1、简介
使用CNN卷积神经网络,实现一个识别衣物种类的模型。
2、代码实现
代码下载:【免费】PyTorch+CNN实现衣物分类代码资源-CSDN下载
下载衣服数据集(训练集+测试集)
python
import torch
from torchvision import datasets
from torchvision.transforms import v2
# 下载训练集数据
training_data = datasets.FashionMNIST(
root="data", # 数据存在data文件夹下
train=True, # 等于True表示下载的是训练集(6万张)
download=True, # 本地没有就自动下载
# 把原始图片 → 转换成 PyTorch 模型能训练的标准格式!
transform=v2.Compose([
v2.ToImage(), # 把数据转换成 PyTorch 能识别的图片结构
v2.ToDtype(torch.float32, scale=True) # 把数据类型变成 32 位浮点数。因为模型只认float
])
)
# 下载测试集数据
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])
)定义一个神经网络模型
NeuralNetwork.py
python
# 这两行导入包含了模型里所有用到的层
# 卷积层:nn.Conv2d
# 全连接层:nn.Linear
# 激活函数:nn.ReLU
# Dropout:nn.Dropout
# 池化层:nn.MaxPool2d
# 序列容器:nn.Sequential
import torch
import torch.nn as nn
# 定义一个CNN模型
class NeuralNetwork(nn.Module):
def __init__(self): # 模型的构造函数
super().__init__() # 必须的固定写法,初始化父类nn.Module
self.conv = nn.Sequential( # 按顺序执行的层容器
# nn.Conv2d → 卷积层,提取图像特征。
# nn.ReLU() -> 激活函数,使神经网络变成非线性的。因为卷积层只会线性计算,需要变成非线性学习复杂特征。
# nn.MaxPool2d → 池化层(压缩图片)。
# 第一层卷积层:nn.Conv2d(1,32,3,padding=1),
# in_channels=1:输入通道数为1(灰度图只有1个通道)。
# out_channels=32:输出通道数为32(提取32种特征)。
# kernel_size=3:卷积核大小3*3。卷积核=图片上的一个小窗口(3*3),用来扫描提取特征。在图片上从左到右、从上到下滑动,提取特征。
nn.Conv2d(1,32,3,padding=1),
# 第二层激活函数层:nn.ReLU() 使神经网络变成非线性的。
nn.ReLU(),
# 第三层池化层:nn.MaxPool2d(2) 缩小图片,只保留最明显最重要的特征,压缩图片 + 抓重点 + 让模型更鲁棒。
# nn.MaxPool2d(2):把图片的高和宽各缩小一半,保留最关键的特征。
nn.MaxPool2d(2),
# 第四层卷积层:nn.Conv2d(32,64,3,padding=1)。
# in_channels=32:输入通道数为32(第一层卷积层输出了32种特征,作为第二个卷积层的输入)。
# out_channels=64:输出通道数为64(输出64个组合特征)。
# kernel_size=3:卷积核大小3*3。卷积核=图片上的一个小窗口(3*3),用来扫描提取特征。在图片上从左到右、从上到下滑动,提取特征。
nn.Conv2d(32,64,3,padding=1),
# 第五层激活函数层:nn.ReLU() 使神经网络变成非线性的。
nn.ReLU(),
# 第六层池化层:nn.MaxPool2d(2) 把图片的高和宽各进一步再缩小一半,保留最关键的特征。
nn.MaxPool2d(2),
# 第七层Dropout层:防止模型过拟合。
# nn.Dropout(0.25):训练时随机关掉 25% 的神经元,防止模型 "死记硬背"(过拟合)。
nn.Dropout(0.25)
)
# 模型的大脑决策层
self.fc = nn.Sequential(
# 第一层全连接层:nn.Linear(64*7*7,128)。输入64*7*7=3136个特征,输出128个神经元。把前面卷积看到的所有边缘、纹理、形状,汇总整理成 128 个高级特征。
# 为什么是64?因为最后一层卷积输出64个通道,所以全连接层才写64。7*7是因为两次池化后,28*28的图片缩小为了7*7。展平后就是64*7*7为全连接层输入。
nn.Linear(64*7*7,128),
# 第二层激活函数层:引入非线性,让模型能够学习复杂的规律。
nn.ReLU(), # 激活函数
# 第三层Dropout层:防止过拟合。
nn.Dropout(0.3), # 训练时,随机让30%的神经元不工作,防止模型死记硬背(过拟合) 每次训练都故意不让一部分神经元参与,强迫模型理解规律,而不是背诵答案!
# 输入128个高级特征(这个128是人为设定的),输出10个数值(分类结果):['T恤', '裤子', '套头衫', '连衣裙', '外套', '凉鞋', '衬衫', '运动鞋', '包', '短靴']
nn.Linear(128,10) # 第二层全连接层->输出10分类结果
)
# 模型的执行流程:图片进来 → 卷积看特征 → 展平 → 全连接判断 → 输出结果!
# 卷积层:看图片,找特征(眼睛)
# 全连接层:做判断分类(大脑)
def forward(self,x):
# 第一步:卷积层提取特征
x=self.conv(x)
# 第二步:展平数据(格式转换),把二维图像展平成一维向量。因为全连接层只认一维向量,不认二维图片。卷积层看的是图片。全连接层看的是向量。
x=torch.flatten(x,1)
# 第三步:全连接层分类,返回结果
return self.fc(x)下载PyTorch 官方自带的【衣服图片数据集】
DataSetLoad.py
python
import torch
from torchvision import datasets
from torchvision.transforms import v2
# 下载训练集数据
training_data = datasets.FashionMNIST(
root="data", # 数据存在data文件夹下
train=True, # 等于True表示下载的是训练集(6万张)
