1. 解码器介绍
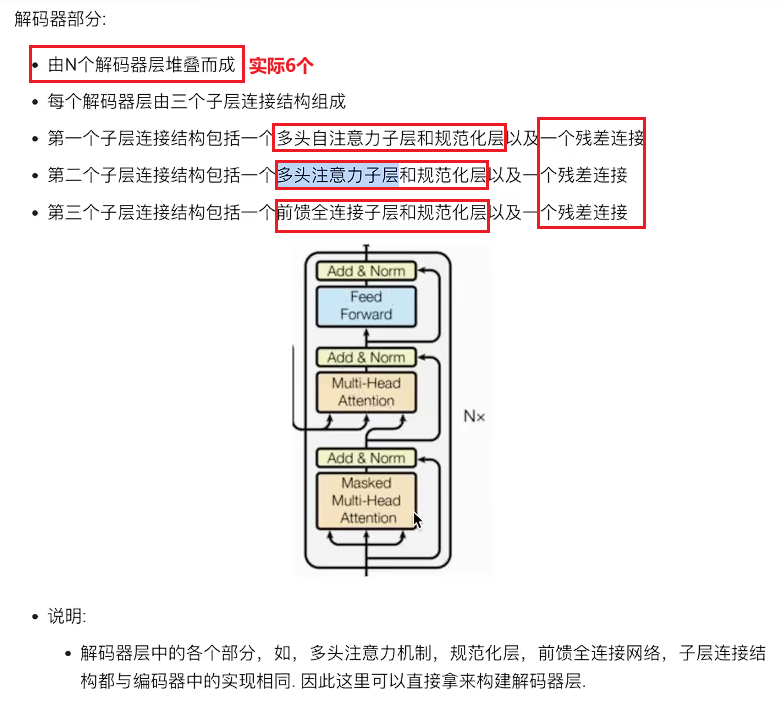
2. 解码器层
2.1 解码器层的作用
作为解码器的组成单元,每个解码器层根據给定的输入向目标方向进行特征提取操作,即解码过程;
2.2 解码器层的代码分析
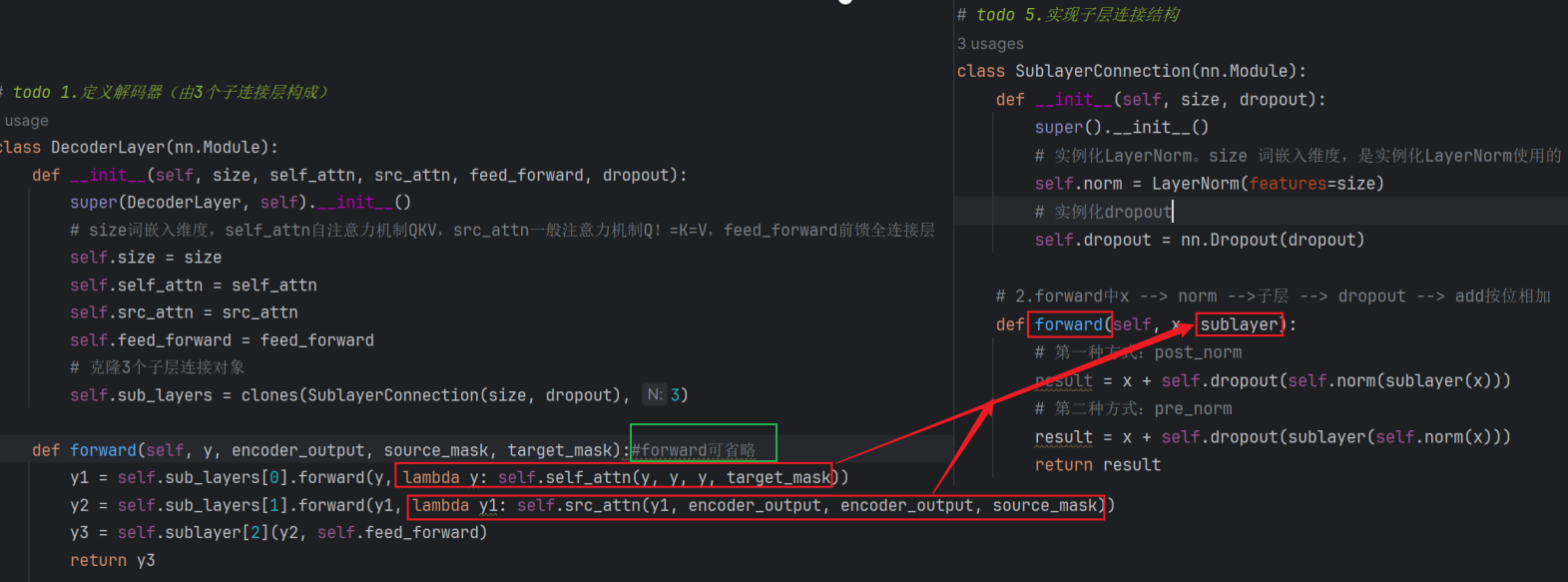
init中:参数:size, self_attn, src_attn, feed_forward, dropout;size词嵌入维度、self_attn自注意力机制、src_attn一般注意力、feed_forward前馈全连接层对象、dropout随机失活的系数;
forward中:参数: x, memory, source_mask, target_mask;x是来自解码器端的输入、memory来自编码器的输出结果、target_mask作用在第一个子层连接层结构即sentence_mask防止未来信息被掩盖、source_mask即padding_mask对目标文本的语句的pad进行mask;x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))第一个子连接层:输入的第一个参数x即为解码器的x、lambda式对应的为 实现子层连接结构 class SubLayerConnection 的forward(self, x, sublayer)中的 sublayer,self.self_attn(..)返回的是自注意力机制(QKV都=x)的对象;最终返回一个新的x。
再送给第二个子连接层:x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))输入的第一个参数x是上一步输出的第一个子连接层的输出结果、第二个参数返回的self.src_attn(x, m, m, source_mask)不是自注意力,而是一般注意力(Q=x,KV=m,Q!=K=V);再将返回的结果送给第三个子连接层 feed_forward;
python
# todo 1.定义解码器层(由3个子连接层构成)
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
# size词嵌入维度,self_attn自注意力机制QKV,src_attn一般注意力机制Q!=K=V,feed_forward前馈全连接层
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
# 克隆3个子层连接对象
self.sub_layers = clones(SublayerConnection(size, dropout), 3)
def forward(self, y, encoder_output, source_mask, target_mask):
# y[2,4,512]:来自解码器的输入,encoder_output[2,4,512]:来自编码器的输出结果,
# source_mask:作用在第二个子层连接结构的多头注意力机制对象上,进行padding_mask,
# target_mask:作用在第一个子层连接结构的多头自注意力机制对象上,进行sentence_mask
# 1.将y送入第一个子层连接结构得到 多头自注意力机制 + add + norm 之后的结果
y1 = self.sub_layers[0].forward(y, lambda y: self.self_attn(y, y, y, target_mask))
# y1 = self.sub_layers[0](y, lambda y: self.self_attn(y, y, y, target_mask)) #forward可省略
# 2.将y1送入第二个子层连接结构得到 多头注意力机制 + add + norm 之后的结果
y2 = self.sub_layers[1].forward(y1, lambda y1: self.src_attn(y1, encoder_output, encoder_output, source_mask))
# y2 = self.sub_layers[1](y1, lambda y1: self.src_attn(y1, encoder_output, encoder_output, source_mask))
# 3.将y2送入第三个子层连接结构得到 前馈全连接层+add+norm 之后的结果
y3 = self.sub_layers[2](y2, self.feed_forward)
