一、前言
本文基于李沐《动手学深度学习 v2》课程内容整理,涵盖回归、分类模型选型、损失函数、数据集划分、过拟合与欠拟合、超参数调优、正则化、权重初始化、梯度稳定性等核心知识点,结合 Kaggle 实战场景与工程落地经验,梳理深度学习从理论到实操的完整流程,适合深度学习入门者系统梳理知识框架。

二、基础模型区分:回归、二分类、多分类
2.1 任务本质区别
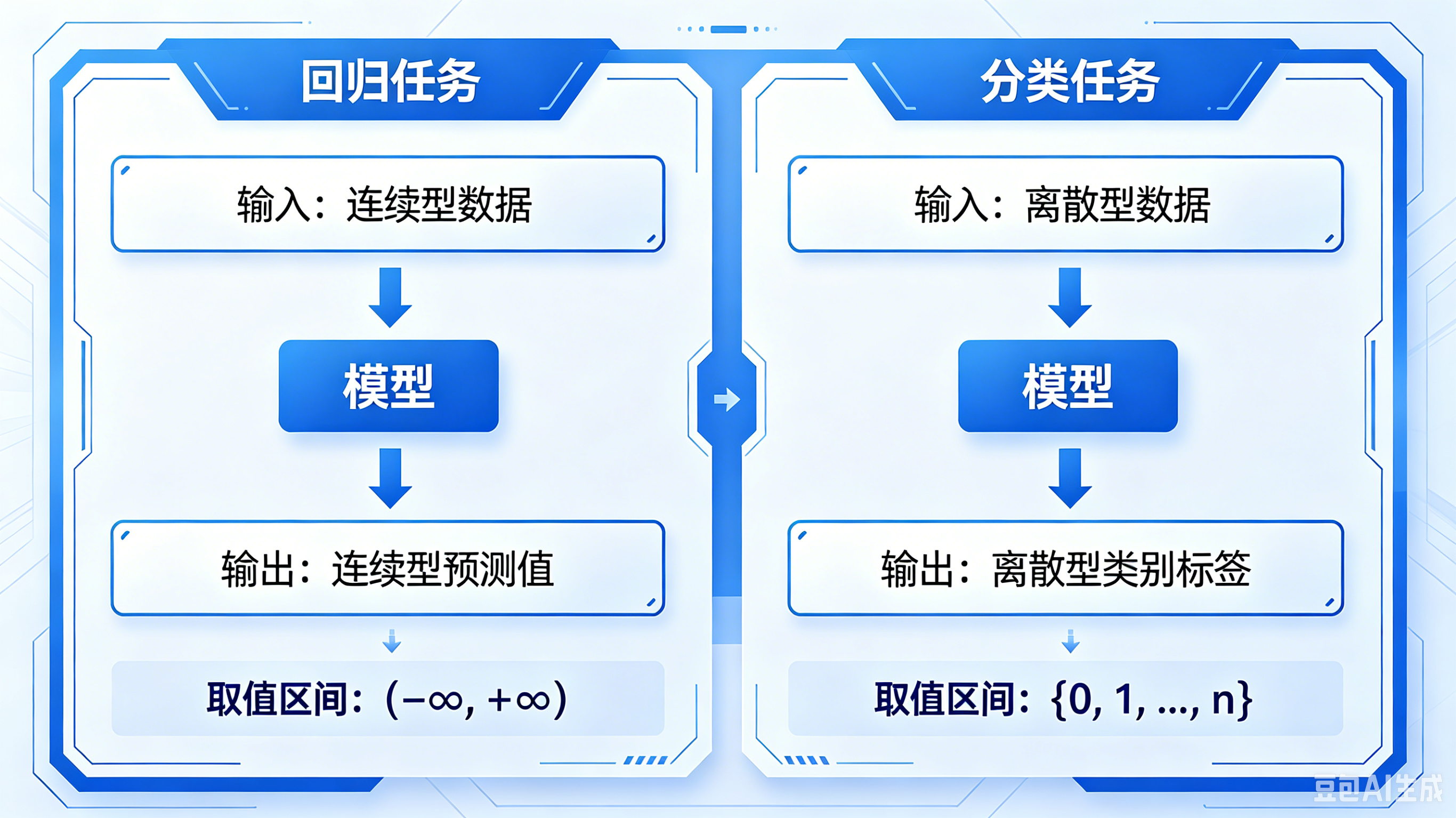
机器学习主流分为回归预测 与分类两大任务,核心差异在输出形式与损失设计:
- 回归任务 :输出连续数值,取值范围为全体实数,损失由预测值与真实值的偏差计算。
- 分类任务:输出类别置信度 / 类别标识,细分二分类、多分类;图像识别、文本分类均属于典型分类场景。
2.2 主流模型对比
| 模型 | 输出形式 | 适用场景 | 配套损失 / 激活 |
|---|---|---|---|
| 线性回归(LinearRegress) | 单个连续数值 | 数值预测、趋势预估 | RMSE(均方误差) |
| Softmax 回归 | 各类别预测概率 | 多分类、图像分类(如 Kaggle 蛋白质图像 28 分类) | 交叉熵损失 |
