第一节:NL2SQL介绍
一、什么是NL2SQL
NL2SQL(也常写作 NLP2SQL)是自然语言处理(NLP)与数据库技术深度融合的交叉领域技术,核心目标是将人类用自然语言(中文、英文等)表达的非结构化数据查询需求,自动转换为可执行的结构化查询语言(SQL)语句 ,并返回对应的数据库查询结果。
它本质上是一种 "自然语言接口"(Natural Language Interface to Databases, NLIDB)的核心实现技术,彻底改变了传统数据库 "只能通过专业语法交互" 的模式,让非技术人员无需掌握 SQL 语法、无需了解底层数据库的表结构、字段关系和数据类型,就能通过日常语言直接访问和分析数据库中的数据。
二、NL2SQL执行流程
为了更直观地理解NLP2SQL的工作机制,下面我们用一个统一案例贯穿整个流程。假设业务人员提出这样一个问题:"最近30天华东地区销量最高的产品是什么?"系统需要从这句自然语言出发,逐步完成问题理解、知识检索、SQL生成、SQL执行和结果返回。
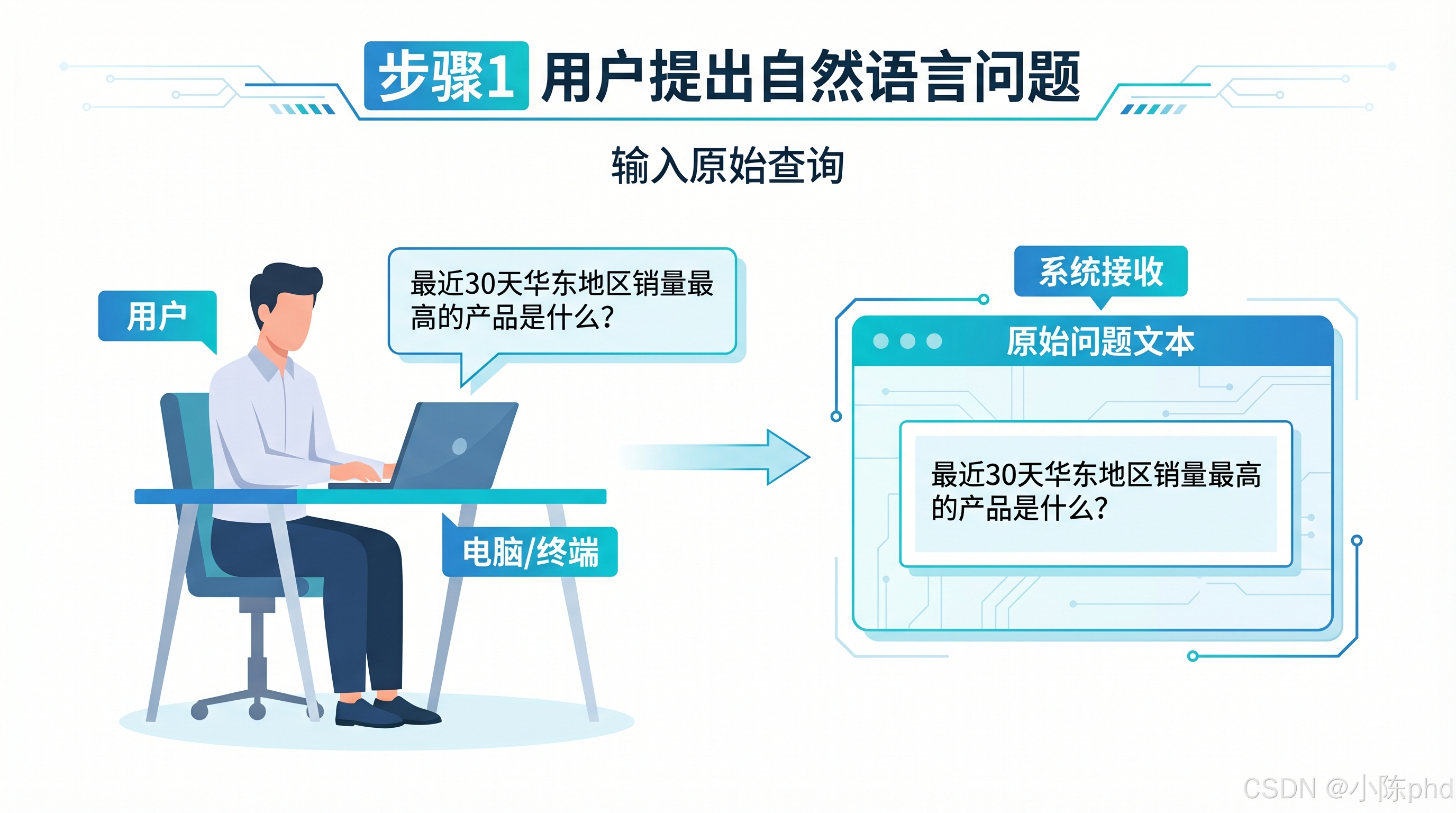
- 用户提出自然语言问题
- 核心动作:用户通过终端输入日常语言表达的查询需求,无需掌握任何 SQL 语法或数据库结构知识
- 输入:用户原始问题文本:"最近 30 天华东地区销量最高的产品是什么?"
- 输出:系统接收并存储原始问题文本,等待后续处理
- 关键特点:完全保留自然语言的模糊性和口语化特征,系统负责后续的结构化转换
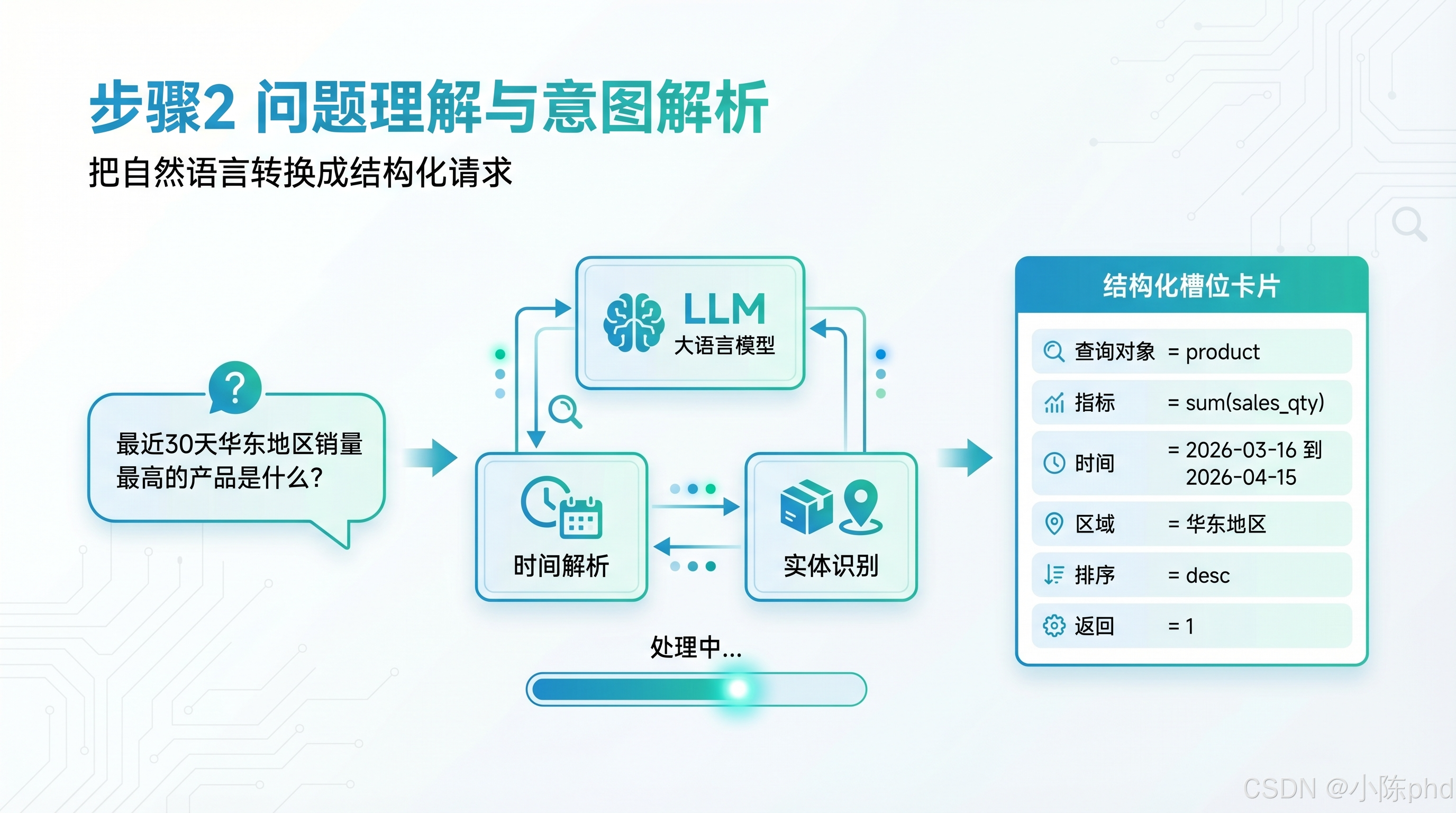
