文章目录
- [1. White Box / Structural Testing(白盒测试 / 结构测试)](#1. White Box / Structural Testing(白盒测试 / 结构测试))
-
- [1.1 白盒测试的特点](#1.1 白盒测试的特点)
- [1.2 Program Graphs / Control Flow Graph(程序图 / 控制流图)](#1.2 Program Graphs / Control Flow Graph(程序图 / 控制流图))
-
- [1.2.1 程序图 / 控制流图的 4 种基本结构](#1.2.1 程序图 / 控制流图的 4 种基本结构)
- [1.2.2 示例 1](#1.2.2 示例 1)
- [1.2.3 DD-Path](#1.2.3 DD-Path)
-
- [1.2.3.1 DD-Path 的正式定义](#1.2.3.1 DD-Path 的正式定义)
- [1.2.3.2 DD-Path Graph(DD 路径图)](#1.2.3.2 DD-Path Graph(DD 路径图))
- [1.2.3.3 示例 1](#1.2.3.3 示例 1)
- [1.2.4 Test Coverage Metrics(测试覆盖率指标)](#1.2.4 Test Coverage Metrics(测试覆盖率指标))
-
- [1.2.4.1 E.F. Miller's Test Coverage Metrics(Miller 提出的测试覆盖率指标)](#1.2.4.1 E.F. Miller’s Test Coverage Metrics(Miller 提出的测试覆盖率指标))
- [1.2.4.2 Statement Coverage Testing(语句覆盖测试) 和 Predicate Coverage Testing(谓词/分支/判定覆盖测试)](#1.2.4.2 Statement Coverage Testing(语句覆盖测试) 和 Predicate Coverage Testing(谓词/分支/判定覆盖测试))
- [1.2.4.3 DD-Path Graph Edge Coverage C₁](#1.2.4.3 DD-Path Graph Edge Coverage C₁)
- [1.2.4.4 DD-Path Coverage Testing C₁P](#1.2.4.4 DD-Path Coverage Testing C₁P)
- [1.2.4.5 Multiple Condition Coverage Testing(多条件覆盖测试)](#1.2.4.5 Multiple Condition Coverage Testing(多条件覆盖测试))
- [1.2.4.6 Dependent DD-Path Pairs Coverage Testing C d C_d Cd(依赖 DD-Path 对覆盖测试)](#1.2.4.6 Dependent DD-Path Pairs Coverage Testing C d C_d Cd(依赖 DD-Path 对覆盖测试))
- [1.2.4.7 Loop Coverage(循环覆盖测试)](#1.2.4.7 Loop Coverage(循环覆盖测试))
- [1.2.4.8 示例 2](#1.2.4.8 示例 2)
- [1.2.5 McCabe's Basis Path Testing(McCabe 基本路径测试)](#1.2.5 McCabe’s Basis Path Testing(McCabe 基本路径测试))
-
- [1.2.5.1 Compute the program graph(画程序图 / 控制流图)](#1.2.5.1 Compute the program graph(画程序图 / 控制流图))
- [1.2.5.2 Calculate the cyclomatic complexity(计算圈复杂度)](#1.2.5.2 Calculate the cyclomatic complexity(计算圈复杂度))
- [1.2.5.3 Select a basis set of paths(选择一组基本路径)](#1.2.5.3 Select a basis set of paths(选择一组基本路径))
