别再手动写提示词了 --- SkillOpt 让技能文档自己进化
我花了很长时间观察一个矛盾:冻结的大语言模型越来越强,但让它们在具体任务上"精通"这件事,我们一直在用最笨的方法 --- 手动写提示词。一个领域专家花几周打磨出一份 skill 文档,模型用它表现不错,但换个场景就不行了,你得从头再写一份。更讽刺的是,模型自己明明能看到哪些地方做错了,但你就是不让它从错误中学习。
SkillOpt 做了一件我一直觉得应该有人做的事:它把自然语言技能文档当作"权重",在不触碰模型参数的前提下,让技能文档像神经网络训练一样自我进化。
背景:强模型 + 弱技能的困境
GPT-5.x、Claude、Qwen 这些模型的能力已经够强了。给它们一个精心设计的 skill 文档 --- 一个描述"你应该怎么一步步做这件事"的 markdown 文件 --- 模型在 QA、具身交互、代码生成、数学推理等任务上的表现会显著提升。问题是,谁来写这份 skill 文档?
传统方案有三种思路,每一种都有合理性,但每一种都遇到了瓶颈:
人工编写(Human skill) --- 领域专家根据自己的经验手动撰写。思路很直接:人最懂怎么做,让最懂的人写。这在小范围、稳定场景下确实管用。但瓶颈也很明显:不可扩展、无法自动迭代。ALFWorld 上 Human skill 只做到 54.7 分,而 SkillOpt 做到了 84.3。
LLM 一次性生成(LLM skill) --- 让大模型直接生成一份 skill 文档,然后就用它。思路也合理:模型本身就理解语言,让它自己写自己的指令。但缺乏从失败中学习的能力 --- 生成完就停了,没有迭代优化。SpreadsheetBench 上 LLM skill 只拿到 35.9,SkillOpt 拿到了 51.7。
梯度类比优化(TextGrad) --- 把 prompt 优化类比成反向传播,让 LLM 给出"文本梯度"来修改 prompt。思路有创新性,但缺乏稳定化机制。没有 bounded edit 控制修改范围,没有 validation gate 防止破坏性重写,没有 slow update 做纵向修正。结果就是一步改好、下一步改崩 --- SpreadsheetBench 上 TextGrad 只做到 31.3。
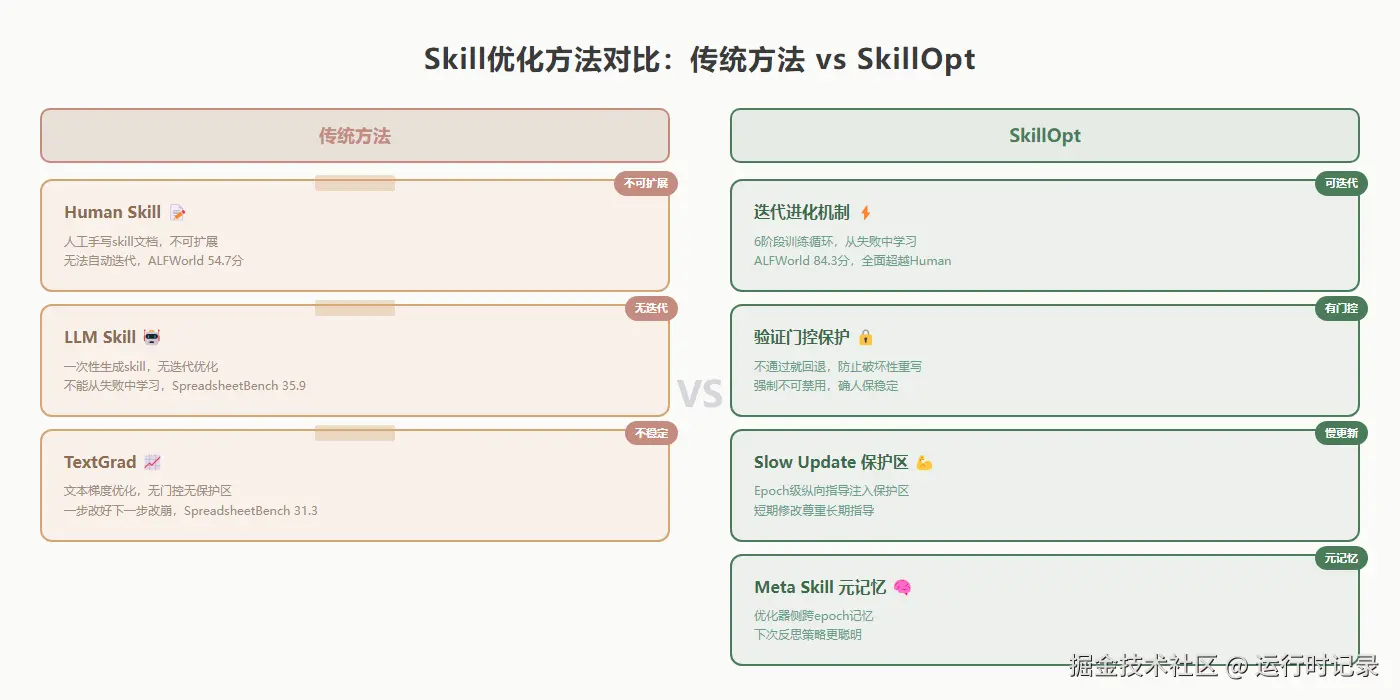
这三种方案不是"烂" --- 它们在各自的设计范围内都有道理。Human skill 在稳定场景下是够用的,LLM skill 在不需要迭代时是快速的,TextGrad 在探索文本优化的可能性。但当你需要持续进化的技能 --- 一个能在失败中学习、在成功中巩固、在跨 epoch 中积累经验的技能 --- 它们都遇到了场景性的瓶颈。
技术诞生:从"训练模型"到"训练文档"
SkillOpt 的诞生不是突然跳出来的。它来自一个清晰的推导链:
模型权重不能改 → 但模型行为必须能改 → 行为由 skill 文档驱动 → skill 文档是自然语言 → 自然语言可以被 LLM 编辑 → 那就让 skill 文档像权重一样经历"训练循环"。
这个推导的核心转折点是:把"训练"这个动作从权重空间搬到文本空间。神经网络训练的前向传播 + 反向传播 + 梯度裁剪 + 验证集评估,每一步都有一个文本空间的对应物。这不是比喻游戏 --- 它是结构映射。Rollout 对应前向传播(用当前 skill 在环境中执行),Reflect 对应反向传播(分析失败轨迹生成"文本梯度"),Aggregate 对应梯度聚合(合并多个 minibatch 的 patch),Select 对应梯度裁剪(排序裁剪 edits),Update 对应参数更新(将 edits 应用到 skill 文档),Evaluate 对应验证集评估(纯决策函数,accept 或 reject)。再加上 Slow Update 对应 epoch 级纵向修正,Meta Skill 对应优化器状态记忆 --- 一套完整的训练隐喻被忠实映射到了文本空间。
核心洞见:Skill 不是模型的附属品,它是可训练的"权重" ---只不过权重是 markdown 而不是 float32。
项目长什么样
