Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第五章 Functions(函数)
程序员在 Python 中使用的第一个组织工具就是函数。与其他编程语言一样,函数可使你将大型程序分解为更小、更简单的组成部分,并为每个部分赋予名称以表示其功能。这有助于提高代码的可读性,使其更加易于理解。同时,函数还支持代码的复用和重构。
Python 中的函数拥有多种附加特性,这些特性使程序员的编程工作变得更加轻松。其中一些特性与其他编程语言中的功能相似,但许多特性是 Python 所独有的。这些附加功能能够使函数的接口更加清晰明了。它们能够消除冗余信息,强化调用者的意图。此外,它们还能显著减少那些难以发现的细微错误。
Item 36:使用 None 和文档字符串指定动态默认参数
有时,使用函数调用、新创建的对象或容器类型(如空列表)作为关键字参数的默认值会很有帮助。例如,假设我想打印标有已记录事件时间的日志消息。在默认情况下,我希望消息包含调用函数的时间。我可能会尝试以下方法,该方法假设每次调用函数时都会重新评估 when 这个关键词参数的默认值:
from time import sleep
from datetime import datetime
def log(message, when=datetime.now()):
print(f"{when}: {message}")
log("Hi there!")
sleep(0.1)
log("Hello again!")
>>>
2024-06-28 22:44:32.157132: Hi there!
2024-06-28 22:44:32.157132: Hello again!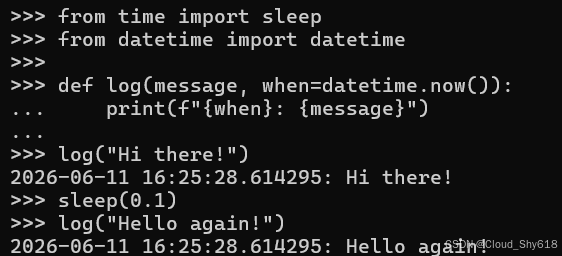
结果与预期不符。时间戳相同是因为 datetime.now() 仅被执行一次:即在函数定义于模块导入的那个时候。默认参数值在每个模块加载时仅被评估一次,这通常发生在程序启动时(详情请见 Item 98:"使用动态导入实现懒加载模块以缩短启动时间")。在包含此代码的模块被加载后,datetime.now() 中的默认参数表达式将再也不会被评估。
在 Python 中实现预期结果的惯用方法是提供默认值为 None 的选项,并在文档字符串中说明实际行为(有关信息,请参阅 Item 118:"为每个函数、类和模块编写文档字符串")。当代码检测到参数值为 None 时,便会相应地分配默认值:
def log(message, when=None):
"""Log a message with a timestamp.
Args:
message: Message to print.
when: datetime of when the message occurred.
Defaults to the present time.
"""
if when is None:
when = datetime.now()
print(f"{when}: {message}")现在时间戳将有所不同:
log("Hi there!")
sleep(0.1)
log("Hello again!")
>>>
2024-06-28 22:44:32.446842: Hi there!
2024-06-28 22:44:32.551912: Hello again!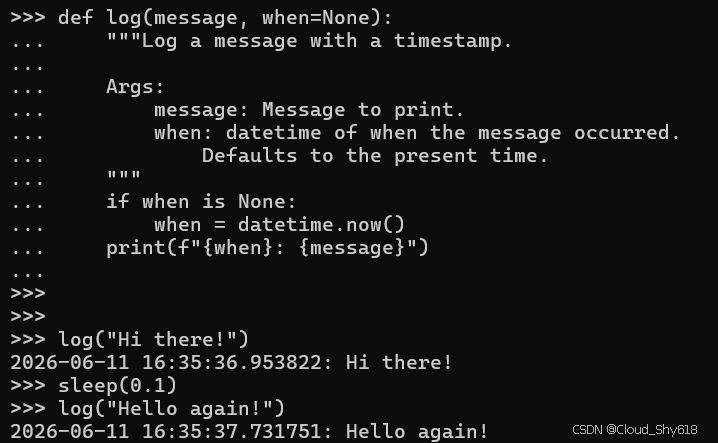
在参数为可修改类型的情况下,使用 None 作为默认参数值显得尤为重要。例如,假设我想要加载一个以 JSON 数据形式编码的值;如果解码数据失败,我希望系统能默认返回一个空字典:
import json
def decode(data, default={}):
try:
return json.loads(data)
except ValueError:
return default这里的问题与上面提到的 datetime.now 示例中的问题类似。为默认值指定的字典将适用于所有对 decode 函数的调用,因为默认参数值仅会被评估一次(即在模块加载时)。这可能导致极其出人意料的行为:
foo = decode("bad data")
foo["stuff"] = 5
bar = decode("also bad")
bar["meep"] = 1
print("Foo:", foo)
print("Bar:", bar)
>>>
Foo: {'stuff': 5, 'meep': 1}
Bar: {'stuff': 5, 'meep': 1}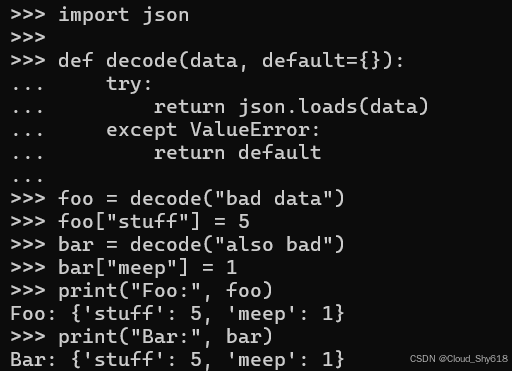
你或许会预想会有两个不同的字典,每个字典都包含一个键和对应的值。但修改其中一个似乎也会同时影响到另一个。罪魁祸首在于 foo 和 bar 都等同于 decode 函数中的默认参数。它们实际上是同一个字典对象:
assert foo is bar解决方法是将关键字参数的默认值设为 None,在函数的文档说明中注明实际的默认值,并在函数体中根据参数值为 None 的情况采取相应处理方式:
def decode(data, default=None):
"""Load JSON data from a string.