- [1.2.5.4 McCabe 基本路径法的局限](#1.2.5.4 McCabe 基本路径法的局限)
- [1.3 指导方针和观察结果](#1.3 指导方针和观察结果)
1. White Box / Structural Testing(白盒测试 / 结构测试)
白盒测试也叫:
| 英文 | 中文意思 |
|---|---|
| Glass box testing | 玻璃盒测试 |
| Structural testing | 结构测试 |
| Clear box testing | 透明盒测试 |
| Open box testing | 开放盒测试 |
测试人员可以看到程序内部结构和代码。
白盒测试是一种利用程序内部工作原理来设计测试数据的方法。
黑盒测试主要根据需求说明书来测试输出。
白盒测试是根据源代码的具体知识来定义测试用例,并检查输出。
1.1 白盒测试的特点
- Rigorous Definitions(定义更严格、更精确):在白盒测试中,测试人员知道软件内部逻辑,包括代码、算法和数据结构,所以可以更精确地定义要测试什么、怎么测试。
- Mathematical Analysis(可以进行数学分析):程序内部结构可以用数学方式表示,比如图、树、矩阵等。
- Useful Measurement(可以得到有用的度量指标):白盒测试可以收集很多关于代码质量的指标。
1.2 Program Graphs / Control Flow Graph(程序图 / 控制流图)
白盒测试一般都会先把代码画成程序图 / 控制流图,然后基于这个图做后面的分析和测试。
程序图是一种有向图。
也叫做控制流图。
如果程序图中有两个节点 i 和 j,那么只有在这种情况下,才会有一条从 i 指向 j 的边:节点 j 对应的语句,可以在节点 i 对应的语句之后立刻执行。
简单来说就是:如果程序执行完 i 后,下一步可能马上执行 j,那么图里就画一条 i → j 的箭头。
所以程序图就是把代码内部的执行流程画成一个有向图:节点表示语句,箭头表示执行顺序,用来帮助白盒测试分析所有可能路径是否都被测试到。
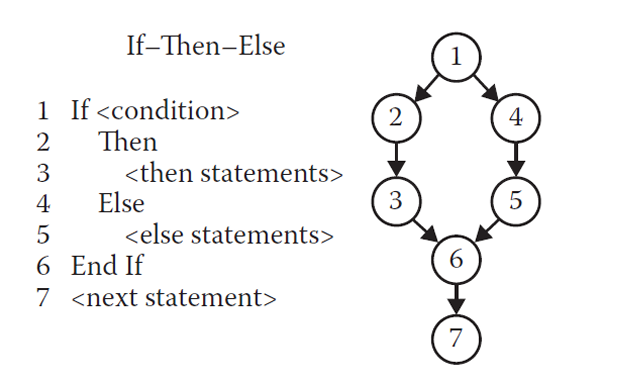
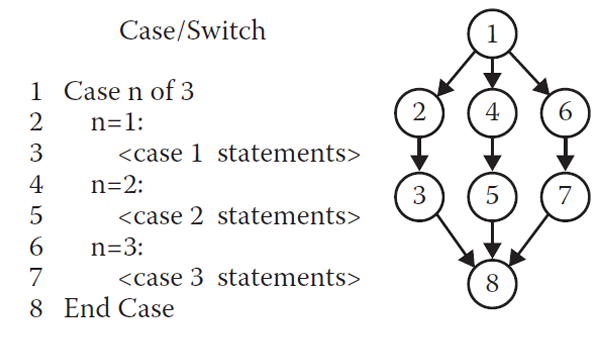
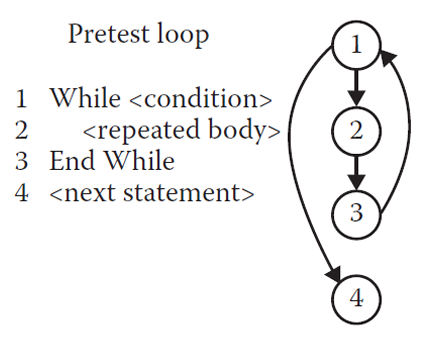
1.2.1 程序图 / 控制流图的 4 种基本结构
- If-Then-Else 结构
- Case / Switch 结构
- Pretest loop 前测试循环(While 循环)
先判断条件,再决定要不要执行循环体。
- Posttest loop 后测试循环(do-until / do-while 循环)
先执行循环体,再判断条件。
我们从这 4 个结构可以看出,node 代表的是一条可执行语句,或者一个语句片段 / 语句块,但并不严格等于代码的一行。例如程序声明、变量定义都不是真正的控制流程判断或主要执行步骤。
如下面的例子所示。
1.2.2 示例 1
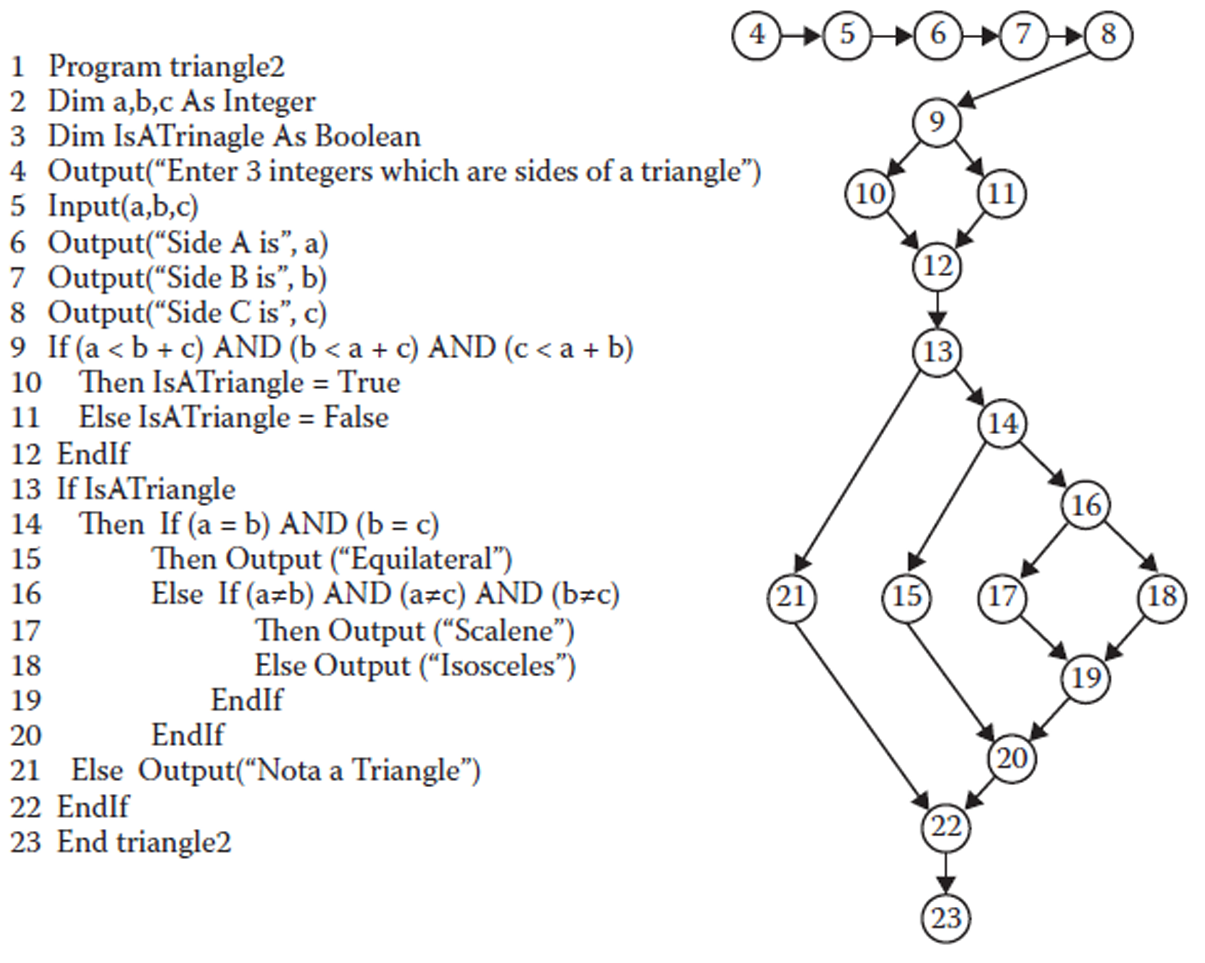
这是我们上一章举的判断三角形的那个例子。
| 图中节点 | 对应代码 |
|---|---|
| 4 | 输出提示语 |
| 5 | 输入 a, b, c |
| 6 | 输出 Side A |
| 7 | 输出 Side B |
| 8 | 输出 Side C |
| 9 | 判断三角形不等式 |
| 10 | IsATriangle = True |
| 11 | IsATriangle = False |
| 13 | 判断 IsATriangle |
| 14 | 判断是否等边 |
| 15 | 输出 Equilateral |
| 16 | 判断是否不等边 |
| 17 | 输出 Scalene |
| 18 | 输出 Isosceles |
| 21 | 输出 Not a Triangle |
| 23 | 程序结束 |
这里不可执行语句不会放进程序图里。
节点 4 到 8 是顺序结构(sequence)。
节点 9 到 12 是一个 if-then-else 结构。
节点 13 到 22 是嵌套的 if-then-else 结构。
节点 4 是程序图的起点(indeg=0,in-degree,入度)。
节点 23 是程序图的终点(outdeg=0,out-degree,出度)。
