一、引言
- 前面我们学习了很多顺序结构:顺序表 、链表 、栈 (先进后出)、队列(先进先出)。这些都是顺序结构,顾名思义,他们存储数据都与先后顺序有关。
- 但是,我们在生活中有时候并不是按照先后顺序 来排的。而是按照优先级 来排的
举个例子:医院急诊中,病重的病人先治;超市中,畅销的商品多进货。 - 在这种情况下,就与数据的先后顺序无关了,而是与数据的优先级 有关。堆就是实现这种优先队列最高效的结构之一。
二、树
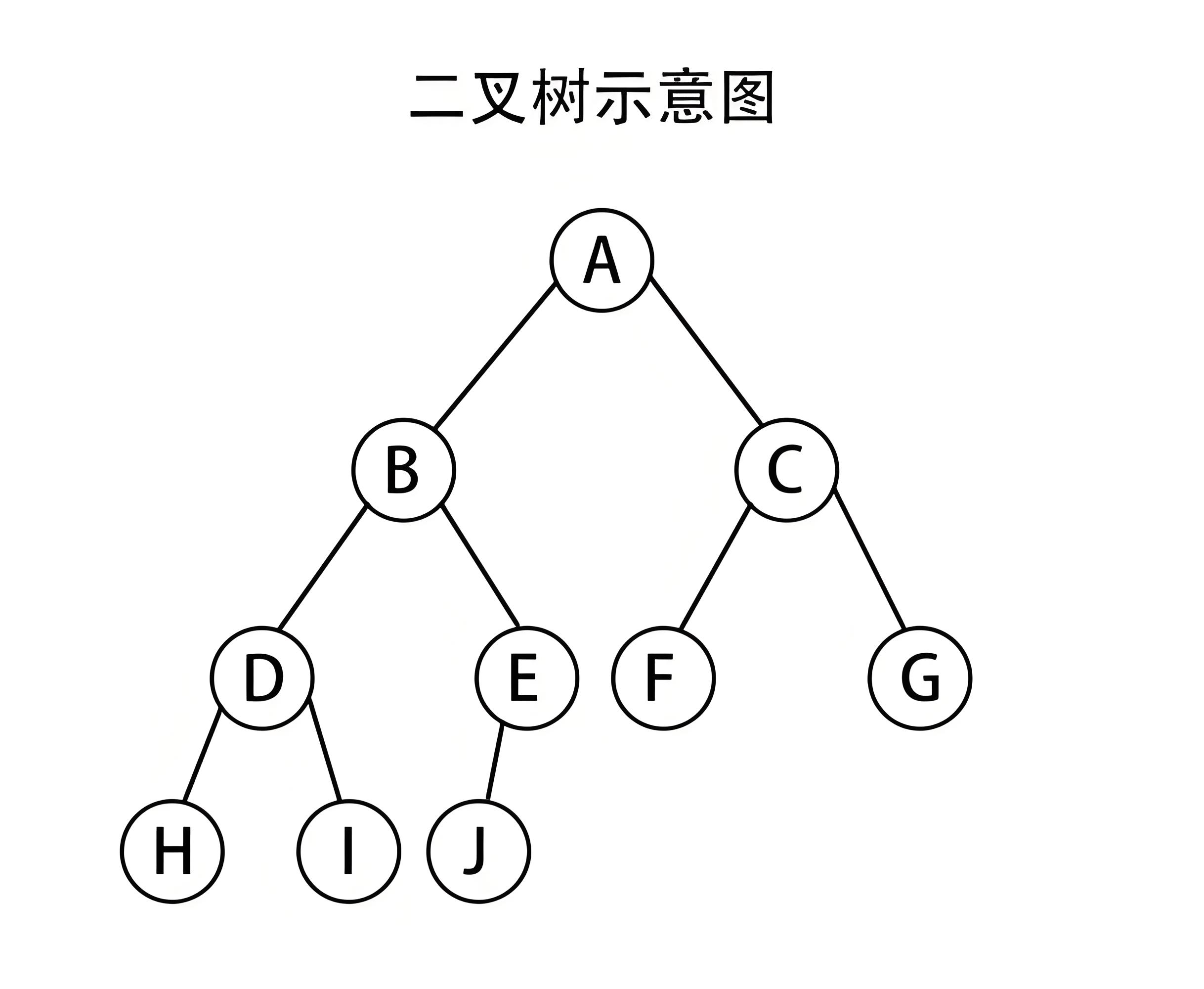
要想学习堆,我们得先来学习一下树。先来看一张树的图:
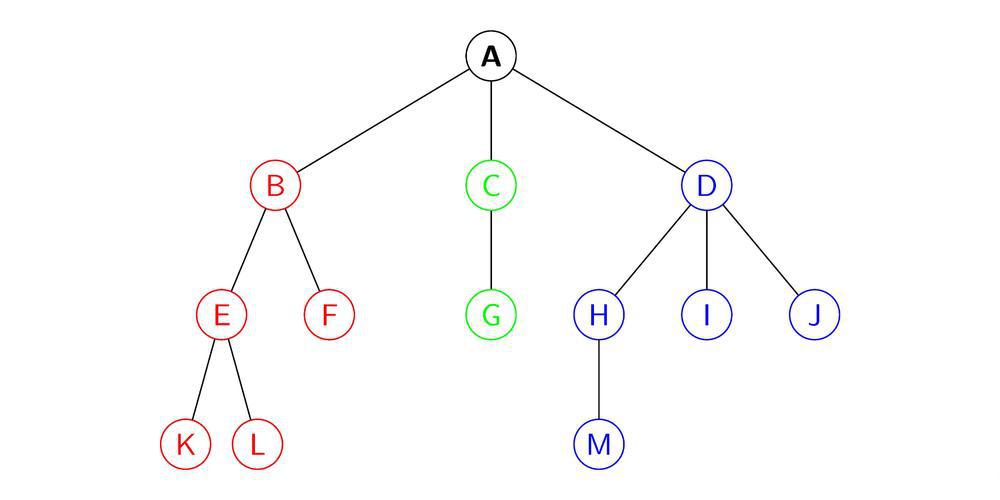
这就是树,它具有以下特点:
- 只有一个根结点
- 每个结点只有一个父结点(树是一种递归定义的数据结构)
- 一棵 N 个结点的树有 N-1 条边(边就是连接两个结点的线段)
我们再来看一些关于树的术语:
- 结点的度 :一个结点的子节点的个数 称为这个结点的度
图中:B的度为2,C的度为1,D的度为3 - 树的度 :一棵树中最大的结点的度 就是树的度
图中这棵树的度为3 - 树的高度/深度 :树中结点的最大层次
若根结点为第一层次,那么图中这棵树的深度就为4,其中一条最长路径为 A->B->E->K - 兄弟结点:属于同一层次的结点互称兄弟结点
- 叶子结点:最底层的结点(无子结点的结点)称为叶子节点
- 空树:一棵树由 n(n>=0) 个结点组成,当 n=0 时,称为空树