Args:
data: JSON data to decode.
default: Value to return if decoding fails.
Defaults to an empty dictionary."""
try:
return json.loads(data)
except ValueError:
if default is None: # Check here
default = {}
return default现在,运行与之前相同的测试代码会得出预期的结果:
foo = decode("bad data")
foo["stuff"] = 5
bar = decode("also bad")
bar["meep"] = 1
print("Foo:", foo)
print("Bar:", bar)
assert foo is not bar
>>>
Foo: {'stuff': 5}
Bar: {'meep': 1}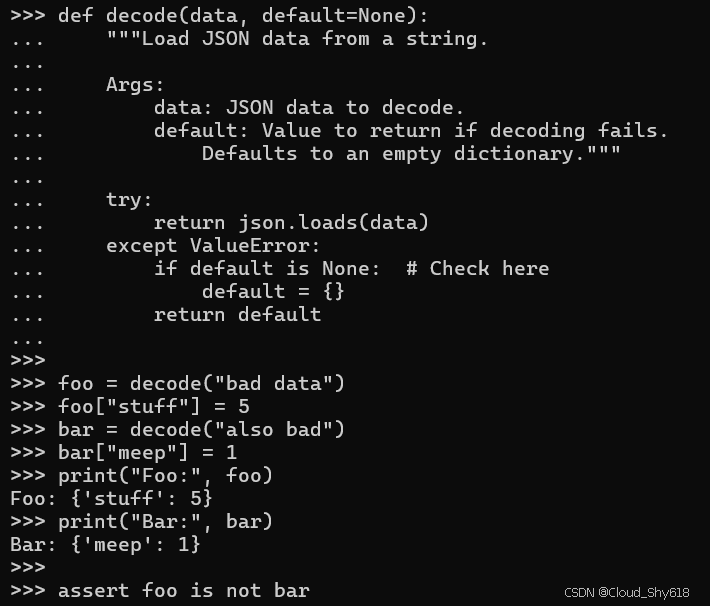
这种方法同样适用于类型注解(参见 Item 124:"考虑通过类型分析来规避错误")。在此处,当参数被标记为有可选值且该值为一个 datetime 对象。因此,when 参数仅有的两个有效选择为 None 或一个 datetime 对象:
def log_typed(message: str, when: datetime | None = None) -> None:
"""Log a message with a timestamp.
Args:
message: Message to print.
when: datetime of when the message occurred.
Defaults to the present time.
"""
if when is None:
when = datetime.now()
print(f"{when}: {message}")注意:
- 默认参数值仅会被评估一次:即在函数定义时、模块加载期间进行。这可能会导致动态值(如函数调用、新创建的对象及容器类型)出现异常行为。
- 将 None 作为关键字参数的占位符默认值,该参数的实际默认值必须由动态方式初始化。在函数的文档字符串中说明该参数的预设默认值。在函数体中检查是否存在 None 参数值,以触发正确的默认行为。
- 使用 None 来表示关键字参数默认值的做法,在带有类型注解的情况下也能正确运行。
Item 37:通过仅使用关键词和仅使用位置参数来增强清晰度
通过关键字传递参数是 Python 函数的一项强大特性(参见 Item 35:"使用关键字参数提供可选行为")。关键字参数使您能够编写出具有灵活性的函数,这些函数对于代码的新读者来说在许多使用场景中都会显得十分清晰明了。例如,假设我想要对一个数进行除法运算,同时需要对特殊情况进行格外谨慎的处理。有时,我想忽略 "除零错误" 异常并返回无穷大;而有时则想忽略 "溢出错误" 异常并返回零。在此处,我定义了一个具备这些选项的函数:
def safe_division(
number,
divisor,
ignore_overflow,
ignore_zero_division,
):
try:
return number / divisor
except OverflowError:
if ignore_overflow:
return 0
else:
raise
except ZeroDivisionError:
if ignore_zero_division:
return float("inf")
else:
raise使用此函数非常简单。下面的调用会忽略因除法运算而产生的浮点溢出情况,并返回零值:
result = safe_division(1.0, 10**500, True, False)
print(result)
>>>
0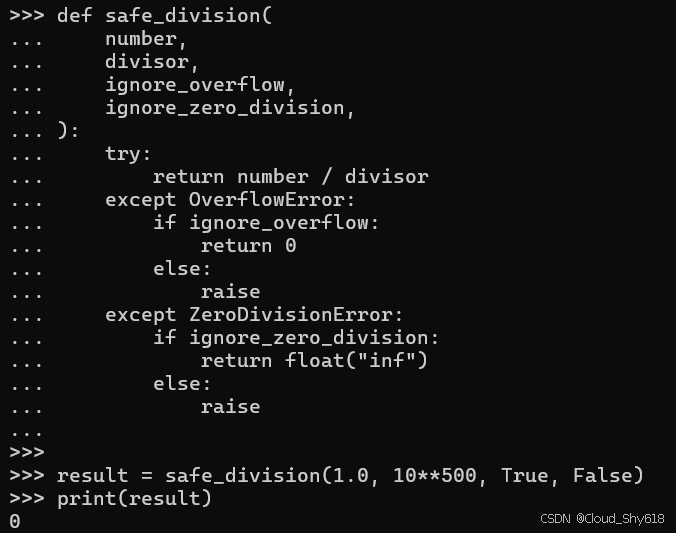
接下来的调用会忽略因除以零而产生的错误,并返回无穷大:
result = safe_division(1.0, 0, False, True)
print(result)
>>>
inf
问题在于,很容易混淆控制异常处理行为的两个布尔参数的位置。这很容易导致难以追踪的漏洞。提高这段代码可读性的方法之一便是使用关键字参数。通过使用默认关键字参数(参见 Item 36:"使用 None 和文档字符串指定动态默认参数"),函数可以变得更为谨慎,并且始终能够重新引发异常:
def safe_division_b(
number,
divisor,
ignore_overflow=False, # Changed
ignore_zero_division=False, # Changed
):
try:
return number / divisor
except OverflowError:
if ignore_overflow:
return 0
else:
raise
except ZeroDivisionError:
if ignore_zero_division:
return float("inf")
else:
raise这样一来,调用者便可利用关键字参数来指定他们希望为特定操作设置的忽略标志,从而覆盖默认行为:
result = safe_division_b(1.0, 10**500, ignore_overflow=True)
print(result)
result = safe_division_b(1.0, 0, ignore_zero_division=True)
print(result)
>>>
0
inf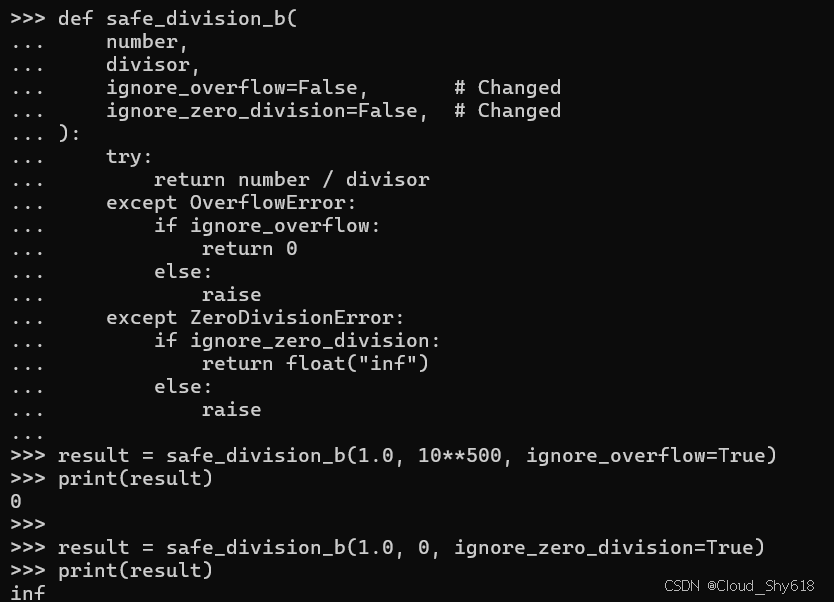
还有一个问题,由于这些关键字参数属于可选行为,并没有任何机制强制函数调用者为了清晰起见而使用关键字参数。即便对 safe_division_b 进行了新的定义,我仍能够以原有方式使用位置参数来调用它:
assert safe_division_b(1.0, 10**500, True, False) == 0对于此类具有复杂功能的函数,最好能通过仅使用关键字参数来定义函数的方式,来要求调用者明确表达其意图。这些参数只能以关键字的形式提供,而绝不能以位置参数的形式提供。
在这里,重新定义 safe_division 函数以接受仅关键字参数。参数列表中的 * 符号表示位置参数的结束和仅关键字参数的开始(*arg 具有相同的效果;请参阅 Item 34:"使用可变位置参数减少视觉噪音"):
def safe_division_c(
number,
divisor,
*, # Added
ignore_overflow=False,
ignore_zero_division=False,
):
try:
return number / divisor
except OverflowError:
if ignore_overflow:
return 0
else:
raise
except ZeroDivisionError:
if ignore_zero_division:
return float("inf")
else:
raise现在,使用与关键字参数对应的位置参数调用函数将不起作用:
safe_division_c(1.0, 10**500, True, False)
>>>
Traceback ...
