2026年第十六届APMCM 亚太地区大学生数学建模竞赛(中文赛项)赛题A题:自来水厂水质预测与评估完整思路、代码、模型、文章,全网首发高质量分享!
PROBLEM STATEMENT
赛题全文
2026 年第十六届APMCM 亚太地区大学生数学建模竞赛
A题自来水厂水质预测与评估
优质自来水是城市和工业的"血液",稳定优质的供水是城市吸引高端制造
业、研发中心、国际企业和高素质人才落户的关键基础设施指标之一。自来水厂
生产高质量的供水是实现这一目标的最公平、最高效的方式。国家在"十五五"
规划期间,提出确保城乡每个人都能获得基础、可靠的安全水源。自来水厂的生
产过程包括取水、混凝、沉淀、过滤、消毒等多个环节。当前自来水厂生产面临
两大挑战:原水水质波动(如雨季浊度剧增、pH 变化)可能导致后续工艺处理效
果下降,甚至影响出厂水质达标;工艺控制滞后(如矾投加量调整后,滤后水浊
度需要数小时才能稳定),缺乏精准的预测与评估决策支持。
水厂水质预测与评估研究是保障饮用水安全、实现工艺智能调控的核心支撑。
传统的经验方法已难以适配水源复杂污染、多工艺耦合、实时优化运行的需求。
研究方法已从静态的实测与试验,迭代为机理动力学模型、数据驱动的机器学习
方法、机理数据混合耦合模型为主流方法。结合数值模型的机理解析、动态预测、
工况仿真、参数优化等多技术交叉融合方法逐渐成为主要研究工具。
现有一家自来水厂连续15 个月的运行监测数据(见附件1,附件2),每天
记录12 次(即每2 小时一次),包含原水水质、工艺过程参数、出厂水质及部分
设备运行状态。这些数据具有高时间分辨率、多变量耦合、非线性、时滞性等特
点,能够反映水厂在不同原水水质、气候条件、运行策略下的动态响应。请你们
队通过建立数学模型,解决以下4 个问题:
问题1 采用合适的定量分析方法,筛选影响自来水浊度(NTU)的主要因素,
解释各因素的影响程度与作用方向,并建立主要影响因素之间的函数关系,预测
附件2 中2026 年2 月1 日,2 月10 日,2 月20 日的水浊度NTU,检验模型效果
(最好能验证不同模型预测结果,以excel 表格形式给出答案)。
问题2 滤后水浊度(FILT. NTU)是衡量混凝沉淀过滤效果的核心指标,主
要受原水浊度(R/W NTU)、原水pH(R/W PH)、矾投加量(ALUM,F/RIDE)、原水
-1-
流量(R/W FLOW)等因素影响,且存在明显的时间滞后。请你们队建立一个动态
数学模型,描述原水指标(R/W NTU、R/W pH)和操作变量(ALUM、R/W FLOW)
如何影响滤后水浊度(FILT. NTU),并给出输入变量的时滞参数(可允许不同变
量不同时滞)。对模型进行参数估计与验证,并提供模型在自选数据上的拟合精
度(如RMSE、R²)。
问题3 出厂水质(主要是水浊度NTU)的达标是水厂的核心目标。但由于从
原水到出厂水要经过多个工艺环节,直接预测未来(如6 小时、12 小时后)的出
厂水质非常困难。请你们队结合质量守恒原理(如清水池的水力停留时间分布)
与数据驱动方法(如LSTM、GRU 或状态空间模型),建立一种混合动态模型,预
测未来1~12 小时的出厂水浊度NTU,并利用模型给出2026 年2 月1 日,2 月10
日,2 月20 日7 点至19 点的NTU 预测结果(以excel 表格形式给出答案)。分
析不同输入变量(特别是原水水质突变、矾投加调整)对预测结果的敏感性。
问题4 以水浊度NTU 为核心指标,结合超标幅度与异常持续时长,建立水
质风险评价体系,将2026 年近3 个月水质划分为:安全、低风险、中风险、高
风险四个等级,给出各等级天数占比并给出3 月份的具体分类结果(以excel 表
格列出)。(注:国标硬性条件固定约束:生活饮用水浊度限值≤1 NTU,作为评
判超标、风险的统一标准。)
-2-
附录:
1数据说明: 自来水厂水质检测指标中各项简写的英文和中文全称(按出现顺序排列): 简写英文全称中文全称 RIVER LEVEL River Water Level 河水水位 R/W PUMP DUTY Raw Water Pump Duty 原水泵运行状态/工作频率 R/W FLOW Raw Water Flow Rate 原水流量 R/W NTU Raw Water Turbidity (NTU) 原水浊度(NTU 单位) R/W CLR Raw Water Color 原水色度 R/W PH Raw Water pH 原水pH 值 FILT. NTU Filtered Water Turbidity (NTU) 滤后水浊度 C/W WELL LEVEL Clear Well Water Level 清水池水位 PH (第二处) pH value of clear/treated water 清水/处理后水pH 值 NTU (第二处) Turbidity of clear/treated water (NTU) 清水/处理后水浊度 CLR (第二处) Color of clear/treated water 清水/处理后水色度 CL2 Chlorine Residual 余氯 F/RIDE Flow Rate of Alum (or Chemical Feed) 矾/混凝剂投加流量 ALUM Alum (Chemical Coagulant) Dosage 明矾/混凝剂投加量 -3- T/W PUMP DUTY Treated Water Pump Duty 送水泵运行状态/工作频率 T/W FLOW Treated Water Flow Rate 送水流量/出厂水流量 18ML LEVEL 18 Million Liters Tank Water Level 1800 万升(18 兆升)水池水位 18ML FLOW 18 Million Liters Tank Flow Rate 1800 万升水池进出水流量 REMARKS Remarks 备注
2单位说明: 符号说明 NTU 为浊度单位(Nephelometric Turbidity Unit) R/W 通常指Raw Water(原水/未处理水) C/W 通常指Clear Well / Treated Water(清水池/处理后水) 18ML 指18 million liters(1800 万升,即18 兆升)的调节水池或储水设施 F/RIDE 为现场常见简写,指混凝剂(矾液)的投加速率/流量
3附件1,附件2 数据说明: (1)时间范围:连续15 个月,每天12 个时间点(如0:00, 2:00, ..., 22:00)。监测指标(共20 个左右): (2)原水:水位(RIVER LEVEL)、原水泵频率(R/W PUMP DUTY)、原水流量(R/W FLOW)、浊度(R/W NTU)、色度(R/W CLR)、pH(R/W PH) (3)过程:滤后水浊度(FILT. NTU)、矾投加量/流量(ALUM、F/RIDE) (4)清水池:清水池水位(C/W WELL LEVEL)、pH、浊度、色度、余氯(CL2) -4- (5)出厂水:送水泵频率(T/W PUMP DUTY)、出厂水流量(T/W FLOW) (6)储水设施:18ML 水池水位与流量(18ML LEVEL、18ML FLOW) (7)备注(REMARKS):可能包含异常事件或人工操作记录(可用作标签)
4附件1,附件2 数据特点: (1)多变量时间序列,存在缺失值、噪声、异常点。 (2)变量间存在非线性关系与不同时间滞后(如矾投加影响滤后水浊度的滞后约2---6 小时)。 (3)部分变量为控制变量(泵频率、矾投加量),部分为状态变量(水位、 水质)。 (4)可能存在周期性(日/周/月)与季节性(雨季/旱季)变化。 -5-
问题1 采用合适的定量分析方法,筛选影响自来水浊度(NTU)的主要因素,
原赛题要求
问题1 采用合适的定量分析方法,筛选影响自来水浊度(NTU)的主要因素,
解释各因素的影响程度与作用方向,并建立主要影响因素之间的函数关系,预测
附件2 中2026 年2 月1 日,2 月10 日,2 月20 日的水浊度NTU,检验模型效果
(最好能验证不同模型预测结果,以excel 表格形式给出答案)。
