一次 Ubuntu 内核升级翻车的完整排错记录:从 Kernel Panic 到锁定 6.14 内核

起因是一台 ThinkStation 工作站,某同学升级后,重启后死活进不去系统,报 Kernel Panic。最后定位到是有人把内核升级到了 6.17,而这个内核装残了。本文记录整个排查与修复过程,包括用第二个系统 chroot 救援、重建引导、最终通过 GRUB 配置锁定到稳定的 6.14 内核。
一、问题现象
机器是一台 ThinkStation PX-1,原本系统跑在一块 NVMe 固态上,运行良好。某次重启后,系统直接黑屏报错:
KERNEL PANIC!
Please reboot your computer.
VFS: Unable to mount root fs on unknown-block(0,0)重启无数次都是这个结果,进不去桌面。
好在这台机器上还有第二个系统,现场运维老师反馈说他们通过第二个系统启动了,让我们看看(装在另一块 SATA 盘 sda 上),可以正常启动。于是排查就从第二个系统里开始。
二、第一步:搞清楚硬盘和系统的布局
进入第二个系统后,先看磁盘结构。发现只剩一个用户,这说明这不是我们之前熟悉的系统,是一个新系统,下一步查看挂载

先用 lsblk -f 看全局:
bash
lsblk -f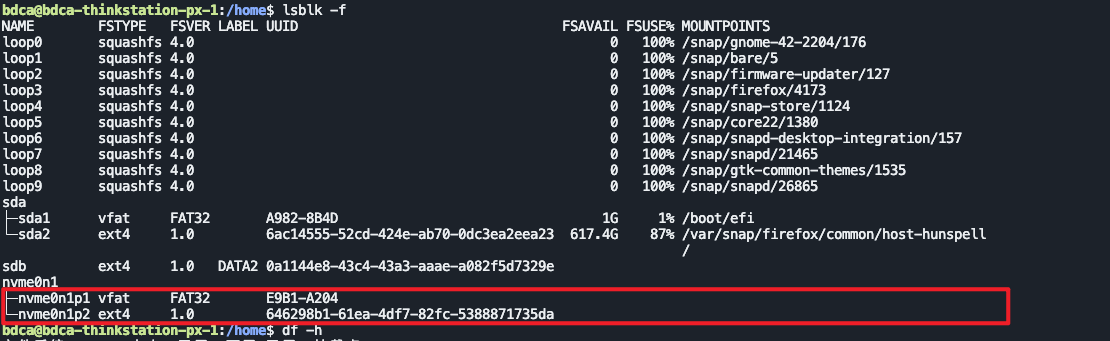
(可以看到,我们的nvme0n1这个盘是没有挂载的)
关键输出(省略 snap 的 loop 设备):
sda
├─sda1 vfat FAT32 A982-8B4D /boot/efi
└─sda2 ext4 1.0 6ac14555-... / ← 当前第二系统
sdb ext4 1.0 DATA2 0a1144e8-... ← 数据盘
nvme0n1
├─nvme0n1p1 vfat FAT32 E9B1-A204 ← 旧系统 EFI 分区
└─nvme0n1p2 ext4 1.0 646298b1-... ← 旧系统根分区再看挂载情况:
bash
df -h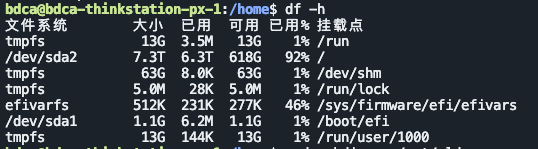
/dev/sda2 7.3T 6.3T 618G 92% /
/dev/sda1 1.1G 6.2M 1.1G 1% /boot/efi那我们有把握相信:
- 当前运行的第二系统在
sda2,它的/home和/在同一分区,里面只有bdca一个用户------所以/home只有一个目录是正常的。 - 旧系统还在 NVMe 盘 上:
nvme0n1p1(EFI)+nvme0n1p2(根分区,UUID646298b1-...),是一套完整的系统结构,只是当前没挂载而已。
也就是说,旧系统和数据都没丢,问题出在"启动"环节,而不是"数据"环节。 这个判断让后面的修复方向明确了:去修引导/内核,而不是去恢复数据。
💡 经验:遇到"目录里东西不见了"的恐慌时,先别下结论。
lsblk -f+df -h看清楚到底挂载了哪块盘、哪些盘没挂载,很多"数据丢失"其实只是"没挂载所以看不见"。
三、第二步:理解 Kernel Panic 报错的含义
VFS: Unable to mount root fs on unknown-block(0,0)这行报错的意思是:内核起来了,但找不到/挂载不了根文件系统 。(0,0) 这个块设备号表示内核根本没识别到任何根分区。常见原因有三类:
- initramfs(初始内存盘)损坏或丢失 ------ 缺少驱动磁盘所需的内核模块,导致内核看不到 NVMe 盘;
- GRUB 里的
root=参数 UUID 不对; - 内核或 initramfs 文件本身损坏。
考虑到旧系统是 NVMe 盘,第 1 种(initramfs 缺 NVMe 驱动)嫌疑最大。于是决定用 chroot 进旧系统重建 initramfs 和引导。
四、第三步:chroot 进旧系统进行救援
chroot 的思路是:用能正常工作的第二系统作为"操作平台",把旧系统的根分区挂载进来,再"切根"进去,就好像在旧系统内部操作一样。
4.1 挂载旧系统的分区

bash
sudo mkdir -p /mnt/old
sudo mount /dev/nvme0n1p2 /mnt/old
# 确认这是旧系统
ls /mnt/old # 应看到 bin boot etc home usr var ...
