GO语言------GMP调度模型
- 基础定义
- 设计哲学与演进
- 调度机制
-
- [工作窃取机制(Work Stealing,工作窃取):当一个P的本地队列为空时,它会怎么办?](#工作窃取机制(Work Stealing,工作窃取):当一个P的本地队列为空时,它会怎么办?)
- [利用 Hand Off(移交)机制处理阻塞:当一个G因系统调用被阻塞时,发生了什么?](#利用 Hand Off(移交)机制处理阻塞:当一个G因系统调用被阻塞时,发生了什么?)
- [基于信号的抢占式调度 (Preemptive Scheduling):Go的Goroutine是抢占式的吗?如果一个G死循环了,会怎样?](#基于信号的抢占式调度 (Preemptive Scheduling):Go的Goroutine是抢占式的吗?如果一个G死循环了,会怎样?)
- [全局队列(Global Queue):如何防止全局队列中的G被饿死?](#全局队列(Global Queue):如何防止全局队列中的G被饿死?)
- GMP为什么高效?
基础定义
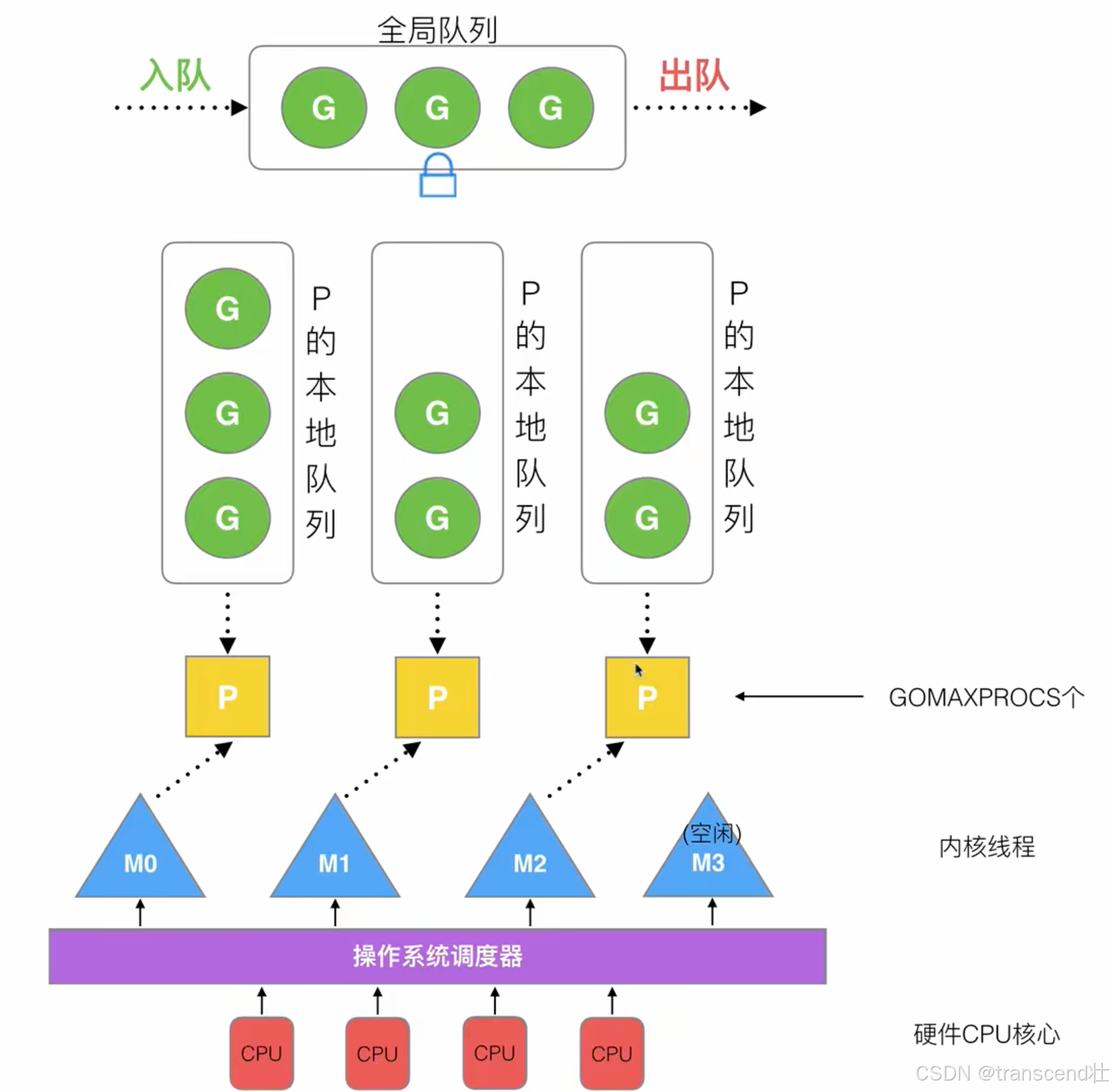
Go 语言的 GMP 模型是实现高并发、轻量级线程(Goroutine)的核心调度算法。
- G(Goroutine):用户态的轻量级协程,由用户态调度。栈内存非常小,初始仅需 2KB(可动态扩容),而操作系统的线程通常需要 1MB~8MB。
- M(Machine):操作系统线程,由操作系统内核管理和调度。M必须绑定一个P才能执行G。
M 消耗 CPU 来执行 G 的代码。M 本身不保存 G 的上下文,它只是一个干活的工具人。
- G 的执行上下文(栈、PC、寄存器等)保存在 G 自身 以及 G 的 gobuf 结构中。当 G 被挂起时,其上下文会被保存回 G 对象里。
- M 保存的是"当前正在执行的 G 的指针"(m.curg),以及和 P 的绑定关系。但这不是 G 的完整运行时上下文,只是指向 G 的引用。
- P(Processor):逻辑处理器,管理本地 Goroutine 队列,负责调度G到M上。每一个 P 都维护着一个本地的 G 队列(Local Queue),里面存放着等待运行的 G。M 必须先绑定一个 P,才能从 P 的本地队列中获取 G 并执行。P 的数量通常等同于 CPU 的核心数(可以通过 runtime.GOMAXPROCS() 设置)
P的数量默认等于 GOMAXPROCS,通常等于 CPU 逻辑核数,如 8 核 16 线程的 CPU 默认 GOMAXPROCS=16
GMP调度模型的最大优势就是通过少量 M 调度大量 G,避免线程频繁切换,从而减少上下文切换浪费的资源,把 CPU 时间专注在任务执行而非上下文切换上。
- GOMAXPROCS的作用是什么?
用于设置P的最大数量,通常设置为CPU核心数。P的数量就是程序的最大并行度。设置过大只会增加调度开销,不会提高性能。
- 如何限制M的数量?
由Go运行时动态调整,默认最大限制是10000。理论上M的数量可以很多,但受操作系统限制。
- 一个Go程序最多能创建多少个Goroutine?
可以创建成千上万个,但绝非"无限"。每个G至少消耗2KB栈内存,过多创建会导致内存耗尽或调度开销过大,项目实践中常使用协程池(如ants库)来控制并发数。
- g0和m0是什么?