问题一完整解答:自来水浊度主要影响因素筛选与指定日期预测
5.1 附件1和附件2
问题一以附件1和附件2的连续运行监测记录为输入对象,核心任务是在统一时间轴上识别影响出厂水浊度NTU的主要因素,并为指定日期预测提供可复核的数据基础。本文首先合并DATE与TIME字段,将原始记录整理为严格递增的2小时频率时间索引,记按时间排序后的采样点为t;目标变量设为出厂水NTU,即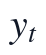 ,候选影响因素记为
,候选影响因素记为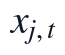 ,包括RIVER LEVEL、R/W FLOW、R/W NTU、R/W CLR、R/W PH、FILT. NTU、C/W WELL LEVEL、PH、CLR、CL2、ALUM、T/W FLOW等水质与运行变量。该处理使附件1的历史运行信息与附件2的后续监测信息处于同一时间尺度,避免不同月份、不同字段口径对模型输入造成结构性差异。
,包括RIVER LEVEL、R/W FLOW、R/W NTU、R/W CLR、R/W PH、FILT. NTU、C/W WELL LEVEL、PH、CLR、CL2、ALUM、T/W FLOW等水质与运行变量。该处理使附件1的历史运行信息与附件2的后续监测信息处于同一时间尺度,避免不同月份、不同字段口径对模型输入造成结构性差异。
变量与约束的设置围绕"只使用预测时点之前可获得信息"展开。出厂水NTU作为监督学习目标,原水浊度、滤后水浊度、加矾量、余氯、流量和液位等变量作为候选解释变量;同时构造1阶、2阶滞后项以及日周期、年周期项,用于刻画水厂水力过程中的短期响应和周期变化。建模样本可表示为:
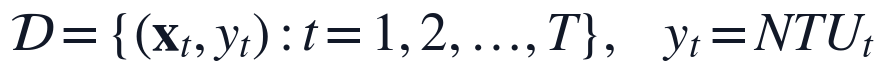
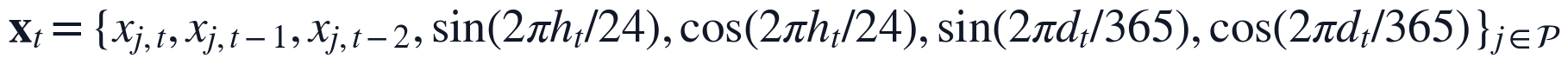
其中,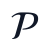 为附件字段和派生特征形成的原始候选变量集合,
为附件字段和派生特征形成的原始候选变量集合,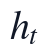 和
和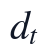 分别表示采样时刻在日内和年内的位置。上述定义将当前工况、短期滞后响应和周期性变化同时纳入同一特征向量,为后续MARS分段样条模型识别阈值效应和局部斜率变化提供输入基础。
分别表示采样时刻在日内和年内的位置。上述定义将当前工况、短期滞后响应和周期性变化同时纳入同一特征向量,为后续MARS分段样条模型识别阈值效应和局部斜率变化提供输入基础。
实现步骤上,本文不直接将原始表格送入模型,而是先完成时间索引核对、字段统一、缺失处理、异常标记和量纲标准化。缺失值优先依据季节---时段分组中位数补齐,连续小缺口采用局部线性插补;异常监测值保留在原时间位置,通过样本权重降低其对模型拟合的影响。这样处理的目的不是改变水厂运行过程本身,而是在保持2小时序列结构完整的前提下,减少缺测和突变记录对主要因素筛选的干扰。
在方法选择上,问题一同时要求筛选主要因素、解释影响程度与作用方向、建立函数关系并预测指定日期NTU。全局线性模型难以描述原水浊度、滤后水浊度、加矾量和余氯等变量在不同运行区间下的非线性边际作用,因此本文采用MARS自适应分段样条作为主模型;在进入MARS前,先用互信息和Spearman秩相关进行弱筛,并对强相关候选变量进行压缩,以减少冗余变量对解释排序的影响。MARS模型进一步通过GCV剪枝控制基函数数量,交互阶数限制在二阶以内,使模型既能表达局部分段关系,又保持函数形式可解释。
与题目要求对应,本节的数据组织和变量定义直接服务于问题一的四类输出:主要影响因素来自候选变量集合及其滞后、周期派生项;影响程度和作用方向由后续分段样条贡献、条件置换重要性和局部斜率解释给出;主要影响因素之间的函数关系由剪枝后的MARS基函数表达;2026年2月1日、2月10日、2月20日的出厂水NTU预测则在相同2小时频率时间轴上生成。附件1和附件2经上述统一处理后,形成了从数据读取、变量构造到模型输入的一致口径,为后续结果表和指定日期预测提供基础。
5.2 构造候选特征:原始运行变量、1阶和2
本文在问题一中采用"构造候选特征:原始运行变量、1阶和2阶滞后变量、日周期正余弦项、年周期正余弦项"的特征组织方式,将附件1和附件2中的2小时频率监测记录整理为监督学习样本。设按日期和时间排序后的采样序号为 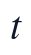 ,出厂水浊度为目标变量 ,候选影响因素 来自 RIVER LEVEL、R/W FLOW、R/W NTU、R/W CLR、R/W PH、FILT. NTU、C/W WELL LEVEL、PH、CLR、CL2、ALUM、T/W FLOW 等字段。原始运行变量反映当前工况,1阶和2阶滞后变量刻画水厂水力输移与混凝、过滤过程的短期响应,周期项则用于表达日内运行节律和季节变化对浊度的背景影响。
,出厂水浊度为目标变量 ,候选影响因素 来自 RIVER LEVEL、R/W FLOW、R/W NTU、R/W CLR、R/W PH、FILT. NTU、C/W WELL LEVEL、PH、CLR、CL2、ALUM、T/W FLOW 等字段。原始运行变量反映当前工况,1阶和2阶滞后变量刻画水厂水力输移与混凝、过滤过程的短期响应,周期项则用于表达日内运行节律和季节变化对浊度的背景影响。
将出厂水NTU作为监督学习目标后,样本集合定义为:
候选特征向量写为:
其中, 为原始候选变量集合, 表示采样点在一天中的小时位置, 表示采样点在一年中的日期位置。该构造将当前状态、短期滞后响应和周期背景统一纳入同一输入空间,使后续MARS分段样条能够在同一框架下识别原水浊度、滤后水浊度、余氯、加矾量和流量等变量的局部阈值效应。
在变量与约束层面,本文首先保持附件数据的2小时等间隔结构,避免随机打乱样本导致时序依赖被破坏。指定日期预测时,特征构造和模型训练均只能调用预测时点之前已出现的数据,因此训练窗口定义为:
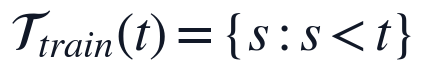
时间频率约束为:
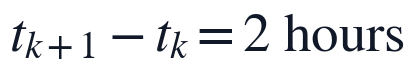
上述约束直接控制2026年2月1日、2月10日和2月20日的预测过程:对任一预测采样点,滞后项只能由该点之前的观测生成,日周期和年周期项仅由时间索引确定,不包含未来水质信息。这样既保留题面给出的连续多变量时间序列结构,又避免使用预测时点之后的数据造成信息泄漏。
由于原始监测序列可能存在缺失记录,特征构造前需要将缺失值转化为可进入模型的 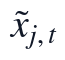 。本文按季节和时段分组计算中位数,并在连续小缺口且端点可用时采用局部线性插补,其分组中位数为:
。本文按季节和时段分组计算中位数,并在连续小缺口且端点可用时采用局部线性插补,其分组中位数为:
bar{x}{j,g}=median{x{j,s}:g(s)=g, x_{j,s} mathrm{非缺失}\}
预处理后的变量定义为:
tilde{x}{j,t}=begin{cases}bar{x}{j,g(t)},&x_{j,t} mathrm{缺失且不可局部插补} x_{j,a}+dfrac{t-a}{b-a}(x_{j,b}-x_{j,a}),&a<t<b mathrm{且端点可用}\\ x_{j,t},&x_{j,t} mathrm{非缺失}end{cases}
其中,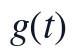 表示采样点所属的季节-时段组合,
表示采样点所属的季节-时段组合,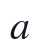 与
与 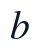 为缺失区间两端的可用观测点。该步骤的实现顺序为先合并DATE与TIME,再生成统一时间索引,随后对每个候选变量逐列补齐,最后再派生滞后项和周期项,从而保证派生特征建立在完整且顺序一致的时间序列上。