return y3
# 定义解码器(由3个子连接层构成) 测试
def test_decoder_layer():
# 定义假如解码器端的输入也是2行6列
y = torch.tensor([[3, 4, 7, 10, 5, 70],
[2, 5, 8, 19, 20, 34]])
# 1.经过embedding层得到的词嵌入结果
my_embed = Embedding(vocab_size=2000, d_model=512)
embed_y = my_embed(y)
print(f'解码器embedding之后的结果:{embed_y.shape}') # [2, 6, 512]
# 2.经过position encoding位置编码层得到的位置编码信息
my_pe = PositionEncoding(d_model=512, dropout_p=0.1, max_len=60)
position_y = my_pe(embed_y)
print(f'解码器位置编码之后结果:{position_y.shape}') # [2, 6, 512]
# 3.实例化多头自注意力机制的对象
self_atten = MultiHeadAttention(embedding_dim=512, head=8, dropout=0.1)
src_atten = copy.deepcopy(self_atten)
# 4.实例化前馈全连接层对象
feed_forward = FeedForward(d_model=512, d_ff=1024)
# 5.实例化解码器层对象
decoder_layer = DecoderLayer(size=512, self_attn=self_atten, src_attn=src_atten, feed_forward=feed_forward,
dropout=0.1)
# 6.整理解码器层的输入:y, encoder_output, source_mask, target_mask
encoder_output = test_encoder()
print(f'编码器层输出的结果:{encoder_output.shape}') # [2, 4, 512]
# target_mask --> 解码器的query和key --> [2, 6, 512] --> query和key的转置相乘之后 --> [2, 6, 6]
target_mask = torch.zeros(8, 6, 6)
# target_mask --> 解码器的query --> [2, 6, 512] --> 和key(编码器) --> [2, 4, 512] --> query和key的转置相乘之后 --> [2, 6, 4]
source_mask = torch.zeros(8, 6, 4)
output = decoder_layer(position_y, encoder_output, source_mask, target_mask)
print(f'解码器层得到结果:{output.shape}') # [2, 6, 512]
if __name__ == '__main__':
test_decoder_layer()3. 解码器
解码器是由6个解码器层堆叠而成;
3.1 解码器的作用
根据编码器的结果以及上一次预测的结果,对下一次可能出现的'值'进行特征表示;
3.2 解码器的代码分析
解码器是由6个解码器层堆叠而成;
init中:参数:layer, N;克隆了6个解码器层,最后一个进行规范化,前向传播时将这6层循环迭代,第一层的得到的结果送入第二层,第二层的结果送到第三层,...,一直送到第6层,第6层得到的结果经过norm得到最终结果;
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import copy
from dm1_input import *
from dm2_encoder import *
# todo 1.定义解码器层(由3个子连接层构成)
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
# size词嵌入维度,self_attn自注意力机制QKV,src_attn一般注意力机制Q!=K=V,feed_forward前馈全连接层
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
# 克隆3个子层连接对象
self.sub_layers = clones(SublayerConnection(size, dropout), 3)
