写在前面

欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师/开发工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
AIGC时代的 《三年面试五年模拟》AI算法工程师/开发工程师求职面试秘籍独家资源: 【三年面试五年模拟】AI算法工程师面试秘籍
Rocky最新撰写AI Agent(AI智能体)的深入浅出全维度解析文章: 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
大家好,我是Rocky。
核心导读
这篇论文表面上是在讲一个很"工程"的问题:如何让 Stable Diffusion 生成得更快、更省显存。Rocky 认为,它真正有价值的地方不只是把采样速度提高到最高约 2 × 2\times 2×、把显存降到最高约 5.6 × 5.6\times 5.6×,而是给出了一个更底层的判断:生成式模型里的很多 token 并不是同等必要的,推理成本可以从"无差别处理所有 token"转向"动态保留足够信息"。
这和 Flash Attention、xFormers 这类优化不在同一个层面。Flash Attention 和 xFormers 主要是在更高效地执行同一件事;Token Merging for Stable Diffusion 则试图让模型少做一部分重复工作。前者优化算子,后者改变 token 流量。对 AIGC 工程来说,这个差别很关键:算子优化会被框架吸收,但 token 级冗余利用是一类更通用的推理加速思想。
论文的核心结论可以压缩成一句话:在不重新训练 Stable Diffusion 的前提下,把空间上相似、语义上冗余的 token 合并,等计算完成后再"解合并"回原 token 位置,可以在较小质量损失下显著降低 U-Net Transformer block 的计算量;但要让它真的可用,必须解决扩散生成作为密集预测任务带来的三个问题:怎么 unmerge、怎么划分 src/dst token、以及应该在 U-Net 的哪些模块和哪些尺度上合并。

图 1 是整篇论文的产品化入口:同一张 2048 × 2048 2048 \times 2048 2048×2048 图,在原始模型中需要 150 秒,xFormers 降到 52 秒,而 xFormers + ToMe 降到 28 秒。这个例子并不能单独证明"所有场景都能 5.4 倍加速",但它清楚说明了 ToMe 的定位:它不是替代 xFormers,而是和 xFormers 叠加,因为它减少的是进入后续计算的 token 数量。
问题背景:作者到底想解决什么
Stable Diffusion 的成本来自一个很朴素的事实:扩散模型不是一次前向就出图,而是在多个 denoising step 中反复调用 U-Net;而 U-Net 里又包含 Transformer-based blocks。只要分辨率升高,token 数量就会上升,attention 的计算压力会迅速变重。换句话说,高分辨率 AIGC 的体验瓶颈,不只是"模型大",更是"每一步都要对所有空间 token 做完整计算"。
已有加速路线大多在做"把同一件事做得更快"。Flash Attention 通过 IO-aware 的方式减少 attention 中的内存访问瓶颈,xFormers 提供更快的 Transformer 组件实现,PyTorch 2.0 也把部分高性能 attention 能力吸收到框架里。这些方法非常重要,但它们没有改变一个事实:模型仍然评估每一个 token。
论文切入点正是在这里:自然图像和生成图像都存在大量冗余。天空、背景、纹理区域、重复结构里的 token 不一定都值得用同等计算预算处理。如果能把相似 token 临时合并,就可能减少计算量。这里要注意,作者没有选择 token pruning,而是选择 token merging。这个选择不是细节,而是整篇论文成立的前提:Stable Diffusion 是密集预测任务,最终每个空间位置都要输出噪声估计;如果直接删掉 token,很多位置就丢了信息,图像结构很快崩。
核心思路:用一句主线串起来