为缺失区间两端的可用观测点。该步骤的实现顺序为先合并DATE与TIME,再生成统一时间索引,随后对每个候选变量逐列补齐,最后再派生滞后项和周期项,从而保证派生特征建立在完整且顺序一致的时间序列上。
为降低异常监测值对后续分段函数拟合的干扰,本文不直接删除异常点,而是在候选特征生成后使用Hampel准则形成稳健样本权重。对变量 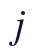 在滑动窗口
在滑动窗口 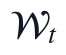 内计算局部中位数和绝对中位差:
内计算局部中位数和绝对中位差:

样本权重进一步写为:
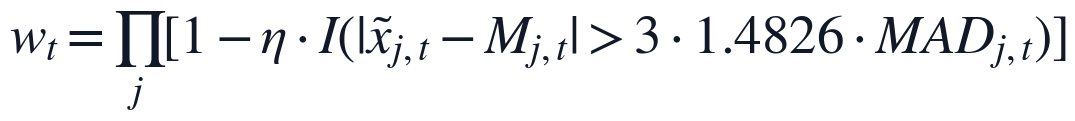
其中,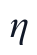 为异常降权比例,
为异常降权比例,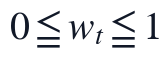 。权重进入后续MARS拟合目标,而不是改变原始时间位置,因此异常时刻仍保留其可能包含的工况信息,但其对参数估计的影响被适度削弱。
。权重进入后续MARS拟合目标,而不是改变原始时间位置,因此异常时刻仍保留其可能包含的工况信息,但其对参数估计的影响被适度削弱。
实现步骤上,本文依次完成数据读取、时间索引统一、缺失补齐、异常降权、原始变量保留、1阶和2阶滞后变量生成、日周期与年周期正余弦项生成,并在进入MARS前对候选变量进行标准化处理。与题目要求对应,该特征集既服务于主要影响因素筛选,也为后续解释影响程度、作用方向和主要因素之间的函数关系提供统一输入;同时,指定日期预测所需的特征完全由预测时点之前的数据和确定性时间项生成,因而能够直接支撑2026年2月1日、2月10日和2月20日各2小时采样点的出厂水NTU预测。
5.3 每个候选变量执行季节-时段分组中位数
本小节针对附件1与附件2合并后的2小时频率监测序列,在进入互信息筛选和MARS分段样条建模之前,先对每个候选变量执行季节-时段分组中位数补缺、局部线性插补和异常降权处理。设 t 为按日期和时刻排序后的采样序号,y_t 为出厂水浊度NTU,x_{j,t} 为第 j 个候选变量,包括 RIVER LEVEL、R/W FLOW、R/W NTU、R/W CLR、R/W PH、FILT. NTU、C/W WELL LEVEL、PH、CLR、CL2、ALUM、T/W FLOW 等水质与运行字段。该步骤的建模切入点不是直接预测 y_t,而是先把不规则缺口、局部噪声和异常冲击转化为可进入后续模型的统一特征矩阵。
为保证变量与约束清晰,本文先将原始观测写成按时间排列的监督学习样本,并保留当前值、短期滞后项和周期项。其基本样本结构为:
其中,为原始候选变量集合,h_t 表示日内小时,d_t 表示年内日期序号。上述定义使后续模型同时接收当前工况、短期水力滞后和周期性信息;同时,所有特征必须服从2小时等间隔约束,并按时间顺序构造,避免在指定日期预测时引入后验信息。
缺失值处理采用"季节-时段分组中位数优先刻画常规水平、局部线性插补保留短缺口趋势"的组合规则。记 g(t) 为时刻 t 所属的季节和日内时段分组,则第 j 个变量在该分组下的参考中位数定义为:
bar{x}{j,g}=median{x{j,s}:g(s)=g, x_{j,s} mathrm{非缺失}\}
据此,预处理后的变量值按缺口类型分配为:
tilde{x}{j,t}=begin{cases}bar{x}{j,g(t)},&x_{j,t} mathrm{缺失且不可局部插补} x_{j,a}+dfrac{t-a}{b-a}(x_{j,b}-x_{j,a}),&a<t<b mathrm{且端点可用}\\ x_{j,t},&x_{j,t} mathrm{非缺失}end{cases}
该约束将缺失值限定在分组中位数、局部线性插补值和原始观测值三类来源内。分组中位数削弱了极端观测对补缺值的影响,局部线性插补则用于连续小缺口两端均可用的情形,使序列在短时间范围内保持平滑过渡。
异常点处理不采用删除方式,而是通过 Hampel 滤波标记局部偏离程度,并生成样本权重 w_t。对每个候选变量,在滑动窗口内计算局部中位数和绝对中位差:
当某一时刻多个变量同时出现局部异常时,其样本权重按变量维度累乘降权:
其中,为异常降权比例,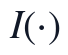 为示性函数,且权重满足。这样处理后,异常运行点仍保留在时间序列中,但其对后续MARS拟合目标的影响被降低,有利于兼顾数据完整性和参数估计的稳定程度。
为示性函数,且权重满足。这样处理后,异常运行点仍保留在时间序列中,但其对后续MARS拟合目标的影响被降低,有利于兼顾数据完整性和参数估计的稳定程度。
实现步骤上,本文首先合并 DATE 与 TIME 字段,生成严格递增的2小时索引;其次逐列遍历中的候选变量,按季节和日内时段计算分组中位数,并对可由相邻端点支撑的短缺口执行局部线性插补;随后在每个变量上进行 Hampel 标记,并把各变量异常标记汇总为 w_t;最后输出、滞后项、周期项和样本权重,供后续互信息、Spearman秩相关、共线压缩和MARS剪枝使用。在与题目要求对应的关系上,本步骤为"筛选影响自来水浊度NTU的主要因素"和"预测指定日期水浊度NTU"提供统一、可复核的输入矩阵,并通过时间顺序约束保证2026年2月1日、2月10日、2月20日的预测只依赖预测时点之前可获得的数据。
5.4 核心结果、预测表格与因素解释
MARS主模型筛选出的首要影响因素集中在滤后水浊度与原水浊度的短时滞后项,其中排序靠前的关键指标为FILT. NTU_滞后1、R/W NTU_滞后2、R/W NTU_滞后1、R/W NTU、RIVER LEVEL_滚动均值6h和CLR_滚动均值6h。模型滚动验证RMSE为0.011230,MAE为0.008900,R2为0.767029;BART对照模型RMSE为0.011227,MAE为0.008959,R2为0.767135,两类非线性模型在同一时间窗口下误差水平接近。指定日期预测中,2026年2月1日出厂水NTU预测均值为0.263746、最大值为0.287423,明显高于2026年2月10日的均值0.186530、最大值0.206432,以及2026年2月20日的均值0.186259、最大值0.209646。因此,三个指定日期均处于较低浊度水平,但2月1日相对更接近高关注层,2月10日与2月20日则表现为低波动、低浊度状态。
表格缺失:Q1/required_submission_outputs/2026年指定日期NTU预测结果.xlsx
结果表格中的关键输出由三部分构成:一是逐2小时采样点的pred_NTU预测值,二是与每条预测共同给出的validation_rmse,三是selected_main_factors字段记录的主要影响因素集合。该表格将题目要求的2026年2月1日、2月10日、2月20日水浊度NTU预测结果与模型效果检验指标放在同一口径下,避免只给日期均值而丢失日内变化信息。从误差指标看,MARS与BART的RMSE差异仅约0.000003,说明指定日期预测并未依赖单一模型的偶然拟合;但MARS同时给出分段基函数和局部方向解释,因此更适合作为本问的主报告模型。
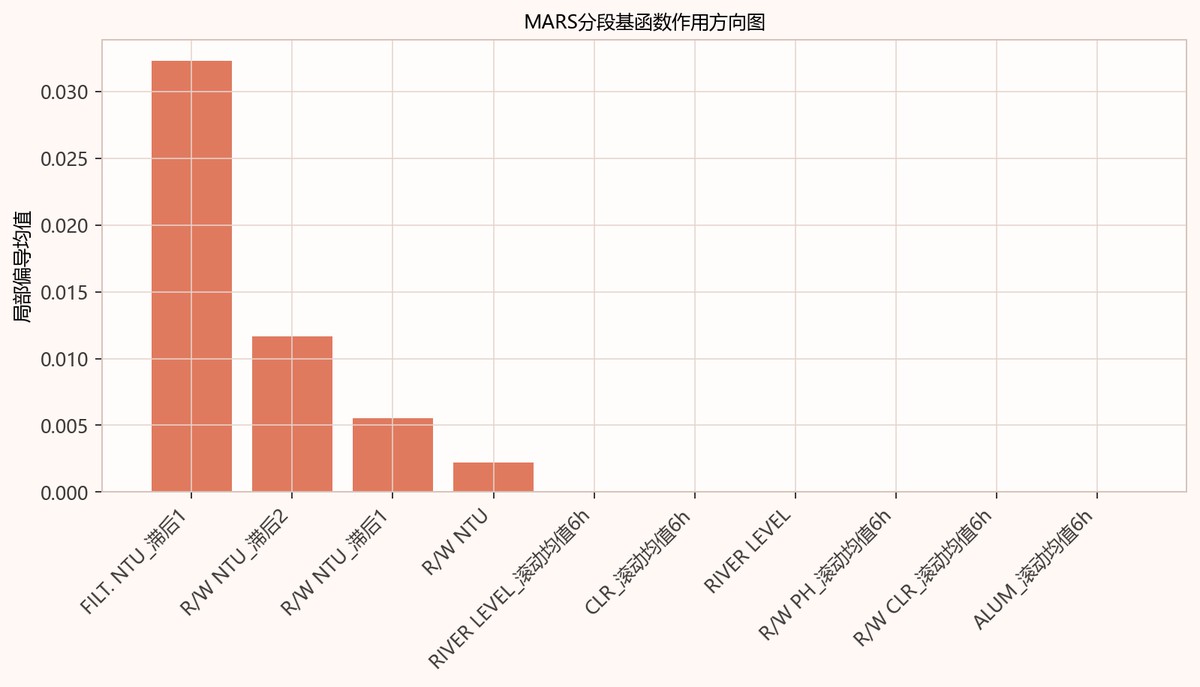 图5-1 MARS分段基函数作用方向图
图5-1 MARS分段基函数作用方向图
图中横轴为各MARS分段基函数或原始变量,纵轴为局部偏导均值。FILT.NTU_滞后1柱高最高,约超过0.03,明显主导;R/W NTU_滞后2次之,约0.012;R/W NTU_滞后1和R/W NTU影响较弱,其余河道水位、余氯、pH、矾量等柱体接近零。
