1、模型部署
(1)概述
对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。
相比于软件部署,模型部署会面临的难题:
1)运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如Pytorch,由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
2)深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。
经过工业界和学术界探索出来的一条流行的流水线:
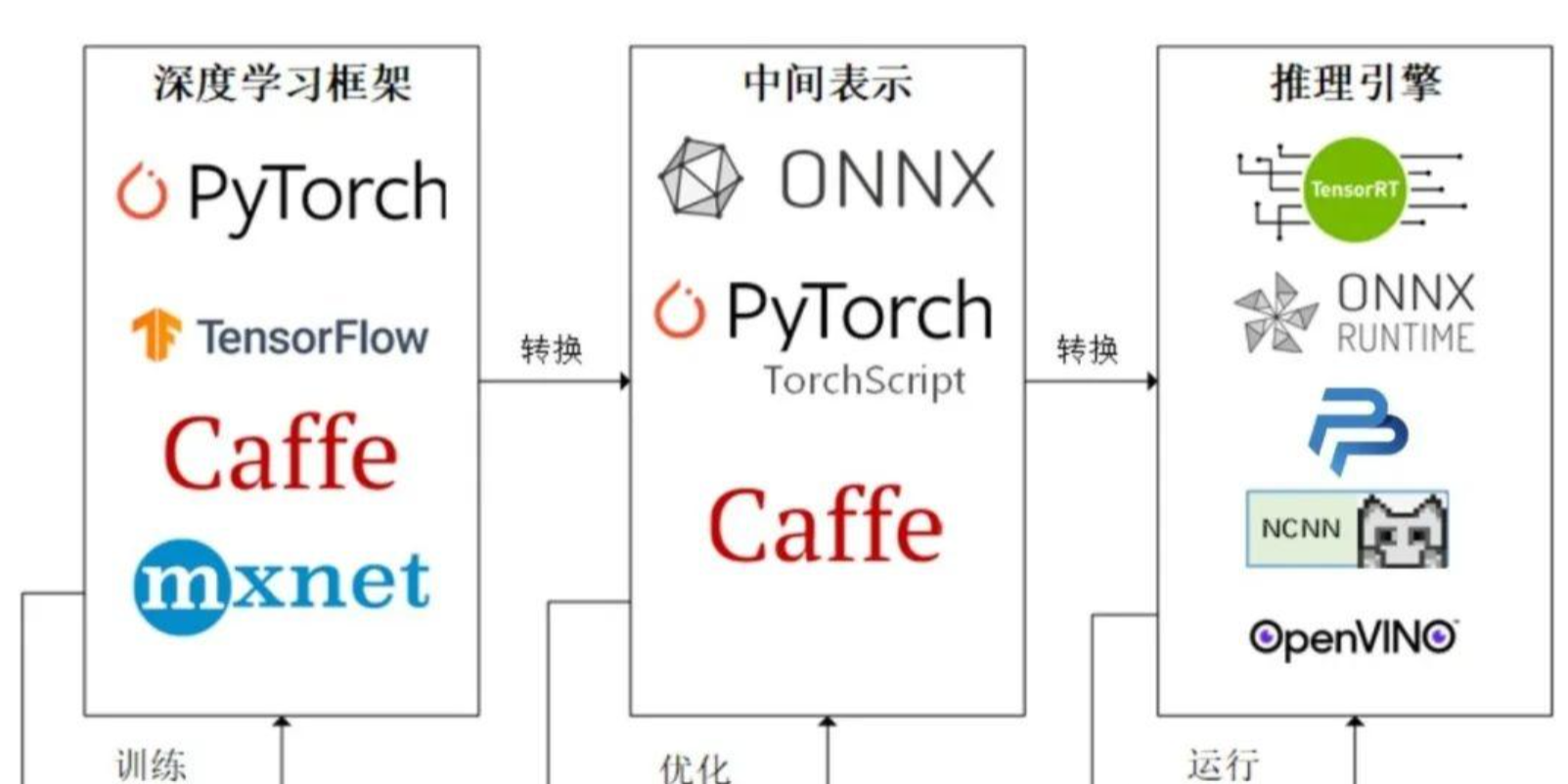
流程:
1)开发者使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。
2)模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。
3)用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型。
(2)概念
模型部署:把训练好的模型在特定环境中运行,模型部署要解决模型框架兼容性差和模型运行速度慢这两大问题。
模型部署的常见流水线:深度学习框架 -> 中间表示 -> 推理引擎,其中比较常用的一个中间表示是ONNX。
深度学习模型:实际上就是一个计算图。模型部署时通常把模型转换成静态的计算图,即没有控制流(分支语句、循环语句)的计算图。
Pytorch框架自带对ONNX的支持,只需要构造一组随机的输入,并对模型调用torch.onnx.export即可完成PyTorch到ONNX的转换。
推理引擎ONNX Runtime对ONNX模型有原生的支持。给定一个.onnx文件,只需要简单使用ONNX Runtime的Python API就可以完成模型推理。
(3)模型部署的难题
1)模型的动态化。处于性能的考虑,各推理框架都默认模型的输入形状、输出形状、结构是静态的。而为了让模型的泛化性更强,部署时需要在尽可能不影响原有逻辑的前提下,让模型的输入输出或是结构动态化。
2)新算子的实现。深度学习技术日新月异,提出新算子的速度往往快于ONNX维护者支持的速度。为了部署最新的模型,部署工程师往往需要自己在ONNX和推理引擎中支持新算子。
3)中间表示和推理引擎的兼容问题。由于各推理引擎的实现不同,对ONNX难以形成统一的支持。为了确保模型在不同的推理引擎中有同样的运行效果,部署工程师往往得为某个推理引擎定制模型代码,这为模型部署引入了许多工作量。
(4)TorchScript概念
TorchScript是一种序列化和优化Pytorch模型的格式,在优化过程中,一个torch.nn.Module模型会被转换成TorchScript的torch.jit.ScriptModule模型。
torch.onnx.export中需要的模型实际上是一个torch.jit.ScriptModule。而要把普通Pytorch模型转一个这样的TorchScript模型,有跟踪(trace)和记录(script)两种导出计算图的方法。默认情况下是跟踪的方法。
跟踪法只能通过实际运行一遍模型的方法导出模型的静态图,即无法识别出模型中的控制流(如循环)。记录法则能通过解析模型来正确记录所有的控制流。
2、ONNX概念说明
(1)概述
ONNX(Open Neural Network Exchange)是一种跨框架的模型表示标准,优势:
1.框架互操作性:允许用户在一个框架中训练模型,在另一个框架中部署。
2.硬件无关性:ONNX运行时(ONNX Runtime)可以在多种硬件平台上运行,包括CPU、GPU以及各种专用AI加速器,类似于JVM。
3.工具链丰富:围绕ONNX生态已经发展出大量工具,包括模型优化器、可视化工具、验证工具等
(2)ProtoBuf
ONNX作为一个文件格式,需要一定的规则去读取我们想要的信息或者是写入我们需要保存的信息。
ONNX使用的是Protobuf这个序列化数据结构去存储神经网络的权重信息。
Protobuf是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
3、实战演示第一个ONNX程序
任务:
1.写一个Pytorch网络结构
2.导出为ONNX格式的模型文件
3.加载ONNX模型并运行
(1)创建Pytorch网络结构并导出
python
import torch
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 5)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(5, 2)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
model = SimpleModel()
# 模拟训练过程
input_sample = torch.randn(1, 10)
target = torch.tensor([1])
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in tqdm(range(100), desc="Training"):
optimizer.zero_grad()
output = model(input_sample)
loss = criterion(output, target)
loss.backward()
optimizer.step()
dummy_input = torch.randn(1, 10)
# 导出模型
torch.onnx.export(
model,
dummy_input,
'simple_model.onnx',
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names=['input'],
output_names=['output'],
dynamic_axes={
'input': {0: 'batch_size'},
'output': {0: 'batch_size'}
}
)(2)使用ONNX Runtime进行推理
python
import onnxruntime as ort
import numpy as np
ort_session = ort.InferenceSession('simple_model.onnx')
input_data = np.random.randn(1, 10).astype(np.float32)
outputs = ort_session.run(None, {'input': input_data})
print("res:", outputs[0])运行结果:
res: \[-1.05651 0.3401999]
(3)torch.onnx.export入参解读
1)model
要导出的Pytorch模型,必须是nn.Module类型
2)dummy_input
假输入,用于Pytorch跑一遍模型,记录计算图。
形状必须和真正推理时的输入一致。
比如模型输入是(batch, 10),这里就必须给(1, 10)
3)export_params=True
是否导出模型权重(参数)。
True:导出权重,模型文件大,可直接推理
False:只导出结构,不导出权重,空模型
4)opset_version=11
ONNX的"语法版本",不同版本支持不同算子。
5)do_constant_folding=True
开启常量折叠优化。
把模型里固定不变的常量提前算好,减少推理算子,加速推理。
比如:x = 2 + 3 -> 直接变x=5
6)input_names='input'
给模型输入起名字。
你给它取名input,那么推理时必须传入input
7)dynamic_axes
动态轴:允许输入维度不固定。
默认导出的模型输入是固定形状,比如(1,10)
加了之后,第0维(batch维度)不固定,可以是任意大小。。比如(4,10)
不加dynamic_axes就只能跑固定shape。
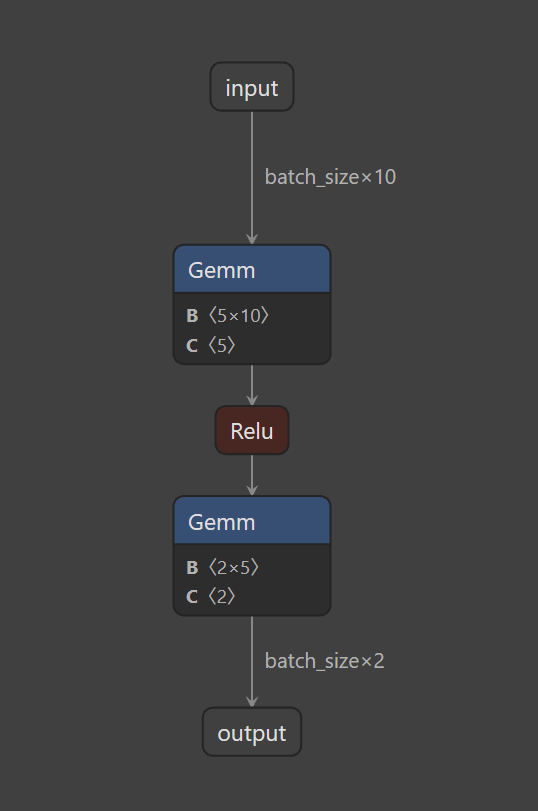
(4)Netron查看模型
示例代码:
python
import netron
import time
model_name = "simple_model.onnx"
netron.start(model_name)
while True:
time.sleep(1)得到图:
4、部署SRCNN模型
(1)创建一个经典的超分辨率模型SRCNN
python
import os
import numpy as np
import torch
import torch.onnx
import torch.nn as nn
import cv2
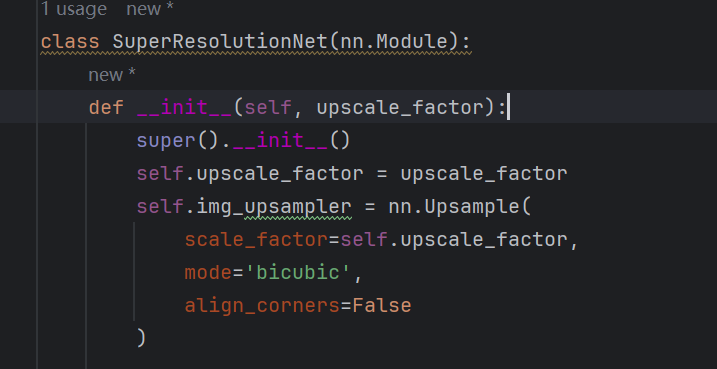
class SuperResolutionNet(nn.Module):
def __init__(self, upscale_factor):
super().__init__()
self.upscale_factor = upscale_factor
self.img_upsampler = nn.Upsample(
scale_factor=self.upscale_factor,
mode='bicubic',
align_corners=False
)
self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)
self.conv2 = nn.Conv2d(64, 32, kernel_size=1, padding=0)
self.conv3 = nn.Conv2d(32, 3, kernel_size=5, padding=2)
self.relu = nn.ReLU()
def forward(self, x):
x = self.img_upsampler(x)
out = self.relu(self.conv1(x))
out = self.relu(self.conv2(out))
out = self.conv3(out)
return out
model_path = r"D:\appdata\models\srcnn\srcnn.pth"
img_path = r"D:\appdata\models\srcnn\000001.png"
def init_torch_model():
torch_model = SuperResolutionNet(upscale_factor=3)
state_dict = torch.load(model_path)['state_dict']
# Adapt the checkpoint
for old_key in list(state_dict.keys()):
new_key = '.'.join(old_key.split('.')[1:])