| 单层感知机 | -1 / 1 二值输出 | 简单二分类 | 无复杂激活,无法解决异或 (XOR) 问题,现已淘汰 |
| 多层感知机(MLP) | -1 / 1 二值输出 | 复杂二分类、非线性任务 | ReLU/Sigmoid 激活 |
拓展实战案例:Kaggle 人类蛋白质显微镜图像分类赛,任务为将细胞图像划分为 28 个细胞器类别,属于典型多分类任务,行业内优先使用 Softmax 搭配卷积网络实现。
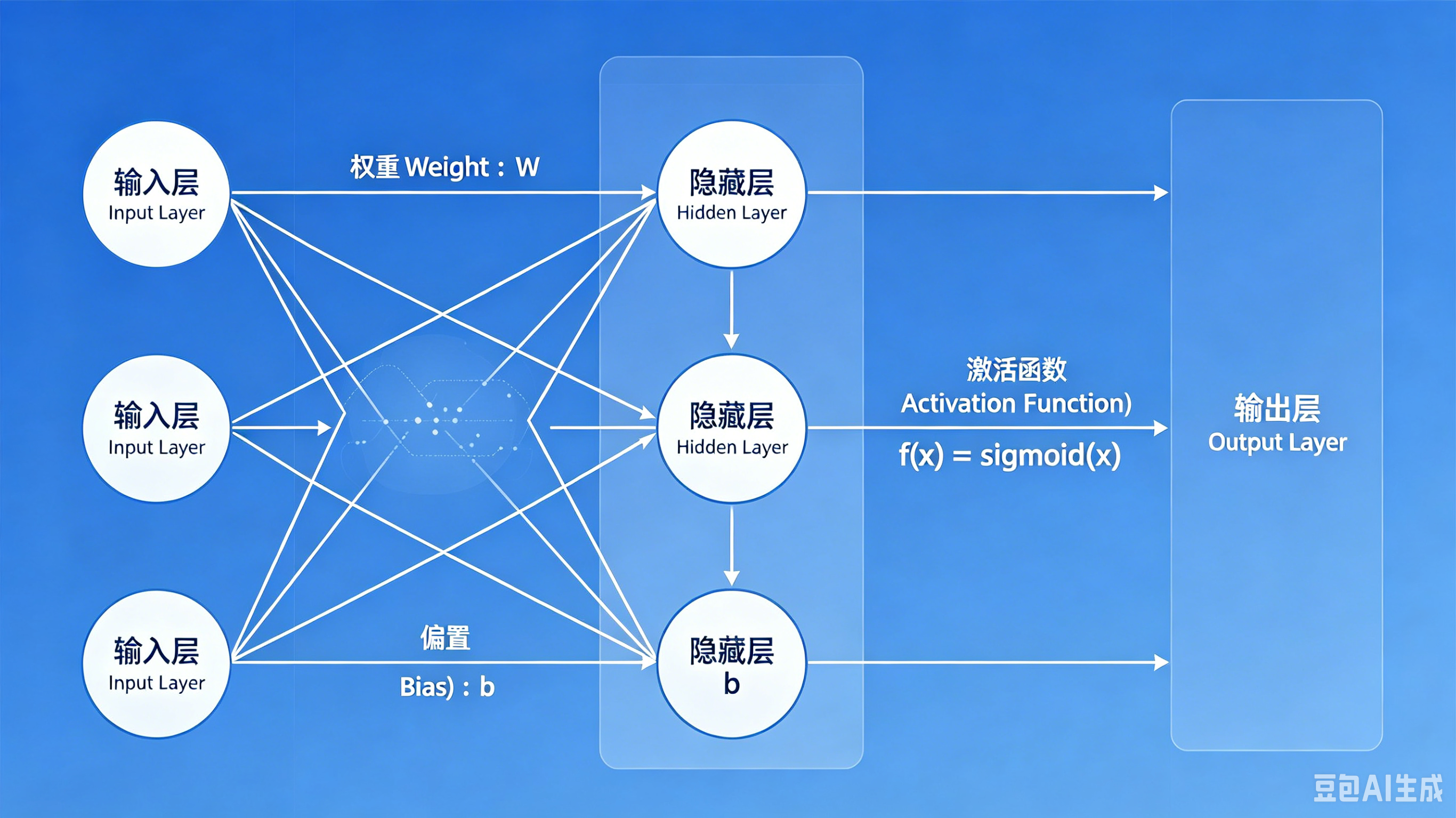
2.3 激活函数选型
激活函数为网络引入非线性,是拟合复杂任务的核心:
- Sigmoid:将数值映射至 (0,1) 区间,多用于早期二分类场景,易出现梯度消失。
- ReLU :当前主流激活函数,计算简单、梯度传导稳定,深度学习网络优先选用。

三、损失函数基础
- RMSE(均方误差):线性回归标配损失函数,通过预测值与真实值的偏差衡量模型误差,驱动参数自动迭代优化。
- 似然函数:分类任务的理论基础,Softmax 回归结合极大似然思想,输出类别概率并计算分类损失。

四、误差体系:训练误差 & 泛化误差
4.1 核心概念