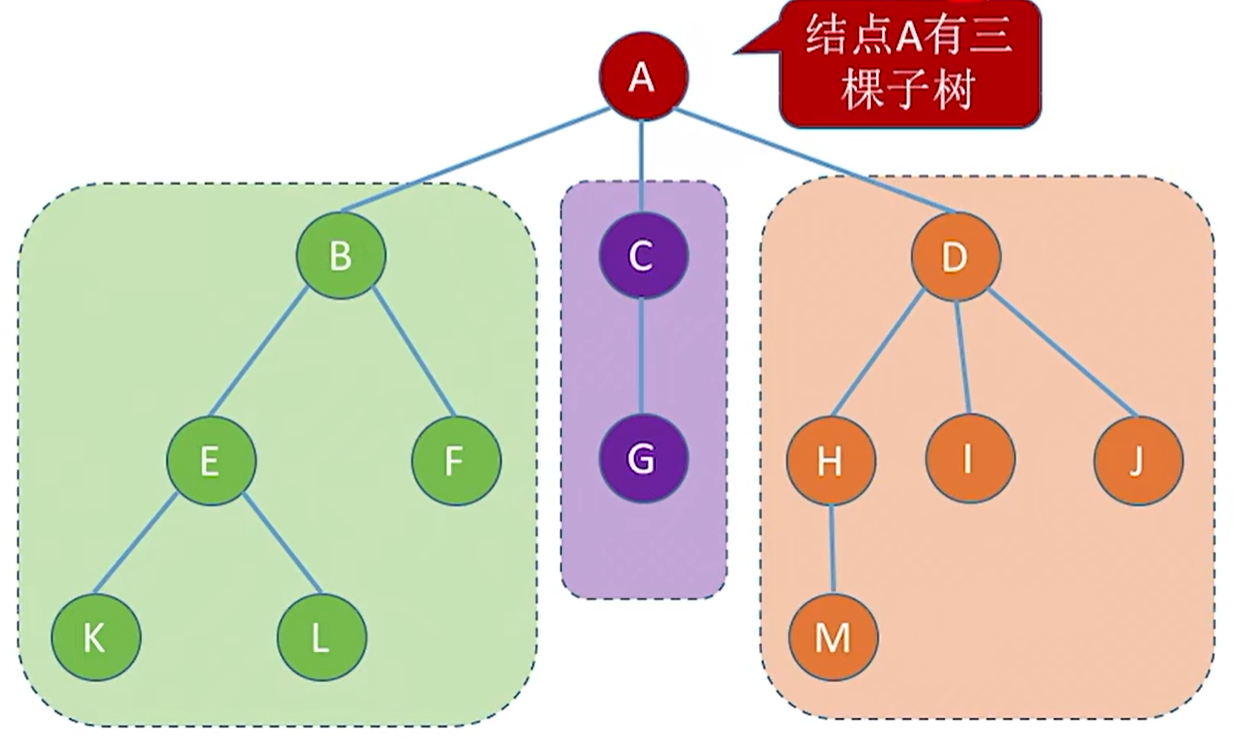
- 子树 :n>1 时,其余结点可分为 m 个互不相交的有限集合,其中每个集合本身又是一棵树,称为根结点的子树。如下图:
从图直观地感受到树的结构之后,我们来想一想这种数据结构该如何定义呢?是用数组还是链表?
如果树的结构不是固定的,那么便无法使用数组来定义,我们需要能够还原出树的结构的定义方式。
若使用数组,就会产生以下分歧:例如我们有一个数组 1, 2, 3, 4, 5,那么它到底是表示的以下哪种树呢?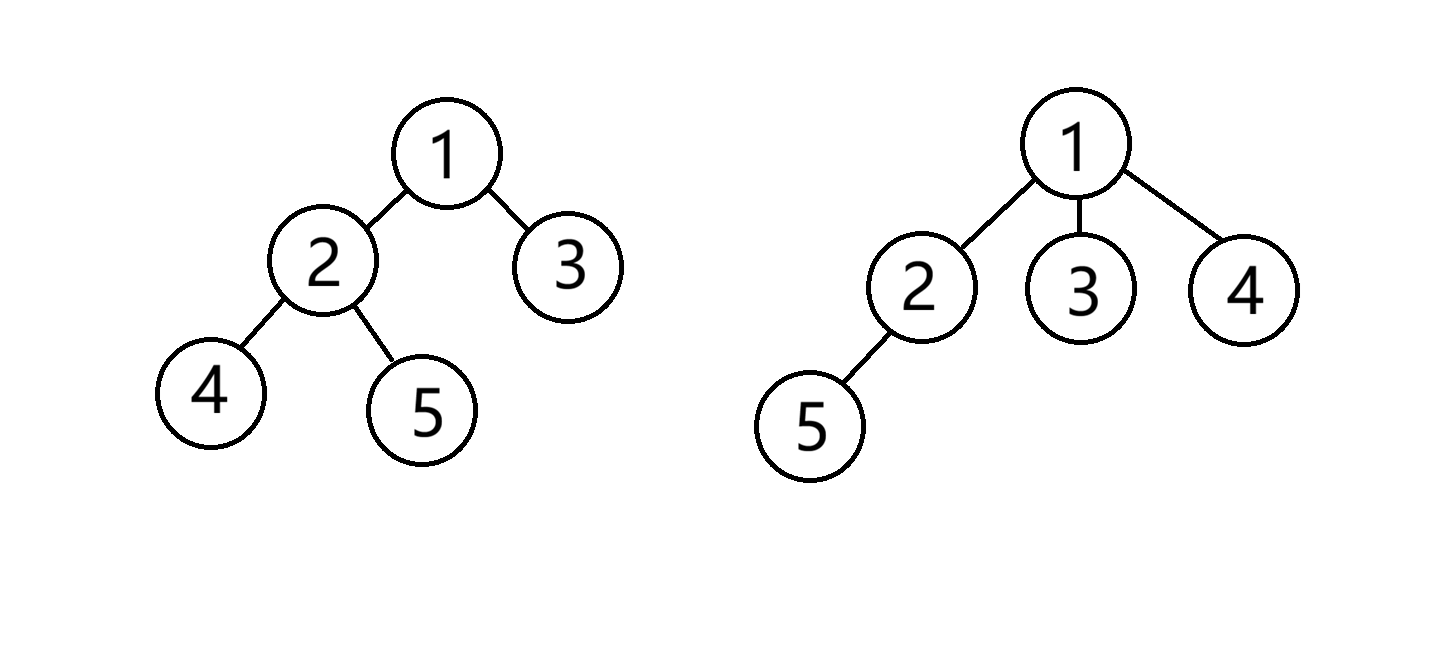
这时候就产生了分歧,因此我们用结点的方式来定义树
定义树的方式有很多种,我这里只举一个比较常见的定义方式。兄弟-儿子表示法
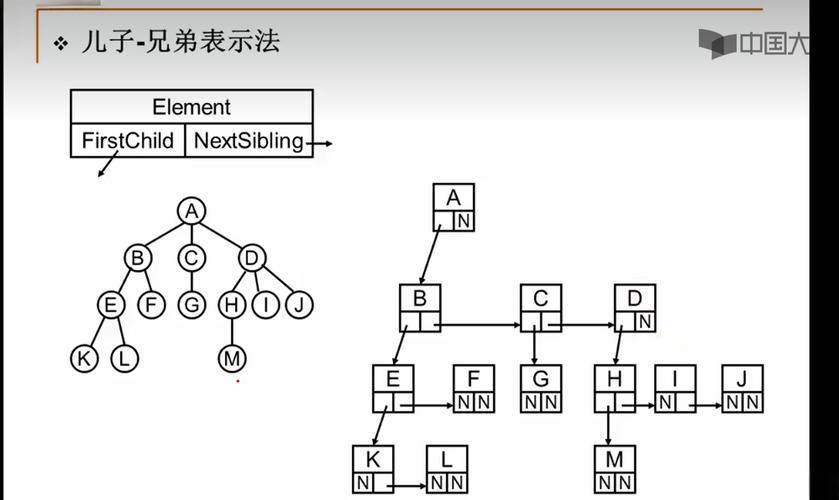
一个结点中,由三个部分组成,一部分存放数据,一部分指向左边第一个儿子,一部分指向右边第一个兄弟,这样的定义方式就称为兄弟-儿子表示法
cpp
struct treeNode
{
int data;
struct treeNode* brother;
struct treeNode* child;
};了解完树之后,我们还得来看一下什么是二叉树
二叉树
二叉树也是树结构的一种,它有以下特点:
- 二叉树由一个根结点 和一个左子树 一个右子树组成
- 二叉树为有序树,子树有左右之分
