目录
[二、为什么选择"YOLOv8 + LPRNet"两阶段方案](#二、为什么选择“YOLOv8 + LPRNet”两阶段方案)
[三、检测端改进:在 YOLOv8s 中加入 SE Attention](#三、检测端改进:在 YOLOv8s 中加入 SE Attention)
[六、桌面端实现:PyQt5 把算法封装成可用工具](#六、桌面端实现:PyQt5 把算法封装成可用工具)
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主。
车牌识别看起来只是"框出车牌、读出号码",真正做起来会发现细节不少。图片来源不同、车牌大小不同、光照和角度不同,都会影响检测框的位置;车牌区域裁剪后,汉字、字母、数字又需要按顺序识别。为了让流程更稳,我采用 YOLOv8s 负责车牌区域定位,在检测网络中加入 SE Attention 增强关键通道表达,再使用 LPRNet 完成字符序列识别,最后通过 PyQt5 做成图形化程序,让用户可以直接选择图片、文件夹、视频或摄像头进行识别。
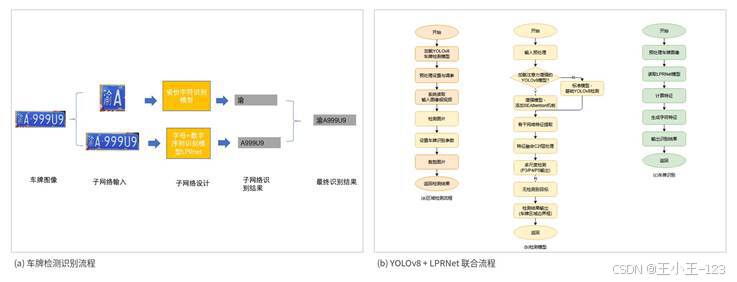
图1 车牌检测与字符识别整体流程
一、项目效果先看:从图片到车牌号自动输出
这个项目最终呈现的是一个桌面端识别工具。打开系统后,可以看到左侧或主区域用于显示待检测图像,按钮区域负责选择图片、选择文件夹、开始运行、视频检测和结果保存,右侧或下方区域展示检测类别、置信度、车牌号、坐标等信息。实际使用时,只需要把待检测图片导入,点击运行,模型会先定位车牌区域,再把车牌区域传给识别模块,最后把识别到的车牌号码显示在界面中。
相比命令行推理,图形界面的优势很明显:不会写代码的人也可以使用,演示时效果更直观,结果也更容易保存。对于学生项目来说,能把算法封装成一个可操作的软件,比只展示训练日志更容易说明项目完整性。图片检测、批量检测、视频检测、结果导出这些功能都做出来后,整个项目就不再像一个"模型实验",而更像一个可以继续扩展的小型应用。
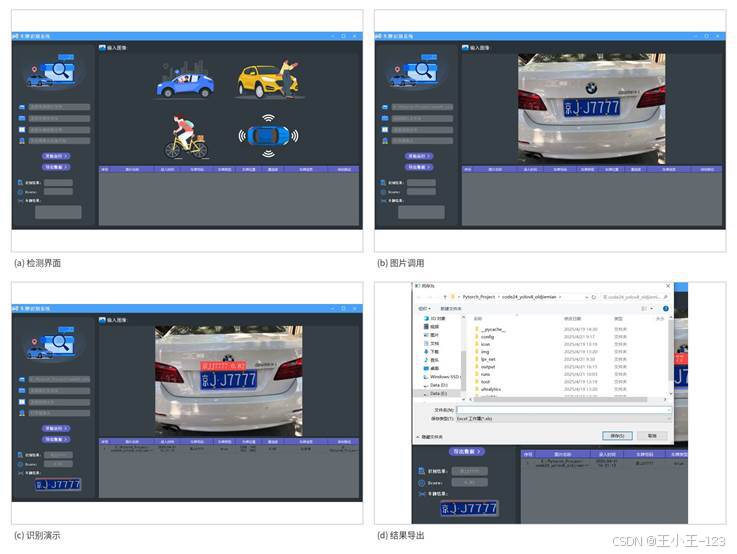