- 训练误差 :模型在训练集上计算得到的误差,反映模型对训练数据的拟合程度。
- 泛化误差 :模型在全新未知数据 上的误差,工程落地唯一关注指标,代表模型真实能力。
核心原则:学习模型的本质是理解误差成因、缩小泛化误差,而非单纯记忆训练数据。
4.2 数据集划分规范
数据集是模型训练的基础,严格区分训练集、验证集、测试集是避免结果失真的关键:
- 训练集:用于模型参数迭代、学习数据特征。
- 验证集 :评估模型效果、调试超参数,不可与训练集混用。
- 测试集 :仅使用一次的最终评测数据集(如 Kaggle 私有榜、线上真实业务数据),严禁反复调参使用。
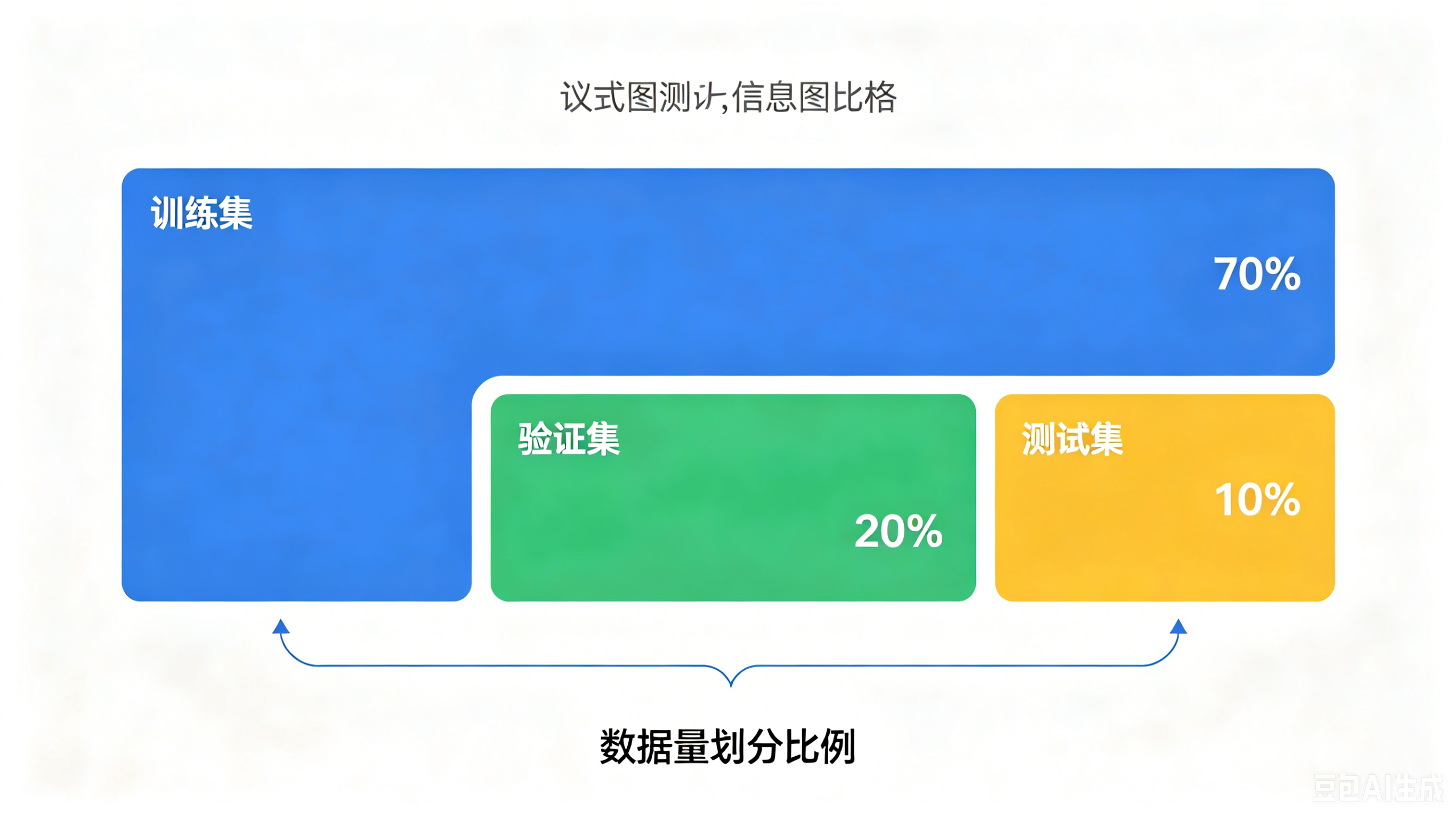
通用划分比例
- 小样本数据:训练集 70% + 测试集 30%
- 大样本数据(万级以上):训练集 50% + 测试集 50%
- 时序数据:存在数据自相关特性,禁止随机划分;截取中间段作为验证 / 测试集,前后分段作为训练集。
4.3 K 折交叉验证
适用场景
训练数据量不足(深度学习常态),无法单独拆分足量验证集时使用。
执行流程
- 将整体训练集均匀划分为 K 个子集(行业常用 K=5、K=10);