SkillOpt 是一个 Python 库 + CLI 工具。你通过 skillopt-train 命令启动训练,它读取 YAML 配置,在 6 个 benchmark 环境上迭代优化 skill 文档,最终产出进化后的 markdown skill 文件。技术栈:Python,核心依赖 openai(LLM 后端)、pyyaml(配置加载)、numpy(分数统计)、azure-identity(认证)。辅助依赖包括 alfworld(仿真环境)、claude-agent-sdk(Claude 后端)、vllm(本地推理)、gradio(WebUI 仪表盘)。
 目录结构映射了训练隐喻:
目录结构映射了训练隐喻:
| 目录 | 角色 | 对应的 NN 训练概念 |
|---|---|---|
skillopt/engine/ |
管线编排 | Training loop runner |
skillopt/gradient/ |
梯度计算 | Backward pass |
skillopt/optimizer/ |
参数更新 | Optimizer (SGD/Adam 等) |
skillopt/evaluation/ |
验证门控 | Validation evaluation |
skillopt/model/ |
LLM 后端 | GPU / compute |
skillopt/envs/ |
环境适配器 | Dataset loader + task env |
skillopt/datasets/ |
数据加载 | Data pipeline |
skillopt/prompts/ |
提示词 | Loss function template |
skillopt/utils/ |
工具 | Utils |
skillopt/config.py |
配置引擎 | Hyperparameters |
skillopt/types.py |
类型系统 | Tensor shapes |
scripts/ |
CLI 入口 | Training script |
configs/ |
配置文件 | Config files |
skillopt_webui/ |
可视化 | TensorBoard |
项目规模中等偏大 --- 核心管线模块约 15 个文件,6 个 benchmark 环境适配器,加上 WebUI 和配置系统。这不是一个周末 hack,是一个完整的训练框架。
它能做什么
SkillOpt 有六个核心能力,按功能域分组:
训练管线域 --- ReflACT 训练循环 (skillopt/engine/trainer.py:516)。6 阶段迭代:Rollout → Reflect → Aggregate → Select → Update → Evaluate。每一步接收上一步输出,epoch 级追加 Slow Update 和 Meta Skill。
梯度计算域 --- Minibatch Reflect (skillopt/gradient/reflect.py:438) 和层级化 Aggregate (skillopt/gradient/aggregate.py:143)。前者批量分析轨迹发现跨轨迹共同模式,后者 MapReduce 式并行合并多 minibatch 的 patch 建议。
参数更新域 --- Skill Edit (skillopt/optimizer/skill.py)、Gradient Clipping (skillopt/optimizer/clip.py)、Rewrite (skillopt/optimizer/rewrite.py)、Slow Update (skillopt/optimizer/slow_update.py:302)、Meta Skill (skillopt/optimizer/meta_skill.py:33)、LR Scheduler (skillopt/optimizer/scheduler.py)、Autonomous LR (skillopt/optimizer/lr_autonomous.py)。三种更新模式(patch / rewrite_from_suggestions / full_rewrite_minibatch),四种 LR 策略(constant / linear / cosine / autonomous)。