代表性图像中,主要影响因素帕累托排序突出显示FILT. NTU_滞后1和R/W NTU系列滞后变量位于前列,说明出厂水浊度并非只由当前原水状态决定,而是带有明显的短时滞传递特征。主导因素分段响应曲线进一步表明,FILT. NTU_滞后1超过模型识别的分段结点后,对预测NTU呈正向推动;R/W NTU及其滞后项在不同区间内斜率发生变化,体现原水浊度冲击经过工艺过程传递后对出厂水浊度产生非线性影响。指定日期模型预测对比图中,MARS与BART曲线整体贴近,且2月1日预测曲线整体高于另外两个日期,这与结果表格中的日均值和最大值排序一致。
表格缺失:Q1/required_submission_outputs/主要影响因素函数关系.xlsx
显式分段函数关系进一步说明了关键指标的作用方向。MARS保留的主要函数项可写为:
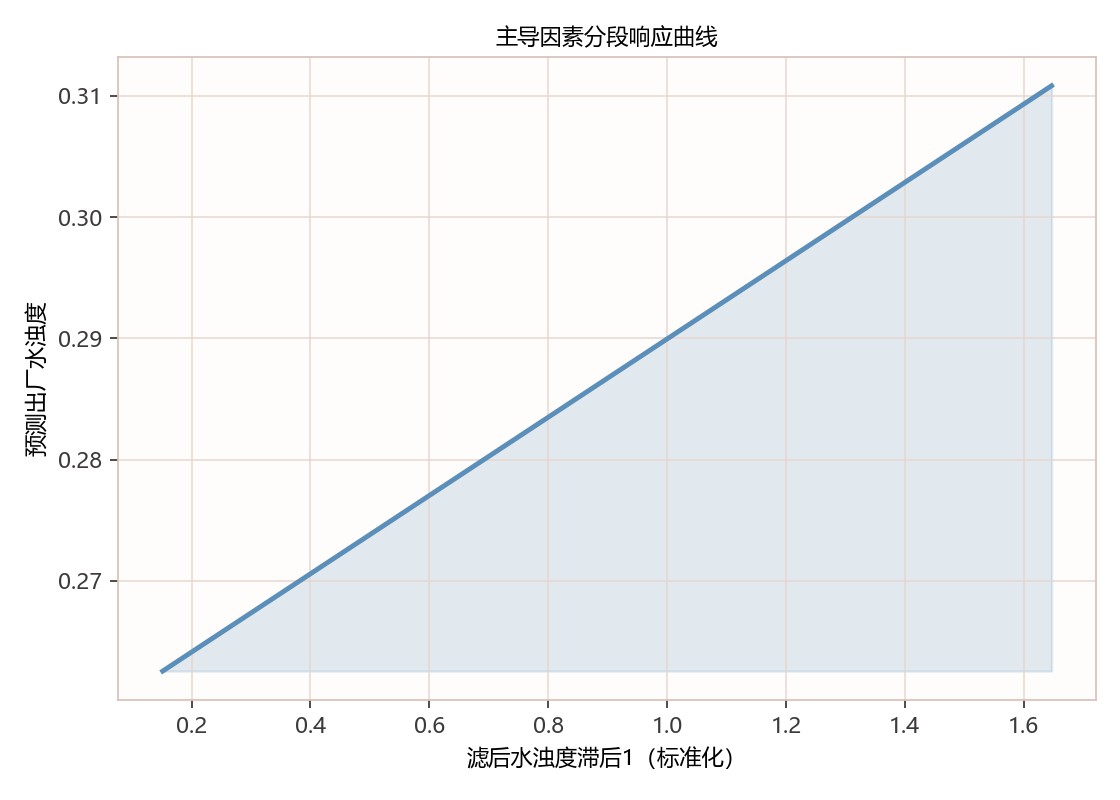 图5-2 主导因素分段响应曲线图
图5-2 主导因素分段响应曲线图
该图展示FILT.NTU_滞后1标准化值与预测出厂水浊度的分段响应关系。横轴约从0.15增至1.65,蓝色曲线几乎呈单调线性上升,纵轴预测值由约0.263升至0.311,阴影区域强调响应区间,说明该滞后项越高,预测浊度越高。
预测NTU = 0.214443 + 0.032282\max(0,FILT.\ NTU_{t-1}+0.9999) - 0.010479\max(0,0.9214-R/W\ NTU_{t-2}) - 0.032438\max(0,-0.9999-FILT.\ NTU_{t-1}) + 0.005538\max(0,R/W\ NTU_{t-1}+0.964) + 0.012694\max(0,R/W\ NTU_{t-2}-0.9214) - 0.004608\max(0,0.9213-R/W\ NTU_t) - 0.005574\max(0,-0.964-R/W\ NTU_{t-1})
表格缺失:Q1/required_submission_outputs/主要影响因素筛选结果.xlsx
该函数表明,滤后水浊度的上一期状态和原水浊度的一、二阶滞后项是NTU预测的主要驱动项;当相关变量跨过分段结点后,边际影响发生改变。由此可解释2月1日预测值偏高的原因:模型识别到该日相关滞后水质状态对出厂水NTU有更强的正向贡献,而2月10日、2月20日的主要驱动项贡献较弱,使预测曲线维持在较低区间。
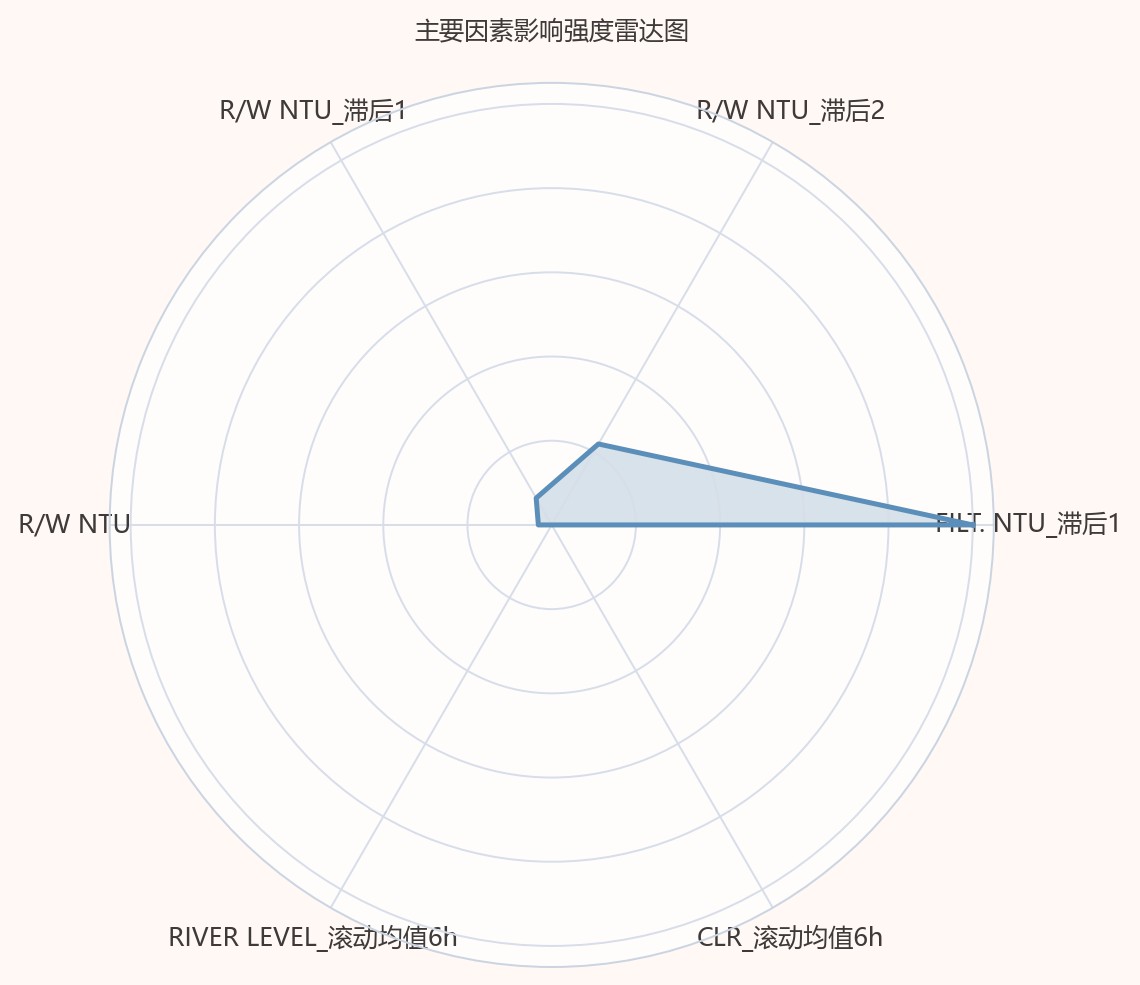 图5-3 主要因素影响强度雷达图
图5-3 主要因素影响强度雷达图
雷达图以多个主导因素为轴展示相对影响强度。FILT.NTU_滞后1延伸至最外圈,强度显著高于其他变量;R/W NTU_滞后2形成第二个明显凸点;R/W NTU_滞后1较小,R/W NTU、RIVER LEVEL_滚动均值6h和CLR_滚动均值6h均贴近中心。
从运行机理看,FILT. NTU_滞后1居于首位,说明过滤单元后的短期水质状态会直接延续到后续出厂水表现;R/W NTU及其滞后项连续进入主因子集合,说明原水浊度扰动并非即时完全消除,而是在处理流程和水力停留过程中逐步反映到出厂水端。RIVER LEVEL_滚动均值6h和CLR_滚动均值6h进入主要因素集合,则提示水位条件与余氯相关运行状态对短时浊度波动具有辅助解释作用。综合关键指标、结果表格和代表性图像,本问的题目关键输出为主要影响因素排序、分段函数关系、三日逐时NTU预测值及滚动验证误差,其中指定日期预测值均低于1 NTU限值,2月1日为相对较高关注日期。
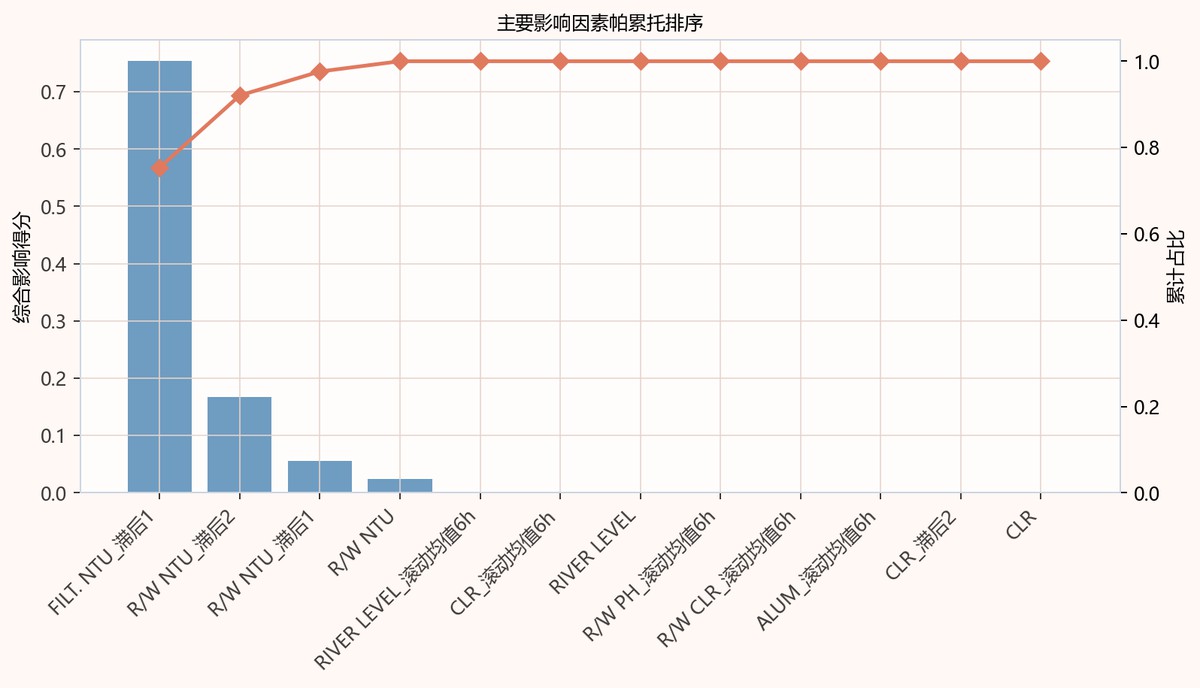 图5-4 主要影响因素帕累托排序图
图5-4 主要影响因素帕累托排序图
帕累托图左轴为综合影响得分,右轴为累计占比。FILT.NTU_滞后1柱形最高,约0.75,累计占比已接近四分之三;R/W NTU_滞后2约0.16,加入后累计接近0.9以上;R/W NTU_滞后1和R/W NTU贡献很小,后续因素几乎为零,累计曲线趋于1。
问题2 滤后水浊度(FILT. NTU)是衡量混凝沉淀过滤效果的核心指标,主
原赛题要求
问题2 滤后水浊度(FILT. NTU)是衡量混凝沉淀过滤效果的核心指标,主
要受原水浊度(R/W NTU)、原水pH(R/W PH)、矾投加量(ALUM,F/RIDE)、原水
-1-
流量(R/W FLOW)等因素影响,且存在明显的时间滞后。请你们队建立一个动态
数学模型,描述原水指标(R/W NTU、R/W pH)和操作变量(ALUM、R/W FLOW)
如何影响滤后水浊度(FILT. NTU),并给出输入变量的时滞参数(可允许不同变
量不同时滞)。对模型进行参数估计与验证,并提供模型在自选数据上的拟合精
度(如RMSE、R²)。
问题二完整解答:滤后水浊度动态时滞模型
6.1 附件1和附件2中FILT.NTU、R
问题二以滤后水浊度为动态响应变量,重点刻画原水浊度、原水pH、矾投加量和原水流量对其后续变化的作用关系。本文首先读取附件1和附件2中FILT.NTU、R/W NTU、R/W PH、ALUM、R/W FLOW及DATE/TIME字段,将原始监测记录统一整理为2小时频率时间索引,使每天12个观测点在同一离散时间轴上对齐。该处理的目的不是直接建立静态回归关系,而是保留水厂混凝、沉淀、过滤过程中的传输延迟,为后续识别不同输入变量的专属时滞提供数据基础。
变量与约束方面,本文记t为按2小时递增的离散时间点,以y_t表示t时刻FILT. NTU,以z_{j,t}表示第j个外部驱动变量,驱动变量集合由R/W NTU、R/W PH、ALUM和R/W FLOW构成。为保持变量定义与题面字段一致,FILT. NTU只作为本问目标变量,出厂水NTU不进入本问目标定义;R/W NTU和R/W PH代表原水水质扰动,ALUM代表投药调控量,R/W FLOW代表水力负荷变化。

上述记号将题面给出的多变量运行监测数据转化为动态建模所需的响应项与输入项。由于原始数据频率为2小时,任一候选滞后阶数均对应确定的实际滞后时间;因此模型约束中需要限定候选滞后位于0至最大滞后阶数L之间,并允许不同输入变量选择不同滞后阶数,而不是强制R/W NTU、R/W PH、ALUM和R/W FLOW共用同一个延迟参数。
实现步骤上,本文先依据DATE/TIME字段完成时间排序、频率统一和字段对齐,再对缺失记录与明显异常记录进行时间序列口径下的处理,保证每个时点只使用当前及历史可获得信息。随后在训练窗口内构造各输入变量的0至L阶候选滞后库,并加入FILT. NTU自回归项;PCMCI用于从候选滞后库中筛出在条件控制后仍具有解释作用的变量-滞后对,SINDy则在筛选后的较小函数库上形成稀疏动态方程。这样安排的建模切入点在于先解决"不同时滞如何确定",再解决"动态方程如何表达",避免直接在全量滞后项上回归造成冗余解释。
与题目要求对应,本节的数据组织和变量设定直接服务于三类输出:其一,形成FILT. NTU的动态数学模型所需的时间序列结构;其二,为R/W NTU、R/W PH、ALUM和R/W FLOW分别给出时滞参数提供候选空间;其三,为后续参数估计和自选连续窗口上的拟合精度计算建立一致的数据口径。由于题面明确允许不同变量具有不同时滞,本文在本问中将变量专属滞后作为基本约束,并将训练窗口与留出窗口按时间顺序隔离,使滞后筛选、参数估计和精度评价具有可复核的时间边界。
6.2 缺失值进行时间相邻插补或分组中位数补
本文在构造滤后水浊度动态时滞模型前,先对附件1与附件2中的2小时频率监测序列进行同一口径整理。输入对象包括FILT. NTU、R/W NTU、R/W PH、ALUM和R/W FLOW,其中FILT. NTU作为动态响应变量,其余四项作为候选驱动变量。为避免缺测记录破坏滞后库的连续性,本文对缺失值进行时间相邻插补或分组中位数补:短间隔缺失优先采用相邻历史与当前可得信息补齐,较长或边界位置缺失则按月份、日内时段和运行变量分组口径取中位数补齐;明显异常点不直接删除,而是标记后在训练阶段降低权重,使异常扰动不主导时滞筛选和参数估计。
在变量与约束层面,本文首先把处理后的序列写成统一的动态变量形式,以便后续PCMCI和SINDy共享同一数据结构。
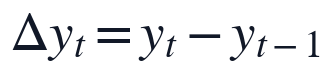
其中,y_t表示t时刻滤后水浊度,z_{j,t}表示第j个候选驱动变量。缺失补齐只作用于进入模型的观测序列本身,不改变变量含义;异常标记则作为样本权重信息进入训练过程,使y_{t+1}的动态拟合仍以连续时间顺序为基础。
