刚上手 K8s 的时候,大部分人都在 default 命名空间里一通操作------部署、测试、删了重建。直到有一天,你发现:
- 开发环境和测试环境的 Pod 混在一起,删错了直接背锅
- 同事的 Deployment 跟你的同名,互相覆盖
- 几十个 Service、ConfigMap 堆在一个列表里,找半天找不到
这不是 K8s 的问题,是没用 Namespace 的问题。
Namespace 是 K8s 最基础也最容易被忽视的资源隔离手段。学完这篇,你能做到:多团队共用一套集群互不干扰、资源按组配额不打架、一键切换操作环境。
一、什么是 Namespace,为什么需要
一句话:Namespace = 集群内的虚拟分区。 它把一组资源(Pod、Service、ConfigMap 等)逻辑隔离,不同 Namespace 下的同名资源互不冲突。
┌─────────────────────────────────────────┐
│ K8s 集群 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ dev │ │ staging │ │ prod │ │
│ │ nginx:v2 │ │ nginx:v2 │ │ nginx:v1 │ │
│ │ java │ │ java │ │ java │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────┘核心特点:
- 同名资源在不同 Namespace 下可以共存(dev/nginx 和 prod/nginx 互不影响)
- 操作时指定 Namespace,不指定就走当前上下文(默认 default)
- Namespace 内的 DNS 自动隔离:
service-name.namespace.svc.cluster.local - 不提供网络隔离(那是 NetworkPolicy 的事),只提供逻辑分组
跨 Namespace 访问示例:
bash
# 同 Namespace:直接用服务名
curl http://nginx-service
# 跨 Namespace:必须带命名空间后缀
curl http://nginx-service.dev.svc.cluster.local二、基础操作:看、建、切
1. 查看 Namespace 和其中资源
bash
# 列出所有 Namespace 加上--show-labels显示标签信息
kubectl get ns
kubectl get namespace --show-labels
# 查看具体 Namespace 下的 Pod
kubectl get pods -n kube-system
# 查看所有 Namespace 下的所有 Pod
kubectl get pods --all-namespaces
# 或简写
kubectl get pods -A2. 创建和删除 Namespace
bash
# 命令行创建
kubectl create ns dev
# 用 YAML 创建(推荐,方便版本管理)
# dev-ns.yaml
apiVersion: v1
kind: Namespace
metadata:
name: dev
labels:
env: dev
kubectl apply -f dev-ns.yaml
# 删除(⚠️ 会删除该 Namespace 下所有资源)
kubectl delete ns dev3. 快速切换 Namespace
每次敲 -n xxx 很累,用 kubectl config set-context 一行搞定:
bash
#切换之后默认命名空间就是liux了
[root@master-1 ~]# kubectl config set-context --current --namespace liux
Context "kubernetes" modified.
[root@master-1 ~]# kubectl get pods
No resources found in liux namespace.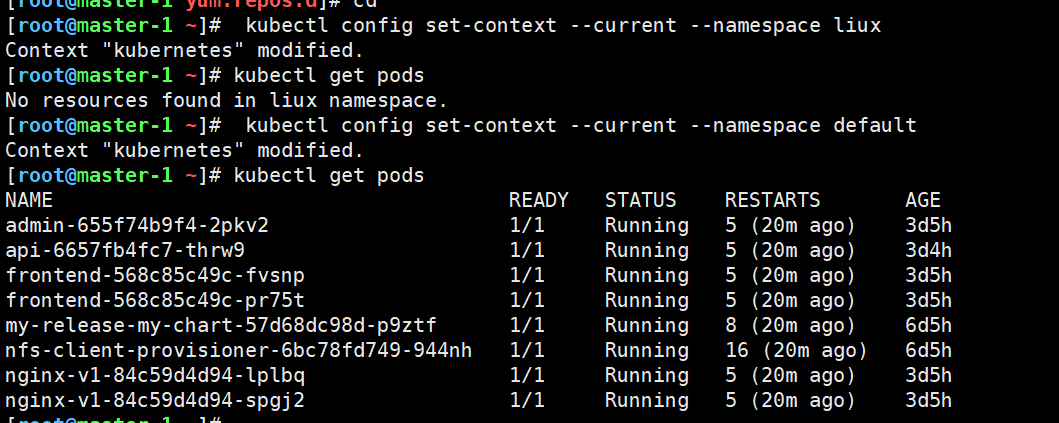
用别名也行:
alias kn='kubectl config set-context --current --namespace',然后kn dev即可。

三、集群自带 Namespace 大盘点
一套新集群默认就有这几个 Namespace,每个都有用:
sh
[root@master-1 ~]# kubectl get ns
NAME STATUS AGE
default Active 329d
kube-node-lease Active 329d
kube-public Active 329d
kube-system Active 329d| Namespace | 作用 | 你该动它吗 |
|---|---|---|
default |
不指定 Namespace 时的落脚点 | ✅ 别用,尽早切到自己的 ns |
kube-system |
K8s 核心组件(kube-dns、metrics-server、kube-proxy 等) | ❌ 别碰,删了集群就废了 |
kube-public |
公开可读的资源(如 cluster-info ConfigMap) | ⚠️ 只读,别往里放东西 |
kube-node-lease |
节点心跳 Lease 对象,用于节点故障检测 | ❌ 系统自用,硬删节点会失联 |
实操看一眼:
bash
# 核心组件都在这里
kubectl get pods -n kube-system
# 查看节点心跳
kubectl get lease -n kube-node-lease
kube-node-lease是 1.14 引入的,取代了原来的 NodeStatus 心跳机制。每个节点一个 Lease 对象,每 10 秒续约一次,比旧方案轻量得多。
四、资源配额:不让一个团队吃光集群
Namespace 只是逻辑分组,不做限制的话,dev 空间可以吃掉 100% 的集群资源。配 ResourceQuota 和 LimitRange 才能真正管控。
1. ResourceQuota ------ 设总上限
yaml
# dev-quota.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: dev-quota
namespace: dev
spec:
hard:
requests.cpu: "1" # 该 ns 下所有 Pod 请求 CPU 总和上限
requests.memory: "1Gi" # 请求内存总和上限
limits.cpu: "2"
limits.memory: "2Gi"
pods: "10" # 最多 10 个 Pod
services: "5" # 最多 5 个 Service
persistentvolumeclaims: "5" # 最多 5 个 PVC
bash
kubectl apply -f dev-quota.yaml
