前言
Python 作为一门语法简洁、应用广泛的编程语言,凭借其强大的标准库和灵活的语法,广受开发者欢迎。想要真正掌握 Python,除了了解基础语法外,还必须熟悉函数、文件操作、异常处理、模块与包,以及常用内置模块等核心知识。这些内容不仅是 Python 入门阶段的重要基础,也是后续进行项目开发、自动化脚本编写和数据处理的必备技能。本文将围绕这些核心主题展开,帮助读者搭建完整的 Python 基础知识体系。
Python函数进阶
函数多返回值(返回元组)
python
def test():
return 'hello world',6
resultOne,resultTwo = test()
print(resultOne)
print(resultTwo)
按照返回值的顺序,写对应顺序的多个变量接收即可
变量之间用逗号隔开
支持不同类型的数据return
函数多种传参方式
函数有4中常见参数使用方式:
- 位置参数
- 关键字参数
- 缺省参数
- 不定长参数
位置参数:调用函数时根据函数定义的参数位置来传递参数
python
def info(name, age, address):
print(f"名字是:{name},年龄是:{age},地址是:{address}")
info('itheima', 18, '河南')
注意:传递的参数和定义的参数的顺序及个数必须一致
关键字参数:函数调用时通过"键=值"形式传递参数.
作用: 可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求.
python
def info(name, age, address):
print(f"名字是:{name},年龄是:{age},地址是:{address}")
info(name = 'itheima',age = 20, address = '北京')
注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用).
作用: 当调用函数时没有传递参数, 就会使用默认是用缺省参数对应的值.
python
def info(name, age, address = '天津'):
print(f"名字是:{name},年龄是:{age},地址是:{address}")
info('itheima', 18)
不定长参数:不定长参数也叫可变参数. 用于不确定调用的时候会传递多少个参数(不传参也可以)的场景.
作用: 当调用函数时不确定参数个数时, 可以使用不定长参数
不定长参数的类型:
- 位置传递
- 关键字传递
python
def info(*names):
print(names)
info("hello", "world", 123, 11)
注意:传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),name是元组类型,这就是位置传递
python
def info(**names):
print(names)
info(name = "hello", sex = "world", address = 123, age = 11)
注意:
参数是"键=值"形式的形式的情况下, 所有的"键=值"都会被names接受, 同时会根据"键=值"组成字典.
匿名函数
python
def my_add(a,b):
return a+b
def test(my_add):
return my_add(1,2)
print(test(my_add))
test需要一个函数作为参数传入,这个函数需要接收2个数字进行计算,计算逻辑由这个被传入函数决定
my_add函数接收2个数字对其进行计算,my_add函数作为参数,传递给了test函数使用
最终,在test函数内部,由传入的my_add函数,完成了对数字的计算操作
函数的定义中
- def关键字,可以定义带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用。
无名称的匿名函数,只可临时使用一次。
匿名函数定义语法:
lambda 传入参数: 函数体(一行代码)
- lambda 是关键字,表示定义匿名函数
- 传入参数表示匿名函数的形式参数,如:x, y 表示接收2个形式参数
- 函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
python
def test(my_add):
return my_add(1,2)
print(test(lambda x,y: x+y))
Python文件操作
文件的编码
计算机使用编码技术(密码本)将内容翻译成0和1存入
计算机中有许多可用编码:
- UTF-8
- GBK
- Big5
- 等
不同的编码,将内容翻译成二进制也是不同的。
文件的读取
在Python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下
python
open(name, mode, encoding)name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
encoding:编码格式(推荐使用UTF-8)
python
file = open('pythonText.txt', 'r', encoding='utf-8')此时的
file是open函数的文件对象,对象是Python中一种特殊的数据类型,拥有属性和方法,可以使用对象.属性或对象.方法对其进行访问
mode常用的三种基础访问模式

read()方法:
python
文件对象.read(num)num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
readlines()方法:
