一、缺失值处理
1.1 删除缺失值 .dropna()
读取数据
python
df.read_csv('路径')查看数据
python
df.info()
df.describe() #大致知道哪些列有缺失删除缺失行
python
df.dropna() # 不会修改原数据,加 inplace=True 修改原数据 默认axis=0
df.dropna(axis=0) # 删除行
df.dropna(axis=1) # 删除列1.2 填充缺失值 .fillna()
np.notnull() 非空返回True,否则为False
np.isnull() 缺失值返回True,否则为False
python
# 遍历列名
for col_name in df.columns:
# 判断每一列是否有缺失值
if np.all(np.notna(df[col_name])) == False:
# 如进来就说明这一列有缺失值
# 打印有缺失值的列名
print(col_name)
# 将该列的缺失值用该列的均值做替换
df[col_name].fillna(df[col_name].mean(), inplace=True)1.3 替换缺失值(缺失值有特殊标志)
背景:实际开发中,不是所有的缺失值都会用NaN来表示,例如:可能用?表示,如何删除这些缺失值呢?
思路:先转换,后删除,即:? --> NaN --> 删除.
python
df.replace('?', np,nan).dropna()二、数据合并
2.1 contact()
可以同时拼接多个表,能行合并、列合并,默认列合并,不能指定拼接字段
细节:行合并参考 行索引;列合并参考 列名
axis=0是列合并,axis=1是行合并
join=outer是满外连接 = 左表全集 + 交集 + 右表全集
join=inner 是内连接 = 交集
python
df=pd.contact([df1,df2], axis=0/1, join='outer/inner')2.2 merge()
只能行合并
how=默认inner ,还有outer、left(左连接)、right(右连接)
on=是指定用那一列/多列 作为拼接字段
python
pd.merge(左表, 右表, how='inner', on=None)三、数据分组
3.1 分组聚合
格式
python
df.groupby(['分组字段1','分组字段2',...]).agg('列名1':'聚合函数名', '列名2':'聚合函数2', ...)场景1:按照单列分组
python
df.groupby(['city']) # DataFrameGroupBy-->DataFrame分组对象
df.groupby('city') # 效果同上场景2 :按照多列分组
python
df.groupby(['city', 'channel'])场景3:如何获得某个分组的数据
python
df.groupby(['city','channel']).get_group(['北京','线上']) # 一个分组的信息
df.groupby(['city','channel']).get_group(['上海','线下']) # 另一个分组的信息场景4:分组+聚合(聚合字段只有1个)
python
写法1:(掌握)
df.groupby(['city','channel']).agg('revenue':'sum') # 返回DataFrame对象
写法2:(了解)
df.groupby(['city','channel']).revenue.sum() # 返回Series对象
df.groupby(['city','channel'])['revenue'].sum() # 返回Series对象
df.groupby(['city','channel'])[['revenue']].sum() # 返回DataFrame对象场景5:分组+聚合(聚合字段有2个,聚合函数相同)
python
写法1:(掌握)
df.groupby(['city','channel']).agg('revenue':'sum','order':'max')
写法2:(了解)
df.groupby(['city','channel'])[['revenue','order']].sum()场景6:分组+聚合(聚合字段有2个,聚合函数不同)
python
# 没有其他写法了
df.groupby(['city','channel']).agg({
'revenue': 'mean',
'unit_cost':'sum'
})3.2 分组过滤
格式
python
df.groupby(['列名1','列名2',...]).filter(lambda x:...)例如:按城市分组,查找每组销售金额平均值大于200的全部数据
python
df.groupby('city').filter(lambda x:x.revenue.mean()>200)
等价于
df.groupby('city').filter(lambda x:x['revenue'].mean()>200)四、交叉表与透视表
交叉表:计算一列数据对另一列数据分组的个数
透视表:指定某一列对另一列的关系
4.1 交叉表(了解)
python
tb = pd.crosstab(值1, 值2)4.2 透视表(掌握)
需求:根据城市、销售渠道分组,计算销售金额总和。
写法1:分组+聚合
python
df.groupby(['city', 'channel']).agg({'revenue':'sum'})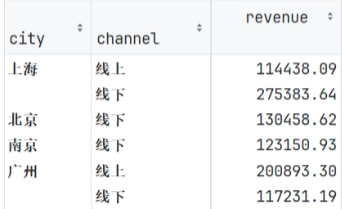
写法2:透视表
参1:指定分组字段;参2:指定分组字段;参3:指定聚合字段;参4:指定聚合函数
python
df.pivot_table(index='city', columns='channel', values='revenue', aggfunc='sum')