TypeError: safe_division_c() takes 2 positional arguments but 4 were given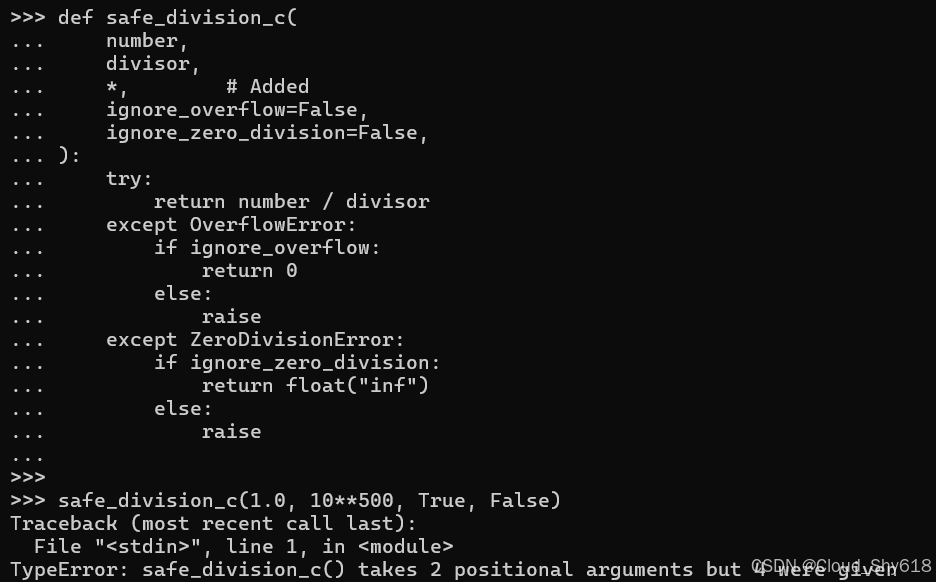
但是关键字参数及其默认值将按预期工作(在一种情况下忽略异常并在另一种情况下引发异常):
result = safe_division_c(1.0, 0, ignore_zero_division=True)
assert result == float("inf")
try:
result = safe_division_c(1.0, 0)
except ZeroDivisionError:
pass # Expected然而,该函数的 safe_division_c 版本仍然存在一个问题:调用者可以使用位置和关键字的混合来指定前两个必需参数(number 和 divisor):
assert safe_division_c(number=2, divisor=5) == 0.4
assert safe_division_c(divisor=5, number=2) == 0.4
assert safe_division_c(2, divisor=5) == 0.4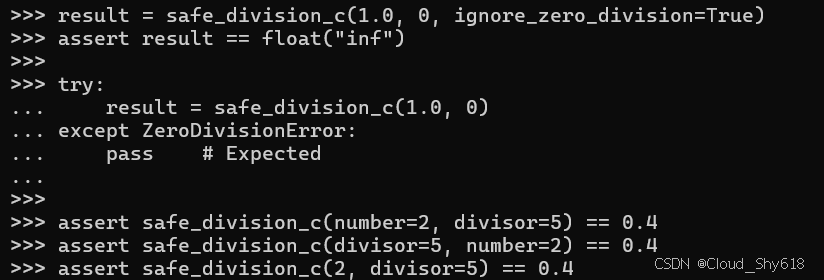
稍后,由于需求的扩大,或者甚至只是因为个人的风格偏好发生变化,可能会决定更改前两个参数的名称:
def safe_division_d(
numerator, # Changed
denominator, # Changed
*,
ignore_overflow=False,
ignore_zero_division=False
):
try:
return number / divisor
except OverflowError:
if ignore_overflow:
return 0
else:
raise
except ZeroDivisionError:
if ignore_zero_division:
return float("inf")
else:
raise不幸的是,这个看似表面的变化破坏了所有使用关键字指定数字或除数参数的现有调用者:
safe_division_d(number=2, divisor=5)
>>>
Traceback ...
TypeError: safe_division_d() got an unexpected keyword argument 'number'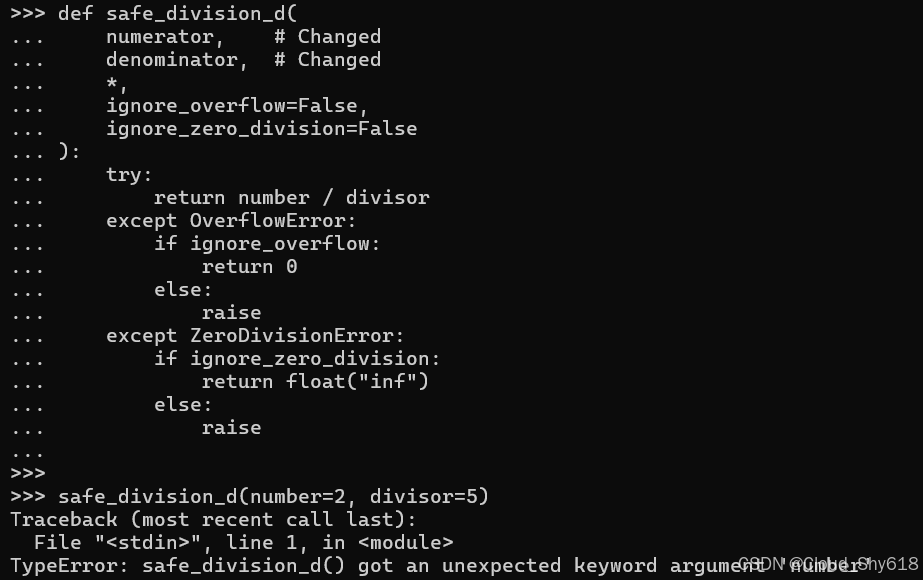
这是特别有问题的,因为我从来没有打算让关键字 number 和 divisor 成为该函数的显式接口的一部分。这些只是我为实现而选择的方便的参数名称,我并不期望任何人明确依赖它们。
因此,Python 3.8 引入了这个问题的解决方案,称为仅位置参数。这些参数只能按位置提供,而不能按关键字提供(与上面演示的仅关键字参数相反)。在这里,重新定义了 safe_division 函数,以对前两个必需参数使用仅位置参数。参数列表中的 / 符号指示仅位置参数的结束位置:
def safe_division_e(
numerator,
denominator,
/, # Added
*,
ignore_overflow=False,
ignore_zero_division=False,
):
try:
return numerator / denominator
except OverflowError:
if ignore_overflow:
return 0