这篇论文的主线可以这样理解:把 Stable Diffusion U-Net 里的空间 token 看成一个动态可压缩的信息场,在计算前把相似 token 合并以减少开销,在计算后把合并结果广播回原位置,以尽量保持密集预测所需的空间完整性。
这个思路有三个层次。第一层是算法假设:相似 token 合并后造成的误差可控,因为它们本来就相似。第二层是扩散适配:分类模型可以一路减少 token,但扩散模型需要每个位置的预测,所以必须 unmerge。第三层是工程选择:ToMe 不能粗暴应用到所有模块、所有层、所有 step;真正有效的设计是把它主要放在 self-attention,并优先作用于 token 数最多的 U-Net block。
| 维度 | 论文做法 | Rocky 解读 |
|---|---|---|
| 加速对象 | Stable Diffusion v1.5 的 U-Net Transformer block | 把扩散模型的主要推理瓶颈拆到 token 级,而不是只依赖底层算子优化 |
| 是否训练 | 不需要重新训练 | 这是工程落地价值最大的点,意味着已有模型、已有权重、已有工作流可以直接受益 |
| 核心机制 | merge 相似 token,计算后 unmerge | "临时降分辨率"不是粗暴缩图,而是在特征空间中做局部信息压缩 |
| 主要风险 | 内容变化、细节损失、prompt adherence 未被 FID 完整衡量 | 这类方法更适合可容忍轻微细节变化的生成场景,不适合对空间精确性极敏感的任务 |
方法展开:沿着论文原始逻辑拆解
从 Stable Diffusion 的 U-Net block 看 ToMe 应该插在哪里
Stable Diffusion 的 U-Net block 里包含 self-attention、cross-attention 和 MLP。self-attention 处理图像 token 之间的空间关系,cross-attention 把文本 prompt 条件注入图像生成过程,MLP 则做通道维度上的特征变换。ToMe 的目标是在这些模块执行前减少 token 数,从而降低计算量。
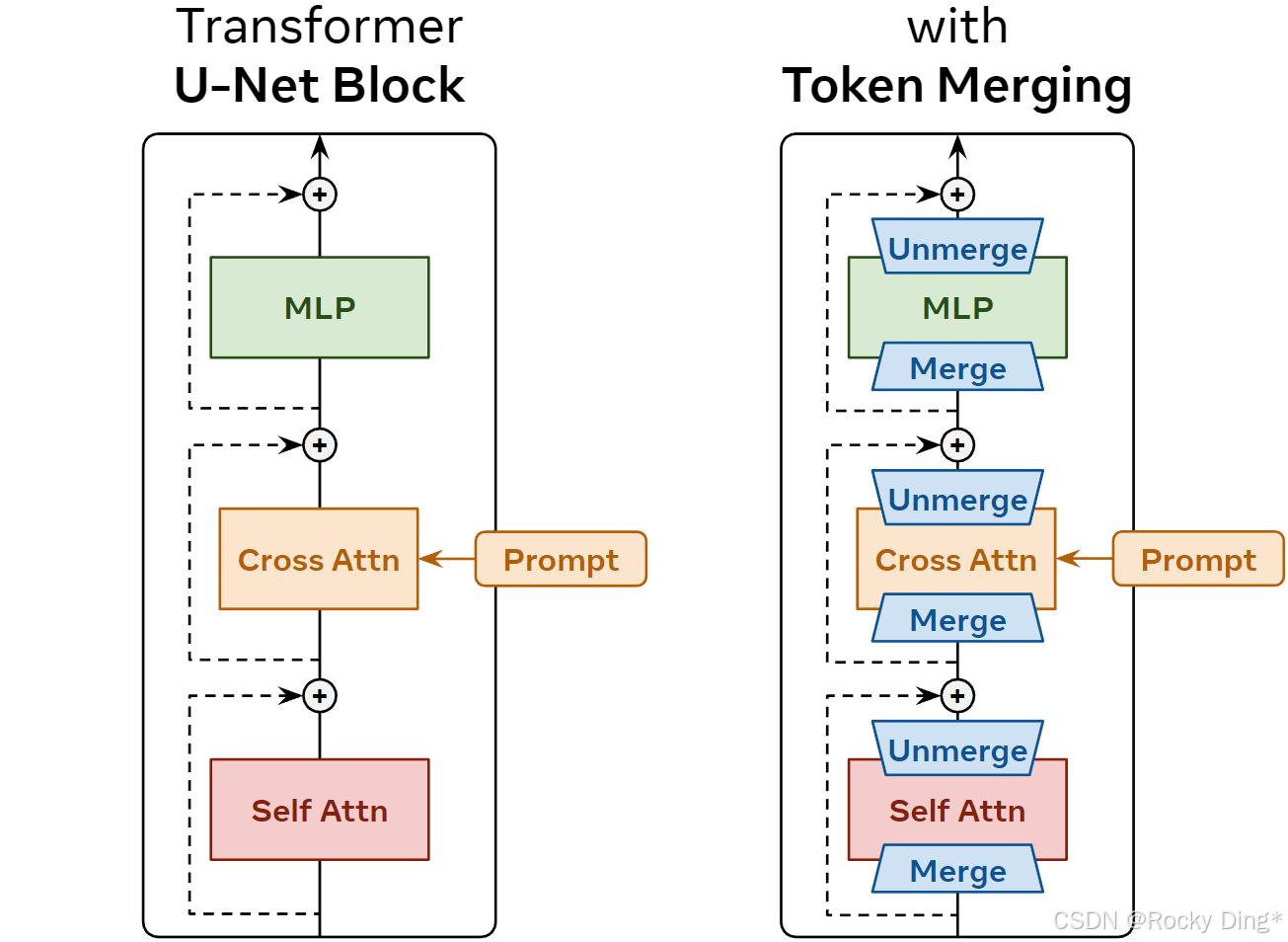
图 2 展示了作者最初的插入方式:在 block 内部各组件计算前 merge,计算后 unmerge,再进入残差连接。这张图背后的关键不是"多插几个 merge/unmerge 模块",而是一个密集预测任务的约束:扩散模型最后仍然需要每个 token 位置的噪声预测,所以 token 不能永久消失。ToMe 在这里更像"临时计算压缩",不是"永久结构裁剪"。
这也解释了为什么把 ViT 分类里的 ToMe 直接搬过来不够。分类任务最后可能只关心一个 class token 或全局表示,空间 token 的永久减少可以被模型结构吸收;扩散生成则需要每个空间位置都回到输出网格。论文把这个差异转化为 unmerge 机制。
unmerge:为什么"合并"比"剪枝"更适合扩散生成
作者给出了最简单的 unmerge 定义。假设两个 c c c 维 token x 1 , x 2 ∈ R c x_1, x_2 \in \mathbb{R}^{c} x1,x2∈Rc 足够相似,将它们合并为一个 token:
公式(1):
x 1 , 2 ∗ = ( x 1 + x 2 ) / 2 x_{1,2}^{*}=(x_1+x_2)/2 x1,2∗=(x1+x2)/2
计算完成后,再把这个合并后的 token 复制回两个原始位置:
公式(2):
x 1 ′ = x 1 , 2 ∗ , x 2 ′ = x 1 , 2 ∗ x_1'=x_{1,2}^{*},\qquad x_2'=x_{1,2}^{*} x1′=x1,2∗,x2′=x1,2∗
这个定义非常朴素,甚至有点"粗"。它确实会损失信息,因为 x 1 x_1 x1 和 x 2 x_2 x2 不可能完全相同。但论文的判断是:如果 merge 时只选择足够相似的 token,那么误差可控;相比直接 pruning 把 token 置零,merging 至少保留了局部信息的平均表达。