- 二叉树的度小于等于2(一个结点最多有两个子结点)
二叉树中,有两种特殊的二叉树:满二叉树、完全二叉树。老规矩,先看图:
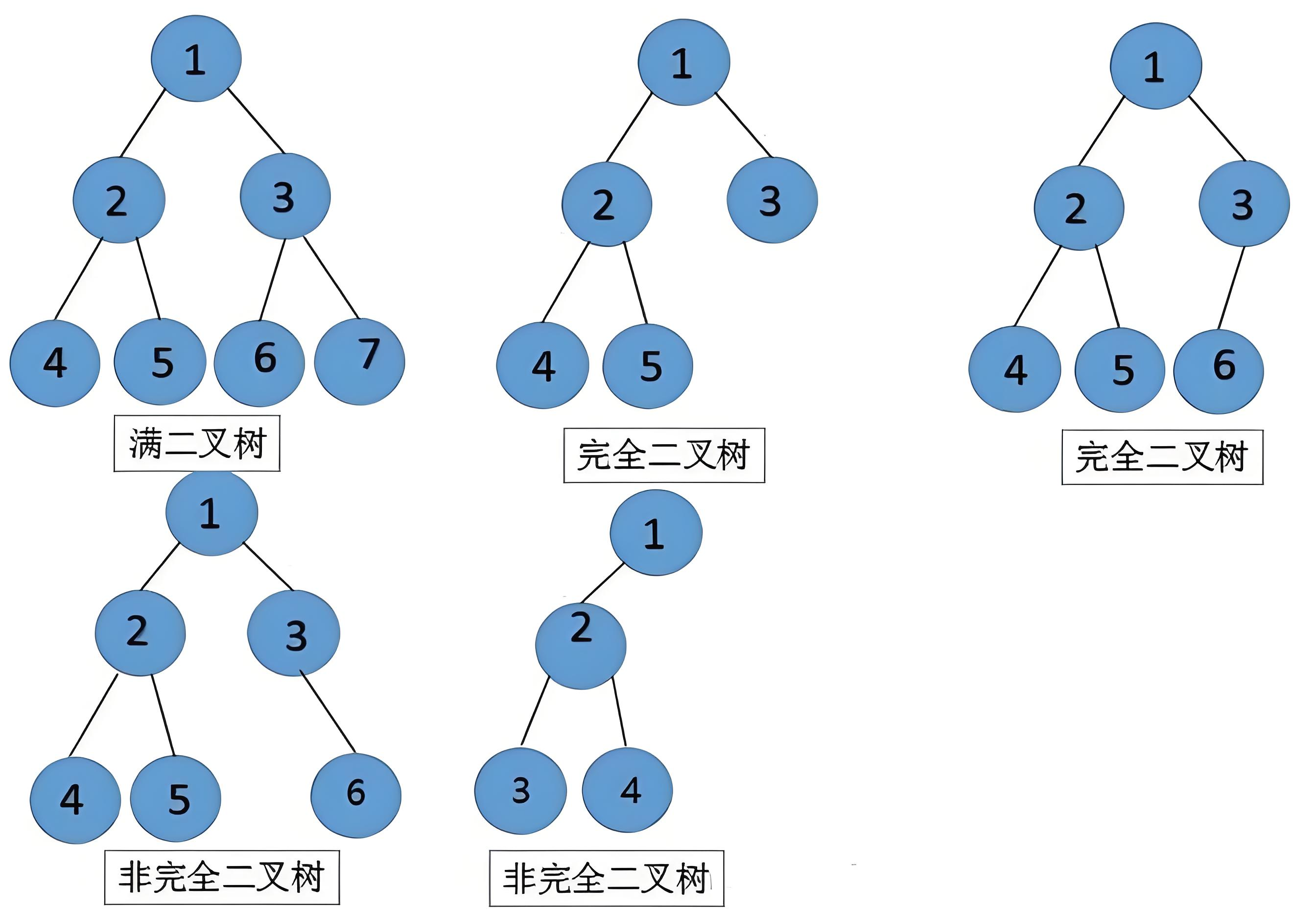
满二叉树:每一层的结点都达到最大的二叉树就是满二叉树
完全二叉树:除了最后一层,其余层的结点都达到最大,最后一层从左向右依次排列
二叉树的性质:
- 非空二叉树的第 i 层上最多有 2^(i-1) 个结点
- 深度为 h 的二叉树最大结点数为 2^h - 1
- 若将二叉树按从左到右、从上到下的顺序依次编号,根结点为0,那么会有以下结论:
i > 0 时,i 的父结点为 (i-1)/2
2i +1 < n 时,i 的左子结点就为 2i + 1 < n
2i +2 < n 时,i 的右子结点就为 2i + 2 < n
二叉树的存储结构
二叉树有两种存储结构:顺序结构、链式结构
顺序结构
顺序结构适合存储完全二叉树,因为存储不完全二叉树时会有很多空间浪费,如图所示
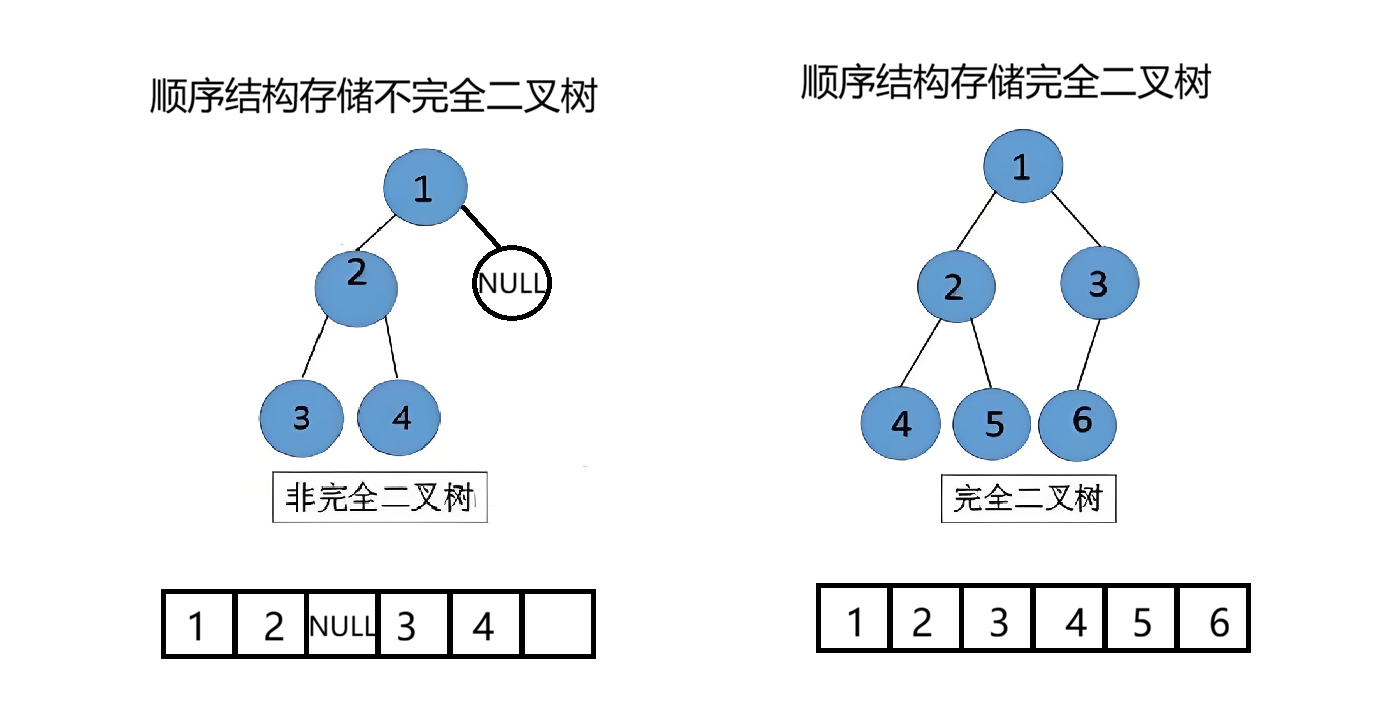
因为我们要保证能用存储结构来还原出二叉树的结构 ,所以空结点的位置也要存储,这样只需要按照顺序即可还原出二叉树,因此使用顺序结构 存储不完全二叉树会有很大的空间浪费。
链式结构
链式结构通常是由三个域组成:数据域 与左右指针域。
链式结构分为二叉链 和三叉链,二叉链只有左右指针,三叉链多了一个指向父结点的指针。
三、堆
有了前面树与二叉树的铺垫,我们正式进入堆。
