给扩散模型装上"能量导航";蛋白质生成和单细胞分析任务更精准
更新概览
Kaiwu-PyTorch-Plugin于6月初正式发布v0.2.0版本,本次更新的核心为:把量子/经典能量模型的"判断力"注入到生成模型和表征学习中。具体如下:
一、新增Q-Diffusion功能,支持使用玻尔兹曼机作为能量模型优化扩散过程;
二、新增Q-Diffusion生成案例:基于DPLM的完整蛋白质序列生成工作流及效果对比;
三、新增Q-VAE单细胞表征学习案例:提供单细胞表征学习完整流程;https://github.com/qboson/kaiwu-pytorch-plugin/tree/main/example/qvae_cell
一、Q-Diffusion
业务场景中很多数据不是连续的像素,而是离散的序列------如蛋白质序列、DNA/RNA序列、文本、图结构等,这类数据的特点是:组合空间巨大,约束条件复杂,靠人工规则筛选困难。传统的离散扩散模型能"生成"候选结果,但缺少一个判断"生成得是否好"的机制。Q-Diffusion (量子扩散模型) 是 KPP 项目中用于能量引导离散扩散生成的通用模块 ,即 在传统离散扩散模型的基础上添加能量引导,引导生成任务 的执行。
相较于传统离散扩散模型主要依靠自身的去噪网络逐步从噪声token中恢复样本,Q-Diffusion的创新点在于**把"扩散生成"和"能量引导"结合起来。**扩散模型每一步产生候选序列后,会调用一个能量模型(如BM或RBM)对这些候选序列进行打分、重排和筛选,从而引导生成过程朝更符合目标方向演化。生成过程既保留了扩散模型的多步探索能力,又利用了能量模型的全局约束表达能力。
二、Q-Diffusion 蛋白质序列生成案例
背景介绍
蛋白质由20种常见的氨基酸组成,本质上是一类离散序列。一个蛋白质序列是否"合理",不仅取决于每个氨基酸token本身是否常见,还取决于整条序列是否满足结构稳定性、功能相关性、进化保守性等约束。
结合思路
本案例采用的思路是:冻结预训练好的蛋白质扩散模型(后续简称DPLM,checkpoint:airkingbd/dplm_150m),让DPLM负责生成候选序列,另外训练一个BM能量模型,负责对候选序列进行整体评价和筛选。