这个程序图没有循环,所以它是一个有向无环图。
1.2.3 DD-Path
最著名的一种结构测试方法,是基于一种叫做"decision-to-decision path"的结构,因此简称 DD-Path。
DD-Path 是从程序图 / 控制流图中提取出来的一段路径。
它不是完整程序路径,而是控制流图中的一小段,因此是控制流图的子路径。
它是控制流图中从一个决策节点(decision node)到另一个决策节点,或者从决策节点到结束节点(terminal node)的一段子路径。
1.2.3.1 DD-Path 的正式定义
从控制流图中抽出来的一段路径,用来简化程序图。
Case 1:如果一个节点入度为 0,它单独可以成为一个 DD-Path(indeg = 0)。
Case 2:如果一个节点出度为 0,它单独可以成为一个 DD-Path(outdeg = 0)。
Case 3:如果一个节点有多个入口,或者多个出口,它也可以单独作为一个 DD-Path(indeg ≥ 2 or outdeg ≥ 2)。
Case 4:如果一个节点只有一个入口和一个出口,它也可能作为单个 DD-Path(indeg = 1 and outdeg = 1)。
Case 5:一段尽可能长的连续路径,也可以作为一个 DD-Path(maximal chain of length ≥ 1)。
或者如下表所示,只要某一段路径符合其中一种情况,它就可以被看作一个 DD-Path。
| Case | 含义 | 是否可以单独算一个 DD-Path |
|---|---|---|
| Case 1 | 入度为 0 的入口节点 | 可以 |
| Case 2 | 出度为 0 的结束节点 | 可以 |
| Case 3 | 分支节点或汇合节点,入度 ≥ 2 或出度 ≥ 2 | 可以 |
| Case 4 | 普通节点,入度 = 1,出度 = 1 | 可以 |
| Case 5 | 一段连续的最大路径链 | 可以 |
1.2.3.2 DD-Path Graph(DD 路径图)
DD-Path Graph 是一个有向图。
但它和普通程序图不同:
| 图 | 节点代表什么 |
|---|---|
| Program Graph / Control Flow Graph | 节点是代码语句或语句片段 |
| DD-Path Graph | 节点是 DD-Path |
也就是说,DD-Path Graph 的节点不是单行代码,而是一段路径。
图中的边 / 箭头表示 DD-Path 之间的控制流关系。
也就是说,如果程序执行完一个 DD-Path 后,可能接着执行另一个 DD-Path,那么它们之间就有一条箭头。
我们可以这样理解:
我们第一步将代码化成程序图。
第二步可以把程序图中的连续路径合并成 DD-Path。
第三步再把这些 DD-Path 当作节点,画成更简单的 DD-Path Graph。
所以整体关系是:源代码 → Control Flow Graph → DD-Path → DD-Path Graph
1.2.3.3 示例 1
我们回到我们之前的示例,我们现在可以按照刚刚说的把CFG(Control Flow Graph,控制流图)转换成 DD-Path Graph(决策到决策路径图)。
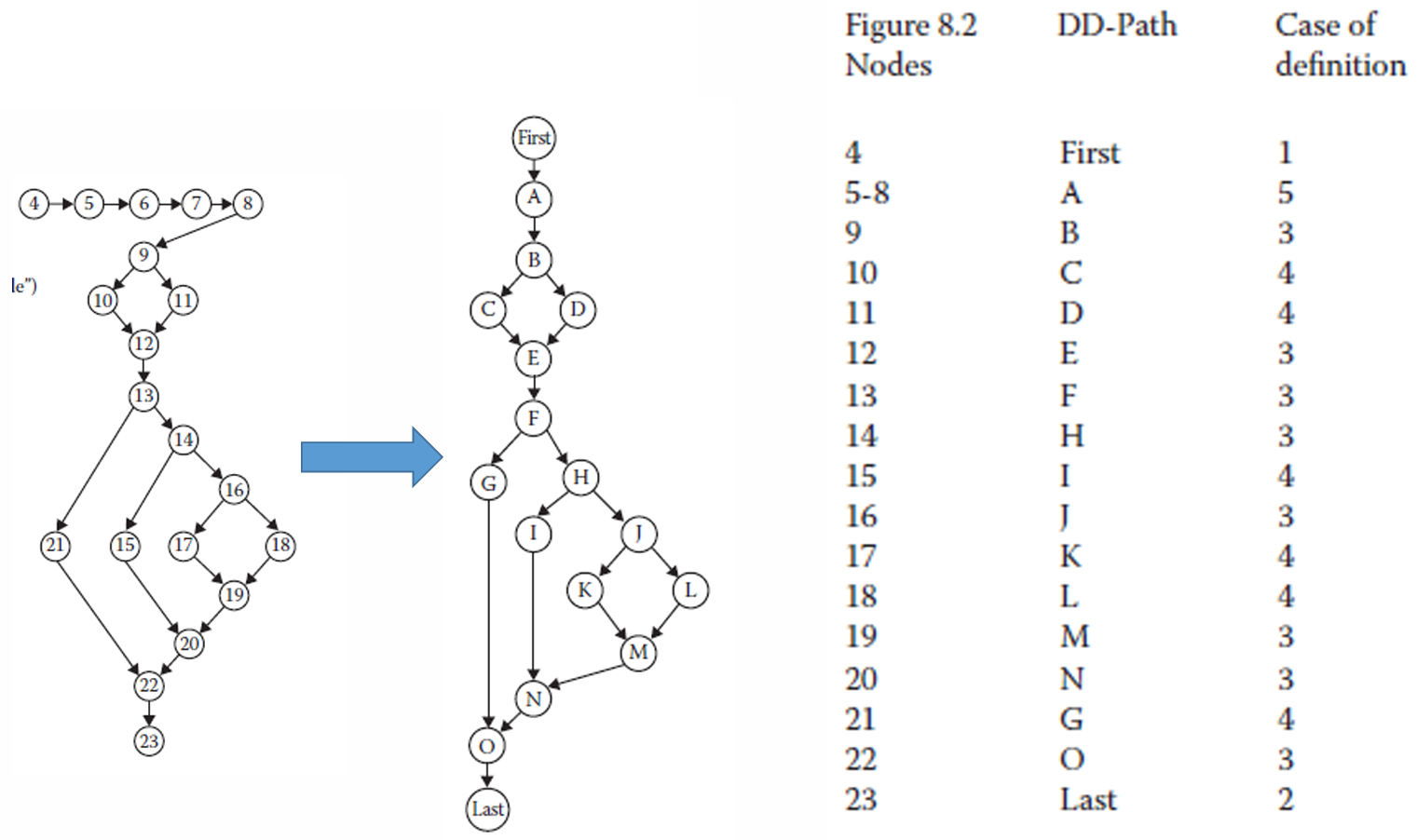
这里把原始控制流图 CFG 中的节点按照 DD-Path 规则进行合并和命名,得到一个更简化的 DD-Path Graph;右边表格说明每个 DD-Path 对应原控制流图中的哪些节点,以及它属于 DD-Path 定义中的哪一种情况。
1.2.4 Test Coverage Metrics(测试覆盖率指标)
使用 DD-Path 的原因,是它可以非常精确地描述测试覆盖情况。
只看需求说明(也就是上一章讲的黑盒测试),很难知道测试用例到底覆盖了程序内部多少代码。
重复测试(Redundancy):
比如我们设计了 10 个测试用例,但它们内部都走同一条程序路径,那就有很多重复。
测试空缺(Gaps):
比如程序里有一条错误处理路径,但是所有测试用例都没有走到它,这就是 gap。
测试覆盖率指标(Test Coverage Metrics)是一种衡量方法,用来判断一组测试用例覆盖了程序的多少部分。
1.2.4.1 E.F. Miller's Test Coverage Metrics(Miller 提出的测试覆盖率指标)