download=True, # 本地没有就自动下载
# 把原始图片 → 转换成 PyTorch 模型能训练的标准格式!
transform=v2.Compose([
v2.ToImage(), # 把数据转换成 PyTorch 能识别的图片结构
v2.ToDtype(torch.float32, scale=True) # 把数据类型变成 32 位浮点数。因为模型只认float
])
)
# 下载测试集数据
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])
)
训练神经网络模型
Training.py
python
import torch # 核心库
import torch.nn as nn # 放卷积层、全连接层、ReLU激活函数 等
# 训练集,打包图片,一批一批喂给模型
from torch.utils.data import DataLoader
from clothingrecognition.DataSetLoad import training_data, test_data
from clothingrecognition.NeuralNetwork import NeuralNetwork
# 训练集
train_dataloader = DataLoader(
training_data,
batch_size=64, # 6万张图片,分批次喂给模型,每批次给模型输入64张图片。
shuffle=True # 打乱顺序。
)
# 测试集
test_dataloader = DataLoader(
test_data,
batch_size=64,
shuffle=False
)
# 设备
# 有GPU 就用 GPU(快 10~20 倍),没有就用 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 把模型搬到 GPU/CPU 上
model = NeuralNetwork().to(device)
# 定义损失函数:损失函数用于给模型打分,模型预测得越错,分数越高。预测的越对,分数越低。
# ['T恤', '裤子', '套头衫', '连衣裙', '外套', '凉鞋', '衬衫', '运动鞋', '包', '短靴'],模型看到一张图片,
# 输出10个原始分数:[1, 2, 3, 5, -1, -2, 0, 1, -5, -10],CrossEntropyLoss把分数变成概率:[0.01, 0.005, 0.02, 0.90, 0.001, ...],
# 之所以要转换成概率,是因为概率方便计算误差,只有【概率】,才能算出清晰的损失值
# 模型认为90%的概率是裙子。如果图片真实标签就是裙子,损失函数计算模型错误程度为10%(loss很小),反之不是裙子,损失函数计算模型错误程度为90%(loss很大)
# 损失函数就是告诉模型:你错的有多严重!!!
loss_fn = nn.CrossEntropyLoss()
# 定义优化器:根据损失函数(loss)指出的错误,自动调整模型里的卷积、全连接层的数字,让模型越练越准!
# torch.optim.Adam:目前最常用、最好用的优化器。图像分类推荐使用它。
# model.parameters():把模型里所有可训练的数字,全部交给优化器调整!
# 这些数字包括:
# 1. 卷积核数值 = 眼睛的滤镜
# 看线条、纹理、形状
# 2. 权重数值 = 大脑的判断分数
# 这个特征重要还是不重要
# 3. 偏置数值 = 基础保底分
# lr:学习率,模型每次改错,改多大的幅度!
# optimizer = 教练(
# 要训练的所有模型数字,
# 每次改错的幅度 = 0.001
# )
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 训练
def train_epoch(dataloader, model, loss_fn, optimizer):
model.train() # 把模型切换到【训练模式】,必须写,只有训练时才开启 Dropout(防止过拟合)。
for X, y in dataloader: # 一张一张batch读取数据。X = 图片(一次 64 张) y = 图片的正确答案(0~9 类别)
X, y = X.to(device), y.to(device) # 把图片和答案送到 GPU / CPU。模型在哪,数据就要送到哪。
pred = model(X) # 模型开始预测:输入64张图片,输出64组预测分数(每组10个数字,对应10个类别)
loss = loss_fn(pred, y) # 计算误差,对比模型预测和真实答案,算出模型错的有多严重,loss越大错的越离谱!
# 梯度:模型改错的方向,模型里有无数个数字(卷积核、权重、偏置)。训练时,模型错了,优化器要改这些数字。梯度会告诉模型每个数字是要变大还是变小,让预测更准确。
# 梯度是正数 → 这个数字要变小
# 梯度是负数 → 这个数字要变大
# 梯度绝对值越大 → 改的幅度越大
optimizer.zero_grad() # 清空上一次的梯度(必须写!),因为梯度会累积,防止上一次的错误影响这一次
loss.backward() # 反向传播,计算出每一个参数的梯度,把错误信息传回模型的每一层,告诉卷积核、权重、偏置:你哪里错了?应该往哪个方向改?
# 所以整个训练流程就是:Step1、清空旧梯度。Step2、计算新梯度。Step3、按新梯度改错。
# 梯度下降:模型改错的方向。沿着梯度方向,一步一步往下走,把错误(loss)降到最低!
optimizer.step() # 优化器开始修改模型!根据刚才的错误方向,自动调整卷积核、权重、偏置,模型变得更准一点点
# 把训练模型想象成:
# 你蒙着眼睛下山,目标:走到山谷最底部(loss最小)
# 山谷高度 = loss(误差)
# 越高 = 错得越厉害
# 越低 = 模型越准
# 你 = 模型
# 脚下的坡度方向 = 梯度
# 脚步大小 = 学习率 lr
# 梯度下降做的事:
# 看坡度(梯度)往哪下坡,就往哪走一步!
# 走一步,loss 就低一点!
# 一直走,直到走到谷底!
# 测试(看准确率!!非常重要)
def test_epoch(dataloader, model, loss_fn):
model.eval()
correct = 0
with ((torch.no_grad())):
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X) # 模型预测答案
# 算模型这次猜对了几张!
correct += (
pred.argmax(1) # 模型认为最可能的类别
== y # 和真实答案对比,对就是 True,错就是 False
).type(
torch.float
).sum().item() # 一批里一共猜对多少张,并累加到总正确数。
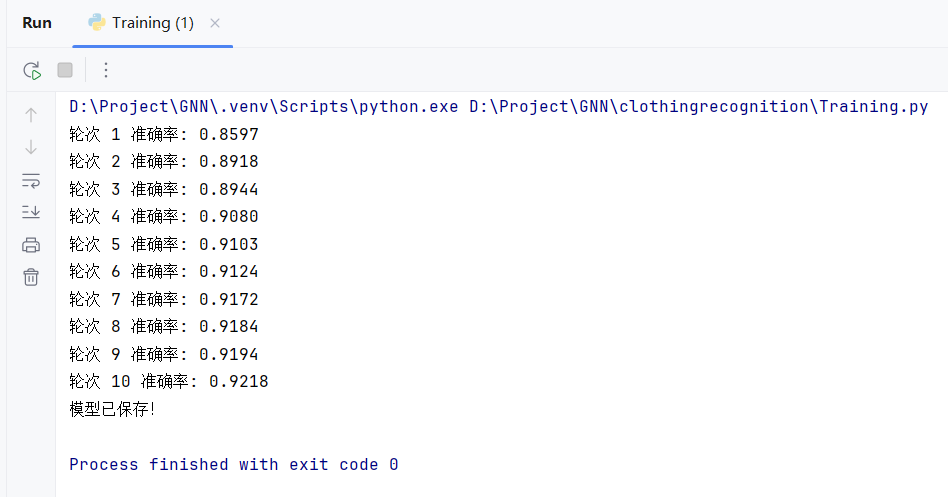
print(f"准确率: {correct / len(dataloader.dataset):.4f}")
# 开始训练
epochs = 10 #10轮训练,每轮训练都给模型看6万张图片。所以模型总共把6万张图片看了10遍。
for t in range(epochs):
print(f"轮次 {t+1}", end=" ")
train_epoch(train_dataloader, model, loss_fn, optimizer)
test_epoch(test_dataloader, model,loss_fn) # 看准确率!
