一、C++基础到进阶的过渡
1.1、虚拟机远程连接Centos
1、指令使用回顾
切换到管理员用户:su root。加上写权限:chmod u+x /地址。修改文件中内容 vi /地址。将文件的写权限退出:chmod u-w /etc/sudoers(整个文件用于为普通用户加入管理员权限)。回到普通用户:exit或者CTRL+D。
Xshell是一款Windows平台上的SSH(secure Shell)客户端软件,能够完成远程连接和管理Linux服务,支持SSH1和SSH2服务,提供了安全的加密连接,能够防止数据被窃取和篡改。
vim/vi进入文件操作所用到的一些命令:
(命令行模式)yy:复制当前行的文本内容,nyy:复制从广播所在行及以后的n行文本内容。p:将剪切板中的内容进行粘贴。dd:删除光标所在的一行文本内容(剪切)。ndd:删除光标所在行及以后的n行数据(剪切)。u:撤销上一步操作。ctrl+r:反撤销。gg:将光标直接跳到首行。nG:直接跳到n行。0:表示光标直接移动到行首。$:表示光标移动到行尾。
(插入模式):i I a A o O s S。
(底行模式):set number设置行号对应set nonumber。/string:查找字符串string。%s/string1/string2/g:表示将所有的string1更换成string2。m,ns/string1/string2/g表示m到n行闭区间内所有的string1更换成string2。
2、C++环境搭建
1、安装gcc编译环境:sudo yum install gcc 安装C环境
安装g++编译环境:sudo yum install gcc-c++ 安装C++环境
2、安装gdb调试工具:sudo yum install gdb
3、安装CMake工具:sudo yum install cmake
3、第一个Linux下的C++程序
1、一步到位的编译:g++ ***.cpp 此时直接生成a.out的执行程序,g++ ***.cpp -o 可执行程序的名称 此时生成可执行程序
如何执行可执行程序:./可执行的名称。
2、分步编译:(重要)ESc ---> iso
第一步:预处理(Pre_processing):功能:将源程序头文件展开、删除注释、宏替换。语法格式:g++ -E ***.cpp -o ***.i。
第二步:编译(Compiling):功能:将程序编译生成汇编语言。语法格式:g++ -S *** -o ***。
第三步:汇编(ASSembling):功能:将汇编语言编译生成二进制文件。语法格式:g++ -c ***.s -o ***.o
第四步:链接(Linking):功能:链接相关库文件,生成可执行程序。语法格式:g++ ***.o -o 可执行。
1.2、sys库的使用
1、man手册的解析以及使用方法
man手册:Linux系统提供的有关函数或指令介绍的相关帮助手册,可以在该手册中查看函数,指令功能,说白了就是相关操作的使用说明书,一共有七章内容,主要使用前三章,第一章是shell指令相关说明,第二章是系统调用函数相关说明(重点),第三章是库函数(重要)。
使用:只需要键入man + 相关函数/指令即可
如果想要查看C语言库函数的相关功能,需要安装相关库:sudo yum install man-pages man-pages-devel。
2、常用的内核提供的函数库sys
1、文件的操作:open(),read(),write(),close(),lseek()等
2、进程控制函数:fork(),exit(),wait(),execl()等
3、信号操作:kill(),signal()等
4、网络通信:socket(),bind(),listen()等
3、使用GDB调试程序
1、当Linux系统下的警告和错误,当程序出现bug时,Linux终端会给大家两种不同的信息
警告(warning):有时的警告是不影响可执行程序的产生
错误(error):错误如果不改正,是不能生成可执行程序的
总结:相比于gcc编译器,g++编译器要求更加严格,警告可以忽略,继续生成可执行程序,但是错误必须更改后才能执行可执行程序。无错误和警告,但是结果错,此时就可以用GDB进行调试。GDB允许让你查看另一个程序执行时"内部"发生了什么,或者另一个程序崩溃时正在做什么。
如何使用:
1、准备一个C++程序
2、编译程序,编译选项中需要加上-g。g++ -g ***.cpp -o ***。
3、启动GDB调试。gdb ./***。
4、GDB常用指令:quit或q表示退出gdb调试。run/r表示执行可执行程序,如果没有设置断点,则将整个程序从头到尾执行一遍。list/l:展示可执行程序的相关行,默认展示十行。l m,n:表示展示从m行到n行的信息,list func:表示展示func函数旁边相关的程序。break/b:设置断点。break 行号:表示在某行设置断点。next/n:表示执行下一条语句。continue/c:表示从断点处继续向后执行,知道下一个断点处或者程序结束。info break:查看所有断点的信息。delete breakpoint 断点编号:表示删除指定的断点。step(s):能够跳入到指定函数中,查看相关函数内部代码。set variable 变量名=值:表示给某个相关变量设置相关的值。
5、gdb使用小技巧:可以通过shell后面跟终端指令,表示执行终端相关操作。set logging on:设置开启日志功能,会在当前目录中生成一个gdb.txt文件来记录日志。watchpoint:观察点,如果设置的观察点的值发生变化,则会将该值的旧值和新值全部展示出来。
6、gdb调试出错的文件:
当一个可执行程序出现错误时,会产生一个core文件,用于查看相关错误信息,Linux系统默认是不产生core文件,需要进行相关设置后才能产生,通过ulimit -a 查看所有Linux的限制内容。通过ulimit -c unlimited来设置core文件的个数。
7、gdb调试其它正在运行的进程
./可执行程序 &:表示将可执行程序后台运行,不占用当前终端。
4、库的制作(静态库与动态库)
准备头文件、源文件和主程序文件:add.cpp add.h main.cpp。将源程序进行联合编译生成可执行程序:g++ add.cpp main.cpp -o exec。执行可执行程序:./exec。(为什么引入库):在上述案例中,主程序要是有的源程序代码,在add.cpp中,如果项目结束后,到了交付阶段,由于主程序的生成需要其他程序联合编译,那么就要将源程序打包一起发给老板,这样改程序的开发者的自身价值就不大了,该项目的知识产权就很容易被窃取。为了保护我们的知识产权,我们引入了库的概念。(什么是库):库在Linux中是一个二进制文件,它是由.cpp文件(不包含main)函数编译而来,其他程序如果想要使用该源文件的函数时,只需在编译生成可执行程序时,链接上该源文件的库文件即可。库中存储的是二进制文件,不容易被窃取知识产权,做到了保护作用。库在Linux中分为静态库和动态库。
window:***.lib:静态库,***.dll:动态库
Linux:***.a:静态库,***.so:动态库
静态库:概念:将一个***.cpp的文件编译生成一个lib***.a的二进制文件,当你需要使用该源文件中的函数时,只需要链接该库即可,后期可以直接调用。
静态体现在:在使用g++编译程序时,会将你的文件和库最终生成一个可执行程序(把静态库也放入到可执行程序中),每个可执行程序单独拥有一个静态库,体积较大,但是,执行效率较高。
制作:1、准备程序。2、编译生成静态库:gcc -c ***.c -o ***.o//只编译不链接生成二进制文件,ar -crs lib***.a ***.o//编译生成静态库。如果有多个.o文件共同编译生成静态库:ar -crs lib***.a ***.o xxx.o ...(ar:用于生成静态库的指令,c:用于创建静态库,r:将文件插入或者替换静态库中同名文件,s:重置金泰克索引。3使用静态库:gcc main.cpp -L库的路径 -l库名 -I 头文件名字。
动态库:概念:将一个***.cpp的文件编译生成一个lib***.so的二进制文件,当你需要使用该源文件中的函数时,只需要链接该库即可,后期可以直接调用。
动态体现在:在使用g++编译程序时,会将你的文件和库中的相关函数的索引表一起生成一个可执行程序,每个可执行程序只拥有函数的索引表,当程序执行到对应函数时,会根据索引表,动态寻找相关库所在位置进行调用,体积较小,执行效率较低,但是可以多个程序共享同一个动态库,所以,动态库也叫共享库。
制作:1、准备程序。2、编译生成动态库:g++ -fPIC -c ***.cpp -o ***.o//编译生成二进制文件。g++ -shared ***.o -o lib***.so//依赖于二进制文件生成一个动态库。上述两个指令可以合成一个指令:g++ -fPIC -shared ***.cpp -o lib***.so。3、使用动态库:gcc main.cpp -L 库的路径 -l库名 -I 头文件的名字。出现错误:./out时,error while loading shared libraries:liibadd.so:cannot open shared object file:No such file or directory。方式1:更改路径的宏:export LD_LIBRARY_PATH=库的路径(.表示当前目录)。方式2:将自己的动态库放入到系统的库函数目录中(/lib64 /usr/64)。
5、如何使用第三方库
1、C/C++语言默认是支持标准输入输出库的,但是其他的相关函数库需要第三方引入,并且,编译程序时,需要链接上对应的库。
2、使用数学库,#include<math.h>后,g++ xxx.cpp -lm -lc。(-lm代表使用数学库,需要连接上数学库,(-lc代表连接标准的c库。
3、线程支持类库:#include<pthread.h>后,g++ xxx.cpp -lphread
sudo yum install manpages-posix manpages-posix-dev:如果不能支持线程库,要安装。
1.3Makefile文件和Cmake文件
1、Makefile的概念
用于工程项目管理的一个文本文件,文件名为Makefile的文本文件,Makefile可大写可小写,一般大写,如果Makefile和makefile文件都存在,系统会默认使用小写。
2、make的概念
make是一个执行Makefile的工具,上一个解释器,用来对Makefile中的命令进行解析并执行一个shell指令。make这个指令在/usr/bin中,默认Linux系统下都已经安装,如果没有安装make,安装指令如下:sudo yum install make。
3、Makefile的用途:
描述了整个工程的编译、链接规则,软件项目的自动化编译,相当于给软件编译写一份脚本文件。
4、学习Makefile的必要性:
Linux/Unix环境下开发的必备技能。
系统架构师、项目经理的核心技能。
研究开源项目、Linux内核源码的必需品
加深对底层软件构造系统及过程的理解
5、如何学习Makefile
1、理论基础
软件的构造过程、程序的编译和链接:预处理------编译------汇编------链接
面向依赖的思想:
依赖一个.cpp文件的程序
可执行程序------依赖于------.o文件<------依赖于------.s文件<------依赖于------.i文件------.cpp文件
依赖多个.cpp文件的程序
可执行程序------依赖于------.o文件<------依赖于------.s文件<------依赖于------.i文件------.cpp文件
------依赖于------.o文件<------依赖于------.s文件<------依赖于------.i文件------.cpp文件
------依赖于------.o文件<------依赖于------.s文件<------依赖于------.i文件------.cpp文件
2、项目编程基础
C++程序语言基础、C语言基础、多文件源码管理、头文件包含、函数声明与定义
6、Makefile的工作过程
Makefile本身是面向依赖进行编写的
源文件 --->编译 ----> 目标文件 ---> 链接 ---->可执行文件
hello.cpp--->hello.o ---->hello
本质上一步就可以生成可执行程序,但是,由于在生成可执行程序时,可能会有多个文件进行参与,后期其他文件可能要进行更改,更改后,会影响到可执行程序的执行,其他没有更改的文件也要参与编译,浪费时间。
7、第一个Makefile文件
Makefile中的注释是以#开头。
语法格式:
目标:依赖
通过依赖生成目标的指令
注意:指令前面必须使用同一个tab键隔开,不能使用多个空格顶过来。
hello:hello.o
g++ hello.o -o hello
hello.o:hello.s
g++ -c hello.s -o hello.o
hello.s:hello.i
g++ -S hello.i -o hello.s
hello.i:hello.cpp
g++ -E hello.cpp -o hello.i
下面进行简化:
hello:hello.o
g++ hello.o -o hello
hello.o:hello.cpp
g++ -c hello.cpp -o hello.o
然后执行Makefile文件:
make ------>默认找到Makefile的第一个目标开始进行执行。
make目标-->找到对应的目标进行执行。
8、Makefile的语法规则
1、规则:构成Makefile的基本单元,构成依赖关系的核心部件,其他内容可以看做为规则的服务
2、变量:类似于C++中的宏,使用变量:(变量名) 或者{变量名},作用:使得Makefile更加灵活
3、条件执行:根据某一变量的值来控制make执行或者忽略Makefile的某一部分
4、函数:文本处理函数:字符串的替换、查找、过滤等待。文件名的处理:读取文件/目录名、前后缀等待
5、注释:Makefile中的注释,是以#开头。
9、规则
1、规则的构成:目标、目标依赖、命令
2、语法格式
目标:目标依赖
命令
注意事项:
命令必须使用tab键开头,一般是shell指令
一个规则中,可以无目标依赖,仅仅是实现某种操作
一个规则中可以没有命令,仅仅描述依赖关系
一个规则中,必须要有一个目标
3、目标详解
1)默认目标:一个Makefile里面可以有多个目标,一般会选择第一个当作默认目标,也就是make默认执行的目标。
2)多目标:一个规则中可以有多个目标,多个目标具有相同的生成命令和依赖文件。
clean distclean: rm hello.\^cpp hello
3)多规则目标:多个规则可以是同一个目标
4)伪目标:并不是一个真正的文件名,可以看作是一个标签,无依赖,相比一般文件,不会重新生成、执行。伪目标:可以无条件执行,相当于对应的指令。
