沿袭公司的传统,项目仓库 A 和 idl 仓库 B 是分开的。因为 B 里面还有一些公用的 idl,就直接在 B 仓库生成,推送到远端,A 拉取依赖。本来让人来操作没啥毛病,这套流程。但是,让 AI 操作的时候,但凡 B 仓库上有点啥问题,比如 idl 写错了生成不了,生成以后推送不上去,有时候甚至没啥错误,它都会把 idl 的生成直接搬到 A 仓库来。(本来想截图的,后来发现会话被压缩了)。这样的例子不是个例,哈佛物理教授疯了:我让AI写论文,结果两周干完博士一年工作!冲击顶刊 教授就总结到

还有在写一个小 demo 的时候需要一个实时音频检测,但凡发生一点小问题,AI 就开始退回到模拟音频检测数据,根本怎么说都不管用。做可观测的时候,跟它说了 grafana 需要模拟用户手动,它懂不懂就挂到 yaml 里尝试自动加载,数据源还不设置。总结一句就是,迎难而退。
最重要的问题还是,它改坏了以后,叫它改回来,它不一定能改的回来。搞可观测干了一天的 dashboard,就是因为某个 pannel 需要调整,它就把整个 dashboard 都调坏了。一天天的,干活就跟吃巧克力一样,永远不知道下一次会发生什么。就像这样 ↓

发生这种问题的本质是因为,在 AI 偶尔的靠谱中不断拉高人对它的预期,让人忘了,不靠谱才是它的本质。它逻辑写对且漂亮是偶尔发生的事情,但是因为偶尔发生,人们就开始误以为它每次都会写对,根本不用约束。从开始那种小心翼翼的试探性使用,转变成让 AI 大胆去尝试,结果就是,干了一天又白干了。捂脸
我的做法非常简单粗暴,让 AI 自己加了一个 skill,开始是用在问题修复上,所以取名叫 fix
yaml
---
name: fix
description: 修复代码问题时,先复述问题让用户确认,再开始修改
---
用户描述了一个问题,你需要:
1. **先复述问题**,包括:
- 当前实际表现(什么不对)
- 期望表现(应该是什么)
- 涉及的状态或场景