- 循环 K 次:每次选取 1 个子集作为验证集,剩余 K-1 个子集作为训练集;
- 取 K 轮验证误差的平均值作为最终模型评估结果。
补充说明:K 值越大,验证结果越可靠,但算力消耗越高;深度学习算力成本高,大型模型一般规避高 K 值交叉验证。
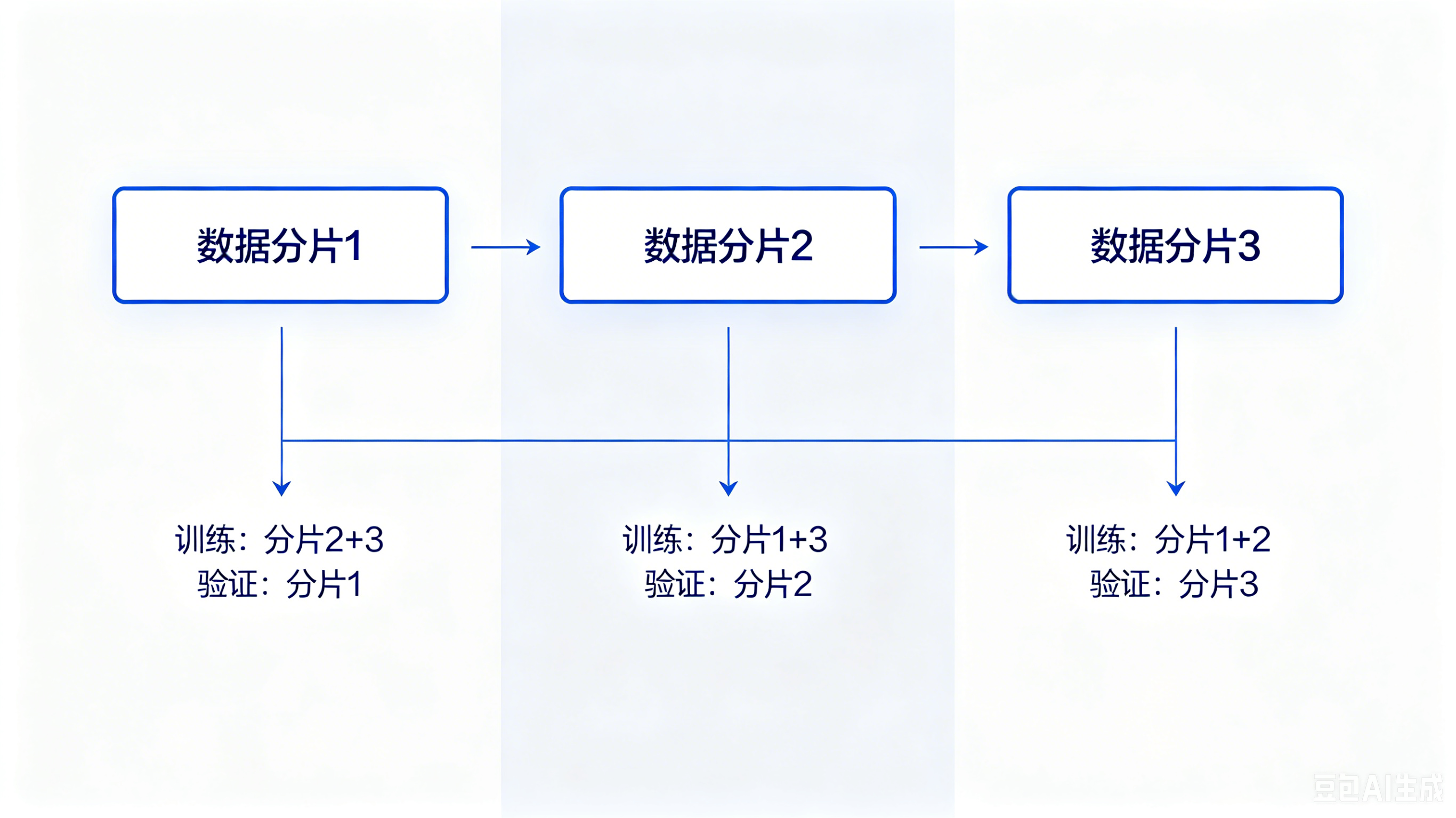
示例:三折交叉验证
将数据分为 3 份,轮流取单份为验证集,其余为训练集:
- 第 1 轮:第 2 份为验证集,1、3 份为训练集
- 第 2 轮:第 1 份为验证集,2、3 份为训练集
- 第 3 轮:第 3 份为验证集,1、2 份为训练集

五、欠拟合 & 过拟合:模型容量与数据复杂度
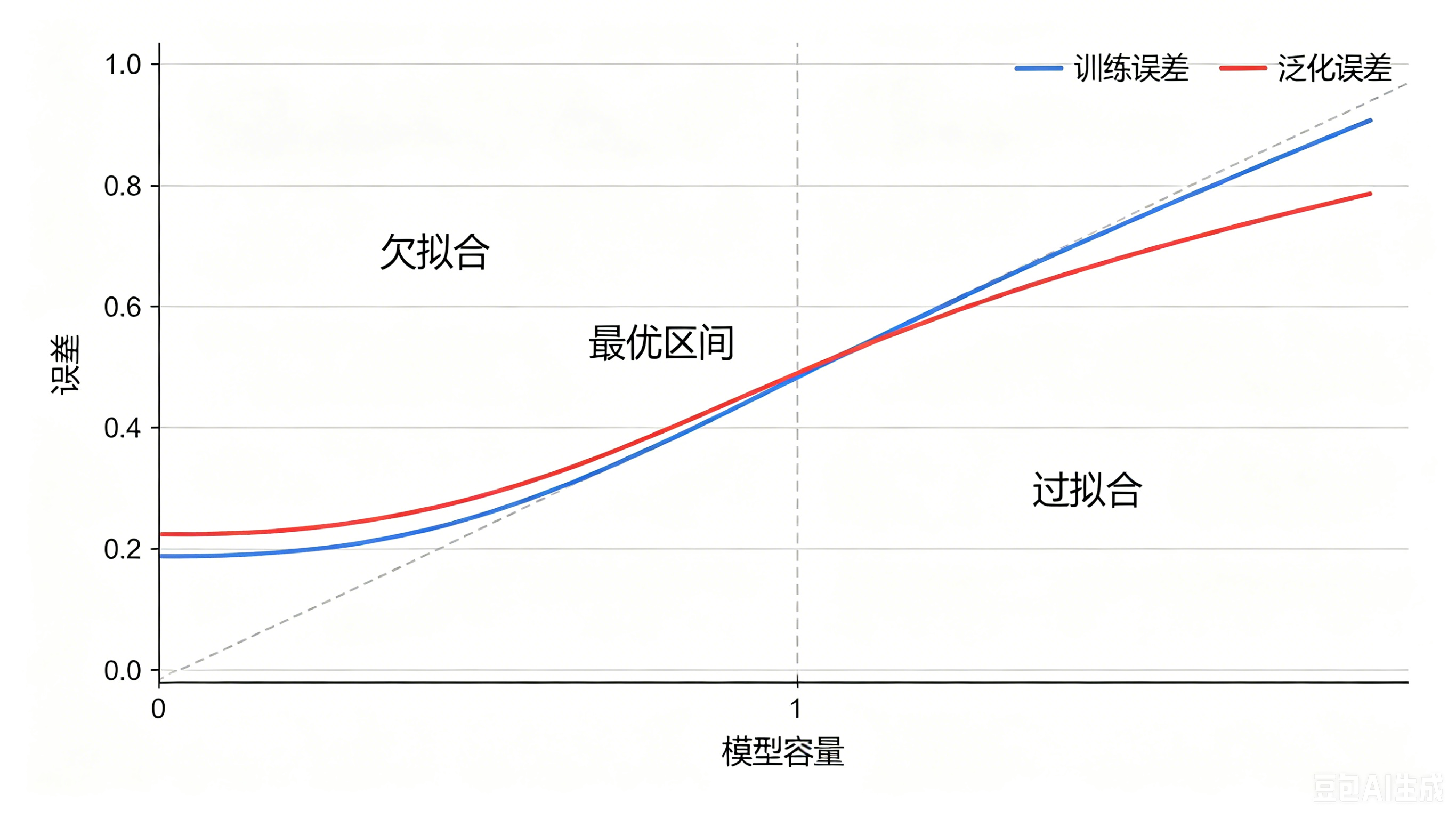
5.1 核心关系
- 模型容量:模型拟合复杂数据的能力(网络层数、参数量越大,容量越高)。
- 数据复杂度:由样本数量、单样本特征维度、数据结构、样本多样性共同决定。
5.2 两种典型问题
- 欠拟合 :模型容量过低,无法捕捉数据规律。表现:训练误差、泛化误差均偏高。 解决方案:提升模型复杂度、增加网络层数、扩充特征。