# 把训练好的模型,保存在代码当前文件夹下
torch.save(model.state_dict(), "my_clothing_recognition_model.pth")
print("模型已保存!")经过10次后,训练好的模型。
使用训练好的模型,对图片进行分类。
Forecast.py
python
import torch
import numpy as np # 图片数组处理
from torchvision.transforms import v2
from PIL import Image
from clothingrecognition.NeuralNetwork import NeuralNetwork
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 选择设备(CPU/GPU)
# 加载模型
model = NeuralNetwork().to(device) # 创建一个空模型
model.load_state_dict(torch.load("my_clothing_recognition_model.pth", map_location=device)) # 加载你训练好的模型参数
model.eval() # 切换到测试模式(不训练,只预测)
img_path = r"D:\Project\GNN\datasetload\data\MyImg\连衣裙.png" # r表示原始字符串
# 图片预处理(和训练时完全一致) 把图片变成模型能看懂的张量
transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])
# 图片格式转换
image = (Image.open(img_path)
.convert("L") # 转成灰度图(FashionMNIST 都是灰度)
.resize((28,28))) # 缩放到 28×28 像素(模型只认这个尺寸)
img_np = np.array(image) # 把图片变成数字数组
# 对每个像素的颜色取反,反转黑白!因为 FashionMNIST数据集是"黑底白字",而要识别的图片一般是"白底黑字",通过反转方便模型识别。
img_np = 255 - img_np
image = Image.fromarray(img_np) # 把反转后的数字数组,重新变回图片。
# 把图片送给模型
X = (
transform(image) # 预处理
# 增加一个维度 → 变成 [1, 1, 28, 28],[批次,通道,高度,宽度]
# 第一个1:批次大小,一次只给模型看1张图片。
# 第二个1:通道数,灰度图只有1个通道
# 因为模型只接收一批图片,但现在只给了它一张图片,必须强行增加一个"批次维度",一批(1张)图片模型才能运行
.unsqueeze(0) # 在最前面强行加一个维度,把单张图片变成模型能识别的 "一批图片"
.to(device) # 送到 GPU/CPU
)
# 模型开始预测
with torch.no_grad():
logits = model(X) # 模型输出 10 个原始分数
pred_probab = torch.softmax(logits, dim=1) # softmax:把分数变成概率(0~1)
y_pred = pred_probab.argmax(1).item() # argmax(1):找出概率最大的类别(模型认为最可能的结果)
class_names = ['T恤', '裤子', '套头衫', '连衣裙', '外套',
'凉鞋', '衬衫', '运动鞋', '包', '短靴']
print("预测结果:", y_pred, "→", class_names[y_pred])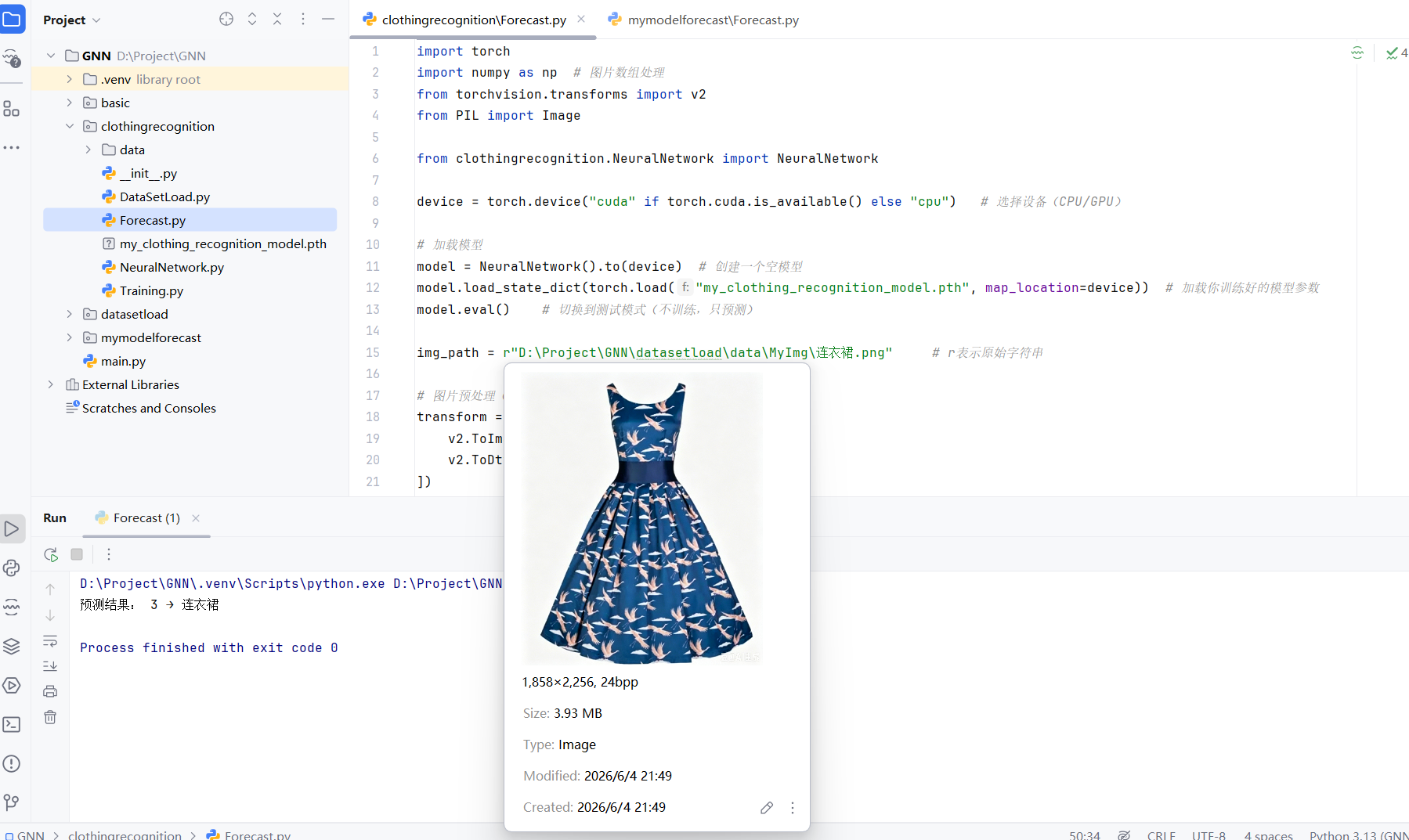