- 问题理解与意图解析
- 核心动作:调用大语言模型 + 专用解析模块,将非结构化自然语言转换为机器可处理的结构化查询请求
关键子模块:
-
大语言模型(LLM):整体意图识别与语义理解
-
时间解析模块:将 "最近 30 天" 转换为精确日期范围(如 2026-03-16 至 2026-04-15)
-
实体识别模块:将 "华东地区" 映射为业务系统中的具体区域集合
输出:结构化槽位卡片查询对象 = product
统计指标 = sum(sales_qty)
时间范围 = 2026-03-16 至 2026-04-15
区域范围 = 华东地区
排序方式 = 降序(desc)
返回条数 = 1
`` 
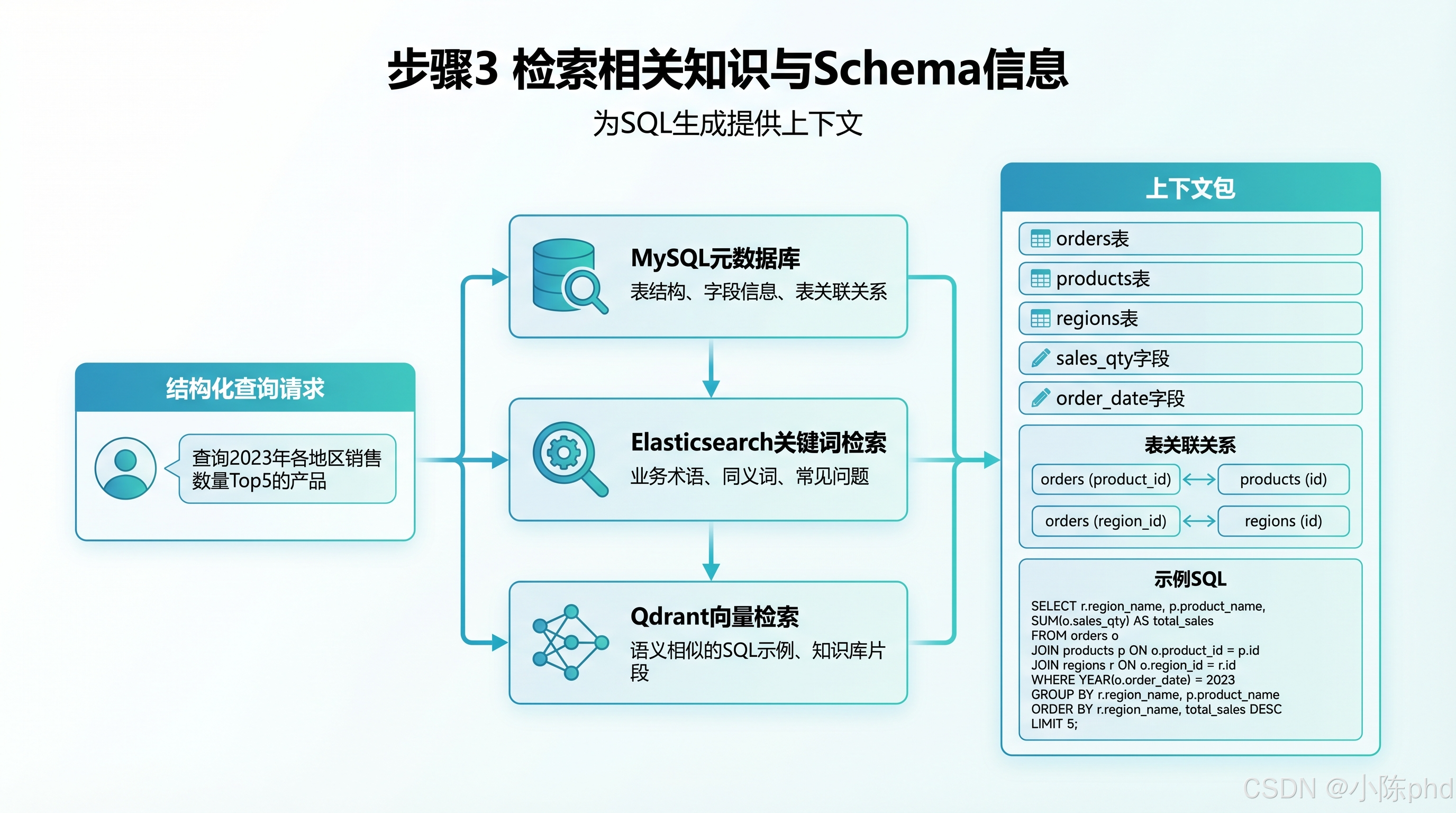
