如果你只把Kafka当成一个"消息队列",那你只用了它三成功力。这篇文章不写代码、不堆配置,只把Kafka的核心骨架拆给你看:它的结构长什么样、消息怎么流、为什么能抗住万亿级吞吐、生产者和消费者到底在扮演什么角色。读完你会真正理解------Kafka不是工具,是一套完整的分布式存储与流转范式。
一、Kafka是什么?先扔掉"消息队列"四个字
很多人入门Kafka时,第一句话是:"Kafka是一个高性能消息队列。"
这个说法没错,但太窄了。更本质的定义是:
Kafka是一个分布式、分区化、多副本的提交日志服务。
注意三个关键词:
-
分布式:数据分散在多台机器上,天然支持水平扩展。
-
分区化:每个主题被拆成多个分片,并发读写的基础。
-
提交日志:数据以追加写的方式持久化到磁盘,像操作系统的日志文件一样------只能追加,不能修改,消费通过移动指针(offset)完成。
换成人话:Kafka是一个能存海量数据、能扛超高并发、能让你随时回头重读历史消息的"超级日志系统"。
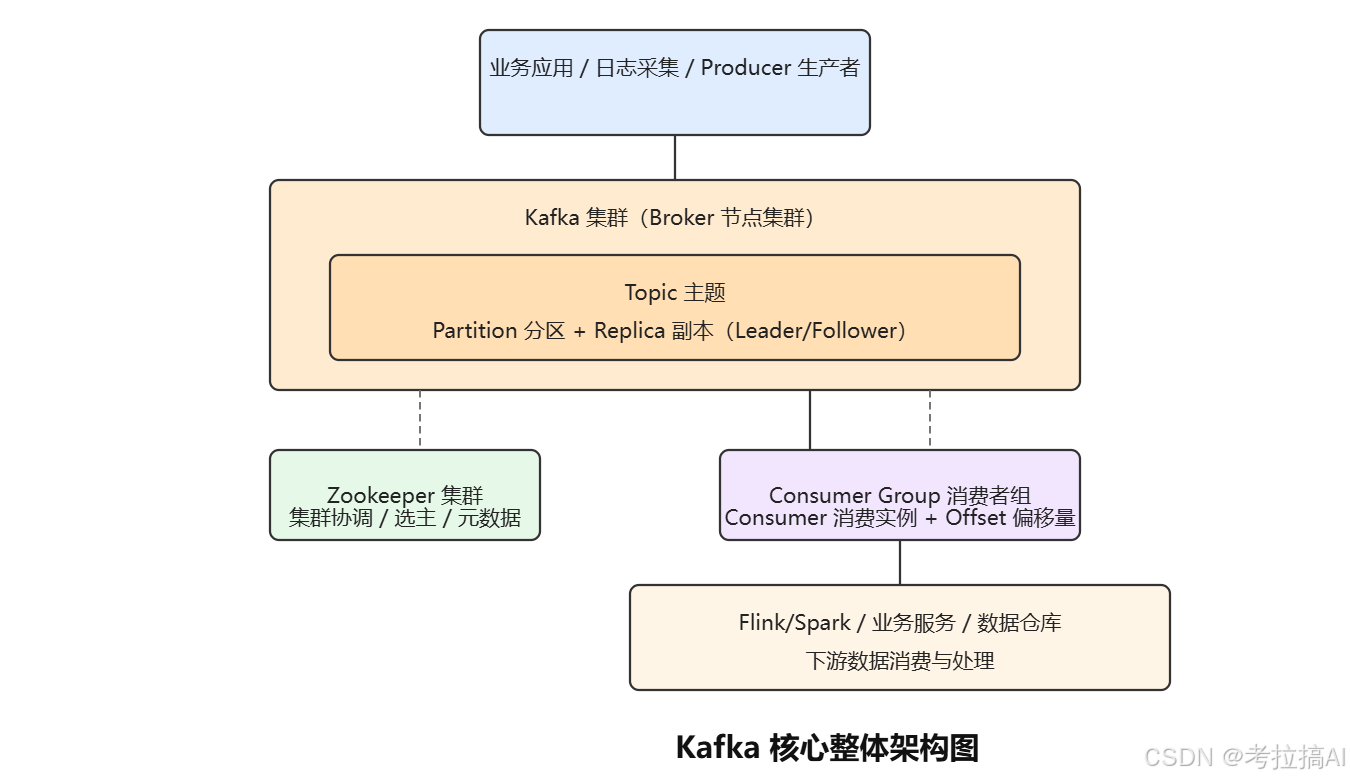
二、Kafka的物理结构:从Topic到Segment的四层解剖
Kafka的存储结构像俄罗斯套娃,一层套一层。从外到内依次是:
第一层:Topic(主题)
逻辑上的消息分类。比如"订单事件"是一个Topic,"用户点击日志"是另一个Topic。生产者往Topic写,消费者从Topic读。
第二层:Partition(分区)
一个Topic可以拆成多个Partition。这是Kafka实现水平扩展 和并行处理的核心。
-
每个Partition是一个有序、不可变的消息序列,新消息追加到尾部。
-
不同Partition可以分布在不同Broker(服务器)上。
-
消息在Partition内部通过Offset(偏移量) 唯一标识,Offset是一个单调递增的整数。
举个例子:Topic order 有3个Partition,第一条消息可能进Partition 0,第二条进Partition 1,第三条进Partition 2......写入是轮询或按key哈希决定。
第三层:Replica(副本)
每个Partition可以有多个副本(Replica),分布在不同的Broker上,用于高可用。
-
Leader副本:所有读写操作都走Leader。它负责对外提供服务。
-
Follower副本:只从Leader同步数据,不处理客户端请求。当Leader挂了,某个Follower会被选举为新Leader。
第四层:Segment(段)
磁盘上,一个Partition并不是一个巨大的文件,而是由多个Segment文件组成。
-
每个Segment包含两个文件:
.log(消息数据)和.index(偏移量索引)。 -
当Segment达到指定大小(如1GB)或时间阈值,就会滚动生成新Segment。
-
老Segment可以被清理或归档,实现有限期存储。
结构层次总结 :
集群 → Broker → Topic → Partition → Replica → Segment → 消息
三、Kafka的工作流程:一条消息的完整旅行
我们追踪一条消息从生产到消费的全过程。
3.1 写入流程(生产者 → Broker)
-
生产者决定要写入哪个Topic。
-
根据消息的key(如果有)进行哈希,决定送往哪个Partition。没有key则轮询。