这里所说的堆与我们之前提到的内存中的动态申请空间的那个堆并不是一回事,这里的堆 是一种数据结构。
堆 是一种完全二叉树 ,它与完全二叉树不同的是具有优先级排序 。堆分为大根堆 和小根堆。
大根堆 :子结点均不大于父结点
小根堆:子结点均不小于父结点
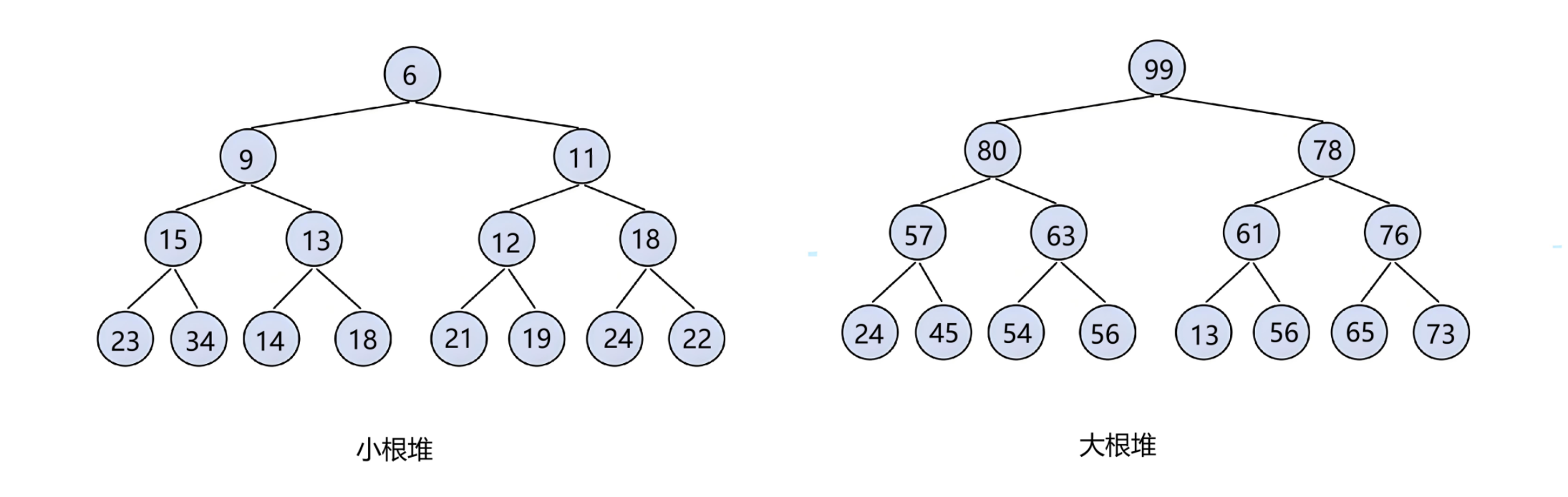
根据图和堆的类型的名字,我们也能够看出:小根堆就是根为最小值的堆 ;大根堆就是根为最大值的堆。由此我们就推出了堆的一个性质:堆顶一定为整个堆的最值。
堆顶为最值的同时保证大根堆的父结点都比子结点大或小,这样的数据结构就叫做堆 。并且一定不要忘了:堆是一种完全二叉树。
还是老规矩,了解完堆的概念之后,就该来学习它的各种操作的实现了。
堆的操作(插入删除调整)
首先来想,若以大根堆为例,插入操作该往哪个位置插入?插入后如何保证这个结点比子结点大、比父结点小?
下面我来给大家讲解一下。我们在实现之前,要先知道这个数据结构它有哪几种操作,以及操作的规范。先明确:堆的插入 只能在最后 ,删除 只能在最前面。
这时候就有同学会问了:这不是和队列一样了吗?单看插入和删除的位置,的确是这样的,但堆是具有优先级排序的结构,因此我们在普通的插入和删除后,还需要进行调整 ,调整到符合堆的顺序的结构,这才算是完整的堆的插入/删除。
那么具体是如何调整的?这里有两种调整方式:向上调整 和向下调整。
在插入操作之后,我们插入的数据在最末尾,也就是叶子结点的位置,此时需要对这个新插入的结点向上调整到合适的位置。