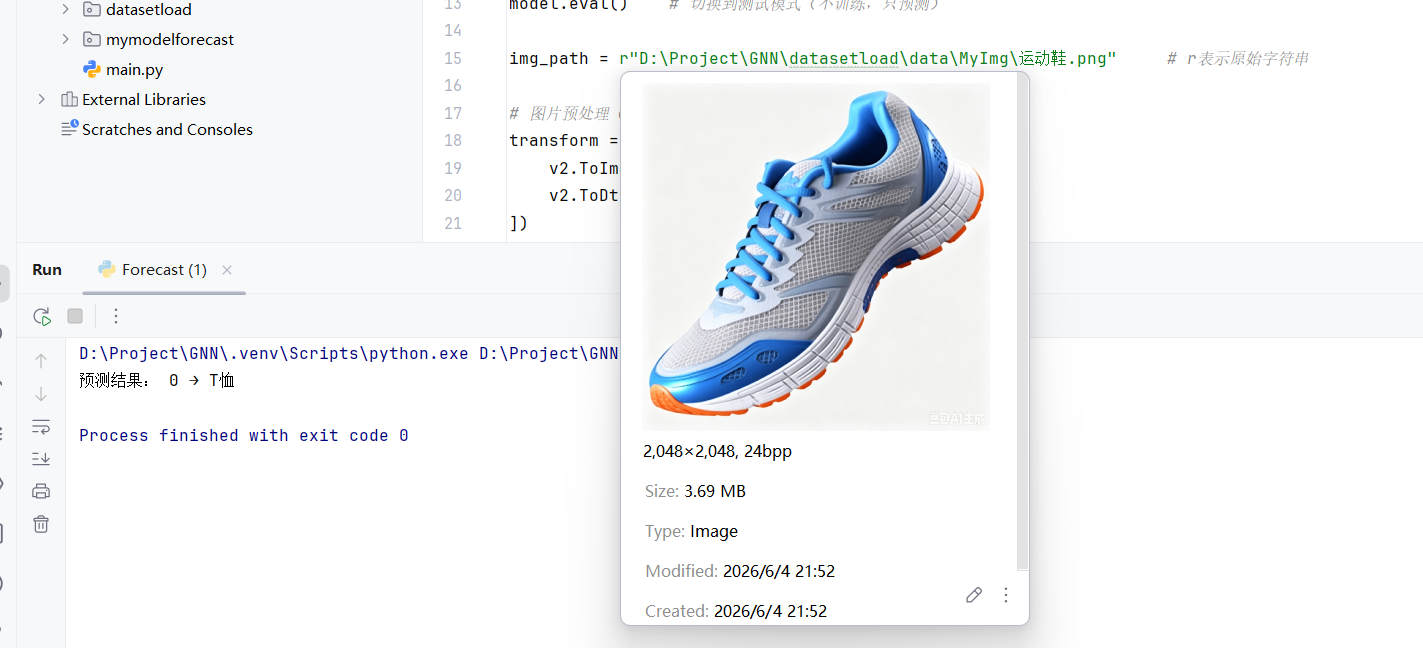
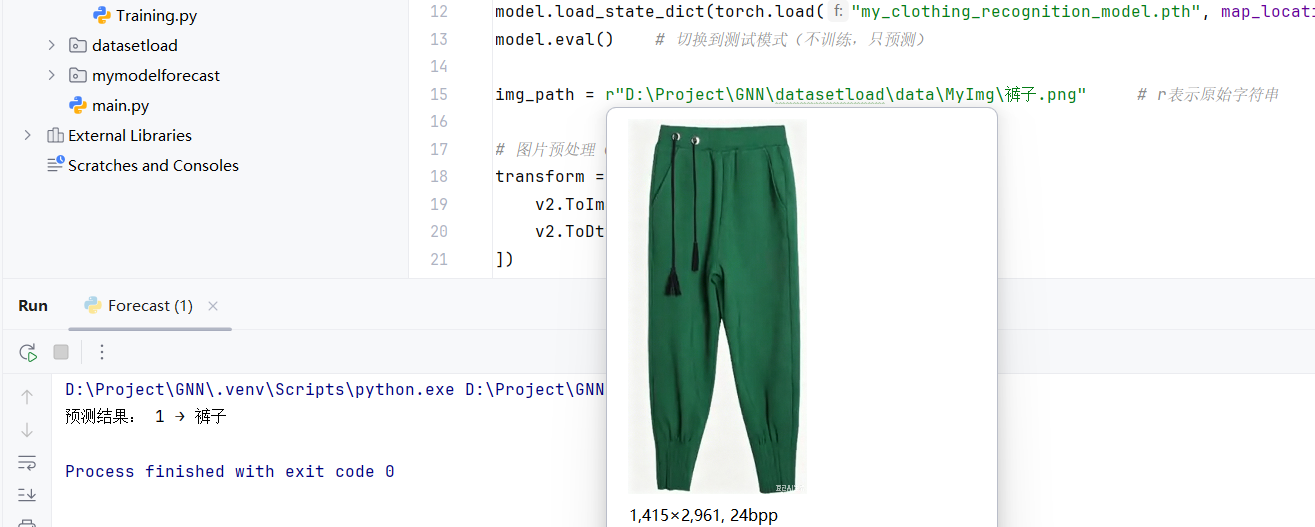
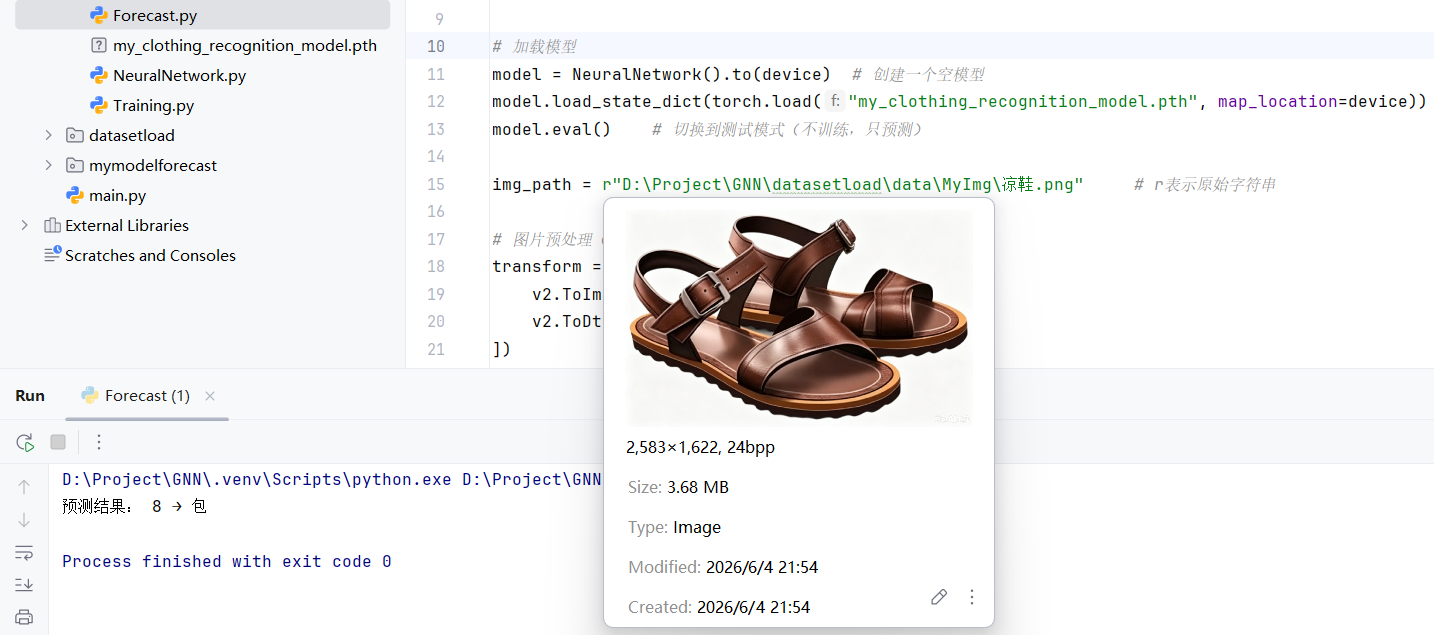
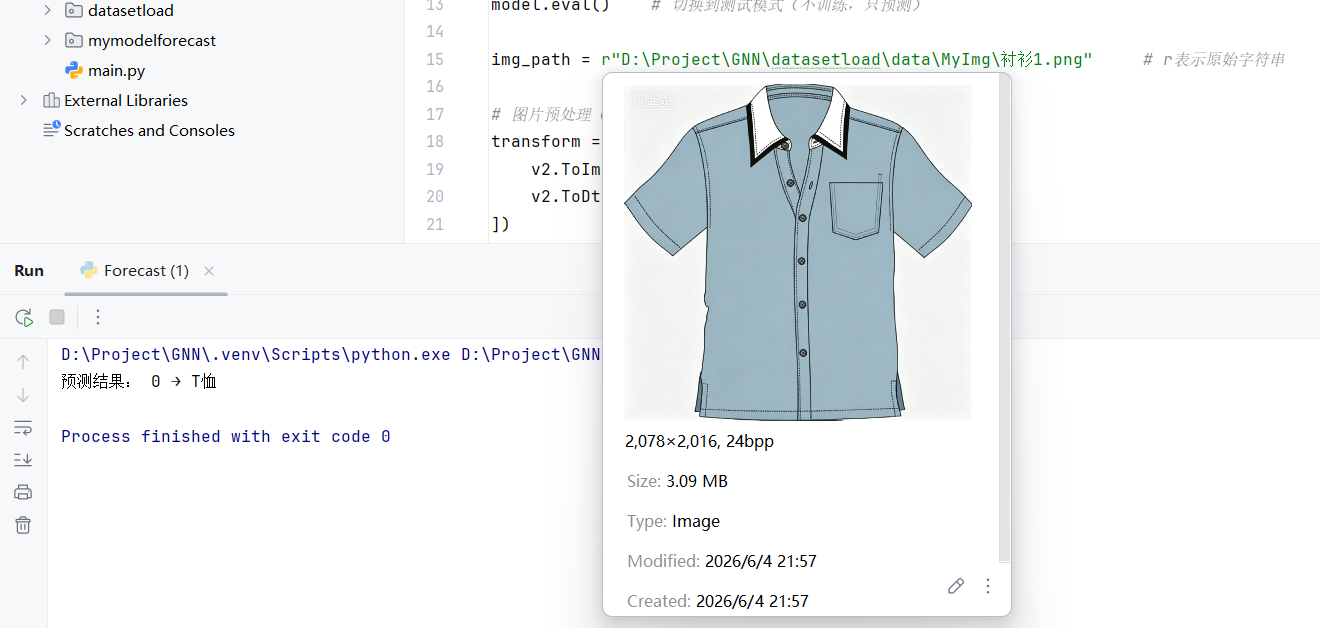
经过初步测试,该模型无法准确预测"鞋子",有时候会把"衬衫"误识别为"T恤"。
3、模型改进
(1)给CNN再加一层卷积
NeuralNetwork.py
python
# 第七层卷积层:
nn.Conv2d(64, 128, 3, padding=1),
# 第八层激活函数层
nn.ReLU(),
# 第九层池化层
nn.MaxPool2d(2),(2)全连接层从128------>256
python
# 模型的大脑决策层
self.fc = nn.Sequential(
# 第一层全连接层:nn.Linear(64*7*7,128)。输入64*7*7=3136个特征,输出128个神经元。把前面卷积看到的所有边缘、纹理、形状,汇总整理成 128 个高级特征。
# 为什么是64?因为最后一层卷积输出64个通道,所以全连接层才写64。7*7是因为两次池化后,28*28的图片缩小为了7*7。展平后就是64*7*7为全连接层输入。
# nn.Linear(64*7*7,128), #128------>256
nn.Linear(128 * 3 * 3, 256), # 为什么是3*3?因为加了一层卷积+池化,最后输出的图片又缩小了一半:7/2=3
# 第二层激活函数层:引入非线性,让模型能够学习复杂的规律。
nn.ReLU(), # 激活函数
# 第三层Dropout层:防止过拟合。
nn.Dropout(0.3), # 训练时,随机让30%的神经元不工作,防止模型死记硬背(过拟合) 每次训练都故意不让一部分神经元参与,强迫模型理解规律,而不是背诵答案!