图2 系统界面、图片调用、识别演示与结果导出
在视频检测中,系统按帧读取视频内容,对每一帧进行车牌区域检测和字符识别。即使画面存在轻微模糊、车牌尺寸较小或背景比较复杂,模型仍能给出较稳定的识别结果。后台日志也会同步记录检测过程,便于后续排查模型加载、图像读取、识别输出和文件保存等问题。
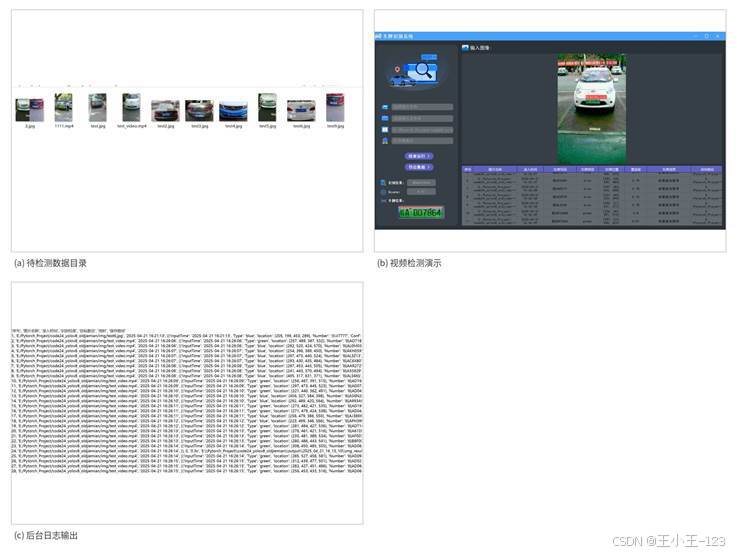
图3 批量数据、视频检测与后台日志展示
二、为什么选择"YOLOv8 + LPRNet"两阶段方案
车牌识别一般可以拆成两个核心问题:第一个问题是车牌在哪里,第二个问题是车牌上写了什么。前者属于目标检测任务,后者属于序列识别任务。直接用一个模型端到端输出车牌号当然也可以,但对数据量、模型结构和训练稳定性要求更高。对于课程设计和毕业设计来说,两阶段结构更清晰,解释起来也更容易。
第一阶段使用 YOLOv8s。YOLOv8 的优势在于实时性好、接口成熟、训练部署方便。它由 Backbone、Neck 和 Head 组成,Backbone 提取图像特征,Neck 进行多尺度融合,Head 输出检测框和类别。车牌通常属于小目标或中小目标,尤其是在监控画面中车牌区域占比不大,因此多尺度特征融合非常重要。YOLOv8s 在精度和速度之间比较平衡,参数量不会过大,普通 GPU 或配置较好的 CPU 环境下也能完成推理。
第二阶段使用 LPRNet。传统车牌识别常见做法是先把每个字符切出来,再逐个分类。这种方式对字符分割质量依赖很强,车牌一旦倾斜、污损、反光或边缘模糊,就容易出现切割错误。LPRNet 不需要逐字符分割,而是把整张车牌图像作为输入,通过卷积网络提取特征,再结合 CTC 思想完成序列解码。这样一来,模型可以直接学习车牌字符的整体排列规律,对轻微倾斜和局部模糊更友好。
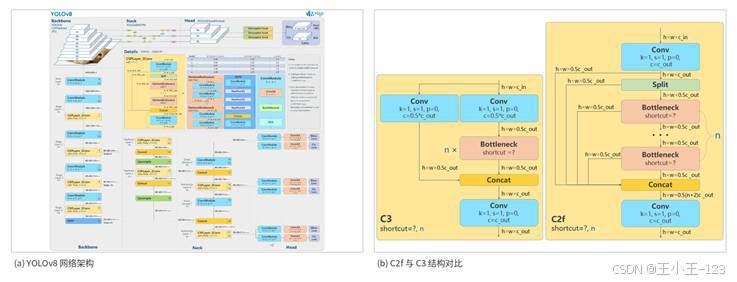
图4 YOLOv8 网络结构与 C2f 模块对比
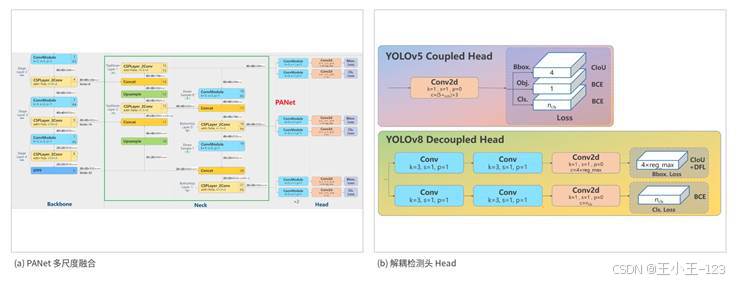
图5 PANet 多尺度融合与解耦检测头
三、检测端改进:在 YOLOv8s 中加入 SE Attention
