一、集群、节点、分片、副本:核心架构名词解读
在开始之前,先用一个现实类比帮你建立直觉:
把 ElasticSearch 集群想象成一家大型图书馆连锁。集群是整个连锁品牌,节点是每家分馆,分片是分馆里的书架区域,副本是对热门书架区域的备份复印件。
下面这张结构图展示了它们的物理关系:
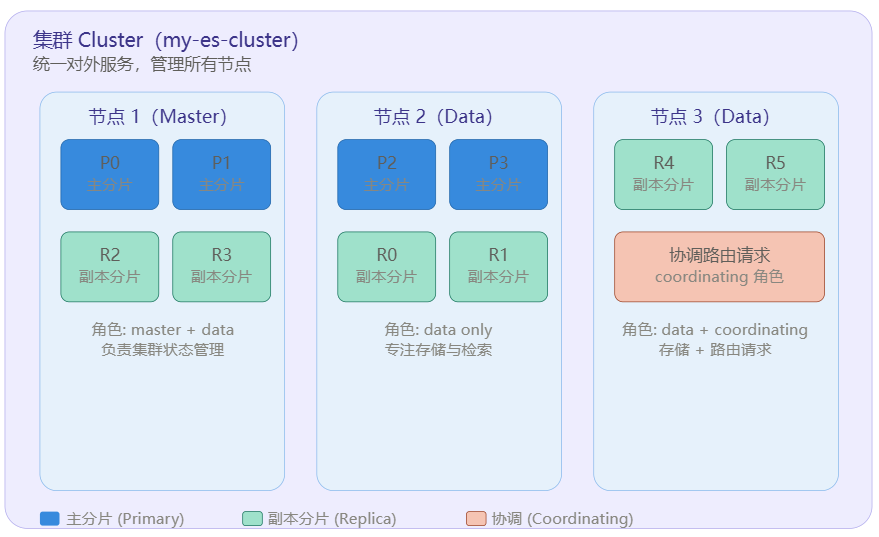
1.1 集群(Cluster)
集群是多个 ES 节点的集合,它们共享同一个集群名称(cluster.name),对外表现为一个整体服务。集群有且只有一个 Active Master 节点,负责维护集群元数据状态(索引信息、节点列表、分片路由表等)。
关键特性:
- 集群名称是节点发现和加入集群的唯一依据,生产环境绝对不能用默认值
elasticsearch - 集群健康状态分三级:🟢 Green(全部正常)/ 🟡 Yellow(主分片正常,有副本缺失)/ 🔴 Red(有主分片不可用)
- 通过
GET /_cluster/health可实时查询
1.2 节点(Node)
节点就是运行 ES 进程的一台机器(或一个实例)。每个节点可同时承担多种角色:
|-----------------|------------------------|---------------------|
| 节点角色 | 配置项 | 职责描述 |
| Master-eligible | node.roles: master | 参与 Master 选举,管理集群状态 |
| Data | node.roles: data | 存储分片数据,执行查询和索引 |
| Ingest | node.roles: ingest | 数据预处理管道(如分词、格式转换) |
| Coordinating | 默认每个节点都是 | 接收请求、路由到正确分片、汇总结果 |
架构师视角:生产环境一定要角色分离。Master 节点不要承担数据存储,避免因数据节点 GC 卡顿而导致假死引发重新选举,整个集群因此抖动。
1.3 分片(Shard)
分片是 ES 水平扩展的核心机制。一个索引的数据会被切分成若干个主分片(Primary Shard),分散到不同节点上存储。每个分片本质上就是一个完整的 Lucene 实例,具有独立的倒排索引。
分片路由公式(默认):
shard_num = hash(document_id) % number_of_primary_shards架构师警告:主分片数在索引创建时设定,之后不能修改(这是 ES 的历史设计局限,8.x 引入了
_split/_shrink API 作为补丁)。所以初始规划必须谨慎,一般按「预期数据量 / 单分片最佳容量(20-40GB)」来估算。
1.4 副本(Replica)
副本分片是主分片的完整拷贝,提供两大价值:
- 高可用:主分片所在节点宕机,副本立刻晋升为新主分片
- 读扩展:搜索请求可以命中副本,分担主分片读压力
副本可以动态调整数量,不影响数据完整性。副本必须分配在与对应主分片不同的节点上(ES 自动保证)。
二、索引、文档、字段:ES 数据模型与 MySQL 表结构对标
理解 ES 数据模型最快的方式是与 MySQL 做类比,但要同时理解它们本质上的区别:
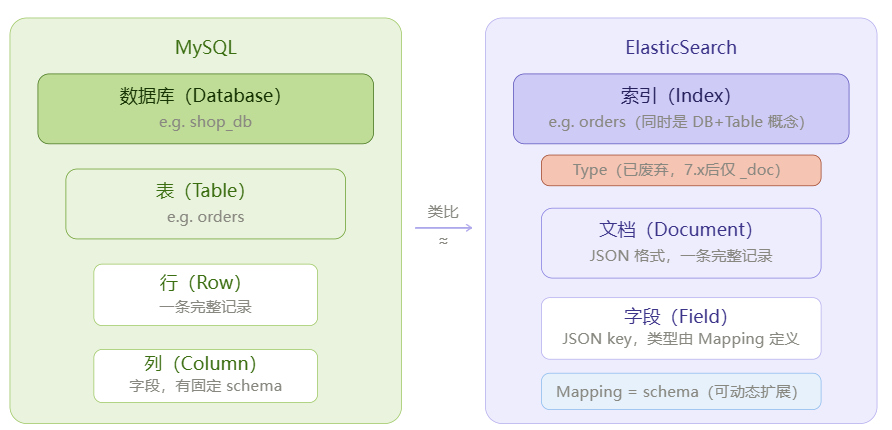
2.1 索引(Index)
ES 中的索引相当于 MySQL 的数据库+表的结合体,命名规范:
- 全小写,可用
-分隔,如user-logs-2024-01 - 命名要体现业务语义 + 时间维度(便于后续按时间管理生命周期)
