六. KKT条件、模型的完整求解与预测
1. 构建拉格朗日函数与求导过程
为了求解软间隔 SVM,我们首先需要引入拉格朗日乘子 αi≥0\alpha_i \ge 0αi≥0 和 μi≥0\mu_i \ge 0μi≥0,针对带有松弛变量 ξi\xi_iξi 的原始目标函数,构建如下无约束的拉格朗日函数:
L(w,b,ξ,α,μ)=12∥w∥2+C∑i=1Nξi−∑i=1Nαiyi(w⋅xi+b)−1+ξi−∑i=1NμiξiL(w, b, \xi, \alpha, \mu) = \frac{1}{2}\|w\|^2 + C\sum_{i=1}^{N} \xi_i - \sum_{i=1}^{N} \alpha_i y_i(w \\cdot x_i + b) - 1 + \\xi_i - \sum_{i=1}^{N} \mu_i \xi_iL(w,b,ξ,α,μ)=21∥w∥2+Ci=1∑Nξi−i=1∑Nαiyi(w⋅xi+b)−1+ξi−i=1∑Nμiξi
为了寻找极值点(转化为对偶问题),我们将拉格朗日函数分别对原变量 w,b,ξiw, b, \xi_iw,b,ξi 求偏导数,并令其等于 0:
-
对 www 求偏导:
∇wL=w−∑i=1Nαiyixi=0 ⟹ w=∑i=1Nαiyixi\nabla_w L = w - \sum_{i=1}^{N} \alpha_i y_i x_i = 0 \implies w = \sum_{i=1}^{N} \alpha_i y_i x_i∇wL=w−i=1∑Nαiyixi=0⟹w=i=1∑Nαiyixi
-
对 bbb 求偏导:
∇bL=−∑i=1Nαiyi=0 ⟹ ∑i=1Nαiyi=0\nabla_b L = -\sum_{i=1}^{N} \alpha_i y_i = 0 \implies \sum_{i=1}^{N} \alpha_i y_i = 0∇bL=−i=1∑Nαiyi=0⟹i=1∑Nαiyi=0
-
对 ξi\xi_iξi 求偏导:
∇ξiL=C−αi−μi=0\nabla_{\xi_i} L = C - \alpha_i - \mu_i = 0∇ξiL=C−αi−μi=0
2. 软间隔SVM的KKT 条件
如果一个解满足最优解,它一定是满足KKT条件的。如果不满足,那一定不是最优解
在引入拉格朗日乘子 αi\alpha_iαi 和 μi\mu_iμi 后,针对软间隔SVM的优化问题,必须满足以下五个具体的 KKT 条件:
-
梯度为零(平稳性条件)
要求拉格朗日函数对原变量 w,b,ξw, b, \xiw,b,ξ 的偏导数为 0:
w∗=∑i=1Nαi∗yixiw^* = \sum_{i=1}^{N} \alpha_i^* y_i x_iw∗=i=1∑Nαi∗yixi
∑i=1Nαi∗yi=0\sum_{i=1}^{N} \alpha_i^* y_i = 0i=1∑Nαi∗yi=0
C−αi∗−μi∗=0C - \alpha_i^* - \mu_i^* = 0C−αi∗−μi∗=0
-
互补松弛条件
拉格朗日乘子与对应的不等式约束的乘积必须为 0:
αi∗yi(w∗⋅xi+b∗)−1+ξi∗=0,i=1,2,...,N\alpha_i^* y_i(w\^\* \\cdot x_i + b\^\*) - 1 + \\xi_i\^\* = 0 , \quad i=1, 2, \dots, Nαi∗yi(w∗⋅xi+b∗)−1+ξi∗=0,i=1,2,...,N
μi∗ξi∗=0,i=1,2,...,N\mu_i^* \xi_i^* = 0 , \quad i=1, 2, \dots, Nμi∗ξi∗=0,i=1,2,...,N
-
不等式约束(原问题可行性)
必须满足原始问题设定的几何间隔和松弛变量约束:
yi(w∗⋅xi+b∗)−1+ξi∗≥0,i=1,2,...,Ny_i(w^* \cdot x_i + b^*) - 1 + \xi_i^* \ge 0 , \quad i=1, 2, \dots, Nyi(w∗⋅xi+b∗)−1+ξi∗≥0,i=1,2,...,N
ξi∗≥0,i=1,2,...,N\xi_i^* \ge 0 , \quad i=1, 2, \dots, Nξi∗≥0,i=1,2,...,N
-
乘子非负(对偶问题可行性)
引入的拉格朗日乘子必须大于等于 0:
αi∗≥0,i=1,2,...,N\alpha_i^* \ge 0 , \quad i=1, 2, \dots, Nαi∗≥0,i=1,2,...,N
μi∗≥0,i=1,2,...,N\mu_i^* \ge 0 , \quad i=1, 2, \dots, Nμi∗≥0,i=1,2,...,N
(注:结合条件1中的 C−αi∗−μi∗=0C - \alpha_i^* - \mu_i^* = 0C−αi∗−μi∗=0 和 μi∗≥0\mu_i^* \ge 0μi∗≥0,可推导出对偶问题的核心约束:0≤αi∗≤C0 \le \alpha_i^* \le C0≤αi∗≤C)
-
等式约束
标准 SVM 原始问题中没有显式的等式约束 hi(x)=0h_i(x) = 0hi(x)=0。但从条件1(对 bbb 求导)中,我们自然得到了对偶问题必须满足的等式约束:
∑i=1Nαi∗yi=0\sum_{i=1}^{N} \alpha_i^* y_i = 0i=1∑Nαi∗yi=0
2. αi\alpha_iαi的物理意义
根据互补松弛条件:αi∗⋅yi(w∗⋅xi+b∗)−1+ξi∗=0(i=1,2,...,N) \alpha_i^* \cdot y_i(w\^\* \\cdot x_i + b\^\*) - 1 + \\xi_i\^\* = 0 \quad (i=1, 2, \dots, N)αi∗⋅yi(w∗⋅xi+b∗)−1+ξi∗=0(i=1,2,...,N)说明两个乘数必定至少有一个为 0。这也完美解释了为什么绝大多数样本的 αi\alpha_iαi 等于 0,只有极少数样本(支持向量)撑起了整个超平面!
