声明
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、项目环境
本次实验使用的是我电脑上的 PyTorch 环境:
text
Python:3.10
PyTorch:2.9.1+cu130
训练设备:cuda
数据集:heart.csv
任务类型:二分类任务二、我对 RNN 的初步理解
RNN,全称是 Recurrent Neural Network,也就是循环神经网络。它和普通全连接神经网络最大的区别是:RNN 可以处理具有顺序关系的数据。
普通神经网络一般认为每次输入都是相互独立的,而 RNN 会保留一个隐藏状态,用来记录前面时间步的信息。因此它常用于文本、语音、时间序列等任务。
RNN 的核心思想可以简单理解成:
text
当前输出 = 当前输入 + 之前记住的信息在 PyTorch 中使用 RNN 时,输入数据通常是三维的:
text
(batch_size, sequence_length, input_size)对应含义如下:
text
batch_size:一次送入模型的样本数量
sequence_length:序列长度,也可以理解为时间步数量
input_size:每一个时间步输入的特征数量本项目的数据集是表格数据,一共有 13 个特征。为了让数据符合 RNN 的输入格式,我将原来的二维数据:
text
(样本数, 13)扩展为:
text
(样本数, 1, 13)也就是说,在这个入门项目里,我把每一条样本看作一个长度为 1 的序列,每个时间步有 13 个特征。
需要注意的是:这个项目并不是典型的时间序列预测任务,因为数据本身没有真正的时间顺序。这里使用 RNN 的主要目的,是为了学习 RNN 在 PyTorch 中的输入格式、模型定义方式以及训练流程。
三、数据集介绍
本次使用的数据集是心脏病预测数据集,文件名为 heart.csv。数据集共有 303 条样本,每条样本包含 13 个特征和 1 个标签。
部分字段含义如下:
text
age:年龄
sex:性别
cp:胸痛类型
trestbps:静息血压
chol:血清胆固醇
fbs:空腹血糖
restecg:静息心电图结果
thalach:最大心率
exang:运动诱发心绞痛
oldpeak:ST段下降值
slope:ST段斜率
ca:主要血管数量
thal:地中海贫血类型
target:是否可能患心脏病其中 target 是预测目标:
text
0:不会患心脏病
1:可能患心脏病数据集标签分布如下:
text
0:138 条
1:165 条可以看到,两个类别数量比较接近,整体上没有特别严重的类别不平衡问题。
四、数据预处理
首先导入需要的库,并设置训练设备。如果电脑支持 GPU,就使用 cuda,否则使用 cpu。
python
import numpy as np
import pandas as pd
import torch
from torch import nn
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device读取数据:
python
df = pd.read_csv("heart.csv")
df.head()划分特征和标签:
python
X = df.iloc[:, :-1]
y = df.iloc[:, -1]由于不同特征的量纲不同,比如年龄、胆固醇、血压等数值范围差别较大,所以需要对特征进行标准化处理。
python
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X = sc.fit_transform(X)然后将数据转换为 PyTorch 张量:
python
X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.int64)划分训练集和测试集,测试集比例设置为 0.1:
python
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.1,
random_state=1
)由于 RNN 需要三维输入,因此这里使用 unsqueeze(1) 增加一个序列维度:
python
X_train = X_train.unsqueeze(1)
X_test = X_test.unsqueeze(1)最终数据形状如下:
text
X_train.shape: (272, 1, 13)
y_train.shape: (272,)
X_test.shape: (31, 1, 13)
y_test.shape: (31,)五、构建数据加载器