state_dict[new_key] = state_dict.pop(old_key)
torch_model.load_state_dict(state_dict)
torch_model.eval()
return torch_model
model = init_torch_model()
input_img = cv2.imread(img_path).astype(np.float32)
# HWC to NCHW
input_img = np.transpose(input_img, [2, 0, 1])
input_img = np.expand_dims(input_img, 0)
# Inference
torch_output = model(torch.from_numpy(input_img)).detach().numpy()
# NCHW to HWC
torch_output = np.squeeze(torch_output, 0)
torch_output = np.clip(torch_output, 0, 255)
torch_output = np.transpose(torch_output, [1, 2, 0]).astype(np.uint8)
# Show image
cv2.imwrite("face_torch.png", torch_output)
x = torch.randn(1, 3, 256, 256)
with torch.no_grad():
torch.onnx.export(
model,
x,
"srcnn.onnx",
opset_version=11,
input_names=['input'],
output_names=['output']
)跳过训练的过程,直接用训练好的模型,模型链接地址:
https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth测试图片地址:
https://raw.githubusercontent.com/open-mmlab/mmediting/master/tests/data/face/000001.png【SuperResolutionNet类说明】
1)nn.Upsample上采样
作用:先把低分辨率图片放大
2)三层卷积(SRCNN标准化结构)
3)ReLU激活函数
给网络增加非线性能力,让模型学习复杂的图像特征。
【前向传播forward】
低分辨率图 -> 上采样放大 -> 卷积提取特征 -> 卷积优化 -> 输出高分辨率图
【init_torch_model函数】
Adapt the checkpoint做权重键名适配,
原key:model.conv1.weight
处理后:conv1.weight
【图像格式说明】
OpenCV读取格式:HWC(高 * 宽 * 通道,RGB)
PyTorch要求格式:NCHW(批次 * 通道 * 高 * 宽)
【整体运行流程总结】
1.导入库 -> 定义SRCNN超分网络
2.加载本地预训练模型权重
3.读取低分辨率图片
4.格式转换(HWC -> NCHW)
5.模型推理得到高清图
6.格式还原(NCHW -> HWC)
7.保存最终高清图片
【torch.onnx.export额外给一组输入的原因】
模型转ONNX,本质就是把Pytorch的模型翻译成ONNX能识别的格式。
PyTorch是动态计算图,灵活度高;但ONNX只支持固定的静态计算图,不识别复杂的控制逻辑。所以PyTorch用了追踪(trace)的方式完成转换:随便给一组输入数据,让模型完整跑一次前向推理,系统趁机记录下这一整套固定的计算流程,最后保存为ONNX文件。
(2)检查模型
python
import onnx
onnx_model = onnx.load("srcnn.onnx")
try:
onnx.checker.check_model(onnx_model)
except Exception:
print("Model incorrect")
else:
print("Model correct")(3)推理引擎-ONNX Runtime
onnx runtime是微软维护的一个跨平台及其学习推理加速器,直接对接onnx的,即onnx runtime可以直接读取并运行.onnx文件,而不需要把.onnx格式的文件转换成其他格式的文件 。
运行推理引擎:
python
import onnxruntime
import cv2
import numpy as np
ort_session = onnxruntime.InferenceSession("srcnn.onnx")
img_path = r"D:\appdata\models\srcnn\000001.png"
input_img = cv2.imread(img_path).astype(np.float32)
input_img = np.transpose(input_img, [2, 0, 1])
input_img = np.expand_dims(input_img, 0)
ort_inputs = {'input': input_img}
ort_output = ort_session.run(['output'], ort_inputs)[0]
ort_output = np.squeeze(ort_output, 0)
ort_output = np.clip(ort_output, 0, 255)
ort_output = np.transpose(ort_output, [1,2,0]).astype(np.uint8)
cv2.imwrite("face_ort.png", ort_output)onnxruntime.InferenceSession用于获取一个ONNX Runtime推理器。
第一个参数为输出张量名的列表,第二个参数为输入值的字典,输入输出张量的名称需要和torch.onnx.export中设置的输入输出名对应。
5、创建ONNX算子
(1)问题背景
在SRCNN的例子中,图片的放大比例是写死在模型里的。
初始化模型时默认令upscale_factor为3,生成了一个放大3倍的Pytorch模型,这个Pytorch模型最终被转换成了ONNX格式的模型。如果需要一个放大4倍的模型,则需要重新生成一遍模型,再做一次到ONNX的转换。
现在的新需求是:假设我们要做一个超分辨率的应用,我们的用户希望图片的放大倍数能够自由设置,而我们交给用户的,只有一个.onnx文件和运行超分辨率模型的应用程序,能够在不修改.onnx文件的前提下改变放大倍数。
新代码如下:
python
import os
import numpy as np
import torch
import torch.onnx
import torch.nn as nn
import cv2
from torch.nn.functional import interpolate
class SuperResolutionNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)
self.conv2 = nn.Conv2d(64, 32, kernel_size=1, padding=0)
self.conv3 = nn.Conv2d(32, 3, kernel_size=5, padding=2)
self.relu = nn.ReLU()
def forward(self, x, upscale_factor):
x = interpolate(
x,
scale_factor=upscale_factor,
mode='bicubic',
align_corners=False
)
out = self.relu(self.conv1(x))
out = self.relu(self.conv2(out))
out = self.conv3(out)
return out
model_path = r"D:\appdata\models\srcnn\srcnn.pth"
img_path = r"D:\appdata\models\srcnn\000001.png"
def init_torch_model():
torch_model = SuperResolutionNet()
state_dict = torch.load(model_path)['state_dict']
# Adapt the checkpoint
for old_key in list(state_dict.keys()):
new_key = '.'.join(old_key.split('.')[1:])
state_dict[new_key] = state_dict.pop(old_key)
torch_model.load_state_dict(state_dict)
torch_model.eval()
return torch_model
model = init_torch_model()
input_img = cv2.imread(img_path).astype(np.float32)
# HWC to NCHW
input_img = np.transpose(input_img, [2, 0, 1])
input_img = np.expand_dims(input_img, 0)
# Inference
torch_output = model(torch.from_numpy(input_img), 3).detach().numpy()
# NCHW to HWC
torch_output = np.squeeze(torch_output, 0)
torch_output = np.clip(torch_output, 0, 255)
torch_output = np.transpose(torch_output, [1, 2, 0]).astype(np.uint8)
# Show image
cv2.imwrite("face_torch2.png", torch_output)
x = torch.randn(1, 3, 256, 256)
with torch.no_grad():
torch.onnx.export(
model,
(x,3),
"srcnn2.onnx",
opset_version=11,
input_names=['input', 'factor'],
output_names=['output']
)上面代码中,PyTorch的interpolate插值算子可以在运行阶段选择放大倍数,因此使用interpolate代替nn.Upsample,从而让模型支持动态放大倍数的超分。
运行程序后,可以得到face_torch2.png文件。
torch.onnx.export中的输入从x变成了(x,3),两个入参。
但是torch.onnx.export导出模型时报错了:
python