4、目标依赖
1)文件时间戳:根据时间戳来判断依赖是否要进行更新,所有文件都更改过,则对所有文件进行编译,生成可执行程序,在上次make之后修改过的cpp文件,会被重新编译,在上次make之修改过的头文件,依赖该头文件的目标依赖也会重新编译。
2)模式匹配:%(通配符匹配。@(目标。^(依赖。$<(第一个依赖。*(普通通配符。%是Makefile中的规则通配符,*是普通通配符。
5、命令
1)命令的组成:由shell命令组成,以tab键开头
2)命令的执行:每条命令,make会开一个进程,每条命令执行完,make会检测这个命令的返回码,如果返回成功,则继续执行后面的命令,如果返回失败,则make会终止当前执行的规则并退出。
3)并发执行命令:make -j4 表示开辟4个线程执行。time make 执行make时,显示当前时间。
10、变量
1、变量基础
1)变量定义:变量名=变量值
2)变量的赋值
追加赋值:+= ------在原有的基础上追加相关内容
条件赋值:?= ------如果之前没有值,则为变量赋值,如果之前有值,则不进行赋值
3)变量的作用:$(变量名)或者#{变量名}
2、变量的分类
1)立即展开变量
使用:=操作符进行赋值
在解析阶段直接赋值常量字符串
2)延迟展开变量
使用=操作符进行赋值
将最后一次赋值的结果给变量名使用
3)注意事项
一般在目标、目标依赖中使用立即展开赋值
在命令中一般使用延迟展开赋值变量
3、变量的外部传递:可以通过命令行给变量进行赋值操作。make ARCH=g++
11、条件执行
1、关键字:ifeq、else、endif、ifneq、else、endif
2、使用注意:条件语句从ifeq开始执行,括号与关键字自减使用空格隔开,括号里面挨着括号处,不允许加空格。
1.4vecode的配置
先配置号vsc,然后以下文件到vsc中学习。安装minGW并配置到环境变量。
1、vsc远程连接Centos
1、查看Linux系统下的用户名和ip地址
2、安装远程连接服务(ssh)
3、远程连接Linux下的Centos系统:用户名@ip地址
1.5Cmake的使用
CMake是一个跨平台的安装编译工具,可以使用简单的语句来描述所有平台的安装(编译过程),可以说是已经成为大部分的C++开发项目的标配,可以使用几行或者几十行的代码来完成非常长的Makefile代码。
1、Cmake的基本语法操作
1>基本语法:指令(参数1 参数2)
参数使用括号括起来,参数之间使用空格隔开
2>注意:指令是大小写无关的,但是参数和变量是大小写相关的
3>变量使用${}来进行取值,但是在if控制语句中,是直接使用变量名的
4>语句不以分号结束。
常用如下:
1>cmake_minimun_required:指定CMake的最小版本支持,一般作为第一条cmake语句
2>project:定义工程的名称,并可以指定工程支持的语言project(HELLOWORLD xxx)
3>set:显示定义变量:set(src sayhello.cpp hello.cpp)定义变量src其值为sayhello.cpp hello.cpp
4>add_executable:通过依赖生成可执行程序:add_executable(main main.cpp)
5>include_directories:向工程添加多个特定的头文件搜索路径,类似于g++指令中的-l。将/usr/lib/mylibfolder 和 ./include添加到工程路径中:include_directories(/usr/lib/mylibfolder ./include)。
6>link_directories:向工程中添加多个特定的库文件搜索路径,类似于g++编译指令的-l选项。link_directories(/usr/lib/mylibfolder ./lib)
7>add_library:生成库文件(包括动态库和静态库)。生成动态库:add_library(hello SHARED {src})。生成静态库:add_library(hello STATIC {SRC})。
8>add_compile_options:添加编译参数。add_compile_options(-Wall -std=c++11)
9>target_link_libraries:为target添加需要连接的共享库,类似于g++编译中的-l指令。将hello动态库添加需要链接的共享库,类似于g++编译中的-l指令。
常用变量:
1>CMAKE_C_FLAGS:gcc编译选项的值
2>CMAKE_CXX_FLAGS:g++编译选项的值。在CMAKE_CXX_FLAGS选项后追加-std=c++11:set(CMAKE_CXX_FLAGS"$CMAKE_CXX_FLAGS} -std=c++11")。
3>CMAKE_BUILD_TYPE:编译类型(Debug、Release):设定编译类型为Debug,调试时需要选择该模式:set(CMAKE_BUILD_TYPE Debug)。设定编译类型为Release,发布时需要选择该模式:set(CMAKE_BUILD_TYPE Release)。
2、Cmake实战
CMake目录结构:项目主目录中会放一个CMakeLists.txt的文本文档,后期使用cmake指令时,依赖的就是该文档。
1>包含源文件的子文件夹中包含CMakeLists.txt文件时,主目录的CMakeLists.txt要通过add_subdirector添加子目录。
2>包含源文件的子文件夹中不包含CMakeLists.txt文件时,子目录编译规则,体现在住不了中的CMakeLists.txt。
两种构建方式:
1>内部构建:不推荐使用。
内部构建会在主目录下,产生一大堆中间文件,哪些中间文件并不是我最终所需要的,和工程源文件放在一起时,会显得比较杂乱无章:在当前目录下,编译主目录中的CMakeLists.txt文件生成Makefile文件:cmake . // . 表示当前路径。执行make命令:生成目标文件:make
2>外部构建:推荐使用
将编译输出的文件与源文件放到不同的目录下,进行编译,此时,编译生成的中间文件,不会跟工程源文件进行混淆:1、在当前目录下,创建一个build文件,用于存储生成中间文件:mkdir build。2、进入build文件夹内:cd build。3、编译上一级目录中的CMakeLists.txt,生成Makefile文件以及其他文件cmake .. //..表示上一级目录。4、执行make命令,生成可执行程序:make
二、标准IO与文件IO
2.1标准IO与文件IO的区别
1、IO概念:
1>IO:顾名思义就是输入输出,程序与外部设备进行信息交换的过程称为IO操作
2>最先接触的IO:#include<stdio.h>标准的缓冲输入输出头文件
2、IO的分类
1>标准IO:使用系统提供的库函数实现
2>文件IO:基于系统调用完成,每执行一次系统调用,进程会从用户空间向内核空间进行一次切换。
3>文件IO与标准IO的区别:标准IO相比于文件IO而言,提供了缓冲区,用户可以将数据先放入缓冲区中,等到了缓冲区时机到了后,统一进行一次调用,将数据刷入内核空间。
4>标准IO接口:printf/scanf、fopen/fclose、fgetc/fputc、fgets/futs、fprintf/fscanf、fread/fwrite、fseek/ftell/rewind。文件IO接口:open/close、read/write、lseek。
2.2标准IO相关内容
1、文件结构体FILE
1>FILE结构体是系统提供的用于描述一个文件全部信息的结构体
2>FILE结构体的原型:
cpp
struct FILE
{
char* _IO_buf_base; //缓冲区的起始地址
char* _IO_buf_end; //缓冲区的终止地址
int _filene; //文件描述符,用于进行系统调用
};3>特殊的FILE指针,这三个指针,全部都是针对终端而言的,当程序启动后,系统默认打开的三个特殊文件指针。
stderr:标准出错指针
stdin:标准输入指针
stdout:b标准输出指针
2、打开文件fopen
cpp
#include<stdio.h>//该函数所在的头文件
FILE *fopen(const char *path, const char *mode);
功能:打开一个文件,并返回当前文件的文件指针
参数1:表示文件路径:是一个字符串
参数2:打开文件的方式,也是一个字符串,字符串必须以以下的字符开头
r:以只读方式打开文件,文件必须存在,否则打开失败
r+:以读写方式打开文件,文件必须存在,否则打开失败
w:以只写方式打开文件,如果文件存在,则清空文件内容;如果文件不存在,则创建新文件
w+:以读写方式打开文件,如果文件存在,则清空文件内容;如果文件不存在,则创建新文件
a:以追加方式打开文件,如果文件存在,则在文件末尾添加内容;如果文件不存在,则创建新文件
a+:以读写方式打开文件,如果文件存在,则在文件末尾添加内容
返回值:成功返回打开的文件指针,失败返回NULL并置错误码3、关闭文件fclose
cpp
#include<stdio.h>
int fclose(FILE *fp);
功能:关闭指定的文件
参数:要关闭的文件指针(由fopen返回的结果)
返回值:成功执行返回0,失败返回EOF并置位错误码错误码:
1>概念:当内核提供的函数出错后,内核空间会向用户空间反馈一个错误信息,由于错误信息比较多也比较复杂,系统就给每种不同的错误信息起了一个编号,用一个整数表示,这个整数就是错误码。
2>错误码都是大于或等于0的数字:0表示成功,2表示文件或目录不存在
3>关于错误码的处理函数(sterror、perror)
cpp
#include<error.h>//错误码所在的头文件,里面定义了一个全局变量
int errno;
//将错误码对应的错误信息转换处理
#include<string.h>
char *strerror(int errnum);
功能:将错误码转换为错误信息描述
参数:错误码
返回值:错误信息字符串描述
//只打印错误码对应的错误信息的函数
#include<stdio.h>
void perro(const char *s);
功能:输出当前错误码对应的错误信息
参数:提示符后,会原样打印处理,并且会提示数据后面加上冒号,并输出完成后,自动换行
返回值:无4、单字符读写:fputc/fgetc
cpp
#include<stdio.h>
int fgetc(FILE *stream);
功能:从指定文件中读取一个字符数据,并以无符号整数的形式返回
参数:文件指针
返回值:成功返回读取的字符对应的无符号整数,失败返回EOF并置位错误码练习:使用fgetc和fputc完成两个文件的拷贝工作,实现指令cp的功能:cp srcfile destfile
5、字符串读写:fgets/fputs
cpp
int fputs(const char *s, FILE *stream);
功能:将指定的字符串,写入到指定的文件中
参数1:要被写入的字符串
参数2:文件指针
返回值:成功返回本次写入字符的个数,失败返回EOF
char *fgets(char *s, int size, FILE *stream);
功能:从stream指向的文件中最多读取size-1个字符到s容器中,遇到回车或文件结束,会结束一次读取,并且会将回车放入容器,最后自动加上一个字符串结束标识'\o'
参数1:字符数组容器起始地址
参数2:要读取的字符个数,最多读取size-1个字符
参数3:文件指针
返回值:成功返回容器s的起始地址,失败返回NULL6、关于标准IO的缓冲区问题
缓冲区分三种
1>行缓存:和终端文件相关的缓冲区叫做行缓存,行缓存区的大小为1024字节,对应的文件指针:stdin、stdout。
2>全缓存:和外界文件相关的缓冲区叫做全缓存,全缓存区的大小为4096字节,对应的文件指针:fp
3>不缓存:和标准出错的缓冲区叫不缓存,不缓存的大小为0字节,对应的文件指针:stderr
7、格式化读写:fprintf/fscanf
cpp
int fprintf(FILE *stream, const char *format, ...);
功能:向指定的文件中输出一个格式串
参数1:文件指针
参数2:格式串,可以包含格式控制符,%d(整数)、%s(字符串)、%f(小数)、%lf(小数)
参数3:可变参数,输出项列表,参数个数由参数2中的格式控制符的个数决定
返回值:成功返回输出的字符个数,失败返回一个负数
int fscanf(FILE *stream, const char *format, ...);
功能:从指定的文件中以指定的格式读取数据,放入程序中
参数1:文件指针
参数2:格式串,可以包含格式控制符,%d(整数)、%s(字符串)、%f(小数)、%lf(小数)
参数3:可变参数,输入项地址列表,参数个数由参数2中的格式控制符的个数决定
返回值:成功返回读入的项数,失败返回EOF并置位错误码缓冲区刷新函数:fflush
cpp
#include <stdio.h>
int fflush(FILE *stream);
功能:刷新给定的文件指针对应的缓冲区
参数:文件指针
返回值:成功返回0,失败返回EOF并置位错误码8、格式化读写:fprintf/fscanf
cpp
int fprintf(FILE *stream, const char *format, ...);
功能:向指定的文件中输出一个格式串
参数1:文件指针
参数2:格式串,可以包括格式控制符,%d(整数), %s(字符串), %f(小数), %lf(小数)
参数3:可变参数,输出项列表,参数个数由参数2中的格式控制符的个数决定
返回值:成功返回输出的字符个数,失败返回一个负数
int fscanf(FILE *stream, const char *format, ...);
功能:从指定的文件中以指定的格式读取数据,放入程序中
参数1:文件指针
参数2:格式串,可以包含格式控制符,%d(整数), %s(字符串), %f(小数), %lf(小数)
参数3:可变参数,输入项地址列表,参数个数由参数2中的控制符的个数决定
返回值:成功返回读入的列表,失败返回EOF并且置位错误码9、格式串转字符串存入字符数组中:sprintf/snprintf
1> 目前所学的函数中,printf是向终端打印一个格式串,fprintf是向外部文件中打印一个格式串
2> 有时候,想要将多个数据类型的数据,组成一个字符串放入字符数组中,此时我们就可以使用sprintf和snprintf
cpp
int sprintf(char *str, const char *format, ...);
功能:将指定的格式串转换为字符串,放入字符数组中
参数1:字符数组的起始地址
参数2:格式串,可以包含多个格式控制符
参数3:可变参数
返回值:成功返回转换的字符个数,失败返回EOF