白盒测试中可以用不同层次的覆盖率指标来衡量测试是否充分。
从上到下,覆盖要求一般越来越严格,测试用例数量也可能越来越多。
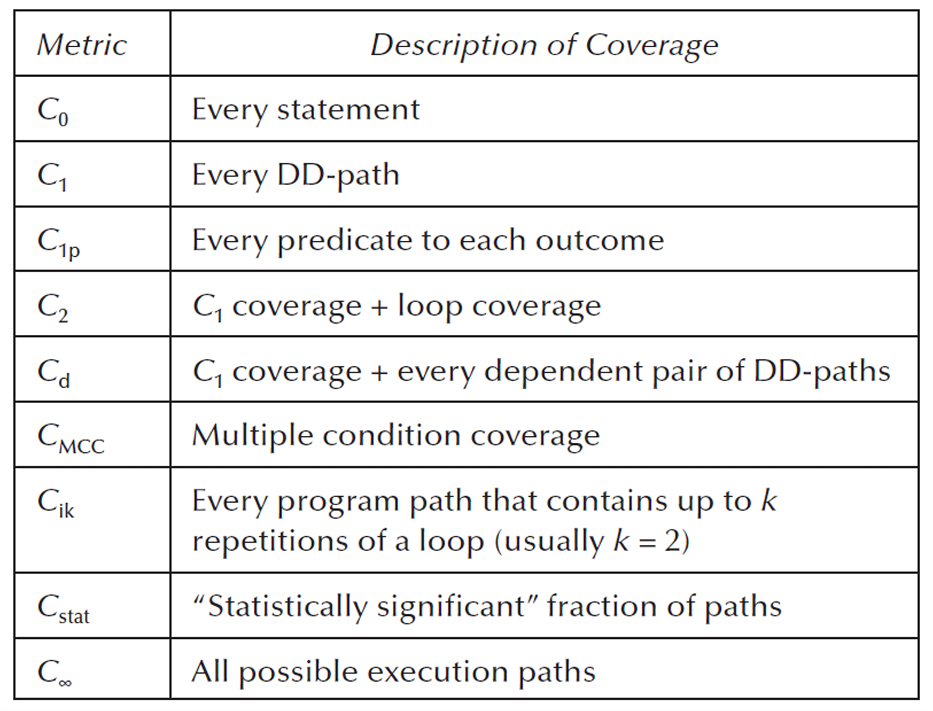
- C₀ :Every statement(语句覆盖)
比如程序里有 20 行可执行代码,测试用例让这 20 行都运行过一次,就满足 C₀。
这是比较基础的覆盖率。 - C₁:Every DD-path(DD-Path 覆盖)
每一条 DD-Path 至少被执行一次。
C₁ 比 C₀ 更强,因为它不仅看语句有没有执行,还关注程序结构中的路径片段有没有覆盖。 - C₁p:Every predicate to each outcome(每个判断条件的每种结果都覆盖)
每个判断条件至少走过 True 和 False 两种结果。 - C₂:C₁ coverage + loop coverage(DD-Path 覆盖 + 循环覆盖)
在 C₁ 的基础上,还要考虑循环。 - C d C_d Cd:C₁ coverage + every dependent pair of DD-paths(DD-Path 覆盖 + 相关 DD-Path 对覆盖)
除了每个 DD-Path 都覆盖,还要覆盖某些有依赖关系的 DD-Path 组合。
也就是说不只看单独路径,还看相邻或相关路径之间的组合关系。 - C M C C C_{MCC} CMCC:Multiple condition coverage(多条件覆盖)
如果一个判断条件里面有多个小条件,要测试这些小条件的组合。 - C i k C_{ik} Cik:Every program path up to k repetitions of a loop(覆盖循环重复 k 次以内的所有路径)
测试所有程序路径,但循环最多只考虑重复 k k k次。 - C s t a t C_{stat} Cstat:Statistically significant fraction of paths(统计上有代表性的路径覆盖)
不测试所有路径,而是选择一部分在统计上有代表性的路径。 - C ∞ C_∞ C∞:All possible execution paths(所有可能执行路径覆盖)
测试程序所有可能的执行路径。
1.2.4.2 Statement Coverage Testing(语句覆盖测试) 和 Predicate Coverage Testing(谓词/分支/判定覆盖测试)
Statement Coverage(语句覆盖)测试的目标是设计一组测试用例,让程序里的每一条语句至少执行一次。
Predicate Coverage(谓词/分支/判定覆盖)也可以叫 Branch Coverage 或 Decision Coverage。
它的目标是让程序中的每个判断条件都至少取一次 True 和一次 False。
这里的判断条件可以是一个简单条件,也可以是一个复合布尔表达式,但把它整体当成一个判断单元。
比如 A or B
虽然里面有 A 和 B 两个小条件,但在 predicate coverage 里,可以把整个 A or B
看成一个整体判断。
它只关心整个表达式最终是 True 还是 False。
因此谓词覆盖相当于让 DD-Path 图里的每一条边都至少走一次。
我们再看一个示例:if (A or B) then C
这里判断条件是:A or B
要让它为 True,可以用:A = True, B = False
要让它为 False,可以用:A = False, B = False
所以这两个测试用例就可以让整个判断表达式分别得到 True 和 False。
1.2.4.3 DD-Path Graph Edge Coverage C₁
C₁ 是在 DD-Path 图中,让每一条边至少被测试走到一次。
也可以理解成前面说的 Predicate Coverage / Branch Coverage / Decision Coverage,每个判断条件的 True 分支和 False 分支都要走一次。
如下图所示例子。
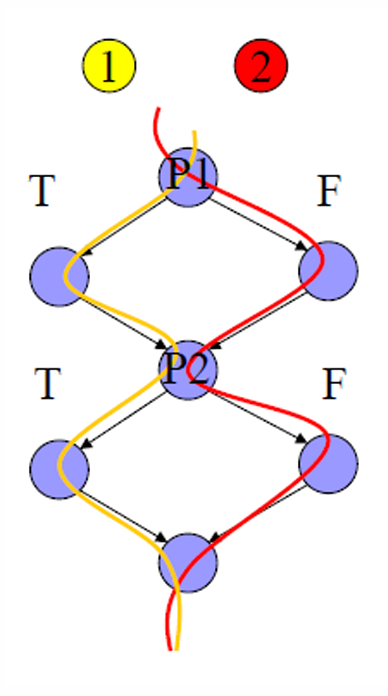
这里用两个测试用例就够了。
| 测试用例 | p1 | p2 |
|---|---|---|
| 1 | T | T |
| 2 | F | F |