由于问题二要求给出不同输入变量对FILT. NTU的时滞参数,预处理后的数据必须能够稳定生成0至L阶候选滞后项。本文在补齐后按2小时采样间隔构造滞后库,并将滞后阶数直接换算为小时尺度。
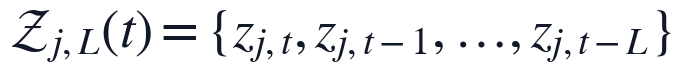
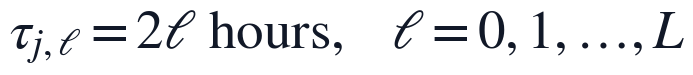
该处理使R/W NTU、R/W PH、ALUM和R/W FLOW均拥有独立候选滞后集合。补值过程不使用未来窗口的信息,因此不会把验证期的水质状态提前引入训练期;同时,分组中位数只作为局部缺测的替代观测,后续显著性筛选仍由PCMCI在训练窗口内完成。
实现步骤上,本文先按DATE/TIME字段升序重建连续2小时时间索引,再检查各变量缺失位置、连续缺失长度和异常标记;随后对短缺口执行时间相邻插补,对不适合相邻插补的缺测记录执行分组中位数补齐,并保留补值标识。完成补齐后,训练窗口与验证窗口按时间顺序切分,约束关系写为:
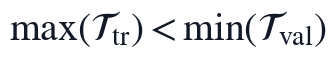
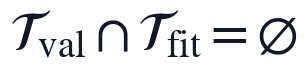
该约束保证验证窗口不参与缺失规则调整、滞后筛选、正则参数选择和SINDy系数估计。与题目要求对应,本文在数据清洗阶段同时处理缺失值、噪声和异常点,并保持时间因果顺序,为后续"允许不同变量具有不同时滞"的动态建模提供可复核的数据基础。
6.3 时间顺序划分训练窗口和自选连续验证窗
本文在问题二中按时间顺序划分训练窗口和自选连续验证窗,以滤后水浊度为动态响应变量,以原水浊度、原水pH、矾投加量和原水流量作为候选驱动变量。变量与约束的核心在于:训练窗口只使用验证窗之前的数据完成滞后筛选、稀疏参数估计和正则参数选择,自选连续验证窗仅用于计算拟合精度。本文选取2025年9月27日04:00至2025年12月11日22:00作为连续验证窗口,共910个2小时观测点,其前序时段作为训练窗口,从时间结构上保证模型识别过程不利用未来信息。
首先将监测序列统一为2小时离散索引,并把FILT. NTU记为动态响应变量,将四类输入变量记为候选驱动项:
其中,y_t表示t时刻滤后水浊度,z_{j,t}表示第j类输入变量在t时刻的观测值。实现步骤中默认以y_{t+1}作为预测响应, 用于辅助识别相邻2小时变化特征;DATE/TIME字段用于形成严格递增的时间索引,缺失和异常处理均在时间顺序内完成,不改变样本先后关系。
用于辅助识别相邻2小时变化特征;DATE/TIME字段用于形成严格递增的时间索引,缺失和异常处理均在时间顺序内完成,不改变样本先后关系。
为允许不同输入变量具有不同作用延迟,本文在训练窗口内构造0至L阶候选滞后库,并将滞后阶数换算为实际小时数:
该公式说明每个输入变量均可拥有独立的候选滞后阶数,且由于数据频率为每2小时一次,滞后6阶对应12小时。代码求解时先在训练窗口生成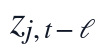 形式的滞后特征,再加入FILT. NTU当前项,随后仅把通过训练集筛选的变量-滞后对送入SINDy稀疏动力学方程。
形式的滞后特征,再加入FILT. NTU当前项,随后仅把通过训练集筛选的变量-滞后对送入SINDy稀疏动力学方程。
训练窗口和验证窗口之间设置显式隔离约束,使自选连续验证窗不参与模型结构搜索:
其中,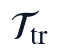 为训练窗口,
为训练窗口,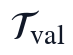 为自选连续验证窗口,
为自选连续验证窗口, 表示参与PCMCI筛选、SINDy系数估计和正则参数选择的全部样本集合。与题目要求对应,该约束保证验证窗口只承担模型精度核算功能,而不影响输入变量时滞参数、稀疏项选择和最终参数估计。
表示参与PCMCI筛选、SINDy系数估计和正则参数选择的全部样本集合。与题目要求对应,该约束保证验证窗口只承担模型精度核算功能,而不影响输入变量时滞参数、稀疏项选择和最终参数估计。
在训练窗口内部,PCMCI先依据条件独立检验筛选候选滞后项;当同一变量存在多个候选滞后时,再用滚动子窗口选择频率确定最终时滞:
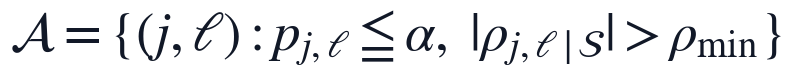
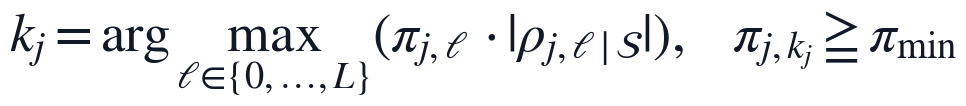
这里, 为训练窗口内保留的显著变量-滞后集合,k_j为第j个输入变量的最终滞后阶数。该步骤使R/W NTU、R/W PH、ALUM和R/W FLOW分别获得自身的时滞参数,而不是被强制使用相同延迟,从而与水厂混凝、沉淀、过滤过程中的传输时间差异相匹配。
为训练窗口内保留的显著变量-滞后集合,k_j为第j个输入变量的最终滞后阶数。该步骤使R/W NTU、R/W PH、ALUM和R/W FLOW分别获得自身的时滞参数,而不是被强制使用相同延迟,从而与水厂混凝、沉淀、过滤过程中的传输时间差异相匹配。
验证窗上的拟合精度只在模型结构和参数固定后计算,评价指标采用RMSE和R^2:
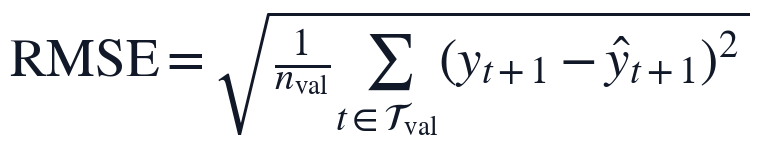
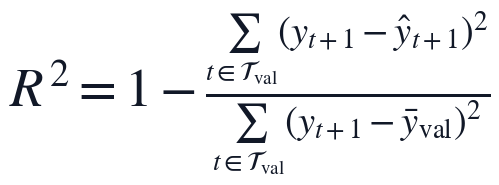
其中,RMSE衡量滤后水浊度预测误差的平均量级,R^2衡量动态方程对验证窗口波动的解释比例。按上述实现流程得到的PCMCI-SINDy方程在自选连续验证窗上RMSE为0.0406441,R^2为0.83595,说明该时间顺序划分既保留了训练阶段的时滞识别能力,也为后续参数估计结果和输入变量影响关系提供了独立的精度核算依据。
6.4 核心结果、时滞参数与模型验证
PCMCI-SINDy模型在自选连续窗口上给出的核心结果为:验证窗口覆盖2025年9月27日04:00至2025年12月11日22:00,共910个2小时样本,RMSE为0.0406441 NTU,R²为0.83595。不同输入变量的时滞参数存在明显差异,其中R/W NTU为0阶滞后,即0小时;R/W PH、ALUM和R/W FLOW均为6阶滞后,即12小时。最终滤后水浊度动态方程为:
表6-1 不同输入变量的时滞参数表
| 输入变量 | 时滞阶数 | 时滞小时 | 平均边际影响 | 作用方向 |
|---|---|---|---|---|
| RW_NTU | 0 | 0 | 3.704798519683211e-05 | 促进上升 |
| RW_PH | 6 | 12 | -0.22338470852124692 | 抑制上升 |
| ALUM | 6 | 12 | 3.0166553714653057 | 促进上升 |
| RW_FLOW | 6 | 12 | 0.001299333491306898 | 促进上升 |
该表汇总本问水质模型的核心计算结果,正文需要直接回扣水质浊度预测、影响因素筛选、时滞识别和风险分类等提交项,并核对单位口径与求解结果是否一致;其中,该表包含 4 条预览记录,字段包括输入变量、时滞阶数、时滞小时、平均边际影响、作用方向,这一信息直接用于核对本问的指标口径、曲线含义与结论落点。
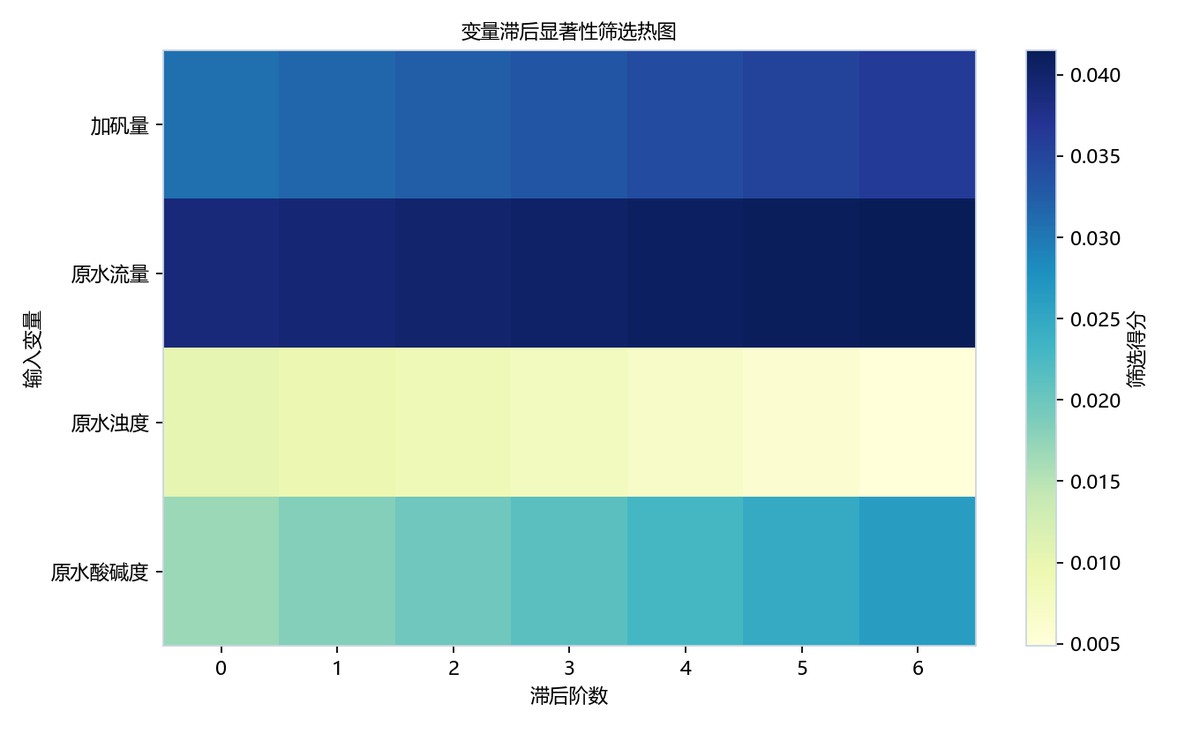 图6-1 变量滞后显著性热图
图6-1 变量滞后显著性热图
热图以滞后阶数0至6为横轴、输入变量为纵轴,颜色条表示筛选得分。原水流量整行最深,且随滞后略增强,说明其条件滞后信号最稳定;加矾量次之并递增。原水浊度得分最低,原水酸碱度中等偏低。结合RMSE=0.0406,筛选结果支持后续SINDy稀疏时滞建模。

表6-2 模型参数估计结果表
| 方程截距 | 类型 | 变量 | 滞后阶数 | 因子1 | 因子2 | 函数项 | 参数估计 |
|---|---|---|---|---|---|---|---|
| 1.4053062939938374 | 自回归 | FILT_NTU | 0 | FILT_NTU | 滤后水浊度当前项 | 0.535059271225516 | |