结合 μi∗ξi∗=0\mu_i^* \xi_i^* = 0μi∗ξi∗=0 以及 0≤αi∗≤C0 \le \alpha_i^* \le C0≤αi∗≤C,在软间隔条件下,参数αi\alpha_iαi与样本自身所处位置存在以下完美对应的数学情况:
只要αi!=0\alpha_i != 0αi!=0都是支持向量样本;αi=0\alpha_i = 0αi=0是普通的非支持向量样本。
- αi=0\alpha_i = 0αi=0 :
- 由 αi+μi=C\alpha_i + \mu_i = Cαi+μi=C 且 αi=0\alpha_i = 0αi=0 得 μi=C\mu_i = Cμi=C;
- 因为 μi=C>0\mu_i = C > 0μi=C>0,由 μiξi=0\mu_i \xi_i = 0μiξi=0 得 ξi=0\xi_i = 0ξi=0;
- 由αiyi(w⋅xi+b)−1+ξi=0\alpha_i y_i(w \\cdot x_i + b) - 1 + \\xi_i = 0αiyi(w⋅xi+b)−1+ξi=0 且 αi=0\alpha_i = 0αi=0,得 yi(w⋅xi+b)−1+ξiy_i(w \cdot x_i + b) - 1 + \xi_iyi(w⋅xi+b)−1+ξi 结果可以是任何数(只要满足约束);
- 但由于该点处于安全区域外,即 yi(w⋅xi+b)>1y_i(w \cdot x_i + b) > 1yi(w⋅xi+b)>1;
- 该点为普通的非支持向量样本,对模型构建没有任何影响(αi=0\alpha_i=0αi=0 代表模型完全忽略它)。
- 0<αi<C0 < \alpha_i < C0<αi<C :
- 由C−αi−μi=0C - \alpha_i - \mu_i = 0C−αi−μi=0 得 μi>0\mu_i > 0μi>0;
- 由μi∗ξi∗=0,i=1,2,...,N\mu_i^* \xi_i^* = 0 , i=1, 2, \dots, Nμi∗ξi∗=0,i=1,2,...,N得 ξi=0\xi_i = 0ξi=0;
- 由αi∗yi(w∗⋅xi+b∗)−1+ξi∗=0,i=1,2,...,N\alpha_i^* y_i(w\^\* \\cdot x_i + b\^\*) - 1 + \\xi_i\^\* = 0 , i=1, 2, \dots, Nαi∗yi(w∗⋅xi+b∗)−1+ξi∗=0,i=1,2,...,N 得 yi(w∗⋅xi+b∗)=1,i=1,2,...,Ny_i(w^* \cdot x_i + b^*) = 1 , i=1, 2, \dots, Nyi(w∗⋅xi+b∗)=1,i=1,2,...,N
- 样本恰好严格处于间隔边界上,是标准的支持向量。
- αi=C\alpha_i = Cαi=C 且 0<ξi<10 < \xi_i < 10<ξi<1 :
- 由 αi+μi=C\alpha_i + \mu_i = Cαi+μi=C 且 αi=C\alpha_i = Cαi=C 得 μi=0\mu_i = 0μi=0;
- 因为 μi=0\mu_i = 0μi=0,由 μiξi=0\mu_i \xi_i = 0μiξi=0 此时无法直接判断 ξi\xi_iξi(ξi\xi_iξi 可为任意值);
- 由 αiyi(w⋅xi+b)−1+ξi=0\alpha_i y_i(w \\cdot x_i + b) - 1 + \\xi_i = 0αiyi(w⋅xi+b)−1+ξi=0 得 yi(w⋅xi+b)=1−ξiy_i(w \cdot x_i + b) = 1 - \xi_iyi(w⋅xi+b)=1−ξi;
- 因为 0<ξi<10 < \xi_i < 10<ξi<1,所以 0<yi(w⋅xi+b)<10 < y_i(w \cdot x_i + b) < 10<yi(w⋅xi+b)<1;
- 样本处于间隔内部(跨过边界但未越过决策面),属于被正确分类但侵入了间隔区域的样本。
- αi=C\alpha_i = Cαi=C 且 ξi=1\xi_i = 1ξi=1 :
- 由 αi+μi=C\alpha_i + \mu_i = Cαi+μi=C 且 αi=C\alpha_i = Cαi=C 得 μi=0\mu_i = 0μi=0;
- 同理,由 αiyi(w⋅xi+b)−1+ξi=0\alpha_i y_i(w \\cdot x_i + b) - 1 + \\xi_i = 0αiyi(w⋅xi+b)−1+ξi=0 得 yi(w⋅xi+b)=1−ξiy_i(w \cdot x_i + b) = 1 - \xi_iyi(w⋅xi+b)=1−ξi;
- 因为 ξi=1\xi_i = 1ξi=1,所以 yi(w⋅xi+b)=0y_i(w \cdot x_i + b) = 0yi(w⋅xi+b)=0;
- 样本恰巧落在了正中间的分离决策超平面上,属于分类的临界点。
- αi=C\alpha_i = Cαi=C 且 ξi>1\xi_i > 1ξi>1 :
- 同理,由 αi=C\alpha_i = Cαi=C 得 μi=0\mu_i = 0μi=0;
- 同理,由 αiyi(w⋅xi+b)−1+ξi=0\alpha_i y_i(w \\cdot x_i + b) - 1 + \\xi_i = 0αiyi(w⋅xi+b)−1+ξi=0 得 yi(w⋅xi+b)=1−ξiy_i(w \cdot x_i + b) = 1 - \xi_iyi(w⋅xi+b)=1−ξi;
- 因为 ξi>1\xi_i > 1ξi>1,所以 yi(w⋅xi+b)<0y_i(w \cdot x_i + b) < 0yi(w⋅xi+b)<0;
- 样本完全越过了决策面,落入了敌方阵营,属于被错误分类的异常噪声样本。
- αi=0\alpha_i = 0αi=0 :
- 由 αi+μi=C\alpha_i + \mu_i = Cαi+μi=C 且 αi=0\alpha_i = 0αi=0 得 μi=C\mu_i = Cμi=C;