对于上诉函数而言,用一个小的容器去存储一个大的转换后的字符时,会出现指针越界的段错误,为了安全起见,引入了snprintf
int snprintf(char *str, size_t size, const char *format, ...);
功能:将字符串中最多size-1个字符转换为字符串,存到字符数组中
参数1:字符数组的起始地址
参数2:要转换的字符个数,最多为size - 1
参数3:格式串,可以包含多个格式控制符
参数4:可变参数
返回值,如果转换的字符小于size时,返回值就是成功转换字符的个数,如果大于size则只转换size - 1个字符,返回值就是size, 失败返回EOF10、模块化读写(fread/fwrite)
cpp
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
功能:从stream指向的文件中,读取nmemb项数据,每一项的大小为size,将整个结果放入ptr指向的容器中
参数1:容器指针,是一个void*类型,表示可以存储任意类型的数据
参数2:要读取数据每一项的大小
参数3:要读取的数据项数
参数4:文件指针
返回值:成功返回nmemb,就是成功读取的项数,失败返回小于项数的和,或是0
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
功能:向stream指向的文件中写入nmemb项数据,每一项的大小为size,数据的起始地址为ptr
参数1:要写入数据的起始地址
参数2:每一项的大小
参数3:要写入的总项数
参数4:文件指针
返回值:成功返回写入的项数,失败返回小于项数的值,或是011、关于文件光标:fseek/ftell/rewind
cpp
int fseek(FILE *stream, long offset, int whence);
功能:移动文件光标位置,将光标从指定位置处进行前后偏移
参数1:文件指针
参数2:偏移量(>0表示从指定位置向后偏移n个字节,<0表示从指定位置向前偏移n个字节,=0表示在指定位置处不偏移。
参数3:偏移的起始位置(SEEK_SET:文件起始位置,SEEK_CUR:文件指针当前位置,SEEK_END:文件结束位置
返回值:成功返回0,失败返回-1并置错误码
long ftell(FILE *stream);
功能:获取文件指针当前的偏移量
参数:文件指针
返回值:成功返回文件指针所在的位置,失败返回-1并置错误码
eg:fseek(fp, 0, SEEK_END);//将光标定位到结尾
ftell(fp);//该函数的返回值,就是文件大小
void rewind(FILE *stream);
功能:将文件光标定位在开头:fseek(fp, 0, SEEK_SET);
参数:文件指针
返回值:无补充知识:关于追代码工具ctags的使用
1、安装ctags:sudu yum install ctags
2、进入/usr/include 目录下,执行sudo catgs -R指令
3、该目录下会多出一个tags的索引文件
4、追相关内容的指令:vi -t 内容
5、继续向后追内容:ctrl+]
6、退出追代码工具:底行模式下输入q,回车退出
2.3文件IO相关内容
就是通过系统调用(内核提供的函数)实现,只要使用的文件IO接口,那么进程就会从用户空间向内核空间进行一次切换。标准IO的实现中,也是在内部调用了文件IO操作。该操作效率较低,因为没有缓冲区的概念,文件IO常用操作:open、close、read、write、lseek。
1、文件描述符
1> 文件描述符的本质是大于等于0的整数,在使用open函数打开文件时,就会产生一个用于操作文件的句柄,这就是文件描述符
2> 在一个进程中,能够打开的文件描述符是有限制的,一般是1024个,0,1023,可以通过指令ulimit -a查看,如果要更改这个限制,可以通过指令ulimit -n数字,进行更改
3> 文件描述符的使用原则一般是最小未分配原则
4> 特殊的文件描述符:0、1、2,这三个描述符在一个进程启动时就默认被打开了,分别表示标准输入、标准输出、标准错误。
2、打开文件open
cpp
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
功能:打开或创建一个文件,并返回该文件的文件描述符,返回文件描述符的规则是最小未分配原则
参数1:要打开的文件夹路径
参数2:打开模式
以下三种方式必须选其一:O_RDONLY(只读), O_WRONDY(只写), O_RDWR(读写)
以下的打开方式可以有零个或多个,跟上述的方式一起用位或运算连接到一起
O_CREAT:用于创建文件,如果文件不存在,则创建文件,如果文件存在,则打开文件,如果flag中包含了该模式,则函数的第三个参数必须要加上。
O_APPEND:以追加的形式打开文件,光标定位在结尾
O_TRUNC:清空文件
O_EXCL:常跟O_CREAT一起使用,确保本次要创建一个新文件,如果文件已经存在,则open函数报错
eg:
"w":O_WRONLY|O_CREAT|O_TRUNC
"w+":O_RDWR|O_CREAT|O_TRUNC
"r":O_RDONLY
"r+":O_RDWR
"a":O_WRONLY|O_CREAT|O_APPEAD
"a+":O_RDWR|O_CREAT|O_APPEAD
参数3:如果参数2中的flag中有O_CREAT时,表示创建新文件,参数3就必须给定,表示新创建的文件权限。如果当前参数给定了创建的文件权限,最终的结果也不一定是参数3的值,系统会用你给定的参数3的值,与系统的umask取反的值进行位与运算后,才是最终创建文件的权限(mode&~umask)。当前终端的umask的值,可以通过指令umask来查看,一般默认为0022,表示当前进程所在的组中对该文件没有写权限,其他用户对该文件也没有写权限。当前终端的umask的值是可以更改的,通过指令:umask数字进行更改,这种方式只对当前终端有效。普通文件的权限一般为:0644,表示当前用户没有可执行权限,当前组中其他用户和其他组中的用户都只有只读权限。目录文件的权限一般为:0755,表示当前用户具有可读,可写,可执行,当前组中其他用户和其他组中的用户都没有可写权限。注意:如果不给权限,那么当前创建的权限会是一个函数值。返回值:成功返回打开文件的文件描述符,失败返回-1并置位错误码。3、关闭文件close
cpp
#include<unistd.h>
int close(int fd);
功能:关闭文件描述符对应的文件
参数:文件描述符
返回值:成功返回0,失败返回-1并置错误码4、文件IO读写操作
cpp
#include<unistd.h>
ssize_t read(int fd, void *buf, size_t count);
功能:从fd文件描述符引用的文件中读取count的字符放入buf对应的容器中
参数1:已经打开文件对应的文件描述符
参数2:容器的起始地址
参数3:要读取的字符个数
返回值:成功返回读取的字符个数,这个个数可能会小于count的值,失败返回-1并置位错误码
ssize_t write(int fd, const void *buf, size_t count);
功能:将buf容器中的count个数据,写入到fd引用的文件中
参数1:已经打开的文件的文件描述符
参数2:要写入的数据的起始地址
参数3:要写入数据的个数
返回值:成功返回写入的字符个数,这个个数可能会小于count的值,失败返回-1并置位错误码5、文件光标相关函数lseek
cpp
#include<sys/types.h>
#include<unistd.h>
off_t lseek(int fd, off_t offset, int whence);
功能:移动光标位置,并返回光标现在所在的位置
参数1:文件描述符
参数2:偏移量
>0:表示从指定位置向后偏移n个字节
<0:表示从指定位置向前偏移n个字节
=0:在指定位置处不偏移
参数3:偏移的起始位置
SEEK_SET:文件起始位置
SEEK_CUR:文件指针当前位置
SEEK_END:文件结束位置
返回值:光标现所在位置
注意:lseek = fseek + ftell6、文件描述符拷贝问题
三、多进程
3.1多进程理论基础
1、多进程引入目的
1> 实现数据在多个任务并发执行的一种途径
2> 可以实现数据在多个进程之间进行通信,共同处理整个程序的相关数据,提供工作效率
2、多进程内存管理
1> 进程是程序的一次执行过程,又一定的生命周期,包含了创建态、就绪态、执行态、挂起态、死亡态
2> 进程是计算机资源分配的基本单位,系统会给每个进程分配0到4G的虚拟内存,其中0到3G是给用户的,3到4G是给内核空间的。用户空间细分为:栈区、堆区、静态区
3> 进程的调度机制:时间片轮询上下文切换机制
4> 并发与并行的区别:
并发:针对于单核CPU系统在处理多个任务时,使用相关的调度机制,实现多个任务进行细化时间片轮询时,在宏观上感觉是多个任务同时执行的操作,同一时刻,只有一个任务在被CPU处理。
并行:是针对多核CPU而言,处理多个任务时,同一时间,每个CPU处理的任务之间是并行的,实现的是真正意义上的多个任务同时执行的。
3、多进程内存管理
1> 物理内存:内存条上(硬件上)真正存在的存储空间
2> 虚拟内存:程序运行后,通过内存映射单元,将物理内存映射出4G的虚拟内存,共进程使用
4、进程和程序的区别
进程:是动态的,进程是程序的一次执行过程,是有生命周期的,进程会被分配0--3G的用户空间,进 程是在内存上存着的
程序:是静态的,没有所谓的生命周期,程序存储在磁盘设备上的二进制文件 hello.cpp ---> g++ ----> a.out
5、进程的种类
进程一共有三种:交互进程、批处理进程、守护进程
1> 交互进程:它是由shell控制,可以直接和用户进行交互的,例如文本编辑器
2> 批处理进程:内部维护了一个队列,被放入该队列中的进程,会被统一处理。例如 g++编译器的一
步到位的编译
3> 守护进程:脱离了终端而存在,随着系统的启动而运行,随着系统的退出而停止。例如:操作系统
的服务进程
6、进程PID的概念
1> PID(Process ID):进程号,进程号是一个大于等于0的整数值,是进程的唯一标识,不可能重 复。
2> PPID(Parent Process ID):父进程号,系统中允许的每个进程,都是拷贝父进程资源得到的
3> 在linux系统中的 /proc目录下的数字命名的目录其实都是一个进程
7、特殊的进程
1> 0号进程(idel):他是由linux操作系统启动后运行的第一个进程,也叫空闲进程,当没有其他进 程运行时,会运行该进程。他也是1号进程和2号进程的父进程
2> 1号进程(init):他是由0号进程创建出来的,这个进程会完成一些硬件的必要初始化工作,除此 之外,还会收养孤儿进程
3> 2号进程(kthreadd):也称调度进程,这个进程也是由0号进程创建出来的,主要完成任务调度 问题
4> 孤儿进程:当前进程还正在运行,其父进程已经退出了。 说明:每个进程退出后,其分配的系统资源应该由其父进程进行回收,否则会造成资源的浪费
5> 僵尸进程:当前进程已经退出了,但是其父进程没有为其回收资源
8、进程有关操作指令
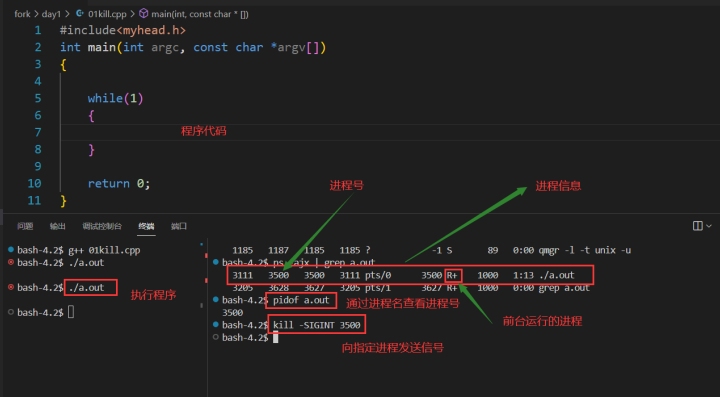
1> ps指令:能够查看当前运行的进程相关属性 ,ps -ef :能够显示进程之间的关系
bash
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 10:22 ? 00:00:01 /usr/lib/systemd/systemd --
switched-root --system --deserialize 22
root 2 0 0 10:22 ? 00:00:00 [kthreadd]
root 4 2 0 10:22 ? 00:00:00 [kworker/0:0H]
root 5 2 0 10:22 ? 00:00:00 [kworker/u256:0]
root 6 2 0 10:22 ? 00:00:00 [ksoftirqd/0]
root 7 2 0 10:22 ? 00:00:00 [migration/0]
root 8 2 0 10:22 ? 00:00:00 [rcu_bh]
root 9 2 0 10:22 ? 00:00:01 [rcu_sched]
root 10 2 0 10:22 ? 00:00:00 [lru-add-drain]
root 11 2 0 10:22 ? 00:00:00 [watchdog/0]
root 13 2 0 10:22 ? 00:00:00 [kdevtmpfs]
root 14 2 0 10:22 ? 00:00:00 [netns]
root 15 2 0 10:22 ? 00:00:00 [khungtaskd]
UID:用户ID号
ps -ajx:能够显示当前进程的状态
ps -aux:可以查看当前进程对CPU和内存的占用率
2> top:动态查看进程的相关属性
PID:进程号
PPID:父进程号
C:用处不大
STIME:开始运行的时间
TTY:如果是问号表示这个进程不依赖于终端而存在
CDM:名称ps -ajx:能够显示当前进程的状态
bash
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
0 1 1 1 ? -1 Ss 0 0:01
/usr/lib/systemd/systemd --switched-root --system --deserialize 22
0 2 0 0 ? -1 S 0 0:00 [kthreadd]
2 4 0 0 ? -1 S< 0 0:00 [kworker/0:0H]
2 5 0 0 ? -1 S 0 0:00 [kworker/u256:0]
2 6 0 0 ? -1 S 0 0:00 [ksoftirqd/0]
2 7 0 0 ? -1 S 0 0:00 [migration/0]
2 8 0 0 ? -1 S 0 0:00 [rcu_bh]
2 9 0 0 ? -1 R 0 0:01 [rcu_sched]
PGID:进程组ID
SID:会话组ID
STAT:进程的状态ps -aux:可以查看当前进程对CPU和内存的占用率
bash
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.6 128020 6032 ? Ss 10:22 0:01
/usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S 10:22 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? S< 10:22 0:00 [kworker/0:0H]
root 5 0.0 0.0 0 0 ? S 10:22 0:00
[kworker/u256:0]