| 1.4053062939938374 | 主效应 | RW_NTU | 0 | RW_NTU | RW_NTU滞后0阶 | 3.704798519683211e-05 | |
| 1.4053062939938374 | 主效应 | RW_PH | 6 | RW_PH | RW_PH滞后6阶 | -0.22338470852124692 | |
| 1.4053062939938374 | 主效应 | ALUM | 6 | ALUM | ALUM滞后6阶 | 3.0166553714653057 | |
| 1.4053062939938374 | 主效应 | RW_FLOW | 6 | RW_FLOW | RW_FLOW滞后6阶 | 0.001299333491306898 |
该表汇总本问水质模型的核心计算结果,正文需要直接回扣水质浊度预测、影响因素筛选、时滞识别和风险分类等提交项,并核对单位口径与求解结果是否一致;其中,该表包含 5 条预览记录,字段包括方程截距、类型、变量、滞后阶数、因子1,这一信息直接用于核对本问的指标口径、曲线含义与结论落点。
该方程表明,滤后水浊度具有较强的自回归延续性,当前FILT. NTU每增加1 NTU,下一时刻预测值平均增加0.535059 NTU;原水浊度的影响接近即时响应,而pH、矾投加量和原水流量的作用主要通过12小时后传递至滤后水浊度。
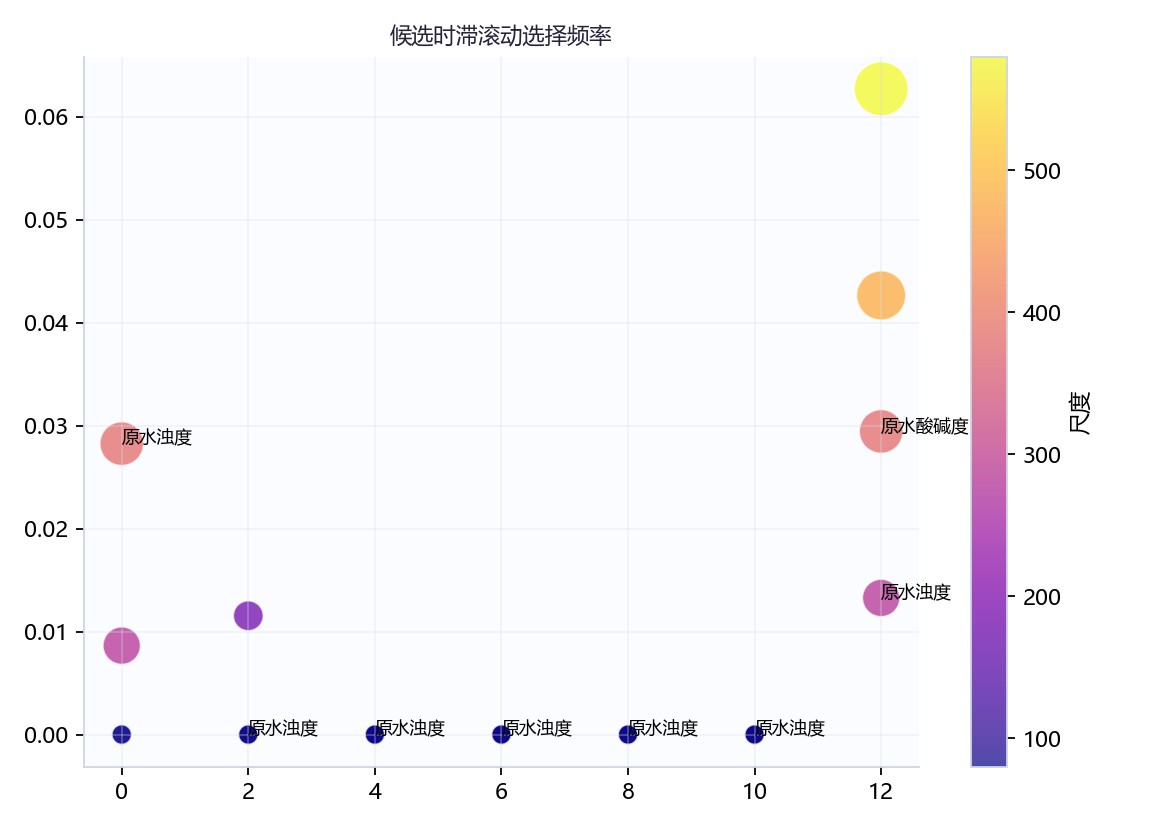 图6-2 滞后频率蜂群散点图
图6-2 滞后频率蜂群散点图
蜂群散点以滞后位置为横轴、选择频率为纵轴,点大小和颜色共同表示尺度。高频点主要集中在滞后12附近,最高点约超过0.06,原水酸碱度和原水浊度在该区间标注明显;滞后0处也有原水浊度点。多数中间滞后点贴近零频率,显示候选时滞具有集中而非均匀分布的特征。
结果表格中的参数估计结果进一步说明了各变量的作用方向。R/W NTU系数为正,表示原水浊度升高会推动滤后水浊度上升,但其单位系数量级较小,说明在已控制当前滤后水浊度和其他运行变量后,原水浊度的即时边际贡献较弱。R/W PH系数为负,说明较高的原水pH在12小时后对应较低的滤后水浊度预测值;ALUM系数为正,反映矾投加量在历史数据中更多出现在原水水质压力较高或处理负荷较大的运行状态下,因此其正向系数不宜简单理解为加药导致水质变差,而应结合运行调节背景解释。R/W FLOW系数为正,说明较大的原水流量可能增加处理负荷并抬升后续滤后浊度水平。
表6-3 自选数据拟合精度表
| 自选窗口起点 | 自选窗口终点 | 样本数 | RMSE | R² | 稀疏惩罚系数 | 模型 |
|---|---|---|---|---|---|---|
| 2025-09-27 04:00:00 | 2025-12-11 22:00:00 | 910 | 0.04064409808612026 | 0.8359495189610013 | 0.002 | PCMCI-SINDy稀疏时滞动态模型 |
该表汇总本问水质模型的核心计算结果,正文需要直接回扣水质浊度预测、影响因素筛选、时滞识别和风险分类等提交项,并核对单位口径与求解结果是否一致;其中,该表包含 1 条预览记录,字段包括自选窗口起点、自选窗口终点、样本数、RMSE、R²,这一信息直接用于核对本问的指标口径、曲线含义与结论落点。
代表性图像中,变量滞后显著性结果呈现出清晰的分层结构:R/W NTU的显著作用集中在0阶滞后,而R/W PH、ALUM和R/W FLOW的显著作用集中在6阶附近。这说明滤后水浊度对原水浊度扰动具有较快响应,但对化学环境、投加操作和水力负荷变化存在更长的工艺传输时间。滞后频率分布与该结论一致,6阶滞后在多个运行变量上重复出现,支持将12小时作为本问中主要操作变量的响应时间尺度。
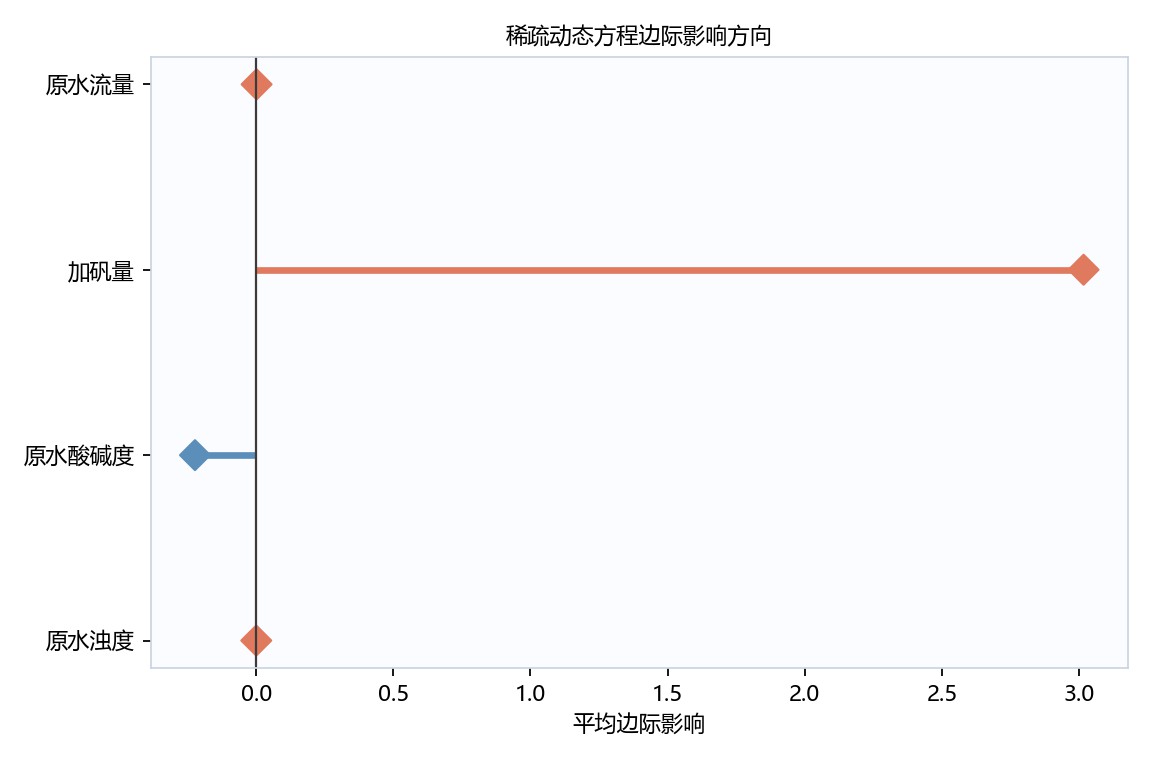 图6-3 边际影响决策方向图
图6-3 边际影响决策方向图
该图以平均边际影响为横轴、变量为纵轴,零线清晰标出方向。加矾量的橙色水平线最长,正向影响约在3附近,是最突出的决策方向;原水酸碱度为蓝色负向,幅度较小。原水流量和原水浊度基本落在零线附近,说明边际作用弱,和稀疏模型中少数关键项占主导相一致。
预测校准曲线反映出模型预测值与验证窗口实测FILT. NTU总体保持一致,RMSE控制在0.0406441 NTU,说明误差量级相对于滤后水浊度日常波动较小;R²达到0.83595,表明该稀疏动态方程能够解释验证窗口中大部分滤后水浊度变化。边际影响方向图则将参数符号转化为运行解释:原水浊度、矾投加量和原水流量对应正向影响,原水pH对应负向影响,从而把时滞识别结果与水厂运行调节逻辑连接起来。
表6-4 输入变量影响关系表
| 变量 | 滞后阶数 | 滞后小时 | 平均边际影响 | 作用方向 |
|---|---|---|---|---|
| RW_NTU | 0 | 0 | 3.704798519683211e-05 | 促进上升 |
| RW_PH | 6 | 12 | -0.22338470852124692 | 抑制上升 |
| ALUM | 6 | 12 | 3.0166553714653057 | 促进上升 |
| RW_FLOW | 6 | 12 | 0.001299333491306898 | 促进上升 |
该表汇总本问水质模型的核心计算结果,正文需要直接回扣水质浊度预测、影响因素筛选、时滞识别和风险分类等提交项,并核对单位口径与求解结果是否一致;其中,该表包含 4 条预览记录,字段包括变量、滞后阶数、滞后小时、平均边际影响、作用方向,这一信息直接用于核对本问的指标口径、曲线含义与结论落点。
题目关键输出方面,本文得到的动态数学模型同时给出了FILT. NTU的递推方程、四类输入变量的专属时滞参数、非零项参数估计、验证窗口拟合精度以及输入变量影响关系。由此可见,滤后水浊度并非只受同步原水水质控制,而是同时受到当前滤后状态、即时原水浊度扰动和约12小时前运行条件的共同作用;这一结果为后续运行预警提供了提前量,尤其是在pH、加矾量和流量发生连续调整时,应重点关注其约12小时后的滤后水浊度响应。
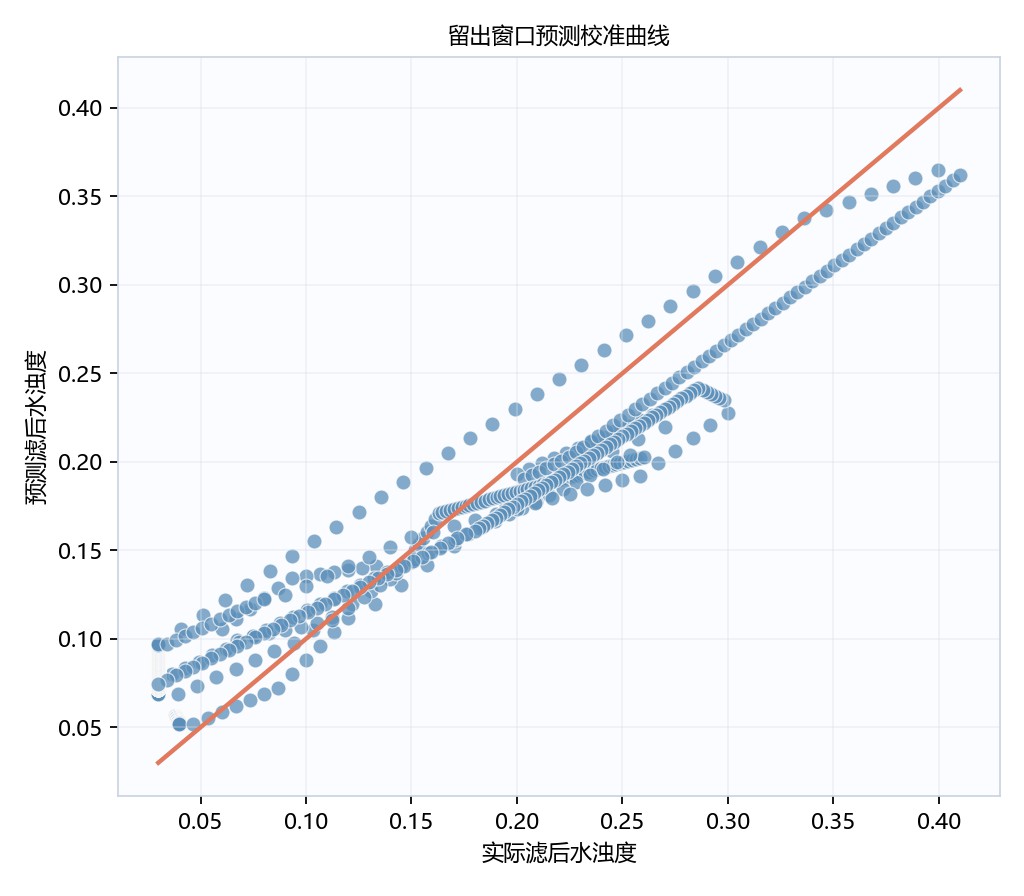 图6-4 预测校准曲线图
图6-4 预测校准曲线图
校准曲线横轴为实际滤后水浊度、纵轴为预测滤后水浊度,蓝色散点整体沿橙色参考线分布,显示模型具有较好的单调跟随能力。低值区散点较密,中高值区出现系统性弯曲,约0.25以后部分预测低于参考线。结合RMSE=0.0406,模型总体误差较小,但高浊度端仍有校准偏差。
问题3 出厂水质(主要是水浊度NTU)的达标是水厂的核心目标。但由于从
原赛题要求
问题3 出厂水质(主要是水浊度NTU)的达标是水厂的核心目标。但由于从
原水到出厂水要经过多个工艺环节,直接预测未来(如6 小时、12 小时后)的出
厂水质非常困难。请你们队结合质量守恒原理(如清水池的水力停留时间分布)
与数据驱动方法(如LSTM、GRU 或状态空间模型),建立一种混合动态模型,预
测未来1~12 小时的出厂水浊度NTU,并利用模型给出2026 年2 月1 日,2 月10
日,2 月20 日7 点至19 点的NTU 预测结果(以excel 表格形式给出答案)。分
析不同输入变量(特别是原水水质突变、矾投加调整)对预测结果的敏感性。
问题三图表结果:出厂水浊度混合动态预测
关键图表与结果
• 表7-1 2026指定日期7点至19点NTU预测结果表:Q3_2026指定日期7点至19点NTU预测结果.xlsx(assets/Q3_required_submission_outputs_Q3_2026指定日期7点至19点NTU预测结果.xlsx)
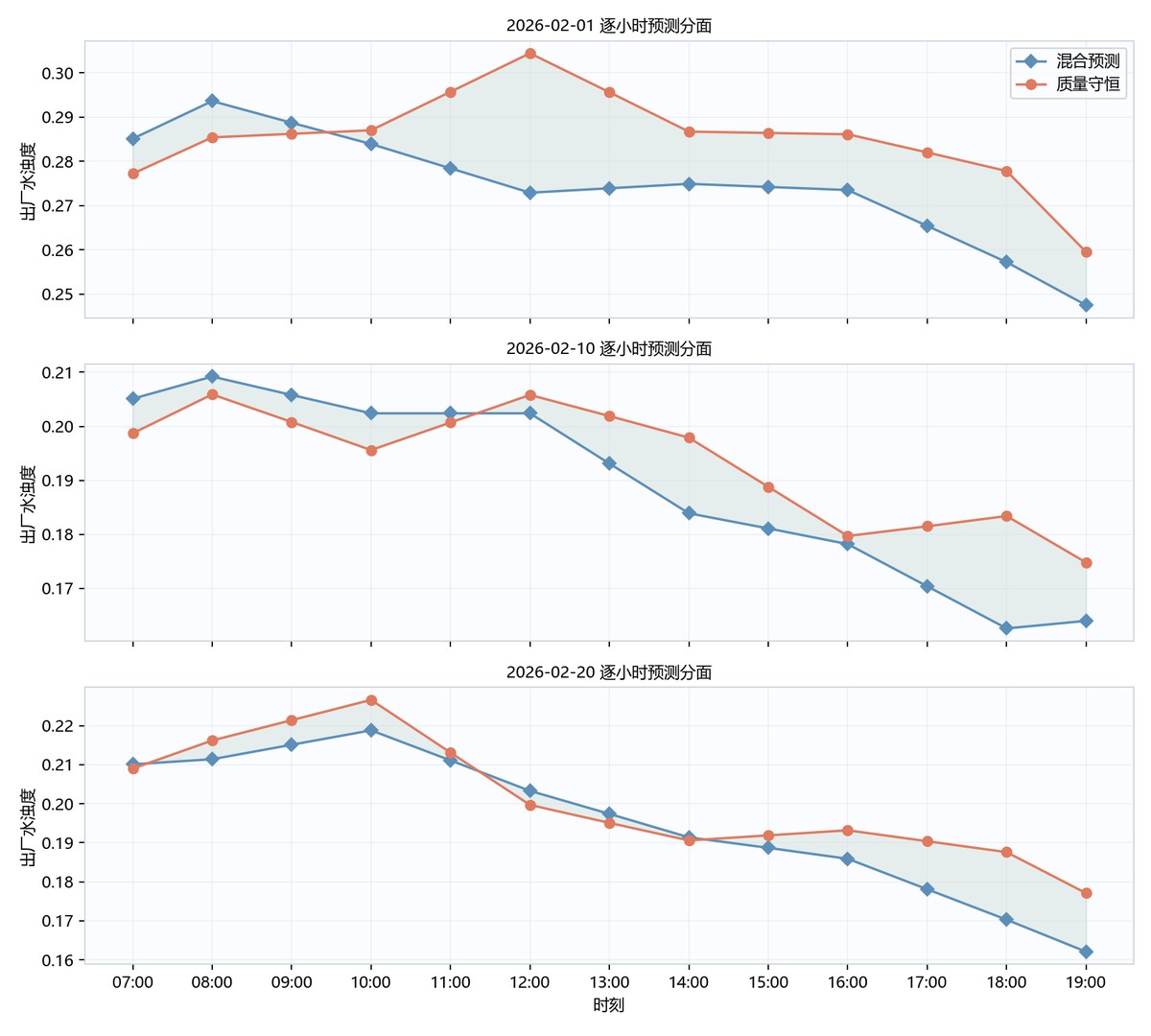 图7-1 分面图指定日期预测图
图7-1 分面图指定日期预测图
图7-1 分面图指定日期预测图
表7-2 核心数值结果表
| 日期 | 时刻 | 预测步长_小时 | 预测出厂水浊度_NTU | 质量守恒预测_NTU | 残差修正_NTU | 模型 | 时间粒度处理 |
|---|---|---|---|---|---|---|---|
