有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主

图1 项目封面效果
一、项目整体介绍
这套项目围绕心脏病健康数据展开,从原始数据整理、字段清洗、统计聚合、模型预测到可视化大屏呈现,形成了一条比较完整的数据挖掘实践链路。数据字段覆盖 BMI、吸烟、饮酒、中风、身体健康天数、精神健康天数、行走困难、年龄段、糖尿病、总体健康、睡眠时长、哮喘、肾病、皮肤癌等多个维度,既能做基础统计,也能继续向机器学习预测方向扩展。
我在整理项目时,重点保留了"能展示、能运行、能讲清楚"的部分。前端侧有大屏页面和多张单页可视化图,后端侧有 MySQL 统计表和 SQL 数据文件,算法侧则使用 XGBoost 完成心脏病风险二分类,并输出混淆矩阵、分类报告、ROC AUC、特征重要性等结果。对于毕业设计或者课程设计来说,这种结构比单纯画几张图更完整,也更容易体现数据工程和算法应用能力。
项目呈现时不需要把所有代码细节逐行展开,重点放在数据从哪里来、如何清洗、分析了哪些指标、模型效果如何、页面展示成什么样。读者一眼能看到整体完成度,也能快速判断这是不是自己需要的资源。
整体定位上,我更倾向把它做成一个"数据分析 + 风险预测 + 大屏展示"的综合项目。前面用清洗流程证明数据处理能力,中间用多维图表呈现分析结果,后面用 XGBoost 模型补上预测能力,再配合 SQL 和 HTML 页面说明工程落地。这样讲起来层次更清楚,展示时也更容易把亮点说完整。
页面素材已经覆盖了常见展示场景:可以先放大屏图吸引注意,再用几张关键分布图说明数据结构,最后用模型指标和特征重要性收尾。这样的顺序比较适合项目介绍页,也适合录制演示视频时按模块讲解。
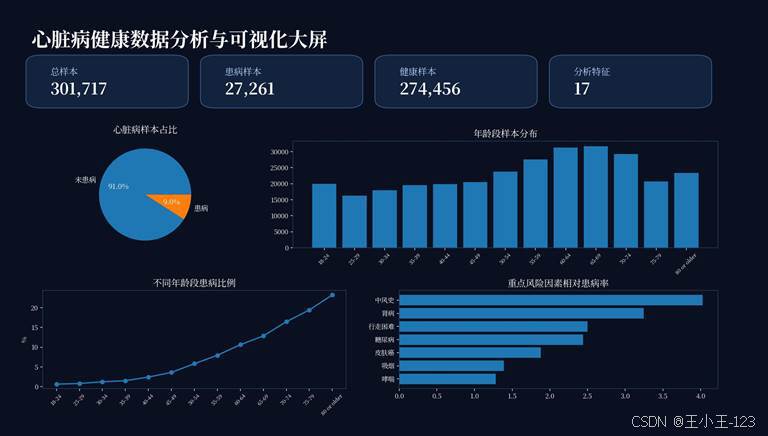
图2 总体可视化大屏预览
|---------|-----------------------------------------------------------|
| 项目项 | 说明 |
| 数据规模 | 清洗前 319,795 条,去重 18,078 条,最终保留 301,717 条有效记录 |
| 核心字段 | BMI、吸烟、饮酒、中风、身体/精神健康天数、行走困难、性别、年龄段、糖尿病、总体健康、睡眠、哮喘、肾病、皮肤癌等 |
| 可视化端 | 基于 Pyecharts、HTML、CSS、JavaScript 生成大屏和单页交互图表 |
| 建模端 | 使用 LabelEncoder 处理类别字段,结合 XGBoost 完成二分类预测,并对比上采样、欠采样后的效果 |
| 数据库端 | SQL 中包含管理表、统计聚合表和多维分析结果表,可支撑可视化页面快速读取 |
二、数据来源与预处理流程
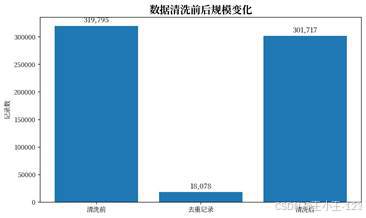