root 6 0.0 0.0 0 0 ? S 10:22 0:00 [ksoftirqd/0]
root 7 0.0 0.0 0 0 ? S 10:22 0:00 [migration/0]
root 8 0.0 0.0 0 0 ? S 10:22 0:00 [rcu_bh]
%CPU:CPU占用率
%MEM :内存占用率2> top:动态查看进程的相关属性
bash
top - 11:43:17 up 1:20, 1 user, load average: 0.04, 0.03, 0.05
Tasks: 111 total, 1 running, 110 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.7 sy, 0.0 ni, 98.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 995676 total, 98992 free, 422940 used, 473744 buff/cache
KiB Swap: 1953788 total, 1953524 free, 264 used. 414260 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1681 zpp 20 0 159040 2464 1108 S 0.3 0.2 0:02.55 sshd
3> kill指令:发送信号的指令
使用方式:kill -信号号 进程号
可以通过指令:kill -l查看能够发送的信号有哪些
1898 zpp 20 0 895384 87616 24368 S 0.3 8.8 0:12.63 node
1941 zpp 20 0 10.9g 114436 24172 S 0.3 11.5 0:07.83 node
1948 zpp 20 0 765236 46700 20368 S 0.3 4.7 0:05.33 node
1 root 20 0 128020 6032 3548 S 0.0 0.6 0:01.10 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
5 root 20 0 0 0 0 S 0.0 0.0 0:00.61
kworker/u256:03> kill指令:发送信号的指令 使用方式:kill -信号号 进程号 可以通过指令:kill -l查看能够发送的信号有哪些
bash
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
1、一共可以发射62个信号,前32个是稳定信号,后面是不稳定信号
2、常用的信号
SIGHUP:当进程所在的终端被关闭后,终端会给运行在当前终端的每个进程发送该信号,默认结束进程
SIGINT:中断信号,当用户键入ctrl + c时发射出来
SIGQUIT:退出信号,当用户键入ctrl + /是发送,退出进程
SIGKILL:杀死指定的进程
SIGSEGV:当指针出现越界访问时,会发射,表示段错误
SIGPIPE:当管道破裂时会发送该信号
SIGALRM:当定时器超时后,会发送该信号
SIGSTOP:暂停进程,当用户键入ctrl+z时发射
SIGTSTP:也是暂停进程
SIGTSTP、SIGUSR2 :留给用户自定义的信号,没有默认操作
SIGCHLD:当子进程退出后,会向父进程发送该信号
3、有两个特殊信号:SIGKILL和SIGSTOP,这两个信号既不能被捕获,也不能被忽略4> pidof:查看进程的进程号 使用方式:pidof 进程名
9、进程状态的切换
1> 可以通过 man ps进行查看进程的状态
bash
进程主状态:
D uninterruptible sleep (usually IO) 不可中断的休眠态,通常是IO
操作
R running or runnable (on run queue) 运行态
S interruptible sleep (waiting for an event to complete) 可中
断的休眠态
T stopped by job control signal 停止态
t stopped by debugger during the tracing 调试时的停止态
W paging (not valid since the 2.6.xx kernel) 已经弃用的状态
X dead (should never be seen) 死亡态
Z defunct ("zombie") process, terminated but not reaped by its
parent 僵尸态
附加态:
< high-priority (not nice to other users) 高优先级进程
N low-priority (nice to other users) 低优先级进程
L has pages locked into memory (for real-time and custom IO)
锁在内存中的进程
s is a session leader 会话组组长
l is multi-threaded (using CLONE_THREAD, like NPTL pthreads
do) 包含多线程的进程
+ is in the foreground process group 前台运行的进程2> 状态切换的实例
bash
1、如果有停止的进程,可以在终端输入指令:jobs -l查看停止进程的作业号
2、通过使用指令:bg 作业号 实现将停止的进程进入后台运行状态,如果只有一个停止的进程,输入bg不
加作业号也可以
3、对后台运行的进程,输入 fg 作业号 实现将后台运行的进程切换到前台运行
4、直接将可执行程序后台运行: ./可执行程序 &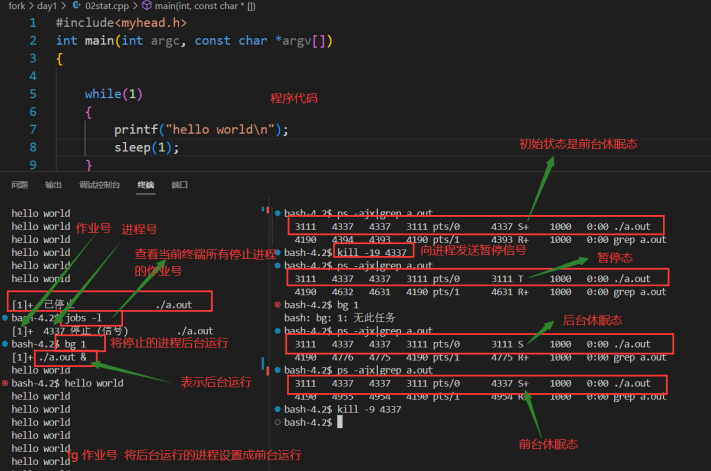
3.2多进程实现
1、进程创建fork
cpp
#include <unistd.h>
pid_t fork(void);
功能:通过拷贝父进程得到一个子进程
参数:无
返回值:成功在父进程中得到子进程的pid,在子进程中的到0,失败返回-1并置位错误码1> 不关注返回值的案例
cpp
#include<myhead.h>
int main(int argc, const char *argv[])
{
printf("ni hao xingqiu\n");
fork(); //创建一个子进程
printf("hello world\n");
while(1); //防止进程结束
return 0;
}2> 多个fork创建进程:如果不关注返回值的话,有n个fork,会产生2^n个进程
3> 关注返回值的情况
cpp
#include<myhead.h>
int main(int argc, const char *argv[])
{
pid_t pid = -1;
pid = fork(); //创建一个子进程,父进程会将返回值赋值给父进程中的pid变量
//子进程会将返回值赋值给子进程中的pid变量
printf("pid = %d\n", pid); //对于父进程而言会得到大于0的数字,对于子进程而言会
得到0
//对pid进程判断
if(pid > 0)
{
//父进程要做执行的代码
printf("我是父进程\n");
}else if(pid == 0)
{
//子进程要执行的代码
printf("我是子进程\n");
}else
{
perror("fork error");
return -1;
}
while(1); //防止进程结束
return 0;
}4> 父子进程并发执行的案例
2、进程号获取getpid\getppid
cpp
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
功能:获取当前进程的进程号
参数:无
返回值:当前进程的进程号
pid_t getppid(void);
功能:获取当前进程的父进程pid号
参数:无
返回值:当前进程的父进程pid3、进程退出 exit_exit
上述两个函数都可以完成进程的退出,区别是在退出进程时,是否刷新标准IO的缓冲区,exit属于库函数,使用该函数退出程序时,会刷新标准IO的缓冲区后退出,_exit属于系统调用(内核提供的函数),使用该函数退出程序时,不会刷新标准IO的缓冲区
cpp
#include<stdlib.h>
void exit(int status);
功能:退出当前进程,并刷新当前进程打开的标准IO的缓冲区
参数:进程退出时的状态,会将改制于0377进程位与运算后,返回给回收资源的进程
返回值:无
#include<unistd.h>
void _exit(int status);
功能:退出当前进程,不刷新当前进程打开的标准IO的缓冲区
参数:进程退出时的状态,会将改制与0377进程位与运算后,返回给回收的进程
返回值:无4、进程资源回收 wait\waitpid
有两个函数可以完成堆进程资源的回收
wait是阻塞回收任意一个子进程的资源函数
waitpid:可以阻塞,也可以非阻塞完成对指定的进程号进程资源回收
cpp
pid_t wait(int *status);
功能:阻塞回收子进程的资源
参数:接收子进程退出时的状态,获取子进程退出时的状态与0377进行位与后的结果,如果不愿意接收,可以填NULL
返回值:成功返回回收资源的哪个进程的pid号,失败返回-1并置位错误码
pid_t waitpid(pid_t pid, int *status, int options);
功能:可以阻塞也可以非阻塞指定进程的资源
参数1:进程号
>0:表示回收指定的进程,进程号位pid(常用)
=0:表示回收当前进程所在进程组中的任意一个子进程
=-1:表示回收指定进程组中的任意一个子进程,进程组id位给定的pid的绝对值
参赛2:接收子进程退出时的状态,获取子程序退出时的状态与0377进程位于后的结果,如果不愿意接收,可以填NULL
参数3:是否阻塞
0:表示阻塞等待:waitpid(-1, &status, 0);等价于 wait(&status)
WNOHANG:表示非阻塞
返回值:
>0: 返回的是成功回收的子进程pid号
=0:表示本次没有回收到子进程
=-1:出错并置位错误码
cpp
#include<myhead.h>
int main(int argc, char* argv[]){
pir_t pid = -1;//定义用于存储进程号的变量
//创建进程
pid = fork();
if(pid > 0){
//父进程程序代码
//输出当前进程号、子进程号,父进程号
printf("self pid=%d, child pid = %d, parent pid = %d\n", getpid(), pid, getppid());
sleep(8);//休眠8秒
//wait(NULL);//回收子进程资源,只有回收了子进程资源后,父进程才继续向后执行
waitpid(-1, NULL, WNOHAANG);//非阻塞回收子进程资源
printf("子进程资源已经回收\n");
}else if(pid == 0){
//子进程程序代码
//输出当前进程号,父进程进程号
printf("self pid=%d, parent pid = %d\n", getpid(), getppid());
//提出子进程
printf("111111111111111111111111111111");//没有加换行,不会自动刷新
sleep(3);
exit(EXIT_SUCCESS);//刷新缓冲区并退出进程
//_exit(EXIT_SUCCESS);//不刷新缓冲区退出进程
}else{
perror("fork error");
return -1;
}
while(1);//防止进程退出
return 0;
}练习:使用多进程完成两个文件的拷贝工作,父进程拷贝前一半内容,子进程拷贝后一半内容,父进程 要回收子进程的资源
cpp
#include<myhead.h>
//定义求文件大小的函数
int get_file_size(const char *srcfile, const char *destfile){
//以只读的形式打开源文件,以创建写的形式打开目标文件
int srcfd, destfd; //记录源文件和目标文件的文件描述符
if ((srcfd = open(srcfile, O_RDONLY)) == -1)
{
perror("open destfile error");
return -1;
}
//求源文件的大小
int len = lseek(srcfd, 0, SEEK_END);
//关闭文件
close(srcfd);
close(destfd);
return len;//将原文件的大小返回
}
//定义拷贝文件的函数
int copy_file(const char *srcfile, const char *destfile, int start, int len)
{
//以只读的形式打开源文件,以只写的形式打开目标文件
int srcfd, destfd; //记录源文件和目标文件的文件描述
if ((srcfd = open(srcfile, O_RDONLY)) == -1)
{
perror("open destfile error");
return -1;
}
//将两个文件的光标位置统一
lseek(srcfd, staqrt, SEEK_SET);
lseek(destfd, start, SEEK_SET);
//开始拷贝
char buf[128] = "";//数据的搬运工
int sum = 0; //记录拷贝的总字节数
while(1)
{
int res = read(srcfd, buf, sizeof(buf));//从源文件中读取数据到缓冲区
sum += res;//将拷贝的字节数累加
if(res == 0 || sum >= len){
write(destfd, buf, res - (sum - len));//将最后一次内容拷贝
break;//文件结束
}
write(destfd, buf, res);//从源文件读多少,写入目标文件多少
}
return 0;
}
/*******************主程序***************************/
int main(int argc, const char *argcv[])
{
//使用外部传参,将要拷贝的文件以及存储文件传进来
if(argc != 3){
printf("input file erro\n");
printf("usage:./a.out srcfile destfile\n");
return -1;
}
//获取源文件长度,分别执行拷贝函数
pid_t = pid = fork();
if(pid > 0){
//父进程拷贝前一半内容