图 3 很重要,因为它没有只展示成功案例。朴素 ToMe 在 token reduction 比例升高时,图像整体仍然像一张完整图片,但内容会发生明显变化。这说明"合并 token"本身能够维持视觉连贯性,却不保证语义内容稳定。对生成模型而言,这个差别很微妙:图像看起来没坏,不等于模型保持了同一个生成意图。

图 4 则把 merging 和 pruning 的差异讲得更直接。如果直接把 token 剪掉并用 0 替代,图像质量快速崩坏。这里的本质是:扩散生成不是一个可以随便丢空间位置的分类问题,它需要空间连续性。Merging 至少保留了被合并区域的平均信息,而 pruning 是把局部证据清空。
表 1 是朴素方案的量化结果:
| Method | r% | FID ↓ | s/im ↓ | GB/im ↓ |
|---|---|---|---|---|
| Baseline | 0 | 33.12 | 3.09 | 3.41 |
| ToMe (Naive) | 10 | 33.14 | 2.60 | 2.99 |
| ToMe (Naive) | 20 | 33.53 | 2.29 | 2.17 |
| ToMe (Naive) | 30 | 33.60 | 2.11 | 1.71 |
| ToMe (Naive) | 40 | 34.67 | 1.81 | 1.26 |
| ToMe (Naive) | 50 | 38.95 | 1.53 | 0.89 |
表 1 的结论非常清楚:朴素 ToMe 的速度和显存收益是真的, 50 % 50\% 50% reduction 时每张图从 3.09 秒降到 1.53 秒,显存从 3.41 GB 降到 0.89 GB;但 FID 从 33.12 恶化到 38.95。Rocky 认为这一步其实是论文最诚实的地方:作者证明了 token redundancy 的存在,但也承认"存在冗余"不等于"随便合并都没事"。
src/dst 划分:生成任务里,空间采样方式会改变内容稳定性
ToMe 的基础操作是把 token 分成 source set 和 destination set,再把 source 中最相似的 token 合并到 destination。原始 ToMe 默认用交替方式划分 src/dst。这个策略在 ViT 分类里问题不大,但在 Stable Diffusion 中会形成规则的列状结构;当 reduction 比例很高时,相当于沿某个方向损伤了图像空间分辨率。
作者的改进是从二维空间结构出发:先尝试 stride 方式选择 dst,再进一步引入 randomness,最后采用"每个 2 × 2 2\times2 2×2 区域随机选择一个 dst token"的方法。这里最有意思的是 classifier-free guidance 的细节:prompted sample 和 unprompted sample 需要用同样的随机划分,否则 guidance 两路信号对应不上,质量会明显下降。
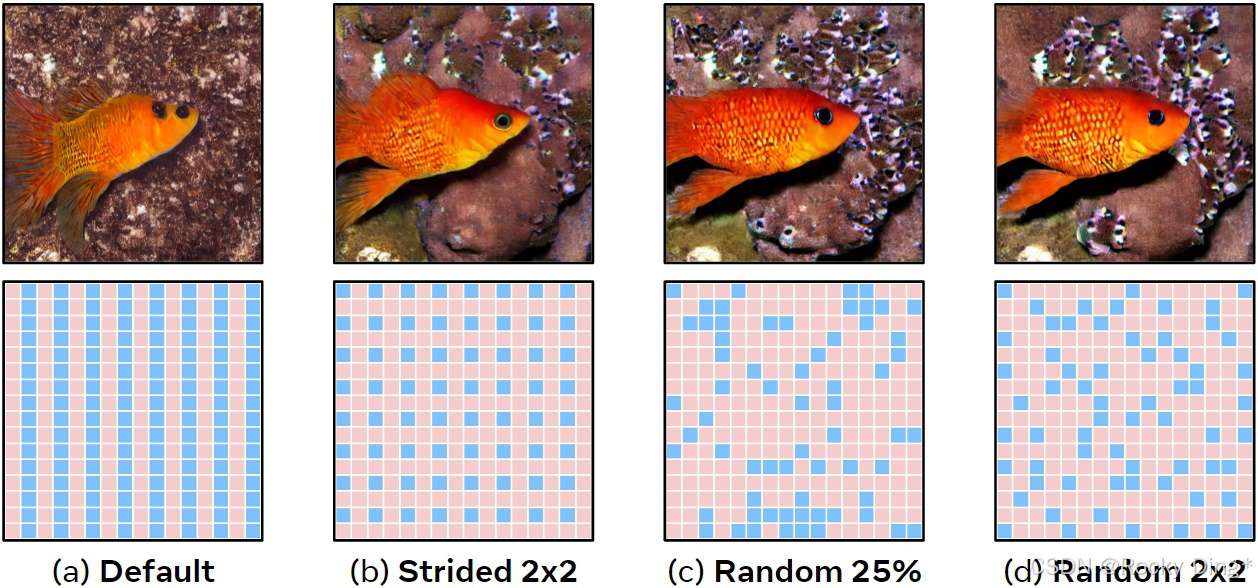
图 5 展示了四种划分方式。默认交替划分会形成规则列;stride 2 × 2 2\times2 2×2 改善了空间覆盖,但仍然是固定网格;完全随机会带来局部 clump;最终的 random 2 × 2 2\times2 2×2 在规则覆盖和随机性之间折中。这个设计很像工程里常见的一类好解法:不是追求纯随机,也不是完全规则,而是在局部约束下引入随机,避免系统性偏差。
表 2 对 partition 策略做了量化:
| Strided s y × s x s_y \times s_x sy×sx | dst% | FID ↓ |
|---|---|---|
| 1 × 2 1\times2 1×2 | 50 | 38.95 |
| 2 × 1 2\times1 2×1 | 50 | 39.28 |
| 2 × 2 2\times2 2×2 | 25 | 36.12 |
| 2 × 4 2\times4 2×4 | 12.5 | 37.09 |
| 4 × 2 4\times2 4×2 | 12.5 | 37.14 |
| 4 × 4 4\times4 4×4 | 6.25 | 38.97 |