2. **描述解决方案**,包括:
- 根本原因分析
- 准备怎么修改(改哪个文件、改什么逻辑)
- 预期修改后的效果
3. **等待用户确认**,用户说"对"或"确认"后,再开始修改代码。
不要在用户确认之前做任何代码修改。当 AI 开始瞎搞时,就可以这样用。
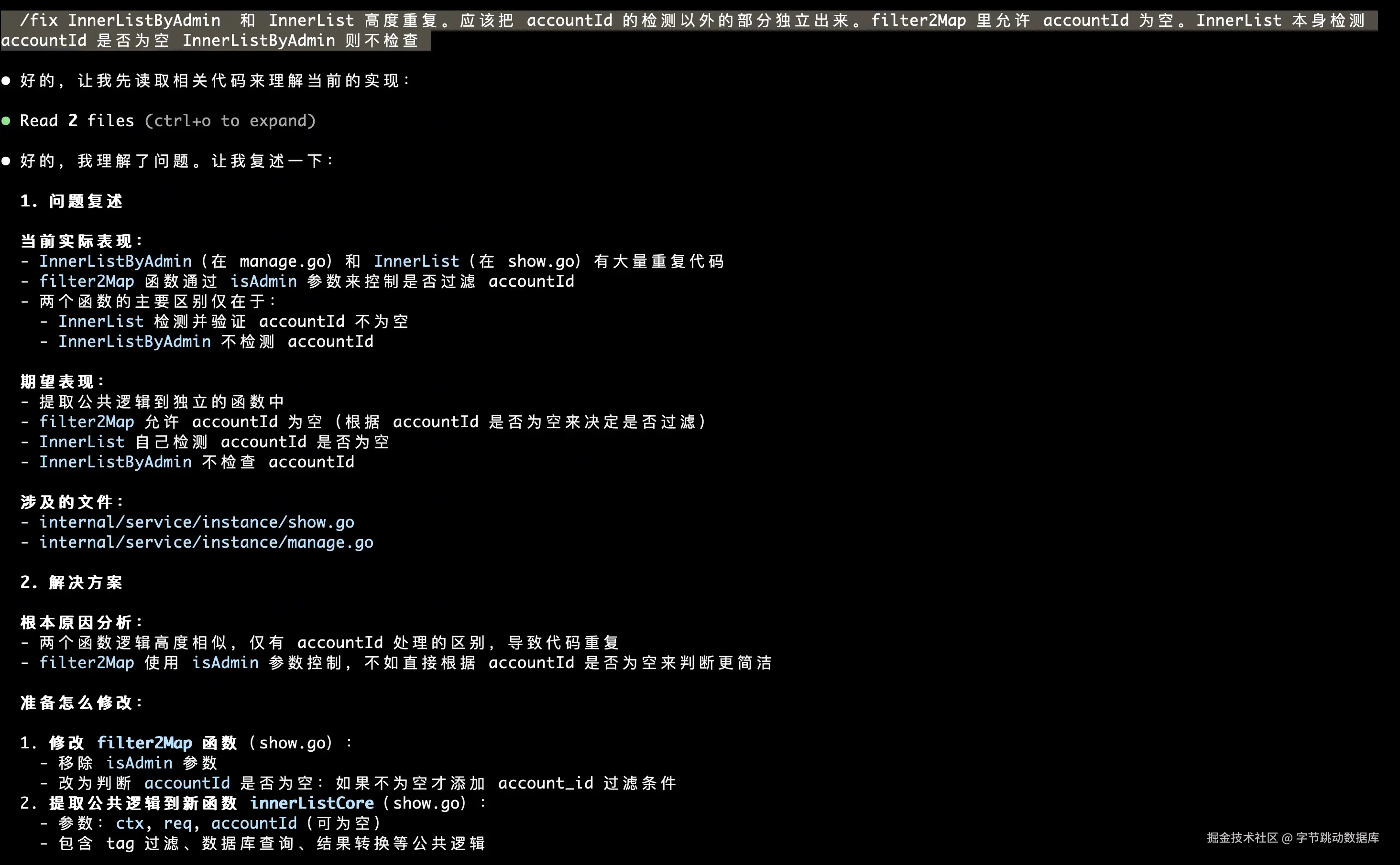
就是搞清楚两件事。
- 它到底有没有听懂你说的问题。之前对话修复的时候,经常发现,你描述的和它改的,就不是同一个问题
- 它准备怎么解决这个问题。它理解问题,且理解问题产生的原因,并给出可能操作方案
让开盲盒,变成了,审核过后的必然。如果在这个阶段有什么不满意,可以继续跟它讨论。
炸一看好像有点像 plan 模式,对不对 ? 但我实际使用 plan 模式的时候,发现效果很不好。每次它 plan 出来以后,就开始问你要权限写代码。每次都要跳过三个选项,选最后一个,才能跟它讨论。而且不是讨论完以后再总结,而是,每次提一个点,就开始总结。每次还会告诉你 context 已经用了很多了(赶紧开始写代码吧),非常增加心理负担。
后来我发现这个 skill 还有其他优点
-
不止能用在代码修复场景,比如写 grafana 面板不对,也可以用这个 skill
-
它能让 AI 冷静下来。正常的流程是你说它改,它会非常迫切想去改代码,没有仔细思考。这有点像人,非常注重产出,而忽略思考。但是这个 skill 一用,它就冷静了。它开始思考。很多直接写代码的时候,会出错的情况,用上这个 skill,它就不会给错误的方案
在群里问的时候,发现很多人都有类似的经历。不知道 你 是怎么解决的呢 ~
想知道,我是干什么的时候,遇到这么奇葩的场景?当然是在用 OpenSearch 做 OpenClaw 的可观测 OpenClaw 透视镜:基于 OpenSearch 的完整可观测实践,只知道养虾花了很多钱,却不知道钱花哪里了,可以来试试这个。