验证门控域 --- Validation Gate (skillopt/evaluation/gate.py:31)。3-way 比较:candidate > current AND > best → accept_new_best;> current → accept;否则 → reject。强制不可禁用。
环境适配域 --- EnvAdapter ABC + 6 个 benchmark 实现(ALFWorld、SearchQA、WebShop、SpreadsheetBench、LiveMath、MATH)+ scaffold 模板。可插拔扩展。
基础设施域 --- 配置引擎(YAML + _base_ 继承)、数据加载(BaseDataLoader/SplitDataLoader)、LLM 后端(多路由 + optimizer/target 分离)、WebUI(Gradio 仪表盘)。
这些功能构成两条完整管线:主训练循环(6 阶段 step 级迭代)和 epoch 级慢更新(Slow Update + Meta Skill 纵向修正)。
它怎么做到的
ReflACT 训练循环:6 阶段管线

整个训练循环从 ReflACTTrainer.train (skillopt/engine/trainer.py:516) 启动。每一步走完 6 个阶段,然后 epoch 级追加 Slow Update 和 Meta Skill。调用链:
less
train(trainer.py:516) →
① Rollout: adapter.rollout → list[RolloutResult]
② Reflect: run_minibatch_reflect(reflect.py:438) → list[RawPatch]
③ Aggregate: merge_patches(aggregate.py:143) → merged Patch
④ Select: rank_and_select(clip.py:25) / decide_autonomous_learning_rate → ranked Patch
⑤ Update: apply_patch_with_report(skill.py:128) → candidate_skill (str)
⑥ Evaluate: evaluate_gate(gate.py:31) → GateResult① Rollout --- 用当前 skill 在环境中执行任务。adapter.rollout 把 skill 注入到 LLM prompt,模型在 benchmark 环境中完成任务,输出 RolloutResult(包含 hard score、soft score、turn 数、失败原因)。这一步是"前向传播" --- 用当前"权重"跑一遍任务。
② Reflect --- 分析轨迹生成"文本梯度"。run_minibatch_reflect 把多条轨迹批量格式化,让 analyst LLM 发现跨轨迹的共同模式。失败轨迹和成功轨迹分别分析,输出 RawPatch(包含 edits 建议 + 来源标记)。核心数据变换在 fmt_minibatch_trajectories (reflect.py:108) --- 多条轨迹合并为一次 LLM 输入,让 analyst 不只看单个失败,而是看"这些任务都犯了什么共同的错"。
③ Aggregate --- 层级化合并 patch。merge_patches 采用 MapReduce 模式:failure patches 和 success patches 分别自底向上逐层合并,最终 failure-first 合并。核心是 _hierarchical_merge (aggregate.py:70) --- while 循环每轮按 batch_size 切分 patch 为批次,ThreadPoolExecutor 并行 _merge_batch,直到只剩 1 个。
④ Select --- 排序裁剪 edits。rank_and_select 用 LLM 排序 edits 按重要性,然后按 learning rate(即每步最多允许多少 edits)裁剪。也可以用 autonomous learning rate 让模型自己决定这步该改多少。