所以这里没有测试所有组合,所有组合其实有 4 种:
| p1 | p2 |
|---|---|
| T | T |
| T | F |
| F | T |
| F | F |
1.2.4.4 DD-Path Coverage Testing C₁P
C₁P 是比前面 C₁ 覆盖 更严格的一种覆盖标准。
C₁ / Edge Coverage 只要求每个判断节点的 True 分支和 False 分支都至少走一次。
C₁P 要求 P1 和 P2 的所有真假组合都要测试到。
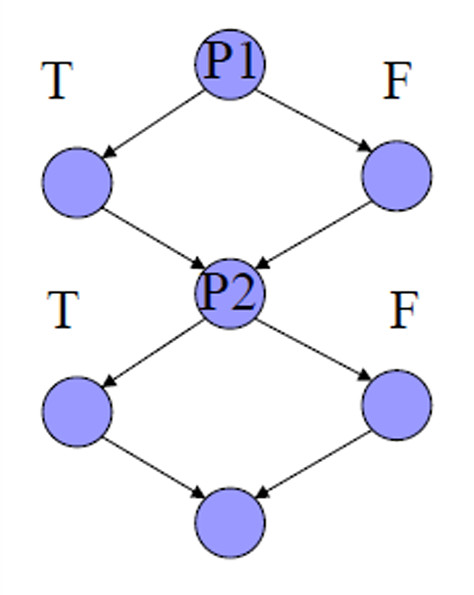
也就是我们刚刚提到的 4 种组合。
| 组合 | P1 | P2 |
|---|---|---|
| 1 | T | T |
| 2 | T | F |
| 3 | F | T |
| 4 | F | F |
1.2.4.5 Multiple Condition Coverage Testing(多条件覆盖测试)
Multiple Condition Coverage Testing(多条件覆盖测试)比 C₁P 更严格。
如果一个判断条件里面有多个小条件,那么测试时要把这些小条件的所有组合都测到。
如果我们刚刚例子中的 P1 是 (A or B)的这种复合布尔表达式。
这里整个判断是 (A or B),只要两种情况,但是里面有两个小条件:A、B。
因此这里组合搭配会有 4 种情况。
| A | B | A or B 的结果 |
|---|---|---|
| True | True | True |
| True | False | True |
| False | True | True |
| False | False | False |
多条件覆盖要求测试就会有 4 个测试用例。
因此Multiple Condition Coverage 不满足于只看整体结果,它还要求 A 和 B 的每种组合都测到,所以要 4 个。
所以这就会导致我们的测试用例呈指数增长。
如果有 n n n个小条件,每个条件都有 True / False 两种可能,那么组合数量就是 2 n 2^n 2n。
1.2.4.6 Dependent DD-Path Pairs Coverage Testing C d C_d Cd(依赖 DD-Path 对覆盖测试)
在简单的 C₁ 覆盖标准 中,我们只关心:
DD-Path 图里的每一条边有没有至少走过一次。
C d C_d Cd测试想进一步增强覆盖要求,不仅测每一条边,还要测试有依赖关系的 DD-Path 对。
因为有些 bug 不是"某一条边没走到"导致的,而是:
前面某个变量赋值之后,后面某个路径使用它时出错。
所以它更容易发现和变量传递、变量使用有关的错误。
如果两个 DD-Path 之间存在"定义 / 引用"关系,那么它们就是依赖的 DD-Path 对。
换句话说,一个 DD-Path 里定义了某个变量,另一个 DD-Path 里使用了这个变量。
比如:
DD1: x = 10
DD2: if x > 0
那么 DD1 和 DD2 就是 dependent DD-Path pair,因为:
DD1 定义 x
DD2 使用 x
所以 C d C_d Cd测试不仅要覆盖 DD-Path 图中的所有边,还要覆盖所有有依赖关系的 DD-Path 对。
因此 C d C_d Cd比 C₁ 更严格。
总结一下,两个 DD-Path 如果一个定义变量、另一个使用这个变量,它们就是 dependent DD-Path pair;C_d 覆盖要求不仅覆盖所有控制流边,还要覆盖这些数据依赖路径,从而发现变量赋值和使用过程中可能出现的错误。
1.2.4.7 Loop Coverage(循环覆盖测试)
如果程序里有循环,测试时不能只随便跑一次,要专门设计测试用例,让循环的不同执行情况都被覆盖。
循环结构一般有三种:
- Concatenated Loop(串联循环):
两个循环前后相连,但互不包含。
类似:
bash
while 条件1:
执行 A
while 条件2:
执行 B
- Nested Loop(嵌套循环):
一个循环里面还有另一个循环。
类似:
bash
while 条件1:
while 条件2:
执行 B
- Knotted Loop(交织循环 / 缠结循环):
循环结构交叉缠在一起,不是简单的前后关系,也不是简单的嵌套关系。