一个文档示例:
Crystal
PUT /orders/_doc/1001
{
"order_id": "1001",
"user_id": "U888",
"amount": 299.00,
"status": "paid",
"created_at": "2024-01-15T10:30:00Z",
"items": [
{ "sku": "PHONE-X1", "qty": 1 }
]
}2.2 文档(Document)
文档是 ES 中最小的数据单元,以 JSON 格式存储。每个文档包含:
|-------------------------|-------------------------|
| 元字段 | 含义 |
| _index | 所属索引 |
| _id | 文档唯一 ID(可自定义或自动生成 UUID) |
| _source | 原始 JSON 内容 |
| _version | 版本号,用于乐观锁并发控制 |
| _seq_no / _primary_term | 新版乐观锁字段(替代 _version) |
2.3 字段(Field)与 Mapping
Mapping是 ES 的 schema 定义,相当于 MySQL 的 CREATE TABLE。核心区别:
- Dynamic Mapping(默认开启):ES 可以自动推断字段类型,比如字符串 →
text+keyword,数字 →long - Explicit Mapping:生产环境强烈建议手动定义,防止类型推断错误导致性能问题
常见字段类型对比:
|-------------|------------------------|---------------|
| MySQL 类型 | ES 类型 | 说明 |
| VARCHAR | text | 全文搜索,会分词 |
| VARCHAR | keyword | 精确匹配,不分词,可聚合 |
| INT/BIGINT | integer / long | 数值范围查询 |
| DATETIME | date | 时间范围查询,支持多种格式 |
| BOOLEAN | boolean | 布尔值 |
| TEXT / JSON | text / object / nested | 复杂内容 |
架构师踩坑:
text 字段无法用于排序和聚合,要做聚合的字段必须用 keyword。很多人忽略这点,导致运行时报错 Fielddata is disabled on text fields by default。
三、主分片与副本分片的作用、分配规则、容错机制
3.1 分配规则(Allocation Rules)
ES 的分片分配由 Master 节点统一调度,遵循以下核心规则:
规则一:同一分片的主副本不能在同一节点上
Crystal
P0 在 Node1 → R0 只能在 Node2 或 Node3规则二:副本数不能超过「总节点数 - 1」
Crystal
3个节点 → 最多支持 2 个副本(1主 + 2副,每台存一份)规则三:分片分配感知(Shard Allocation Awareness)
生产环境需配置机架感知,防止整个机架断电导致数据丢失:
Crystal
# elasticsearch.yml
cluster.routing.allocation.awareness.attributes: rack_id
node.attr.rack_id: rack1 # 每台机器打标签3.2 容错机制全景
下面这张图演示了节点 1(Master)宕机后,集群的自愈过程:
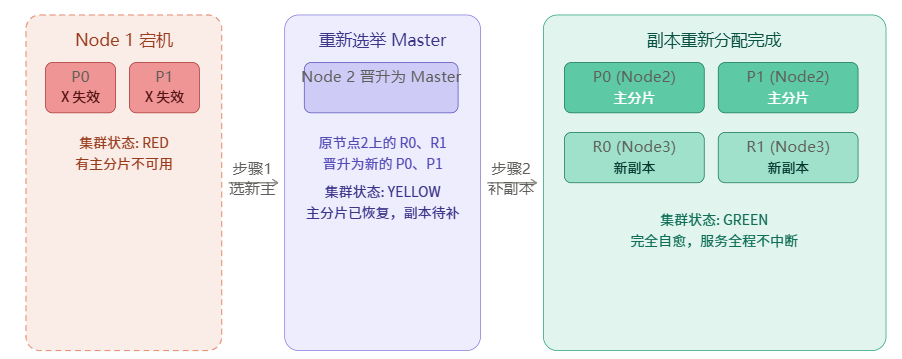
容错三步骤总结:
Step 1 → 集群状态变 RED:Master 检测到 Node 1 心跳超时(默认 discovery.zen.ping_timeout = 30s),将其标记为失联,相关主分片变为 Unassigned。
Step 2 → 重新选举 Master(如果 Node 1 是 Master):剩余 Master-eligible 节点通过 Zen Discovery(或 8.x 的 raft 协议)投票选出新 Master,耗时通常在 1~30 秒。
Step 3 → 副本晋升 + 补充新副本,状态恢复 GREEN:新 Master 将失去主分片对应的副本提升为主分片,同时在其他可用节点上创建新的副本,直至所有副本就位,集群恢复 Green。
关键数字:整个切换过程对外服务不中断,但可能有短暂的写入拒绝(1 主 0 副的极端配置)。生产环境至少 1 个副本,配合
index.unassigned.node_left.delayed_timeout(默认1分钟)可避免因节点短暂重启导致的不必要数据迁移。
四、倒排索引核心原理(搜索引擎底层核心,必懂重点)
这是 ES 能在毫秒级完成全文搜索的根本原因,也是面试和架构评审中最高频的考点。
4.1 正排索引 vs 倒排索引
用最直白的方式理解两者的差异:
正排索引(MySQL B+ 树):
Crystal
文档ID → 文档内容
Doc1 → "ElasticSearch is a search engine"
Doc2 → "search engine based on Lucene"问题:要搜包含"search"的文档,必须逐行扫描------O(n) 全表扫。
倒排索引(Inverted Index):
Crystal
词项(Term)→ 文档ID列表(Posting List)
"elasticsearch" → [Doc1]
"search" → [Doc1, Doc2]
"engine" → [Doc1, Doc2]
"lucene" → [Doc2]搜索"search"时,直接查词典 → 取回 [Doc1, Doc2],O(1) 词典查找 + 极快集合运算。
下面这张图展示了从原始文档到倒排索引的完整构建过程:
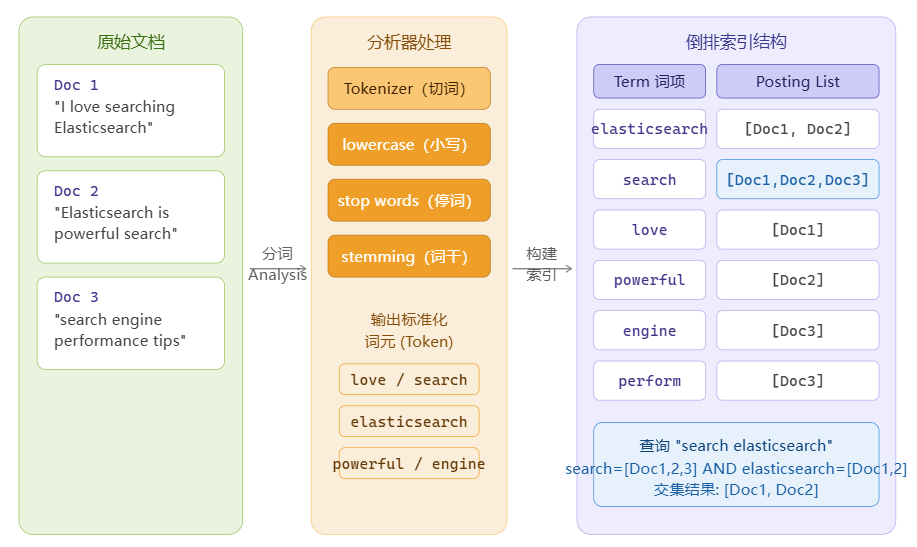
4.2 倒排索引的完整数据结构
一个完整的 Lucene 倒排索引不只是简单的「词 → 文档列表」,它包含:
Crystal
词典(Term Dictionary)
└── "search" → Posting List
├── Doc1: freq=2, positions=[3, 8], offsets=[10-16, 40-46]
├── Doc2: freq=1, positions=[5], offsets=[22-28]
└── Doc3: freq=1, positions=[1], offsets=[0-6]关键组成:
|---------------------|-----------------------------------|---------|
| 结构 | 作用 | 存储在哪 |
| Term Dictionary(词典) | 有序词项列表,支持二分查找 | .tim 文件 |
| Term Index(词典索引) | FST(有限状态转换机)前缀树,加速词典查找 | 内存 |