else:
raise
except ZeroDivisionError:
if ignore_zero_division:
return float("inf")
else:
raise当按位置提供所需参数时,我可以验证此函数是否有效:
assert safe_division_e(2, 5) == 0.4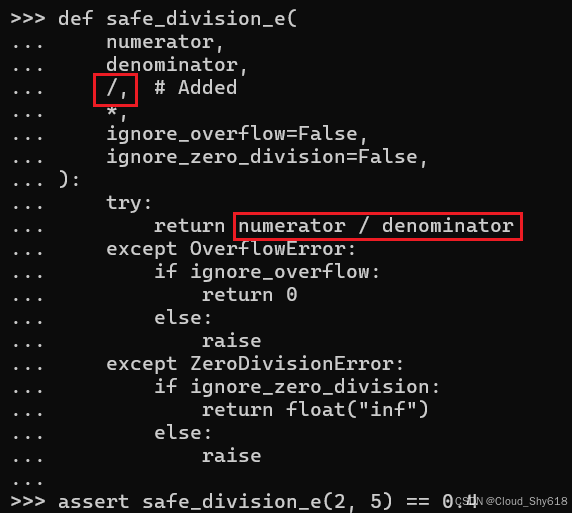
但如果关键字用于仅位置参数,则会引发异常:
safe_division_e(numerator=2, denominator=5)
>>>
Traceback ...
TypeError: safe_division_e() got some positional-only arguments
➥passed as keyword arguments: 'numerator, denominator'
现在,我可以确定 safe_division_e 函数定义中的前两个必需的位置参数已与调用者解耦。如果我再次更改参数名称,不会造成麻烦。仅关键字和位置参数的一个显著结果是,参数列表中 / 和 * 符号之间的任何参数名称都可以按位置或按关键字传递(这是 Python 中所有函数参数的默认值)。根据您的 API 风格和需求,允许两种参数传递风格可以提高可读性并减少噪音。例如,在这里我向 safe_division 添加了另一个可选参数,该参数允许调用者指定在对结果进行舍入时使用多少位数字:
def safe_division_f(
numerator,
denominator,
/,
ndigits=10, # Changed
*,
ignore_overflow=False,
ignore_zero_division=False,
):
try:
fraction = numerator / denominator # Changed
return round(fraction, ndigits) # Changed
except OverflowError:
if ignore_overflow:
return 0
else:
raise
except ZeroDivisionError:
if ignore_zero_division:
returnfloat("inf")
else:
raise现在,可以用所有这些不同的方式调用该函数的新版本,因为 ndigit 是一个可选参数,可以按位置或关键字传递:
result = safe_division_f(22, 7)
print(result)
result = safe_division_f(22, 7, 5)
print(result)
result = safe_division_f(22, 7, ndigits=2)
print(result)
>>>
3.1428571429
3.14286
3.14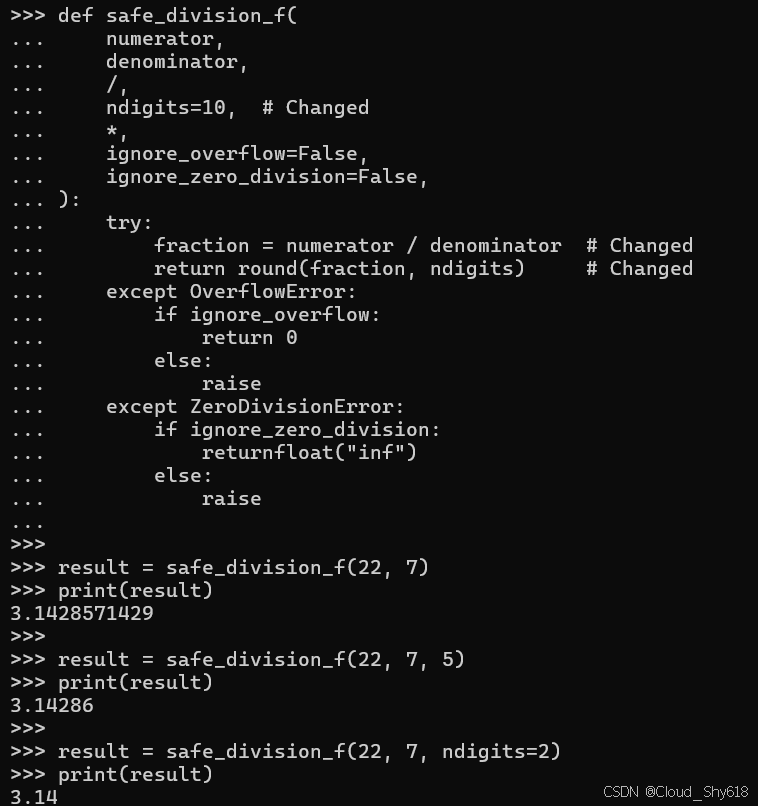
注意:
- 仅关键字参数强制调用者按关键字(而不是按位置)提供某些参数,这使得函数调用的意图更加清晰。仅关键字参数在参数列表中的 * 之后定义(无论是单独还是作为变量参数的一部分,如 *args)。
- 仅位置参数确保调用者无法使用关键字提供某些参数,这有助于减少耦合。仅位置参数在参数列表中的单个 / 之前定义。
- 参数列表中 / 和 * 字符之间的参数可以通过位置或关键字提供,这是 Python 参数的默认设置。
Item 38:使用 functools.wraps 定义函数装饰器