| Random method | fix randomness across batch | FID ↓ |
|---|---|---|
| rand 25% | no | 46.08 |
| rand 25% | yes | 36.00 |
| rand 2 × 2 2\times2 2×2 | yes | 35.66 |

表 2 的关键不是某一个数字,而是两个机制判断。第一,二维结构比一维交替更适合图像 token;第二,CFG 下的两路样本必须共享 partition randomness。后者是很多论文摘要里不会强调、但工程实现里很容易踩坑的细节。
设计实验:ToMe 应该作用在什么模块、什么层、什么时间
在有了 random 2 × 2 2\times2 2×2 partition 之后,论文继续问三个工程问题:What、Where、When。
第一个问题是 ToMe 应该作用到哪些模块。作者比较 self-attention、cross-attention、MLP 的组合后发现,只作用在 self-attention 上是更好的速度-质量折中。这个结果很符合直觉:self-attention 负责图像 token 之间的空间冗余建模,最适合做 token 合并;cross-attention 直接承载 prompt 条件,如果合并不当,可能破坏文本条件对空间位置的控制;MLP 虽然也耗时,但 token 合并收益没有 self-attention 那么干净。
第二个问题是应该作用在哪些层。U-Net 不同尺度的 block token 数不同,深层低分辨率 block 的 token 已经很少,对它们做 merging 的收益有限,甚至可能引入不必要误差。因此论文发现,只在 token 数最多的 block 上应用 ToMe,可以保留大部分速度收益,同时改善 FID。
第三个问题是应该在扩散过程的什么时候 merge。作者测试了 early step 多 merge、late step 少 merge 的 schedule,发现确实略有改善,但收益不够大,最终没有把它作为复杂默认策略。
表 3 汇总了这组设计实验:
| self attn | cross attn | mlp | FID ↓ | s/im ↓ |
|---|---|---|---|---|
| yes | yes | yes | 35.66 | 1.56 |
| yes | no | yes | 36.10 | 1.57 |
| yes | no | no | 33.73 | 1.64 |
| no | no | yes | 34.70 | 2.81 |
| min tokens | blocks | FID ↓ | s/im ↓ |
|---|---|---|---|
| 64 | 15 (all) | 35.66 | 1.56 |
| 256 | 14 | 35.71 | 1.55 |
| 1024 | 9 | 34.37 | 1.56 |
| 4096 | 4 | 33.29 | 1.63 |
| r% start | r% end | FID ↓ | s/im ↓ |
|---|---|---|---|
| 70 | 30 | 35.89 | 1.65 |
| 60 | 40 | 35.53 | 1.58 |
| 50 | 50 | 35.66 | 1.56 |
| 40 | 60 | 36.09 | 1.58 |
| 30 | 70 | 36.45 | 1.61 |
Rocky 认为,表 3 的启发比表面数字更大:推理加速不是把一个 trick 全局打满,而是要知道模型结构里哪些部分真正有冗余,哪些部分承载条件控制,哪些部分的 token 数已经不值得优化。很多 AIGC 工程优化失败,不是因为没有加速方法,而是因为把优化当成全局开关,而不是结构化预算分配。
实验与证据:结果能支撑到什么程度
论文的评测设置是:使用 Stable Diffusion v1.5 生成 2,000 张 512 × 512 512\times512 512×512 ImageNet-1k 类别图像,每类 2 张;采样使用 50 PLMS steps,CFG scale 为 7.5;FID 在这 2,000 张样本和 5,000 张 ImageNet-1k validation 样本之间计算;速度是在单张 4090 GPU 上对 2,000 张样本取平均。