项目数据来自公开心脏病健康相关数据集,原始记录量为 319795 条。导入后先通过 Pandas 读取 CSV,再检查重复值、空值和字段类型。处理过程中共发现 18078 条重复记录,删除重复记录后保留 301717 条有效样本;随后统一字段命名,将列名转换为小写,并插入 id 字段,方便后续入库和查询。
清洗后的字段结构比较规整,既有连续型指标,如 BMI、PhysicalHealth、MentalHealth、SleepTime,也有大量类别型变量,如 Smoking、Stroke、AgeCategory、Race、Diabetic、GenHealth 等。这样的数据特点很适合用来做可视化展示:一方面可以按年龄、性别、疾病史分组统计,另一方面也能把类别字段编码后送入模型进行预测。
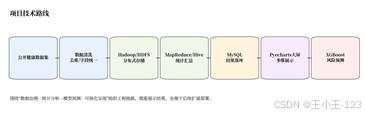
在数据处理脚本中,清洗结果被分别保存为 CSV 和 Excel,同时复制到脚本目录,方便后续 Flume、Hive 或数据库导入使用。项目还准备了 Hadoop、Flume、Hive 相关配置和启动脚本,说明它不是只停留在 Notebook 里的临时分析,而是按照大数据课程项目的思路把采集、清洗、存储和展示串到了一起。
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
| 图3 项目技术路线 | 图4 数据清洗前后规模变化 |
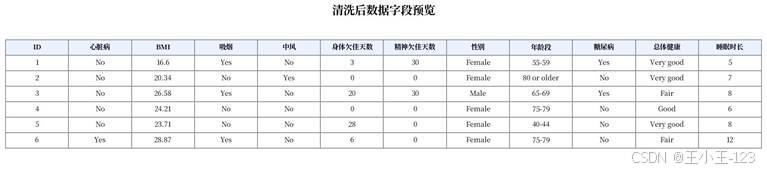
图5 清洗后数据字段预览
三、系统功能与工程结构
从资源结构看,项目材料比较齐全:有原始数据和清洗后数据,有数据预处理脚本,有可视化绘制脚本,有大屏制作 Notebook,有 XGBoost 预测脚本,还有 SQL 文件和单页图表 HTML。这样的组织方式适合后续继续包装为完整系统,也便于按模块演示。
可视化部分采用 Pyecharts 生成 HTML 图表,图表主题覆盖心脏病患者占比、性别占比、年龄分布、不同年龄段 BMI 均值、不同年龄段心脏病情况、种族分布、糖尿病/哮喘/肾病等健康因素与心脏病之间的关系。单页图表可以独立打开,大屏页面则把多个图表组合到一个展示页面里。
数据库侧的 SQL 文件包含管理表、统计结果表和可视化汇总表,例如 heartdisease_counts、sex_counts、agecategory_counts、race_counts、diabetic_counts、agecategory_bmi_avg、agecategory_heartdisease_counts 等。前端直接读取聚合后的统计表,可以减少实时计算压力,页面加载也更稳定。
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