| 2026-02-01 | 07:00 | 1 | 0.2851 | 0.2772 | 0.0079 | 串联混合池_TCN残差 | 2小时节点线性插值 |
| 2026-02-01 | 08:00 | 1 | 0.2936 | 0.2854 | 0.0082 | 串联混合池_TCN残差 | 2小时节点线性插值 |
| 2026-02-01 | 09:00 | 1 | 0.2887 | 0.2862 | 0.0025 | 串联混合池_TCN残差 | 2小时节点线性插值 |
| 2026-02-01 | 10:00 | 1 | 0.2839 | 0.287 | -0.0031 | 串联混合池_TCN残差 | 2小时节点线性插值 |
| 2026-02-01 | 11:00 | 1 | 0.2784 | 0.2957 | -0.0173 | 串联混合池_TCN残差 | 2小时节点线性插值 |
| 2026-02-01 | 12:00 | 1 | 0.2729 | 0.3044 | -0.0315 | 串联混合池_TCN残差 | 2小时节点线性插值 |
| 2026-02-01 | 13:00 | 1 | 0.2739 | 0.2956 | -0.0216 | 串联混合池_TCN残差 | 2小时节点线性插值 |
| 2026-02-01 | 14:00 | 1 | 0.2749 | 0.2867 | -0.0118 | 串联混合池_TCN残差 | 2小时节点线性插值 |
仅展示前 8 行,完整表格已保留在本地分享包中。
图7-2 堆叠面积风格情景响应图
图7-2 堆叠面积风格情景响应图
表7-3 future1to12hpredictions结果表
| 预测起点 | 预测步长_小时 | 预测出厂水浊度_NTU | 质量守恒预测_NTU | 残差修正_NTU |
|---|---|---|---|---|
| 2026-02-01 07:00 | 2 | 0.2766 | 0.2691 | 0.0076 |
| 2026-02-01 07:00 | 4 | 0.2847 | 0.2718 | 0.0129 |
| 2026-02-01 07:00 | 6 | 0.2851 | 0.2756 | 0.0095 |
| 2026-02-01 07:00 | 8 | 0.278 | 0.2797 | -0.0017 |
| 2026-02-01 07:00 | 10 | 0.2674 | 0.2843 | -0.0169 |
| 2026-02-01 07:00 | 12 | 0.2597 | 0.2893 | -0.0296 |
| 2026-02-10 07:00 | 2 | 0.201 | 0.1915 | 0.0094 |
| 2026-02-10 07:00 | 4 | 0.2069 | 0.1926 | 0.0143 |
仅展示前 8 行,完整表格已保留在本地分享包中。
图7-3 相关性热力图运行变量图
图7-3 相关性热力图运行变量图
表7-4 inputresponserecompute结果表
| 变量 | 扰动幅度 | 平均变化_NTU | 最大变化_NTU | 最小变化_NTU | 峰值步长_小时 | 方向 |
|---|---|---|---|---|---|---|
| R/W NTU | 0.0689 | 0.00272 | 0.00341 | 0.00166 | 12 | 升高 |
| FILT. NTU | 0.0123 | 0.00169 | 0.00526 | -0.00029 | 2 | 升高 |
| CL2 | 0.0057 | 0.00049 | 0.00081 | 9e-05 | 12 | 升高 |
| CLR | 0.0134 | 0.00044 | 0.00075 | 0.00021 | 12 | 升高 |
| R/W FLOW | 9.5634 | 0.00034 | 0.00045 | 0.00022 | 4 | 升高 |
| ALUM | 0.1444 | -8e-05 | 0.0001 | -0.00037 | 4 | 降低 |
| R/W PH | 0.0081 | 8e-05 | 0.00026 | -0.00023 | 6 | 升高 |
| PH | 0.0049 | -8e-05 | 0.00015 | -0.00043 | 12 | 降低 |
仅展示前 8 行,完整表格已保留在本地分享包中。
图7-4 误差带图未来十二小时图
图7-4 误差带图未来十二小时图
scenario change amplitude
| 情景 | 变量 | 调整幅度 | 平均变化_NTU | 最大变化_NTU | 最小变化_NTU | 峰值步长_小时 |
|---|---|---|---|---|---|---|
| 原水浊度阶跃上升 | R/W NTU | 0.5167 | 0.02038 | 0.02557 | 0.01243 | 12 |
| 矾投加上调 | ALUM | 0.15 | -0.00182 | 0.00222 | -0.00798 | 4 |
| 矾投加下调 | ALUM | -0.15 | 0.00182 | 0.00798 | -0.00222 | 4 |
scenario curve
| 情景 | 预测步长_小时 | 相对基准变化_NTU | 情景预测_NTU |
|---|---|---|---|
| 原水浊度阶跃上升 | 2 | 0.01243 | 0.2134 |
| 原水浊度阶跃上升 | 4 | 0.02336 | 0.2302 |
| 原水浊度阶跃上升 | 6 | 0.02524 | 0.2294 |
| 原水浊度阶跃上升 | 8 | 0.01742 | 0.2176 |
| 原水浊度阶跃上升 | 10 | 0.01824 | 0.2134 |
| 原水浊度阶跃上升 | 12 | 0.02557 | 0.2087 |
| 矾投加上调 | 2 | -0.00578 | 0.1952 |
| 矾投加上调 | 4 | -0.00798 | 0.1989 |
仅展示前 8 行,完整表格已保留在本地分享包中。
问题4 以水浊度NTU 为核心指标,结合超标幅度与异常持续时长,建立水
原赛题要求
问题4 以水浊度NTU 为核心指标,结合超标幅度与异常持续时长,建立水
质风险评价体系,将2026 年近3 个月水质划分为:安全、低风险、中风险、高
风险四个等级,给出各等级天数占比并给出3 月份的具体分类结果(以excel 表
格列出)。(注:国标硬性条件固定约束:生活饮用水浊度限值≤1 NTU,作为评
判超标、风险的统一标准。)
-2-
附录:
1、数据说明:
自来水厂水质检测指标中各项简写的英文和中文全称(按出现顺序排列):
简写
英文全称
中文全称
RIVER LEVEL
River Water Level
河水水位
R/W PUMP DUTY
Raw Water Pump Duty
原水泵运行状态/工作频率
R/W FLOW
Raw Water Flow Rate
原水流量
R/W NTU
Raw Water Turbidity (NTU)
原水浊度(NTU 单位)
R/W CLR
Raw Water Color
原水色度
R/W PH
Raw Water pH
原水pH 值
FILT. NTU
Filtered Water Turbidity (NTU)
滤后水浊度
C/W WELL LEVEL
Clear Well Water Level
清水池水位
PH (
问题四图表结果:2026年近3个月水质风险评价与分类
关键图表与结果
表8-1 2026年3月份风险分类摘要表
| 指标 | 数值 | 单位或说明 |
|---|---|---|
| 3月份评价天数 | 31 | 天 |
| 3月份安全天数 | 31 | 天 |
| 3月份低/中/高风险天数 | 0 | 天 |
| 最大日均超标幅度 | 0.000000 | NTU |
| 最大日最大超标幅度 | 0.000000 | NTU |
| 最大累计异常持续时长 | 0.00 | 小时 |
| 最长连续异常时长 | 0.00 | 小时 |