在训练时, 适配层将DPLM提取到的序列特征转换为BM 可识别 的表示 ,BM学习 真实蛋白序列与生成候选之间的差异,对候选序列进行能量打分;在 **生成时,**BM对候选序列进行重排和筛选,选择更符合真实蛋白分布或目标约束的结果。
案例代码请参考: https://github.com/qboson/kaiwu-pytorch-plugin/tree/main/example/qdiffusion/dplm
结果说明
使用ESM2模型**(** Meta **AI 开发的蛋白质语言模型,是生物 AI 领域的重要工具)**将蛋白序列转换为embedding向量,比较生成序列和真实序列在向量空间里的距离。
|-------------------|---------|----------------------|----------------------|------------|------------|
| label | 数据数 | 平均 余弦 距离 | 中位 余弦 距离 | 平均L2距离 | 中位L2距离 |
| B aseline | 100 | 0.228741 | 0.208566 | 5.105006 | 4.967555 |
| G uided | 100 | 0.189941 | 0.158290 | 4.669310 | 4.437943 |
-
baseline **:**未加入BM,单独使用DPLM生成的结果;
-
guided **:**加入Q-Diffusion后的生成结果;
-
余弦 **距离:**衡量两个序列embedding的方向差异;
-
**L2距离:**表示欧氏距离,衡量两个embedding向量之间的整体距离。
余弦距离和L2距离均为越小越好。使用Q-Diffusion后,两项指标均明显下降,说明 模型生成的蛋白序列在ESM2表征空间中更接近真实蛋白序列 。
Q-VAE单细胞表征学习案例
背景介绍
单细胞RNA测序数据主要记录每个细胞中基因的表达水平,具有数据维度高、噪声强、易受批次效应影响等特点。实际分析中常关心的是模型是否能从这些复杂数据中提取出有用的低维表征,让相同类型的细胞聚在一起,不同类型的细胞区分开来。