⑤ Update --- 将 edits 应用到 skill 文档。核心逻辑在 _apply_edit_with_report (skill.py:48) --- 5 种字符串操作:append(追加到末尾)、insert_after(在指定文本后插入)、replace(替换指定文本)、delete(删除指定文本)、和 slow_update 区域保护。最后一种很关键 --- step 级的 edits 不能修改 Slow Update 保护区(<!-- SLOW_UPDATE_START --> 到 <!-- SLOW_UPDATE_END --> 之间的内容)。短期修改尊重长期指导。
⑥ Evaluate --- 验证门控决策。evaluate_gate (gate.py:31) 是纯函数 --- 比较 candidate hard score、current hard score、best hard score,三路决策。candidate > current AND > best → accept_new_best(同时更新 current 和 best);candidate > current → accept(只更新 current);否则 → reject(什么都不改)。这个 gate 强制不可禁用 --- 配置 use_gate=false 直接 raise ValueError。设计哲学:没有验证的优化是不负责任的优化。
Minibatch Reflect:发现跨轨迹模式
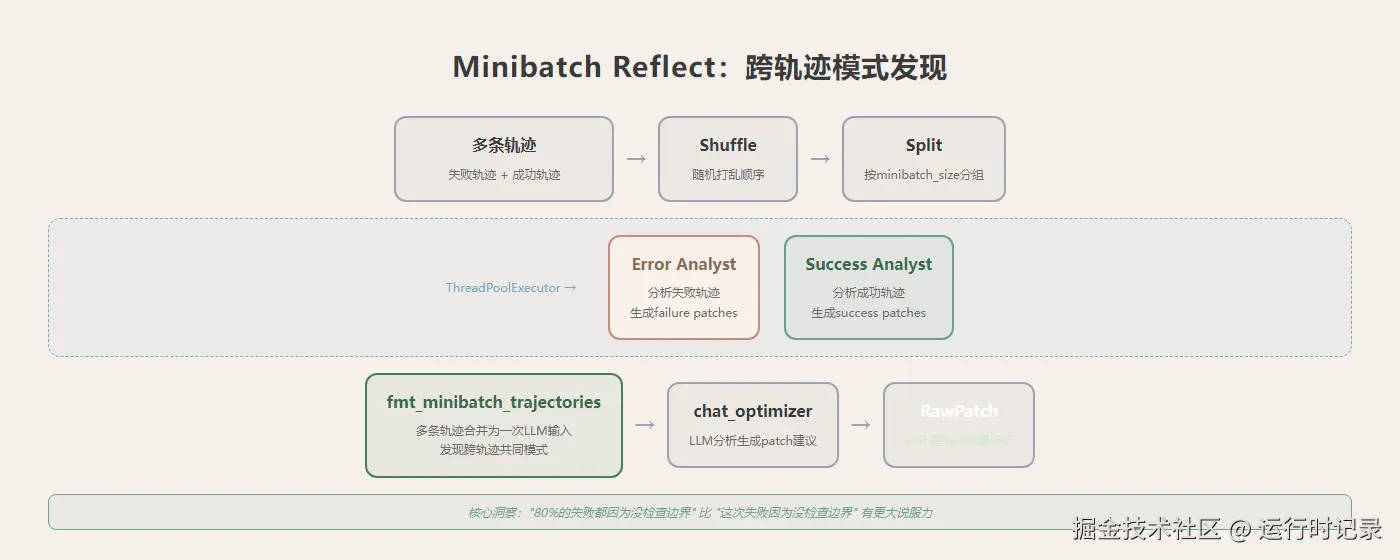 Reflect 阶段不是逐条分析每条失败轨迹。run_minibatch_reflect (
Reflect 阶段不是逐条分析每条失败轨迹。run_minibatch_reflect (reflect.py:438) 先 shuffle 再按 minibatch_size 分组,每组多条轨迹合并为一次 LLM 输入。ThreadPoolExecutor 并行跑 error_analyst 和 success_analyst。核心变换在 fmt_minibatch_trajectories (reflect.py:108) --- 不是一条一条喂给 LLM,而是把多条轨迹拼成一段文本,让 analyst 看到模式:"80% 的失败都因为没检查边界条件"比"这次失败因为没检查边界条件"有更大说服力。
Slow Update + Meta Skill:epoch 级纵向优化
每步的 6 阶段是横向迭代 --- 改一版 skill,看分数变了没有。但 skill 的进化不只是横向的。相邻 epoch 的 skill 在同样本上的表现对比,能揭示更深层的规律:哪些错误是旧版犯的而新版修好了(improved)、哪些是新版新犯的(regressed)、哪些一直犯(persistent_fail)、哪些一直没问题(stable_success)。
 Slow Update (
Slow Update (slow_update.py:302) 是 target-facing guidance --- 给 skill 本身写指导。build_comparison_pairs (slow_update.py:152) 把前版和现版 skill 在同样本上的表现分四类(improved / regressed / persistent_fail / stable_success),然后 LLM 分析这些对比,输出一段纵向指导文本,注入到 skill 文档的 <!-- SLOW_UPDATE --> 保护区域。Step 级 edits 不能修改这个区域 --- 短期修改尊重长期指导。
Meta Skill (meta_skill.py:33) 是 optimizer-facing memory --- 不修改 skill 本身,而是从纵向对比中提炼优化器指导。输出写入独立 JSON 文件,被 format_meta_skill_context 渲染为 prompt 上下文块,供下一步 Reflect/Aggregate/Select 的 optimizer 消费。相当于优化器有了"上次我犯了什么错、什么策略有效"的记忆。
两条链的关键差异:
- Slow Update 输出写入 skill 文档保护区(target-facing),Meta Skill 输出写入独立 JSON(optimizer-facing)