| 图6 项目代码与资源结构 | 图7 数据库统计表结构 |
四、多维可视化分析展示
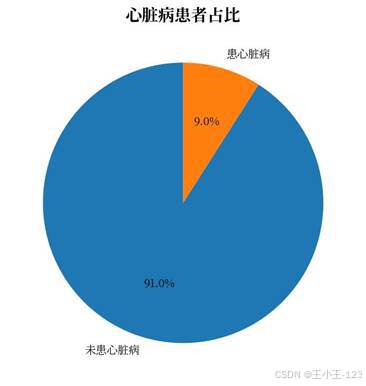
可视化展示是这个项目最容易吸引读者的部分。心脏病样本占比图可以先给出整体认知:清洗后的 301717 条记录中,患心脏病样本为 27261 条,未患心脏病样本为 274456 条,整体存在明显的类别不平衡。这个现象也解释了为什么后续模型训练需要考虑上采样和欠采样。
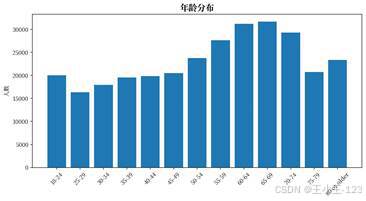
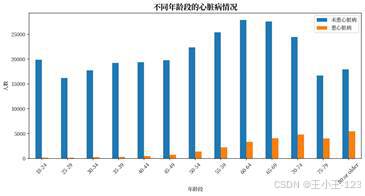
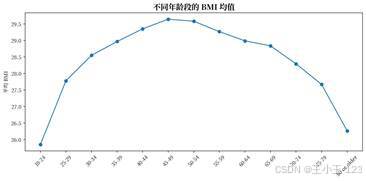
年龄维度的趋势非常直观。随着年龄段升高,心脏病比例整体上升,尤其在 60 岁以后更加明显。年龄段分布、不同年龄段患病情况、不同年龄段 BMI 均值组合在一起,可以形成一组完整的"年龄画像",既能看人群规模,也能看风险变化。
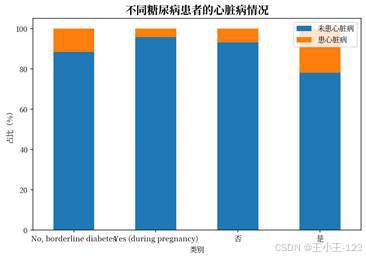
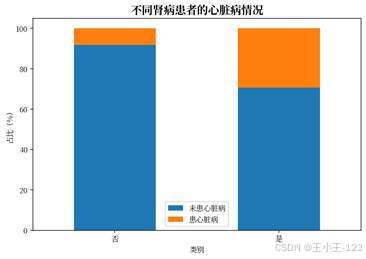
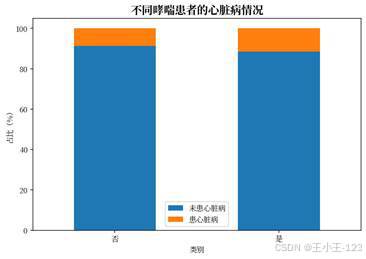
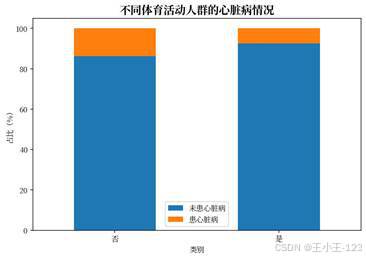
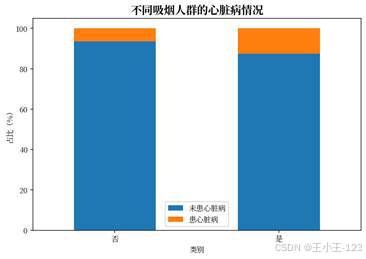
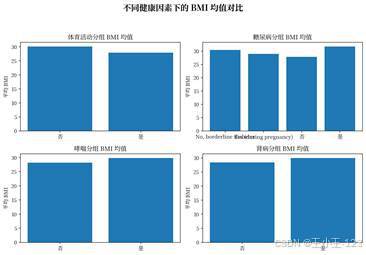
疾病史和生活方式维度也有较好的展示价值。糖尿病、肾病、哮喘、吸烟、是否进行体育活动等变量都可以拆成分组图表,观察不同人群中的患病比例差异。对于展示页面来说,这类图表比单纯的总量饼图更有说服力,因为它能解释"哪些因素值得重点关注"。
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
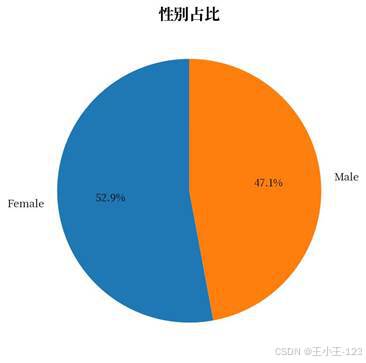
| 图8 心脏病患者占比 | 图9 性别占比 |
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
| 图10 年龄分布 | 图11 不同年龄段的心脏病情况 |
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
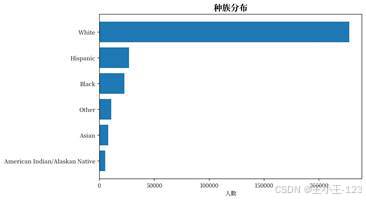
| 图12 不同年龄段 BMI 均值 | 图13 种族分布 |
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