TypeError: upsample_bicubic2d() received an invalid combination of arguments - got (Tensor, NoneType, bool, list), but expected one of:
* (Tensor input, tuple of ints output_size, bool align_corners, tuple of floats scale_factors)
didn't match because some of the arguments have invalid types: (Tensor, !NoneType!, bool, !list of [Tensor, Tensor]!)
* (Tensor input, tuple of ints output_size, bool align_corners, float scales_h = None, float scales_w = None, *, Tensor out = None)这就是模型部署中的兼容性问题,解决方法:自定义算子。
(2)原因分析及尝试解决
报错原因是因为PyTorch模型在导出到ONNX模型时,模型的输入参数的类型必须全部是torch.Tensor,而实际上我们传入的第二个参数"3"是一个整型变量,这不符合PyTorch转ONNX的规定。
解决方法:将输入3改为torch.tensor(3),如果需要数值则通过torch.Tensor.item()来把只有一个元素的torch.Tensor转换成数值。
修改后的代码如下:
python
import os
import numpy as np
import torch
import torch.onnx
import torch.nn as nn
import cv2
from torch.nn.functional import interpolate
class SuperResolutionNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)
self.conv2 = nn.Conv2d(64, 32, kernel_size=1, padding=0)
self.conv3 = nn.Conv2d(32, 3, kernel_size=5, padding=2)
self.relu = nn.ReLU()
def forward(self, x, upscale_factor):
x = interpolate(
x,
scale_factor=upscale_factor.item(),
mode='bicubic',
align_corners=False
)
out = self.relu(self.conv1(x))
out = self.relu(self.conv2(out))
out = self.conv3(out)
return out
model_path = r"D:\appdata\models\srcnn\srcnn.pth"
img_path = r"D:\appdata\models\srcnn\000001.png"
def init_torch_model():
torch_model = SuperResolutionNet()
state_dict = torch.load(model_path)['state_dict']
# Adapt the checkpoint
for old_key in list(state_dict.keys()):
new_key = '.'.join(old_key.split('.')[1:])
state_dict[new_key] = state_dict.pop(old_key)
torch_model.load_state_dict(state_dict)
torch_model.eval()
return torch_model
model = init_torch_model()
input_img = cv2.imread(img_path).astype(np.float32)
# HWC to NCHW
input_img = np.transpose(input_img, [2, 0, 1])
input_img = np.expand_dims(input_img, 0)
# Inference
torch_output = model(torch.from_numpy(input_img), torch.tensor(3)).detach().numpy()
# NCHW to HWC
torch_output = np.squeeze(torch_output, 0)
torch_output = np.clip(torch_output, 0, 255)
torch_output = np.transpose(torch_output, [1, 2, 0]).astype(np.uint8)
# Show image
cv2.imwrite("face_torch2.png", torch_output)
x = torch.randn(1, 3, 256, 256)
with torch.no_grad():
torch.onnx.export(
model,
(x, torch.tensor(3)),
"srcnn2.onnx",
opset_version=11,
input_names=['input', 'factor'],
output_names=['output']
)此时程序能够正常运行,但是有一个报警:
python
TracerWarning: Converting a tensor to a Python number might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
scale_factor=upscale_factor.item(),翻译一下:你把一个Pytorch张量(tensor)转成了普通python数字,onnx追踪器无法记录这个动态值,会把它当成固定常量。
因为ONNX追踪(trace)只能记录张量运算,不能记录Python变量。所以转成onnx后,scale_factor会被固定死,以后向改放大倍数,onnx模型不会生效。
通过netron查看图结构:
python
import netron
import time
model_name = r"D:\workspace\github\nano-vllm\llm\tests\onnx\openmmlab\srcnn2.onnx"
netron.start(model_name)
while True:
time.sleep(1)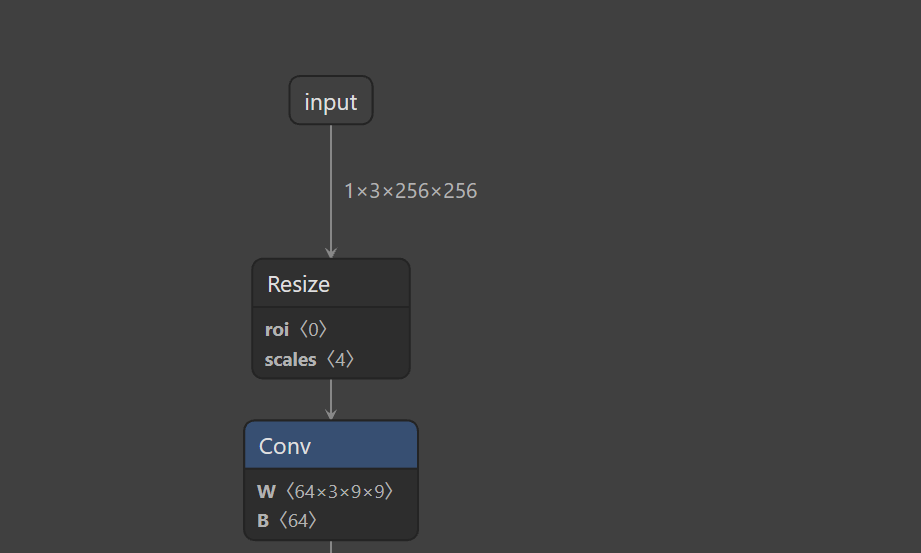
可以发现,虽然我们把模型推理的输入设置为了两个,但ONNX模型还是和之前一样,只有一个"input"输入。这是由于我们使用了torch.Tensor.item()把数据从Tensor里取出来,而导出ONNX模型时这个操作是无法被记录的,只好报了一条TraceWarning。这导致interpolate插值函数的放大倍数还是被设置成了"3"这个固定值,所以srcnn2.onnx和srcnn.onx完全相同。
(3)问题分析2及终极解决方案
仔细观察Netron上的onnx模型,可以发现无论是最早的nn.Upsample还是后来的interpolate,Pytorch里的插值操作最后都会转换成onnx定义的resize操作。
也就是说,所谓Pytorch转ONNX,实际上就是把每个Pytorch的操作映射成了ONNX定义的算子。
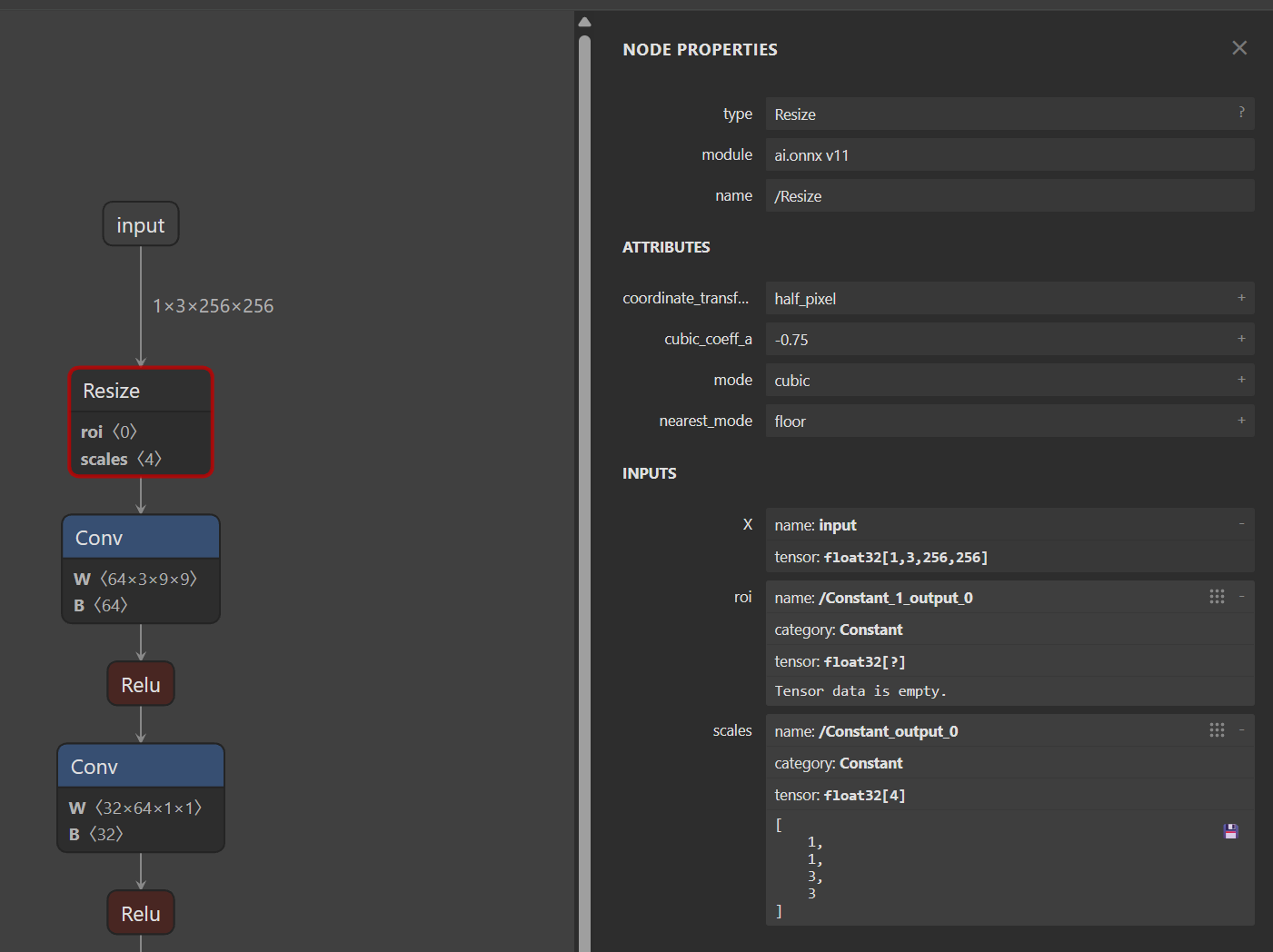
查看Resize的Inputs->scales信息,它的长度为4,其内容是1,1,3,3,表示Resize操作每一个维度的缩放系数。其类型是Constant,表示是一个常数。
如果我们能够自己生成一个ONNX的Resize算子,让scales成为一个可变量而不是常量,就像它上上面的X一样,那这个超分辨率模型就能动态缩放了。
新的需求:定义一个实现插值的Pytorch算子,然后让它映射到一个我们期望的ONNX Resize算子上。
新代码如下:
python
import os
import numpy as np
import torch
import torch.onnx
import torch.nn as nn
import cv2
from torch.nn.functional import interpolate
class NewInterpolate(torch.autograd.Function):
@staticmethod
def symbolic(g, input, scales):
return g.op(
"Resize",
input,
g.op(
"Constant",
value_t=torch.tensor([], dtype=torch.float32)),
scales,
coordinate_transformation_mode_s="pytorch_half_pixel",
cubic_coeff_a_f=-0.75,
mode_s='cubic',
nearest_mode_s='floor'
)
@staticmethod
def forward(ctx, input, scales):
scales = scales.tolist()[-2:]
return interpolate(input,
scale_factor=scales,
mode='bicubic',
align_corners=False)
class StrangeSuperResolutionNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)
self.conv2 = nn.Conv2d(64, 32, kernel_size=1, padding=0)
self.conv3 = nn.Conv2d(32, 3, kernel_size=5, padding=2)
self.relu = nn.ReLU()
def forward(self, x, upscale_factor):
x = NewInterpolate.apply(x, upscale_factor)
out = self.relu(self.conv1(x))
out = self.relu(self.conv2(out))
out = self.conv3(out)
return out
model_path = r"D:\appdata\models\srcnn\srcnn.pth"
img_path = r"D:\appdata\models\srcnn\000001.png"
def init_torch_model():
torch_model = StrangeSuperResolutionNet()