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
python
file = open('pythonText.txt', 'r', encoding='utf-8')
content = file.readlines()
print(content)
file.close()
readline()方法:一次读取一行内容
python
file = open('pythonText.txt', 'r', encoding='utf-8')
content = file.readline()
print(f"第一行内容:{content}")
content = file.readline()
print(f"第二行内容:{content}")
file.close()
for循环读取文件行
python
for line in file:
print(line)
close() 关闭文件对象
最后通过close,关闭文件对象,也就是关闭对文件的占用
如果不调用close,同时程序没有停止运行,那么这个文件将一直被Python程序占用。
with open 语法
python
with open('pythonText.txt', 'r', encoding='utf-8') as file:
print(file.readlines())
通过在with open的语句块中对文件进行操作
可以在操作完成后自动关闭close文件,避免遗忘掉close方法
文件的写入
python
file = open("pythonText.txt", "w",encoding="utf-8")
#文件写入
file.write("hei man")
#内容刷新
file.flush()注意:
直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
当调用flush的时候,内容会真正写入文件
这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
文件如果不存在,使用"w"模式,会创建新文件
文件如果存在,使用"w"模式,会将原有内容清空
文件的追加
python
file = open("pythonText.txt", "a",encoding="utf-8")
#文件写入
file.write("hello world\n")
file.write("itheima\n")
file.write("123456\n")
file.close()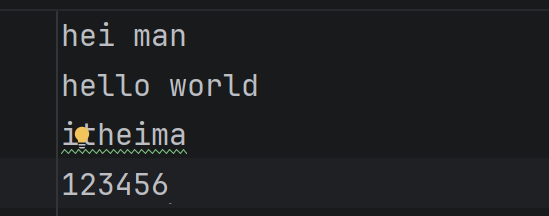
注意:
a模式,文件不存在会创建文件
a模式,文件存在会在最后,追加写入文件
b模式,二进制处理
Python异常、模块与包
了解异常
异常 指的是程序运行期间发生的错误事件。当 Python 解释器遇到一个无法正常处理的情况(比如除以零、打开不存在的文件)时,它会创建并抛出一个异常对象,如果这个异常没有被捕获处理,程序就会中断并打印出错信息(traceback)。
python
print(1 / 0)
语法错误:代码解析阶段发现的错误,比如括号不匹配、缩进错误。程序根本跑不起来。
异常的捕获方法
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。
基本语法:
python
try:
可能发生错误的代码
except:
如果出现异常执行的代码需求:尝试以r模式打开文件,如果文件不存在,则以w方式打开。
python
file = None
try:
file = open('hello.txt','r',encoding='utf-8')
except:
file = open('hello.txt','w',encoding='utf-8')捕获指定异常
基本语法:
python
try:
print(name)
except NameError as e:
print('name变量名称未定义错误')如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。
一般try下方只放一行尝试执行的代码。
当捕获多个异常时,可以把要捕获的异常类型的名字,放到except 后,并使用元组的方式进行书写。
python
try:
print(2/0)
except (NameError, ZeroDivisionError):
print('ZeroDivision错误!!!')
捕获异常并输出描述信息
基本语法:
python
try:
print(num)
except (NameError, ZeroDivisionError) as e:
print(e)捕获所有异常
基本语法:
python
try:
print(name)
except Exception as e:
print(e)异常else
else表示的是如果没有异常要执行的代码。
python
try:
print(1)
except Exception as e:
print(e)
else:
print('我是else,是没有异常的时候执行的代码')finally表示的是无论是否异常都要执行的代码,例如关闭文件。
python
file = None
try:
file = open("hello.txt", 'r')
except:
file = open("hello.txt", 'w')
else:
print("Hello World")
finally:
file.close()
异常的传递
异常是具有传递性的

当函数func01中发生异常, 并且没有捕获处理这个异常的时候, 异常
会传递到函数func02, 当func02也没有捕获处理这个异常的时候
main函数会捕获这个异常, 这就是异常的传递性.