这个设置足够说明 ToMe for SD 在作者设定下的速度、显存和 FID 趋势,但也要看到它的边界:FID 不直接衡量 prompt adherence,也不能充分衡量局部细节、文本渲染、人物一致性、可控生成等现代 AIGC 工作流更关心的指标。因此,论文中的"质量接近"主要应该理解为在 ImageNet 类别生成和 FID 评价下接近,而不是对所有文生图场景无条件接近。
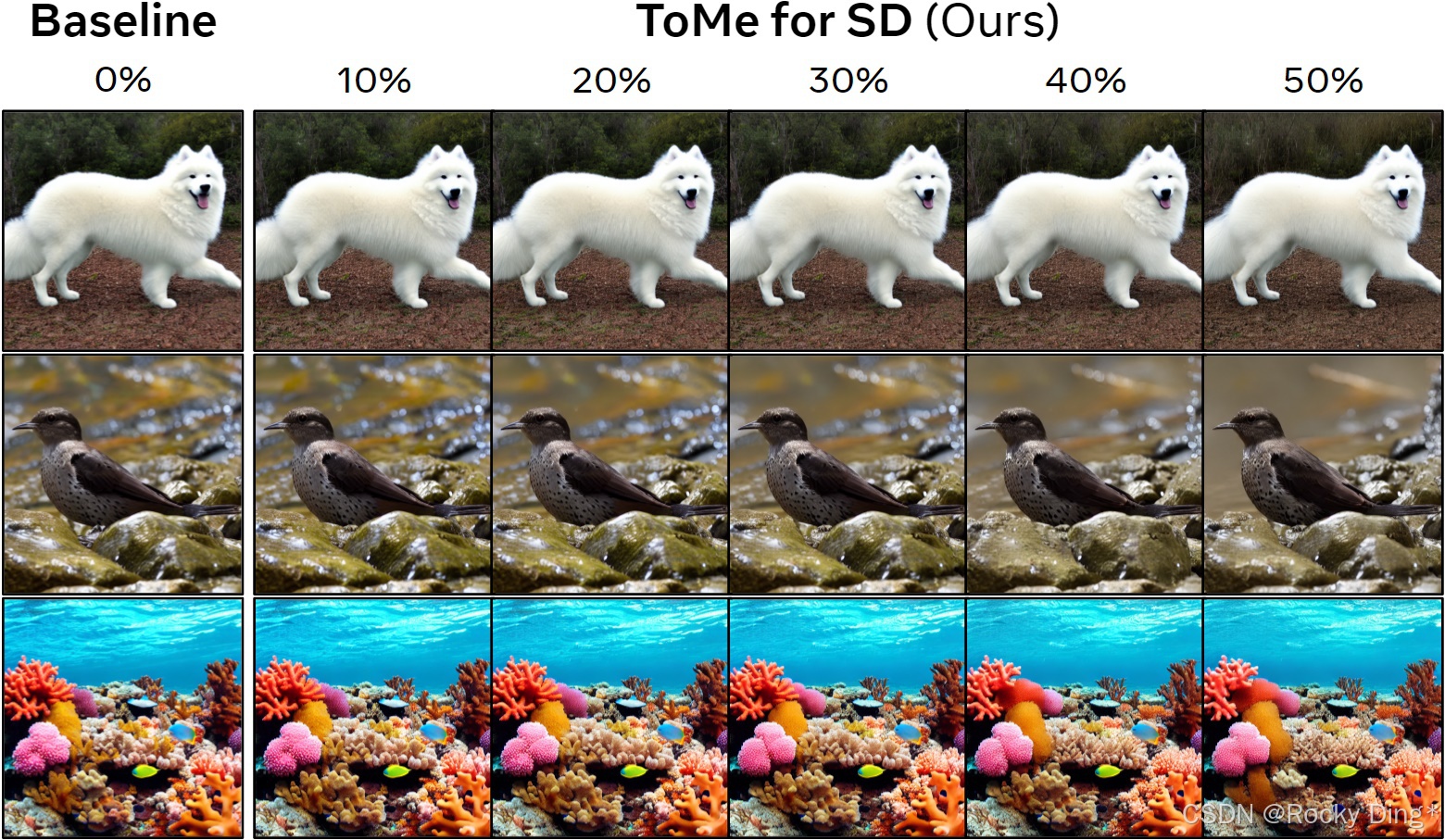
图 6 展示了最终方法的可视化效果。和图 3 的朴素版本相比,改进后的 ToMe for SD 更能保持 baseline 的主体和构图;但作者也指出,某些背景和细节仍会丢失。对产品落地来说,这意味着它适合作为"速度/成本优先"的可调开关,而不是在所有高精度生成任务里默认拉满。
最终量化结果如下:
| Method | r% | FID ↓ | s/im ↓ | GB/im ↓ |
|---|---|---|---|---|
| Baseline | 0 | 33.12 | 3.09 | 3.41 |
| ToMe for SD | 10 | 32.86 | 2.56 | 2.99 |
| ToMe for SD | 20 | 32.86 | 2.29 | 2.17 |
| ToMe for SD | 30 | 32.80 | 2.06 | 1.71 |
| ToMe for SD | 40 | 32.87 | 1.85 | 1.26 |
| ToMe for SD | 50 | 33.02 | 1.65 | 0.89 |
| ToMe for SD | 60 | 33.37 | 1.52 | 0.60 |
表 4 是整篇论文最强的证据。和 baseline 相比, 60 % 60\% 60% token reduction 时,FID 从 33.12 到 33.37,速度从 3.09 秒/图到 1.52 秒/图,显存从 3.41 GB 到 0.60 GB。这里的显存收益尤其值得注意,因为它可能把某些本来跑不动或 batch 很小的场景变成可运行。
但 Rocky 会给这个结论加一个限定:FID 接近不等于用户感知完全等价。图像生成系统的真实质量往往是多指标合成:主体一致性、风格稳定性、细节保真、prompt adherence、负面提示遵循、ControlNet/IP-Adapter 等外部控制链路的稳定性,都可能受到 token 合并影响。论文证明了 ToMe 是一个有价值的底层加速方向,但没有证明它在所有复杂生产工作流中都可以无脑开启。
与 xFormers 叠加:为什么这不是又一个算子优化
作者还专门测试了 ToMe 和 xFormers 的叠加。这个实验的意义在于区分两类优化:xFormers 优化的是 Transformer 计算实现,ToMe 优化的是参与计算的 token 数。一个是"算得更快",一个是"少算一些"。因此二者天然可以叠加。

图 7 展示了更激进配置下的速度收益:在 2048 × 2048 2048\times2048 2048×2048 生成中,作者展示了 28 秒、20 秒、18 秒等不同速度档位。但图里也能看到一个现实边界:越激进,细节损失越明显;而且当 ToMe 已经减少了足够多的 transformer token 后,剩余耗时会越来越多来自 ToMe 控制不了的模块,继续加速的边际收益下降。
这对工程团队很重要。很多推理优化在早期看起来都有线性收益,但一旦主要瓶颈被削掉,系统瓶颈就会转移。ToMe 对高分辨率图更显著,因为 token 规模足够大;对小图,扩散模型的其他部分可能成为瓶颈,叠加收益就没有那么夸张。论文还指出,ToMe 和 xFormers 的显存收益并没有同样叠加,这说明实际部署不能只看单点 benchmark,而要看完整推理栈的瓶颈迁移。

图 8 给出更多 60 % 60\% 60% token merged 的示例。它支撑了论文的一个实践判断:在很多自然图像类别上,大比例 token 合并仍能保持主体视觉一致。但"most of the time"也很诚实,它暗示方法不是严格等价变换,而是带有概率性质量风险的近似加速。