| Posting List(倒排列表) | 文档 ID 列表(压缩存储,Frame of Reference) | .doc 文件 |
| Frequency(词频) | 该词在每个文档中出现的次数,用于相关性评分 | .doc 文件 |
| Position(位置) | 词项在文档中的位置,用于短语查询 | .pos 文件 |
| Norm(归一化因子) | 文档长度对相关性的惩罚因子 | .nvd 文件 |
4.3 分词器(Analyzer)的三个阶段
Crystal
原始文本
↓
[Character Filters] --- 字符过滤(如去 HTML 标签)
↓
[Tokenizer] --- 核心切词(如标准分词、IK中文分词)
↓
[Token Filters] --- 词项过滤(小写化、去停词、同义词扩展)
↓
标准化 Token 列表 → 写入倒排索引中文场景必用:内置分析器对中文支持极差(逐字切分),生产必须安装
analysis-ik(IK分词器)或 analysis-smartcn,并在 Mapping 中指定 "analyzer": "ik_max_word"。
五、ES 数据读写的基本流程(入门版简化流程)
5.1 写入流程
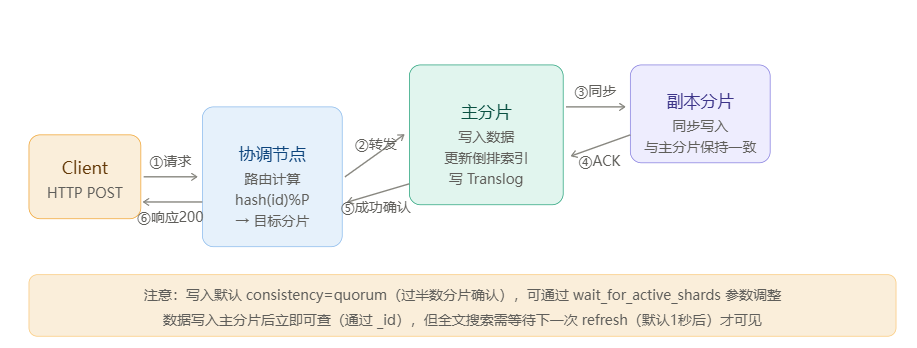
写入六步骤详解:
- 客户端发请求:向集群任意节点发送
PUT/POST请求(该节点自动成为本次请求的协调节点) - 路由计算:协调节点计算
shard_num = hash(_id) % primary_shard_count,确定目标主分片 - 转发到主分片:协调节点将请求转发到主分片所在节点
- 主分片执行写入:更新内存中的 Lucene 索引段,同时写入 Translog(事务日志,用于崩溃恢复)
- 同步到副本:主分片并行将操作转发给所有副本,等待 ACK
- 响应客户端:所有配置的副本确认后,返回成功响应
5.2 读取(查询)流程
Crystal
客户端
↓
协调节点(接收请求)
↓
广播到所有相关分片(主分片 or 副本分片,轮询负载均衡)
↓
各分片本地执行查询,返回 Top N 文档 ID + 分数
↓
协调节点合并所有分片结果,二次排序,取全局 Top N
↓
根据文档 ID 回填 _source 内容(fetch 阶段)
↓
返回最终结果给客户端深入点:查询分两个阶段------Query Phase(轻量,只传 ID 和分数)和 Fetch Phase(重量,传完整文档)。
from + size 的深翻页问题根源就在于每个分片都要返回 from + size 条记录给协调节点做归并,大 from 会导致内存和 CPU 暴涨------这是架构师面试必问点。
六、近实时搜索、刷新、持久化基础机制
这是理解 ES"为什么写完还看不到数据"的关键。
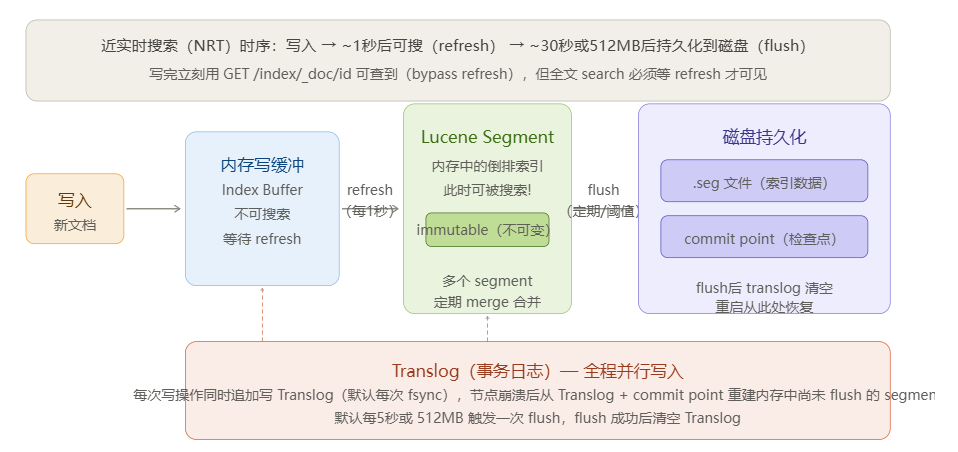
6.1 三个核心概念区分
Refresh(刷新)
- 将内存写缓冲(Index Buffer)中的数据写入一个新的 Lucene Segment(内存,但对搜索可见)
- 默认每 1 秒一次(
index.refresh_interval = 1s) - 这就是"近实时(NRT)"的含义:写入后最多 1 秒内可被搜索到
- 调优:批量写入场景可设为
-1(关闭自动刷新),写完后手动POST /index/_refresh
Flush(冲刷)
- 将内存中的 Segment 真正写入磁盘(fsync),并更新 commit point
- 同时清空对应的 Translog
- 默认每 30 分钟或 Translog 超过 512MB 时触发