提示:
当所有函数都没有捕获异常的时候, 程序就会报错
利用异常具有传递性的特点, 当我们想要保证程序不会因为异常崩溃的时候, 就可以在main函数中设置异常捕获, 由于无论在整个程序哪里发生异常, 最终都会传递到main函数中, 这样就可以确保所有的异常都会被捕获
python
def test1():
print("test1 start")
2 / 0
print("test2 end")
def test2():
print("test2 start")
test1()
print("test2 end")
def main():
try:
test2()
except ZeroDivisionError as e:
print(f"异常为:{e}")
main()
Python模块
Python 模块(Module),是一个 Python 文件,以 .py 结尾. 模块能定义函数,类和变量,模块里也能包含可执行的代码.
模块的作用: python中有很多各种不同的模块, 每一个模块都可以帮助我
们快速的实现一些功能, 比如实现和时间相关的功能就可以使用time模块
我们可以认为一个模块就是一个工具包, 每一个工具包中都有各种不同的
工具供我们使用进而实现各种不同的功能.
模块在使用前需要先导入 导入的语法如下

常用的组合形式如:
- import 模块名
- from 模块名 import 类、变量、方法等
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
import模块名
基本语法:
python
import 模块名
import 模块名1,模块名2
模块名.功能名()导入time模块中的sleep方法
python
import time
print("start")
time.sleep(2)
print("end")from 模块名 import 功能名
基本语法:
python
from 模块名 import 功能名
功能名()导入time模块中的sleep方法
python
from time import sleep
print("start")
sleep(2)
print("end")from 模块名 import *
基本语法:
python
from 模块名 import *
功能名()导入time模块中所有的方法
python
from time import *
print("start")
sleep(2)
print("end")as定义别名
基本语法:
python
# 模块定义别名
import 模块名 as 别名
# 功能定义别名
from 模块名 import 功能 as 别名模块别名
python
import time as tm
print("start")
tm.sleep(2)
print("end")功能别名
python
from time import sleep as sp
print("start")
sp(2)
print("end")制作自定义模块
新建一个Python文件,命名为my_module1.py,并定义test函数
python
import my_moduleOne