- Slow Update 在 epoch >= 2 时必执行,Meta Skill 需额外配置 use_meta_skill=True
- Slow Update 的内容会被后续 rollout 读到(影响模型行为),Meta Skill 的内容只被 optimizer 读到(影响优化策略)
数据流向
SkillOpt 有三条数据管线:
主管线(每步 6 阶段):
scss
YAML config → load_config(config.py:244) → flat dict → ReflACTTrainer.train(trainer.py:516)
BatchSpec → adapter.rollout → list[RolloutResult]
→ adapter.reflect → list[RawPatch]
→ _normalise_patches → failure + success patches
→ merge_patches → merged Patch
→ rank_and_select → ranked Patch
→ apply_patch_with_report → candidate_skill (str)
→ evaluate_gate → GateResult
→ accept/reject → 更新 current_skill / best_skillEpoch 级慢更新管线:
scss
prev_skill + curr_skill + sample items
→ adapter.rollout(prev) + adapter.rollout(curr)
→ build_comparison_pairs → 4类(improved/regressed/persistent_fail/stable_success)
→ run_slow_update → dict(reasoning, slow_update_content)
→ replace_slow_update_field → updated_skill (注入保护区)数据加载管线:
bash
YAML/JSONL → load_raw_items → list[dict]
→ ratio split + shuffle → train/val/test
→ plan_train_epoch → list[BatchSpec] 核心数据结构扮演不同角色:BatchSpec 是输入载体(批次请求规格),RolloutResult 是中间状态(单个任务执行结果),Edit/Patch/RawPatch 是中间状态(编辑建议),GateResult 是最终输出(门控决策),SlowUpdateResult 是最终输出(epoch 级慢更新结果)。数据从 YAML 配置流入,经过 6 阶段变换,最终产出 accept 或 reject 的决策 --- 如果 accept,candidate skill 成为新的 current skill;如果 reject,什么都不改。
核心数据结构扮演不同角色:BatchSpec 是输入载体(批次请求规格),RolloutResult 是中间状态(单个任务执行结果),Edit/Patch/RawPatch 是中间状态(编辑建议),GateResult 是最终输出(门控决策),SlowUpdateResult 是最终输出(epoch 级慢更新结果)。数据从 YAML 配置流入,经过 6 阶段变换,最终产出 accept 或 reject 的决策 --- 如果 accept,candidate skill 成为新的 current skill;如果 reject,什么都不改。
Skill 文档本身以 markdown 文件形式持久化,带版本号 skill_vXXXX.md。这是另一个关键设计决策:人可读比二进制格式重要。你随时可以打开 skill 文件看到它在说什么,直接手动修改也行 --- 它就是一个 markdown 文件,只不过这个文件在被自动训练。
项目评价
做得好的:
训练隐喻的一致性是我最欣赏的设计。不是随便用了几个术语凑个类比 --- 每个 NN 训练概念都有忠实的文本空间映射,而且映射后的实现是完整可运行的。Rollout 真的是"前向传播"(用当前参数跑任务),Reflect 真的是"反向传播"(分析失败生成修改建议),Gate 真的是"验证集评估"(不通过就 reject)。这不是概念包装,是结构映射。