- 检索相关知识与Schema信息
- 核心动作:通过多源检索为 SQL 生成提供精准上下文,从根源上解决大模型 "幻觉" 问题
三大检索渠道:
-
元数据库:获取表结构、字段信息、主外键关联关系(orders 表、products 表、regions 表)
-
Elasticsearch 关键词检索:匹配业务术语、同义词、数据口径说明(确认 "销量" 对应 sales_qty 字段)
-
向量检索:召回语义相似的历史问答样本和示例 SQL
输出:完整的 SQL 生成上下文包,包含目标表、字段映射、表关联关系和参考 SQL
-
生成候选SQL语句
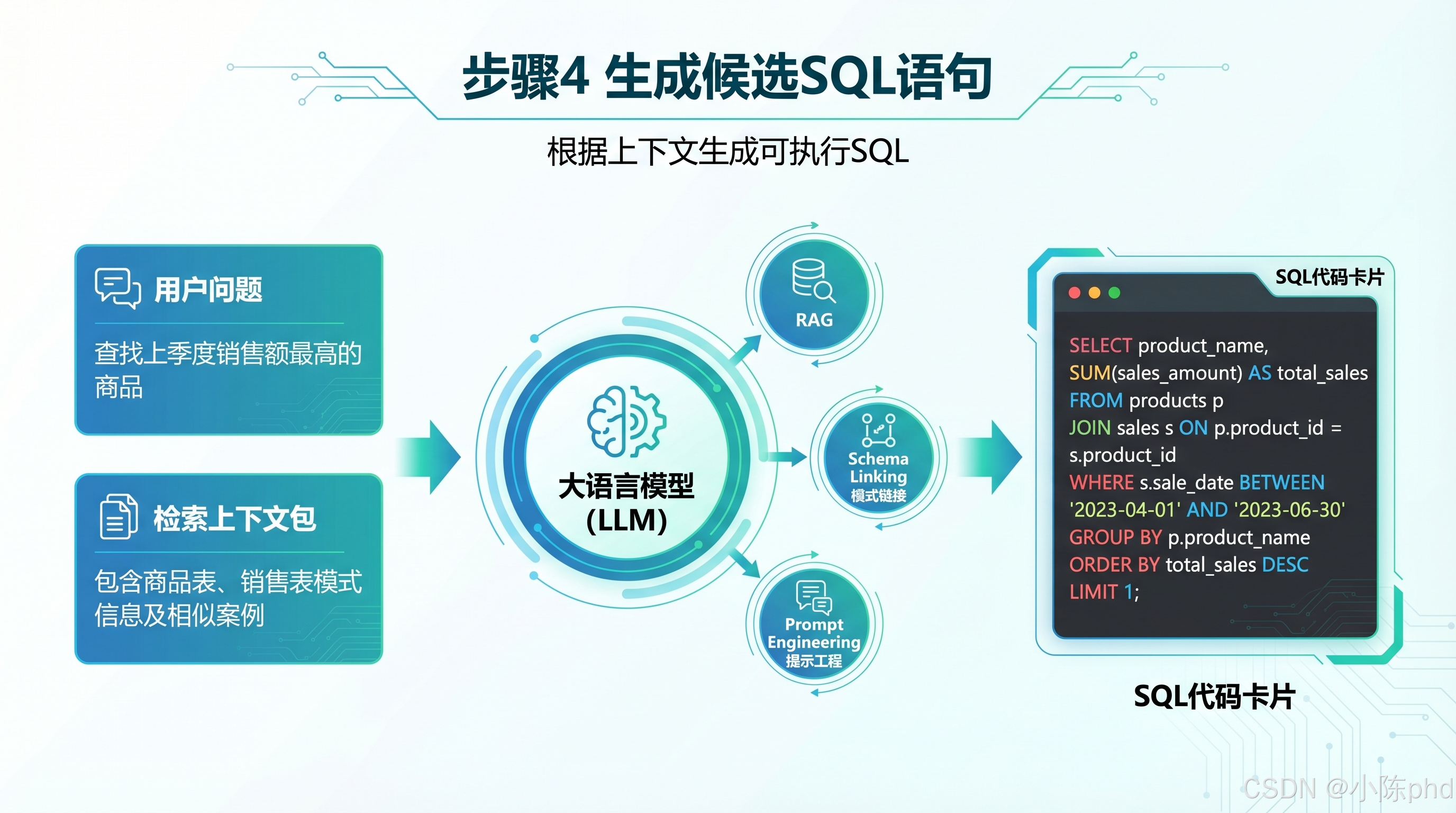