而删除操作具体的实现方法是:先将首尾互换,再让有效数据个数-1,就完成了删除。但此时根结点就不再是原来的值了,因此需要对此时的根结点向下调整到合适的位置。
文字看不懂没关系,上图
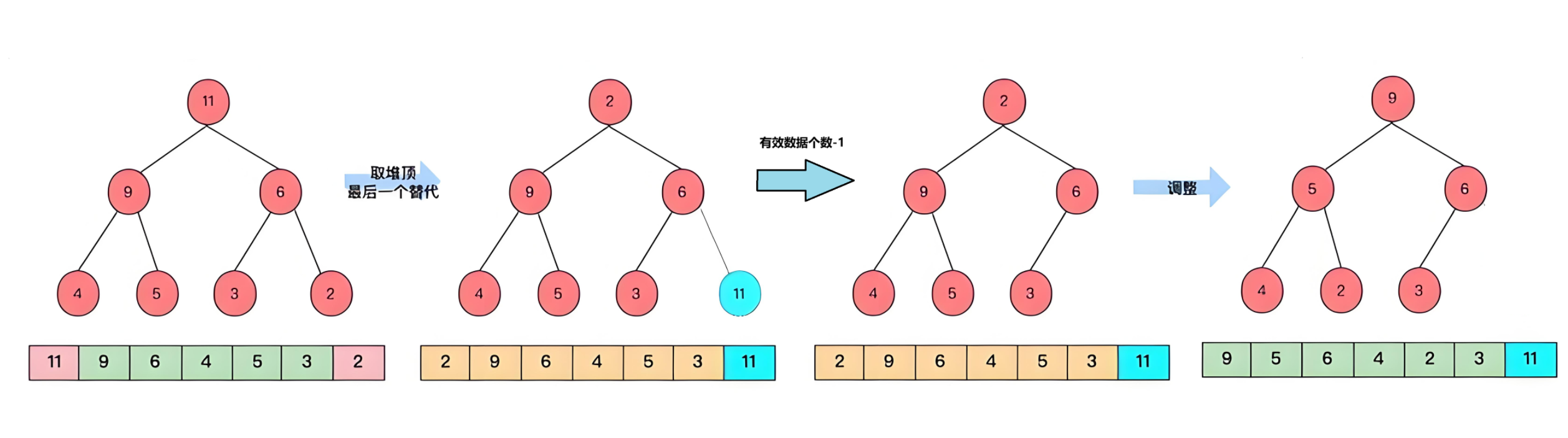 小根堆的删除操作
小根堆的删除操作
原理懂了之后,下面我们就开始上代码
cpp
// 以大堆为例
typedef struct Heap
{
int* arr;
int size;
int capacity;
}Heap;
// 初始化
void HeapInit(Heap* heap)
{
assert(heap);
heap->arr = NULL;
heap->size = heap->capacity = 0;
}
// 销毁
void HeapDestry(Heap* heap)
{
assert(heap);
if (heap->arr)
{
free(heap->arr);
heap->arr = NULL;
}
heap->size = heap->capacity = 0;
}
// 交换
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
// 向上调整
void AdjustUp(int* arr, int child)
{
assert(arr);
int parent = (child - 1) / 2;