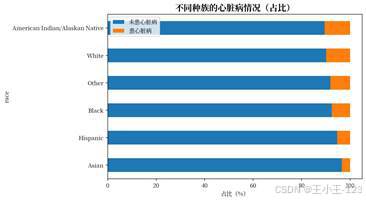
| 图14 不同种族的心脏病情况 | 图15 不同糖尿病患者的心脏病情况 |
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
| 图16 不同肾病患者的心脏病情况 | 图17 不同哮喘患者的心脏病情况 |
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
| 图18 不同体育活动人群的心脏病情况 | 图19 不同吸烟人群的心脏病情况 |
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
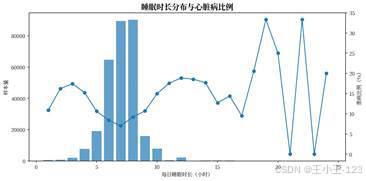
| 图20 不同健康因素下的 BMI 均值对比 | 图21 睡眠时长分布与心脏病比例 |
五、 XGBoost 心脏病风险预测模型
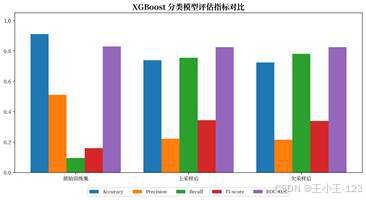
模型部分以 heartdisease 作为预测目标,将 Yes 映射为 1,将 No 映射为 0。训练前先删除 id 和目标列,对类别型字段进行 LabelEncoder 编码,然后按照 8:2 划分训练集和测试集。原始训练集下,XGBoost 的 Accuracy 达到 0.9101,ROC AUC 达到 0.8290,说明模型具备较好的整体区分能力。
不过,原始数据存在明显类别不平衡,直接训练时少数类召回率只有 0.0956。为了解决这个问题,项目进一步尝试了上采样和欠采样。上采样后 Accuracy 为 0.7393,Recall 提升到 0.7549;欠采样后 Accuracy 为 0.7243,Recall 达到 0.7806。虽然整体准确率下降,但对患病样本的识别能力明显增强,这也更符合风险筛查场景的需求。
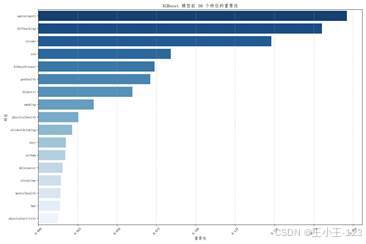
特征重要性图显示,agecategory、diffwalking、stroke、sex、kidneydisease、genhealth、diabetic、smoking 等变量对预测结果贡献较高。这些结果和可视化分析中的趋势是相互呼应的:年龄、行动能力、既往病史和总体健康评价,都是心脏病风险判断中较为关键的因素。
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
| 图22 XGBoost 分类模型评估指标对比 | 图23 XGBoost 特征重要性 |
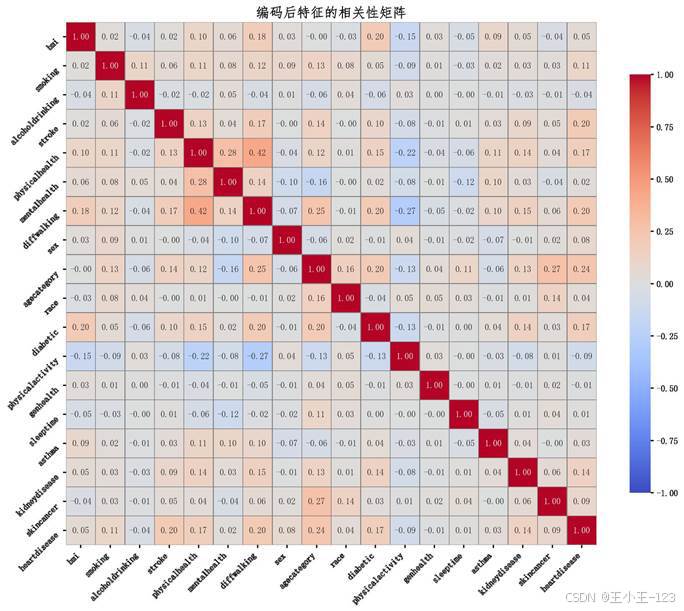
图24 编码后特征相关性矩阵
六、页面展示与适用场景