- m0:是Go程序启动时的主线程,是Go程序启动时由操作系统创建的第一个系统线程,是所有M的祖宗。它负责初始化Go运行时的环境,比如内存、P的创建,以及最终运行用户的main函数。
- g0:代表特殊的 Goroutine,每个M(包括m0)都拥有一个属于自己的g0。g0不执行用户代码,而是关注执行调度逻辑(比如找到下一个要执行的G并切换过去)、垃圾回收(GC)、栈扩容等运行时管理任务。
- 实际开发中,如何通过理解GMP进行性能调优?
- 减少系统调用:频繁的系统调用会导致Hand Off,增加M的创建和销毁开销。可以用缓冲池等技术优化。
- 控制P数量:在容器环境(如Docker)中,GOMAXPROCS默认读取的是宿主机的CPU数,而不是容器的限制。这会导致P数量过多,竞争激烈。推荐使用automaxprocs库自动设置。
- 避免G阻塞:减少锁的使用,多用Channel。
m0
- 身份:Go程序的第一个M(Machine),对应操作系统的主线程(main thread),m0是所有M的始祖。
- 生命周期:从程序启动到结束,m0 永远存在,不会被销毁。
- 核心职责:
- 启动程序:执行C语言编写的_rt0_amd64汇编入口,然后过渡到Go的runtime·rt0_go函数。
- 初始化内存:创建最初的堆、栈、分配器。
- 创建第一个P:设置GOMAXPROCS个P,并初始化allp。
- 创建 g0:为自己的执行准备g0。
- 运行 main 函数:最终通过调度,执行用户代码中的main.main()。
注意:除了m0,其他所有M(如m1, m2...)都是Go运行时在需要时(如系统调用阻塞后通过Hand Off机制)动态创建的。
g0
- 身份:每个M都有的一个特殊Goroutine,不由用户创建,也不在用户代码的调用栈上。
- 栈特点:g0 拥有大栈(至少64KB,根据不同平台和Go版本有差异,远大于普通G的初始2KB栈),这是为了保证调度和GC这类关键任务永远有足够的栈空间,不会发生栈溢出。
- 核心职责:
- 执行调度循环:schedule() 函数就运行在g0上。当一个普通G(g)让出CPU时,M会切换到g0,由g0去决定下一个运行哪个G。
- 执行GC工作:垃圾回收的标记、清扫等大部分STW(Stop The World)和并发阶段的工作,都由g0(或专门的gc worker,但其底层也依赖g0的机制)执行。
- 栈扩容:当一个普通G的栈空间不足时,会触发栈复制操作,这个操作也是在g0上完成的,因为需要分配新的栈内存并拷贝数据,不适合在G自身的栈上进行。
- 执行系统调用包装:一些底层的、需要特殊处理的操作会通过g0来执行。
g0 的关键作用:调度切换
这是理解g0最核心的一点。一个G让出CPU后,到另一个G被执行的完整过程是:
- 当前普通G(gA)主动让出(如Channel操作)或被抢占。
- gA 调用mcall(),这个函数会保存gA的当前执行现场(PC、SP等),并将M的当前Goroutine从gA切换到g0。
- 现在M运行在g0的栈上,g0调用schedule()函数,从P的队列中选择下一个要执行的G(gB)。
- g0 调用execute(),然后调用gogo(),从g0切换回gB,恢复gB的现场,开始执行gB。
如果没有g0,调度器将没有自己干净、安全的执行环境,很容易导致栈混乱或递归问题。
设计哲学与演进
为什么GMP模型比之前的GM模型好?P的作用是什么?(既然有了M,为什么还要引入P?)