Python 具有可应用于函数的特殊装饰器语法。装饰器能够在每次调用它所包装的函数之前和之后运行额外的代码。这意味着装饰器可以访问和修改输入参数、返回值和引发异常。这些功能对于强制语义、调试、注册函数等非常有用。
例如,假设我想打印函数调用的参数和返回值。当调试递归函数的嵌套函数调用堆栈时,这尤其有用。(记录异常也可能很有用;请参阅 Item 86:"了解异常和基本异常之间的区别")。在这里,我通过使用 *args 和 **kwargs(参见 Item 34:"使用可变位置参数减少视觉噪音"和 Item 35:"使用关键字参数提供可选行为")来定义这样的装饰器,将所有参数传递给包装函数:
def trace(func):
def wrapper(*args, **kwargs):
args_repr = repr(args)
kwargs_repr = repr(kwargs)
result = func(*args, **kwargs)
print(f"{func.__name__}"
f"({args_repr}, {kwargs_repr}) "
f"-> {result!r}")
return result
return wrapper我可以使用 @symbol 将此装饰器应用于函数:
@trace
def fibonacci(n):
"""Return the n-th Fibonacci number"""
if n in(0, 1):
return n
return fibonacci(n - 2) + fibonacci(n - 1)使用 @ 符号相当于在它包装的函数上调用装饰器,并将返回值赋值给同一范围内的原始名称:
fibonacci = trace(fibonacci)修饰函数在斐波那契运行之前和之后运行包装器代码。它打印递归堆栈中每个级别的参数和返回值:
fibonacci(4)
>>>
fibonacci((0,), {}) -> 0
fibonacci((1,), {}) -> 1
fibonacci((2,), {}) -> 1
fibonacci((1,), {}) -> 1
fibonacci((0,), {}) -> 0
fibonacci((1,), {}) -> 1
fibonacci((2,), {}) -> 1
fibonacci((3,), {}) -> 2
fibonacci((4,), {}) -> 3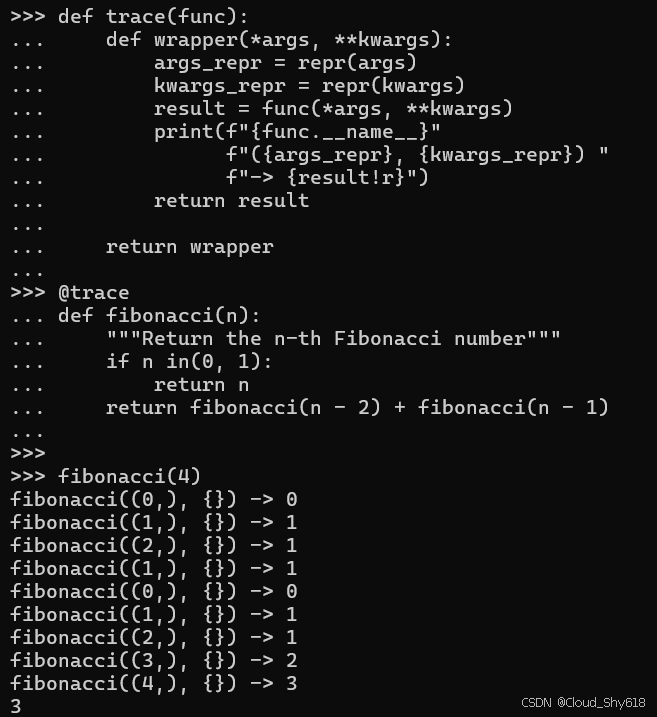
这很有效,但它有一个意想不到的副作用。装饰器返回的值(上面调用的函数)并不认为它被命名为斐波那契:
print(fibonacci)
>>>
<function trace.<locals>.wrapper at 0x104a179c0>
其原因不难看出。跟踪函数返回在其主体内定义的包装器。包装函数是由于装饰器而分配给包含模块中的 fibonacci 名称的函数。这种行为是有问题的,因为它破坏了进行内部审查的工具,例如调试器(请参阅 Item 114:"考虑使用 pdb 进行交互式调试")。例如,当调用修饰后的斐波那契函数时,help 内置函数是无用的。它应该打印出上面定义的文档字符串("""返回第 n 个斐波那契数"""),但它没有:
help(fibonacci)
>>>
Help on function wrapper in module __main__:
wrapper(*args, **kwargs)
另一个问题是对象序列化器(参见 Item 107:"使用 copyreg 使 pickle 序列化可维护")会中断,因为它们无法确定被修饰的原始函数的位置:
import pickle
pickle.dumps(fibonacci)
>>>
Traceback ...