这篇工作的边界与可复现性
这篇论文的可复现性相对不错:作者明确给出了代码仓库,实验模型是 Stable Diffusion v1.5,采样设置、FID 计算方式、样本数量和 GPU 类型也有披露。方法本身不需要重新训练,这降低了复现门槛。
但边界同样明确。
第一,unmerge 策略很简单,只是把合并 token 复制回原位置。这个方法成立依赖"被合并 token 足够相似"这一假设。一旦场景里存在高频细节、边界、文字、局部结构、人物五官或强控制条件,简单复制可能不够。
第二,论文主要使用 FID 做量化指标,而 FID 对 prompt adherence 不敏感。作者自己也提到,cross-attention 合并可能降低 prompt adherence,但 FID 未必能反映出来。这一点在今天的文生图系统里尤其关键,因为用户不是只要"像 ImageNet 的自然图",而是要"符合我这个复杂 prompt 的图"。
第三,方法在不同模型架构上的泛化还需要重新验证。Stable Diffusion v1.5 的 U-Net block 结构、latent resolution、attention 分布和后续 SDXL、DiT、Rectified Flow 或多模态扩散 Transformer 并不完全一样。ToMe 的思想可以迁移,但默认参数不应该直接照搬。
第四,工程链路里还要考虑组合问题。现代 AIGC 工作流常常叠加 ControlNet、LoRA、IP-Adapter、Tiled Diffusion、高清修复、区域重绘等模块。ToMe 是否影响控制信号、风格一致性和局部编辑稳定性,需要单独评测。
如果继续研究/落地,应该关注什么
Rocky 认为,这篇工作最大的后续价值不是把 Stable Diffusion v1.5 再快一点,而是把"token 预算"变成生成模型推理系统里的显式资源。
第一,可以研究更好的 unmerge。简单复制是最低成本方案,但不一定是最优。未来可以探索基于局部结构、attention map、uncertainty 或 denoising timestep 的自适应 unmerge,让高风险位置恢复更多差异信息,低风险位置继续共享计算。
第二,可以让 merge ratio 随内容动态变化。论文使用固定比例或简单 schedule,但真实图像里的冗余不是均匀分布的。天空和背景可以更激进,人物脸部、文字、边缘和小目标应该更保守。真正产品化的 ToMe 可能不是一个全局滑杆,而是一个空间自适应预算器。
第三,评测体系需要从 FID 走向工作流指标。对今天的 AIGC 产品,至少应补充 prompt adherence、CLIP score、局部细节保真、OCR/text rendering、人脸一致性、ControlNet 条件遵循、LoRA 风格保持,以及用户偏好评测。否则速度收益可能掩盖细节退化。
第四,ToMe 可以和更上层的产品策略结合。比如草图预览、批量灵感探索、低成本多候选生成,可以使用更高 merge ratio;最终出图、人物精修、商业交付,可以降低 merge ratio 或关闭 ToMe。这种"质量-成本档位"才是推理优化真正进入产品的方式。
术语与概念速查
| 术语 | 解释 |
|---|---|
| Token Merging / ToMe | 将相似 token 合并以减少 Transformer 计算量的方法,原始工作主要面向 ViT 分类,本文将其适配到 Stable Diffusion |
| Stable Diffusion | 基于 latent diffusion 的图像生成模型,通过 U-Net 多步去噪生成图像 |
| U-Net block | Stable Diffusion 去噪网络中的基础模块,包含 self-attention、cross-attention、MLP 等组件 |
| self-attention | 图像 token 之间互相建模空间关系的 attention,本文发现它是最适合应用 ToMe 的模块 |
| cross-attention | 将文本 prompt 条件注入图像 token 的模块,合并不当可能影响 prompt adherence |