- 因为 μi=C>0\mu_i = C > 0μi=C>0,由 μiξi=0\mu_i \xi_i = 0μiξi=0 得 ξi=0\xi_i = 0ξi=0;
- 代入互补条件 αiyi(w⋅xi+b)−1+ξi=0\alpha_i y_i(w \\cdot x_i + b) - 1 + \\xi_i = 0αiyi(w⋅xi+b)−1+ξi=0。由于 αi=0\alpha_i = 0αi=0,方括号内的值可以是任何数(只要满足约束);
- 但由于该点处于安全区域外,即 yi(w⋅xi+b)>1y_i(w \cdot x_i + b) > 1yi(w⋅xi+b)>1;
- 该点为普通的非支持向量样本,对模型构建没有任何影响(αi=0\alpha_i=0αi=0 代表模型完全忽略它)。
3. SMO (序列最小优化) 算法求解 α∗\alpha^*α∗
SMO算法的核心机制: 采用了坐标上升法。
问题背景: 梳理一下我们之前走到的步骤,SVM 的对偶问题最终化简为一个只包含 α\alphaα 的二次规划问题:
目标函数: minα12∑i=1N∑j=1NαiαjyiyjK(xi,xj)−∑i=1Nαi\min_{\alpha} \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j K(x_i, x_j) - \sum_{i=1}^{N} \alpha_iαmin21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi
约束条件: ∑i=1Nαiyi=0且0≤αi≤C\sum_{i=1}^{N} \alpha_i y_i = 0 \quad \text{且} \quad 0 \le \alpha_i \le Ci=1∑Nαiyi=0且0≤αi≤C
这是一个包含 NNN 个变量(α1,α2,...,αN\alpha_1, \alpha_2, \dots, \alpha_Nα1,α2,...,αN)的极其庞大的公式,直接用传统方法求解效率极低。
SMO算法的核心目标: 我们最后求解出来的最佳 α∗\alpha^*α∗,一定是让整个结果完全满足 KKT 条件的。如果不满足,那一定不是最优解。
因此,SMO 的核心思想就是:每次不断地调整局部 α\alphaα 的值,直到所有的 αi\alpha_iαi 都满足 KKT 条件,此时就一定得到了全局最优解。
【关键补充:两个变量的挑选策略 (启发式搜索)】
既然每次需要同时优化两个变量,SMO 采用了一种极具效率的"先找主犯,再找最佳搭档"的策略:
1. 第一个变量的选择(找违反 KKT 最严重的主犯):
算法会扫描各个数据点,检查它们当前的 αi\alpha_iαi 是否严格遵守了 KKT 规定的数学等价关系:
-
αi=0⇔yig(xi)≥1\alpha_i = 0 \Leftrightarrow y_i g(x_i) \ge 1αi=0⇔yig(xi)≥1 (非支持向量必须在安全区外)
-
0<αi<C⇔yig(xi)=10 < \alpha_i < C \Leftrightarrow y_i g(x_i) = 10<αi<C⇔yig(xi)=1 (标准支持向量必须精准踩在边界上)
-
αi=C⇔yig(xi)≤1\alpha_i = C \Leftrightarrow y_i g(x_i) \le 1αi=C⇔yig(xi)≤1 (违规样本必须在边界内部)
(注:公式中的 g(xi)g(x_i)g(xi) 即为模型预测值 ∑αjyjK(xj,xi)+b\sum \alpha_j y_j K(x_j, x_i) + b∑αjyjK(xj,xi)+b)
算法通常会优先扫描 0<αi<C0 < \alpha_i < C0<αi<C 的样本,一旦发现有人不满足上述等价关系,立马将其定为 α1\alpha_1α1。
2. 第二个变量的选择(找让步子迈得最大的搭档):
为了让优化效率最高,我们希望每次更新的"跨度"越大越好。
定义模型预测误差为:Ei=g(xi)−yiE_i = g(x_i) - y_iEi=g(xi)−yi(预测值与真实标签的偏差)。
SMO 挑选 α2\alpha_2α2 的标准是:寻找能使 ∣E1−E2∣|E_1 - E_2|∣E1−E2∣ (误差之差的绝对值)达到最大的那个样本。
也就是说,如果 α1\alpha_1α1 的误差 E1E_1E1 是个很大的正数,算法就会去全场找一个误差 E2E_2E2 为极小负数的样本来配合。这种"两极中和"能让参数更新的步子迈到最大。
循环终止条件:
两个 α\alphaα 都找到后,就进行下面的数学优化与更新。然后继续找下一对,直到全场再也找不到任何违反 KKT 条件的 α\alphaα 为止,算法收敛停止。
推导步骤(坐标上升法的改良):
第 1 步:传统"坐标上升法"的失效(尝试只动 1 个变量)
在最优化理论中,有一种基本算法叫坐标上升法 (Coordinate Ascent),它的思路是每次只优化一个变量,固定其他变量(在二维图上表现为沿着坐标轴画折线"走楼梯"逼近极值)。
假设我们有向量 α=α1,α2,...,αN\alpha = \\alpha_1, \\alpha_2, \\dots, \\alpha_Nα=α1,α2,...,αN。我们尝试用传统的坐标上升法,即只固定除 α1\alpha_1α1 以外的所有变量,仅留下 α1\alpha_1α1 进行优化。
根据对偶问题中必须满足的等式约束条件:
∑i=1Nαiyi=0\sum_{i=1}^{N} \alpha_i y_i = 0i=1∑Nαiyi=0
将其展开,把 α1\alpha_1α1 单独拎出来:
α1y1+∑i=2Nαiyi=0\alpha_1 y_1 + \sum_{i=2}^{N} \alpha_i y_i = 0α1y1+i=2∑Nαiyi=0
移项,将固定不变的部分移到等式右边:
α1y1=−∑i=2Nαiyi\alpha_1 y_1 = -\sum_{i=2}^{N} \alpha_i y_iα1y1=−i=2∑Nαiyi