AttributeError: Can't pickle local object 'trace.<locals>.
➥wrapper'
解决方案是使用 functools 内置模块中的 wraps 辅助函数。这是一个帮助你编写装饰器的装饰器。当您将其应用于包装函数时,它将有关内部函数的所有重要元数据复制到外部函数。在这里,使用包装重新定义了 trace 装饰器:
from functools import wraps
def trace(func):
@wraps(func) # Changed
def wrapper(*args, **kwargs):
args_repr = repr(args)
kwargs_repr = repr(kwargs)
result = func(*args, **kwargs)
print(f"{func.__name__}" f"({args_repr}, {kwargs_repr}) " f"-> {result!r}")
return result
return wrapper
@trace
def fibonacci(n):
"""Return the n-th Fibonacci number"""
if n in (0, 1):
return n
return fibonacci(n - 2) + fibonacci(n - 1)现在,运行 help 函数会产生预期的结果,即使该函数已被修饰:
help(fibonacci)
>>>
Help on function fibonacci in module __main__:
fibonacci(n)
Return the n-th Fibonacci number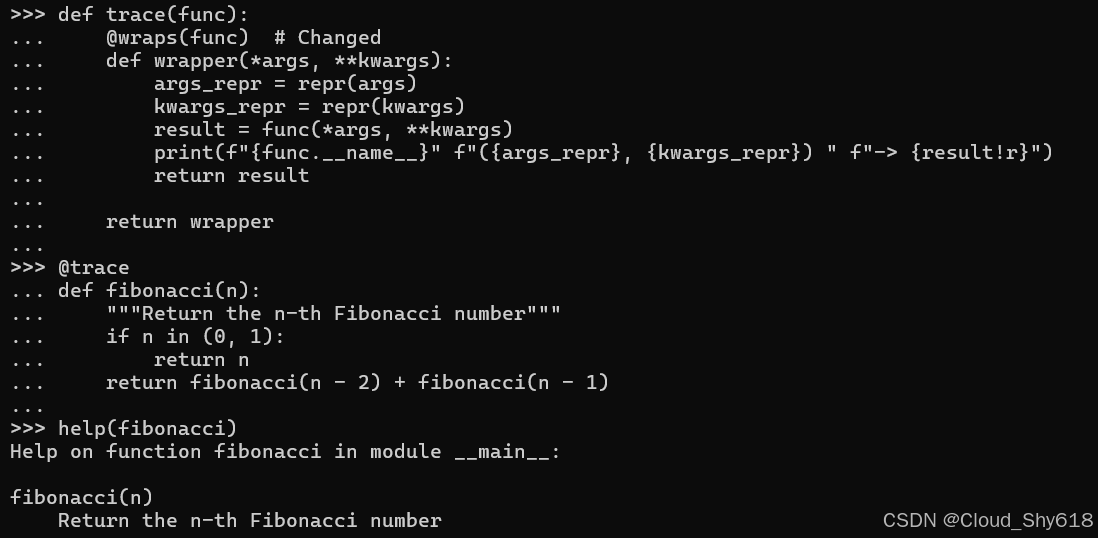
pickle 对象序列化器也可以工作:
print(pickle.dumps(fibonacci))
>>>
b'\x80\x04\x95\x1a\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\
➥x94\x8c\tfibonacci\x94\x93\x94.'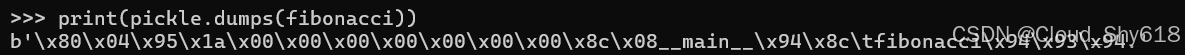
除了这些示例之外,Python 函数还有许多其他标准属性(例如 __name__、__module__、__annotations__),必须保留这些属性以维护语言中函数的接口。使用 wraps 确保您始终获得正确的行为。
注意:
- Python 中的装饰器是一种允许一个函数在运行时修改另一个函数的语法。
- 使用装饰器可能会导致进行内部审查的工具(例如调试器)出现奇怪的行为。
- 当您定义自己的装饰器时,请使用 functools 内置模块中的 wraps 装饰器以避免产生问题。
Item 39:对于 Glue 函数,更喜欢 functools.partial 而不是 lambda 表达式
Python 中的许多 API 接受简单函数作为其接口的一部分(请参阅 Item 100:"按复杂条件排序使用关键参数"、Item 27:"优先使用 defaultdict 而非 setdefault 来处理内部状态中的缺失项"和 Item 24:"考虑使用 itertools 来使用迭代器和生成器")。然而,这些接口可能会导致冲突,因为它们可能无法满足您的需求。
例如,functools 内置模块中的 reduce 函数允许您从近乎无限的可迭代值中计算一个结果。在这里,我使用 reduce 来计算许多对数的总和(这可以有效地将它们相乘):
import math
import functools
def log_sum(log_total, value):
log_value = math.log(value)
return log_total + log_value
result = functools.reduce(log_sum, [10, 20, 40], 0)
print(math.exp(result))
>>>
8000.0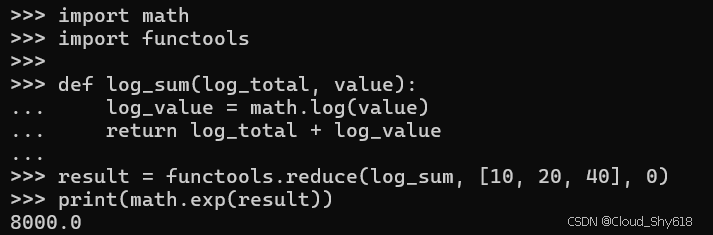
问题是你并不总是有一个像 log_sum 这样的函数与 reduce 所需的函数签名完全匹配。例如,假设您只是反转了参数(因为无论如何它都是任意选择),即第一位是 value 和第二位是 log_total。 如何轻松地将这个功能适配到所需的接口中?