-
生产者请求Broker集群获取该Partition的Leader位置。
-
生产者将消息追加写入到Leader所在Broker的对应Partition当前活跃Segment尾部。
-
Leader写入成功后,根据
acks配置决定是否需要等待Follower同步。 -
Leader返回确认给生产者。
这一步的核心是:Kafka只在Leader上写入,Follower异步拉取。写入是顺序追加,所以即使单Partition也能达到很高的吞吐。
3.2 存储流程(Broker内部)
-
消息一旦写入Segment,就被持久化到磁盘(受刷盘策略控制,但一般依赖操作系统Page Cache)。
-
每个消息在Partition内获得一个唯一的Offset(逻辑位置)。
-
Kafka会定期滚动Segment,并可能根据保留策略(按时间或大小)删除老Segment。
3.3 读取流程(消费者 → Broker)
-
消费者指定要消费的Topic和Partition,并带上当前消费到的Offset。
-
消费者请求Broker集群,找到该Partition的Leader(读也走Leader,早期版本如此,新版本有Follower读特性,但入门阶段记住读写都走Leader)。
-
Leader从该Offset所在的Segment开始读取消息,返回给消费者。
-
消费者处理消息,并定期提交Offset(提交到Kafka内部__consumer_offsets主题)。
-
下次拉取时从新Offset继续。
注意:Kafka的消费是拉模式(pull),消费者主动拉取消息。这不同于RabbitMQ的推送。
四、核心概念深挖:Producer、Consumer、Consumer Group
4.1 Producer(生产者)
生产者就是向Kafka写入数据的客户端。它的关键行为:
-
分区策略 :决定消息去往哪个Partition。默认策略:有key则
hash(key) % 分区数,无key则轮询或粘性分区(批量打包提升效率)。 -
批量发送:生产者不会一条一条立即发,而是攒一批(按消息条数或时间阈值)再发送,大幅提升吞吐。
-
重试与幂等 :开启幂等后(
enable.idempotence=true),Kafka会为每个生产者分配Producer ID,并为每条消息生成序列号,Broker据此去重,保证消息在分区内不重复。 -
事务:支持跨分区跨主题的原子写入。
4.2 Consumer(消费者)
消费者从Kafka拉取数据的客户端。关键点:
-
订阅:消费者可以订阅一个或多个Topic。
-
拉取 :通过
poll()方法主动拉取一批消息,拉取频率和数量由应用控制。 -
Offset管理 :消费者需要记录自己消费到了哪个Offset。Kafka内部有一个特殊的
__consumer_offsets主题,自动保存每个消费者组的提交进度。 -
手动/自动提交:可以自动定期提交,也可以业务处理完后再手动提交(确保精确一次语义)。
4.3 Consumer Group(消费者组)------ 最精妙的设计
一个消费者组包含多个消费者实例。同一个消费者组内,一个Partition只能被一个消费者消费;不同消费者组之间独立消费,互不影响。
这个模型带来了两大核心能力:
-
队列模式:如果所有消费者属于同一个组,那么每个消息只会被组内一个消费者处理------这不就是一个传统消息队列吗?
