大家好,我是HLAIA光子。
最近在对我的项目 OpenMMV 做 RAG 重构。
OpenMMV 是分布式微服务架构,我在看项目设计的时候,回想起来给项目设计的分布式锁是比较基础的 Redis SETNX 互斥锁,而分布式事务就根本没有用什么不得了的架构了。即使这样,上线之后也没出过数据一致性的问题(可能是因为用户基数还比较少吧hhh)。
我想了下为什么设计这样的分布式锁和分布式事务的方案,然后正好用这篇文章来谈谈我的想法。
分布式锁
回忆下分布式锁是做什么的,分布式锁就是在多个进程、多台机器之间,保证同一时刻只有一个实例能操作某个资源。
常见实现
下面是最主流的几种分布式锁实现,简单过一遍,详细的内容可以去各大八股网站查。
Redis SETNX 。SETNX 就是 SET if N ot eX ists ,SET key value NX PX ttl,key 不存在时设置成功就算拿到锁,存在则失败。释放的时候用 Lua 脚本校验 value 再删除,保证原子性。优点是简单轻量,上手成本几乎为零。缺点是没有可重入、没有读写分离、锁续期要自己实现。
Redisson。这玩意挺🐂b。基于 Redis 的分布式锁框架,支持可重入锁、读写锁、信号量、CountDownLatch,自带看门狗自动续期。场景复杂的时候可以用 Redisson ,代价是引入了一个比较大的依赖,配置不当容易踩坑。
RedLock。Redis 作者 Antirez 提出的算法,在多个独立的 Redis 实例上同时加锁,超过半数成功才算获取锁。解决的是单节点 Redis 故障导致锁丢失的问题。争议在于它并没有真正解决分布式系统中的时钟和网络分区问题。Martin Kleppmann 专门写过文章质疑它的正确性,实际生产中用的人不多。
ZooKeeper。利用临时顺序节点实现分布式锁,强一致性靠 ZooKeeper 的 ZAB 协议保证。可靠性最高,但性能不如 Redis,而且 ZooKeeper 也需要单独运维。
我的选择
在 OpenMMV 里我选择的是最简单的 SETNX 方案,手动实现一个轻量的互斥锁。加锁用 setIfAbsent,就是 Redis 的 SETNX 命令。释放锁用一段 Lua 脚本,先 GET 比较 value 是不是自己当初设置的 UUID,是的话才 DEL,不是就放弃。整个释放过程在 Redis 端原子执行。
拿锁失败怎么办?
我做了重试机制,默认重试 3 次,每次间隔 100ms;全部都重试失败后不阻塞请求,直接查数据库作为降级兜底。这个设计比"拿不到锁就一直等"要务实得多。
用在哪
OpenMMV 的这个场景用到了分布式锁:缓存防击穿。
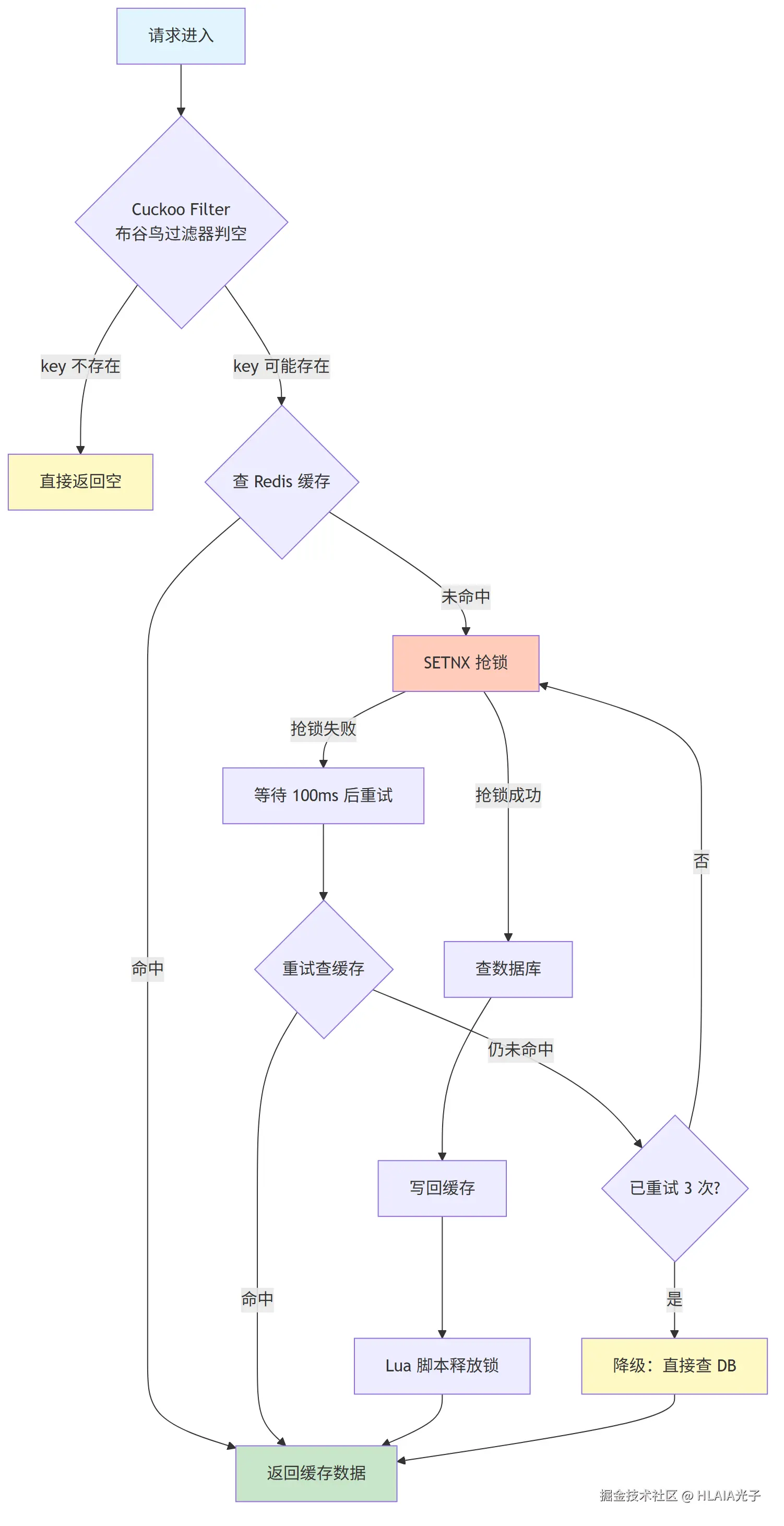
流程是这样的:请求进来先过 Cuckoo Filter 判空,没被拦截就查缓存,缓存命中直接返回。缓存没命中时,用 SETNX 抢锁。抢到了去查数据库,查完写缓存再释放锁。抢锁期间别的请求会等待重试,重试时再做一次缓存检查,很可能锁持有者已经把缓存写好了,直接用就行。全部重试失败就降级查数据库。
我锁的 key 设计是,openmmv:lock:cache:user:{id}、openmmv:lock:cache:work:{id}、openmmv:lock:leaderboard:works,分别保护用户缓存、作品缓存和排行榜缓存。三个 key三个场景,一家子就是得整整齐齐啊。
为什么不用 Redisson
很多人第一反应是直接上 Redisson,功能强,生态好。但对我来说,这个场景只需要"互斥 + 原子释放"这两个能力,SETNX + Lua 完全满足需求,不用再上复杂的模块了。
少一个依赖就少一份运维成本,少一份出问题的概率。项目里用到的 Redis 操作都是基础的 String 和 Hash,Spring Data Redis 的 RedisTemplate 已经绑定了 Lettuce 连接池。没有必要再加一个 Redisson 来维护两套系统。
分布式事务
锁讲完了,接下来说事务。我直接选择不用分布式事务。
常见实现
简单过一下主流的分布式事务方案。
XA 两阶段提交。数据库层面的分布式事务协议。第一阶段所有参与者 prepare,第二阶段协调者通知 commit 或 rollback。优点是强一致,缺点是性能差,需要长时间持有数据库锁,而且所有参与者必须支持 XA 协议。实际生产中用得不多,MySQL 的 XA 实现也有些已知的坑。
TCC。Try-Confirm-Cancel 模式,在业务层面实现分布式事务。Try 阶段预留资源,Confirm 确认执行,Cancel 回滚释放。灵活性高,但业务侵入性挺大的,每个操作都要写三个接口。
SAGA。把长事务拆成一串本地事务,每一步都有一个对应的补偿操作。某一步失败就逆序执行之前步骤的补偿。适合流程长、参与方多的场景,比如电商的下单流程。
Seata AT 模式。阿里开源的分布式事务框架,自动拦截 SQL 生成回滚日志,对业务代码侵入最小。国内用得比较多,代驾是引入了一整套 Seata Server 的运维负担,而且对 SQL 的支持有一些限制。
基于消息的最终一致性。不追求强一致,通过消息队列把状态变更异步通知到下游,配合幂等消费和重试机制,保证最终数据一致。这是最轻量的方案,也是我选择的方案。
我的选择
OpenMMV 没有任何分布式事务框架。没有 Seata,没有 XA,没有 TCC,没有 SAGA
至少截止 2026.6.10 是没有的。以后有没有,谁知道呢?
跨服务的数据一致性就靠 Kafka 最终一致性 来保障。
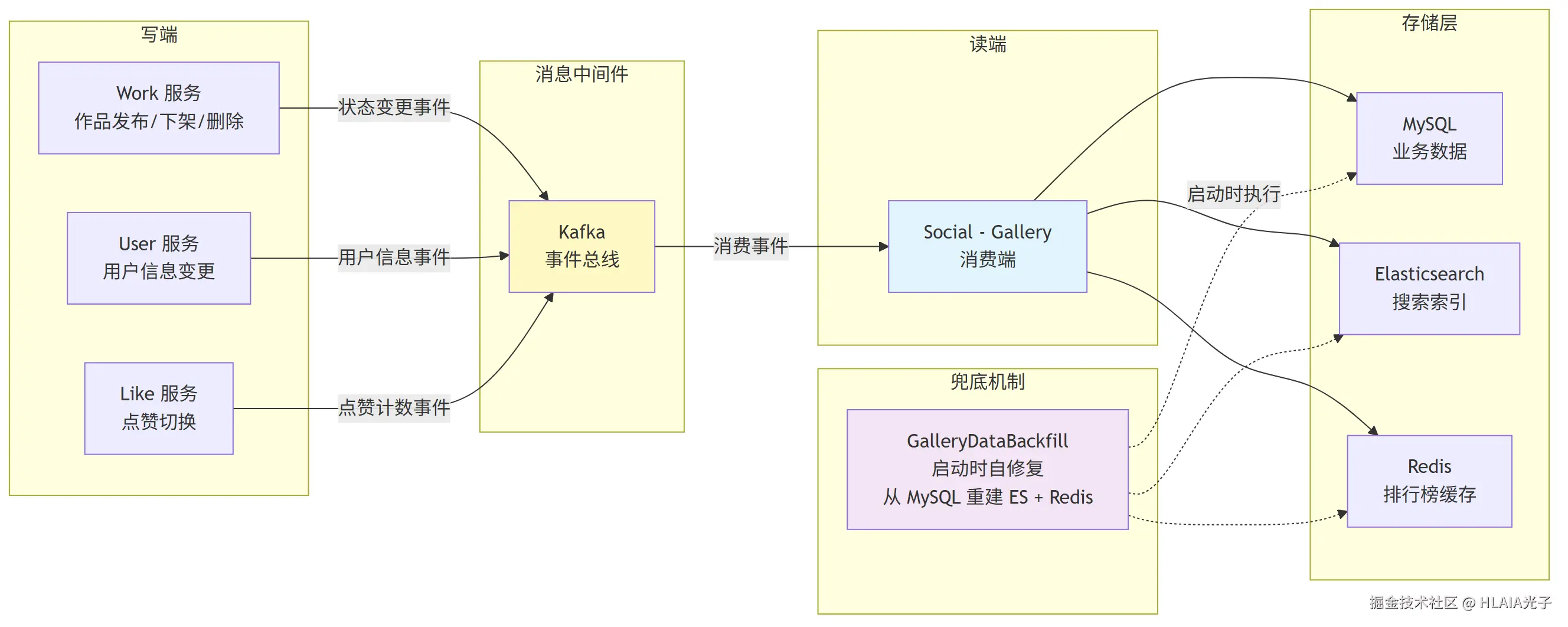
举几个实际的例子。用户在 Work 服务发布了作品,Work 服务写完数据库后发一条 Kafka 消息,Social 服务的 Gallery 收到消息后更新 MySQL、ES 索引和 Redis 排行榜。用户改了昵称,User 服务发消息,Gallery 同步更新 author_name。点赞操作触发 Like 服务更新计数,消息同步到 Redis 排行榜和 ES。
这些场景有一个共同特点:它们都允许短暂的延迟。用户发布作品后排行榜晚一两秒更新,用户改个昵称后 Gallery 里晚几秒同步,体验上完全可接受。追求强一致反而是过度设计,毕竟这个地方又不涉及马内。