copy_file(argv[1], argv[2], 0, len / 2);//从开头位置拷贝,拷贝len / 2内容
//回收子进程资源
wait(NULL);
}else if(pid == 0){
//子进程拷贝后一半内容
copy_file(argv[1], argv[2], len / 2, len - len / 2);//从len / 2位置拷贝,拷贝len - len / 2内容
//退出进程
exit(EXIT_SUCCESS);
}else{
perror("fork error");
return -1;
}
printf("文件拷贝完成\n");
return 0;
}5、父进程创建两个进程为其收尸
cpp
#include<myhead.h>
int main(int argc, const char *argv[])
{
pid_t pid = -1;//创建大儿子
if(pid > 0){
//父进程
pid_t pid_2 = fork();;//创建二儿子
if(pid_2 > 0){
//父进程
printf("我是父进程\n");
//回收两个子进程的资源
wait(NULL);
wait(NULL);
}else if(pid_2 == 0){
sleep(3);
//二儿子进程内容
printf("我是进程2\n");
exit(EXIT_SUCCESS);
}
}else if(pid == 0){
sleep(3);
//大儿子进程
printf("我是进程1\n");
exit(EXIT_SUCCESS);
}else{
perror("fork error");
return -1;
}
return 0;
}
6、僵尸进程和孤儿进程
1> 孤儿进程:当前进程还正在运行,其父进程已经退出了。 说明:每个进程退出后,其分配的系统资源应该由其父进程进行回收,否则会造成资源的浪费
cpp
#include<myhead.h>
int main(int argc, const char *argv[])
{
pid_t pid = -1;//定义用于存储进程号的变量
//创建进程
pid = fork();
if(pid > 0){
//父进程的程序代码
sleep(5);
exit(EXIT_SUCCESS);//父进程退出
}else if(pid == 0){
//子进程程序代码
while(1){
printf("hello world\n");
sleep(1);
}
}else{
perror("fork error");
return -1;
}
while(1);//防止进程退出
return 0;
}
2> 僵尸进程:当前进程已经退出了,但是其父进程没有为其回收资源
cpp
#include<myhead.h>
int main(int argc, const char *argv[])
{
pid_t pid = -1;//定义用于存储进程号的变量
//创建进程
pid = fork();
if(pid > 0){
//父进程程序代码
while(1){
printf("hello world\n");
sleep(1);
}
}else if(pid == 0){
//子进程程序代码
sleep(5);
exit(EXIT_SUCCESS);//子进程退出
}else{
perror("fork error");
return -1;
}
while(1);//防止进程退出
return 0;
}
3.3进程间通信IPC
1> 由于多个进程的用户空间是相互独立的,其栈区、堆区、静态区的数据都是彼此私有的,所以不可能通过用户空间中的区域完成多个进程之间数据的通信
2> 可以使用外部文件来完成多个进程之间数据的传递,一个进程向文件中写入数据,另一个进程从文件中读取数据。该方式要必须保证写进程先执行,然后再进程读进程,要保证进程执行的同步性。
3> 我们可以利用内核空间来完成对数据的通信工作,本质上,在内核空间创建一个特殊的区域,一个进程向该区域中存放数据,另一个进程可以从该区域中读取数据
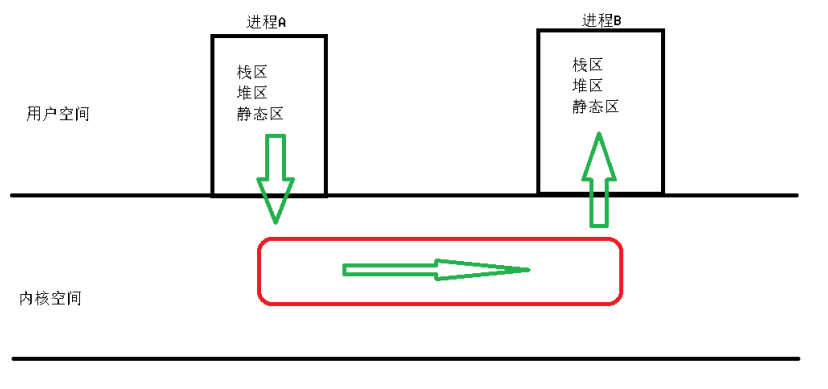
4> 引入原因:用户空间中的数据,不能作为多个进程之间数据交换的容器
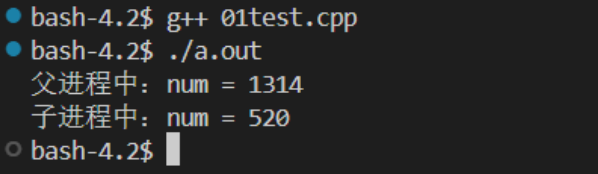
cpp
#include<myhead.h>
int num = 520; //定义一个全局变量
int main(int argc, const char *argv[])
{
pid_t pid = fork();//创建一个子进程
if(pid > 0){
//父进程
num = 1314;
printf("父进程中: num = %d\n", num);
wait(NULL);//等待子进程结束
}else if(pid == 0){
//子进程
sleep(3);
printf("子进程中: num = %d\n", num);
}else{
peerror("fork error");
return -1;
}
return 0;
}效果图:
1、进程间通信的概念
1> IPC:interprocess communication 进程间通信
2> 使用内核空间来完成多个进程间相互通信,根据使用的容器或方式不同,分为三类通信机制
3> 进程间通信方式分类
bash
1、内核提供的通信方式(传统的通信方式)
无名管道
有名管道
信号
2、system V提供的通信方式
消息队列
共享内存
信号量(信号灯集)
3、套接字通信:socket 网络通信(跨主机通信)2、无名管道
1> 管道的管理:管道是一种特殊的文件,该文件不用于存储数据,只用于进程间通信。管道分为有名管道和无名管道。
bash
文件类型:bcd-lsp
b:块设备文件
c:字符设备文件
d:目录文件,文件夹
-:普通文件
l:链接文件
s:套接字文件(网络编程)
p:管道文件2> 在内核空间中创建出一个管道通信,一个进程可以将数据写入管道,经由管道缓冲到另一个进程中读取
3> 无名管道:顾名思义就是名誉名字的管道,会在内存中创建出该管道,不存在于文件系统,随着进程结束而消失
4> 无名管道仅适用于亲缘进程间通信,不适用于非亲缘进程间通信
5> 无名管道的API
cpp
#include<myhead.h>
int main(int argc, const char *argv[])
{
//可以在此创建管道文件,并返回该管道文件的两端,那么父子进程都会拥有该管道两端的文件描述符
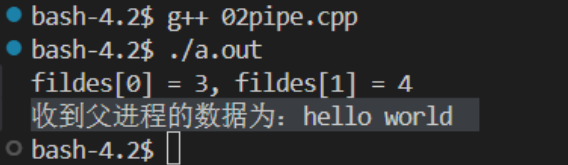
int fildes[2];//存放管道文件的两端文件描述符
//创建无名管道,并返回该管道的两端文件的文件描述符
if(pipe(fildes) == -1){
perror("pipe error");
return -1;
}
printf("fildes[0] = %d, fildes[1] = %d\n", fildes[0], fildes[1]);//3 4
pid_t pid = fork();//创建一个子进程
if(pid > 0){
//父进程
//不用读端,就关闭
close(fildes[0]);
wait(NULL);//等待回收子进程
}else if(pid == 0){
//子进程
//关闭写端
close(fildes[1]);
//通过读端从管道文件中读取数据
char rbuf[128] = "";
read(fildes[0], rbuf, sizeof(rbuf));
printf("收到父进程的数据为: %s\n", rbuf);//将数据输出到终端
//关闭终端
close(fildes[0]);
//退出子进程
exit(0);
}else{
perror("fork error");
return -1;
}
return 0;
}
6> 管道通信特点
bash
1、管道可以实现自己给自己发信息
2、对管道中数据的操作是一次性的,当管道中的数据被读取后,就从管道中消失了,在读取时会被阻塞
3、管道文件的大小:64K
4、由于返回的是管道文件的文件描述符,所以对管道的操作只能是文件IO相关函数,但是,不可以使用lseek对光标进程偏移,必须做到先进先出
5、管道的读写特点:
当读端存在时,写端有多少写多少,知道写满64K后,在write阻塞
当读端不存在时,写端再向管道中写入数据时,会发生管道破裂,内核空间会向用户空间发射一个SIGPIPE信号,进程收到该信号后,退出
当写端存在时:读端有多少读多少,没有数据,会在read出阻塞
当写端不存在时:读端有多少读多少,没有数据,不会在read处阻塞了
6、管道通信是半双工通信方式
单工:只能进程A向B发送信息
半双工:同一时刻只能A向B发信息
全双工:任意时刻,AB可以互相通信验证自己跟自己通信
cpp
#include<myhead.h>
int main(int argc, const char *argv[]){
int fildes[2];//存放管道文件的两端文件描述符
//创建无名管道,并返回该管道的两端文件的文件描述符
if(pipe(fildes) == -1){
perror("pipe error");
return -1;
}
printf("fildes[0] = %d, fildes[1] = %d\n", fildes[0], fildes[1]);//3
//定义两个容器
char wbuf[128] = "hello, pipe!";//写入管道文件的数据
char rbuf[128] = "";//从管道文件中读取数据的容器
//将wbuf中的数据写入管道文件中,从管道中读取数据放入rbuf中
write(fildes[1], wbuf, sizeof(wbuf));//将数据写入管道文件中
read(fildes[0], rbuf, sizeof(rbuf));//从管道文件中读取数据放入rbuf中
printf("从管道文件中读取的数据为: %s\n", rbuf);//将数据输出到终端
//关闭管道文件的两端
close(fildes[0]);
close(fildes[1]);
return 0;
}对管道文件大小的验证
cpp
#include<myhead.h>
int main(int argc, const char *argv[])
{
int fildes[2];//存放管道文件的两端文件描述符
//创建无名管道,并返回该管道的两端文件的文件描述符
if(pipe(fildes) == -1){
perror("pipe error");
return -1;
}
printf("fildes[0] = %d, fildes[1] = %d\n", fildes[0], fildes[1]);//3
char buf = 'A';//定义一个字符变量
int count = 0;//记录向管道中写入数据的个数
while(1){
write(fildes[1], &buf, sizeof(buf));//向管道中写入数据
count++;//写入数据的个数加1
printf("向管道中写入了%d个数据\n", count);
}
//关闭管道文件的两端
close(fildes[0]);
close(fildes[1]);
return 0;
}3、有名管道
1> 顾名思义就是有名字的管道文件,会在文件系统中创建一个真实存在的管道文件
2> 既可以完成亲缘进程间的通信,也可以完成非亲缘进程间通信
3> 有名管道的API
cpp
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
功能:创建一个管道文件,并存在与文件系统中
参数1:管道文件的名称
参数2:管道文件的权限,内容详见open函数的mode参数
返回值:成功返回0,失败返回-1并置位错误码
注意:管道文件被创建后,其他进程就可以进行打开读写操作了,但是,必须要保证当前管道文件的
两端都打开后,才能进行读写操作,否则函数会在open处阻塞4> 案例:
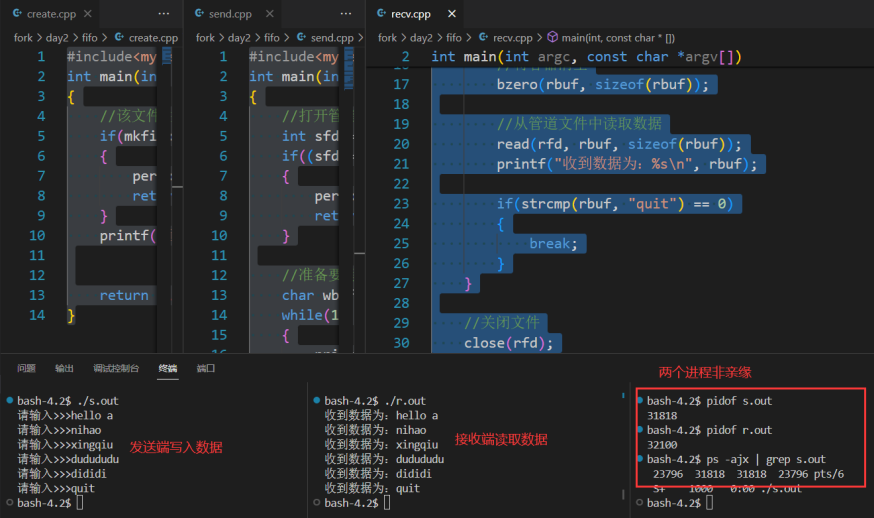
send.cpp
cpp
#include<myhead.h>
int main(int argc, const char *argv[]){
//打开管道文件
int sfd = -1;
if((sfd = open("./myfifo", O_WRONLY)) == -1){
perror("open error");
return -1;
}
//准备要写入的数据
char wbuf[128] = "";
while(1){
printf("请输入>>>");
fgets(wbuf, sizeof(wbuf), stdin);//从终端获取输入的数据
wbuf[strlen(wbuf) - 1] = '\0';//去掉
//将数据写入管道
write(sfd, wbuf, sizeof(wbuf));
if(strcmp(wbuf, "quit") == 0){
break;
}
}
//关闭管道文件
close(sfd);
return 0;
}recv.cpp
cpp
include<myhead.h>
int main(int argc, const char *argv[]){
//打开管道文件
int rfd = -1;
if((rfd = open("./myfifo", O_RDONLY)) == -1){
perror("open error");
return -1;
}
//准备要写入的数据
char rbuf[128] = "";
while(1){
//将容器清空
bzero(rbuf, sizeof(rbuf));
//从管道中读取数据
read(rfd, rbuf, sizeof(rbuf));
printf("收到的数据为: %s\n", rbuf);//将数据输出到终
if(strcmp(rbuf, "quit") == 0){
break;
}
}
//关闭管道文件
close(rfd);
return 0;
}
练习:使用有名管道实现,两个进程之间相互通信,提示:可以使用多进程和多线程
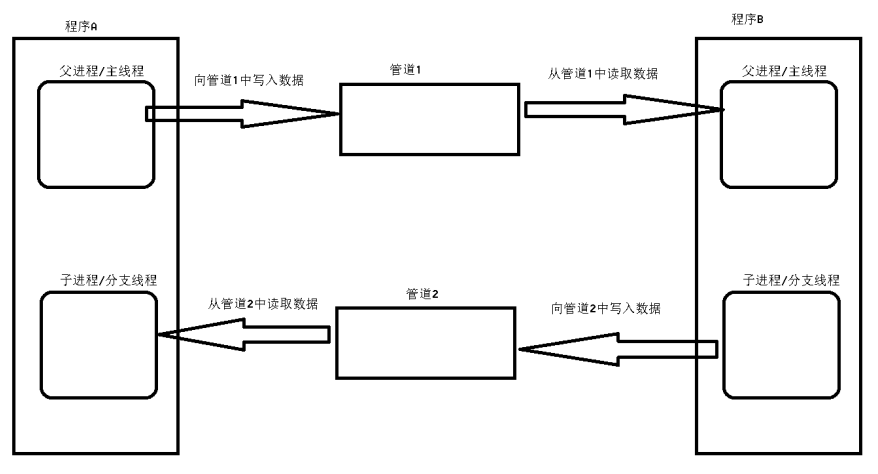
1> create.cpp
cpp
#include<myhead.h>
int main(int argc, const char *argv[]){
//该文件主要负责创建管道文件,注意:如果管道文件已经存在,则mkfifo函数会报错
if(mkfifo("./myfifo1", 0664) == -1){
perror("mkfifo error");
return -1;
}
if(mkfifo("./myfifo2", 0664) == -1){
perror("mkfifo error");
return -1;
}
printf("管道文件创建成功!\n");
return 0;
}2> send.cpp
cpp
#include<myhead.h>