- 核心动作:大模型在严格约束下生成符合业务逻辑的可执行 SQL 语句
- 输入:用户原始问题 + 结构化意图 + 检索得到的上下文包
关键技术:
- Prompt Engineering:设计专用提示词引导模型生成规范 SQL
- Schema Linking:强制模型只能使用已检索到的表和字段,杜绝幻觉
输出:候选 SQL 语句
sql
SELECT p.product_name, SUM(o.sales_qty) AS total_sales
FROM orders o
JOIN products p ON o.product_id = p.product_id
JOIN regions r ON o.region_id = r.region_id
WHERE o.order_date BETWEEN '2026-03-16' AND '2026-04-15'
AND r.region_name = '华东地区'
GROUP BY p.product_id, p.product_name
ORDER BY total_sales DESC
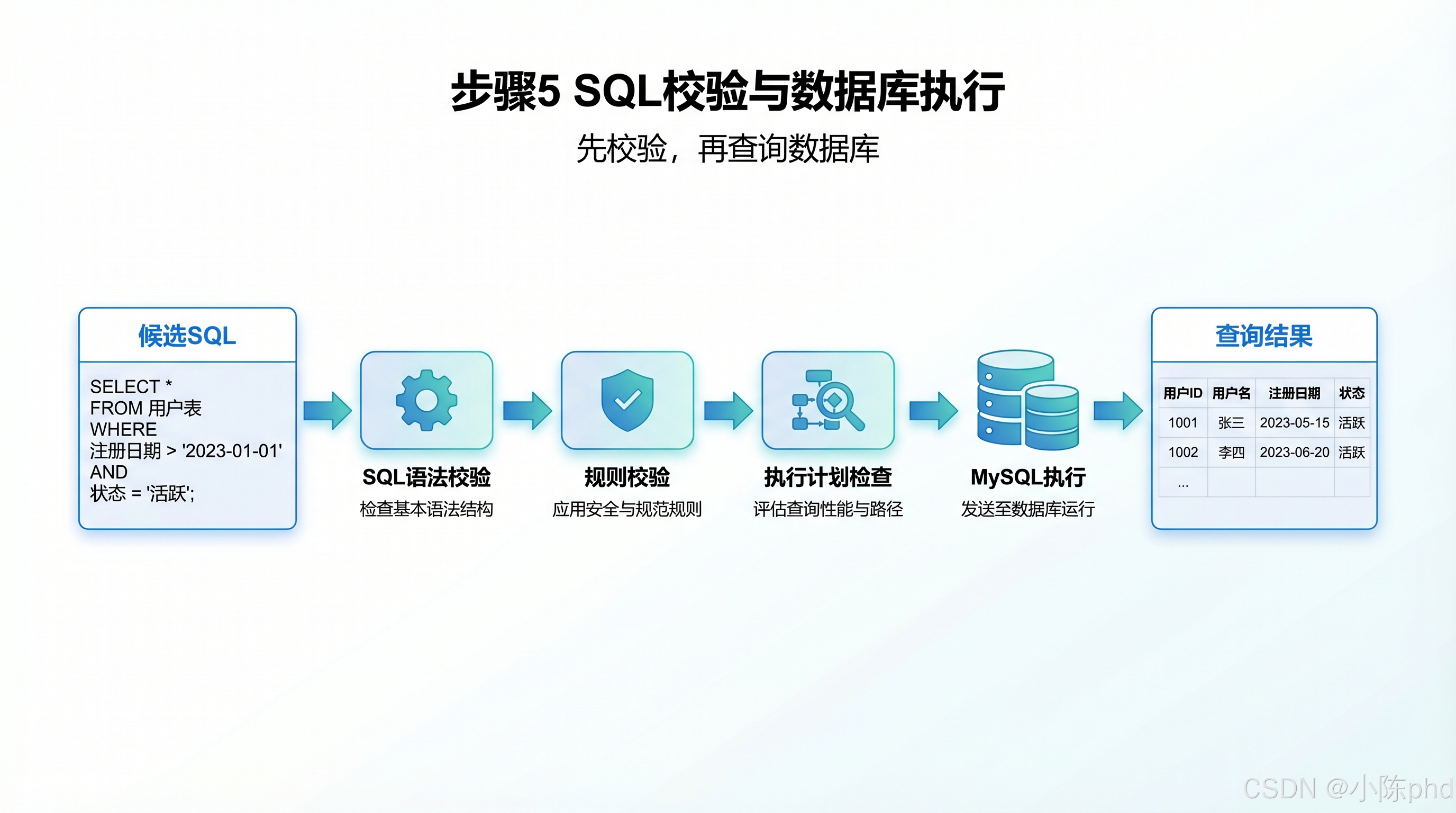
LIMIT 1;- SQL校验与数据库执行
- 核心动作:对生成的 SQL 进行多层级安全与正确性校验,通过后执行查询
四层校验机制:
- 语法校验:使用 SQL Parser 检查 SQL 语法合法性
- 语义校验:验证字段和表是否存在、关联关系是否正确
- 业务口径校验:确认使用的字段符合业务定义
- 执行计划检查:通过 EXPLAIN 查看查询性能,避免全表扫描