| src/dst partition | ToMe 中把 token 分成 source 与 destination,再把 source token 合并到 destination token 的划分策略 |
| unmerge | 在计算后把合并 token 恢复到原始 token 位置的操作,是 ToMe 适配扩散密集预测任务的关键 |
| CFG | Classifier-free guidance,扩散模型中常见的提示引导机制,通常同时计算 prompted 和 unprompted 两路信号 |
| FID | Fréchet Inception Distance,常用于衡量生成图像分布与真实图像分布距离,但不能完整衡量 prompt adherence 和局部可控性 |
| xFormers | 高性能 Transformer 组件库,优化计算实现;与 ToMe 的 token 数减少可以叠加 |
拓展思考:值得继续扩展研究与思考的创新点
这篇论文放到今天看,仍然有跨周期价值。原因不在于某个具体数字,而在于它抓住了生成模型推理优化的一条长期主线:模型能力越来越强,调用成本也越来越重要;当算子优化逐渐被框架吸收,下一阶段的效率竞争会转向动态计算、token 预算、条件计算和任务自适应推理。
Rocky 认为,ToMe for Stable Diffusion 可以给 AI 工程团队三个提醒。
第一,不要只盯着模型参数量。很多时候,用户感知到的慢,来自推理路径里的重复计算。能否识别冗余、跳过冗余、压缩冗余,是生成式系统从 demo 走向产品的关键能力。
第二,不要把加速和质量看成单一开关。真正成熟的产品应该有多档策略:快速预览、普通生成、高质量出图、精修交付。ToMe 这类方法天然适合成为推理策略的一部分,而不是一个固定默认值。
第三,工具红利最终会被吸收,判断能力会留下来。今天 xFormers、Flash Attention、PyTorch attention、ToMe、TensorRT、量化、蒸馏都可能成为工程工具箱的一部分。但更重要的是判断:什么模块能压缩,什么模块不能动;什么指标能说明质量,什么指标会误导;什么场景追求速度,什么场景必须保真。
这也是这篇短论文最值得学习的地方。它不是提出一个宏大的新模型,而是在一个已经广泛使用的模型上,用非常克制的方式证明了一件事:AIGC 的推理成本里有结构性冗余,而结构性冗余可以被算法识别、被工程利用、被产品分层消化。 这类工作不一定最热闹,但很容易变成基础设施的一部分。
推荐阅读
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)
1. 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2025年可以说是AI Agent全面落地应用的元年,因此Rocky在持续撰写对AI Agent的全维度解析文章:深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2. 深入浅出完整解析扩散模型DDPM、DDIM、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
和Rocky一起学习探究扩散模型的本质原理与和核心基础知识,同时不断跟进扩散模型的最新发展。Rocky在本文中对扩散模型的本质做了全面系统的梳理与讲解:深入浅出完整解析扩散模型DDPM、DDIM、SDE、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
3. 深入浅出完整解析FLUX.2、Seedream(即梦)、Z-image、GLM-Image核心基础知识
https://zhuanlan.zhihu.com/p/1975174691049189562
4. 深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
5. 深入浅出完整解析DeepSeek系列核心基础知识
6、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,从0到1训练自己的AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:深入浅出完整解析Sora、Wan2.1、AnimateDiff、CogVideoX等AI视频大模型核心基础知识