state_dict = torch.load(model_path)['state_dict']
# Adapt the checkpoint
for old_key in list(state_dict.keys()):
new_key = '.'.join(old_key.split('.')[1:])
state_dict[new_key] = state_dict.pop(old_key)
torch_model.load_state_dict(state_dict)
torch_model.eval()
return torch_model
model = init_torch_model()
factor = torch.tensor([1,1,3,3], dtype=torch.float)
input_img = cv2.imread(img_path).astype(np.float32)
# HWC to NCHW
input_img = np.transpose(input_img, [2, 0, 1])
input_img = np.expand_dims(input_img, 0)
# Inference
torch_output = model(torch.from_numpy(input_img), factor).detach().numpy()
# NCHW to HWC
torch_output = np.squeeze(torch_output, 0)
torch_output = np.clip(torch_output, 0, 255)
torch_output = np.transpose(torch_output, [1, 2, 0]).astype(np.uint8)
# Show image
cv2.imwrite("face_torch3.png", torch_output)
x = torch.randn(1, 3, 256, 256)
with torch.no_grad():
torch.onnx.export(
model,
(x, factor),
"srcnn3.onnx",
opset_version=11,
input_names=['input', 'factor'],
output_names=['output']
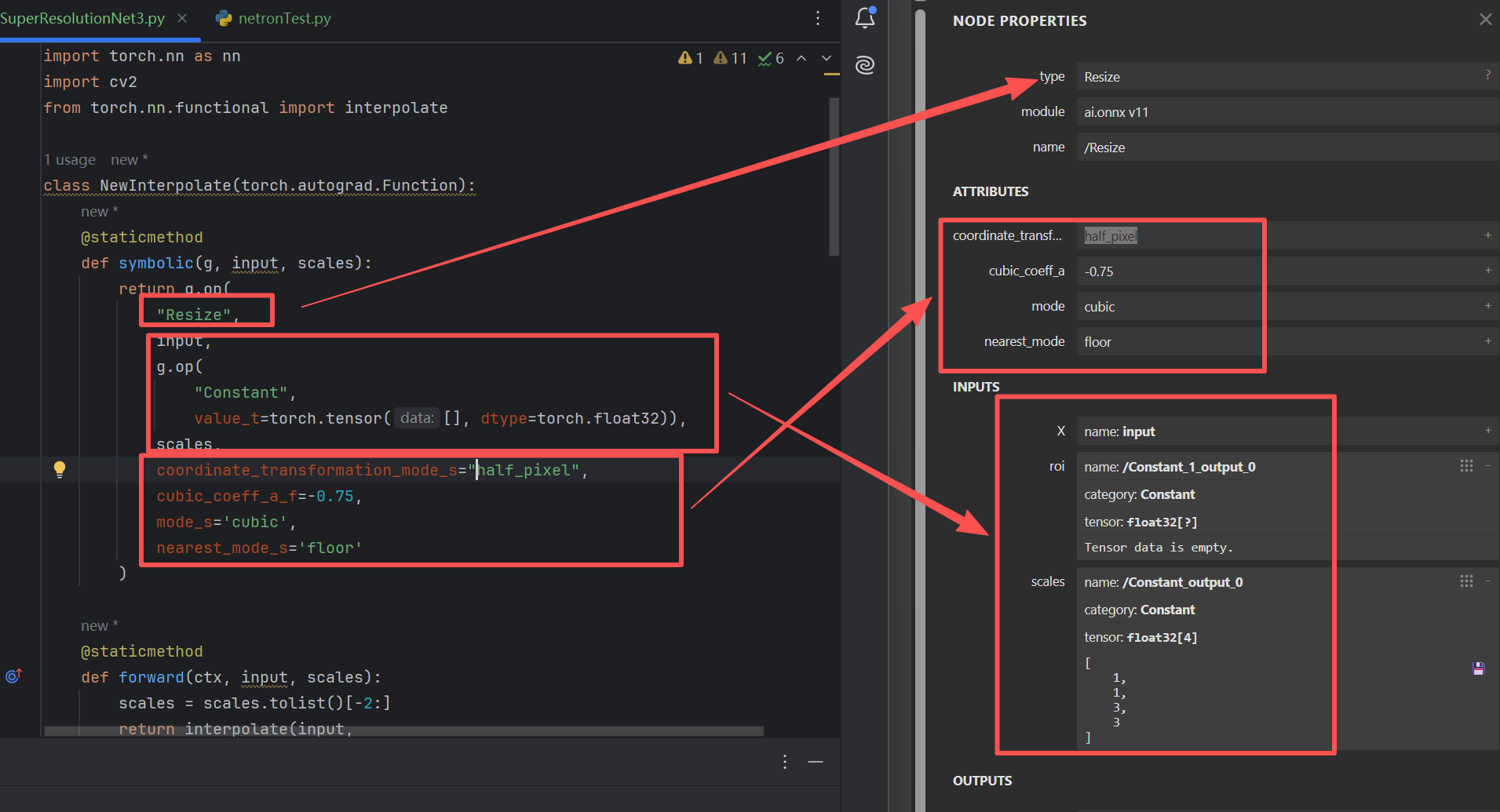
)NewInterpolate是一个自定义ONNX算子包装类,作用只有一个:让PyTorch的双三次上采样,在导出ONNX时能正确、动态地工作,不会变成固定常数。它解决的是:torch.nn.functional.interpolate导出ONNX不支持动态scale的问题。
1)它继承自torch.autograd.Function
这是Pytorch自定义算子的标准写法。
作用:
-既能在Pytorch里正常运行
-又能自定义导出ONNX的行为
一个自定义Function必须写两个静态方法:
-forward:在Pytorch中执行的代码
-symbolic:导出ONNX时执行的代码
2)forward方法(PyTorch推理用)
必须使用@staticmethod标注,这个是torch.autograd.Function这个基类强制要求的,这样不依赖对象实例,不需要self。
ctx:上下文,保存前向传播的信息,主要给反向传播(求导)用。forward方法第一个参数必须是ctx,之后的参数是算子的自定义输入。
传进来的scales是1,1,3,3对应NCHW四个维度,-2:就是3,3,高和宽各放大3倍。
3)symbolic方法(导出ONNX用)
作用:把PyTorch的上采样操作,手动翻译成ONNX能看懂的标注算子(Resize)。
python
@staticmethod
def symbolic(g, input, scales):这是PyTorch规定的导出接口,当执行torch.onnx.export()时,不会执行forward,而是执行symbolic,它负责生成ONNX计算图。
g:graph,表示ONNX计算图构造器,可以理解成画图工具,所有g.op(...)都是画在ONNX节点。symbolic方法第一个参数必须是g,之后的参数是算子的自定义输入,和forward函数一样。
在g.op()中,算子的属性需要以{attribute_name}_{type}=attribute_value这样的格式传入。{type}指定了算子属性的数据类型。比如name_s实际上是定义了一个字符串类型,名字叫做name的属性。
ONNX的Resize算子固定需要3个输入:
-图像:input
-尺寸:roi
-缩放比例:scales
所以代码里写:
python
g.op(
"Resize",
input, # 第1输入:图像
empty_roi, # 第2输入:空区域(必须写)
scales # 第3输入:缩放比例
)对于roi,我们不需要按区域缩放,只需要按比例缩放,所以传空张量。
python
coordinate_transformation_mode_s="pytorch_half_pixel",
cubic_coeff_a_f=-0.75,
mode_s='cubic',
nearest_mode_s='floor'上面的参数是Resize算子的配置参数,作用是:让ONNX的缩放结果和Pytorch完全一模一样。
整个函数的翻译:
python
@staticmethod
def symbolic(g, input, scales):
return g.op(
"Resize", # 用 ONNX 官方缩放算子
input, # 输入图像
空张量, # ONNX 强制要求的占位符
scales, # 动态缩放比例 [1,1,3,3]
模式=双三次, # 和 PyTorch 一样
对齐方式=PyTorch, # 保证结果一模一样
插值系数=-0.75 # 保证结果一模一样
)代码和netron中的计算图中Resize节点的属性的映射关系:
导出srcnn3.onnx进行可视化:
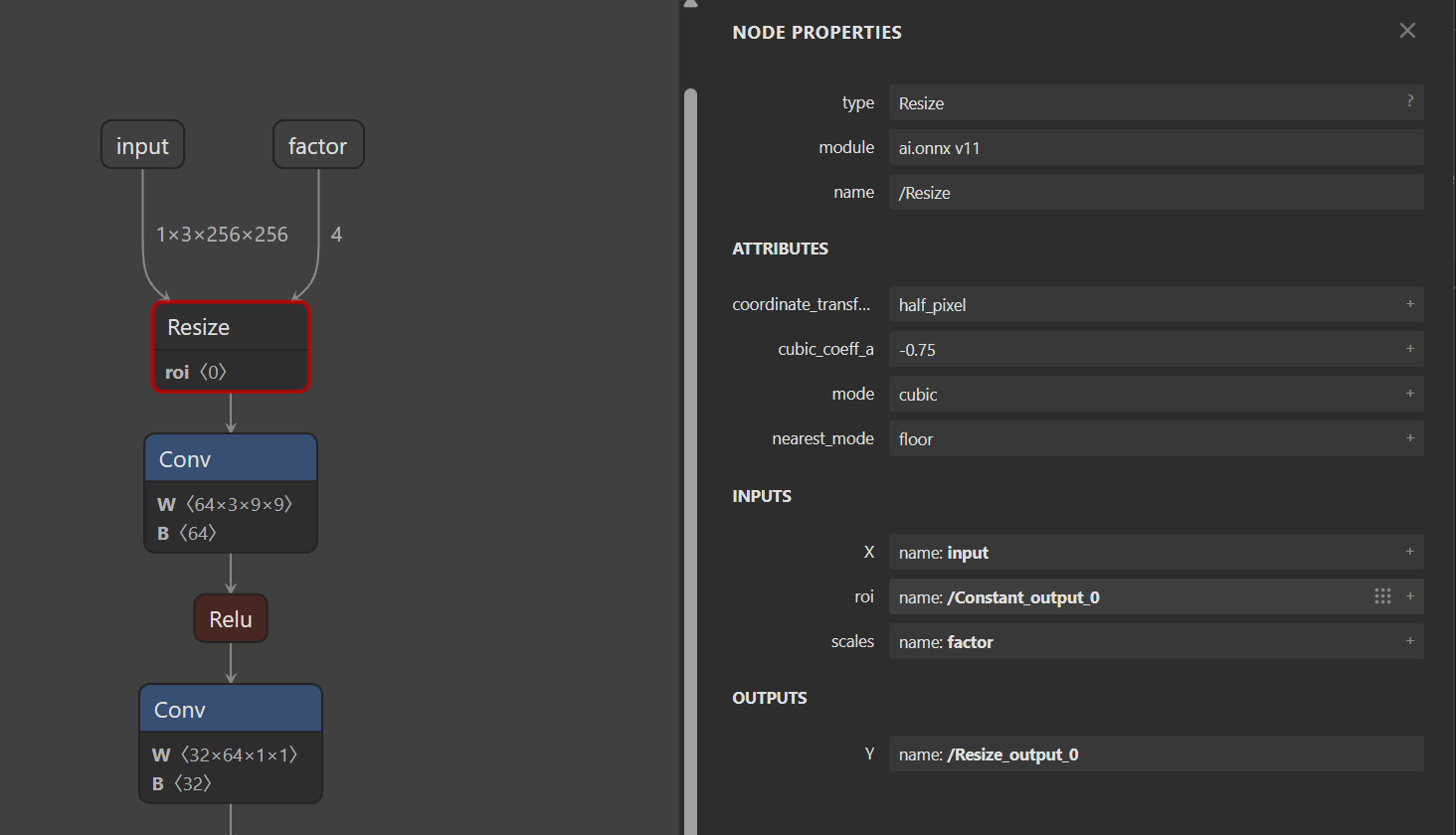
此时,可以看到ONNX模型有两个输入,第二个输入表示图像的缩放比例。
运行onnx runtime推理代码:
python
import onnxruntime
import cv2
import numpy as np
ort_session = onnxruntime.InferenceSession("srcnn3.onnx")
img_path = r"D:\appdata\models\srcnn\000001.png"
input_img = cv2.imread(img_path).astype(np.float32)
input_img = np.transpose(input_img, [2, 0, 1])
input_img = np.expand_dims(input_img, 0)
input_factor = np.array([1,1,4,4], dtype=np.float32)
ort_inputs = {'input': input_img, 'factor': input_factor}
ort_output = ort_session.run(['output'], ort_inputs)[0]
ort_output = np.squeeze(ort_output, 0)
ort_output = np.clip(ort_output, 0, 255)
ort_output = np.transpose(ort_output, [1,2,0]).astype(np.uint8)
cv2.imwrite("face_ort_3.png", ort_output)运行后得到一个边长放大4倍的超分辨率图片。
6、深入理解torch.onnx.export
(1)trace和script机制
通过下面代码比较torch.onnx.export的trace和script两种方法。
Pytorch版本为2.5.1,使用for循环无法得到loop节点,所以用while替换。
python
import torch
class Model(torch.nn.Module):
def __init__(self, n):
super().__init__()
self.n = n # n 还在 __init__ 里!
self.conv = torch.nn.Conv2d(3, 3, 3)
def forward(self, x):
# 🔥 唯一能在 PyTorch 2.5.1 生成 Loop 的写法
loop_count = torch.tensor(self.n)
while loop_count > 0:
x = self.conv(x)
loop_count -= 1
return x
models = [Model(2), Model(3)]
model_names = ['model_2', 'model_3']
for model, model_name in zip(models, model_names):
dummy_input = torch.randn(1, 3, 10, 10)
model_script = torch.jit.script(model)
torch.onnx.export(
model_script,
dummy_input,
f'{model_name}_script.onnx',
opset_version=11
)
model_trace = torch.jit.trace(model, dummy_input)
torch.onnx.export(
model_trace,
dummy_input,
f'{model_name}_trace.onnx',
opset_version=11
)查看trace的计算图(model_2_trace和model_3_trace):
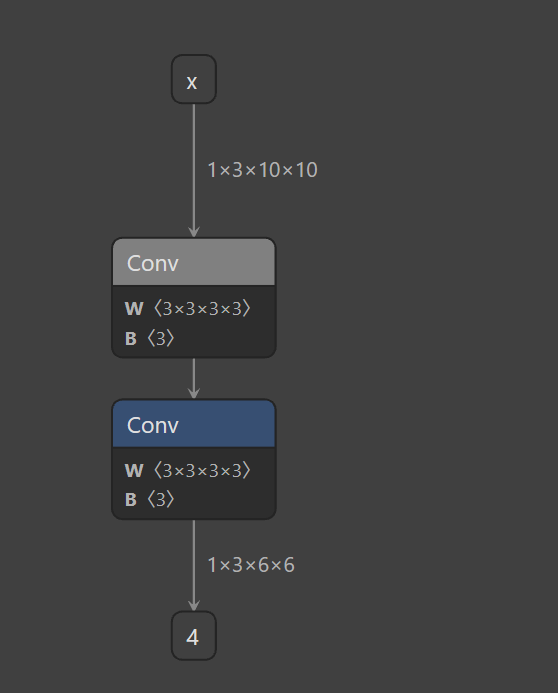
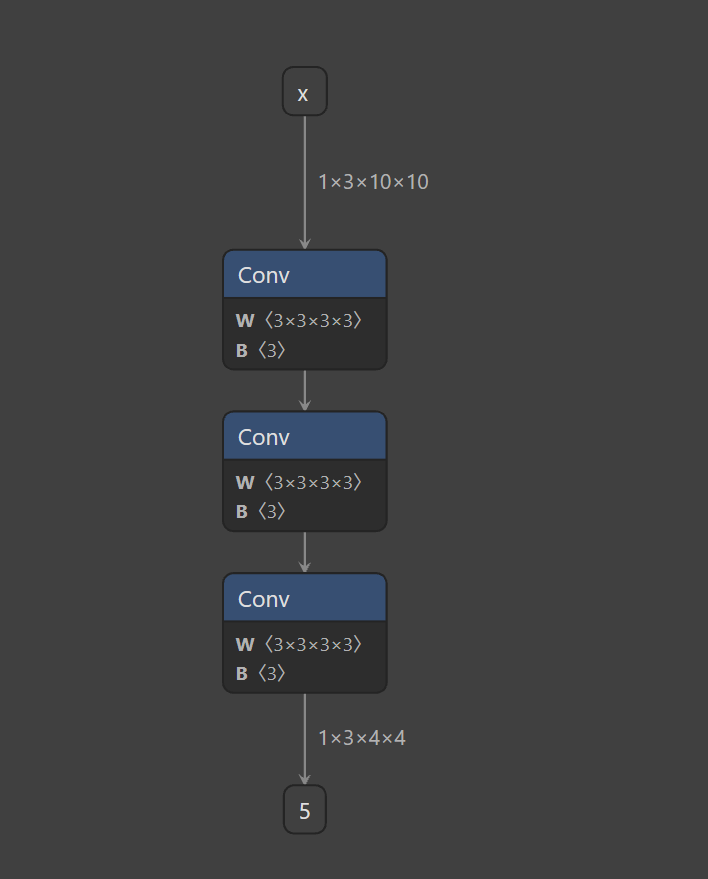
可以看到对于不同的n,onnx模型的结构是不同的。
查看trace的计算图(model_2_trace和model_3_trace一样的):
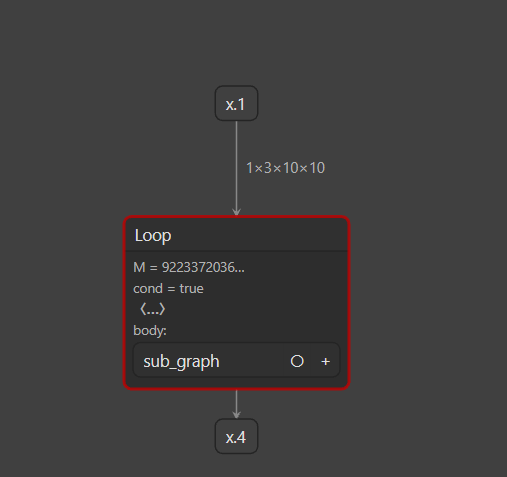
用记录法的话,最终的ONNX模型用Loop节点来表示循环,这样对不同的n,ONNX模型也有同样的结构。
(2)使模型在ONNX转换时有不同的行为
有时候,我们希望在模型导出至ONNX时有一些不同的行为,模型在直接用PyTorch推理时有一套逻辑,而在导出的ONNX模型中有另一套逻辑。
torch.onnx.is_in_onnx_export()可以实现这一任务,该函数仅在执行torch.onnx.export()时为真。
举例:
python
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = torch.nn.Conv2d(3, 3, 3)
def forward(self, x):
x = self.conv(x)
if torch.onnx.is_in_onnx_export():
x = torch.clip(x, 0, 1)
return x (3)跟踪中断
Pytorch转ONNX的跟踪导出法(trace)不是万能的,跟踪导出法(trace)只能记录张量运算,一旦出现张量与Python变量互转,动态逻辑就会变成常量,导致ONNX模型失真。
举例:
python
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = x * x[0].item()
return x, torch.Tensor([i for i in x])
model = Model()
dummy_input = torch.rand(10)
torch.onnx.export(model, dummy_input, 'a.onnx') (4)Pytorch对ONNX的算子支持
在转换普通的torch.nn.Module模型时,PyTorch一方面会用跟踪法执行前向推理,把遇到的算子整合成计算图;另一方面,PyTorch还会把遇到的每个算子翻译成ONNX中定义的算子。在这个翻译过程中,可能会碰到:
-该算子可以一对一地翻译成一个ONNX算子
-该算子在ONNX中没有直接对应地算子,会翻译成一至多个ONNX算子
-该算子没有定义翻译成ONNX的规则,报错
查看torch.onnx文件的根目录:
python
>>> print(torch.onnx.__file__)
D:\appdata\conda\new_envs\py311\Lib\site-packages\torch\onnx\__init__.py在Pytorch中,和ONNX有关的定义全部放在torch.onnx目录中:
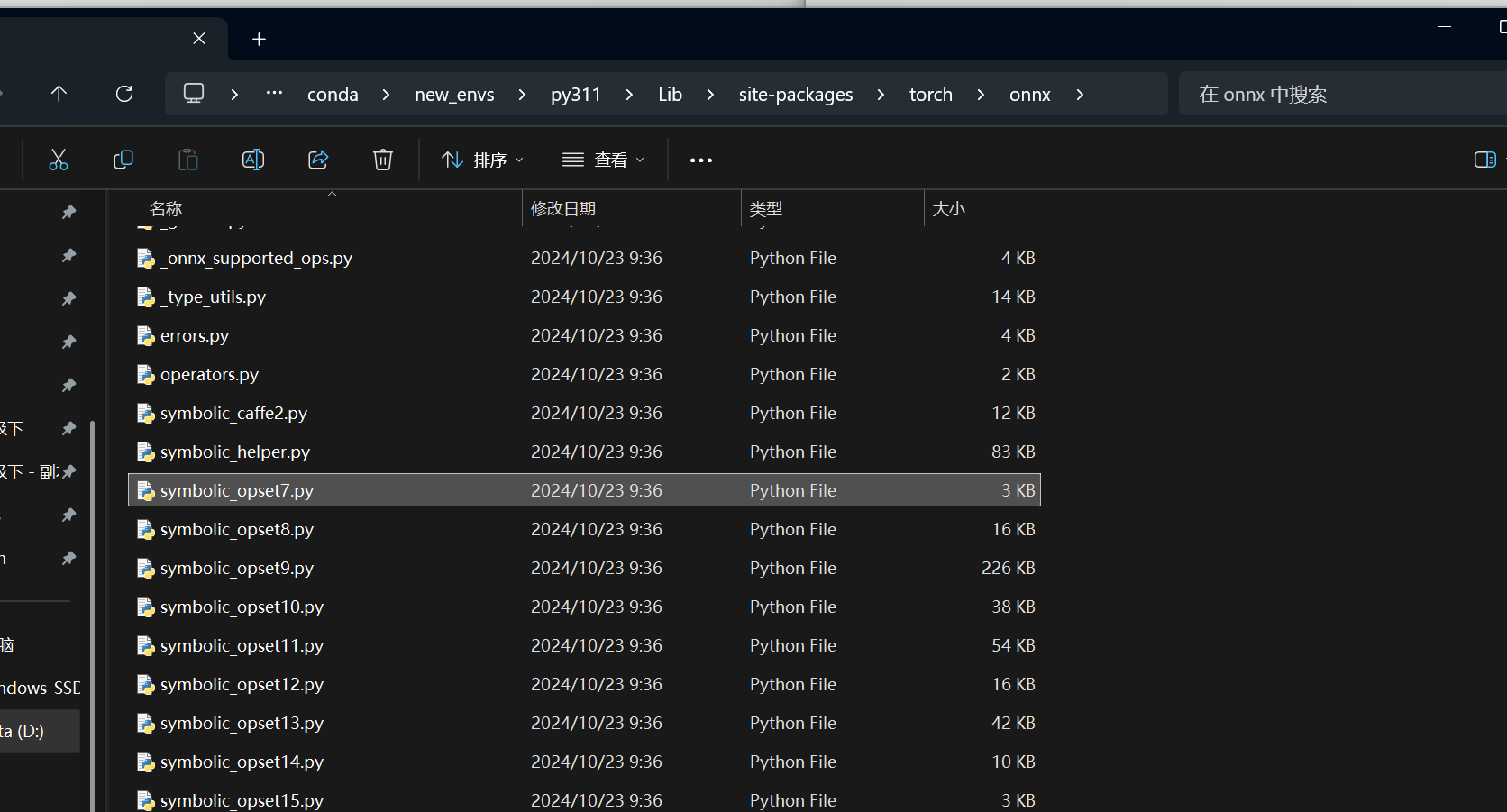
其中,symbolic_opset{n}.py(符号表文件)即表示 PyTorch 在支持第 n 版 ONNX 算子集时新加入的内容。
7、缺失算子的补全方案
(1)背景
要使Pytorch算子顺利转到ONNX,需要保证以下3个缓解不出错:
-算子在PyTorch中有实现
-有把该PyTorch算子映射成一个或多个ONNX算子的方法
-ONNX有相应的算子
可在实际部署中,这三部分的内容都有可能有所缺失。其中最坏的情况是:定义了一个全新的算子,它不仅缺少PyTorch实现,还缺少PyTorch到ONNX的映射关系。
对于这三个缓解,分别有以下的支持的方法:
1)PyTorch算子
-组合现有算子
-添加TorchScript算子
-添加普通C++拓展算子
2)映射方法
-为ATen算子添加符号函数
-为TorchScript算子添加符号函数
-封装成torch.autograd.Function并添加符号函数
3)ONNX算子
-使用现有ONNX算子
-定义新ONNX算子
(2)支持ATen算子
ATen:它是PyTorch内置的C++张量计算库,PyTorch算子在底层绝大多数计算都是用ATen实现的。
算子缺失问题:算子在ATen中已经实现了,ONNX中也有相关算子的定义,但是相关算子映射成ONNX的规则没有写。这种情况下,只需要为ATen算子补充描述映射规则的符号函数就可以了。
以Asinh算子为例,该算子在ATen中有实现,但是缺少映射到ONNX算子的符号函数,示例代码:
python
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.asinh(x)
model = Model()
input = torch.rand(1, 3, 10, 10)
torch.onnx.export(model, input, 'asinh.onnx')报错信息:
python
torch.onnx.errors.UnsupportedOperatorError: Exporting the operator 'aten::asinh' to ONNX opset version 17 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues.(2.1)获取ATen中算子接口定义
查询torch/_C/_VariableFunctions.pyi 和 torch/nn/functional.pyi 这两个文件。
python
>>> import torch,os
>>> vf_path = os.path.join(os.path.dirname(torch.__file__), "_C", "_VariableFunctions.pyi")
>>> print(vf_path)
D:\appdata\conda\new_envs\py311\Lib\site-packages\torch\_C\_VariableFunctions.pyi
>>> func_path = os.path.join(os.path.dirname(torch.__file__), "nn", "functional.pyi")
>>> print(func_path)
D:\appdata\conda\new_envs\py311\Lib\site-packages\torch\nn\functional.pyi_VariableFunctions.pyi:底层ATen原生算子(torch.*)的接口字典
functional.pyi:神经网络F.*函数的接口字典
共同点:.pyi=只有签名、无实现;编译生成;用于补全、类型检查、ONNX算子映射开发。
我们在_VariableFunctions.pyi中找到了asinh的函数定义:
python
def asinh(input: Tensor, *, out: Optional[Tensor] = None) -> Tensor: 所以该算子是一个有实现的ATen算子。
(2.2)添加符号函数
1)什么是符号函数(symbolic function)
-它是PyTorch算子 -> ONNX算子的翻译函数
-导出ONNX时会自动调用
-作用:告诉Pytorch某个算子应该转成ONNX里的哪个算子
2)符号函数长什么样
python
def symbolic(g, 输入1, 输入2, ...):-g:固定参数,代表计算图
-后面参数:必须严格对应ATen算子的参数(从.pyi文件查)
-返回值:g.op(...)生成的ONNX算子
3)g.op()是什么
-用来在ONNX图中创建一个算子节点
-用法:
python
g.op("ONNX算子名", 输入1, 输入2...)4)写符号函数的步骤
-去.pyi文件查ATen算子参数
-去ONNX文档查对应ONNX算子
-写符号函数,参数一一对应
-用g.op映射到ONNX算子
5)如何注册符号函数
python
register_custom_op_symbolic(aten::算子名, 符号函数, opset版本)6)最终的代码
python
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.asinh(x)
from torch.onnx import register_custom_op_symbolic
def asinh_symbolic(g, input, *, out=None):
return g.op("Asinh", input)
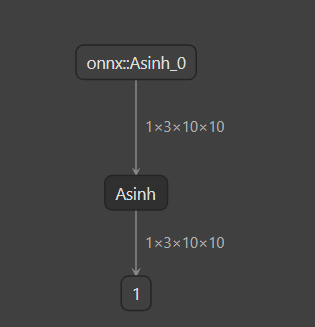
register_custom_op_symbolic('aten::asinh', asinh_symbolic, 11)
model = Model()
input = torch.rand(1, 3, 10, 10)
torch.onnx.export(model, input, 'asinh.onnx', opset_version=11, input_names=['input'], output_names=['output'])生成的计算图的Netron可视化:
(2.3)测试算子
在完成了一份自定义算子后,一定要测试一下算子的正确性。
一般要用PyTorch运行一遍原算子,再用推理引擎(比如ONNX Runtime)运行一下ONNX算子,最后比对两次的运行结果。
python
import numpy as np
import onnxruntime
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.asinh(x)
model = Model()
input = torch.rand(1, 3, 10, 10)
torch_output = model(input).detach().numpy()
sess = onnxruntime.InferenceSession('asinh.onnx')
ort_output = sess.run(None, {'input': input.numpy()})[0]
assert np.allclose(torch_output, ort_output)使用np.allclose来保证两个结果张量的误差在一个可以允许的范围内。
(3)支持TorchScript算子
对于一些比较复杂的运算,仅使用PyTorch原生算子是无法实现的。
这个时候,就要考虑自定义一个Pytorch算子,再把它转换到ONNX中。
新增PyTorch算子首推做法是添加TorchScript算子。
以可变形卷积(Deformable Convolution)算子为例,介绍为现有TorchScript算子添加ONNX支持的方法。
(3.1)使用TorchScript算子
python
import torch
import torchvision
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = torch.nn.Conv2d(3, 18, 3)
self.conv2 = torchvision.ops.DeformConv2d(3, 3, 3)
def forward(self, x):
return self.conv2(x, self.conv1(x))点击torchvision.ops.DeformConv2d后可以看到:
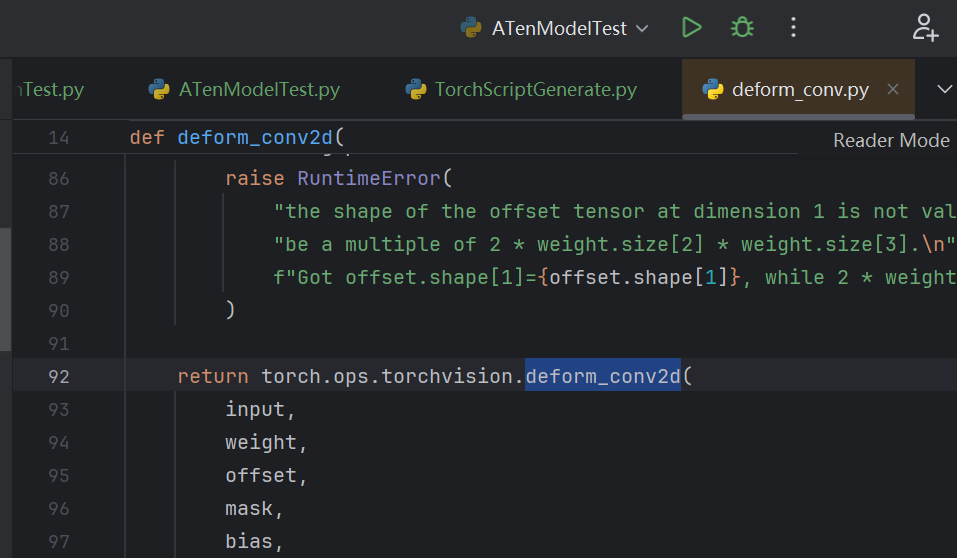
最终会调用deform_conv2d这个算子。
(3.2)自定义ONNX算子
但是在ONNX中找不到deform相关的算子,那么只能自己定义一个ONNX算子了。
g.op()是用来定义ONNX算子的函数。
对于ONNX官方定义的算子,g.op()的第一个参数就是算子的名称。而对于一个自定义算子,g.op()的第一个参数是一个带命名空间的算子名,比如:
g.op("custom::deform_conv2d", ...)