- 错误处理:校验失败时自动触发 SQL 重写流程,由大模型根据错误信息重新生成
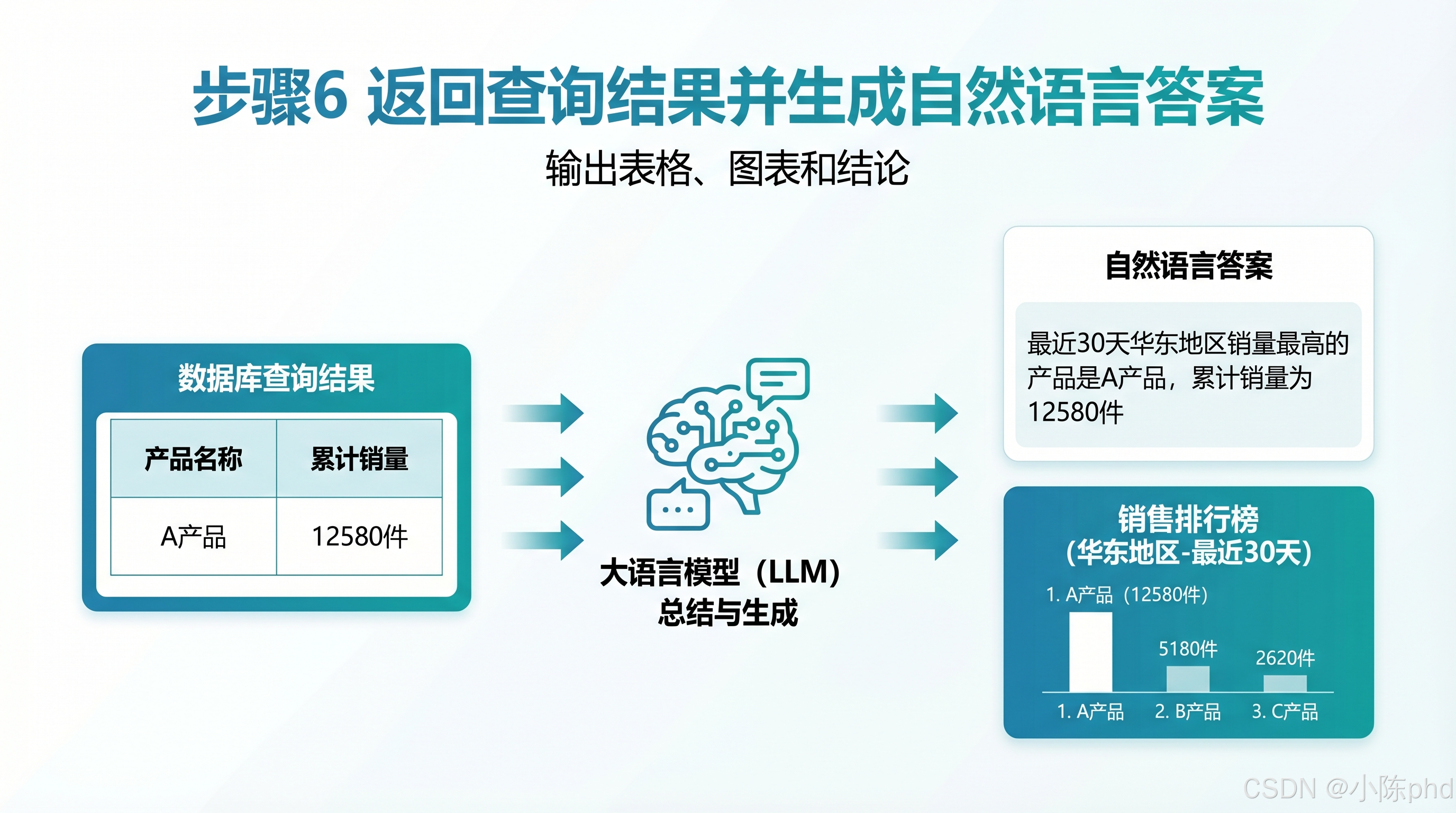
- 输出:数据库查询结果集:product_name=A产品,total_sales=12580
- 返回查询结果并生成自然语言答案
- 核心动作:将结构化的数据库结果转换为用户易读的自然语言表述
处理流程:
- 整理数据库返回的结构化结果
- 补充查询条件说明(统计周期、统计范围)
- 大模型按照业务模板生成自然语言答案
- 输出:最终自然语言回答:"最近 30 天华东地区销量最高的产品是 A 产品,累计销量为 12580 件。"
- 可选输出:配套的数据表格、柱状图或趋势图等可视化展示