def log_sum_alt(value, log_total): # Changed一种解决方案是在表达式中定义 lambda 函数,以对输入参数重新排序,以匹配 reduce 的要求:
result = functools.reduce(
lambda total, value: log_sum_alt(value, total), # Reordered
[10, 20, 40],
0,
)对于一次性的情况,创建一个 lambda 就可以了。但是,如果您发现自己重复执行此操作并复制代码,则值得使用可以多次调用的重新排序的参数定义另一个辅助函数:
def log_sum_for_reduce(total, value):
return log_sum_alt(value, total)函数接口不匹配的另一种情况是当您需要传递一些附加信息以供处理时使用。例如,假设我想选择对数的底数,而不是始终使用自然对数:
def logn_sum(base, logn_total, value): # New first parameter
logn_value = math.log(value, base)
return logn_total + logn_value为了传递这个函数给 reduce,我需要以某种方式为每个调用提供基本参数。但 reduce 并没有给我一个轻易做到这一点的方法。同样,lambda 可以在这里提供帮助,它允许我指定一个参数并传递其余参数。在这里,我总是提供 10 作为 logn_sum 的第一个参数,以便计算以 10 为底的对数:
result = functools.reduce(
lambda total, value: logn_sum(10, total, value), # Changed
[10, 20, 40],
0,
)
print(math.pow(10, result))
>>>
8000.000000000004
这种将某些参数固定为特定值,同时允许其余参数正常传递的模式在函数式代码中非常常见。这种技术通常称为 Currying 或 partial application。 functools 内置模块提供了 partial 函数,使之变得简单且更具可读性。它将函数部分应用为第一个参数,后跟固定位置参数:
result = functools.reduce(
functools.partial(logn_sum, 10), # Changed
[10, 20, 40],
0,
)partial 也允许您轻松固定关键字参数(有关信息,请参阅 Item 35:"通过关键字参数提供可选行为" 和 Item 37:"通过仅关键字和仅位置参数增强清晰度")。例如,假设 logn_sum 函数接受 base 作为仅关键字参数,如下所示:
def logn_sum_last(logn_total, value, *, base=10): # New kwarg
logn_value = math.log(value, base)
return logn_total + logn_value在这里,我使用 partial 将 base 的值固定为欧拉数:
import math
log_sum_e = functools.partial(logn_sum_last,
base=math.e) # Pinned `base`
print(log_sum_e(3, math.e**10))
>>>
13.0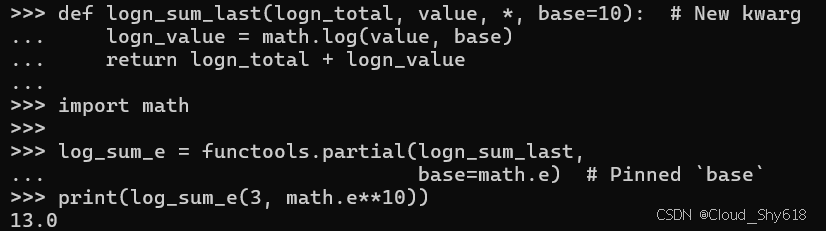
使用 lambda 表达式可以实现相同的行为,但它很冗长且容易出错:
log_sum_e_alt = lambda *a, base=math.e, **kw: \
logn_sum_last(*a, base=base, **kw)partial 还允许您检查已提供的参数以及正在包装的函数,这有助于调试:
print(log_sum_e.args, log_sum_e.keywords, log_sum_e.func)
>>>
() {'base': 2.718281828459045} <function logn_sum_last at
➥0x1033534c0>
一般来说,由于这些额外的优点,当它满足您的用例时,您应该更倾向于使用 partial。然而,partial 不能用于完全重新排序参数,因此这时使用 lambda 更合适。
在许多情况下,lambda 或 partial 实例仍然不够,特别是当您需要将状态作为简单函数接口的一部分访问或修改时。幸运的是,Python 提供了额外的工具,包括闭包,使之成为可能(请参阅 Item 33:"了解闭包如何与变量作用域和 nolocal 交互"和 Item 48:"接受函数而不是简单接口的类")。
注意:
- lambda 表达式可以通过重新排序参数或固定某些参数值来简洁地使两个函数接口兼容。
- functools 内置的 partial 函数是用于创建具有固定位置和关键字参数的函数的通用工具。
- 如果您需要重新排序包装函数的参数,请使用 lambda 而不是 partial。