def forward(self, y, encoder_output, source_mask, target_mask):
# y[2,4,512]:来自解码器的输入,encoder_output[2,4,512]:来自编码器的输出结果,
# source_mask:作用在第二个子层连接结构的多头注意力机制对象上,进行padding_mask,
# target_mask:作用在第一个子层连接结构的多头自注意力机制对象上,进行sentence_mask
# 1.将y送入第一个子层连接结构得到 多头自注意力机制 + add + norm 之后的结果
y1 = self.sub_layers[0].forward(y, lambda y: self.self_attn(y, y, y, target_mask))
# y1 = self.sub_layers[0](y, lambda y: self.self_attn(y, y, y, target_mask)) #forward可省略
# 2.将y1送入第二个子层连接结构得到 多头注意力机制 + add + norm 之后的结果
y2 = self.sub_layers[1].forward(y1, lambda y1: self.src_attn(y1, encoder_output, encoder_output, source_mask))
# y2 = self.sub_layers[1](y1, lambda y1: self.src_attn(y1, encoder_output, encoder_output, source_mask))
# 3.将y2送入第三个子层连接结构得到 前馈全连接层+add+norm 之后的结果
y3 = self.sub_layers[2](y2, self.feed_forward)
return y3
# 定义解码器(由3个子连接层构成) 测试
def test_decoder_layer():
# 定义假如解码器端的输入也是2行6列
y = torch.tensor([[3, 4, 7, 10, 5, 70],
[2, 5, 8, 19, 20, 34]])
# 1.经过embedding层得到的词嵌入结果
my_embed = Embedding(vocab_size=2000, d_model=512)
embed_y = my_embed(y)
print(f'解码器embedding之后的结果:{embed_y.shape}') # [2, 6, 512]
# 2.经过position encoding位置编码层得到的位置编码信息
my_pe = PositionEncoding(d_model=512, dropout_p=0.1, max_len=60)
position_y = my_pe(embed_y)
print(f'解码器位置编码之后结果:{position_y.shape}') # [2, 6, 512]
# 3.实例化多头自注意力机制的对象
self_atten = MultiHeadAttention(embedding_dim=512, head=8, dropout=0.1)
src_atten = copy.deepcopy(self_atten)
# 4.实例化前馈全连接层对象
feed_forward = FeedForward(d_model=512, d_ff=1024)
# 5.实例化解码器层对象
decoder_layer = DecoderLayer(size=512, self_attn=self_atten, src_attn=src_atten, feed_forward=feed_forward,
dropout=0.1)
# 6.整理解码器层的输入:y, encoder_output, source_mask, target_mask
encoder_output = test_encoder()
print(f'编码器层输出的结果:{encoder_output.shape}') # [2, 4, 512]
# target_mask --> 解码器的query和key --> [2, 6, 512] --> query和key的转置相乘之后 --> [2, 6, 6]
target_mask = torch.zeros(8, 6, 6)