- Flush 之后数据才真正安全持久化,重启后无需从 Translog 回放
Translog(事务日志)
- 每次写操作都同步追加到 Translog(默认每次请求 fsync,可调为异步)
- 作用:崩溃恢复。节点重启后,从最后一次 commit point 的检查点开始,重放 Translog 中未 flush 的操作,重建内存 Segment
6.2 关键参数与性能调优
|-------------------------------------|---------|-------------------------------|
| 参数 | 默认值 | 说明 |
| index.refresh_interval | 1s | 改为 -1 可在批量写入时极大提升性能 |
| index.translog.durability | request | 改为 async 可提升写入 TPS,但有微量数据丢失风险 |
| index.translog.sync_interval | 5s | async 模式下的 fsync 间隔 |
| index.translog.flush_threshold_size | 512mb | Translog 大小触发 flush 的阈值 |
| indices.memory.index_buffer_size | 10% 堆 | 写缓冲占 JVM 堆的比例 |
6.3 Segment Merge(段合并)
refresh 每秒产生一个新 Segment,长期积累会导致搜索性能下降(需扫描更多 Segment)。ES 后台持续执行 Merge 操作,将多个小 Segment 合并为一个大 Segment,同时物理删除被标记为删除的文档(ES 的删除是标记删除,Merge 时才真正释放空间)。
优化提示:对于只追加不修改的时序数据(如日志),可以对历史索引执行
POST /index/_forcemerge?max_num_segments=1,将每个分片合并为单一 Segment,大幅提升查询性能,同时释放磁盘空间。
本章重点总结
|------------------|---------------------------------|------------------------------------|
| 知识点 | 一句话总结 | 面试/架构要点 |
| 集群 | 多节点统一对外服务 | 集群名不能用默认值,Green/Yellow/Red 三态 |
| 节点角色 | Master/Data/Ingest/Coordinating | 生产环境必须角色分离,Master 不存数据 |
| 分片 | 数据水平切分的基本单元 | 主分片数创建后不可改,规划要按数据量估算 |
| 副本 | 主分片的完整备份 | 可动态调整,必须在不同节点,提供读扩展和高可用 |
| 索引/文档/字段 | 对标 MySQL 库表行列 | Mapping 要提前定义,text vs keyword 必须区分 |
| 倒排索引 | 词 → 文档 ID 列表的高效查找结构 | 分词器的选择影响搜索质量,中文必须用 IK |
| 写入流程 | 协调→主分片→副本→响应 | 深翻页问题、quorum 一致性要理解 |
| NRT / refresh | 写后 1 秒内可搜索 | refresh_interval=-1 是批量写优化必备 |
| flush + translog | 持久化保证 + 崩溃恢复 | translog 不清空会撑爆磁盘,flush 成功才真正安全 |