原始 YOLOv8s 已经具备不错的检测能力,但车牌场景仍然存在一些典型难点。比如夜间灯光反射会让车牌边界变得不清晰,新能源绿牌与背景颜色接近时容易受到干扰,远距离监控画面中的车牌面积较小,车辆遮挡也会影响模型对车牌区域的判断。为了提升模型对关键特征的关注能力,我在 YOLOv8s 的结构中加入了 SE Attention 模块。
SE Attention 的核心思想很直接:先通过全局平均池化压缩每个通道的信息,再通过两层全连接生成通道权重,最后把这些权重作用到原始特征图上。通俗一点说,就是让网络自己判断哪些通道更重要,哪些通道可以降低权重。车牌检测任务中,字符边缘、车牌边框、颜色区域和局部纹理都可能成为有效信息,SE 模块可以帮助模型把注意力集中到这些更有价值的通道上。
我没有把注意力模块随意堆叠到所有位置,而是放在主干与 Neck、Head 相关的关键连接处。这样做的好处是既能增强特征表达,又不会明显增加参数量和推理开销。训练过程中可以看到,加入注意力后损失下降更平稳,检测框贴合程度更好,复杂背景下被忽略或误识别的目标明显减少。对于车牌这种目标小、信息密集、边界细的任务,通道注意力的收益比较直观。
四、数据准备:标注、划分与训练集组织
数据部分主要围绕蓝牌和绿牌两类车牌展开。样本来源包括公开交通图像、模拟场景拍摄图像以及部分网络数据,用来覆盖白天、夜间、雨天、不同角度和不同背景。为了适配 YOLOv8 的训练流程,图像统一整理为标准目录结构,并使用 LabelImg 对车牌区域进行人工框选,标签保存为 TXT 格式。每个标签文件记录类别编号和归一化后的边界框坐标。
数据整理完成后,按照训练集、验证集和测试集进行划分。项目中一共整理了 9638 张图像,其中训练集 6910 张,验证集 1363 张,测试集 1365 张。这样的划分可以保证模型有足够样本学习车牌区域特征,同时通过验证集观察训练过程中的泛化表现,再用测试集做最终效果评估。
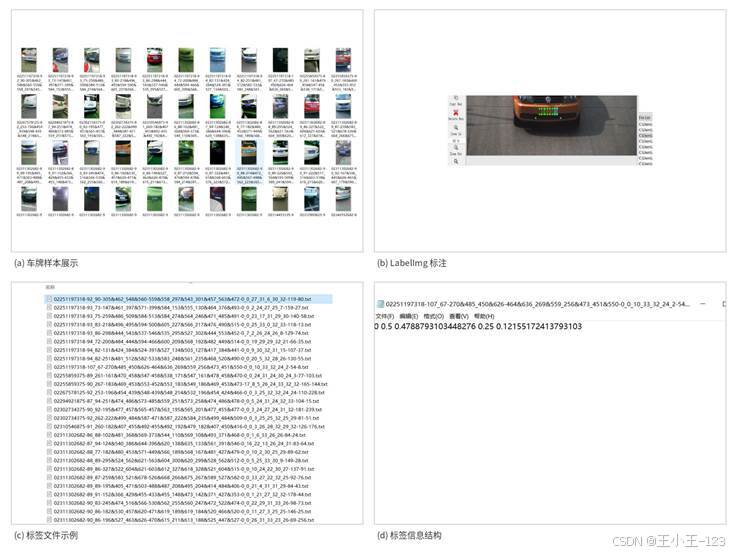
图6 数据展示、LabelImg 标注与标签信息
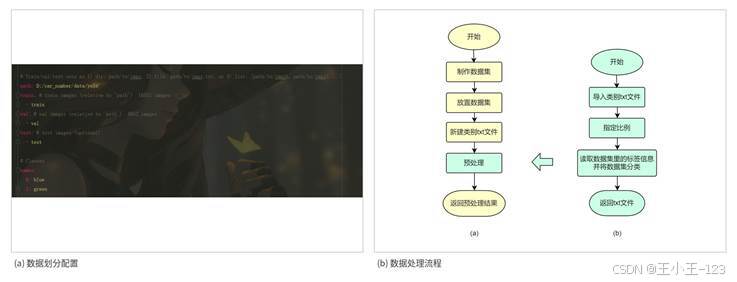