7、Stable Diffusion 3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识
8、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
9、Stable Diffusion 1.x-2.x核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:深入浅出完整解析Stable Diffusion(SD)核心基础知识
10、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1训练自己的ControlNet模型,从0到1上手构建ControlNet商业变现应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
ControlNet文章地址:深入浅出完整解析ControlNet核心基础知识
11、LoRA系列模型核心原理,核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
LoRA文章地址:深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知识
12、深入浅出完整解析AIGC时代Transformer核心基础知识
在AIGC时代中,Transformer为AI行业带来了深刻的变革。Transformer架构正在一步一步重构所有的AI技术方向,成为AI技术架构大一统与多模态整合的关键核心基座,大有一统"AI江湖"之势。Rocky也对Transformer模型进行持续的深入浅出梳理与解析:
Transformer文章地址:深入浅出完整解析AIGC时代Transformer核心基础知识
13、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布!
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:手把手教你成为AIGC算法工程师,斩获AIGC算法offer!
14、50万字大汇总《"三年面试五年模拟"之算法工程师的求职面试"独孤九剑"秘籍》文章正式发布!
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能多多star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
15、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:深入浅出完整解析主流AI绘画框架(ComfyUI、Stable Diffusion WebUI、Fooocus)核心基础知识
16、GAN网络核心基础知识,网络架构,GAN经典变体模型,经典应用场景,GAN在AIGC时代的商业应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
17. AI算法工程师的《三年面试五年模拟》求职秘籍
18. AIGC产业的深度思考与分析
2023年3月21日,微软创始人比尔·盖茨在其博客文章《The Age of AI has begun》中表示,自从1980年首次看到图形用户界面(graphical user interface)以来,以OpenAI为代表的科技公司发布的AIGC模型是他所见过的最具革命性的技术进步。
Rocky也认为,AIGC及其生态,会成为AI行业重大变革的主导力量。AIGC会带来一个全新的红利期,未来随着AIGC的全面落地和深度商用,会深刻改变我们的工作、生活、学习以及交流方式,各行各业都将被重新定义,过程会非常有趣。
那么,在此基础上,我们该如何更好的审视AIGC的未来?我们该如何更好地拥抱AIGC引领的革新?Rocky准备从技术、产品、商业模式、长期主义等维度持续分享一些个人的核心思考与观点,希望能帮助各位读者对AIGC有一个全面的了解: