1.作者介绍
曹博蕾,女,西安工程大学电子信息学院,2025级研究生
研究方向:机器视觉与人工智能
电子邮件:2783124403@qq.com
董柯帆,男,西安工程大学电子信息学院,2025级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:867068473@qq.com
2. KNN算法理论知识介绍
2.1 KNN算法基本思想
KNN是一种基于实例的监督学习算法。与需要显式建立参数模型的算法不同,KNN的"训练"过程主要是保存训练样本,在预测阶段再进行距离计算和邻居投票。因此,KNN算法具有原理直观、实现简单、适合小规模结构化数据分类等特点。
对于一个待分类样本,KNN会先计算它与训练集中每个样本之间的距离,然后选择距离最小的K个样本作为"最近邻"。在分类任务中,模型统计这K个邻居中各类别出现的次数,出现次数最多的类别即为预测类别。该过程体现了"近朱者赤,近墨者黑"的思想:如果一个新样本在特征空间中靠近某一类样本,它很可能也属于该类别。
|--------|----------|----------------------|
| 步骤 | 核心操作 | 作用说明 |
| 1 | 确定K值 | 设置参与投票的最近邻样本数量 |
| 2 | 计算距离 | 衡量测试样本与训练样本之间的相似程度 |
| 3 | 选择邻居 | 选取距离最小的K个训练样本 |
| 4 | 投票分类 | 统计K个邻居中类别出现次数,得到最终类别 |
2.2 距离度量方法
在KNN中,"距离"直接决定了哪些样本会被选为邻居,因此距离度量方法会影响模型分类结果。常见距离度量如下表所示。
|----------|----------------------------------------------------------------------------|--------------|-----------------|
| 距离方法 | 数学表达式 | 特点 | 适用场景 |
| 曼哈顿距离 | 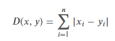 | 沿坐标轴方向累计差异 | 高维稀疏数据、文本向量等 |
| 沿坐标轴方向累计差异 | 高维稀疏数据、文本向量等 |
| 欧氏距离 | 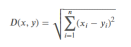 | 衡量空间直线距离,最常用 | 连续数值特征、低维结构化数据 |
| 衡量空间直线距离,最常用 | 连续数值特征、低维结构化数据 |
| 切比雪夫距离 | 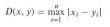 | 只关注最大维度差异 | 棋盘距离或单维极差影响大的问题 |
| 只关注最大维度差异 | 棋盘距离或单维极差影响大的问题 |
| 闵氏距离 | 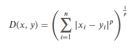 | 通过p值统一不同距离 | 需要灵活调整距离形式的场景 |
| 通过p值统一不同距离 | 需要灵活调整距离形式的场景 |
本实验采用Scikit-learn中KNeighborsClassifier的默认欧氏距离。由于帕尔默企鹅数据中的喙长、喙深、鳍肢长度、体重均为连续数值型特征,欧氏距离能够较直观地反映不同企鹅个体在体态特征空间中的接近程度。
2.3 K值选择与特征标准化
K值是KNN算法中最重要的超参数之一。K值过小,模型容易受到噪声样本影响,表现为过拟合;K值过大,模型会过度平滑类别边界,导致欠拟合。因此,实验中通常通过遍历或交叉验证寻找最优K值。
同时,KNN依赖距离计算,不同特征的数值量纲会显著影响距离大小。例如体重单位为g,数值通常在数千左右,而喙长、喙深单位为mm,数值远小于体重。如果不进行标准化,体重特征可能在距离计算中占据过大权重。为避免量纲差异干扰,本实验使用StandardScaler将各特征转换为均值为0、方差为1的标准化形式。
3. 数据集介绍
本实验使用帕尔默企鹅数据集(Palmer Penguins Dataset)。该数据集常用于机器学习入门教学和可视化分析,数据记录了南极帕尔默群岛附近企鹅的物种、岛屿、喙部尺寸、鳍肢长度、体重和性别等信息。
实验目标是根据企鹅的四项连续体态特征预测企鹅种类。目标变量species包含Adelie、Chinstrap、Gentoo三类。根据实验结果,清洗后的测试集中共有67条样本,其中Adelie为29条、Chinstrap为14条、Gentoo为24条。
|-----------------------------------|----------------------------------|----------|------------|
| 字段名称 | 中文含义 | 数据类型 | 是否用于建模 |
| species | 企鹅种类:Adelie / Chinstrap / Gentoo | 分类变量 | 目标标签 |
| bill_length_mm / culmen_length_mm | 喙长,单位mm | 连续数值 | 输入特征 |
| bill_depth_mm / culmen_depth_mm | 喙深,单位mm | 连续数值 | 输入特征 |
| flipper_length_mm | 鳍肢长度,单位mm | 连续数值 | 输入特征 |
| body_mass_g | 体重,单位g | 连续数值 | 输入特征 |
4. 实验过程与代码实现
4.1 实验环境与依赖库
|--------|--------------------|----------------------|
| 类别 | 工具/库 | 主要作用 |
| 编程语言 | Python | 完成数据处理、建模与可视化 |
| 数据处理 | pandas、numpy | 读取CSV、清洗缺失值、数组计算 |
| 机器学习 | scikit-learn | 划分数据集、标准化、KNN训练、模型评价 |
| 可视化 | matplotlib、seaborn | 绘制K值曲线、混淆矩阵和散点图 |
| 结果保存 | openpyxl | 将实验数据与预测结果导出到Excel文件 |
安装依赖命令: pip install pandas numpy matplotlib seaborn scikit-learn openpyxl
4.2 实验设计
|----------|-------------------------------------|-------------------------------|
| 实验环节 | 设置 | 说明 |
| 数据清洗 | dropna删除缺失样本 | 避免空值影响距离计算和模型训练 |
| 输入特征 | 喙长、喙深、鳍肢长度、体重 | 四项连续体态特征,适合欧氏距离度量 |
| 标签变量 | species | 三分类目标:Adelie、Chinstrap、Gentoo |
| 数据划分 | 训练集80%,测试集20% | 使用stratify保持类别比例一致 |
| 随机种子 | random_state=42 | 保证实验结果可复现 |
| 超参数寻优 | K=1~20逐一遍历 | 选择测试准确率最高的K作为最终模型参数 |
| 最终模型 | KNeighborsClassifier(n_neighbors=1) | 实验输出显示最优K=1 |
4.3 完整实验代码
KNN帕尔默企鹅三分类完整实现
python
# -*- coding: utf-8 -*-
"""
基于KNN的帕尔默企鹅种类预测分类实验
功能:读取企鹅数据集,完成数据清洗、标准化、K值寻优、模型训练、模型评估、样本预测和结果保存。
说明:如果你的数据集字段为 culmen_length_mm / culmen_depth_mm,代码会自动重命名为 bill_length_mm / bill_depth_mm。
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 1. 读取数据集
# 请将 penguins.csv 放在当前代码同级目录,或把路径修改为自己的实际路径
df_raw = pd.read_csv("penguins.csv")
print("原始数据维度:", df_raw.shape)
print("字段名称:", df_raw.columns.tolist())
print("各列缺失值统计:\n", df_raw.isnull().sum())
# 2. 兼容不同版本的字段命名
# 有些数据集使用 culmen_length_mm / culmen_depth_mm,有些使用 bill_length_mm / bill_depth_mm
rename_map = {
"culmen_length_mm": "bill_length_mm",
"culmen_depth_mm": "bill_depth_mm"
}
df_raw = df_raw.rename(columns={k: v for k, v in rename_map.items() if k in df_raw.columns})
# 3. 检查关键字段是否存在,避免 KeyError: 'species'
required_cols = ["species", "bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]
missing_cols = [col for col in required_cols if col not in df_raw.columns]
if missing_cols:
raise ValueError(f"数据集中缺少必要字段:{missing_cols}。请检查CSV表头或手动补充species标签。")