图7 数据划分配置与处理流程
在训练之前,还需要把类别文件、图片路径、标签路径和模型配置文件统一起来。类别简化为 blue 和 green,便于模型同时完成车牌检测和颜色类别区分。图像输入前统一缩放到 640×640,并结合边缘填充避免图像变形。这样处理之后,训练数据格式更加规整,模型读取速度也更稳定。
五、训练流程:从预训练权重到模型收敛
训练阶段没有从零开始随机初始化,而是使用预训练权重作为起点。这样做可以缩短前期收敛时间,让模型先具备基础的边缘、纹理和形状识别能力,再逐步适应车牌检测任务。训练过程中,图片按批次送入网络,模型完成前向传播后计算损失,再通过反向传播不断更新参数。
检测端主要关注 box loss、cls loss、dfl loss 以及 Precision、Recall、mAP 等指标。box loss 反映检测框位置偏差,cls loss 反映类别判断能力,dfl loss 用于提升边界框回归质量。Precision 越高,说明误检越少;Recall 越高,说明漏检越少;mAP50 和 mAP50-95 可以综合判断模型检测效果。
识别端训练 LPRNet 时,以蓝牌和绿牌测试集进行识别验证,核心指标为 Accuracy,同时统计预测正确、序列长度错误、字符错误等情况。LPRNet 使用贪婪解码完成字符输出,不额外引入语言模型或规则校验,在这种直接解码方式下仍然能够保持较高精度,说明网络对车牌字符序列的建模能力比较稳定。
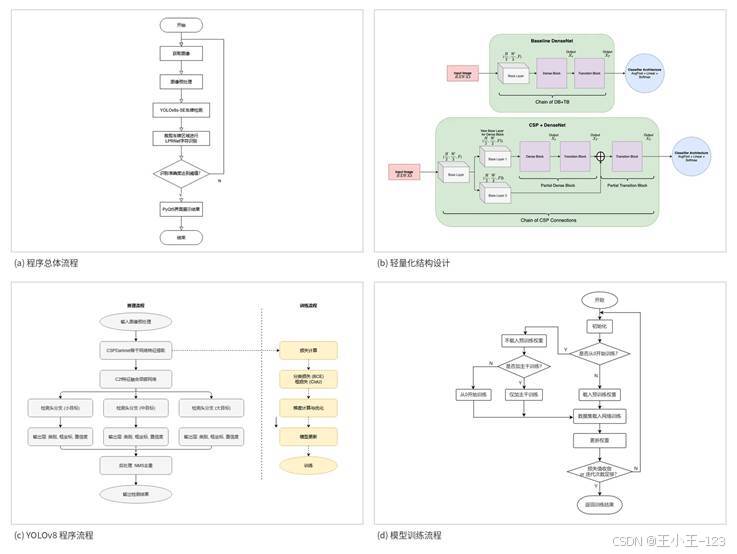
图8 程序总体流程、轻量化结构与训练流程
六、桌面端实现:PyQt5 把算法封装成可用工具
很多深度学习项目的问题不是模型不能跑,而是展示和使用不够方便。为了让系统更适合演示和落地,我用 PyQt5 设计了图形界面。界面开发先通过 Qt Designer 完成布局,再把界面文件转换为 Python 代码,最后绑定按钮事件和模型推理逻辑。这样做比纯代码手写界面更直观,后期维护也更方便。