- 回顾GM模型(Go 1.1之前):
- 架构:只有一个全局运行队列,所有M都从该队列中获取G。
- 痛点:所有操作(入队、出队)都需要一个全局锁。当M数量增多,锁竞争会非常激烈,导致严重的性能瓶颈。
在早期的 Go 版本中,调度器只有一个全局的 Goroutine 队列,多核 CPU 下并发调度需要频繁加锁,导致性能很差。为了解决这个问题,Go 从 1.1 版本开始引入了 GMP 模型。
- 引入P的优化(GMP模型):
- 减少锁竞争:每个P都有自己的本地队列,绝大多数G的入队和出队操作都只需访问本地队列,无需加锁。
- 提高数据局部性:P的本地队列可以保证刚创建的G优先被同一个M执行,利用CPU缓存,性能更好。
- 解耦资源与线程:
- M的数量会因系统调用阻塞而动态增减,如果把队列绑在M上,队列的维护会非常复杂。
- P是独立的,数量固定(默认等于CPU核心数)。当M阻塞时,它可以将P"移交"给另一个空闲的M,保证了即使在系统调用发生时,P也能继续调度其他G,最大化CPU利用率。
调度机制
工作窃取机制(Work Stealing,工作窃取):当一个P的本地队列为空时,它会怎么办?
- 当一个P的本地队列空了,它不会干等着。
- 它会先去全局队列里找G。
- 如果全局队列也是空的,它就会随机从其他P的本地队列中"偷"一半的G放到自己的队列中。
- 这确保了所有的M都"有活干",实现了CPU的最大化利用。
利用 Hand Off(移交)机制处理阻塞:当一个G因系统调用被阻塞时,发生了什么?
- M与P解绑:阻塞的M会主动交还它绑定的P。
- P被接管:这时会唤醒一个休眠的M(从休眠线程池中唤醒一个M)或创建一个新的M,然后P和这个M进行绑定
- 其他G继续运行:新M利用这个P,继续执行P本地队列中剩余的其他G。
- 阻塞的M和G的恢复:当原本阻塞的M恢复后,它会带着之前阻塞的G一起,尝试"重新上岗"。原本阻塞的M会优先尝试找一个空闲的P,然后和这个P进行绑定,并继续运行原先在自己身上的G。如果找不到空闲的P,M会把G放入全局队列中,然后自己进入休眠状态。
基于信号的抢占式调度 (Preemptive Scheduling):Go的Goroutine是抢占式的吗?如果一个G死循环了,会怎样?
在早期的 Go 中,如果一个 G 在执行死循环(例如 for {}),它会一直独占 M,导致其他 G 被饿死。
抢占式调度:Go从1.14版本开始,实现了基于信号的抢占式调度。如果一个G运行时间过长(超过10ms),会触发调度,强制它让出P,给其他G执行的机会。这解决了早期版本中一个死循环G会"卡死"整个进程的问题。
全局队列(Global Queue):如何防止全局队列中的G被饿死?
- 公平性保障:调度器会保证公平性,P每调度61次,就会优先从全局队列中获取一个G来执行,防止新G源源不断地在本地队列中产生,导致全局队列的G被"饿死"。
全局队列作为兜底方案,用来存放:
- 从系统调用中恢复、但找不到 P 的 G。
- 因为抢占式调度被踢下来的 G。
- 当 P 的本地队列已满(256个)且要创建新 G 时:会取出本地队列的一半(128个)G,连同新 G 一起放入全局队列,而不是单独拿一半出去。
GMP为什么高效?
Go 的 GMP 模型之所以高效,核心在于它解决了传统线程模型中的三大痛点:内存开销大、调度效率低、并发能力受限。
- 轻量的用户态线程:G 是 Goroutine,一个普通栈起始只有 2KB(可伸缩),而操作系统线程(M)的栈通常固定为 1~8MB。
高效的调度机制: - 工作窃取(Work Stealing)解决资源竞争
- 利用 Hand Off(移交)机制处理阻塞
- "自旋线程"降低调度延迟
为了防止频繁的线程休眠和唤醒产生过高的系统开销,M会进入自旋状态:
- 当 P 空闲时,与其绑定的 M 并不会立刻休眠,而是会进行短暂的"自旋" (spinning)。它会在短时间内疯狂检查有没有新来的 G,试图在进入内核态休眠之前就把活干了。
- 效果:极大地降低了毫秒级甚至微秒级的调度延迟。