int main(int argc, const char *argv[]){
//创建子进程
pid_t pid = fork();
if(pid > 0){
//父进程,完成向管道1中写入数据
//打开管道文件
int sfd = -1;
if((sfd = open("./myfifo1", O_WRONLY)) == -1){
perror("open error");
return -1;
}
//准备要写入的数据
char wbuf[128] = "";
while(1){
fgets(wbuf, sizeof(wbuf), stdin);//从终端获取输入的数据
wbuf[strlen(wbuf) - 1] = '\0';//去掉
//将数据写入管道
write(sfd, wbuf, sizeof(wbuf));
if(strcmp(wbuf, "quit") == 0){
break;
}
}
//关闭管道文件
close(sfd);
//回收子进程
wait(NULL);
}else if(pid == 0){
//子进程,完成从管道2中读取数据
//打开管道文件
int rfd = -1;
if((rfd = open("./myfifo2", O_RDONLY)) == -1){
perror("open error");
return -1;
}
//准备要写入的数据
char rbuf[128] = "";
while(1){
//将容器清空
bzero(rbuf, sizeof(rbuf));
//从管道中读取数据
read(rfd, rbuf, sizeof(rbuf));
printf("收到的数据为: %s\n", rbuf);//将数据输出到终
if(strcmp(rbuf, "quit") == 0){
break;
}
}
//关闭管道文件
close(rfd);
//退出进程
exit(EXIT_SUCCESS);
}else{
perror("fork error");
return -1;
}
return 0;
}3> recv.cpp
cpp
#include<myhead.h>
int main(int argc, const char *argv[]){
//创建子进程
pid_t pid = fork();
if(pid > 0){
//父进程,完成从管道1中读取数据
//打开管道文件
int rfd = -1;
if((rfd = open("./myfifo1", O_RDONLY)) == -1){
perror("open error");
return -1;
}
//准备要写入的数据
char rbuf[128] = "";
while(1){
//将容器清空
bzero(rbuf, sizeof(rbuf));
//从管道中读取数据
read(rfd, rbuf, sizeof(rbuf));
printf("收到的数据为: %s\n", rbuf);//将数据输出到终端
if(strcmp(rbuf, "quit") == 0){
break;
}
}
//关闭文件
close(rfd);
//回收子进程
wait(NULL);
}else if(pid == 0){
//子进程,完成向管道2中写入数据
//打开管道文件
int sfd = -1;
if((sfd = open("./myfifo2", O_WRONLY)) == -1){
perror("open error");
return -1;
}
//准备要写入的数据
char wbuf[128] = "";
while(1){
fgets(wbuf, sizeof(wbuf), stdin);//从终端获取输入的数据
wbuf[strlen(wbuf) - 1] = '\0';//去掉换行符
//将数据写入管道
write(sfd, wbuf, sizeof(wbuf));
if(strcmp(wbuf, "quit") == 0){
break;
}
}
//关闭管道文件
close(sfd);
//退出进程
exit(EXIT_SUCCESS);
}else{
perror("fork error");
return -1;
}
return 0;
}4、信号
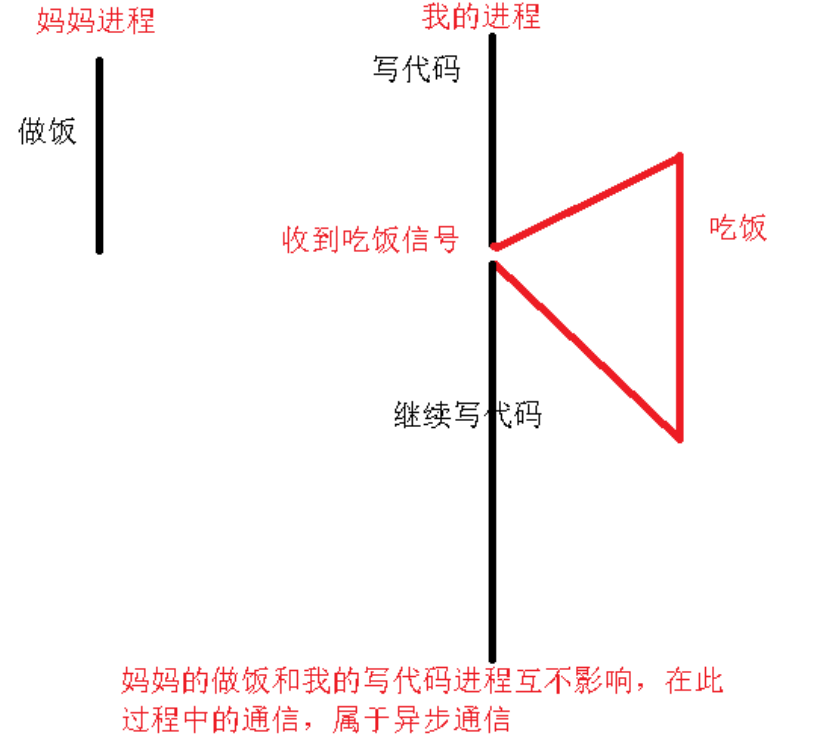
1> 信号相关概念
bash
1、信号是软件模拟硬件的中断功能,信号是软件实现的,中断是硬件实现的
中断:停止当前正在执行的事情,去做另一件事
2、信号是linux内核实现的,没有内核就没有信号的概念
3、用户可以给进程发信号:例如键入ctrl+C
内核可以向进程发送信号:例如SIGPIPE
一个进程可以给另一个进程发送信号,需要通过相关函数来完成
4、信号通信是属于异步通信工作
同步:表示多个任务有先后顺序的执行,例如去银行办理业务
异步:表示多个任务没有先后顺序执行,例如你在敲代码,你妈妈在做饭2> 通信原理图
3> 信号的种类及功能
bash
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
4> 对应信号的处理方式有三种:捕获、忽略、默认
5> 对信号的处理函数:signal
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
1、一共可以发射62个信号,前32个是稳定信号,后面是不稳定信号
2、常用的信号
SIGHUP:当进程所在的终端被关闭后,终端会给运行在当前终端的每个进程发送该信号,默认结束进程
SIGINT:中断信号,当用户键入ctrl + c时发射出来
SIGQUIT:退出信号,当用户键入ctrl + /是发送,退出进程
SIGKILL:杀死指定的进程
SIGSEGV:当指针出现越界访问时,会发射,表示段错误
SIGPIPE:当管道破裂时会发送该信号
SIGALRM:当定时器超时后,会发送该信号
SIGSTOP:暂停进程,当用户键入ctrl+z时发射
SIGTSTP:也是暂停进程
SIGTSTP、SIGUSR2 :留给用户自定义的信号,没有默认操作
SIGCHLD:当子进程退出后,会向父进程发送该信号
3、有两个特殊信号:SIGKILL和SIGSTOP,这两个信号既不能被捕获,也不能被忽略4> 对应信号的处理方式有三种:捕获、忽略、默认
5> 对信号的处理函数:signal
cpp
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
功能:将信号与信号处理方式绑定到一起
参数1:要处理的信号
参数2:处理方式
SIG_IGN:忽略
SIG_DFL:默认,一般信号的默认操作都是杀死进程
typedef void (*sighandler_t)(int):用户自定义的函数
返回值:成功返回处理方式的起始地址,失败返回SIG_ERR并置位错误码
注意:只要程序与信号绑定一次,后续但凡程序收到该信号,对应的处理方式就会立即响应
cpp
#include<myhead.h>
//定义信号处理函数
void handler(int signo){
if(signo == SIGINT){
printf("用户键入了Ctrl + C\n");
}
}
int main(int argc, const char *argv[]){
/*1、尝试忽略SIGINT信号,SIG_INGN
if(signal(SIGINT, SIG_IGN) == SIG_ERR)
{
perror("signal error");
return -1;
}
*/
/*2、尝试捕获SIGINT信号
if(signal(SIGINT, handler) == SIG_ERR)
{
perror("signal error");
return -1;
}
*/
//3.尝试默认相关信号的操作
if(signal(SIGINT, SIG_DFL) == SIG_ERR)
{
perror("signal error");
return -1;
}
while(1){
printf("正在执行...\n");
sleep(1);
}
return 0;
}尝试捕获和忽略SIGKILL信号
cpp
#include<myhead.h>
//定义信号处理函数
void handler(int signo)
{
if(signo == SIGINT)
{
printf("用户键入了ctrl + c\n");
}
}
/*********************主程序*********************/
int main(int argc, const char *argv[])
{
/*1、尝试忽略SIGKILL信号,SIG_INGN,函数报错,错误原因参数不合法
if(signal(SIGKILL, SIG_IGN) == SIG_ERR)
{
perror("signal error");
return -1;
}*/
/*2、尝试捕获SIGINT信号,执行报错,错误原因参数不合法
if(signal(SIGKILL, handler) == SIG_ERR)
{
perror("signal error");
return -1;
}*/
/*3、尝试默认相关信号的操作,执行报错,错误原因参数不合法
if(signal(SIGKILL, SIG_DFL) == SIG_ERR)
{
perror("signal error");
return -1;
}*/
while(1)
{
printf("我真的还想再活五百年\n");
sleep(1);
}
return 0;
}6> 使用信号的方式完成对僵尸进程的回收
当进程退出后,会向父进程发送一个SIGCHLD的信号,当父进程收到该信号后,可以将其进程捕获,在信号处理函数中,可以以非阻塞的方式回收僵尸进程
cpp
#include<myhead.h>
//定义信号处理函数
void handler(int signo)
{
if(signo == SIGCHLD)
{
//回收僵尸进程
while(waitpid(-1, NULL, WNOHANG) > 0);
}
}
int main(int argc, const char *argv[]){
//当子进程退出后,会向父进程发送一个SIGCHLD的信号,无名可以将其捕获,在信号处理函数中,将子进程资源回收
if(signal(SIGCHLD, handler) == SIG_ERR){
perror("signal error");
return -1;
}
//创建10个僵尸进程
for(int i = 0; i < 10; i++){
if(fork() == 0){//当子进程创建出来后,立马扼杀在摇篮中
exit(EXIT_SUCCESS);
}
}
while(1);
return 0;
}7> 信号发送函数;kill、raise
cpp
#include <signal.h>
int kill(pid_t pid, int sig);
功能:向指定进程或进程组发送信号
参数1:进程号或进程组号
>0:表示向执行进程发送信号
=0:向当前进程所在的进程组中的所有进程发送信号
=-1:向所有进程发送信号
<-1:向指定进程组发送信号,进程组的ID号为给定pid的绝对值
参数2:要发送的信号
返回值:成功返回0,失败返回-1并置位错误码
#include <signal.h>
int raise(int sig);
功能:向自己发送信号 等价于:kill(getpid(), sig);
参数:要发送的信号
返回值:成功返回0,失败返回非0数组
cpp
#include<myhead.h>
//定义信号处理函数
void handler(int signo){
if(signo == SIGUSR1){
printf("逆子,何至于此!!!\n");
raise(SIGKILL); //向自己发送一个自杀信号 kill(getpid(),SIGKILL)
}
}
int main(int argc, const char *argv[]){
//将子进程发送的信号绑定在指定功能中
if(signal(SIGUSR1, handler) == SIG_ERR){
perror("signal error");
return -1;
}
//创建父子进程
pid_t pid = fork();
if(pid > 0){
//父进程
while(1){
printf("我真的还想再活500年\n");
sleep(1);
}
}else if(pid == 0){
//子进程
sleep(5);
printf("红尘已经看破, 叫上父亲一起die把\b");
kill(getppid(), SIGUSR1);//向自己的父亲进程发送了一个自定义的信号
exit(EXIT_SUCCESS);//退出进程
}
return 0;
}8> 总结:信号可以完成多个进程间通知作用,但是,不能进行数据传输功能
5、system V提供的进程间通信概述
1> 对于内核提供的三种通信方式,对于管道而言,只能实现单向的数据通信,对于信号通信而言,只能完成多进程之间消息的通知,不能起到数据传输的效果。为了解决上述问题,引入的系统V进程通信
2> system V提供的进程间通信方式分别是:消息队列、共享内容、信号量(信号灯集)
3> 有关system V进程间通信对象相关指令
bash
ipcs 可以查看所有的信息(消息队列、共享内存、信号量)
ipcs -q:可以查看消息队列的信息
ipcs -m:可以查看共享内存的信息
ipcs -s:可以查看信号量的信息
ipcrm -q/m/s ID :可以删除指定ID的IPC对象4> 上述的三种通信方式,也是借助内核空间完成的相关通信,原理是在内核空间创建出的对象容器,在进行进程间通信时,可以将信息放入对象中,另一个进程就可以从该容器中取数据了。
5> 与内核提供的管道、信号通信不同:system V的ipc对象实现了数据传递的容器与程序相分离,也就是说,即使程序已经结束,但是放入到容器中的数据依然存在,除非将容器手动删除。
6、消息队列
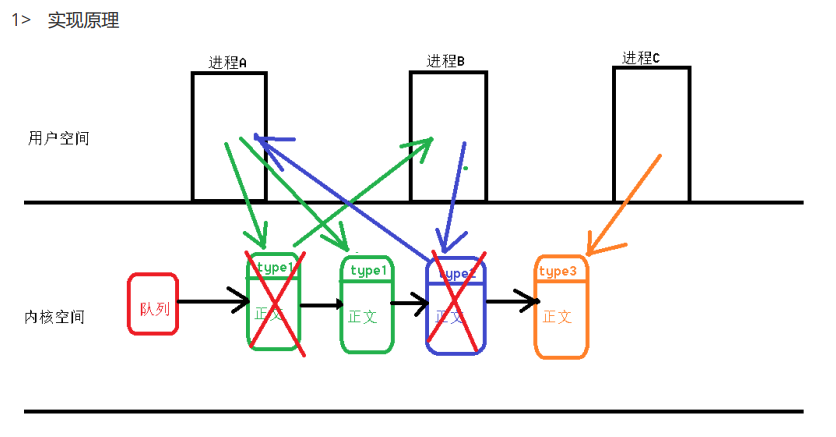
1> 实现原理
2> 消息队列实现的API
cpp
1、创建key值
#include<sys/types.h>
#include<sys/ipc.h>
key_t ftok(const char *pathname, int proj_id);
功能:通过给定的文件以及给定的一个随机值,创建出一个4字节整数的key值,拥有system V IPC对象的创建
参数1:一个文件路径,要求是已经存在的文件路径,提供了key值3字节的内容,其中,文件的设备号占1字节,文件的inode号占2字节
参数2:一个随机整数,取后8位(1字节)跟前面的文件共同组成key值,必须是非0的数字
返回值:成功返回key值,失败返回-1并置位错误码
2、通过key值,创建消息队列
#include<sys/types.h>
#include<sys/ipc.h>