界面功能主要包括图片选择、文件夹选择、视频选择、摄像头调用、模型运行、结果展示和结果导出。图片识别时,系统会把检测框绘制到原图上,并显示车牌号、类别和置信度;批量识别时,可以对文件夹内的多张图片循环处理;视频识别时,系统按帧读取并实时展示;结果导出时,可以保存为 CSV 或 Excel,方便后续统计。
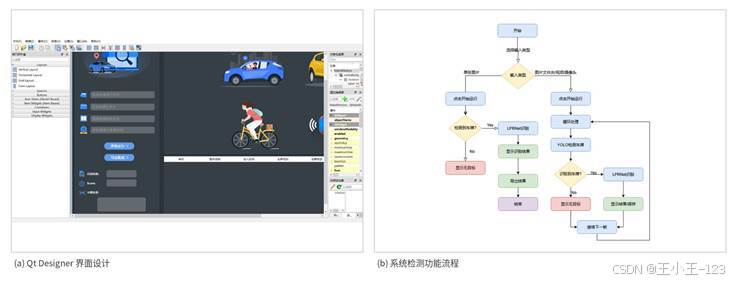
图9 Qt Designer 界面设计与检测功能流程
这部分是项目展示中很加分的一环。因为用户能直接看到"导入图像---点击运行---出现框和车牌号---导出结果"的完整闭环,系统完整度会比单独放一张预测图更强。对于后续扩展来说,界面层也可以继续接入数据库、车辆黑名单、停车计费规则、摄像头 RTSP 流或云端接口。
七、实验效果:检测稳定,识别速度快
从检测结果看,加入 SE Attention 后,模型在蓝牌和绿牌上的区分能力较好。混淆矩阵显示,blue 类样本大部分能够被正确识别,green 类虽然存在少量交叉误检,但整体仍保持较高水平。F1-Confidence 曲线接近上界,说明模型在置信度阈值变化时仍能兼顾精度和召回。
Precision-Recall 曲线表现也比较理想,说明检测端误检和漏检都控制得比较好。Recall-Confidence 曲线在较低阈值区域保持稳定,这对于实际部署很重要,因为车牌识别宁可多给出候选区域,也不能轻易漏掉关键车牌。Loss 曲线整体下降平稳,训练和验证指标没有明显震荡,说明注意力模块没有破坏原有网络结构的稳定性。
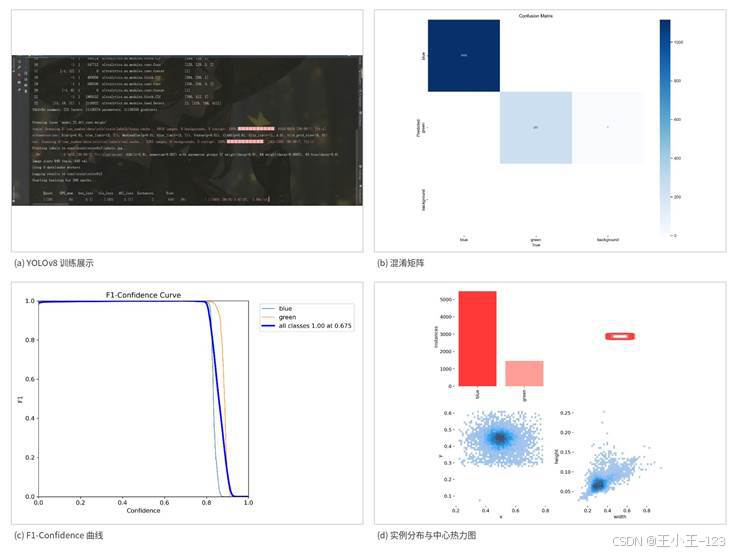
图10 训练展示、混淆矩阵、F1 曲线与样本分布
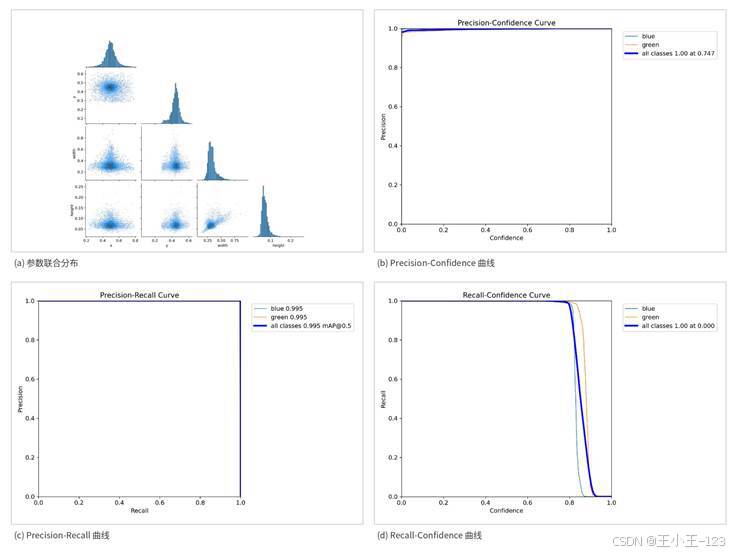
图11 参数分布、精度曲线与召回曲线
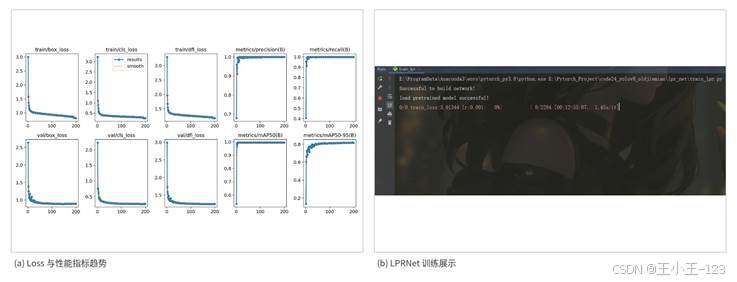
图12 Loss 指标变化与 LPRNet 训练展示
识别端的表现同样比较稳定。蓝牌整体识别准确率达到 99.5%,绿牌整体识别准确率达到 95.5%。蓝牌准确率更高,主要是因为蓝牌格式更常见、样本量更多、字符结构更稳定;绿牌样本相对少一些,并且新能源车牌字符长度和颜色特征与蓝牌不同,所以更容易受到样本不均衡和复杂环境影响。