# 4. 删除含有缺失值的样本
# KNN基于距离计算,空值会导致模型无法正常训练,因此先删除缺失样本
df_clean = df_raw.dropna(subset=required_cols).reset_index(drop=True)
print("清洗后数据维度:", df_clean.shape)
# 5. 构建输入特征X和分类标签y
feature_cols = ["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]
X = df_clean[feature_cols]
y = df_clean["species"]
# 6. 按8:2比例分层划分训练集和测试集
# stratify=y保证训练集和测试集中三类企鹅占比与原始数据基本一致
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)
# 7. 特征标准化
# 只用训练集拟合scaler,测试集复用训练参数,防止测试集信息泄露
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 8. 遍历K值,寻找最优近邻数量
k_range = range(1, 21)
acc_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train_scaled, y_train)
y_pred = knn.predict(X_test_scaled)
acc = accuracy_score(y_test, y_pred)
acc_scores.append(acc)
best_k = list(k_range)[int(np.argmax(acc_scores))]
print("最优K值:", best_k)
print("最高测试集准确率:", max(acc_scores))
# 9. 使用最优K值训练最终模型
knn_final = KNeighborsClassifier(n_neighbors=best_k)
knn_final.fit(X_train_scaled, y_train)
y_pred_final = knn_final.predict(X_test_scaled)
# 10. 输出模型评估结果
final_acc = accuracy_score(y_test, y_pred_final)
print(f"最终测试集准确率:{final_acc:.4f}")
print("完整分类报告:")
print(classification_report(y_test, y_pred_final))
labels = sorted(y.unique())
cm = confusion_matrix(y_test, y_pred_final, labels=labels)
print("混淆矩阵:\n", cm)
# 11. 绘制K值选择曲线
plt.figure(figsize=(8, 5))
plt.plot(list(k_range), acc_scores, marker="o")
plt.scatter([best_k], [max(acc_scores)], s=100, label=f"最优K={best_k}")
plt.xlabel("K值(近邻数量)")
plt.ylabel("测试集准确率")
plt.title("KNN最优K值选择曲线")
plt.xticks(list(k_range))
plt.grid(alpha=0.3)
plt.legend()
plt.tight_layout()
plt.savefig("knn最优K值曲线.png", dpi=300)
plt.show()
# 12. 绘制混淆矩阵热力图
plt.figure(figsize=(6, 5))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=labels, yticklabels=labels)
plt.xlabel("预测企鹅种类")
plt.ylabel("真实企鹅种类")
plt.title(f"KNN企鹅分类混淆矩阵(K={best_k})")
plt.tight_layout()
plt.savefig("knn分类混淆矩阵.png", dpi=300)
plt.show()
# 13. 绘制测试集散点图(喙长 vs 喙深)
plot_df = X_test.copy()
plot_df["true_species"] = y_test.values
plot_df["pred_species"] = y_pred_final
plt.figure(figsize=(8, 5))
sns.scatterplot(data=plot_df, x="bill_length_mm", y="bill_depth_mm", hue="true_species", style="true_species", s=80)