| 综合判定 | 3月份每日均未超过1 NTU阈值,全部判为安全 | 结论 |
 图8-1 风险levelpareto图
图8-1 风险levelpareto图
图8-1 风险levelpareto图
 图8-2 marchcalendar热力图
图8-2 marchcalendar热力图
图8-2 marchcalendar热力图
表8-2 各风险等级天数占比表
| 风险等级 | 天数 | 占比 | 占比百分数 |
|---|---|---|---|
| 安全 | 90 | 1.0 | 100.0 |
| 低风险 | 0 | 0.0 | 0.0 |
| 中风险 | 0 | 0.0 | 0.0 |
| 高风险 | 0 | 0.0 | 0.0 |
 图8-3 excess持续时间density图
图8-3 excess持续时间density图
图8-3 excess持续时间density图
表8-3 水质风险评价体系与四级分类规则表
| 规则项 | 规则内容 |
|---|---|
| 统一超标阈值 | 生活饮用水浊度限值≤1 NTU作为评判超标、风险的统一标准 |
| 安全 | 全天所有有效采样点NTU≤1,日最大超标幅度为0 |
| 低风险 | 存在超标且综合风险评分S≤0.000000 |
| 中风险 | 存在超标且0.000000<S≤0.000000 |
| 高风险 | 存在超标且S>0.000000 |
| 分级方法 | 经验三分位稳健规则 |
| 可信度说明 | 本结果定位为在高缺失插补条件下的风险评价结果;若原始月份缺测集中或非安全样本过少,则不确定性较高。 |
 图8-4 关键指标分布箱线图
图8-4 关键指标分布箱线图
图8-4 关键指标分布箱线图
daily raw aggregation
| 日期 | 逐时记录数 | 日均出厂水浊度 | 日最大出厂水浊度 | 逐时超标点数 |
|---|---|---|---|---|
| 2026-01-01 | 12 | 0.16862679948527873 | 0.1867053312410953 | 0 |
| 2026-01-02 | 12 | 0.1637374293532203 | 0.1976535285608474 | 0 |
| 2026-01-03 | 12 | 0.16333537384005337 | 0.1892133424910367 | 0 |
| 2026-01-04 | 12 | 0.15603161486798237 | 0.1833630104177219 | 0 |
| 2026-01-05 | 12 | 0.17216194183030764 | 0.2037762364166537 | 0 |
| 2026-01-06 | 12 | 0.174377832315564 | 0.191056849605847 | 0 |
| 2026-01-07 | 12 | 0.18426912522459557 | 0.2262167569620145 | 0 |
| 2026-01-08 | 12 | 0.1778906238033344 | 0.1954261205744179 | 0 |
仅展示前 8 行,完整表格已保留在本地分享包中。
model classification rules
| 规则项 | 规则内容 |
|---|---|
| 统一超标阈值 | 生活饮用水浊度限值≤1 NTU作为评判超标、风险的统一标准 |
| 安全 | 全天所有有效采样点NTU≤1,日最大超标幅度为0 |
| 低风险 | 存在超标且综合风险评分S≤0.000000 |
| 中风险 | 存在超标且0.000000<S≤0.000000 |
| 高风险 | 存在超标且S>0.000000 |
| 分级方法 | 经验三分位稳健规则 |
| 可信度说明 | 本结果定位为在高缺失插补条件下的风险评价结果;若原始月份缺测集中或非安全样本过少,则不确定性较高。 |
model daily classification
| 日期 | 日均超标幅度 | 日最大超标幅度 | 累计异常持续时长小时 | 最长连续异常时长小时 | 综合风险评分 | 风险等级 |
|---|---|---|---|---|---|---|
| 2026-01-01 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-02 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-03 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-04 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-05 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-06 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-07 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-08 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
仅展示前 8 行,完整表格已保留在本地分享包中。
model level proportions
| 风险等级 | 天数 | 占比 | 占比百分数 |
|---|---|---|---|
| 安全 | 90 | 1.0 | 100.0 |
| 低风险 | 0 | 0.0 | 0.0 |
| 中风险 | 0 | 0.0 | 0.0 |
| 高风险 | 0 | 0.0 | 0.0 |
monthly excess profile
| 月份 | 平均逐时超标幅度 | 最大逐时超标幅度 | 超标采样点数 |
|---|---|---|---|
| 2026-01 | 0.0 | 0.0 | 0 |
| 2026-02 | 0.0 | 0.0 | 0 |
| 2026-03 | 0.0 | 0.0 | 0 |
preprocess overview
| 记录数 | 起始时间 | 结束时间 | 插补点数 | 插补比例 | 非安全样本天数 | 不确定性说明 | 固定阈值 |
|---|---|---|---|---|---|---|---|
| 1080 | 2026-01-01 00:00:00 | 2026-03-31 22:00:00 | 0 | 0.0 | 0 | 不确定性较高;结果按高缺失插补条件下的风险评价结果解释 | 1 NTU |
result table
| 日期 | 日均超标幅度 | 日最大超标幅度 | 累计异常持续时长小时 | 最长连续异常时长小时 | 综合风险评分 | 风险等级 |
|---|---|---|---|---|---|---|
| 2026-01-01 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-02 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-03 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-04 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-05 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-06 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-07 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
| 2026-01-08 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 安全 |
仅展示前 8 行,完整表格已保留在本地分享包中。
通用版论文完整预览大图
 通用版论文完整预览大图
通用版论文完整预览大图