- 过拟合 :模型容量过高,过度记忆训练数据噪声,无法泛化到新数据。表现:训练误差极低、泛化误差极高。 解决方案:正则化、丢弃法、扩充数据集、数据预处理降噪。
工程实操:工业场景中难以做到完全拟合,小幅过拟合属于可接受范围。

六、超参数调优实战
6.1 基础概念
- 模型内部参数:网络权重、偏置,由模型在训练集自动迭代更新。
- 超参数:人为预先设定、依靠验证集调试的参数(学习率、网络层数、正则系数、树模型参数等)。
6.2 主流调参方式
- 经验调参:依托行业经验设定参数区间,是入门最常用方式。
- 网格遍历:在指定区间内按步长遍历所有参数组合,择优选用。
- 随机搜索 :随机抽取多组超参数组合,对比验证误差,选择最优组合;也可对多组优质模型结果做集成平均。
6.3 常用超参数参考区间
以树模型、神经网络通用参数为例:
| 超参数 | 参考区间 | 作用说明 |
|---|---|---|
| learning_rate(学习率) | 0.01 ~ 0.3 | 数值越小训练越稳健,收敛越慢 |
| n_estimators(决策树数量) | 50 ~ 500 | 数量越多模型效果越好,推理速度越慢 |
| max_depth(树深度) | 3 ~ 10 | 限制模型复杂度,防止过拟合 |