while (parent >= 0)
{
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
// 向下调整
void AdjustDown(int* arr, int parent, int n)
{
assert(arr);
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && arr[child] < arr[child + 1])
{
child++;
}
if (arr[parent] < arr[child])
{
Swap(&arr[parent], &arr[child]);
}
else
{
break;
}
}
}
// 入堆
void HeapPush(Heap* heap, int x)
{
assert(heap);
if (heap->size = heap->capacity)
{
int newCapacity = heap->capacity = 0 ? 4 : 2 * heap->capacity;
int* tmp = (int*)realloc(heap->arr, sizeof(int) * newCapacity);
if (tmp == NULL)
{
perror("realloc failed");
exit(1);
}
heap->arr = tmp;
heap->capacity = newCapacity;
}
heap->arr[heap->size] = x;
heap->size++;
AdjustUp(heap, heap->size - 1);
}
// 出堆
void HeapPop(Heap* heap)
{
assert(heap && heap->arr);
Swap(&heap->arr[0], &heap->arr[heap->size - 1]);
heap->size--;
AdjustDown(heap, 0, heap->size);
}
// 判空
bool HeapEmpty(Heap* heap)
{
assert(heap);
return heap->size;
}四、堆的扩展
堆排序
基本思想
堆排序是一种基于二叉堆(完全二叉树)的排序算法。它的核心思想分为两步:
-
建堆 :将待排序数组构建成一个大堆(升序用大堆,降序用小堆)。大堆满足:任意父节点的值 ≥ 其子节点的值,因此堆顶就是数组中的最大值。
-
排序 :反复将堆顶(当前最大值)与数组末尾元素交换,然后堆大小减一,再对新的堆顶执行向下调整,使剩余部分重新满足大堆性质。重复此过程,直到堆大小为1,数组即完成升序排序。
为什么升序用大堆?因为每次把最大值交换到末尾,最终数组从左到右就是从小到大。
cpp
// 堆排序
// 这里是大堆--升序
void HeapSort(int* arr, int n)
{
assert(arr);
int parent = (n - 1 - 1) / 2;