两边同乘 y1y_1y1(因为 y12=1y_1^2 = 1y12=1),得到:
α1=−y1∑i=2Nαiyi\alpha_1 = -y_1 \sum_{i=2}^{N} \alpha_i y_iα1=−y1i=2∑Nαiyi
结论: 只要我们固定了除 α1\alpha_1α1 以外的所有 α\alphaα,等式右边就变成了一个彻底的已知常数 。这意味着 α1\alpha_1α1 的值被直接死死锁定了,根本无法沿着该坐标轴进行任何滑动和优化! 因此,传统的单变量坐标上升法在 SVM 中完全失效。
第 2 步:SMO 的破局(同时选择 2 个变量进行优化)
既然动 1 个变量行不通,SMO 算法巧妙地对坐标上升法进行了改良:每次迭代时,同时选择两个变量(例如 α1\alpha_1α1 和 α2\alpha_2α2)进行更新,而将剩下的 α3\alpha_3α3 到 αN\alpha_NαN 全部固定为常数。
再次根据等式约束 ∑i=1Nαiyi=0\sum_{i=1}^{N} \alpha_i y_i = 0∑i=1Nαiyi=0 展开:
α1y1+α2y2+∑i=3Nαiyi=0\alpha_1 y_1 + \alpha_2 y_2 + \sum_{i=3}^{N} \alpha_i y_i = 0α1y1+α2y2+i=3∑Nαiyi=0
将固定的常数部分(α3\alpha_3α3 到 αN\alpha_NαN)移到等式右边:
α1y1+α2y2=−∑i=3Nαiyi\alpha_1 y_1 + \alpha_2 y_2 = -\sum_{i=3}^{N} \alpha_i y_iα1y1+α2y2=−i=3∑Nαiyi
由于等式右边全是我们固定的已知常数,我们可以把右边看作一个统一的常数 ζ\zetaζ:
α1y1+α2y2=ζ\alpha_1 y_1 + \alpha_2 y_2 = \zetaα1y1+α2y2=ζ
(注:这在几何上代表了一条位于二维平面上的直线,后续我们的 α1\alpha_1α1 和 α2\alpha_2α2 只能在这条直线上滑动寻优)
第 3 步:目标函数的完全展开与"常数剥离"
现在,我们要把 α1\alpha_1α1 和 α2\alpha_2α2 从庞大的对偶目标函数中"生挖"出来,把其余所有的项全部看作常数。
原始对偶目标函数为(设 Kij=K(xi,xj)K_{ij} = K(x_i, x_j)Kij=K(xi,xj) 以简化书写):
W(α)=12∑i=1N∑j=1NαiαjyiyjKij−∑i=1NαiW(\alpha) = \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j K_{ij} - \sum_{i=1}^{N} \alpha_iW(α)=21i=1∑Nj=1∑NαiαjyiyjKij−i=1∑Nαi
我们将这个巨大的双重求和公式强行拆解成三部分:
-
纯 α1\alpha_1α1 和 α2\alpha_2α2 的内部互动:
包含 (i=1,j=1)(i=1, j=1)(i=1,j=1)、(i=2,j=2)(i=2, j=2)(i=2,j=2)、(i=1,j=2)(i=1, j=2)(i=1,j=2)、(i=2,j=1)(i=2, j=1)(i=2,j=1) 四项:
12α12y12K11+12α22y22K22+12α1α2y1y2K12+12α2α1y2y1K21\frac{1}{2} \alpha_1^2 y_1^2 K_{11} + \frac{1}{2} \alpha_2^2 y_2^2 K_{22} + \frac{1}{2} \alpha_1 \alpha_2 y_1 y_2 K_{12} + \frac{1}{2} \alpha_2 \alpha_1 y_2 y_1 K_{21}21α12y12K11+21α22y22K22+21α1α2y1y2K12+21α2α1y2y1K21
(注:因为 yi∈{−1,+1}y_i \in \{-1, +1\}yi∈{−1,+1},所以 y12=1,y22=1y_1^2 = 1, y_2^2 = 1y12=1,y22=1;又因为核函数矩阵是对称的,所以 K12=K21K_{12} = K_{21}K12=K21)
合并同类项后极度简化为:
12K11α12+12K22α22+y1y2K12α1α2\frac{1}{2} K_{11} \alpha_1^2 + \frac{1}{2} K_{22} \alpha_2^2 + y_1 y_2 K_{12} \alpha_1 \alpha_221K11α12+21K22α22+y1y2K12α1α2
-
α1,α2\alpha_1, \alpha_2α1,α2 与其他固定常数的互动(后面的 ∑\sum∑):
即 i∈{1,2}i \in \{1, 2\}i∈{1,2} 且 j≥3j \ge 3j≥3 的项。为了方便,我们令 vi=∑j=3NαjyjKijv_i = \sum_{j=3}^{N} \alpha_j y_j K_{ij}vi=∑j=3NαjyjKij(这是一个已经固定的常数):
y1α1v1+y2α2v2y_1 \alpha_1 v_1 + y_2 \alpha_2 v_2y1α1v1+y2α2v2
-
完全与 α1,α2\alpha_1, \alpha_2α1,α2 无关的项(被直接扫进历史垃圾堆):
包括 i≥3i \ge 3i≥3 且 j≥3j \ge 3j≥3 的二次项,以及后面的 −∑i=3Nαi-\sum_{i=3}^N \alpha_i−∑i=3Nαi。我们统统把它们打包记为一个大常数 CconstantC_{\text{constant}}Cconstant。
最后,别忘了目标函数末尾的一阶项 −α1−α2-\alpha_1 - \alpha_2−α1−α2。
将以上所有部件组装起来,我们就得到了一个只关于 α1\alpha_1α1 和 α2\alpha_2α2 的二元二次函数:
W(α1,α2)=12K11α12+12K22α22+y1y2K12α1α2−α1−α2+y1v1α1+y2v2α2+CconstantW(\alpha_1, \alpha_2) = \frac{1}{2} K_{11} \alpha_1^2 + \frac{1}{2} K_{22} \alpha_2^2 + y_1 y_2 K_{12} \alpha_1 \alpha_2 - \alpha_1 - \alpha_2 + y_1 v_1 \alpha_1 + y_2 v_2 \alpha_2 + C_{\text{constant}}W(α1,α2)=21K11α12+21K22α22+y1y2K12α1α2−α1−α2+y1v1α1+y2v2α2+Cconstant
第 4 步:代入消元,化简为一元二次方程(降维打击)
在上一步中,我们得到了一个二元函数。现在,根据第 2 步得出的直线约束方程:
α1=y1(ζ−α2y2)\alpha_1 = y_1(\zeta - \alpha_2 y_2)α1=y1(ζ−α2y2)
我们将这个 α1\alpha_1α1 的表达式,直接强行代入 到上面的 W(α1,α2)W(\alpha_1, \alpha_2)W(α1,α2) 中。
虽然代入后式子看起来会变长,但本质上,α1\alpha_1α1 被彻底消灭了!原式中只剩下 α2\alpha_2α2 这唯一一个未知变量。
整个极其复杂的 SVM 对偶问题,在这一刻,被彻底降维成了一个初中数学里最简单的一元二次函数:
W(α2)=Aα22+Bα2+CW(\alpha_2) = A \alpha_2^2 + B \alpha_2 + CW(α2)=Aα22+Bα2+C
(其中 A, B, C 均是由 Kij,yiK_{ij}, y_iKij,yi 和常数组成的已知数字)
因为开口必然向上(由核函数的半正定性保证),我们只需要求导 ∂W∂α2=0\frac{\partial W}{\partial \alpha_2} = 0∂α2∂W=0,就能直接得到一个未经约束的理论极值,记作 α2unclipped\alpha_2^{\text{unclipped}}α2unclipped(未剪裁值)。
【关键补充:剪裁操作 (Clipping)】
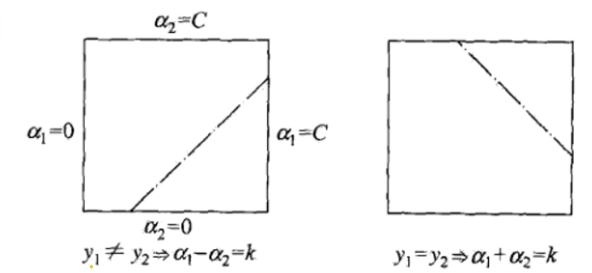
虽然我们通过求导算出了理论极值 α2unclipped\alpha_2^{\text{unclipped}}α2unclipped,但这个极值在现实中可能"违法"。因为 α1\alpha_1α1 和 α2\alpha_2α2 还必须服从两道"死命令":
- 方形牢笼(边界约束): 0≤α1≤C0 \le \alpha_1 \le C0≤α1≤C 且 0≤α2≤C0 \le \alpha_2 \le C0≤α2≤C。两人的值绝对不能跑出这个 C×CC \times CC×C 的正方形。
- 直线轨道(等式约束): α1y1+α2y2=ζ\alpha_1 y_1 + \alpha_2 y_2 = \zetaα1y1+α2y2=ζ。两人的值必须严格在这条直线上滑动。
因此,必须对理论极值进行"剪裁",具体操作如下:
-
① 划定合法区间 L,HL, HL,H: 直线穿过 C×CC \times CC×C 的正方形盒子,只会截取出一小段合法的线段。我们将这段线段投影到 α2\alpha_2α2 轴上,就能得出 α2\alpha_2α2 真实的合法活动区间:最低不能低于 LLL (Lower),最高不能高于 HHH (Higher)。具体的边界公式取决于 y1y_1y1 和 y2y_2y2 是否同号(因为这决定了直线是斜向上的还是斜向下的):
-
如果 y1≠y2y_1 \neq y_2y1=y2(异号,直线斜率为正):
L=max(0,α2old−α1old),H=min(C,C+α2old−α1old)L = \max(0, \alpha_2^{\text{old}} - \alpha_1^{\text{old}}), \quad H = \min(C, C + \alpha_2^{\text{old}} - \alpha_1^{\text{old}})L=max(0,α2old−α1old),H=min(C,C+α2old−α1old)
-
如果 y1=y2y_1 = y_2y1=y2(同号,直线斜率为负):
L=max(0,α2old+α1old−C),H=min(C,α2old+α1old)L = \max(0, \alpha_2^{\text{old}} + \alpha_1^{\text{old}} - C), \quad H = \min(C, \alpha_2^{\text{old}} + \alpha_1^{\text{old}})L=max(0,α2old+α1old−C),H=min(C,α2old+α1old)
-
-
② 执行"一刀切" (剪裁): 拿着算出来的理论极值 α2unclipped\alpha_2^{\text{unclipped}}α2unclipped 去和合法区间 L,HL, HL,H 进行对比:
- 情况 A (超出上限): 如果 α2unclipped>H\alpha_2^{\text{unclipped}} > Hα2unclipped>H ,强行将其按回上限,即 α2new=H\alpha_2^{\text{new}} = Hα2new=H。
- 情况 B (跌破下限): 如果 α2unclipped<L\alpha_2^{\text{unclipped}} < Lα2unclipped<L ,强行将其拉回下限,即 α2new=L\alpha_2^{\text{new}} = Lα2new=L。
- 情况 C (合法安全): 如果 L≤α2unclipped≤HL \le \alpha_2^{\text{unclipped}} \le HL≤α2unclipped≤H ,完美,直接采纳,即 α2new=α2unclipped\alpha_2^{\text{new}} = \alpha_2^{\text{unclipped}}α2new=α2unclipped。