确认无误后,挂载 EFI 分区和 chroot 必需的虚拟文件系统:
bash
# 旧系统的 EFI 分区
sudo mount /dev/nvme0n1p1 /mnt/old/boot/efi
# 绑定挂载系统虚拟目录
sudo mount --bind /dev /mnt/old/dev
sudo mount --bind /proc /mnt/old/proc
sudo mount --bind /sys /mnt/old/sys
sudo mount --bind /run /mnt/old/run
sudo mount --bind /dev/pts /mnt/old/dev/pts4.2 切进旧系统

bash
sudo chroot /mnt/old执行成功后,命令行就处于"旧系统内部"了。
4.3 重建 initramfs、更新并重装 GRUB
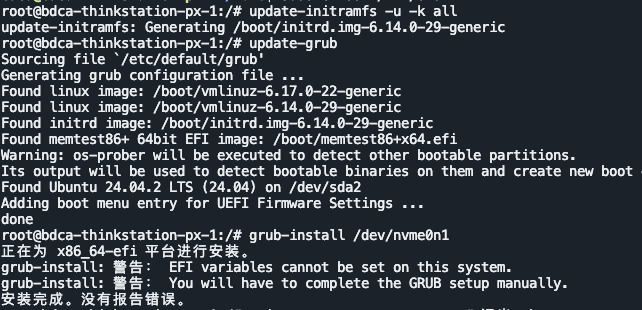
bash
# 重建所有内核的 initramfs
update-initramfs -u -k all
# 重新生成 GRUB 配置
update-grub
# 重装 GRUB 引导(注意:目标是整块盘 nvme0n1,不是分区!)
grub-install /dev/nvme0n1⚠️ 关于
grub-install /dev/nvme0n1会不会破坏数据?不会。它只往两个地方写东西:① EFI 分区里的引导文件;② 磁盘开头的引导扇区(UEFI 下基本忽略)。都是"引导相关"区域,不碰分区里的用户数据。 但两个铁律:目标盘符必须写对 (绝不能误写成正在用的 sda,否则会毁掉第二系统的引导);必须写整块盘 (
nvme0n1,不带p1/p2)。
4.4 grub-install 的一个警告
执行 grub-install 时出现:
grub-install: 警告: EFI variables cannot be set on this system.
grub-install: 警告: You will have to complete the GRUB setup manually.
安装完成。没有报告错误。这个警告在 chroot 环境里很常见,不代表失败。 含义是:引导文件已成功写入 EFI 分区,但没能往主板 UEFI 固件的 NVRAM 里更新启动项记录------因为 chroot 环境下访问 UEFI 变量的接口(efivarfs)没有正确传入。
实际影响通常不大:UEFI 有标准回退路径 EFI/BOOT/BOOTX64.EFI,而且旧系统原本的启动项往往还在,重启时在 BIOS 启动菜单里直接选 NVMe 盘即可。
4.5 退出并卸载
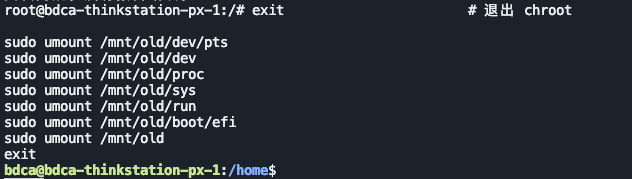
bash
exit
sudo umount /mnt/old/dev/pts
sudo umount /mnt/old/dev
sudo umount /mnt/old/proc
sudo umount /mnt/old/sys
sudo umount /mnt/old/run
sudo umount /mnt/old/boot/efi
sudo umount /mnt/old然后重启,开机按 F12 进启动菜单,选择从 NVMe 盘启动。
五、第四步:重启后的真相------问题根本不在引导
重启后,在 GRUB 菜单里手动选择 Ubuntu, with Linux 6.14.0-29-generic,系统正常进去了!
但如果让它走默认项,依然 panic。这时真相浮出水面:
旧系统本身没坏,是有人把内核升级到了 6.17,而这个 6.17 内核有问题。GRUB 默认又总是选最新内核,所以一重启就默认进 6.17 然后崩溃。
看一眼 GRUB 菜单结构来确认:
bash
sudo grep -E "menuentry '|submenu '" /boot/grub/grub.cfg
输出(节选):
menuentry 'Ubuntu' ... 'gnulinux-simple-646298b1-...'
submenu 'Advanced options for Ubuntu' ... {
menuentry 'Ubuntu, with Linux 6.17.0-22-generic' ...
menuentry 'Ubuntu, with Linux 6.17.0-22-generic (recovery mode)' ...
menuentry 'Ubuntu, with Linux 6.14.0-29-generic' ...
menuentry 'Ubuntu, with Linux 6.14.0-29-generic (recovery mode)' ...