-
发布/订阅模式:如果多个消费者组订阅同一个Topic,每个组都能独立消费全量消息------这不就是广播吗?
消费者组与Partition的关系:
-
如果消费者数 < 分区数,部分消费者会消费多个分区。
-
如果消费者数 = 分区数,每个消费者消费一个分区,达到最大并行度。
-
如果消费者数 > 分区数,多余的消费者将闲置(无法分配到分区)。
这就是Kafka实现弹性伸缩的秘密------增加消费者就能线性提升处理能力,但上限是分区数。
五、Kafka的适用场景(哪些事非它不可)
✅ 场景一:日志与事件采集
-
成千上万的服务器产生日志,需要统一收集、缓冲、供下游分析(如ELK)。
-
Kafka的高吞吐和持久化让日志永不丢失,消费端可按需消费历史日志。
✅ 场景二:实时流处理
-
与Spark Streaming、Flink等框架集成,作为数据管道。
-
例如:用户行为实时统计、异常检测。
✅ 场景三:消息解耦与削峰
-
在微服务之间充当异步缓冲区,尤其是上游流量波动大的场景(如电商秒杀)。
-
相比RocketMQ,Kafka更适合数据量极大、对单条消息延迟不极度敏感的场景。
✅ 场景四:数据库变更数据捕获(CDC)
-
将数据库binlog发到Kafka,下游构建缓存、同步到数仓或搜索引擎。
-
因为Kafka支持消息长期存储,可以反复消费历史变更。
❌ 不合适场景
-
消息粒度路由复杂:Kafka不支持像RabbitMQ那样的灵活Exchange绑定。
-
延迟队列:Kafka不原生支持延迟消息,需要额外逻辑。
-
单条消息价值极高且必须精准一次且性能要求不极致:可以选RocketMQ的事务消息更顺手。
六、一张图总结Kafka核心模型
text
Producer → [Topic] → Partition 0 → [Segment0, Segment1, ...]
→ Partition 1 → [Segment0, Segment1, ...]
→ Partition 2 → [Segment0, Segment1, ...]
Consumer Group A:
- Consumer 1 → Partition 0
- Consumer 2 → Partition 1
- Consumer 3 → Partition 2
Consumer Group B:
- Consumer 1 → Partition 0, Partition 1, Partition 2 (独立消费全量)两条铁律:
-
同一个Partition内的消息,严格有序。
-
同一个消费者组内,一个Partition只能被一个消费者消费。
理解了这两条,你就理解了Kafka并发模型与顺序保证的全部边界。
七、写在最后:Kafka的设计哲学
Kafka的优雅不在于它做了什么复杂的事,而在于它刻意放弃了一些能力来换取极致的吞吐和可扩展性:
-
放弃全局有序,换来了分区级的并行。
-
放弃消息删除,换来了顺序写的极高性能。
-
放弃即时推送给消费者(改用拉),换来了消费者自主控制消费速度。
这些设计选择让它成为大数据领域的"基础设施",而不是一个普通的中间件。
如果你下次面试被问到"Kafka和传统MQ最大的区别是什么?",你可以自信地答:Kafka本质是一个分布式提交日志,而不是一个消息队列。 这句话,值一个offer。
本文只讲概念,不掺杂代码与部署,是Kafka入门的"第一块砖"。如果你还想了解Partition选举、ISR机制、零拷贝原理、生产者幂等实现细节,欢迎留言,下一期安排。
📌 延伸思考 :
消费者组内如果某个消费者崩溃了,它负责的Partition会如何重新分配?答案就是Kafka的Rebalance机制------这也是面试中排在第二的高频题。你敢挑战吗?