#include<sys/msg.h>
int msgget(key_t key, int msgflg);
功能:通过给定的key值,创建出一个消息队列的对象,并返回消息队列的句柄ID,后期可以通过该ID操作整个消息队列
参数1:key值,该值可以是IPC_PRIVATE,也可以是ftok创建出来的,前者只用于亲缘进程间的通信
参数2:创建标示
IPC_CREAT:创建并打开一个消息队列,如果消息队列已经存在,则直接打开
IPC_EXCL:确保本次创建处理的上一个新的消息队列,如果消息队列已经存在,则报错,错误码位EEXIST
0644:该消息队列的操作权限
eg:IPC_CREAT|0644 或者 IPC_CREAT|IPC_EXCL|0644
返回值:成功返回消息队列的ID号,失败返回-1并置位错误码
3、向消息队列中存放数据
#include<sys/types.h>
#include<sys/ipc.h>
#include<sys/msg.h>
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
功能:向消息队列中存放一个指定格式的消息
参数1:打开的消息队列的id号
参数2:要发送的消息的起始地址,消息一般定义为一个结构体类型,由用户手动定义
struct msgbuf{
long mtype; /* message type, must be > 0 */ 消息的类型
char mtext[1];/* message data */ 消息正文
};
参数3:消息正文的大小
参数4:是否阻塞的标识
0:标识阻塞形式向消息队列中存放消息,如果消息队列满了,就在该函数处阻塞
IPC_NOWAIT:标识非阻塞的形式向消息队列中存放消息,如果队列满了,直接返回
返回值:成功返回0,失败返回-1并置位错误码
4、从消息队列中取信息
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
功能:从消息队列中取数指定类型的消息放入给定的容器中
参数1:打开的消息队列的id号
参数2:要接收的消息的起始地址,消息一般被定义为一个结构体类型,由用户手动定义
struct msgbuf{
long mtype;/* message type, must be > 0 */ 消息的类型
char mtext[1]; /* message data */ 消息正文
};
参数3:消息正文的大小
参数4:要接收的消息类型
0:表示每次都取消消息队列中的第一个消息,无论类型
>0:读取队列中第一个类型为msgtyp的消息
<0:读取队列中的一个消息,消息为绝对值小于msgtyp的第一个消息
eg: 10-->8-->3-->6-->5-->20-->2
-5: 会从队列中绝对值小于5的类型的消息中选取第一个消息,就是3
参数5:是否阻塞的标识
0:标识阻塞形式向消息队列中读取消息,如果消息队列空了,就在该函数处阻塞
IPC_NOWAIT:标识非阻塞的形式向消息队列中读取消息,如果消息队列空了,直接返回
返回值:成功返回实际读取的正文大小,失败返回-1并置位错误码
5、销毁消息队列
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
功能:对给定的消息队列执行相关的操作,该操作由cmd参数而定
参数1:消息队列的ID号
参数2:要执行的操作
IPC_RMID:删除一个消息队列,当cmd为该值时,第三个参数可以省略填NULL即可
IPC_STAT:表示获取当前消息队列的属性,此时第三个参数就是存放获取的消息队列属性
的容器起始地址
IPC_SET:设置当前消息队列的属性,此时第三个参数就是要设置消息队列的属性数据的起
始地址
3> 发送端实现
参数3:消息队列数据容器结构体,如果第二个参数为IPC_RMID,则该参数忽略填NULL即可,如果
是 IPC_STAT、 IPC_SET填如下结构体:
struct msqid_ds {
struct ipc_perm msg_perm; /* Ownership and permissions */
消息队列的拥有者和权限
time_t msg_stime; /* Time of last msgsnd(2) */ 最后
一次发送消息的时间
time_t msg_rtime; /* Time of last msgrcv(2) */ 最后
一次接收消息的时间
time_t msg_ctime; /* Time of last change */ 最后
一次状态改变的时间
unsigned long __msg_cbytes; /* Current number of bytes in queue
(nonstandard) */ 已用字节数
msgqnum_t msg_qnum; /* Current number of messages in
queue */ 消息队列中消息个数
msglen_t msg_qbytes; /* Maximum number of bytes allowed
in queue */最大消息个数
pid_t msg_lspid; /* PID of last msgsnd(2) */ 最后
一次发送消息的进程pid
pid_t msg_lrpid; /* PID of last msgrcv(2) */ 最后
一次读取消息的进程pid
};
该结构体的第一个成员类型如下:
struct ipc_perm {
key_t __key; /* Key supplied to msgget(2) */ key
值
uid_t uid; /* Effective UID of owner */ 当前进
程的uid
gid_t gid; /* Effective GID of owner */ 当前进
程的组ID
uid_t cuid; /* Effective UID of creator */ 消息队
列创建者的用户id
gid_t cgid; /* Effective GID of creator */ 消息队
列创建者的组id
unsigned short mode; /* Permissions */ 消息队
列的权限
unsigned short __seq; /* Sequence number */ 队列号
};
返回值:成功返回0,失败返回-1并置位错误码3> 发送端实现
cpp
#include<myhead.h>
//消息类型的定义
struct msgBuf{
long mtype;//消息的类型
char mtext[1024];//消息正文
}
#define MSGSZ (sizeof(struct msgBuf) - sizeof(long))//正文大小
int main(int argc, const char *argv[]){
//1.创建key值,拥有创建出一个消息队列
key_t key = ftok("/", 'k');
//参数1:已经存在的路径
//参数2:是一个随机值
if(key == -1){
perror("ftok error");
return -1;
}
printf("key = %#x\n", key);//输出键值
//2.通过key值创建出一个消息队列,并返回该消息队列的id
int msqid = -1;
if((msqid = msgget(key, IPC_CREAT|0664)) == -1){
perror("msgget error");
return -1;
}
printf("msggid = %d\n", msqid);//输出id号
//3.向消息队列中存放信息
//组建一个消息
struct msgBuf buf;
while(1){
printf("请输入消息的类型:");
scanf("ld", &buf.mtype);
getchar();
printf("请输入消息正文:");
fgets(buf.mtext, MSGSZ, stdin);//从终端输入数据
buf.mtext[strlen(buf.mtext) - 1] = '\0';//将换行更换成'\0'
//将上述组装的消息放入消息队列中,以阻塞的方式将其放入消息队列
msgsnd(msqid, &buf, MSGSZ, 0);
printf("消息存入成功\n");
//判断退出条件
if(strcmp(buf.mtext, "quit") == 0){
break;
}
}
return 0;
}4> 接收端实现
cpp
#include<myhead.h>
//消息类型的定义
struct msgBuf{
long mtype;//消息的类型
char mtext[1024];//消息正文
};
#define MSGSZ(sizeof(struct msgBuf) - sizeof(long))//正文的大小
int main(int argc, const char *argv[]){
//1.创建key值,用于创建出一个消息队列
keyh_t key = ftok("/", 'k');
//参数1:已经存在的路径
//参数2:是一个随机值
if(key == -1){
perror("ftok error");
return -1;
}
printf("key = %#x\n", key);//输出键值
//2.通过key值创建出一个消息队列,并返回该消息队列的id
int msqid = -1;
if((msqie = msgget(key, IPC_CREAT|0664)) == -1){
perror("msgget error");
return -1;
}
printf("msgqid = %d\n", msqid);//输出id号
//3.从消息队列中取信息
//组建一个消息
struct msgBuf buf;
while(1){
//清空容器
bzero(&buf, sizeof(buf));
//读取信息
msgrcv(msqid, &buf, MSGSZ, 1, 0);
//参数4:表示读取的消息类型
//参数5:表示是否阻塞读取
printf("读取到的消息为:%s\n", buf.mtext);
if(strcmp(buf.mtext, "quit") == 0){
break;
}
}
//4.删除消息队列
if(msgctl(msqid, IPC_RMID, NULL) == -1){
perror("msgctl error");
return -1;
}
return 0;
}5> 注意事项:
1、对于消息而言,由两部分组成:消息的类型和消息正文,消息结构体由用户自定义
2、对于消息队列而言,任意一个进程都可以向消息队列中发送信息,也可以从消息队列中取消息
3、多个进程,使用相同的key值打开的是同一个消息队列
4、对消息队列中的消息读取操作是一次性的,被读取后,消息队列中不存在该信息了。
5、消息队列的大小:16KB
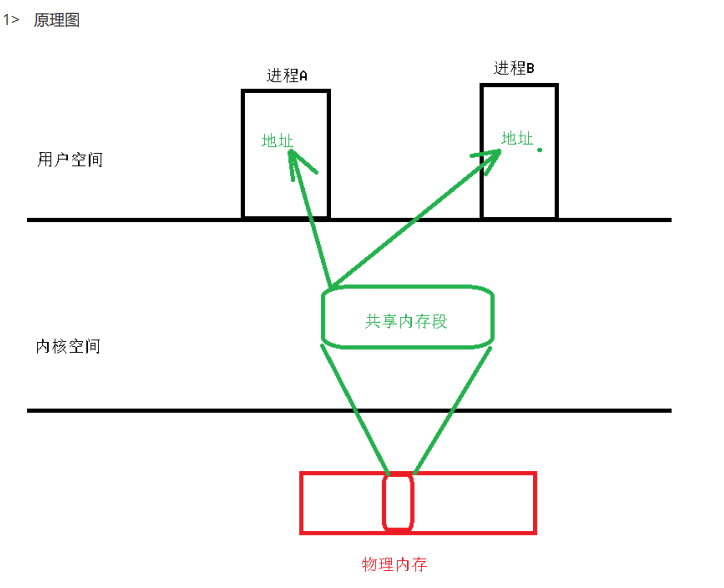
7、共享内存
1> 原理图
2> 共享内存的API
cpp
1、创建key值
#include<sys/types.h
#include<sys/ipc.h>
key_t ftok(const char *pathname, int proj_id);
功能:通过给定的文件以及给定的一个随机值,创建出一个4字节整数的key值,用于system V IPC对象的创建
参数1:一个文件路径,要求是已经存在的文件路径,提供了key值3字节的内容,其中,文件的设备号占字节,文件的inode号占2字节
参数2:一个随机整数,取后8位(1字节)跟前面的文件共同组成key值,必须是非0的数字
返回值:成功返回key值,失败返回-1并置位错误码
2、通过key值创建共享内存段
#include<sys/ipc.h>
#include<sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
功能:申请指定大小的物理内存,映射到内核空间,创建出共享内存段
参数1:申请的大小,可以是IPC------PRIVATE,也可以是ftok创建出来的key值
参数2:申请的大小,是一页(4096字节)的整数倍,并且向上取整
参数3:创建标识
IPC_CREAT:创建并打开一个共享内容,如果共享内存已经存在,则直接打开
IPC_EXCL:确保本次创建处理的是一个新的共享内存,如果共享内存已经存在,则报错,错误码位EEXIST
0664:该共享内存的操作权限
eg: IPC_CREAT|0664 或者 IPC_CREAT|IPC_EXCL|0664
返回值:成功返回共享内存段的id,失败返回-1并置位错误码
3、将共享内存段的地址映射到用户空间
#include<sys/types.h>
#include<sys/shm.h>
void *shmat(int shmid, const void *shmaddr, int shmflg);
功能:将共享内存段映射到用户空间
参数1:共享内存的id号
参数2:物理地址的起始地址,一般填NULL,由系统自动选择一个合适的对齐页
参数3:对共享内存段的操作
0:表示读写操作
SHM_RDONLY:只读
返回值:成功返回用于操作共享内存的指针,失败返回(void*)-1并置为错误码
4、释放共享内存的映射关系
int shmdt(const void *shmaddr);
功能:将进程与共享内存的映射取消
参数:共享内存的指针
返回值:成功返回0,失败返回-1并置位错误码
5、共享内存的控制函数
#include<sys/ipc.h>
#include<sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
功能:根据给定的不同的cmd执行不同的操作
参数1:共享内存的ID
参数2:要操作的指令
IPC_RMID:删除共享内存段,第三个参数可以省略
IPC_STAT:获取当前共享内容的属性
IPC_SET:设置当前共享内存的属性
参数3:如果参数2位IPC_RMID,则参数3可以省略填NULL,如果参数2为另外两个,参数3填如下结构体变量
struct shmid_ds {
struct ipc_perm shm_perm; /* Ownership and permissions */
size_t shm_segsz; /* Size of segment (bytes) */
time_t shm_atime; /* Last attach time */
time_t shm_dtime; /* Last detach time */
time_t shm_ctime; /* Last change time */
pid_t shm_cpid; /* PID of creator */
pid_t shm_lpid; /* PID of last shmat(2)/shmdt(2) */
shmatt_t shm_nattch; /* No. of current attaches */
...