plt.xlabel("喙长 Bill Length (mm)")
plt.ylabel("喙深 Bill Depth (mm)")
plt.title("测试集分类结果可视化(喙长 vs 喙深)")
plt.tight_layout()
plt.savefig("测试集分类散点图.png", dpi=300)
plt.show()
# 14. 新企鹅样本预测示例
new_sample = pd.DataFrame([
[45.0, 14.0, 210.0, 4500.0],
[39.0, 18.0, 180.0, 3750.0],
[50.0, 17.0, 195.0, 3900.0]
], columns=feature_cols)
new_sample_scaled = scaler.transform(new_sample)
new_pred = knn_final.predict(new_sample_scaled)
for i, (row, pred) in enumerate(zip(new_sample.values, new_pred), start=1):
print(f"新企鹅{i} 特征:喙长{row[0]}mm、喙深{row[1]}mm、鳍长{row[2]}mm、体重{row[3]}g")
print(f"预测种类:{pred}")
# 15. 将实验结果保存到Excel,便于课程归档和汇报查看
result_detail = X_test.copy()
result_detail["真实类别"] = y_test.values
result_detail["预测类别"] = y_pred_final
result_detail["是否预测正确"] = result_detail["真实类别"] == result_detail["预测类别"]
k_result = pd.DataFrame({"K值": list(k_range), "测试集准确率": acc_scores})
new_pred_result = new_sample.copy()
new_pred_result["预测种类"] = new_pred
with pd.ExcelWriter("企鹅KNN分类完整结果.xlsx", engine="openpyxl") as writer:
df_raw.to_excel(writer, sheet_name="原始数据", index=False)
df_clean.to_excel(writer, sheet_name="清洗后数据", index=False)
k_result.to_excel(writer, sheet_name="K值准确率", index=False)
result_detail.to_excel(writer, sheet_name="测试集预测明细", index=False)
new_pred_result.to_excel(writer, sheet_name="新样本预测", index=False)
print("实验完成:图像和Excel结果已保存。")5. 实验结果与分析
5.1 K值选择结果
实验遍历K=1到K=20的取值,并记录每个K值在测试集上的准确率。根据PPT实验结果,K=1时测试集准确率达到1.0000,并被选为最终模型参数;K=1至K=7时准确率均保持在较高水平,K从8开始准确率下降到约0.9851,说明过大的K会引入更多距离较远的邻居,导致局部分类边界被平滑。
在本数据集中,三类企鹅在体态特征空间中分布较清晰,尤其是Gentoo与另外两类在喙深、鳍肢长度、体重等特征上差异明显,因此较小的K值能够较好捕捉局部类别结构。
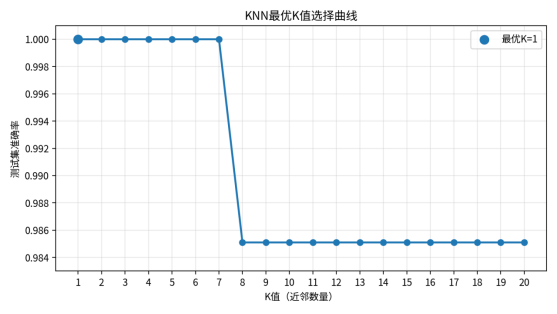
图1 KNN最优K值选择曲线
|----------|--------------|------------------------|
| K值范围 | 测试集准确率表现 | 结果解释 |
| K=1 | 1.0000 | 最优K值,最终模型采用该参数 |
| K=2~7 | 1.0000 | 分类边界稳定,邻居投票未改变预测结果 |
| K=8~20 | 约0.9851 | 邻居范围扩大后,少量样本受到其他类别邻居影响 |
5.2 分类评估结果
在独立测试集上,K=1的KNN最终模型取得了1.0000的准确率。三类企鹅Adelie、Chinstrap、Gentoo的precision、recall和F1-score均为1.00,说明模型在本次测试划分下没有出现误分类。
从混淆矩阵可以看到,测试集中29只Adelie、14只Chinstrap和24只Gentoo均被正确预测到对应类别,非对角线元素全部为0。这一结果表明,四项体态特征对三类企鹅具有较高判别性,也说明标准化处理对基于距离的KNN模型是必要且有效的。
