文章目录
引言
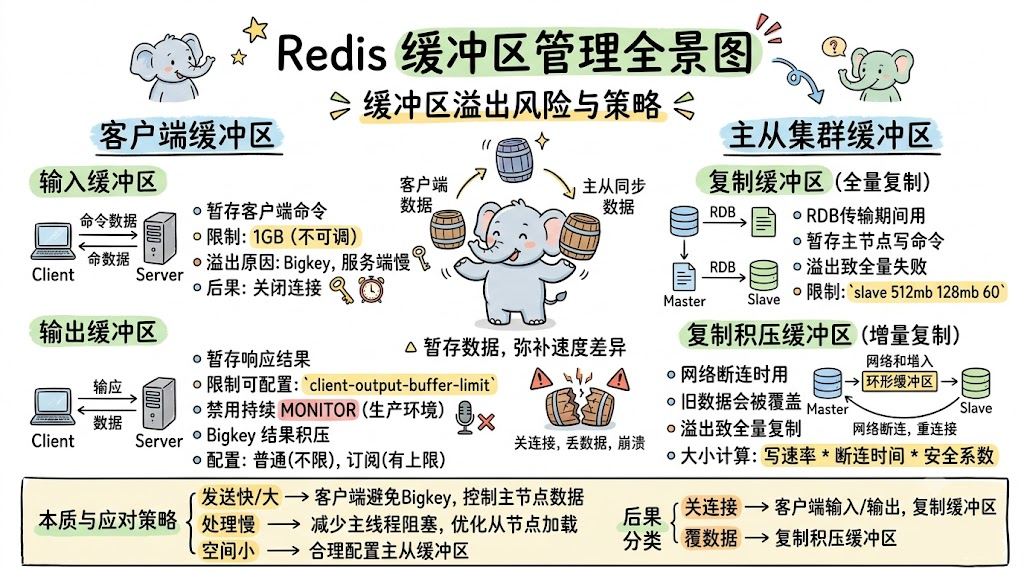
缓冲区是Redis中一个看似简单却极易引发严重问题的机制。它的职责是暂存命令数据,弥补发送方和接收方之间的速度差异。但如果管理不当,缓冲区溢出会导致客户端连接被强制关闭、数据丢失、甚至Redis实例崩溃。
Redis中的缓冲区主要出现在两个场景:客户端与服务器端的通信过程,以及主从节点间的数据同步过程。本文将逐一分析各类缓冲区的溢出风险和应对策略。
客户端输入缓冲区
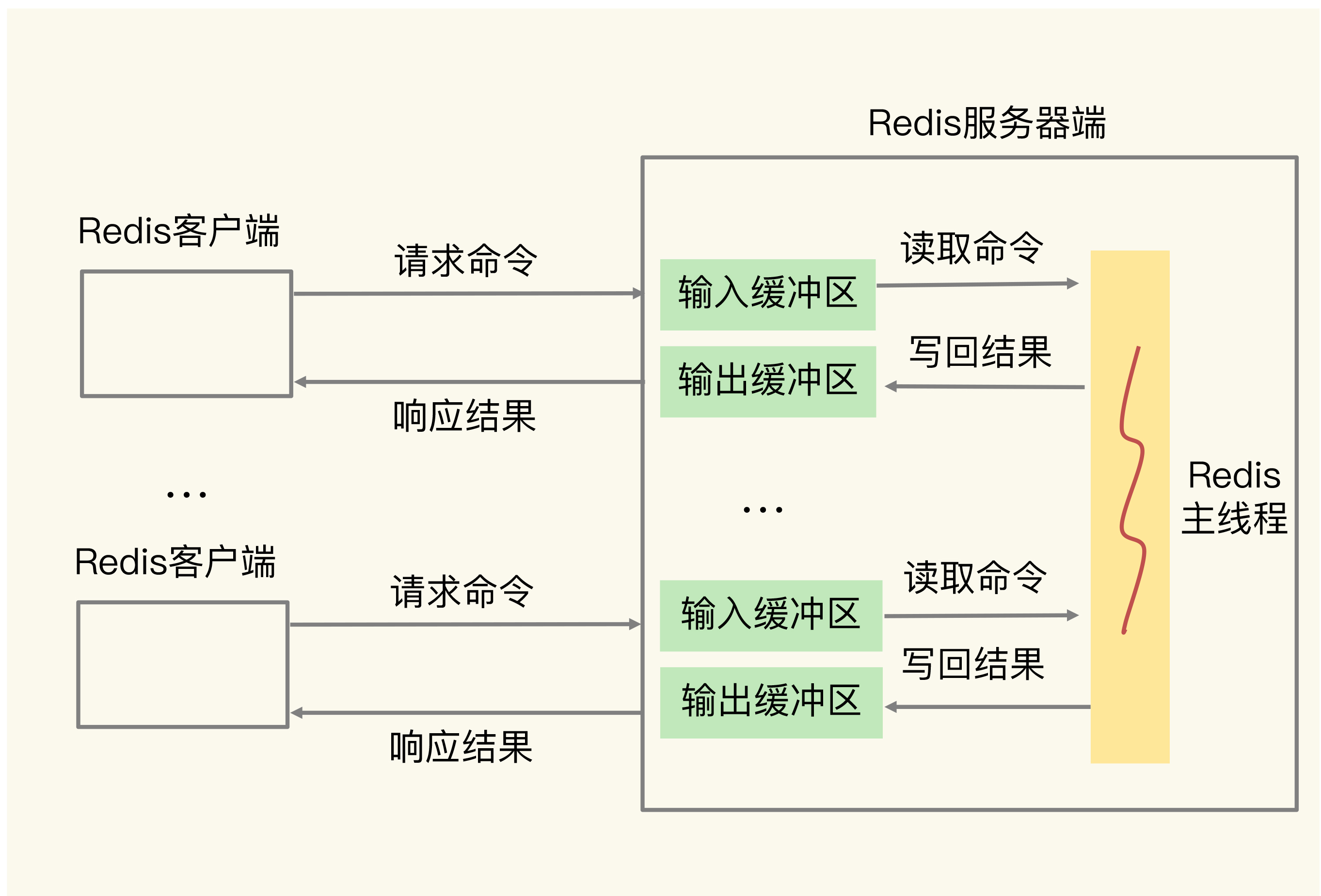
工作机制
Redis服务器端为每个连接的客户端维护一个输入缓冲区。客户端发送的命令先暂存在输入缓冲区中,Redis主线程再从中读取命令进行处理。
溢出的两种原因
- 写入bigkey:一次性写入百万级别的集合数据,命令本身体积巨大
- 服务端处理过慢:Redis主线程出现间歇性阻塞,无法及时消费缓冲区中的命令,导致积压
如何监控
使用CLIENT LIST命令查看每个客户端的缓冲区使用情况:
bash
redis-cli CLIENT LIST输出中需要关注的字段:
- cmd:客户端最近执行的命令
- qbuf:输入缓冲区已使用的大小
- qbuf-free:输入缓冲区剩余可用空间
当qbuf很大而qbuf-free接近0时,说明输入缓冲区即将溢出。一旦溢出,Redis会直接关闭该客户端连接。
关键限制
Redis的客户端输入缓冲区大小上限硬编码为1GB,无法通过配置修改。这个限制是合理的:
- 1GB对绝大部分正常请求已经足够
- 如果允许更大,可能因为单个客户端占用过多内存导致Redis崩溃
应对策略
由于无法调整输入缓冲区大小,只能从源头控制:
- 避免写入bigkey
- 避免Redis主线程阻塞(参考前文的变慢诊断方法)
多客户端的内存压力
当多个客户端同时连接,它们的输入缓冲区内存总和可能超过maxmemory配置,触发数据淘汰。更严重的情况下,会导致OOM(内存溢出),Redis直接崩溃。
客户端输出缓冲区
结构组成
Redis为每个客户端设置的输出缓冲区包含两部分:
- 固定缓冲空间:16KB,用于暂存OK响应和错误信息
- 动态缓冲空间:可动态增长,用于暂存大小可变的查询结果
三种溢出场景
场景一:返回bigkey的大量结果
查询一个包含百万元素的集合,返回结果会占满输出缓冲区。
场景二:MONITOR命令
MONITOR命令会持续输出Redis执行的所有命令操作:
bash
redis-cli MONITOR
1617123456.789012 [0 127.0.0.1:6379] "SET" "key1" "value1"
1617123456.789013 [0 127.0.0.1:6379] "GET" "key2"
...输出结果会持续占用输出缓冲区,最终导致溢出。MONITOR只应在调试环境中使用,禁止在生产环境持续运行。
场景三:缓冲区大小设置不合理
输出缓冲区配置
通过client-output-buffer-limit配置项控制输出缓冲区,需要区分客户端类型。