// 建堆
while (parent >= 0)
{
AdjustDown(arr, parent, n);
parent--;
}
// 排序
while (n > 0)
{
Swap(&arr[0], &arr[n - 1]);
n--;
AdjustDown(arr, 0, n);
}
}时间复杂度 :建堆 O(n),排序过程执行 n-1 次交换和向下调整,每次向下调整 O(log n),总 O(n log n)。整体 O(n log n)。
空间复杂度 :原地排序,仅使用常数个额外变量,O(1)。
TOP-K问题
何为TOP-K问题?
从海量数据(N 非常大,无法全部载入内存)中找出最大(或最小)的前 K 个数。
常见变体:
-
找出数组中最大的 K 个数
-
找出数组中第 K 大的数
核心思想
用大小为 K 的小堆:
-
取前 K 个元素,建成一个小堆(堆顶是堆中最小的元素)。
-
遍历剩下的 N-K 个元素,对于每个元素
x:如果
x> 堆顶(即比当前第 K 大的元素还大),则用x替换堆顶,然后向下调整,重新使堆保持小堆性质。 -
遍历结束后,堆中的 K 个元素就是最大的 K 个数。
-
时间复杂度 :建堆 O(K),遍历剩余 N-K 个元素,每个元素最多触发一次替换和调整 O(log K),总 O(N log K) 。
当 K 远小于 N 时,接近 O(N)。
具体代码大家可以下去之后自己试着实现以下。
以上就是本期全部内容了,有不懂的可以在评论区留言。感谢观看!