这套项目适合用于数据分析、数据挖掘、可视化大屏、机器学习预测等方向的综合展示。页面层面可以展示大屏和单页图表,算法层面可以展示分类模型、采样策略、特征重要性和相关性矩阵,工程层面可以展示数据文件、SQL、脚本和 Notebook。多个模块组合之后,项目完整度会比普通可视化作业更高。
如果后续继续完善,可以把 HTML 图表接入 Flask 或 Django 后端,增加登录、文件上传、模型预测接口和管理端页面;也可以把 XGBoost 模型保存成 pkl 文件,前端输入个体健康信息后直接返回风险判断结果。这样项目就能从"数据分析展示"升级成"健康风险预测系统"。
从展示效果来看,重点不在于把所有公式、参数和代码细节全部堆出来,而是要让读者快速看到:数据规模足够、分析维度完整、图表数量丰富、模型有结果、项目资源齐全。这样呈现更适合放在项目论坛、资源介绍页或者毕设成果展示中。
七、项目亮点总结
第一,数据链路完整。项目从原始 CSV 开始,经历去重、缺失检查、字段统一、保存清洗数据、入库和可视化输出,流程清楚,适合复现。
第二,图表维度丰富。年龄、性别、种族、糖尿病、肾病、哮喘、体育活动、吸烟、睡眠、BMI 等维度均有图表支撑,展示时不会显得单薄。
第三,模型部分有对比。XGBoost 不只给出一次训练结果,还结合上采样、欠采样对类别不平衡问题进行处理,能够说明模型调试思路。
第四,资源文件齐全。数据、代码、Notebook、SQL、HTML 图表、配置脚本基本都在,后续无论是写论文、录视频、部署演示,还是继续扩展系统功能,都比较方便。
八、运行展示建议
拿到资源后,可以先从数据预处理脚本开始检查运行环境,确认 Pandas、Numpy、Matplotlib、Sklearn、XGBoost 等库可以正常导入;再打开清洗后的 CSV,核对字段数量、样本规模和目标变量分布。这样做的好处是先保证数据基础没有问题,后面无论是生成图表还是训练模型,都不容易出现路径或编码错误。
可视化演示建议分两步进行:第一步直接打开已经生成的单页 HTML 图表,让读者看到年龄、性别、BMI、糖尿病、肾病、哮喘等维度的分析效果;第二步再展示大屏页面,把多个图表放在同一个页面中统一呈现。这样既能看单个指标,也能看整体仪表盘效果。
模型演示可以重点讲三件事:先说明为什么要把 heartdisease 转成 0/1,再说明类别字段为什么需要编码,最后说明类别不平衡为什么会影响召回率。只要这三点讲清楚,XGBoost 指标对比和特征重要性就有了上下文,答辩时也更容易回答老师关于模型合理性的追问。
如果需要继续包装成系统,可以把清洗、统计、预测和展示拆成四个菜单:数据管理、统计分析、风险预测、可视化大屏。每个菜单只保留必要操作,后台统一读取 MySQL 数据表,模型部分提供单条预测和批量预测两种入口,整个项目就会更像一个完整应用。
每文一语
把一个项目真正跑通,比停留在想法里更有价值;数据会说话,前提是你先把链路搭起来。