# 查看配额和使用情况
kubectl describe quota -n dev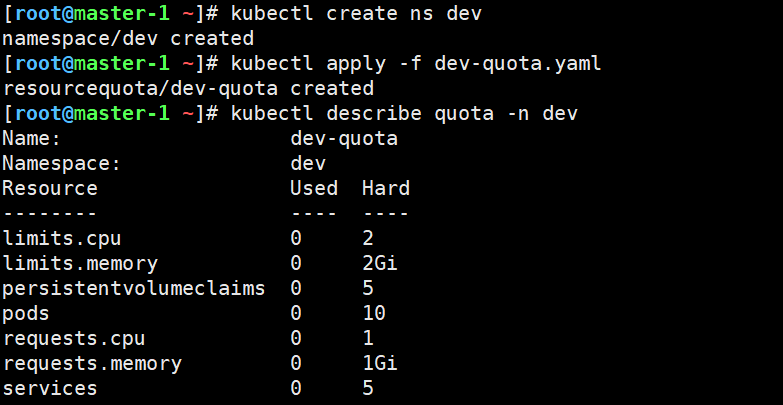
2. LimitRange ------ 设默认值和边界
没设 limits 的 Pod 等于"无限制"(BestEffort 优先级,随时可能被驱逐)。用 LimitRange 给该 ns 下的容器设默认值:
yaml
# dev-limits.yaml
# 定义 LimitRange 资源,用于在命名空间级别设置容器资源配额限制
apiVersion: v1
kind: LimitRange
metadata:
name: dev-limits # 资源名称
namespace: dev # 生效的命名空间(dev 环境)
spec:
limits:
- type: Container # 限制类型:Container(也可为 Pod、PVC 等)
# 默认资源限制(容器未单独声明 requests/limits 时使用)
default:
cpu: "250m" # 默认 CPU 限制:250 毫核(0.25 核)
memory: "512Mi" # 默认内存限制:512 MiB
# 默认资源请求(调度器据此分配节点资源)
defaultRequest:
cpu: "100m" # 默认 CPU 请求:100 毫核(0.1 核)
memory: "128Mi" # 默认内存请求:128 MiB
# 资源上限(容器可设置的最大值,超过则拒绝创建)
max:
cpu: "1" # 最大 CPU:1 核
memory: "2Gi" # 最大内存:2 GiB
# 资源下限(容器 requests/limits 不能低于此值)
min:
cpu: "50m" # 最小 CPU:50 毫核(0.05 核)
memory: "64Mi" # 最小内存:64 MiB
bash
kubectl apply -f dev-limits.yaml加上之后,dev 空间下新建的容器不写 limits,自动补 250m CPU + 512Mi 内存;设过头了(超过 max)直接拒绝创建。
验证 LimitRange 是否生效:
bash
# 创建一个不写 resources 的 Pod
kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: test-no-limits
namespace: dev
spec:
containers:
- name: busybox
image: busybox
command: ["sleep", "3600"]
EOF
# 查看实际生效的 requests/limits
kubectl describe pod test-no-limits -n dev
# 会看到:Limits: cpu=250m, memory=512Mi; Requests: cpu=100m, memory=128Mi
# 清理测试 Pod
kubectl delete pod test-no-limits -n dev| QoS 类 | requests/limits 情况 | 驱逐优先级 |
|---|---|---|
| Guaranteed | CPU 和内存的 requests == limits(且均设置) | 最低(最后被驱逐) |
| Burstable | 至少有一个容器设置了 requests 或 limits,但不满足 Guaranteed 条件 | 中等 |
| BestEffort | 没有任何 requests 或 limits | 最高(最先被驱逐) |