如果在g.op()里不加前面的命名空间,则算子会被默认成ONNX的官方算子。
因为ONNX是一套标准,本身不包括实现。所以,我们就简略地定义一个ONNX可变形卷积算子,而不去写它在某个推理引擎上的实现。
完整的模型导出代码:
python
import torch
import torchvision
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = torch.nn.Conv2d(3, 18, 3)
self.conv2 = torchvision.ops.DeformConv2d(3, 3, 3)
def forward(self, x):
return self.conv2(x, self.conv1(x))
from torch.onnx import register_custom_op_symbolic
from torch.onnx.symbolic_helper import parse_args
@parse_args("v", "v", "v", "v", "v", "i", "i", "i", "i", "i", "i", "i", "i", "none")
def symbolic(g,
input,
weight,
offset,
mask,
bias,
stride_h, stride_w,
pad_h, pad_w,
dil_h, dil_w,
n_weight_grps,
n_offset_grps,
use_mask):
return g.op("custom::deform_conv2d", input, offset)
register_custom_op_symbolic("torchvision::deform_conv2d", symbolic, 9)
model = Model()
input = torch.rand(1, 3, 10, 10)
torch.onnx.export(model, input, 'dcn.onnx')TorchScript算子的符号函数要求标注出每一个输入参数的类型,比如
-v:表示value类型
-i:表示int类型
-f:表示float类型
-none:表示该参数为空
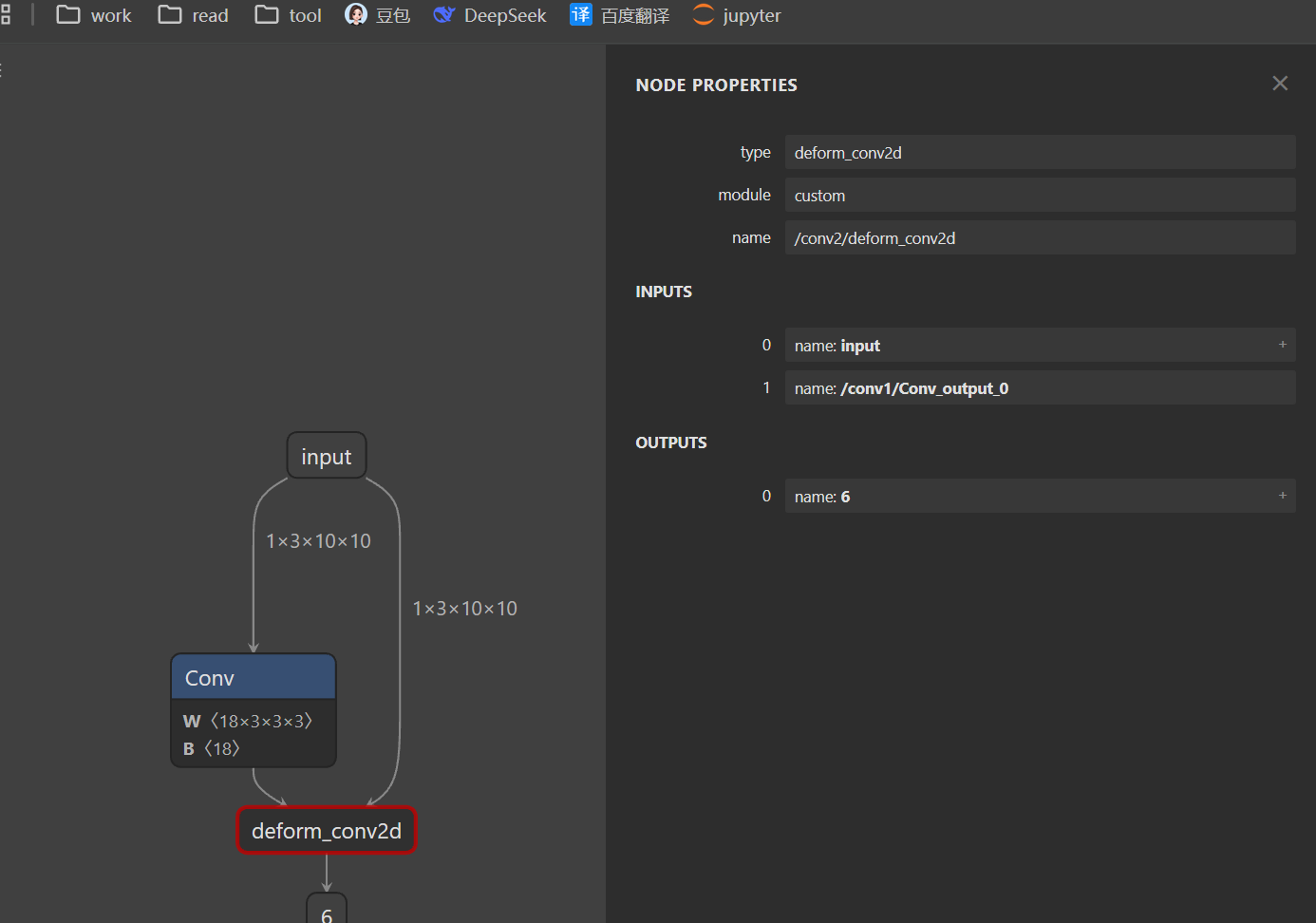
查看Netron可以看到自定义的ONNX算子,包含了两个输入,一个输出,和我们预想的一样。
8、ONNX模型修改
解决的疑问:
1.ONNX模型在底层是用什么格式存储的?
2.如何不依赖深度学习框架,只用ONNX的API来构造一个ONNX模型
3.如果没有源代码,只有一个ONNX模型,该如何对这个模型进行调试
(1)ONNX的底层实现
底层存储基础:ONNX 基于 Protobuf(谷歌序列化协议) 实现,分为数据定义文件和二进制文件两部分。
Protobuf 工作逻辑:先编写数据结构定义文件(相当于数据模板 / 类),再依据模板将数据序列化为二进制文件(相当于类的实例),也可反向解析读取数据。
ONNX 与 Protobuf 的对应关系:
Protobuf 定义文件:存于 ONNX 开源库,规定了模型、算子节点、张量等网络结构的标准格式;
二进制文件:即后缀为 .onnx 的模型文件,依照上述规范存储完整神经网络数据。
使用方式:手动基于 Protobuf 编写 ONNX 模型复杂度高,ONNX 提供了配套 API,无需深入了解 Protobuf 即可完成模型构建、读取等操作。
(2)ONNX模型的结构
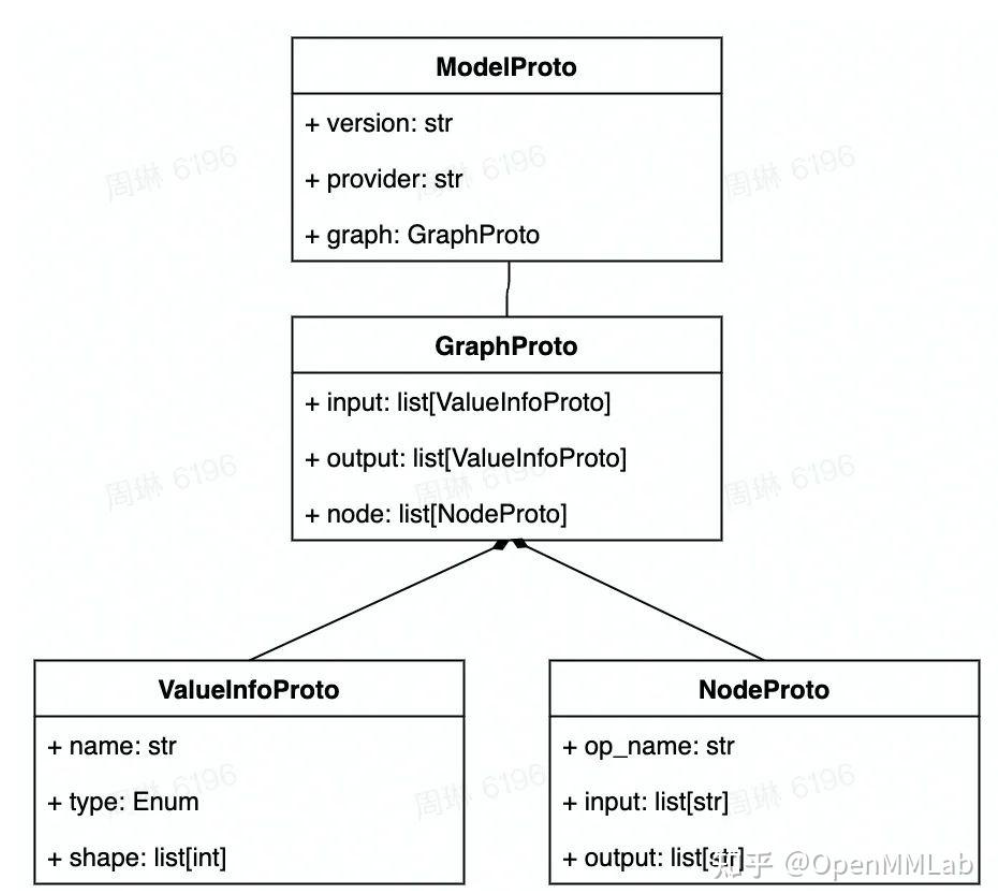
ONNX模型主要由以下结构组织起来的:
ValueInfoProto -> NodeProto -> GraphProto -> ModelProto。
根据上面的结构,我们需要自底向上构造这个模型。
helper.make_tensor_value_info:构造出一个描述张量信息的ValuleInfoProto对象。
helper.make_node:构造算子节点信息NodeProto对象。传入算子类型、输入算子名、输出算子名。在ONNX中,如果某节点的输入名和之前某节点的输出名相同,就默认这两个节点是相连的。所以ONNX对节点的输入有一定的要求:一个节点的输入,要么是整个模型的输入,要么是之前某个节点的输出。一个不满足标准的ONNX模型可能无法被推理引擎正确识别。ONNX提供了onnx.checker.check_model来判断一个ONNX模型是否满足标准。
helper.make_graph:构造计算图GraphProto对象。传入节点、图名称、输入张量信息、输出张量信息。这个的节点的一个要求:计算图的节点必须以拓扑序给出。如果按拓扑序遍历所有节点的话,能保证每个节点的输入都能在之前节点的输出里找到。
helper.make_model:把计算图GraphProto封装进模型ModelProto里。
(3)构造ONNX模型
构造一个描述线性函数output = a * x + b的ONNX模型的例子:
python
import onnx
from onnx import helper
from onnx import TensorProto
a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10])
x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10])
b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10])
output = helper.make_tensor_value_info('output', TensorProto.FLOAT, [10, 10])
mul = helper.make_node('Mul', ['a', 'x'], ['c'])
add = helper.make_node('Add', ['c', 'b'], ['output'])
graph = helper.make_graph([mul, add], 'linear_func', [a, x, b], [output])
model = helper.make_model(graph)
onnx.checker.check_model(model)
print(model)
onnx.save(model, 'linear_func.onnx')用ONNX Runtime运行模型:
python
import onnxruntime
import numpy as np
sess = onnxruntime.InferenceSession('linear_func.onnx')
a = np.random.rand(10, 10).astype(np.float32)
b = np.random.rand(10, 10).astype(np.float32)
x = np.random.rand(10, 10).astype(np.float32)
output = sess.run(['output'], {'a': a, 'b': b, 'x': x})[0]
assert np.allclose(output, a * x + b)(4)读取并修改ONNX模型
python
import onnx
model = onnx.load('linear_func.onnx')
node = model.graph.node
node[1].op_type = 'Sub'
onnx.checker.check_model(model)
onnx.save(model, 'linear_func_2.onnx')(5)子模型提取
目标:通过提取子模型,以方便后续对ONNX模型本身进行调试。
首先构建一个模型,代码如下:
python
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.convs1 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3),
torch.nn.Conv2d(3, 3, 3),
torch.nn.Conv2d(3, 3, 3))
self.convs2 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3),
torch.nn.Conv2d(3, 3, 3))
self.convs3 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3),
torch.nn.Conv2d(3, 3, 3))
self.convs4 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3),
torch.nn.Conv2d(3, 3, 3),
torch.nn.Conv2d(3, 3, 3))
def forward(self, x):
x = self.convs1(x)
x1 = self.convs2(x)
x2 = self.convs3(x)
x = x1 + x2
x = self.convs4(x)
return x
model = Model()
input = torch.randn(1, 3, 20, 20)
torch.onnx.export(model, input, 'whole_model.onnx')提取子模型的代码:
python
import onnx
onnx.utils.extract_model('whole_model.onnx',
'partial_model.onnx',
['input.1'],
['/convs1/convs1.1/Conv_output_0'])提取结果可视化如下:
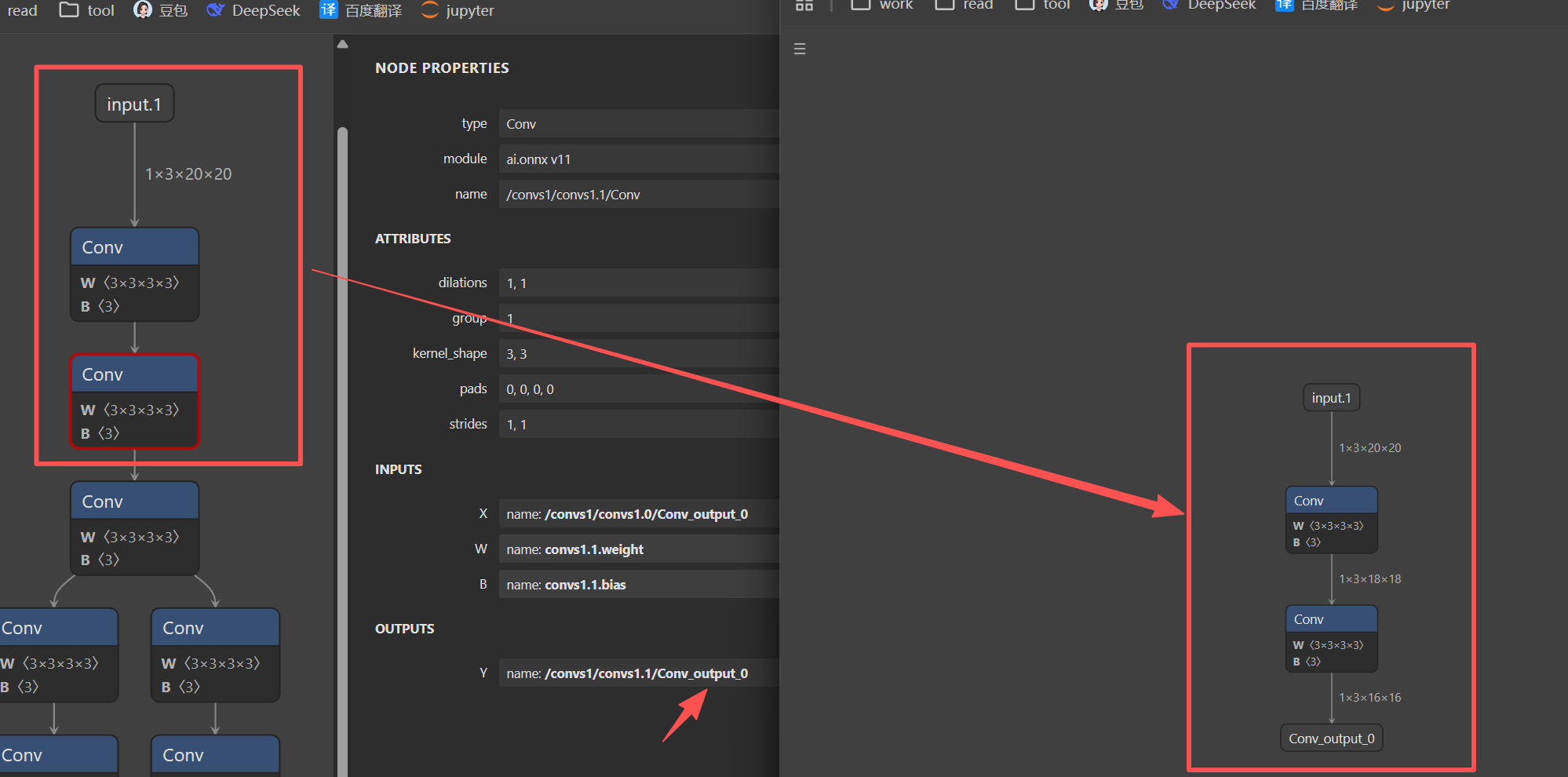
onnx.utils.extract_model的函数原型:
python
onnx.utils.extract_model(
input_path,
output_path,
input_names,
output_names,
check_model=True,
infer_shapes=True
)功能:从一个ONNX模型里,按张量名字切出一个子图并保存为新ONNX。
-input_names:字符串列表,子模型的输入张量名字(不是节点名,是张量名)
-output_names:子模型的输出张量名字
注意点:子模型需要确保任何一个节点的输入,都有一个前面节点的输出。
比如下面只把左边作为子模型是不行的,需要左右都有才行。
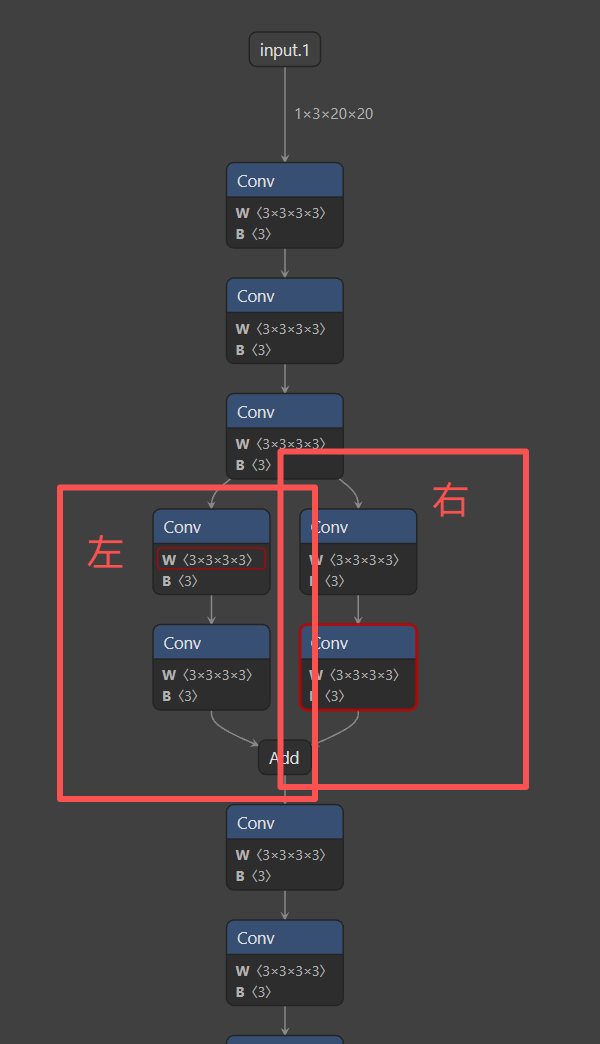
为了方便调试,我们可以把原模型拆分成多个互不相交的子模型。这样,在每次调试时,可以只对原模型的部分子模型调试。
9、精度对齐工具
(1)概念