普通客户端:
bash
client-output-buffer-limit normal 0 0 0三个0分别表示:缓冲区大小上限、持续写入量上限、持续写入时间上限,全部设为0表示不限制。
普通客户端采用阻塞式发送(发一个命令等一个响应),输出缓冲区一般不会积压太多数据,所以通常不设限制。
订阅客户端:
bash
client-output-buffer-limit pubsub 8mb 2mb 60含义:
8mb:缓冲区大小上限,超过则直接关闭连接2mb 60:如果连续60秒内写入量超过2MB,也关闭连接
订阅客户端不是阻塞式通信------频道有消息就会推送,如果消息量大,缓冲区会快速增长,所以需要设置限制。
主从集群中的缓冲区
主从复制涉及两种缓冲区:全量复制时的复制缓冲区,和增量复制时的复制积压缓冲区。
复制缓冲区(全量复制)
工作机制:主节点向从节点传输RDB文件期间,继续接收客户端写命令。这些写命令暂存在复制缓冲区中,等RDB传输完成后再发送给从节点执行。主节点为每个从节点维护一个独立的复制缓冲区。
溢出风险:如果从节点接收和加载RDB较慢,同时主节点写入量很大,复制缓冲区就会持续增长。溢出后,主节点会直接关闭与从节点的连接,导致全量复制失败。
配置方法:
bash
client-output-buffer-limit slave 512mb 128mb 60含义:
512mb:缓冲区大小上限128mb 60:连续60秒写入超过128MB则关闭连接