print(my_moduleOne.test(2, 5))
注意:
每个Python文件都可以作为一个模块,模块的名字就是文件的名字. 也就是说自定义模块名必须要符合标识符命名规则
在实际开发中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,
这个开发人员会自行在py文件中添加一些测试信息,例如,在my_moduleOne.py文件中添加测试代码test(2,2)
python
def test(a, b):
print(a + b)
test(2, 2)此时,无论是当前文件,还是其他已经导入了该模块的文件,在运行的时候都会自动执行test函数的调用
python
def test(a, b):
print(a + b)
# 只在当前文件中调用该函数,其他导入的文件内不符合该条件,则不执行test函数调用
if __name__ == '__main__':
test (2, 2)
注意事项:当导入多个模块的时候,且模块内有同名功能. 当调用这个同名功能的时候,调用到的是后面导入的模块的功能
__ all __
如果一个模块文件中有__all__变量,当使用from xxx import *导入时,只能导入这个列表中的元素
python
__all__ = ['testOne']
def testOne():
print("testOne")
def testTwo():
print("testTwo")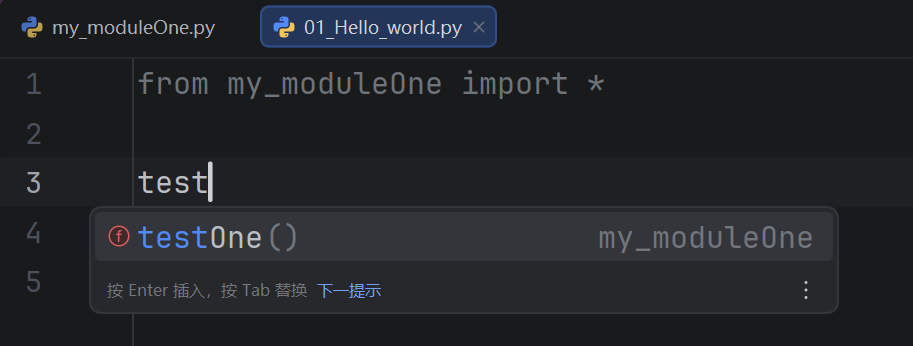
Python包
自定义包
什么是Python包
从物理上看,包就是一个文件夹,在该文件夹下包含了一个 init .py 文件,该文件夹可用于包含多个模块文件
从逻辑上看,包的本质依然是模块
包的作用:
当我们的模块文件越来越多时,包可以帮助我们管理这些模块, 包的作用就是包含多个模块,但包的本质依然是模块
步骤如下:
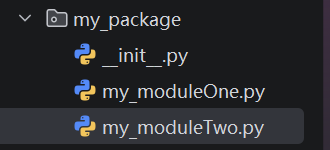
① 新建包my_package
② 新建包内模块:my_moduleOne 和 my_moduleTwo
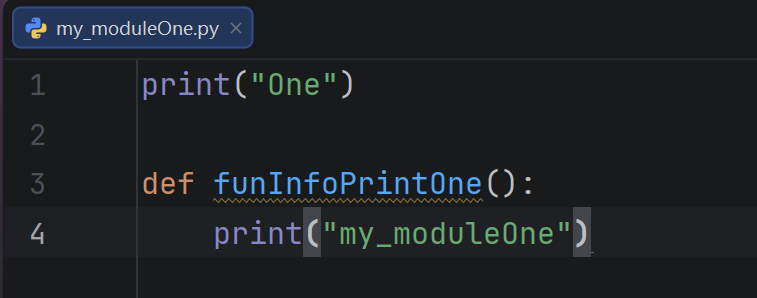
③ 模块内代码如下
Pycharm中的基本步骤:
New Python Package 输入包名 OK 新建功能模块(有联系的模块)
注意:新建包后,包内部会自动创建
__init__.py文件,这个文件控制着包的导入行为
导入包
方式一:
python
import 包名.模块名
包名.模块名.目标
python
import my_package.my_moduleOne
import my_package.my_moduleTwo
my_package.my_moduleOne.funInfoPrintOne()
my_package.my_moduleTwo.funInfoPrintTwo()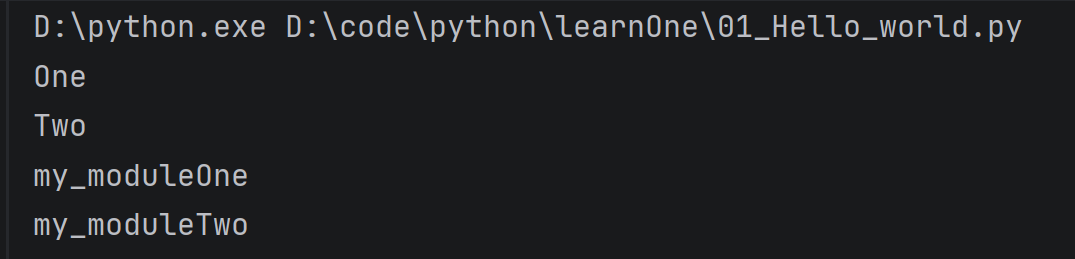
方式二:
注意:必须在__init__.py文件中添加__all__ = [],控制允许导入的模块列表