-
③ 联动更新 α1\alpha_1α1: 拿到剪裁后真正合法有效的 α2new\alpha_2^{\text{new}}α2new,将其代回直线方程 α1=y1(ζ−α2newy2)\alpha_1 = y_1(\zeta - \alpha_2^{\text{new}} y_2)α1=y1(ζ−α2newy2) 中,算出配套的 α1new\alpha_1^{\text{new}}α1new。
算法闭环总结: SMO 算法就是不断地在 NNN 个参数中挑出违背 KKT 条件最严重的 2 个参数,利用常数剥离和等式约束消元法,将 NNN 维的复杂寻优瞬间降维成求解一个一元二次方程的顶点。然后再通过"画牢笼算上下限 →\rightarrow→ 强制修剪越界值"的剪裁操作确保结果合法。如此循环往复,直到所有的 αi\alpha_iαi 都严格满足 KKT 条件,训练宣告完成。
4. 计算偏置 b∗b^*b∗
我们利用 SMO 算法解出所有的 α∗\alpha^*α∗ 后,w∗w^*w∗ 可以由公式 w∗=∑αi∗yixiw^* = \sum \alpha_i^* y_i x_iw∗=∑αi∗yixi 隐式表达。剩下的任务是求 b∗b^*b∗。
根据上面的物理意义,我们找出一个满足 0<αj∗<C0 < \alpha_j^* < C0<αj∗<C 的样本点(即严格在边界上的标准支持向量 xjx_jxj)。因为对于它,严格满足 yj(w∗⋅xj+b∗)=1y_j(w^* \cdot x_j + b^*) = 1yj(w∗⋅xj+b∗)=1。
两边同乘 yjy_jyj 移项,并将 w∗w^*w∗ 代入,即可求得偏置 b∗b^*b∗:
b∗=yj−∑i=1Nαi∗yiK(xi,xj)b^* = y_j - \sum_{i=1}^N \alpha_i^* y_i K(x_i, x_j)b∗=yj−i=1∑Nαi∗yiK(xi,xj)
(注:这里用核函数 K(xi,xj)K(x_i, x_j)K(xi,xj) 替换了原本的内积)
5. 对新样本 xxx 进行分类预测
模型全部训练完毕后,当来了一个新的未知样本 xxx 时,我们不需要真的算出 w∗w^*w∗ 的具体数值。我们将 w∗w^*w∗ 代入感知机决策公式,测试时也仅依赖内积计算(即可完美结合核函数):
f(x)=sign(∑i=1Nαi∗yiK(x,xi)+b∗)f(x) = \text{sign} \left( \sum_{i=1}^N \alpha_i^* y_i K(x, x_i) + b^* \right)f(x)=sign(i=1∑Nαi∗yiK(x,xi)+b∗)
(注:sign\text{sign}sign 为符号函数,结果 >0>0>0 分类为 +1+1+1,<0<0<0 分类为 −1-1−1)
七.支持向量机求解步骤
- 写出原问题的标准式
- 写出原问题的拉格朗日函数
- 写出对偶函数
- 写出对偶问题
- 若满足强对偶定理,求解对偶问题
例题:已知有三个训练数据点:正例 x1=(3,3)Tx_1 = (3, 3)^Tx1=(3,3)T, x2=(4,3)Tx_2 = (4, 3)^Tx2=(4,3)T,负例 x3=(1,1)Tx_3 = (1, 1)^Tx3=(1,1)T。写出支持向量机优化问题§、对偶问题(D)、KKT条件;尝试用SMO算法,写出分离超平面方程
目标:严格按照一般优化问题的解题步骤,写出支持向量机优化问题 §、对偶问题 (D)、KKT条件;并尝试用 SMO 算法的思想,解出 α∗\alpha^*α∗,最终写出分离超平面方程。
第 1 步:写出原问题的标准式 §
根据硬间隔 SVM 的目标函数和约束条件,我们代入具体的点:
x1=(3,3)T,y1=1x_1 = (3,3)^T, y_1 = 1x1=(3,3)T,y1=1
x2=(4,3)T,y2=1x_2 = (4,3)^T, y_2 = 1x2=(4,3)T,y2=1
x3=(1,1)T,y3=−1x_3 = (1,1)^T, y_3 = -1x3=(1,1)T,y3=−1
优化问题 § 标准式:
minw,b12∣∣w∣∣2=minw1,w2,b12(w12+w22)\min_{w,b} \frac{1}{2}||w||^2 = \min_{w_1, w_2, b} \frac{1}{2}(w_1^2 + w_2^2)w,bmin21∣∣w∣∣2=w1,w2,bmin21(w12+w22)
约束条件 (s.t.): yi(w⋅xi+b)≥1(i=1,2,3)y_i(w \cdot x_i + b) \ge 1 \quad (i=1,2,3)yi(w⋅xi+b)≥1(i=1,2,3)
展开即为:
{1⋅(3w1+3w2+b)≥11⋅(4w1+3w2+b)≥1−1⋅(w1+w2+b)≥1⇒w1+w2+b≤−1\begin{cases} 1 \cdot (3w_1 + 3w_2 + b) \ge 1 \\ 1 \cdot (4w_1 + 3w_2 + b) \ge 1 \\ -1 \cdot (w_1 + w_2 + b) \ge 1 \quad \Rightarrow \quad w_1 + w_2 + b \le -1 \end{cases}⎩ ⎨ ⎧1⋅(3w1+3w2+b)≥11⋅(4w1+3w2+b)≥1−1⋅(w1+w2+b)≥1⇒w1+w2+b≤−1
第 2 步:写出原问题的拉格朗日函数
为三个约束条件分别引入非负拉格朗日乘子 α1,α2,α3≥0\alpha_1, \alpha_2, \alpha_3 \ge 0α1,α2,α3≥0。
拉格朗日函数:
L(w,b,α)=12∣∣w∣∣2−∑i=13αiyi(w⋅xi+b)−1L(w,b,\alpha) = \frac{1}{2}||w||^2 - \sum_{i=1}^{3} \alpha_i y_i(w \\cdot x_i + b) - 1L(w,b,α)=21∣∣w∣∣2−i=1∑3αiyi(w⋅xi+b)−1
展开代入数据:
L(w,b,α)=12(w12+w22)−α1(3w1+3w2+b−1)−α2(4w1+3w2+b−1)−α3(−w1−w2−b−1)L(w,b,\alpha) = \frac{1}{2}(w_1^2 + w_2^2) - \alpha_1(3w_1 + 3w_2 + b - 1) - \alpha_2(4w_1 + 3w_2 + b - 1) - \alpha_3(-w_1 - w_2 - b - 1)L(w,b,α)=21(w12+w22)−α1(3w1+3w2+b−1)−α2(4w1+3w2+b−1)−α3(−w1−w2−b−1)
第 3 步:写出对偶问题 (D)
根据之前的推导,令 LLL 对 w,bw, bw,b 偏导为 000,得到对偶目标函数 minα12∑∑αiαjyiyj(xi⋅xj)−∑αi\min_{\alpha} \frac{1}{2}\sum\sum \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) - \sum \alpha_iminα21∑∑αiαjyiyj(xi⋅xj)−∑αi。
首先计算各个点之间的内积(核函数矩阵 Kij=xi⋅xjK_{ij} = x_i \cdot x_jKij=xi⋅xj):
- x1⋅x1=3×3+3×3=18x_1 \cdot x_1 = 3\times3 + 3\times3 = 18x1⋅x1=3×3+3×3=18
- x1⋅x2=3×4+3×3=21x_1 \cdot x_2 = 3\times4 + 3\times3 = 21x1⋅x2=3×4+3×3=21
- x1⋅x3=3×1+3×1=6x_1 \cdot x_3 = 3\times1 + 3\times1 = 6x1⋅x3=3×1+3×1=6
- x2⋅x2=4×4+3×3=25x_2 \cdot x_2 = 4\times4 + 3\times3 = 25x2⋅x2=4×4+3×3=25
- x2⋅x3=4×1+3×1=7x_2 \cdot x_3 = 4\times1 + 3\times1 = 7x2⋅x3=4×1+3×1=7
- x3⋅x3=1×1+1×1=2x_3 \cdot x_3 = 1\times1 + 1\times1 = 2x3⋅x3=1×1+1×1=2
代入目标函数公式,并加入等式约束 ∑αiyi=0\sum \alpha_i y_i = 0∑αiyi=0:
对偶问题 (D):
minα12(18α12+25α22+2α32+42α1α2−12α1α3−14α2α3)−(α1+α2+α3)\min_{\alpha} \left \\frac{1}{2} (18\\alpha_1\^2 + 25\\alpha_2\^2 + 2\\alpha_3\^2 + 42\\alpha_1\\alpha_2 - 12\\alpha_1\\alpha_3 - 14\\alpha_2\\alpha_3) - (\\alpha_1 + \\alpha_2 + \\alpha_3) \\rightαmin21(18α12+25α22+2α32+42α1α2−12α1α3−14α2α3)−(α1+α2+α3)
约束条件:
{α1(1)+α2(1)+α3(−1)=0⇒α1+α2=α3α1≥0, α2≥0, α3≥0\begin{cases} \alpha_1(1) + \alpha_2(1) + \alpha_3(-1) = 0 \quad \Rightarrow \quad \alpha_1 + \alpha_2 = \alpha_3 \\ \alpha_1 \ge 0, \ \alpha_2 \ge 0, \ \alpha_3 \ge 0 \end{cases}{α1(1)+α2(1)+α3(−1)=0⇒α1+α2=α3α1≥0, α2≥0, α3≥0
第 4 步:写出 KKT 条件
强对偶定理成立,最优解 (w∗,b∗,α∗)(w^*, b^*, \alpha^*)(w∗,b∗,α∗) 必须满足以下 KKT 条件:
- 梯度为零: w1∗=3α1∗+4α2∗−α3∗;w2∗=3α1∗+3α2∗−α3∗w_1^* = 3\alpha_1^* + 4\alpha_2^* - \alpha_3^* \quad ; \quad w_2^* = 3\alpha_1^* + 3\alpha_2^* - \alpha_3^*w1∗=3α1∗+4α2∗−α3∗;w2∗=3α1∗+3α2∗−α3∗
- 等式约束: α1∗+α2∗−α3∗=0\alpha_1^* + \alpha_2^* - \alpha_3^* = 0α1∗+α2∗−α3∗=0
- 互补松弛条件:
- α1∗(3w1∗+3w2∗+b∗−1)=0\alpha_1^* (3w_1^* + 3w_2^* + b^* - 1) = 0α1∗(3w1∗+3w2∗+b∗−1)=0
- α2∗(4w1∗+3w2∗+b∗−1)=0\alpha_2^* (4w_1^* + 3w_2^* + b^* - 1) = 0α2∗(4w1∗+3w2∗+b∗−1)=0
- α3∗(−w1∗−w2∗−b∗−1)=0\alpha_3^* (-w_1^* - w_2^* - b^* - 1) = 0α3∗(−w1∗−w2∗−b∗−1)=0
- 原问题可行: 3w1∗+3w2∗+b∗≥13w_1^* + 3w_2^* + b^* \ge 13w1∗+3w2∗+b∗≥1 等 3 个原不等式成立。
- 对偶问题可行: α1∗,α2∗,α3∗≥0\alpha_1^*, \alpha_2^*, \alpha_3^* \ge 0α1∗,α2∗,α3∗≥0
第 5 步:求解对偶问题 (结合 SMO 思想)
由于有约束 α3=α1+α2\alpha_3 = \alpha_1 + \alpha_2α3=α1+α2,我们直接将 α3\alpha_3α3 代入对偶目标函数中进行消元(这正是 SMO 算法每次挑出两个变量,用等式约束消掉一个的核心思想的体现!):