| subsample(数据采样率) | 0.5 ~ 1.0 | 随机采样训练数据,弱化过拟合 |
| L1 正则 (reg_alpha) | 0 ~ 10 | 稀疏化特征,过滤无效特征 |
| L2 正则 (reg_lambda) | 0 ~ 10(常用 1~5) | 限制参数大小,平滑模型 |
6.4 K 折交叉验证的落地用法
- 利用 K 折验证确定最优超参数,再使用全量训练集重新训练最终模型;
- 筛选 K 轮中精度最优的单组模型,固定超参数直接上线;
- 集成学习:保留 K 轮训练得到的 K 个模型,预测时对结果取平均,提升鲁棒性。

七、正则化与模型复杂度控制
针对过拟合问题,主流通过正则化、丢弃法约束模型容量。
7.1 权重衰退(L2 正则)
- 原理:在损失函数中增加 L2 正则项,限制网络参数的绝对值大小,避免参数极端化。
- 核心:正则项权重是控制模型复杂度的超参数。
7.2 丢弃法(Dropout)
- 原理:训练过程中随机将隐藏层部分输出置 0,弱化神经元之间的依赖关系,抑制过拟合。
- 核心:丢弃概率为关键超参数,仅作用于多层感知机、神经网络的隐藏层。

八、训练稳定性:梯度问题与权重初始化