精度对齐是模型部署中一个重要环节。在把深度学习框架模型转换成中间表示模型后,部署工程师要做的第一件事就是精度对齐,确保模型的计算结果与之前相当。精度对齐时最常用的方法,就是使用测试集评估一遍中间表示模型,看看模型的评估指标(如准确率、相似度)是否下降。
模块在Pytorch模型中的输出可以轻松得到,可是对应ONNX模型里的哪一个输出。在小模型里,能够通过阅读PyTorch模型的源码,推断出每个ONNX模块与PyTorch模块的对应关系。但是在大模型中,我们是难以建立PyTorch与ONNX的对应关系的。
(2)设计思路
我们可以定义一个叫做 Debug 的 ONNX 算子,它有一个属性调试名 name。而由于每一个 ONNX 算子节点又自带了输出张量的名称,这样一来,ONNX 节点的输出名和调试名绑定在了一起。我们可以顺着 PyTorch 里的调试名,找到对应 ONNX 里的输出,完成 PyTorch 和 ONNX 的对应。
(3)代码实现
python
import torch
import onnx
import onnxruntime
import numpy as np
# ------------------- 自定义 Debug 算子 -------------------
class DebugOp(torch.autograd.Function):
@staticmethod
def forward(ctx, x, name):
return x
@staticmethod
def symbolic(g, x, name):
return g.op("my::Debug", x, name_s=name)
debug_apply = DebugOp.apply
# ------------------- 最终修复版 Debugger -------------------
class Debugger:
def __init__(self):
super().__init__()
self.torch_value = dict()
self.onnx_value = dict()
self.output_debug_name = []
def debug(self, x, name):
# 永远保存 PyTorch 值
self.torch_value[name] = x.detach().cpu().numpy()
return debug_apply(x, name)
def extract_debug_model(self, input_path, output_path):
model = onnx.load(input_path)
inputs = [i.name for i in model.graph.input]
outputs = []
for node in model.graph.node:
if "Debug" in node.op_type:
debug_name = node.attribute[0].s.decode("ASCII")
self.output_debug_name.append(debug_name)
outputs.append(node.output[0])
node.op_type = "Identity"
node.domain = ""
del node.attribute[:]
extractor = onnx.utils.Extractor(model)
extracted = extractor.extract_model(inputs, outputs)
onnx.save(extracted, output_path)
print(f"✅ 调试模型已保存:{output_path}")
print(f"📊 捕获调试点:{self.output_debug_name}")
def run_debug_model(self, input_dict, debug_model_path):
sess = onnxruntime.InferenceSession(
debug_model_path,
providers=["CPUExecutionProvider"]
)
outputs = sess.run(None, input_dict)
# 🔥 修复:强制按顺序赋值,保证一一对应
for i, name in enumerate(self.output_debug_name):
self.onnx_value[name] = outputs[i]
def print_debug_result(self):
print("\n========== PyTorch VS ONNX 对齐结果 ==========")
# 🔥 修复:遍历已捕获的调试点
for name in self.output_debug_name:
t = self.torch_value[name]
o = self.onnx_value[name]
mse = np.mean((t - o) ** 2)
print(f"✅ {name} MSE: {mse:.8f}")总结:
- DebugOp:PyTorch算子,前向直通,导出为my::Debug
- debug():在模型中记录Pytorch中间值+插入Debug节点
- extract_debug_model:找到所有Debug节点 -> 改为Identity -> 提取含Debug输出的子图
- run_debug_model:运行ONNX,收集所有Debug中间结果
- print_debug_result:对比PyTorch/ONNX中间变量,输出MSE
使用端程序:
python
import torch
from llm.tests.onnx.openmmlab.Debugger import Debugger
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.convs1 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3, 1, 1),
torch.nn.Conv2d(3, 3, 3, 1, 1),
torch.nn.Conv2d(3, 3, 3, 1, 1))
self.convs2 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3, 1, 1),
torch.nn.Conv2d(3, 3, 3, 1, 1))
self.convs3 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3, 1, 1),
torch.nn.Conv2d(3, 3, 3, 1, 1))
self.convs4 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3, 1, 1),
torch.nn.Conv2d(3, 3, 3, 1, 1),
torch.nn.Conv2d(3, 3, 3, 1, 1))
def forward(self, x):
x = self.convs1(x)
x = self.convs2(x)
x = self.convs3(x)
x = self.convs4(x)
return x
torch_model = Model()
debugger = Debugger()
from types import MethodType
def new_forward(self, x):
x = self.convs1(x)
x = debugger.debug(x, 'x_0')
x = self.convs2(x)
x = debugger.debug(x, 'x_1')
x = self.convs3(x)
x = debugger.debug(x, 'x_2')
x = self.convs4(x)
x = debugger.debug(x, 'x_3')
return x
torch_model.forward = MethodType(new_forward, torch_model)
dummy_input = torch.randn(1, 3, 10, 10)
torch.onnx.export(torch_model, dummy_input, 'before_debug.onnx', input_names=['input'])
debugger.extract_debug_model('before_debug.onnx', 'after_debug.onnx')
debugger.run_debug_model({'input':dummy_input.numpy()}, 'after_debug.onnx')
debugger.print_debug_result()运行结果:
python
✅ 调试模型已保存:after_debug.onnx
📊 捕获调试点:['x_0', 'x_1', 'x_2', 'x_3']
========== PyTorch VS ONNX 对齐结果 ==========
✅ x_0 MSE: 0.00000000
✅ x_1 MSE: 0.00000000
✅ x_2 MSE: 0.00000000
✅ x_3 MSE: 0.00000000after_debug.onnx模型的Netron可视化:
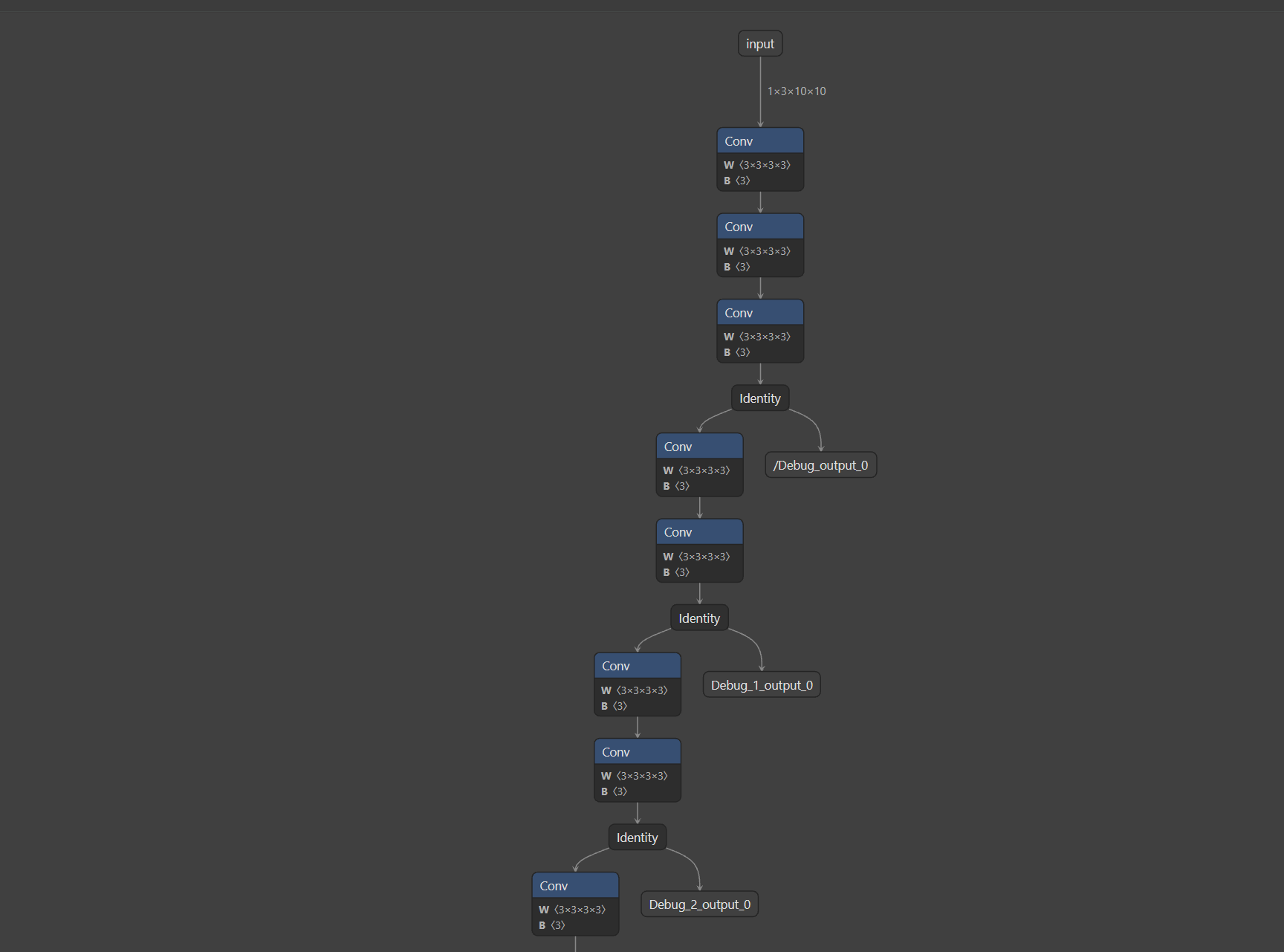
10、TensorRT模型构建与推理
(1)概述
TensorRT 是由 NVIDIA 发布的深度学习框架,用于在其硬件上运行深度学习推理。TensorRT 提供量化感知训练和离线量化功能,用户可以选择 INT8 和 FP16 两种优化模式,将深度学习模型应用到不同任务的生产部署,如视频流、语音识别、推荐、欺诈检测、文本生成和自然语言处理。TensorRT 经过高度优化,可在 NVIDIA GPU 上运行, 并且可能是目前在 NVIDIA GPU 运行模型最快的推理引擎。
使用TensorRT生成模型有两种方式:
-直接通过TensorRT的API逐层搭建网络
-将中间表示的模型转换成TensorRT模型,比如将ONNX模型转换成TensorRT模型。
(2)将ONNX转换成TensorRT模型
示例代码:
python
import torch
import onnx
import tensorrt as trt
onnx_model = 'trt_model.onnx'
class NaiveModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.pool = torch.nn.MaxPool2d(2, 2)
def forward(self, x):
return self.pool(x)
device = torch.device('cuda:0')