在 YOLOv8s 原始模型和加入 SE 模块后的模型对比中,Precision 和 Recall 基本保持在同一高水平,差异主要体现在 mAP50-95 这类更严格的指标上。加入注意力机制后,mAP50-95 有小幅提升,边界框位置和细节处理更稳。提升幅度虽然不是夸张式增长,但考虑到 SE 模块本身很轻量,这个改动是值得保留的。

图13 原始 YOLOv8s 日志与改进后效果对比
八、项目亮点总结
第一,系统结构完整。项目不是停留在算法层,而是从数据整理、模型训练、性能评估到前端界面都做了闭环。检测端负责定位,识别端负责读数,界面端负责交互和展示,三个部分之间逻辑清晰。
第二,技术组合合理。YOLOv8s 负责轻量实时检测,SE Attention 负责强化通道特征,LPRNet 负责免分割字符识别,PyQt5 负责桌面端封装。这种组合既能体现深度学习方法,也能体现工程实现能力。
第三,功能展示直观。系统支持图片、文件夹、视频和摄像头输入,也支持识别结果保存。无论是答辩演示还是项目汇报,都可以通过界面快速展示识别流程,不需要现场敲命令。
第四,实验指标支撑充分。项目中给出了混淆矩阵、F1 曲线、Precision-Recall 曲线、Recall-Confidence 曲线、训练损失曲线以及 LPRNet 识别结果,能够从多个角度说明模型性能,而不是只展示几张成功案例。
九、可继续优化的方向
这个系统已经具备完整雏形,但后续仍有很多可以扩展的空间。第一,可以继续扩大夜间、雨天、强反光、遮挡车牌和远距离车牌的数据量,提高模型在极端场景下的鲁棒性。第二,可以在检测端尝试 CBAM、ECA、CoT-block 等注意力模块,与 SE Attention 做对比,看不同注意力机制对小目标检测的影响。第三,可以在识别端加入轻量语言先验或规则校验,减少相似字符误识别,例如 0/O、1/I、8/B 等。
工程部署方面,也可以把桌面端继续升级为 Web 系统,后端提供模型推理接口,前端负责展示图片、视频流和识别记录。对于停车场、园区门禁、道路监控等场景,还可以接入数据库,记录车牌号、识别时间、图片路径、置信度和通行状态。再往后扩展,就能做成一个简化版车牌管理平台。