Optimizer/Target backend 分离也很聪明。optimizer 用推理分析力强的模型(比如 GPT-5.x)来分析轨迹、生成 edits,target 用任务执行力强的模型来实际执行任务。反思和执行需要不同能力 --- 让同一个模型既做反思又做执行,就像让一个人同时当教练和选手。
Gate 强制不可禁用是最让我信服的设计决策。没有验证的优化就是瞎改 --- 可能一步改好、下一步改崩。Gate 确保只有确实变好了才 accept,否则 reject 回退。这不是限制,是保护。
还不够的:
全项目没有任何测试。 这是最大风险。6 阶段管线、3 种更新模式、4 种 LR 策略、epoch 级慢更新 --- 这么多路径组合,零测试意味着每个组合只靠手动验证。_apply_edit_with_report 的 5 种字符串操作出了边界 case 你不会知道,直到生产环境里 silently skip。
Skill patch 依赖字符串精确匹配。 replace 和 delete 操作的 target 必须字面出现在 skill 文档中。如果 LLM 生成的 edit 里 target 字符串有一点点偏差 --- 多一个空格、少一个换行 --- 操作就 silently skip,没有任何日志告诉你它跳过了。这在真实使用中是高频失败点。
Optimizer backend 只支持 openai_chat 和 claude_chat。 不支持 qwen/codex。如果你用本地模型跑 target,optimizer 还得走 API --- 这对成本和延迟都有影响。
可配置的能力边界:
| 配置项 | 默认值 | 作用 |
|---|---|---|
train.num_epochs |
4 | 训练 epoch 数 |
train.batch_size |
40 | 每 step 样本数 |
optimizer.learning_rate |
4 | 每 step 最多 edits 数 |
optimizer.lr_scheduler |
cosine | 编辑预算调度策略 |
optimizer.skill_update_mode |
patch | skill 更新方式(patch/rewrite) |
optimizer.use_slow_update |
true | 是否启用 epoch 级纵向更新 |
optimizer.use_meta_skill |
true | 是否启用 optimizer 端元技能记忆 |
gradient.minibatch_size |
8 | 反思 minibatch 大小 |
evaluation.use_gate |
true(不可设 false) | 验证门控 |
SkillOpt 适合的场景:你有一个冻结模型,需要让它在某个具体任务域上持续进化表现,不想微调权重,有 API 预算跑 optimizer。不适合的场景:你需要完全本地化运行(optimizer 必须走 API)、你需要保证每次 patch 都成功应用(字符串匹配可能 silently skip)、你需要确定性输出(LLM 生成 edits 本身是非确定性的)。
说实话,SkillOpt 的想法让我兴奋。不是因为它的实现已经完美 --- 缺测试、字符串匹配脆弱、backend 支持不够广。而是因为把自然语言文档当作可训练权重这件事,终于有人做得够完整了。从 Rollout 到 Reflect 到 Gate 到 Slow Update 到 Meta Skill,每一步都有实际代码、有真实 benchmark 数据、有明确的设计决策。这不是概念 demo,是一个可以跑的框架。
6 个 benchmark 上全面超越 Human skill --- 不是因为 skill 文档更"聪明",而是因为 skill 文档进化了。从失败中学习、从成功中巩固、在跨 epoch 中积累纵向指导 --- 这是手动写提示词做不到的。
如果你也在纠结"怎么让冻结模型在具体任务上更好",去 SkillOpt 看看。跑一个 benchmark,看你的 skill 文档在几轮训练后怎么变化。你可能也会像我一样,觉得训练文档这件事终于有了靠谱的框架。