# generate onnx model
torch.onnx.export(NaiveModel(),
torch.randn(1,3,224,224),
onnx_model,
input_names=['input'],
output_names=['output'],
opset_version=11)
onnx_model = onnx.load(onnx_model)
# create builder and network
logger = trt.Logger(trt.Logger.ERROR)
builder = trt.Builder(logger)
EXPLICIT_BATCH = 1 << (int)(
trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH
)
network = builder.create_network(EXPLICIT_BATCH)
# parse onnx
parser = trt.OnnxParser(network, logger)
if not parser.parse(onnx_model.SerializeToString()):
error_msgs = ''
for error in range(parser.num_errors):
error_msgs += f'{parser.get_error(error)}\n'
raise RuntimeError(f'Failed to parse onnx, {error_msgs}')
config = builder.create_builder_config()
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 24)
profile = builder.create_optimization_profile()
profile.set_shape('input', [1,3,224,224], [1,3,224,224], [1,3,224,224])
config.add_optimization_profile(profile)
with torch.cuda.device(device):
serialized_engine = builder.build_serialized_network(network, config)
# 保存引擎
with open('trt_model.engine', mode='wb') as f:
f.write(serialized_engine)
print("generating file done!")代码讲解:
1)代码功能
把一个简单的PyTorch模型 -> 转成ONNX -> 再转成TensorRT引擎,让模型在NVIDIA显卡上跑得飞快。
2)trt.Logger(trt.Logger.ERROR)
创建日志记录器,只打印错误日志
3)trt.Builder(logger)
创建TensorRT建造器,负责把模型建成加速引擎
4)EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
明确告诉TensorRT,输入的大小是固定的
5)builder.create_network(EXPLICIT_BATCH)
创建空的网络结构,相当于给工程师一张空白图纸
6)trt.OnnxParser(network, logger)
创建ONNX解析器,把ONNX模型翻译成TensorRT能看懂的结构
7)parser.parse(onnx_model.SerializeToString())
开始解析ONNX,把ONNX模型读进TensorRT
8)builder.create_builder_config()
创建构建配置,config=给工程师的施工说明书
9)config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 24)
设置显卡内存,给模型分配16MB显存用于计算。
10)profile.set_shape(输入名, 最小尺寸, 常用尺寸, 最大尺寸)
设置输入形状
11)builder.build_serialized_network(network, config)
构建TensorRT加速引擎,让TensorRT把模型编译成显卡能快速运行的引擎。
12)f.write(serialized_engine)
保存引擎文件,以后直接加载这个引擎,推理速度能提升几倍到几时倍
(3)模型推理
示例代码:
python
from typing import Union, Optional, Dict
import torch
import tensorrt as trt
import time
class TRTWrapper(torch.nn.Module):
def __init__(self, engine: Union[str, trt.ICudaEngine], output_names: Optional[list] = None):
super().__init__()
self.engine = engine
# 加载引擎文件
if isinstance(self.engine, str):
logger = trt.Logger(trt.Logger.ERROR)
runtime = trt.Runtime(logger)
with open(self.engine, 'rb') as f:
engine_bytes = f.read()
self.engine = runtime.deserialize_cuda_engine(engine_bytes)
self.context = self.engine.create_execution_context()
# 获取输入输出名
self._input_names = []
self._output_names = []
for i in range(self.engine.num_io_tensors):
name = self.engine.get_tensor_name(i)
mode = self.engine.get_tensor_mode(name)
if mode == trt.TensorIOMode.INPUT:
self._input_names.append(name)
else:
self._output_names.append(name)
if output_names is not None:
self._output_names = output_names
def forward(self, inputs: Dict[str, torch.Tensor]):
# 设置输入
for name, tensor in inputs.items():
tensor = tensor.contiguous().cuda()
if tensor.dtype == torch.long:
tensor = tensor.int()
self.context.set_input_shape(name, tensor.shape)
self.context.set_tensor_address(name, tensor.data_ptr())
# 创建输出
outputs = {}
for name in self._output_names:
# 🔥 修复:必须转成 tuple()
shape = tuple(self.context.get_tensor_shape(name))
out = torch.empty(shape, dtype=torch.float32, device='cuda')
self.context.set_tensor_address(name, out.data_ptr())
outputs[name] = out
# 运行推理
self.context.execute_async_v3(torch.cuda.current_stream().cuda_stream)
return outputs
# 测试
if __name__ == "__main__":
model = TRTWrapper('trt_model.engine', ['output'])
dummy_input = {'input': torch.randn(1, 3, 224, 224).cuda()}
# -------- 🔥 预热模型(GPU第一次跑会慢,必须预热)--------
model(dummy_input)
print("✅ 模型预热完成\n")
# -------- ⏱️ 开始计时 --------
torch.cuda.synchronize() # 等待前面GPU任务结束
start_time = time.time()
# 推理
out = model(dummy_input)
# 结束计时
torch.cuda.synchronize()
end_time = time.time()
# 计算耗时(毫秒)
cost_time = (end_time - start_time) * 1000
# 输出结果
print("✅ 推理成功!输出形状:", out['output'].shape)
print(f"⏱️ 模型推理耗时:{cost_time:.2f} ms")代码解读:
1)TRTWrapper
把复杂的TensorRT推理包装成一个简单的模型类,以后只用model(input)就能跑预测。
2)self.context = self.engine.create_execution_context()
创建执行上下文,给引擎一个工作台
3)处理输入数据
python
for name, tensor in inputs.items():
tensor = tensor.contiguous().cuda() # 搬到GPU
self.context.set_input_shape(name, tensor.shape) # 告诉TRT输入大小
self.context.set_tensor_address(name, tensor.data_ptr()) # 告诉TRT数据位置把输入数据送到显卡,告诉TRT:数据在这里,大小是这个
4)创建输出空间
python
for name in self._output_names:
shape = tuple(self.context.get_tensor_shape(name)) # 输出大小
out = torch.empty(shape, device='cuda') # 在GPU上建空张量提前在显卡上准备一块空间,用来存预测结果
5)self.context.execute_async_v3(stream)
真正跑推理
总结这个类做的4件事情:
1.加载.engine高速模型
2.自动识别输入输出名
3.把数据送给显卡
4.跑推理,返回结果