容量估算:假设每条写命令1KB,512MB的缓冲区可以累积约512K条命令。同时,主节点在全量复制期间可承受的写命令速率上限约为2000条/秒(128MB / 1KB / 60秒)。
实际配置时,需要根据写命令大小和业务写入速率来估算缓冲区是否够用。
避免溢出的措施:
- 控制主节点数据量在2~4GB,加快全量同步速度
- 根据实际写负载设置合理的缓冲区大小
- 控制从节点数量------每个从节点都需要一个独立的复制缓冲区,从节点越多,主节点内存开销越大
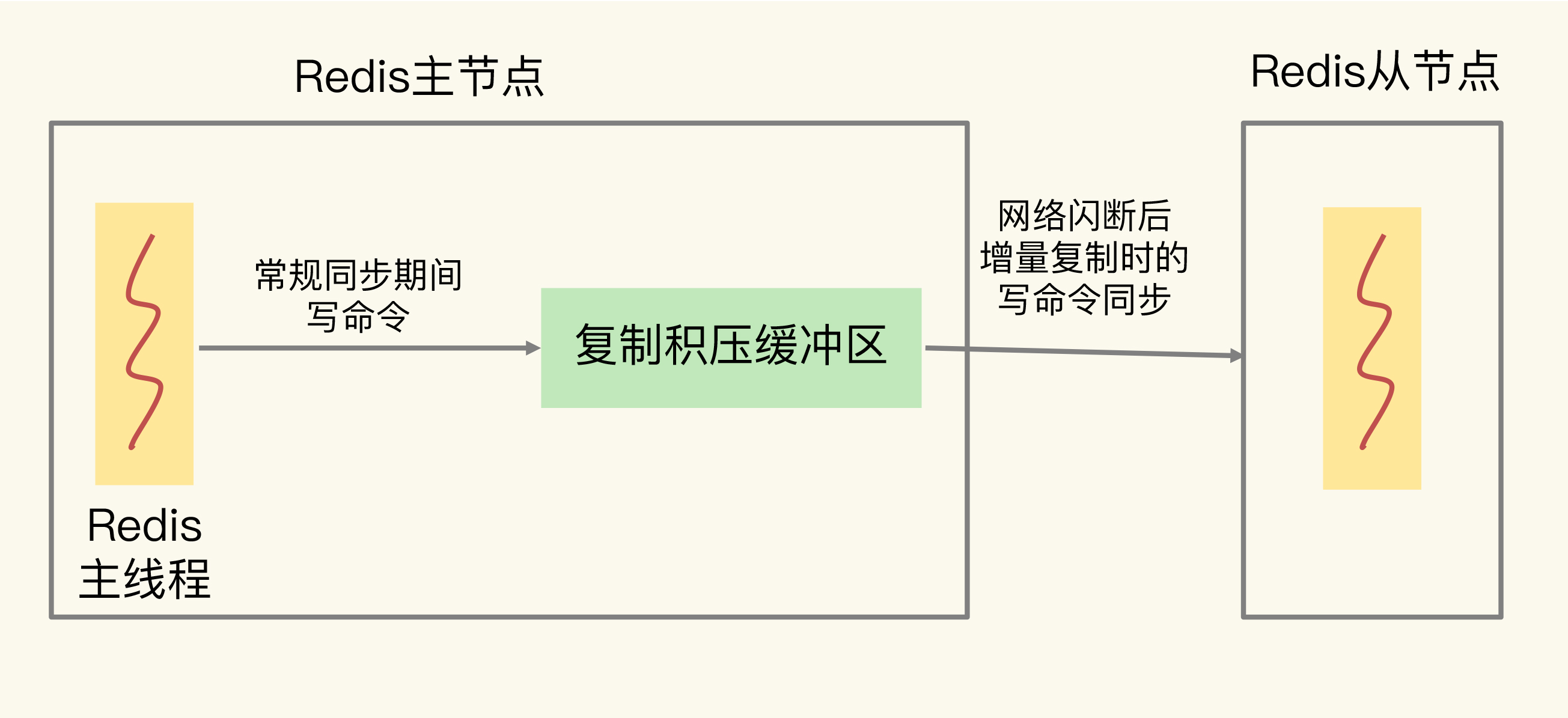
复制积压缓冲区(增量复制)
工作机制:主节点把写命令同步给从节点的同时,也写入复制积压缓冲区(repl_backlog_buffer)。当从节点网络闪断后重新连接,可以从这个缓冲区读取断连期间的写命令,进行增量同步。
关键特性 :复制积压缓冲区是一个环形缓冲区,大小固定。写满后新数据会覆盖旧数据。
溢出影响:如果从节点断连时间过长,断连期间的写命令已经被新数据覆盖,从节点就无法进行增量同步,只能退化为全量复制。
配置方法:
bash
repl-backlog-size 256mb大小的设置依据:需要能容纳从节点可能断连期间内主节点接收的所有写命令。计算公式:
repl-backlog-size = 写命令速率(MB/s) × 预期最大断连时间(s) × 安全系数(通常取2)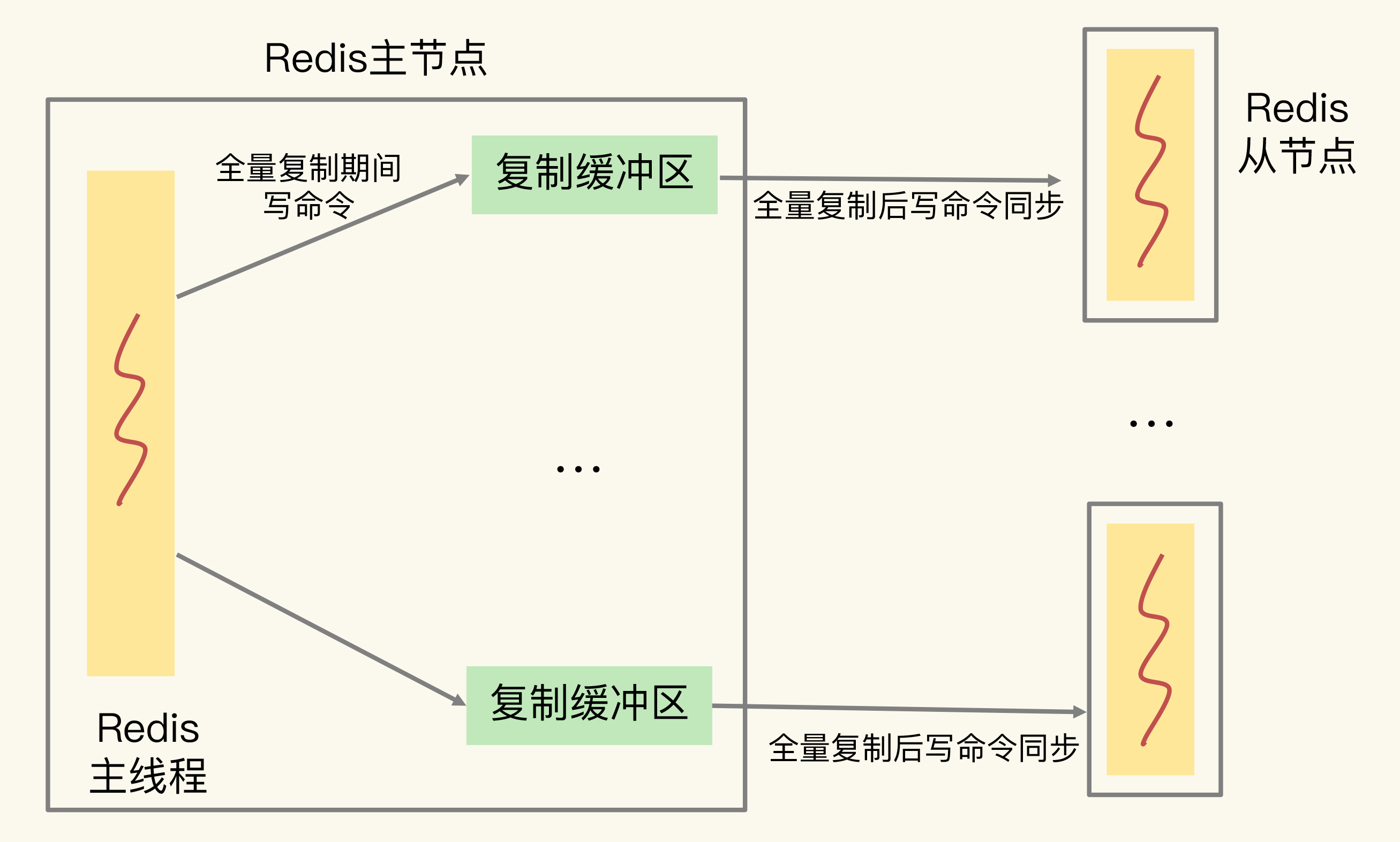
缓冲区溢出的本质与应对
从本质上看,缓冲区溢出只有三个原因:
- 数据发送过快过大:bigkey写入、大量频道消息推送
- 数据处理过慢:主线程阻塞、从节点加载RDB慢
- 缓冲区空间过小:配置不合理
对应的解决思路:
| 原因 | 客户端场景 | 主从场景 |
|---|---|---|
| 发送过快过大 | 避免bigkey | 控制主节点数据量,避免大RDB |
| 处理过慢 | 减少主线程阻塞 | 优化从节点加载速度 |
| 空间过小 | 输入缓冲区无法调整 | 合理设置复制缓冲区和积压缓冲区大小 |
溢出后果分类
按照溢出后的影响,可以把Redis的缓冲区分为两类:
溢出导致连接关闭:
- 普通客户端输入/输出缓冲区
- 订阅客户端输出缓冲区
- 从节点客户端的复制缓冲区
连接关闭意味着业务程序无法读写Redis,或者全量复制失败需要重新执行。
溢出导致数据覆盖:
- 复制积压缓冲区(环形缓冲区)
旧命令被覆盖后,从节点无法增量同步,只能全量复制,增加主节点负担。
总结
缓冲区是Redis保证数据不丢失的重要机制,但使用不当反而会成为问题的根源。核心要点:
- 输入缓冲区上限1GB不可调,只能从源头控制写入量
- 输出缓冲区需要根据客户端类型(normal/pubsub/slave)分别配置
- 复制缓冲区大小要匹配主节点的写负载和全量同步时间
- 复制积压缓冲区大小要覆盖从节点可能的最大断连时间
- 生产环境禁止持续使用MONITOR命令
- 控制从节点数量,避免主节点复制缓冲区内存开销过大
在排查Redis内存异常增长或连接频繁断开的问题时,缓冲区应该是首要检查的方向之一。