# 输入128个高级特征(这个128是人为设定的),输出10个数值(分类结果):['T恤', '裤子', '套头衫', '连衣裙', '外套', '凉鞋', '衬衫', '运动鞋', '包', '短靴']
# nn.Linear(128,10) # 第二层全连接层->输出10分类结果
nn.Linear(256, 10) # 第二层全连接层->输出10分类结果
)(3)学习率从 1e-3 → 改成 1e-4,训练轮次增加到30次
Training.py
python
# optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
epochs = 30(4)增加数据增强(防止模型死记硬背,提升泛化能力)
DataSetLoad.py
python
import torch
from torchvision import datasets
from torchvision.transforms import v2
# 训练集 → 带数据增强(✅ 正确)
train_transform = v2.Compose([
v2.ToImage(),
v2.RandomHorizontalFlip(p=0.5), # 随机翻转
v2.RandomAffine(degrees=5, translate=(0.05, 0.05)), # 随机位移
v2.ToDtype(torch.float32, scale=True)
])
# 测试集 → 不带任何随机(✅ 正确)
test_transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])
# 下载训练集数据
training_data = datasets.FashionMNIST(
root="data1", # 数据存在data1文件夹下
train=True, # 等于True表示下载的是训练集(6万张)
download=True, # 本地没有就自动下载
transform=train_transform
)
# 下载测试集数据
test_data = datasets.FashionMNIST(
root="data1",
train=False,
download=True,
transform=test_transform