为了防止消息丢失或消费失败,我加了三层保障。
第一层,@TransactionalEventListener 保证消息在事务提交后才发送,事务回滚就不发。
第二层,消费端做了幂等处理,重复消费不会导致数据错误。
第三层,服务启动时有个 Backfill 自修复机制,从 MySQL 重建 ES 索引和 Redis 数据,兜底修复可能的事件丢失。
为什么分布式事务在这里是多余的
回头看项目里的跨服务场景,随便举出四类例子。
CQRS 投影。Gallery 是 Work 服务的读模型,职责就是把写端的数据投影成方便查询的形式。CQRS 本身就是最终一致的设计,用分布式事务强一致反而违背了架构的初衷。
事件驱动通知。点赞计数同步、昵称变更同步,这类操作本来就该异步的,晚几秒更新不影响业务。
同步代理调用。Admin 服务通过 Feign 调其他服务,Feign 调用本身就是一致性边界。调用成功就完了,失败就返回错误,不需要跨服务事务来协调。
只读查询降级。AI 服务查 User、Gallery 查 Work,纯读操作,查不到就用默认值,这里不涉及数据一致性问题。
那我说白了,我白说了 (bushi)
我的架构是 CQRS + 事件驱动,那我追求的其实就是最终一致性。在这些场景下引入 Seata 或 XA,就白白增加复杂度和性能损耗。
写在最后
分布式锁和事务是微服务架构里的"标配"话题,但标配不意味着必须上。
在 OpenMMV 里,我用 SETNX 解决并发问题,用 Kafka + 幂等 + 自修复解决跨服务一致性文图,这个方案简单又好维护。
技术选型这块,不要说什么"别人都用了所以我也要用"。用不用得回到场景本身啊,你需要什么级别的保证,强一致还是最终一致,互斥就够了还是需要可重入。把场景分析清楚了之后,选型就是水到渠成的事了。
实际项目里还有一个很现实的考量:你引入的每一个框架,将来都要有人维护、升级、排障。那何况OpenMMV就我一个人维护呢?
如果你觉得这篇文章有帮助,点赞关注,点点赞~