这种循环最复杂,测试也最麻烦,因为路径之间相互交叉。
循环条件本质上也是一个判断,所以测试时至少要覆盖它的两个结果:
| 循环条件结果 | 含义 |
|---|---|
| True | 进入循环 / 继续循环 |
| False | 退出循环 / 不进入循环 |
可以把循环次数当成一个变量,用边界值测试的方法来测。
比如循环最多执行 10 次,那么可以测试:
| 测试情况 | 含义 |
|---|---|
| minimum | 最少次数,比如 0 次 |
| minimum+ | 比最少多一点,比如 1 次 |
| nominal | 正常次数,比如 5 次 |
| maximum- | 接近最大次数,比如 9 次 |
| maximum | 最大次数,比如 10 次 |
如果做 robust testing,还可以测超出范围的情况。
如果是嵌套循环(nested loops),测试时应该先测最里面的循环,然后再逐层向外测。
原因是:内层循环通常会被外层循环反复触发,如果不先搞清楚内层循环是否正确,外层测试会变得很乱。
如果循环是交织循环(knotted loop),也就是交织循环 / 缠结循环,就需要用数据流分析测试方法。
如果两个循环之间有复杂跳转或变量依赖,就不能只靠简单的循环次数覆盖来测,而要分析:变量在哪里被定义?变量在哪里被使用?前一个循环的变量变化会不会影响后一个循环?
因此使用 data flow analysis testing(数据流分析测试)。
1.2.4.8 示例 2
下图展示了一个示例,它展示了语句覆盖 C₀ 和 分支/判定覆盖 C₁ 的区别。
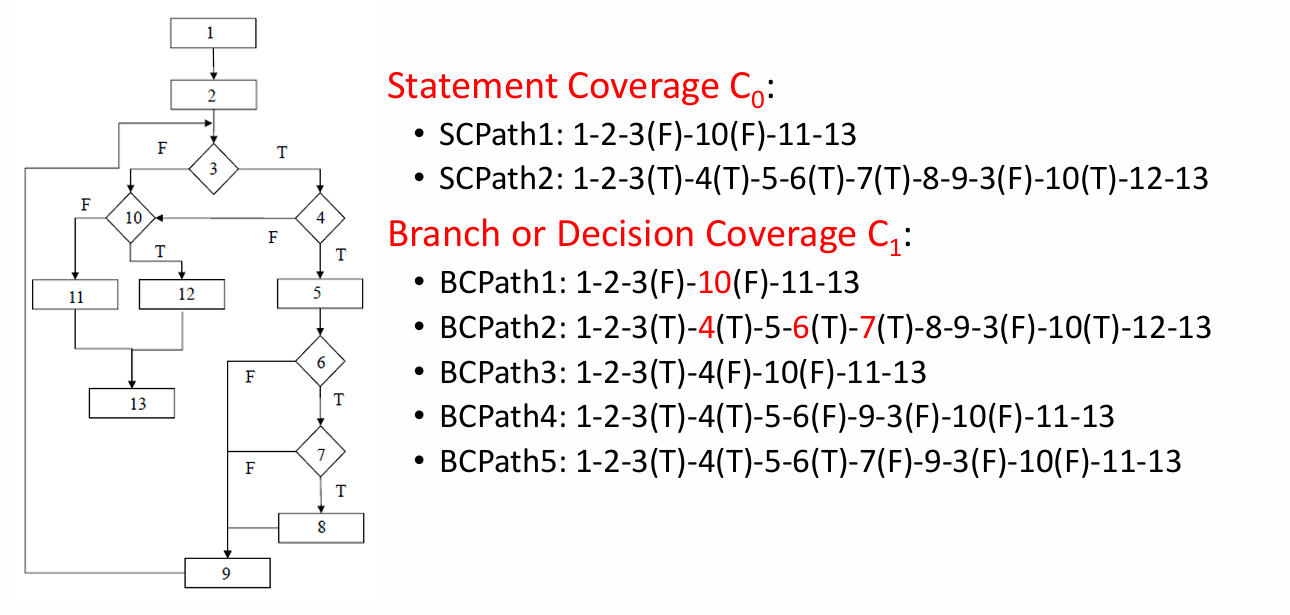
语句覆盖 C₀ 的目标是:
让程序中的每个节点 / 每条语句至少执行一次。
SCPath1: 1-2-3(F)-10(F)-11-13
SCPath2: 1-2-3(T)-4(T)-5-6(T)-7(T)-8-9-3(F)-10(T)-12-13
这两个路径加起来,基本把所有节点都走到了。所以满足 C₀ 语句覆盖。
分支覆盖 / 判定覆盖 C₁ 的目标是:
每个判断节点的 True 和 False 分支都至少走一次。
所以它比 C₀ 更严格。
BCPath1: 1-2-3(F)-10(F)-11-13
BCPath2: 1-2-3(T)-4(T)-5-6(T)-7(T)-8-9-3(F)-10(T)-12-13
BCPath3: 1-2-3(T)-4(F)-10(F)-11-13
BCPath4: 1-2-3(T)-4(T)-5-6(F)-9-3(F)-10(F)-11-13
BCPath5: 1-2-3(T)-4(T)-5-6(T)-7(F)-9-3(F)-10(F)-11-13
这些路径的目的不是单纯执行所有节点,而是为了保证:
| 判断节点 | True 是否测到 | False 是否测到 |
|---|---|---|
| 3 | 有 | 有 |
| 4 | 有 | 有 |
| 6 | 有 | 有 |
| 7 | 有 | 有 |
| 10 | 有 | 有 |
1.2.5 McCabe's Basis Path Testing(McCabe 基本路径测试)
基本路径测试是 Tom McCabe 提出的一种白盒测试方法。
它的核心思想是先计算程序的逻辑复杂度,然后用这个复杂度来确定需要测试多少条基本路径。
常用的复杂度指标叫 Cyclomatic Complexity(圈复杂度)。
圈复杂度表示程序中有多少条相对独立的执行路径。
Basis Path Testing 的四个步骤:
- Compute the program graph(画程序图 / 控制流图)
- Calculate the cyclomatic complexity(计算圈复杂度)
- Select a basis set of paths(选择一组基本路径)
- Generate test cases for each of these paths(为每条路径设计测试用例)
1.2.5.1 Compute the program graph(画程序图 / 控制流图)
要做 McCabe's Basis Path Testing,首先需要一个程序的控制流图或 DD-Path 图,然后才能计算圈复杂度、选择基本路径。
下图是一个示例,这是一个 DD-Path 图。