python
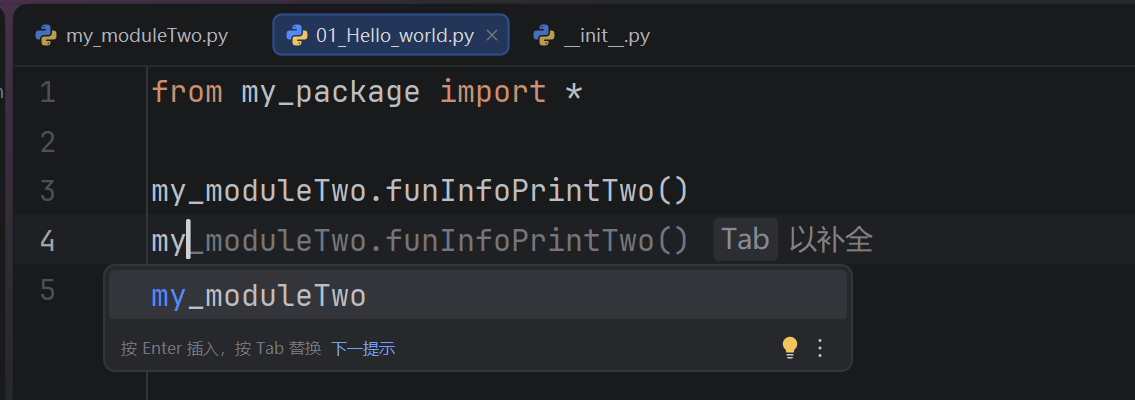
from 包名 import *
模块名.目标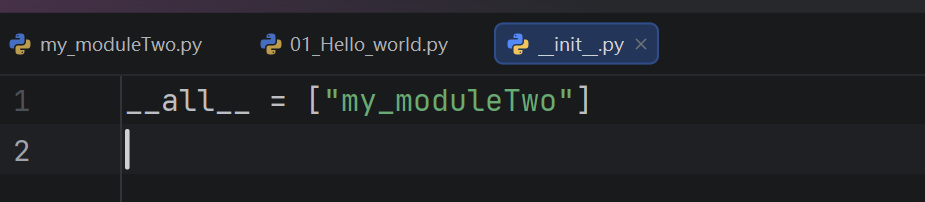
注意:
__all__针对的是 ' from ... import * ' 这种方式
对 ' import xxx ' 这种方式无效
安装第三方包
在Python程序的生态中,有许多非常多的第三方包(非Python官方),可以极大的帮助我们提高开发效率,如:
- 科学计算中常用的:numpy包
- 数据分析中常用的:pandas包
- 大数据计算中常用的:pyspark、apache-flink包
- 图形可视化常用的:matplotlib、pyecharts
- 人工智能常用的:tensorflow
- 等
这些第三方的包,极大的丰富了Python的生态,提高了开发效率。
但是由于是第三方,所以Python没有内置,所以我们需要安装它们才可以导入使用哦。
安装第三方包 - pip
第三方包的安装非常简单,我们只需要使用Python内置的pip程序即可。
打开我们许久未见的:命令提示符程序,在里面输入:
pip install 包名称
即可通过网络快速安装第三方包
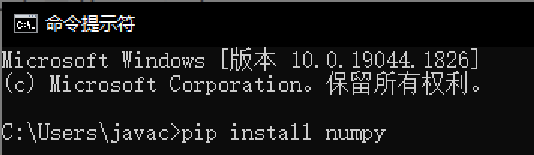
由于pip是连接的国外的网站进行包的下载,所以有的时候会速度很慢。
我们可以通过如下命令,让其连接国内的网站进行包的安装:
python
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
https://pypi.tuna.tsinghua.edu.cn/simple 是清华大学提供的一个网站,可供pip程序下载第三方包
PyCharm也提供了安装第三方包的功能:
Python常用内置模块
Python内置了许多的模块,下面简单介绍几个常用的:
- time 模块,时间相关的功能
- random模块,随机数相关的功能
- os模块,操作系统、文件管理等相关功能
- sys,Python解释器相关功能
时间戳是用一个数字来表示时间。数字指代从1970-01-01 00:00:00开始经过了多久。
有2种精度:
- 秒级精度
- 如时间戳3就表示时间是:1970-01-01 00:00:03
- 如时间戳90,就表示时间是:1970-01-01 00:01:30
- 毫秒级精度
- 如时间戳3000就表示时间是:1970-01-01 00:00:03
- 如时间戳90000,就表示时间是:1970-01-01 00:01:30

通过random模块可以获得随机的数字。

os模块 - 文件相关

sys模块 - Python解释器相关

总结
通过对 Python 函数、文件操作、异常处理、模块与包以及常用内置模块的学习,我们可以逐步建立起完整的 Python 基础能力。这些知识点看似分散,实则相互关联:函数负责组织逻辑,文件操作负责数据交互,异常处理负责程序健壮性,模块与包负责代码结构化,内置模块则为开发提供了强大的工具支持。只有将这些内容融会贯通,才能真正提升 Python 编程能力。