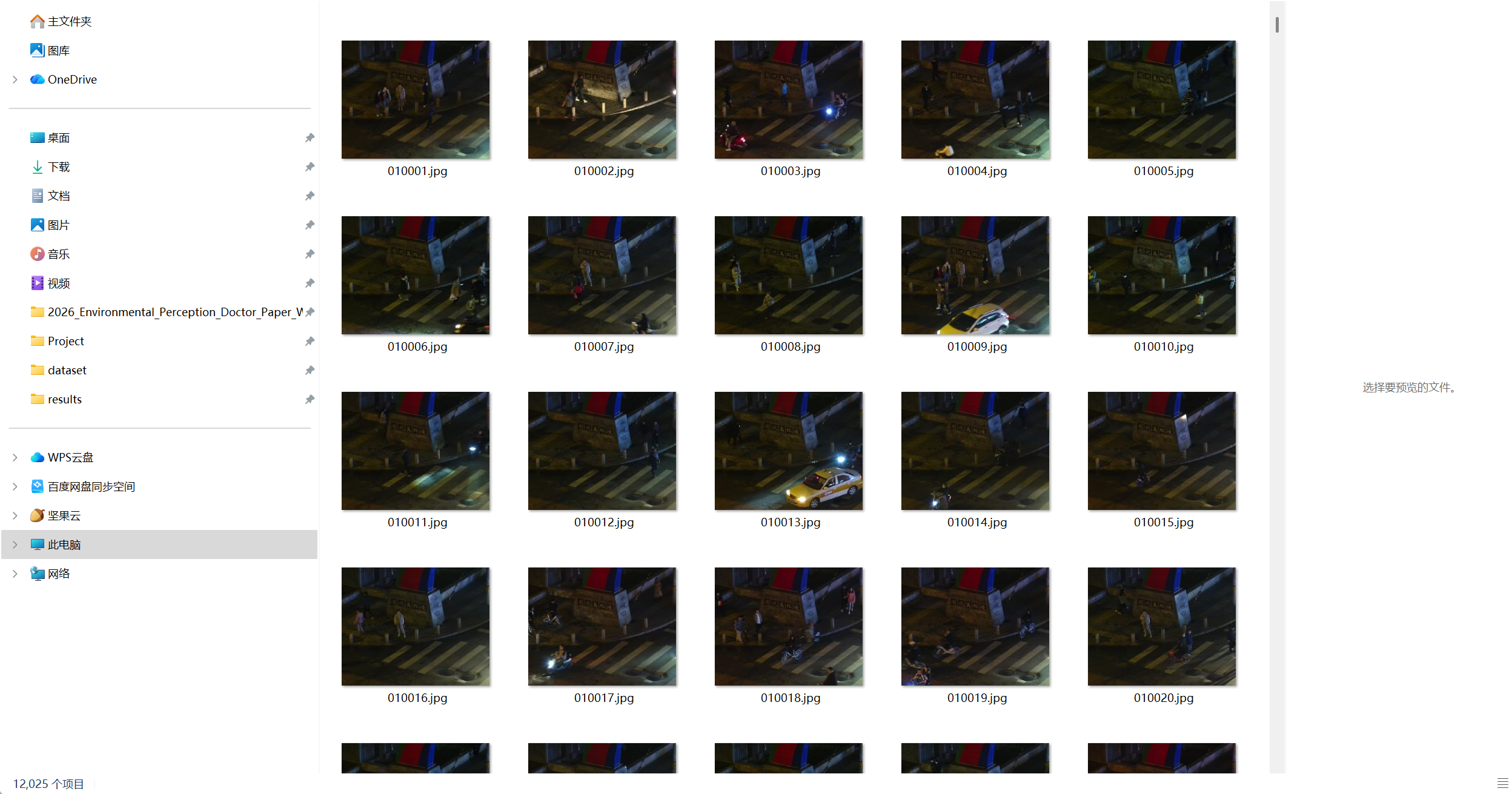
为了用yolo模型对数据集进行测试,需转换格式并划分数据集
1、下载数据集
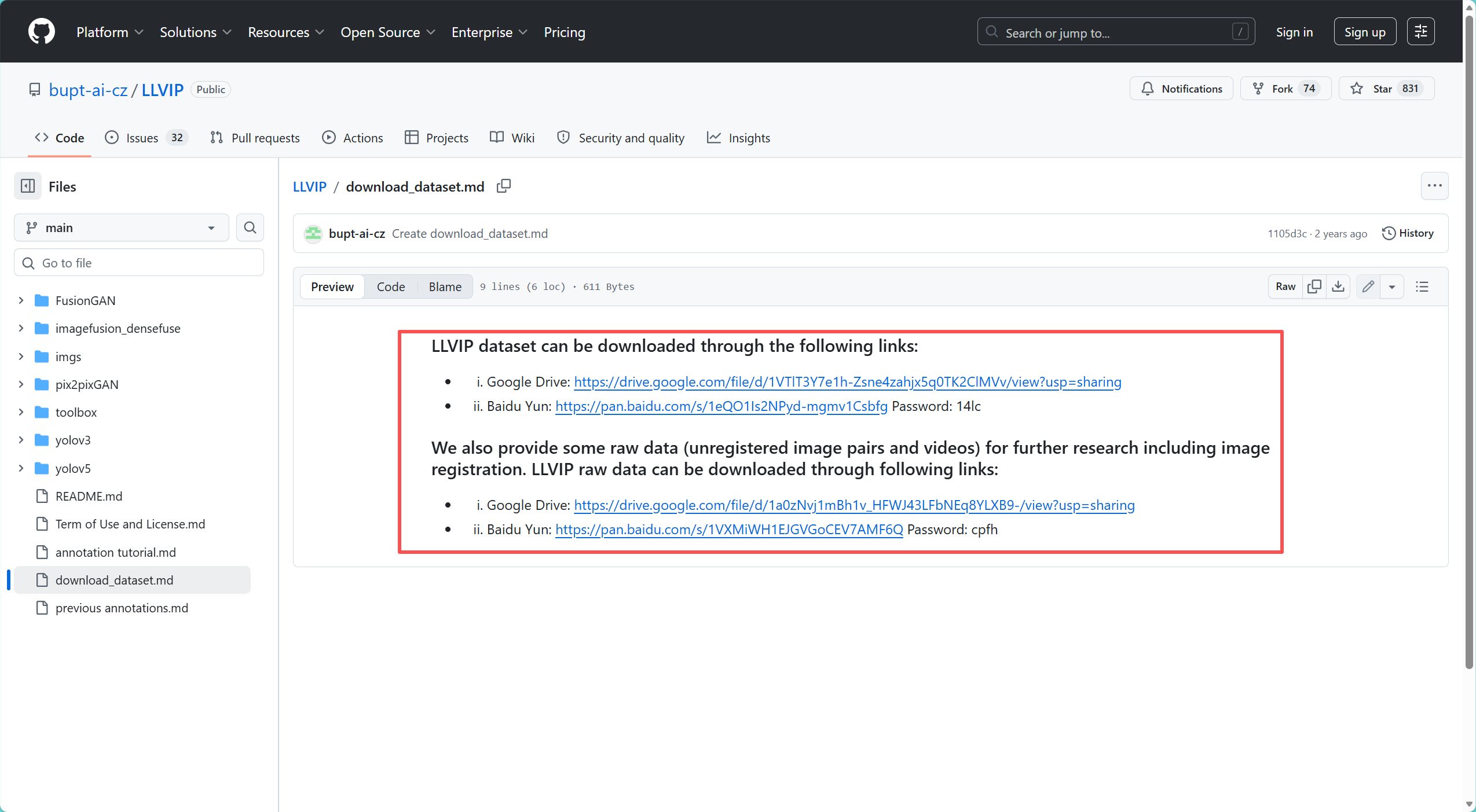
下载得到压缩文件,解压后得到以下文件夹

annotations是voc标签
infrared是红外光图像
visible是可见光图像
2、转换数据集格式(VOC2YOLO)
参考:目标检测-数据处理,YOLO2JSON、VOC2YOLO、YOLO2VOC、JSON2YOLO-CSDN博客
注意:此处有个坑,原始的train图像文件夹下的
100030.jpg
100033.jpg
这两个图像没有目标,所以可以把它们删除,不然数据集和标签数量不对等

3、划分数据集
按照train:val:test=7:1:2划分,但由于test已经划分好了,3463/15488=0.2236,只能让val的比例尽可能为0.1,差不多就是1804张,则train就是10218张
划分数据集参考:
目标检测-数据划分(YOLO格式)_yolo数据集划分代码-CSDN博客
最终划分结果为:
|-------|-------|
| train | 10218 |
| val | 1805 |
| test | 3463 |

4、可视化验证