结合思路
本案例将VAE的表征学习能力和BM能量建模能力结合,流程如下:
(1)通过编码器将高维基因表达矩阵压缩到低维潜在空间;
(2)解码器根据潜在表示重构原始表达数据;
(3)训练完成后,模型提取X_qvae作为单细胞低维表征,用于UMAP、聚类和分类评估,同时计算QVAE_Energy,用于观察不同细胞类型在能量空间中的分布差异。
在传统VAE的重构损失和KL约束之外,本例引入BM能量模型对潜在表示进行能量建模和约束------不仅要求模型重构有较高相似性,还要求低维潜在空间本身有合理的能量结构。
案例代码请参考: https://github.com/qboson/kaiwu-pytorch-plugin/tree/main/example/qvae_cell,案例展示了模型训练、表征提取、能量分析的完整流程。
结果说明
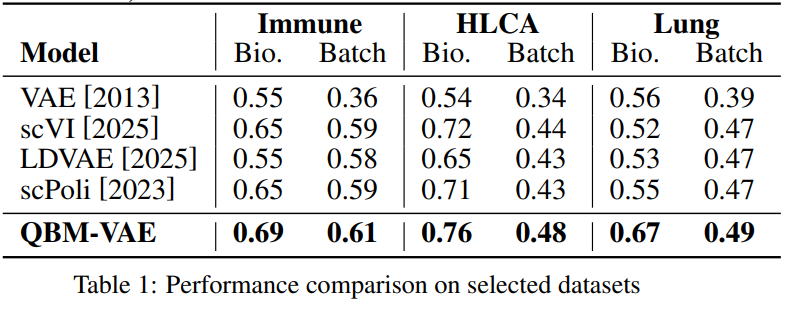
(1)性能表现
在多个单细胞数据集上,QBM-VAE在批次效应校正、表征聚类、分类等任务上均取得了SOTA结果:
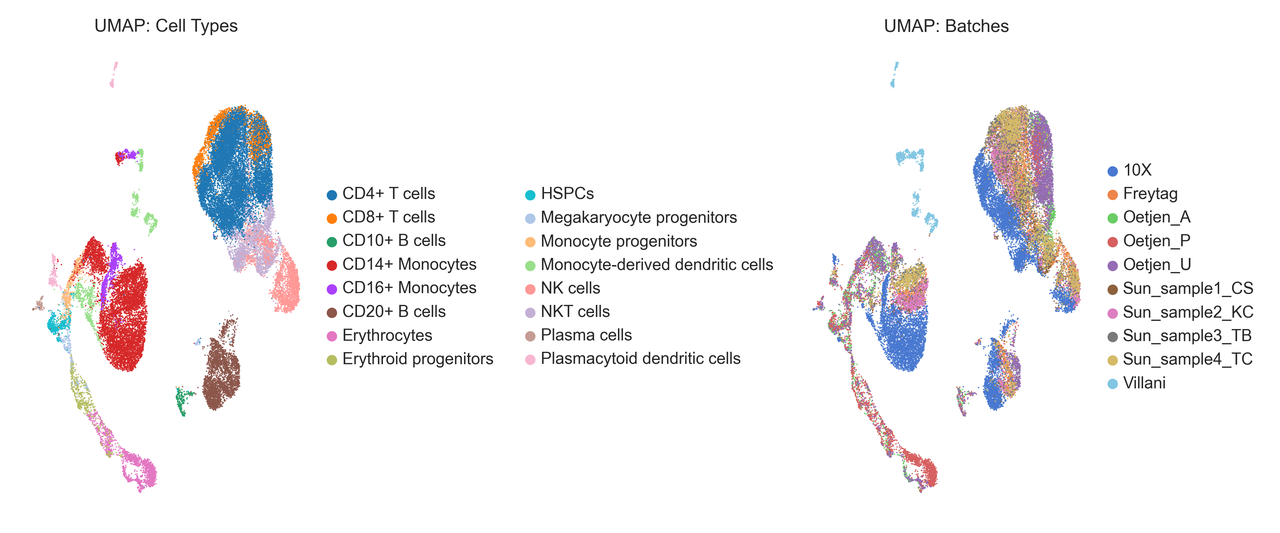
(2)可视化效果
将提取的X_qvae表征用于单细胞可视化:
-
按细胞类型(Cell Types)着色,不同类型细胞形成清晰的独立区域;
-
**按批次(Batches)着色,**不同批次细胞混合均匀,没有与细胞类型存在对应关系。
这说明模型不仅成功学习到细胞的内在表征,将不同的细胞区分开来,同时有效减弱了批次的干扰。
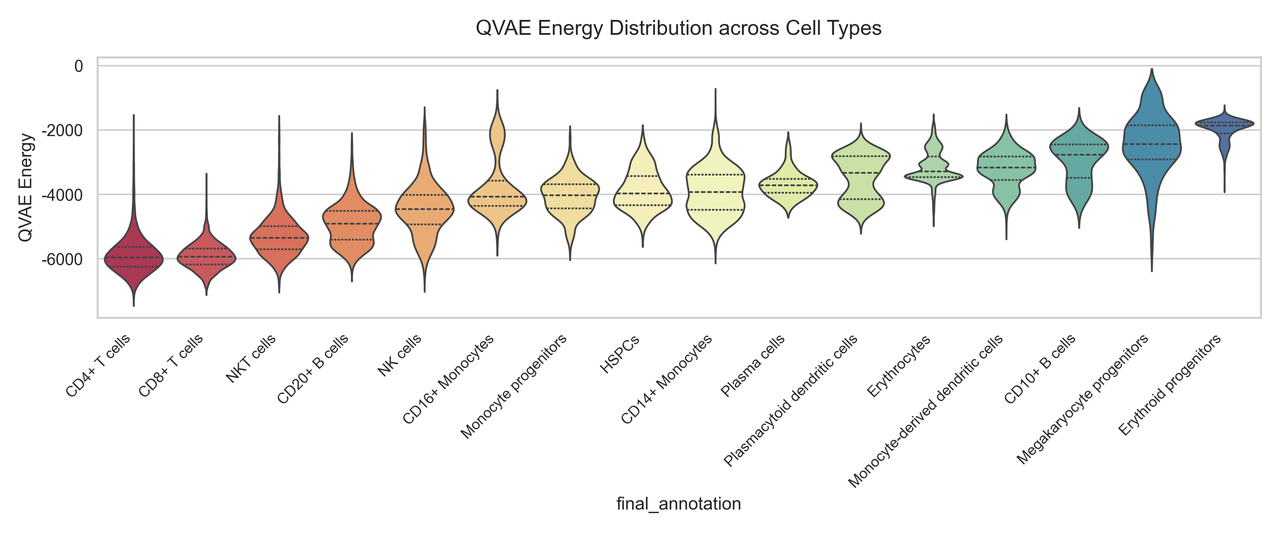
(3)能量景观分析
Q-VAE模型的优势在于:不同细胞类型、不同分化程度的细胞会呈现出不同的energy分布。
能量 值 的下降 对应了细胞分化过程,形成"能量景观图",可帮助定位细胞在分化路径中的位置,这是经典 VAE 无法提供的视角。
arXiv 论文链接: https://arxiv.org/abs/2508.11190
欢迎大家前来体验,同时欢迎大家提出意见及反馈!