}可以看到:
- 旧系统根分区 UUID 是
646298b1-...(NVMe),正确; - 6.17 和 6.14 都收在 "Advanced options for Ubuntu" 子菜单里;
- 顶层那个
'Ubuntu'(gnulinux-simple)默认指向最新内核,也就是 6.17------这就是默认崩溃的根源。
💡 关于
GRUB_DEFAULT=0的常见误解:0指的是顶层菜单的第 0 项 ,也就是那个'Ubuntu'简单入口,而它内部被设定为"自动抓最新内核"。所以不是"排序第一恰好是 6.17",而是"第 0 项这个入口永远指向最新的内核"。系统装了 6.17,它就指向 6.17。
六、第五步:让默认启动锁定到 6.14
既然 6.14 能正常用,先把 GRUB 默认项改成 6.14,保证重启自动进稳定内核。
bash
sudo nano /etc/default/grub修改这三行:
GRUB_DEFAULT="Advanced options for Ubuntu>Ubuntu, with Linux 6.14.0-29-generic"
GRUB_TIMEOUT_STYLE=menu
GRUB_TIMEOUT=5说明:
GRUB_DEFAULT用 "子菜单名>菜单项名" 的完整路径精确定位 6.14,名称必须和grep出来的完全一致;- 原本配置是
GRUB_TIMEOUT_STYLE=hidden+GRUB_TIMEOUT=0,意味着菜单完全隐藏、0 秒直接进默认项。强烈建议改成显示菜单 + 等 5 秒,这样万一以后又出问题,开机还有机会手动选别的内核,不至于又得走 chroot 救援。
保存退出(nano:Ctrl+O 回车,Ctrl+X),然后务必执行:
bash
sudo update-grub一个意外但关键的发现
update-grub 的输出里藏着真正的病根:
Found linux image: /boot/vmlinuz-6.17.0-22-generic
Found linux image: /boot/vmlinuz-6.14.0-29-generic
Found initrd image: /boot/initrd.img-6.14.0-29-generic注意:6.17 和 6.14 都有内核镜像(vmlinuz),但 initrd(初始内存盘)只找到了 6.14 的,6.17 根本没有!
所以最初的 Unable to mount root fs:6.17 内核缺 initramfs ,启动时加载不了 NVMe 驱动,自然找不到根分区。即便之前在 chroot 里跑过 update-initramfs -u -k all,6.17 的 initrd 仍然没生成出来------说明 6.17 这个内核包本身就装残了。
这也说明:之前的 chroot 修复并非白做 ------grub-install 把引导修好了,让机器能正常进入 NVMe 的 GRUB 菜单;只是当时没意识到崩溃的真正原因是"默认进了坏内核",所以体感上"好像没生效"。真正解决问题的,是后面这步改 GRUB_DEFAULT + update-grub。
七、结果与后续加固
改完 GRUB_DEFAULT 并 update-grub 后重启------开机显示菜单、5 秒后自动进入 6.14、系统正常。问题解决。✅
八、总结与经验
这次排错的完整链条:
| 阶段 | 现象/动作 | 结论 |
|---|---|---|
| 表象 | 重启 Kernel Panic,Unable to mount root fs |
内核找不到根分区 |
| 定位环境 | lsblk -f + df -h |
旧系统在 NVMe,数据都在,问题在启动层 |
| 救援尝试 | 用第二系统 chroot,重建 initramfs + grub-install | 引导修好,但默认仍崩 |
| 真相 | 手动选 6.14 能进;update-grub 显示 6.17 缺 initrd |
病根是 6.17 内核装残 + GRUB 默认选最新内核 |
| 解决 | 改 GRUB_DEFAULT 锁定 6.14 + update-grub |
重启自动进 6.14,问题解决 |
| 加固 | purge 6.17 + apt-mark hold 锁内核 | 除根 + 防复发 |
几条值得记住的经验:
- "看不到数据"不等于"数据丢了" ,先用
lsblk -f/df -h看清挂载关系。 - 有第二个可用系统时,chroot 是极强的救援手段,但要分清你修的是"引导问题"还是"内核问题"。
Unable to mount root fs八成和 initramfs/内核有关 ,update-grub输出里"有 vmlinuz 没 initrd"是极有价值的线索。- 内核升级是高风险操作 ,生产机器升级前应保留旧内核,并在确认新内核稳定前用
GRUB_DEFAULT锁定旧内核 +apt-mark hold防止自动升级。 - 别把 GRUB 菜单设成完全隐藏 + 0 秒,留个 5 秒菜单,关键时刻能救命。
完。如果你也遇到内核升级后开机 Kernel Panic,希望这篇能帮你少走弯路。