|--------------|---------------|------------|--------------|-------------|
| 类别 | Precision | Recall | F1-score | Support |
| Adelie | 1.00 | 1.00 | 1.00 | 29 |
| Chinstrap | 1.00 | 1.00 | 1.00 | 14 |
| Gentoo | 1.00 | 1.00 | 1.00 | 24 |
| Accuracy | - | - | 1.00 | 67 |
| Macro avg | 1.00 | 1.00 | 1.00 | 67 |
| Weighted avg | 1.00 | 1.00 | 1.00 | 67 |
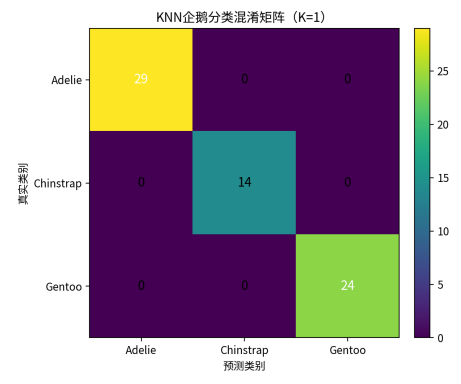
图2 KNN企鹅分类混淆矩阵(K=1)
|----------------|------------|---------------|------------|
| 真实类别\预测类别 | Adelie | Chinstrap | Gentoo |
| Adelie | 29 | 0 | 0 |
| Chinstrap | 0 | 14 | 0 |
| Gentoo | 0 | 0 | 24 |
5.3 可视化散点图与样本预测
散点图以喙长和喙深两个特征进行二维展示。虽然模型实际使用了四个特征,但二维可视化仍能帮助观察不同企鹅类别的分布情况:Adelie样本通常喙长较短,Chinstrap样本喙长较长且喙深偏大,Gentoo样本喙深相对较小,类别之间整体具有较明显的分布差异。
实验还构造了3组新企鹅体态数据进行预测,用于验证模型的落地使用效果。模型分别预测为Gentoo、Adelie和Chinstrap,说明训练后的KNN模型不仅能完成测试集评估,也可以对新的单条样本进行快速分类。
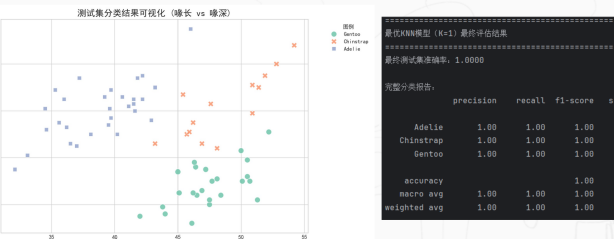
图3 测试集分类散点图与分类评估报告截图
|--------|-----------|-----------|-----------|----------|-----------|
| 样本 | 喙长/mm | 喙深/mm | 鳍长/mm | 体重/g | 预测类别 |
| 新企鹅1 | 45.0 | 14.0 | 210.0 | 4500.0 | Gentoo |
| 新企鹅2 | 39.0 | 18.0 | 180.0 | 3750.0 | Adelie |
| 新企鹅3 | 50.0 | 17.0 | 195.0 | 3900.0 | Chinstrap |
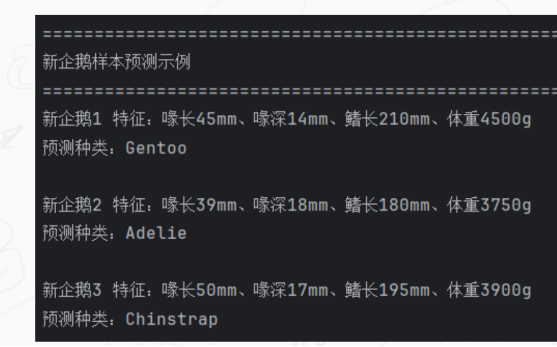
图4 新企鹅样本预测结果截图
6. 问题与分析
|-------------------|----------------------------|---------------------------|-------------------------------------------|
| 问题 | 现象 | 原因 | 解决办法 |
| 缺少pandas模块 | 运行时报No module named pandas | 本地环境未安装数据处理库 | 执行 pip install pandas 或安装requirements中的依赖 |
| KeyError: species | 代码访问df_raw'species'时报错 | CSV文件中没有species列,或列名拼写不一致 | 检查表头;若无类别列,需要手动补充企鹅种类标签 |
| 量纲差异影响距离 | 体重数值远大于尺寸特征 | KNN基于距离计算,量纲不一致会改变距离权重 | 使用StandardScaler,仅用训练集fit,测试集transform |
| K值选择不稳定 | 不同K值准确率可能不同 | K过小易过拟合,K过大易欠拟合 | 遍历K=1~20或使用交叉验证确定最优K |
7. 总结与展望
本实验基于KNN算法完成了帕尔默企鹅种类预测分类任务。实验从数据读取与缺失值清洗出发,选取喙长、喙深、鳍肢长度和体重四项物理特征作为输入,通过分层划分保证训练集和测试集类别分布一致,再使用StandardScaler消除量纲差异,最后通过遍历K值确定最优参数并训练最终分类器。
实验结果显示,当K=1时,模型在测试集上取得1.0000的准确率,三类企鹅的Precision、Recall和F1-score均达到1.00,混淆矩阵中没有误分类样本。这表明帕尔默企鹅数据集中三类企鹅的体态特征区分度较高,也说明KNN算法在小规模、低维、结构化分类任务中具有较好的实用价值。
后续可以进一步尝试交叉验证、不同距离度量、特征组合对比、PCA降维可视化,以及与决策树、随机森林、支持向量机、逻辑回归等分类模型进行横向比较,从而更全面地理解不同机器学习算法在同一数据集上的性能差异。