深度网络极易出现梯度爆炸、梯度消失,导致训练报错(输出 NaN/Inf),核心解决方案为合理权重初始化、梯度优化。
8.1 梯度爆炸问题
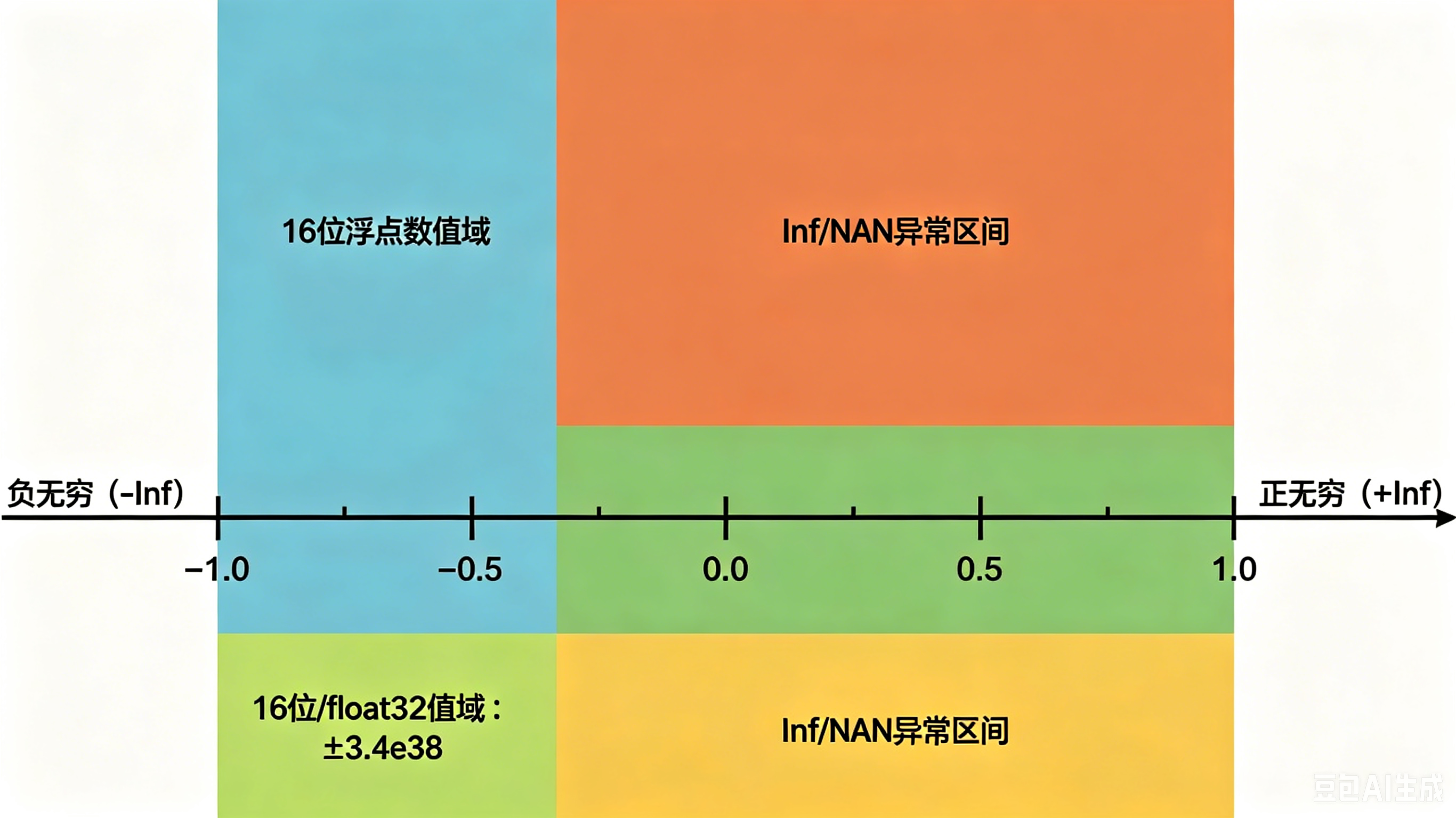
- 现象:梯度数值超出浮点值域,出现无穷大 (Inf)、非数值 (NaN);16 位浮点数对该问题尤为敏感。
- 诱因:学习率过大 → 参数更新幅度过大 → 梯度进一步放大;学习率过小则模型无法收敛。
- 临时解决:降低学习率、调整激活函数、选用 32 位浮点数(float32)训练。
8.2 权重初始化
- 随机初始化:简单网络可使用
(0, 0.01)正态分布初始化,不适用于深度网络。 - Xavier 初始化:业界通用的深度网络初始化方案,保证每一层输入、输出数值分布稳定,从源头降低梯度异常概率。
8.3 通用优化方案(保证训练稳定)
- 数值改造:将矩阵乘法转化为加法(如 ResNet、LSTM 结构设计思想),弱化梯度连乘放大效应;
- 梯度处理:梯度归一化、梯度裁剪;
- 基础优化:搭配合理权重初始化 + ReLU 激活函数。

九、技术演进与工程落地思路
9.1 经典模型迭代路线
单层感知机 → 多层感知机 (MLP) → SVM → 卷积神经网络 (CNN)