五、实战:划分 dev / staging / prod 三套环境
第一步:创建 Namespace
bash
#开发环境
kubectl create ns dev
# 预发环境
kubectl create ns staging
#生产环境
kubectl create ns prod第二步:贴标签,方便管理
bash
kubectl label ns dev env=dev
kubectl label ns staging env=staging
kubectl label ns production env=prod第三步:资源配额
yaml
# quota.yaml
#开发
apiVersion: v1
kind: ResourceQuota
metadata:
name: dev-quota
namespace: dev
spec:
hard:
requests.cpu: "1" # 该 ns 下所有 Pod 请求 CPU 总和上限
requests.memory: "1Gi" # 请求内存总和上限
limits.cpu: "2"
limits.memory: "2Gi"
pods: "10" # 最多 10 个 Pod
services: "5" # 最多 10 个 Service
persistentvolumeclaims: "5" # 最多 5 个 PVC
---
#生产
apiVersion: v1
kind: ResourceQuota
metadata:
name: prod-quota
namespace: prod
spec:
hard:
requests.cpu: "1"
requests.memory: "2Gi"
limits.cpu: "2"
limits.memory: "4Gi"
pods: "20"
#部署
kubectl apply -f quota.yaml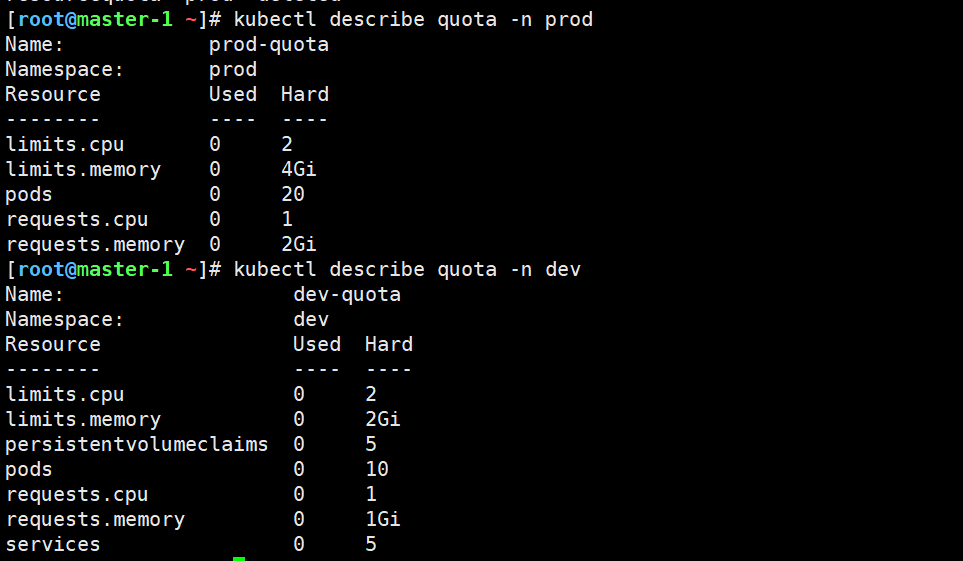
第四步:验证隔离效果
bash
# 在dev 下部署一个 nginx
kubectl create deployment nginx --image=nginx:1.22.1 -n dev
# 在 prod下部署同名 nginx
kubectl create deployment nginx --image=nginx:1.22.1 -n prod
# 两者互不影响
kubectl get deploy -n dev
kubectl get deploy -n prod
# 查看各 ns 的资源使用
kubectl describe quota -n dev
kubectl describe quota -n prod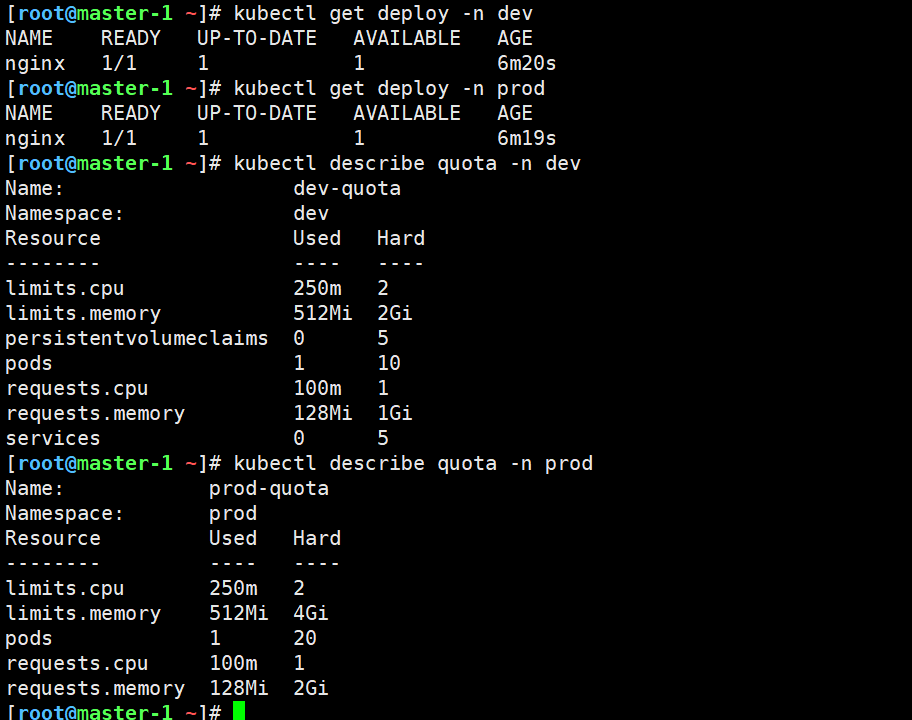
六、总结
Namespace 是 K8s 资源管理的第一道防线。 它不负责网络安全,但它是配额管理、权限控制(RBAC)、监控分组的基础。
落地清单:
- 不再使用
default命名空间,按环境/团队创建独立 Namespace - 给每个 Namespace 配 ResourceQuota(防资源抢占)+ LimitRange(防无限制 Pod)
- 切换默认命名空间,告别
-n重复输入 - 贴上标签(env / team / app),方便后续按标签筛选和管理
- 生产环境额外用 RBAC + NetworkPolicy 加固,Namespace 只是起点
资源配额设完只是开始。过两周看看
describe quota的实际使用率,按需调整------设太紧了团队卡脖子,设太松了等于没设。