};
该结构体的第一个成员结构体:
struct ipc_perm {
key_t __key; /* Key supplied to shmget(2) */
uid_t uid; /* Effective UID of owner */
gid_t gid; /* Effective GID of owner */
3> 发送端流程
uid_t cuid; /* Effective UID of creator */
gid_t cgid; /* Effective GID of creator */
unsigned short mode; /* Permissions + SHM_DEST and
SHM_LOCKED flags */
unsigned short __seq; /* Sequence number */
};
返回值:成功返回0,失败饭hi-1并置位错误码3> 发送端流程
cpp
#include<myhead.h>
#define PAGE_SIZE 4096//一页的大小
int main(int argc, const char *argv[]){
//1.创建key值
key_t key = ftok("/", 'k');
if(key == -1){
perror("ftok error");
return -1;
}
printf("key = %#x\n", key);//输出key值
//2.通过key值创建共享内存段
int shmid = -1;
if((shmid = shmget(key, PAGE_SIZE, IPC_CREAT|0664)) == -1){
perror("shmget error");
return -1;
}
printf("shmid = %d\n", shmid);
//3.将共享内存段映射到用户空间
char *addr = (char *)shmat(shmid, NULL, 0);
//NULL表示让系统自动寻找对齐页
//0表示对该共享内存段的操作是读写操作打开
if(addr == (void*) -1){
perror("shmat error");
return -1;
}
printf("addr = %p\n", addr);//输出共享内存段映射的地址
//4.对共享内存进程操作
while(1){
printf("请输入>>>");
fgets(addr, PAGE_SIZE, stdin);//从终端输入数据放入共享内存中
addr[strlen(addr) - 1] = 0;
if(strcmp(addr, "quit") == 0){
break;
}
sleep(5);//休眠5秒
printf("结束吧\n");
//5.取消映射
if(shmdt(addr) == -1){
perror("取消映射\n");
return -1;
}
}
return 0;
}4> 接受端流程
cpp
#include<myhead.h>
#define PAGE_SIZE 4096
int main(int argc, const char *argv[]){
//1.创建key值
key_t key = ftok("/", 'k');
if(key == -1){
perror("ftok error");
return -1;
}
printf("key = %#x\n", key);//输出key值
//2.通过key值创建共享内存段
int shmid = -1;
if((shmid = shmget(key, PAGE_SIZE, IPC_CREAT|0664)) == -1){
perror("shmget erorr");
return -1;
}
printf("shmid = %d\n", shmid);
//3.将共享内存映射到用户空间
char *addr = (char*) shmat(shmid, NULL, 0);
//NULL表示让系统自动寻找对齐页
//0表示对该共享内存段的操作是读写操作打开
if(addr == (void*) -1){
perror("shmat error");
return -1;
}
printf("addr = %p \n", addr);//输出共享内存段映射的地址
//4.对共享内存进行操作
while(1){
sleep(2);
printf("读取到消息为:%s\n", addr) //通过地址访问共享内存中的数据
if(strcmp(addr, "quit") == 0){
break;
}
}
//5.取消映射
if(shmat(addr) == -1){
perror("取消映射\n");
return -1;
}
//6、删除共享内存段
if(shmctl(shmid, IPC_RMID, NULL) == -1){
perror("shmctl error");
return -1;
}
return 0;
}5> 注意:
1、共享内存是多个进程共享同一个内存空间,使用时可能会产生竞态,为了解决整个问题,共享内存一般会跟信号量一起使用,完成进程的同步功能
2、共享内存VS消息队列,消息队列能够保证数据的不丢失性,而共享内存能够保证数据的时效性
3、对共享内存的读取操作不是一次性的,当读取后,数据依然存放在共享内存中
4、使用共享内存,跟正常使用指针是一样的,使用时,无需再进行用户空间与内核空间的切换了,所以说,共享内存是所有进程间通信方式中效率最高的一种通信方式。
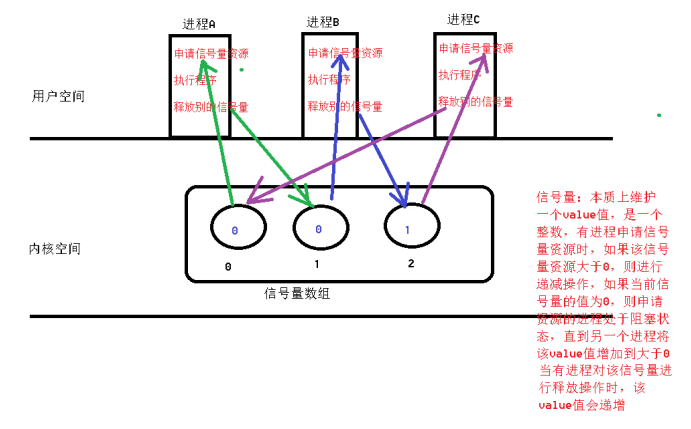
8、信号量(信号灯集)
1>原理图
2> 信号量相关API
cpp
*pathname, int proj_id); //ftok("/", 'k');
功能:通过给定的文件以及给定的一个随机值,创建出一个4字节整数的key值,用于system V
IPC对象的创建
参数1:一个文件路径,要求是已经存在的文件路径,提供了key值3字节的内容,其中,文件的设备
号占1字节,文件的inode号占2字节
参数2:一个随机整数,取后8位(1字节)跟前面的文件共同组成key值,必须是非0的数字
返回值:成功返回key值,失败返回-1并置位错误码
2、通过key值创建信号量集
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int semget(key_t key, int nsems, int semflg);
功能:通过给定的key值创建一个信号量集
参数1::key值,该值可以是IPC_PRIVATE,也可以是ftok创建出来的,前者只用于亲缘进程间的
通信
参数2:信号量数组中信号量的个数
参数3:创建标识
IPC_CREAT:创建并打开一个信号量集,如果信号量集已经存在,则直接打开
IPC_EXCL:确保本次创建处理的是一个新的信号量集,如果信号量集已经存在,则报错,错
误码位EEXIST
0664:该信号量集的操作权限
eg: IPC_CREAT|0664 或者 IPC_CREAT|IPC_EXCL|0664
返回值:成功返回信号量集的id,失败返回-1并置位错误码
3、关于信号量集的操作:P(申请资源)V(释放资源)
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int semop(int semid, struct sembuf *sops, size_t nsops);
功能:完成对信号量数组的操作
参数1:信号量数据ID号
参数2:有关信号量操作的结构体变量起始地址,该结构体中包含了操作的信号量编号和申请还是释
放的操作
struct sembuf
{
unsigned short sem_num; /* semaphore number */ 要操作的信号量的编号
short sem_op; /* semaphore operation */ 要进行的操作,大于0
表示释放资源,小于0表示申请资源
short sem_flg; /* operation flags */ 操作标识位,0标识阻塞方
式,IPC_NOWAIT表示非阻塞
}
参数3:本次操作的信号量的个数
返回值:成功返回0,失败返回-1并置位错误码
4、关于信号量集的控制函数
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int semctl(int semid, int semnum, int cmd, ...);
功能:执行有关信号量集的控制函数,具体控制内容取决于cmd
参数1:信号量集的ID
参数2:要操作的信号量的编号,编号是从0开始
参数3:要执行的操作
IPC_RMID:表示删除信号量集,cmd为该值时,参数2可以忽略,参数4可以不填
SETVAL:表示对参数2对应的信号量进行设置操作(初始值)
GETVAL:表示对参数2对应的信号量进行获取值操作
SETALL:设置信号量集中所有信号量的值
GETALL:获取信号量集中的所有信号量的值
IPC_STAT:表示获取当前信号量集的属性
IPC_SET:表示设置当前信号量集的属性、
参数4:根据不同的cmd值,填写不同的参数值,所以该处是一个共用体变量
union semun {
int val; /* Value for SETVAL */ 设置信号量的值
struct semid_ds *buf; /* Buffer for IPC_STAT, IPC_SET */ 关于
信号量集属性的操作
unsigned short *array; /* Array for GETALL, SETALL */ 对于信
号量集中所有信号量的操作
struct seminfo *__buf; /* Buffer for IPC_INFO
(Linux-specific) */
};
返回值:成功时:SETVAL、IPC_RMID返回0,GETVAL返回当前信号量的值,失败返回-1并置位
错误码
例如:
1) 给0号信号量设置初始值为1
union semun us; //定义一个共用体变量
us.val = 1; //对该共用体变量赋值
semctl(semid, 0, SETVAL, us); //该函数就完成了对0号信号量设置初始值为1的操作
2) 删除信号量集
semctl(semid, 0, IPC_RMID);3> 将上述函数进行二次封装,封装成为只有信号量的创建、申请资源、释放资源、销毁信号量集
sem.h
cpp
#ifndef _SEM_H_
#define _SEM_H_
//创建信号量集并初始化:semcount表示本次创建的信号量集中信号灯的个数
int create_sem(int semcount);
//申请资源操作,semno表示要被申请资源的信号量编号
int P(int semid, int semno);
//释放资源操作,semno表示要被释放资源的信号量编号
int V(int semid, int semno);
//删除信号量集
int delete_sem(int semid);
#endifsem.cpp
cpp
#include<myhead.h>
union semun {
int val; // 设置信号量的值
struct semid_ds *buf; //关于信号量集属性的操作
unsigned short *array; //对于信号量集中所有信号量的操作
struct seminfo *__buf; /* Buffer for IPC_INFO(Linux-specific)
*/
};
//定义一个关于对信号量初始化函数
int init_sem(int semid, int semno)
{
int val = -1;
printf("请输入第%d个信号量的初始值:", semno+1); //让用户输入信号量的初始值
scanf("%d", &val);
getchar(); //吸收回车,以免影响其他程序
//调用semctl完成设置
union semun us;
us.val = val;
if(semctl(semid, semno, SETVAL, us) == -1)
{
perror("semctl error");
return -1;
}
return 0;
}
//创建信号量集并初始化:semcount表示本次创建的信号量集中信号灯的个数
int create_sem(int semcount)
{
//1、创建key值
key_t key = ftok("/", 'k');
if(key == -1)
{
perror("ftok error");
return -1;
}
//2、通过key值创建信号量集
int semid = -1;
if((semid = semget(key, semcount, IPC_CREAT|IPC_EXCL|0664)) == -1)
{
if(errno == EEXIST) //表示信号量集已经存在,直接打开即可
{
semid = semget(key, semcount, IPC_CREAT|0664); //将信号量集直接打开
return semid;
}
perror("semget error");
return -1;
}
//3、循环将信号量集中的所有信号量进行初始化
//该操作,只有在第一次创建信号量集时需要进行操作,后面再打开该信号量集时,就无需进行初始化
操作了
for(int i=0; i<semcount; i++)
{
init_sem(semid, i); //调用自定义函数将每个信号量进行初始化
}
//将信号量集的id返回
return semid;
}
//申请资源操作,semno表示要被申请资源的信号量编号
int P(int semid, int semno)
{
//定义一个结构体变量
struct sembuf buf;
buf.sem_num = semno; //要操作的信号编号
buf.sem_op = -1; //-1表示要申请该信号量的资源
buf.sem_flg = 0; //表示阻塞形式进行申请
//调用semop函数完成资源的申请
if(semop(semid, &buf, 1) == -1)
{
perror("P error");
return -1;
}
return 0;
}
//释放资源操作,semno表示要被释放资源的信号量编号
int V(int semid, int semno)
{
//定义一个结构体变量
struct sembuf buf;
4> 使用信号量集完成共享内存中两个进程对共享内存使用的同步问题
shmsnd.cpp
buf.sem_num = semno; //要操作的信号编号
buf.sem_op = 1; //1表示要释放该信号量的资源
buf.sem_flg = 0; //表示阻塞形式进行释放
//调用semop函数完成资源的释放
if(semop(semid, &buf, 1) == -1)
{
perror("V error");
return -1;
}
return 0;
}
//删除信号量集
int delete_sem(int semid)
{
//调用semctl函数完成对该信号量集的删除
if(semctl(semid, 0, IPC_RMID) == -1)
{
perror("delete error");
return -1;
}
return 0;
}4> 使用信号量集完成共享内存中两个进程对共享内存使用的同步问题
shmsnd.cpp
cpp
#include<myhead.h>
#include"sem.h" //将自定义的头文件加入
#define PAGE_SIZE 4096 //一页的大小
int main(int argc, const char *argv[])
{
//11、创建并打开信号量集
int semid = create_sem(2); //调用自定义函数,完成对信号量集的创建
//1、创建key值
key_t key = ftok("/", 'k');
if(key == -1)
{
perror("ftok error");
return -1;
}
printf("key = %#x\n", key); //输出key值
//2、通过key值创建共享内存段
int shmid = -1;
if((shmid= shmget(key, PAGE_SIZE, IPC_CREAT|0664)) == -1)
{
perror("shmget error");
shmrcv.cpp
return -1;
}
printf("shmid = %d\n", shmid);
//3、将共享内存段映射到用户空间
char *addr = (char *)shmat(shmid, NULL, 0);
//NULL表示让系统自动寻找对齐页
//0表示对该共享内存段的操作是读写操作打开
if(addr == (void*)-1)
{
perror("shmat error");
return -1;
}
printf("addr = %p\n", addr); //输出共享内存段映射的地址
//4、对共享内存进行操作
while(1)
{
//22、调用自定义函数:申请0号信号量的资源
P(semid, 0);
printf("请输入>>>");
fgets(addr, PAGE_SIZE, stdin); //从终端输入数据放入共享内存中
addr[strlen(addr)-1] = 0;
//33、调用自定义函数:释放1号信号量的资源
V(semid, 1);
if(strcmp(addr, "quit") == 0)
{
break;
}
}
//5、取消映射
if(shmdt(addr) == -1)
{
perror("取消映射\n");
return -1;
}
//44、调用自定义函数:删除信号量集
delete_sem(semid);
return 0;
}shmrcv.cpp
cpp
#include<myhead.h>
#include"sem.h"
#define PAGE_SIZE 4096 //一页的大小
int main(int argc, const char *argv[])
{
//11、调用自定义函数:创建并打开信号量集
int semid = create_sem(2);
//1、创建key值
key_t key = ftok("/", 'k');
if(key == -1)
{
perror("ftok error");
return -1;
}
printf("key = %#x\n", key); //输出key值
//2、通过key值创建共享内存段
int shmid = -1;
if((shmid= shmget(key, PAGE_SIZE, IPC_CREAT|0664)) == -1)
{
perror("shmget error");
return -1;
}
printf("shmid = %d\n", shmid);
//3、将共享内存段映射到用户空间
char *addr = (char *)shmat(shmid, NULL, 0);
//NULL表示让系统自动寻找对齐页
//0表示对该共享内存段的操作是读写操作打开
if(addr == (void*)-1)
{
perror("shmat error");
return -1;
}
printf("addr = %p\n", addr); //输出共享内存段映射的地址
//4、对共享内存进行操作
while(1)
{
//22、调用自定义函数完成对1号信号量资源的申请
P(semid, 1);
printf("读取到消息为:%s\n", addr); //通过地址访问共享内存中的数据
if(strcmp(addr, "quit") == 0)
{
break;
}
//33、释放0号信号量的资源
V(semid, 0);
}
//5、取消映射
if(shmdt(addr) == -1)
{
perror("取消映射\n");
return -1;
}
//6、删除共享内存段
if(shmctl(shmid, IPC_RMID, NULL) == -1)
{
perror("shmctl error");
return -1;
}
return 0;
}5> 注意:
1、信号量集是完成多个进程间同步问题的,一般不进行信息的通信
2、信号量集的使用,本质上是对多个value值进行管控,每个信号量控制一个进程,在进程执行 前,申请一个信号量的资源,执行后,释放另一个信号量的资源
3、如果当前进程申请的信号量值为0,则当前进程在申请处阻塞,直到其他进程将该信号量中的 资源增加到大于0
6> 练习:进程1输出字符A,进程2输出字符B,进程3输出啊字符C,使用信号量集完成,最终输出的 结果为ABCABCABCABC...