如果要部署在边缘设备上,可以考虑模型压缩、ONNX 导出、TensorRT 加速或 NCNN 推理。检测模型可以换成更轻量的 YOLOv8n,识别模型也可以进一步裁剪通道数,以换取更低延迟。这样一来,系统就不只适合电脑端演示,也能面向嵌入式设备和实际摄像头场景。
十、结语
车牌识别是一个很适合做成完整项目的方向。它既有明确的应用场景,又有成熟的算法路线,还能通过界面和可视化结果快速体现工作量。这个项目围绕 YOLOv8s、SE Attention、LPRNet 和 PyQt5 完成了从检测到识别、从训练到部署、从模型到界面的完整串联。整体效果比较适合学生项目展示,也适合继续扩展为智慧停车、车辆管理和交通监控类应用。
从实现体验来看,最关键的不是单纯追求某一个指标,而是把每个环节打通:数据要能训练,模型要能推理,识别结果要能展示,结果文件要能保存,界面操作要足够简单。只有这些环节都串起来,一个项目才会真正有"系统感"。
附:项目技术栈速览
|--------|------------------------------------------|-------------------------|
| 模块 | 主要技术 | 作用 |
| 车牌检测 | YOLOv8s + SE Attention | 定位蓝牌、绿牌车牌区域,输出检测框与置信度 |
| 字符识别 | LPRNet + CTC Decode | 读取省份简称、字母和数字组合,减少字符切割依赖 |
| 数据处理 | LabelImg / TXT 标签 / train-val-test | 完成样本标注、类别划分和训练集组织 |
| 界面展示 | PyQt5 / Qt Designer | 实现图片、文件夹、视频、摄像头检测与结果导出 |
| 评估分析 | mAP / Precision / Recall / F1 / Accuracy | 从检测与识别两个维度验证模型效果 |
每文一语
把复杂问题拆成清晰步骤,再用合适的工具逐个解决,项目就会一点点变得完整。