训练时使用 TensorDataset 和 DataLoader 封装数据。
python
from torch.utils.data import TensorDataset, DataLoader
train_dl = DataLoader(
TensorDataset(X_train, y_train),
batch_size=64,
shuffle=False
)
test_dl = DataLoader(
TensorDataset(X_test, y_test),
batch_size=64,
shuffle=False
)这里的 batch_size 设置为 64。由于数据集比较小,所以训练速度很快。
六、构建 RNN 模型
模型结构如下:
python
class model_rnn(nn.Module):
def __init__(self):
super(model_rnn, self).__init__()
self.rnn0 = nn.RNN(
input_size=13,
hidden_size=200,
num_layers=1,
batch_first=True
)
self.fc0 = nn.Linear(200, 50)
self.fc1 = nn.Linear(50, 2)
def forward(self, x):
out, _ = self.rnn0(x)
out = out[:, -1, :]
out = self.fc0(out)
out = self.fc1(out)
return out这个模型主要分为三部分:
text
第一部分:RNN 层
第二部分:全连接层 fc0
第三部分:输出层 fc1其中:
text
input_size=13:每个时间步输入 13 个特征
hidden_size=200:RNN 隐藏层维度为 200
num_layers=1:使用 1 层 RNN
batch_first=True:输入格式为 batch 在前,即 (batch, seq, feature)RNN 层输出后,我只取最后一个时间步的输出:
python
out = out[:, -1, :]因为本项目中每条样本的序列长度是 1,所以这里取最后一个时间步其实就是取该样本经过 RNN 后的输出表示。
最后经过两层全连接层,输出 2 个值,对应两个类别:
text
0:不会患心脏病
1:可能患心脏病七、模型训练
本项目使用交叉熵损失函数,优化器使用 Adam。
python
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-4
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
epochs = 50训练函数的核心流程为:
text
1. 将数据送入模型
2. 计算预测结果
3. 计算损失函数
4. 梯度清零
5. 反向传播
6. 更新参数
7. 统计准确率和损失训练代码如下:
python
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss测试函数与训练函数类似,但测试阶段不需要更新梯度,所以使用 torch.no_grad():
python
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss八、实验结果
本次实验训练 50 轮,训练设备为 cuda。
部分训练输出如下:
text
Epoch: 1, Train_acc:44.9%, Train_loss:0.705, Test_acc:51.6%, Test_loss:0.674
Epoch:10, Train_acc:73.9%, Train_loss:0.600, Test_acc:87.1%, Test_loss:0.533
Epoch:16, Train_acc:82.0%, Train_loss:0.527, Test_acc:90.3%, Test_loss:0.440
Epoch:50, Train_acc:84.6%, Train_loss:0.354, Test_acc:87.1%, Test_loss:0.292最终实验结果如下:
text
最佳轮数:第 16 轮
最佳测试集准确率:90.32%
最终加载最佳模型后的准确率:90.32%训练曲线如下:
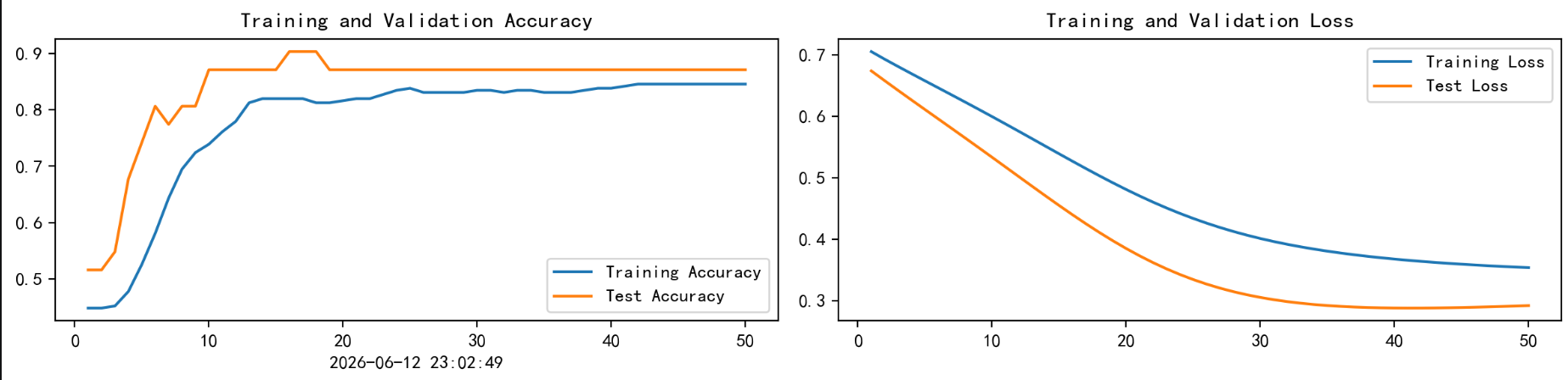
从曲线可以看到,随着训练轮数增加,训练集准确率逐渐上升,训练损失逐渐下降。测试集准确率在前期提升较快,在第 16 轮附近达到最高值,之后基本稳定在 87% 左右。