W(α1,α2)=1218α12+25α22+2(α1+α2)2+42α1α2−12α1(α1+α2)−14α2(α1+α2)−2α1−2α2W(\alpha_1, \alpha_2) = \frac{1}{2} 18\\alpha_1\^2 + 25\\alpha_2\^2 + 2(\\alpha_1+\\alpha_2)\^2 + 42\\alpha_1\\alpha_2 - 12\\alpha_1(\\alpha_1+\\alpha_2) - 14\\alpha_2(\\alpha_1+\\alpha_2) - 2\alpha_1 - 2\alpha_2W(α1,α2)=2118α12+25α22+2(α1+α2)2+42α1α2−12α1(α1+α2)−14α2(α1+α2)−2α1−2α2
合并同类项,完成了降维打击,得到一个纯粹的一元二次函数(包含两个变量):
W(α1,α2)=4α12+132α22+10α1α2−2α1−2α2W(\alpha_1, \alpha_2) = 4\alpha_1^2 + \frac{13}{2}\alpha_2^2 + 10\alpha_1\alpha_2 - 2\alpha_1 - 2\alpha_2W(α1,α2)=4α12+213α22+10α1α2−2α1−2α2
求极值,分别对 α1,α2\alpha_1, \alpha_2α1,α2 求偏导并令其为 0:
{∂W∂α1=8α1+10α2−2=0∂W∂α2=13α2+10α1−2=0\begin{cases} \frac{\partial W}{\partial \alpha_1} = 8\alpha_1 + 10\alpha_2 - 2 = 0 \\ \frac{\partial W}{\partial \alpha_2} = 13\alpha_2 + 10\alpha_1 - 2 = 0 \end{cases}{∂α1∂W=8α1+10α2−2=0∂α2∂W=13α2+10α1−2=0
解这个方程组,得到未经剪裁的理论极值:α1=1.5,α2=−1\alpha_1 = 1.5, \alpha_2 = -1α1=1.5,α2=−1。
【触发 SMO 的剪裁机制】
我们发现 α2=−1<0\alpha_2 = -1 < 0α2=−1<0,跌破了下限!违背了 αi≥0\alpha_i \ge 0αi≥0 的约束。
这意味着理论极值在合法的"方形牢笼"外面。因此,最优解必定在边界上。我们强制进行剪裁,令 α2=0\alpha_2 = 0α2=0。
将合法的 α2=0\alpha_2 = 0α2=0 重新代回 WWW 对 α1\alpha_1α1 的导数公式中:
8α1+0−2=0⇒α1=148\alpha_1 + 0 - 2 = 0 \quad \Rightarrow \quad \alpha_1 = \frac{1}{4}8α1+0−2=0⇒α1=41
再通过等式约束求出 α3\alpha_3α3:
α3=α1+α2=14+0=14\alpha_3 = \alpha_1 + \alpha_2 = \frac{1}{4} + 0 = \frac{1}{4}α3=α1+α2=41+0=41
最终求得完美满足 KKT 条件的最优乘子:
α∗=(14,0,14)T\alpha^* = (\frac{1}{4}, 0, \frac{1}{4})^Tα∗=(41,0,41)T
(注:α2=0\alpha_2=0α2=0 说明点 x2(4,3)x_2(4,3)x2(4,3) 非常安全,不是支持向量;而 α1,α3>0\alpha_1, \alpha_3 > 0α1,α3>0 说明点 x1x_1x1 和 x3x_3x3 恰好压在边界线上,是标准的支持向量!)
第 6 步:写出最终分离超平面方程
拿到 α∗\alpha^*α∗ 后,计算模型权重 w∗w^*w∗:
w∗=∑i=13αi∗yixi=14(1)(33)+0+14(−1)(11)=(0.50.5)w^* = \sum_{i=1}^3 \alpha_i^* y_i x_i = \frac{1}{4}(1)\begin{pmatrix} 3 \\ 3 \end{pmatrix} + 0 + \frac{1}{4}(-1)\begin{pmatrix} 1 \\ 1 \end{pmatrix} = \begin{pmatrix} 0.5 \\ 0.5 \end{pmatrix}w∗=i=1∑3αi∗yixi=41(1)(33)+0+41(−1)(11)=(0.50.5)
计算偏置 b∗b^*b∗(找一个支持向量,比如 x1(3,3)x_1(3,3)x1(3,3) 代入):
b∗=y1−w∗⋅x1=1−(0.5×3+0.5×3)=1−3=−2b^* = y_1 - w^* \cdot x_1 = 1 - (0.5 \times 3 + 0.5 \times 3) = 1 - 3 = -2b∗=y1−w∗⋅x1=1−(0.5×3+0.5×3)=1−3=−2
最终的分离超平面方程为:
w∗⋅x+b∗=0⇒0.5x(1)+0.5x(2)−2=0w^* \cdot x + b^* = 0 \quad \Rightarrow \quad 0.5x^{(1)} + 0.5x^{(2)} - 2 = 0w∗⋅x+b∗=0⇒0.5x(1)+0.5x(2)−2=0
即:x(1)+x(2)−4=0x^{(1)} + x^{(2)} - 4 = 0x(1)+x(2)−4=0
补充:SVM 核心思想小结
- 线性本质: 它是一种力图最大化分隔边界与数据点之间"安全距离"的线性模型。
- 非线性扩展: 利用核函数(Kernel Method),它不仅度量了样本之间的相似度,更实现了低维度数据向高维线性可分空间的"免费跳跃"。
- 计算逻辑: 原始问题 →\rightarrow→ 构建松弛变量(应对噪声) →\rightarrow→ 转化为凸优化问题 →\rightarrow→ 利用拉格朗日法转化为只依赖内积的对偶形式(降维打击) →\rightarrow→ 结合核函数与 SMO 算法高效解出参数 α\alphaα →\rightarrow→ 反求 b∗b^*b∗ 并输出预测模型。