规律:技术框架不断更新,但机器学习底层逻辑、数据处理、模型调优思想长期稳定,掌握核心原理才能适配技术迭代。
9.2 完整工程流程(拿到数据后标准步骤)
- 数据层:数据清洗、降噪、特征提取;
- 模型层:根据任务选型(回归 / 分类),AI 辅助或人工选定模型;
- 初始化:网络权重初始化、基础参数配置;
- 数据集划分:拆分训练集、验证集、测试集;
- 训练调优:训练模型、验证集调试超参数、正则化抑制过拟合;
- 最终评测:使用仅一次的测试集评估泛化能力,上线落地。
9.3 待进阶知识点
本文梳理了模型、调参、训练基础,后续需深耕:数据清洗、高阶特征工程、复杂网络结构设计。

十、总结
- 任务选型:回归用线性回归 + RMSE,多分类用 Softmax,二分类优先多层感知机 + ReLU;
- 数据划分:严格区分训练 / 验证 / 测试集,小数据用 K 折交叉验证,时序数据禁止随机划分;
- 拟合控制:欠拟合提升模型容量,过拟合使用 L2 正则、Dropout、扩充数据集;
- 训练稳定:深度网络使用 Xavier 初始化 + ReLU,警惕梯度爆炸,优先选用 float32;
- 工程核心:理论是根基,实操以泛化误差为唯一目标,小幅过拟合在业务中可接受。