这说明模型已经学到了一定的分类能力,但由于数据集比较小,测试集只有 31 条样本,因此测试准确率会受到数据划分影响。
九、混淆矩阵分析
模型在测试集上的混淆矩阵如下:
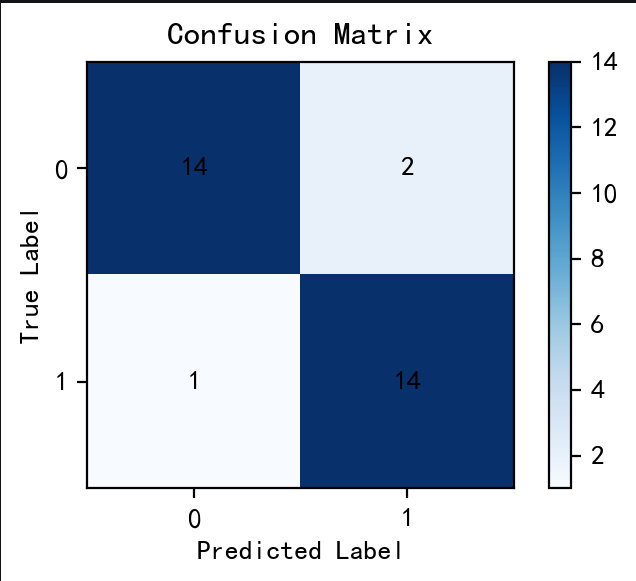
混淆矩阵结果为:
text
[[14, 2],
[ 1, 14]]对应含义如下:
text
真实为 0,预测为 0:14 条
真实为 0,预测为 1:2 条
真实为 1,预测为 0:1 条
真实为 1,预测为 1:14 条也就是说,在 31 条测试样本中,模型预测正确了 28 条,预测错误了 3 条。
分类报告如下:
text
precision recall f1-score support
0 0.9333 0.8750 0.9032 16
1 0.8750 0.9333 0.9032 15
accuracy 0.9032 31
macro avg 0.9042 0.9042 0.9032 31
weighted avg 0.9051 0.9032 0.9032 31从结果来看,模型对两个类别的识别效果比较接近:
text
类别 0 的 precision 更高,说明预测为 0 时比较可靠;
类别 1 的 recall 更高,说明真实为 1 的样本大多数被模型识别出来了。十、调用模型进行预测
训练完成后,可以取测试集中的一条数据进行预测:
python
test_X = X_test[0].unsqueeze(1)
pred = model(test_X.to(device)).argmax(1).item()
print("模型预测结果为:", pred)
print("0:不会患心脏病")
print("1:可能患心脏病")这里需要注意,输入模型的数据仍然要保持 RNN 需要的三维格式。
十一、本次项目中遇到的问题
1. RNN 输入维度问题
刚开始学习 RNN 时,我最容易混淆的就是输入维度。普通表格数据一般是二维:
text
(batch_size, feature_size)但是 RNN 需要三维:
text
(batch_size, sequence_length, input_size)所以本项目中使用:
python
X_train = X_train.unsqueeze(1)
X_test = X_test.unsqueeze(1)把数据从 (272, 13) 变成 (272, 1, 13)。
2. RNN 输出如何接全连接层
RNN 的输出 out 是三维的:
text
(batch_size, sequence_length, hidden_size)如果要做分类,一般会取最后一个时间步的输出:
python
out = out[:, -1, :]这样得到的形状就是:
text
(batch_size, hidden_size)然后就可以接全连接层进行分类。
3. 表格数据用 RNN 的意义
这次项目的数据并不是严格意义上的序列数据,所以 RNN 在这里并不是最适合的模型。如果单纯追求心脏病预测准确率,逻辑回归、随机森林、XGBoost 或者普通 MLP 可能更合适。
但是对于我学习 RNN 来说,这个项目非常适合作为第一步。因为它的数据量小、训练速度快、流程清晰,可以帮助我先把 RNN 的输入格式、模型结构、训练方式跑通。
十二、总结
通过这个项目,我对 RNN 有了更具体的理解。
以前我只是知道 RNN 可以处理序列数据,但不太清楚在代码里应该怎么写。通过这次实验,我真正理解了 RNN 输入数据的三维结构:
text
(batch_size, sequence_length, input_size)也理解了 nn.RNN 输出之后,为什么通常要取最后一个时间步的输出再接全连接层。
本次实验完成了以下内容:
text
1. 读取 heart.csv 数据集
2. 对特征进行标准化
3. 划分训练集和测试集
4. 构建 TensorDataset 和 DataLoader
5. 搭建 RNN 二分类模型
6. 使用 CrossEntropyLoss 和 Adam 训练模型
7. 绘制训练曲线
8. 输出混淆矩阵和分类报告
9. 保存模型和实验结果最终模型在测试集上取得了 90.32% 的准确率,混淆矩阵结果为:
text
[[14, 2],
[ 1, 14]]作为我的第一个 RNN 项目,这次实验让我从"知道 RNN 是什么"走到了"能用 PyTorch 把 RNN 跑起来"。后面如果继续学习,我希望可以用真正的序列数据来做实验,比如文本分类、股票时间序列预测或者传感器行为识别,这样能更好地体会 RNN 在序列建模中的作用。