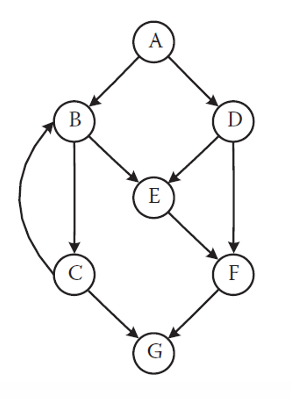
这个程序只有一个入口节点 A,也只有一个出口节点 G。
1.2.5.2 Calculate the cyclomatic complexity(计算圈复杂度)
Cyclomatic Complexit(圈复杂度)表示程序中"线性独立路径"的数量。
路径越多,说明程序逻辑越复杂,需要测试的基本路径也越多。
也可以理解为根据程序中的判断点数量(the number of decisions)来衡量程序逻辑复杂度。
Cyclomatic Complexit(圈复杂度)的计算公式有两个:
V ( G ) = e − n + 2 p V(G) = e - n + 2p V(G)=e−n+2p(普通程序图,有入口和出口)
V ( G ) = e − n + p V(G) = e - n + p V(G)=e−n+p(闭合图,出口连回入口)
其中:
| 符号 | 含义 |
|---|---|
| V(G) | 圈复杂度 |
| e | edges,边的数量,也就是箭头数 |
| n | nodes,节点数量 |
| p | connected regions,连通区域数量 |
一般一个程序图只有一个连通区域,所以:p = 1
我们回到前面的例子。
我们用第一种算法(线性独立路径数量)进行计算。
V(G) = e - n + 2p = 10 - 7 + 2(1) = 5
因此这个程序有 5 条线性独立路径。
我们用第二种算法(线性独立回路数量)进行计算。
这里边数变成了 11,是因为它把原图人为加了一条边:出口节点 → 入口节点
V(G) = e - n + p = 11 - 7 + 1 = 5
因此计算结果仍然是5。
所以这两种公式虽然不同,但是计算结果一致,可以将这里的图进行转换,使普通程序图变为闭合图进行计算。
1.2.5.3 Select a basis set of paths(选择一组基本路径)
线性独立路径就是一条执行路径,这条路径相比之前选过的路径,至少包含一个新的语句块,或者一个新的判断条件结果。
简单说:新路径 = 至少带来一点之前没测过的新东西
McCabe's Baseline Method(基线路径法)是选择基本路径的一种方法。
它的思路是:先选一条正常执行路径作为 baseline path,然后每次改变其中一个判断条件,得到新的路径。
先选择一条 最正常、最典型的程序执行路径。然后每次反转一个判断条件,生成新的独立路径,直到所有需要考虑的分支变化都覆盖到。
下图给出之前的例子中,我们计算出的 5 条线性独立路径怎么使用 McCabe's Baseline Method(基线路径法)选出 5 条线性独立路径。
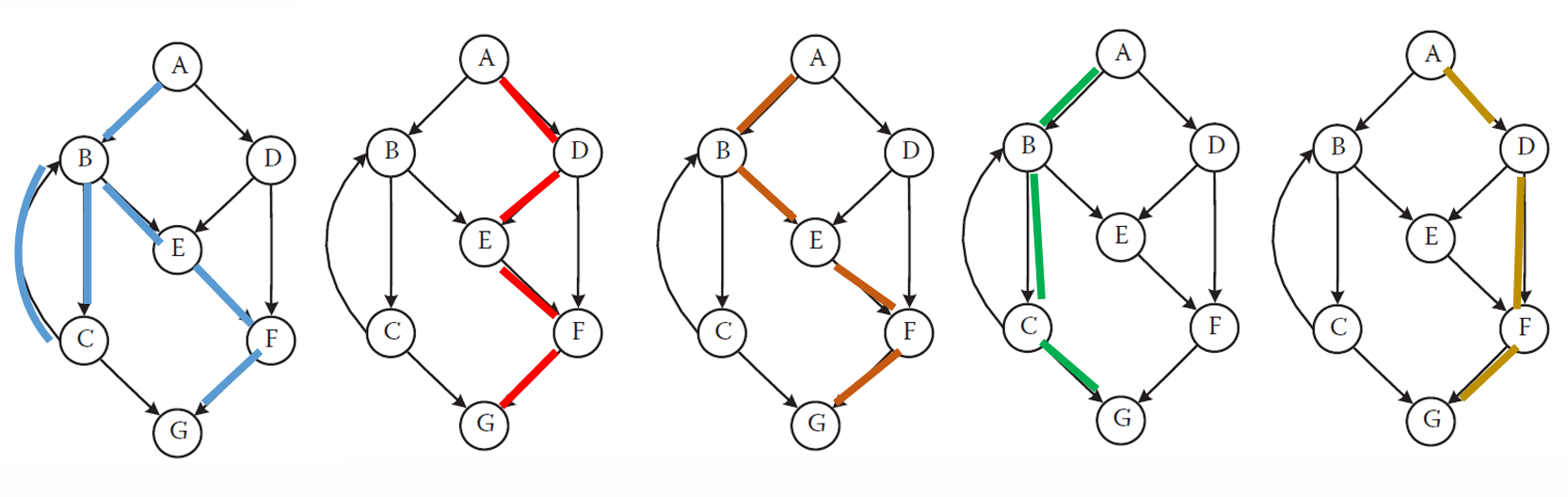
先选一条主路径,然后每次改变一个分支选择,得到新的独立路径。
比如蓝色路径中从 A 走向 B:
A → B
如果把这个选择翻转,就可能走:
A → D
于是得到红色或黄色路径。
再比如蓝色路径中从 B 走向 C:
B → C
如果改成:
B → E
就得到橙色路径:
A → B → E → F → G
再比如在 C 处,原来循环回 B:
C → B
如果改成直接退出到 G:
C → G
就得到绿色路径:
A → B → C → G
我们从这里也可以看出 McCabe 方法算出来的 圈复杂度 V(G)=5,意思不是"程序总共只有 5 条路径",而是这个程序至少有 5 条线性独立路径,需要选 5 条作为基本路径来测试。
McCabe 方法的思想是从很多可能路径中选出一组"基本路径",这些基本路径能够代表程序的主要控制结构。
1.2.5.4 McCabe 基本路径法的局限
McCabe 的基本路径法有两个主要薄弱点。
第一点就是我们刚刚提到的。
- 只要测试了所有基本路径,就足够了。其实不是!(Testing the set of basis paths is sufficient (it is not!))。
这 5 条基本路径只是最基本的覆盖要求,不代表程序就完全没问题了。 - McCabe 方法为了定义"线性独立路径",需要把程序路径看成类似数学里的向量空间。
这个说法比较抽象。
可以简单理解为:McCabe 方法把每条程序路径当成一个"路径向量",然后判断:这条路径是不是独立的?它是不是包含新的边?它能不能和其他路径组成一组 basis paths?