)最后训练新的模型
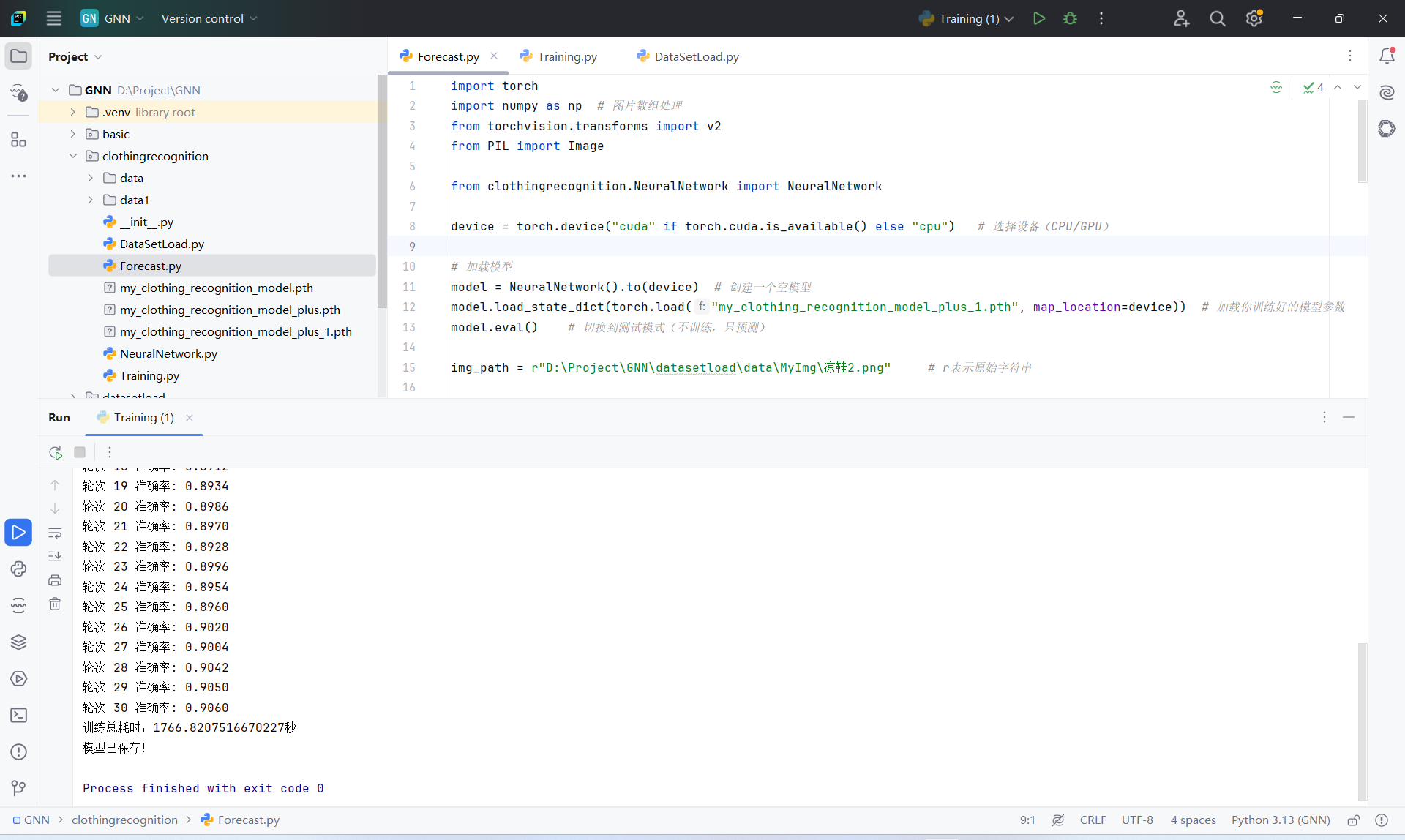
训练好后的新模型,有一点进步,至少可以把运动鞋识别成"短靴"了!但依旧会混淆"衬衫"和"T恤"。也识别不出"凉鞋"。
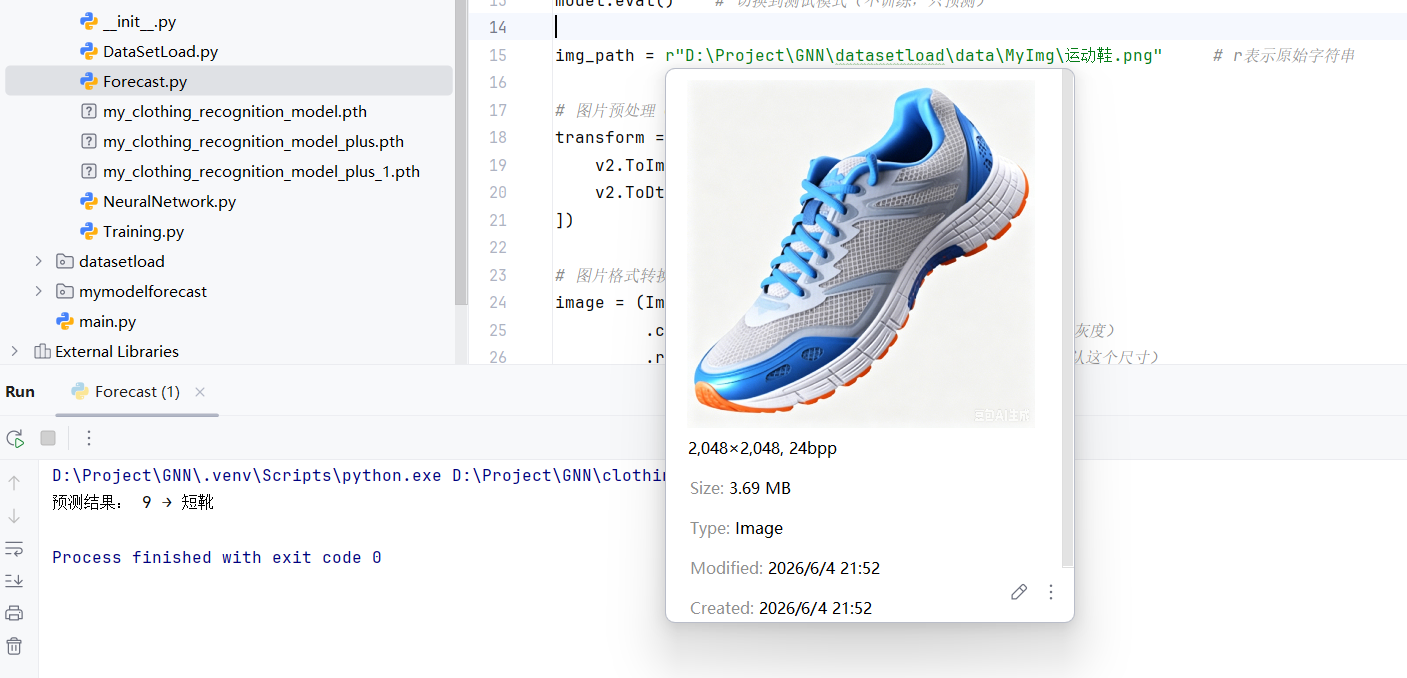
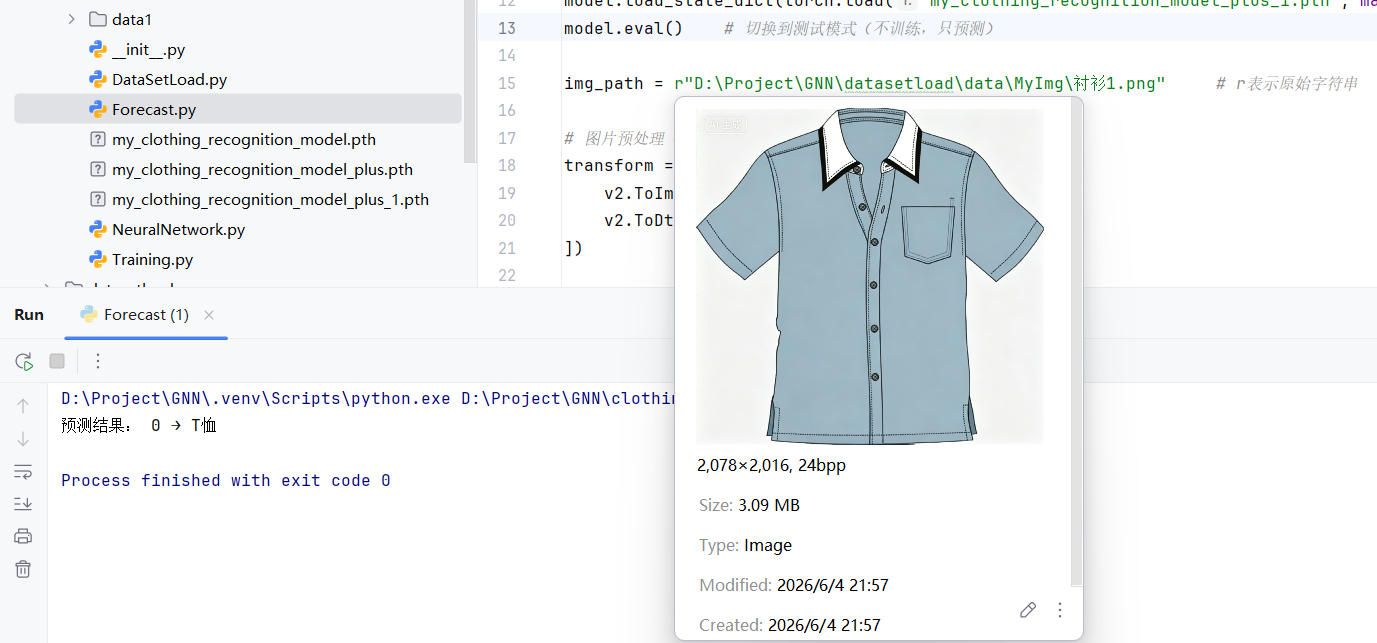
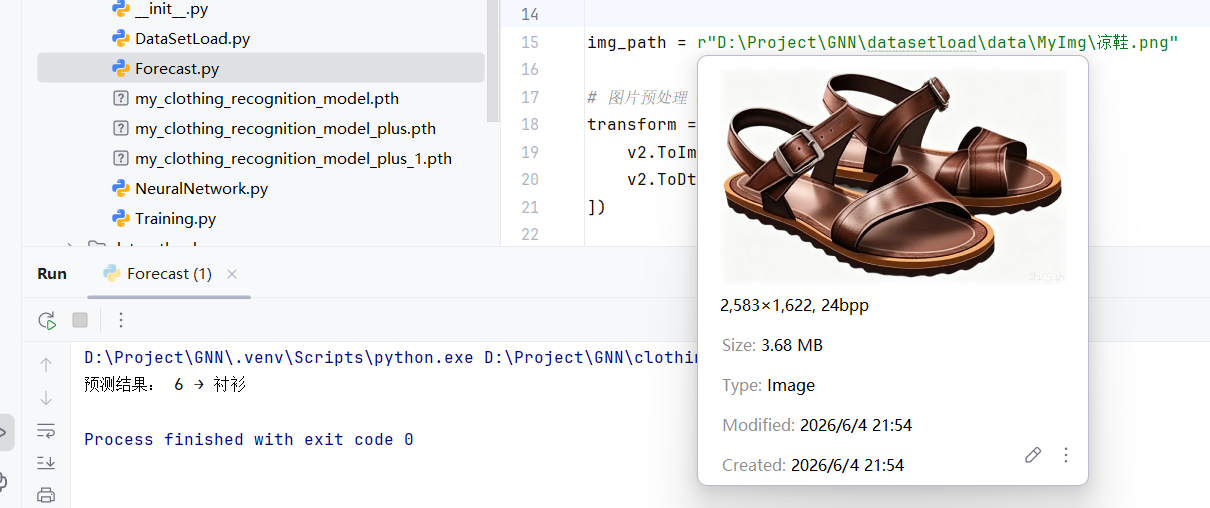
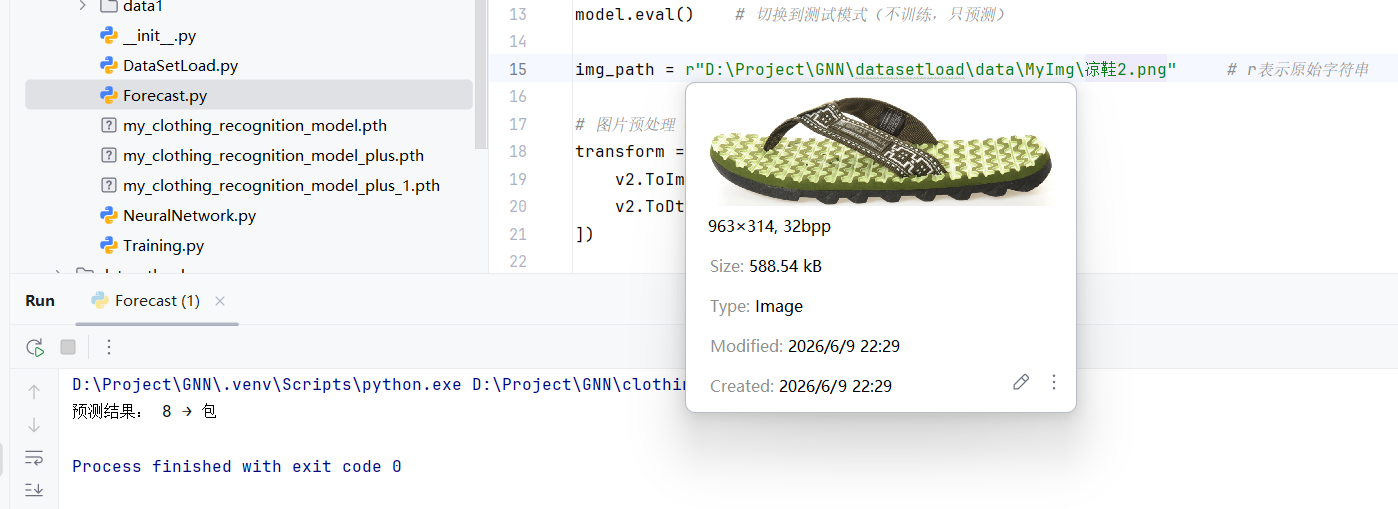
其原因,我觉得是因为FashionMNIST给的数据集图片太过于粗糙了。因此想要模型能更好的识别出衣物,还需要投喂更精细的图片。

4、总结
因为这次是以学习PyTorch的CNN用法为目的,因此就不继续对模型进行改进了。模型代码主要来自于PyTorch官方教程文档和豆包。
5、参考资料
Building Models with PyTorch --- PyTorch Tutorials 2.12.0+cu130 documentation