# target_mask --> 解码器的query --> [2, 6, 512] --> 和key(编码器) --> [2, 4, 512] --> query和key的转置相乘之后 --> [2, 6, 4]
source_mask = torch.zeros(8, 6, 4)
output = decoder_layer(position_y, encoder_output, source_mask, target_mask)
print(f'解码器层得到结果:{output.shape}') # [2, 6, 512]
# todo 2.定义解码器(由6个解码器层堆叠而成)
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
# 克隆6个解码器层
self.layers = clones(layer, N)
# 规范化层
self.norm = LayerNorm(layer.size)
def forward(self, y, encoder_output, source_mask, target_mask):
for layer in self.layers:
y = layer(y, encoder_output, source_mask, target_mask)
return self.norm(y)
# 定义解码器(由6个解码器层堆叠而成) 测试
def test_decoder():
# 定义假如解码器端的输入也是2行6列
y = torch.tensor([[3, 4, 7, 10, 5, 70],
[2, 5, 8, 19, 20, 34]])
# 1.经过embedding层得到的词嵌入结果
my_embed = Embedding(vocab_size=2000, d_model=512)
embed_y = my_embed(y)
print(f'解码器embedding之后的结果:{embed_y.shape}') # [2, 6, 512]
# 2.经过position encoding位置编码层得到的位置编码信息
my_pe = PositionEncoding(d_model=512, dropout_p=0.1, max_len=60)
position_y = my_pe(embed_y)
print(f'解码器位置编码之后结果:{position_y.shape}') # [2, 6, 512]
# 3.实例化多头自注意力机制的对象
self_atten = MultiHeadAttention(embedding_dim=512, head=8, dropout=0.1)
src_atten = copy.deepcopy(self_atten)
# 4.实例化前馈全连接层对象
feed_forward = FeedForward(d_model=512, d_ff=1024)
# 5.实例化解码器层对象
decoder_layer = DecoderLayer(size=512, self_attn=self_atten, src_attn=src_atten, feed_forward=feed_forward,
dropout=0.1)
# 6.整理解码器层的输入:y, encoder_output, source_mask, target_mask
encoder_output = test_encoder()
print(f'编码器层输出的结果:{encoder_output.shape}') # [2, 4, 512]
# target_mask --> 解码器的query和key --> [2, 6, 512] --> query和key的转置相乘之后 --> [2, 6, 6]
target_mask = torch.zeros(8, 6, 6)
# target_mask --> 解码器的query --> [2, 6, 512] --> 和key(编码器) --> [2, 4, 512] --> query和key的转置相乘之后 --> [2, 6, 4]
source_mask = torch.zeros(8, 6, 4)
# 实例化解码器对象
decoder = Decoder(decoder_layer, N=6)
output = decoder(position_y, encoder_output, source_mask, target_mask)
print(f'解码器层得到结果:{output.shape}') # [2, 6, 512]
if __name__ == '__main__':
# test_decoder_layer()
test_decoder()