它借用了数学中 linear independence(线性独立) 和 basis(基) 的思想。
而程序路径本身并不是真正的数学向量。
例如回到我们之前的程序图。
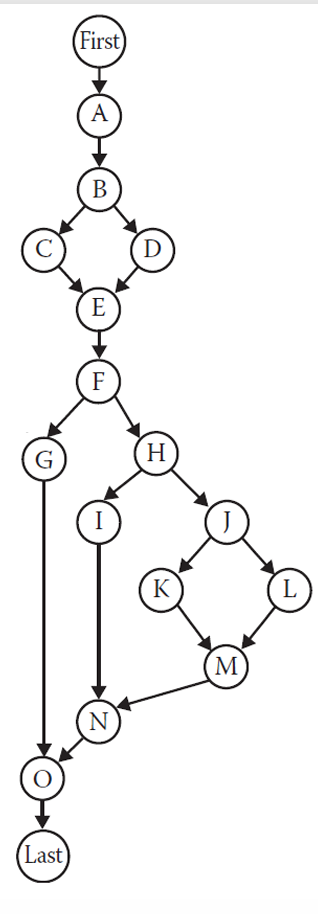
V(G) = 18 - 15 + 2(1) = 5
Original p1: A-B-C-E-F-H-J-K-M-N-O-Last (Scalene)
这是原始选定的 baseline path,基线路径。
这条路径对应的输出是:不等边三角形。
我们现在有:Flip p1 at B - p2: A-B-D-E-F-H-J-K-M-N-O-Last (Infeasible)
在路径 p1 中,节点 B 这里有一个判断 / 分支。
原来 p1 在 B 处走的是:
B → C
现在把它反过来,改走:
B → D
于是得到新路径 p2。
这条路径在图上看起来存在,但实际程序逻辑中不可能执行。
p2:
A-B-D-E-F-H-J-K-M-N-O-Last (Infeasible)
在 B 处翻转得到,但实际不可行。
p3:
A-B-C-E-F-G-O-Last (Infeasible)
在 F 处翻转得到,也不可行。
p4:
A-B-C-E-F-H-I-N-O-Last (Equilateral)
在 H 处翻转得到。
这条路径可行,对应:Equilateral,也就是等边三角形。
p5:
A-B-C-E-F-H-J-L-M-N-O-Last (Isosceles)
在 J 处翻转得到。
这条路径可行,对应:Isosceles,也就是等腰三角形。
这就是所谓的第二点把程序路径数学化、向量化,会忽略代码语义,可能产生 infeasible path。
对于第一点,这里测完 basis paths 不等于测完所有路径,也不等于测试充分。
McCabe 方法根据控制流图可以找出一组看起来独立的路径,但它只看图的连接关系,不一定理解代码的实际逻辑。因此,有些路径虽然在图上能画出来,但由于变量关系或条件逻辑矛盾,实际没有任何输入能走到。
回到刚刚的例子,如果程序走到了节点 C,那么根据程序逻辑,后面必须走到节点 H;如果程序走到了节点 D,那么后面必须走到节点 G。
这些逻辑约束会排除掉路径 2 和路径 3。
还需要补充一条"不是三角形"的基本路径。
最后真正可执行、逻辑上合理的路径有 4 条。
它们分别对应三角形问题的四种输出:
| 路径 | 输出 |
|---|---|
| p1: A-B-C-E-F-H-J-K-M-N-O-Last | Scalene 不等边三角形 |
| p4: A-B-C-E-F-H-I-N-O-Last | Equilateral 等边三角形 |
| p5: A-B-C-E-F-H-J-L-M-N-O-Last | Isosceles 等腰三角形 |
| p6: A-B-D-E-F-G-O-Last | Not a triangle 不是三角形 |
1.3 指导方针和观察结果
功能测试 / 黑盒测试主要关注程序功能和输入输出,但它和源代码内部结构距离比较远。
路径测试(Path testing)太关注控制流图本身,而不一定充分考虑代码真实逻辑。
基本路径测试告诉我们至少需要多少测试(lower bound)。不代表测完这些路径就完全充分。
路径测试提供了一些指标,可以用来反过来检查功能测试设计得好不好。
- 多个功能测试走同一条路径 → 可能冗余(Redundancy)。
- 没有达到 DD-Path 覆盖 → 说明功能测试有空缺(Gaps)。
覆盖率指标可以用来制定最低测试要求。
覆盖率指标还可以帮助我们决定哪些代码需要更严格测试。