决策树
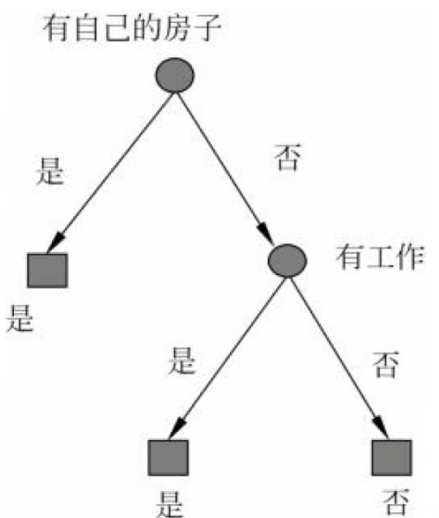
一.树的定义
-
最顶端的叫根节点,所有样本的预测都是从根节点开始。
-
每一个圆形节点表示判断,每个节点只对样本的某个属性进行判断。
-
矩形节点是标记节点,走到矩形节点表示判断结束,将矩形节点中的标签作为对应的预测结果。
中间节点用于分割数据;叶子节点用于标签预测
二.信息熵
1. 决策树模型怎么玩
-
决策树的预测阶段,每进来一个样本,根据判断节点实际情况,对对应的特征进行判断,直到走到标记节点。
-
如何构建决策树
- 按顺序对每一个特征进行判断(低效)
- 每个判断节点都尽可能让一半进入A分支,另一半进入B分支(高效)
2. 信息熵定义
(1).熵的定义
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量,设X是一个取有限个值的离散随机变量,其概率分布为
P(X=xi)=pi,i=1,2,...,nP(X = x_i) = p_i, \quad i = 1, 2, ..., nP(X=xi)=pi,i=1,2,...,n
则随机变量X的熵定义为
H(X)=−∑i=1npilogpiH(X) = - \sum_{i=1}^{n} p_i \log p_iH(X)=−i=1∑npilogpi
熵越大,则随机变量的不确定性越大。其中0≤H(P)≤logn0 \le H(P) \le \log n0≤H(P)≤logn
注:均匀分布的时候熵最大。
(2).熵的类别
经验熵,经验条件熵,特征熵
- H(D)H(D)H(D)(经验熵): 看的是"标签(好苹果/坏苹果)"的分布。只跟目标类别有关。
- H(D∣A)H(D|A)H(D∣A)(经验条件熵): 看的是"按照特征分开后,各分支里标签(好苹果/坏苹果)"的分布。
- HA(D)H_A(D)HA(D)(特征熵): 完全不管标签!只看"特征 AAA 自身取值(比如红/绿)"的分布。
习题:
我们有10个苹果,1个好苹果A,9个坏苹果B。熵的计算如下:
H(P)=−∑i=1npilogpi=−P(A)logP(A)+P(B)logP(B)H(P) = -\sum_{i=1}^{n} p_i \log p_i = -P(A) \\log P(A) + P(B) \\log P(B)H(P)=−i=1∑npilogpi=−P(A)logP(A)+P(B)logP(B)
=−110log110+910log910=0.47= -\\frac{1}{10} \\log \\frac{1}{10} + \\frac{9}{10} \\log \\frac{9}{10} = 0.47=−101log101+109log109=0.47
1个坏苹果9个好苹果时,我们可以认为大部分都是坏苹果。内部并不混乱,确定性很大,熵就小。
如果5个好苹果5个坏苹果呢?
H(P)=−∑i=1npilogpi=−P(A)logP(A)+P(B)logP(B)H(P) = -\sum_{i=1}^{n} p_i \log p_i = -P(A) \\log P(A) + P(B) \\log P(B)H(P)=−i=1∑npilogpi=−P(A)logP(A)+P(B)logP(B)
=−510log510+510log510=1= -\\frac{5}{10} \\log \\frac{5}{10} + \\frac{5}{10} \\log \\frac{5}{10} = 1=−105log105+105log105=1
5个坏苹果5个好苹果时,里面就有点乱了,我们并不太能确定随机的一个苹果是好苹果还是坏苹果,熵就大。
3.信息增益定义
(1).定义
信息增益:表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
(2).公式
特征A对训练集D的信息增益g(D,A)g(D, A)g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即
g(D,A)=H(D)−H(D∣A)g(D, A) = H(D) - H(D|A)g(D,A)=H(D)−H(D∣A)
(3).算法
输入:训练数据集 DDD 和特征 AAA
输出:特征 AAA 对训练数据集 DDD 的信息增益 g(D,A)g(D,A)g(D,A)
-
计算数据集 DDD 的经验熵 H(D)H(D)H(D)
H(D)=−∑k=1K∣Ck∣∣D∣log∣Ck∣∣D∣H(D) = -\sum_{k=1}^{K} \frac{|C_k|}{|D|} \log \frac{|C_k|}{|D|}H(D)=−k=1∑K∣D∣∣Ck∣log∣D∣∣Ck∣
- DDD:当前的训练数据集。
- ∣D∣|D|∣D∣ :数据集 DDD 中的总样本个数。
- KKK :目标变量(标签)的类别总数 。例如,要预测苹果是"好"还是"坏",类别只有两类,则 K=2K=2K=2。
- CkC_kCk :数据集中属于第 kkk 个类别的样本构成的子集。
- ∣Ck∣|C_k|∣Ck∣ :属于第 kkk 个类别的样本个数 。显然有 ∑k=1K∣Ck∣=∣D∣\sum_{k=1}^{K} |C_k| = |D|∑k=1K∣Ck∣=∣D∣。
- ∣Ck∣∣D∣\frac{|C_k|}{|D|}∣D∣∣Ck∣ :第 kkk 个类别在总体数据中出现的概率(比例)。
-
计算特征 AAA 对数据集 DDD 的经验条件熵 H(D∣A)H(D|A)H(D∣A)
H(D∣A)=−∑i=1n∣Di∣∣D∣H(Di)H(D|A) = -\sum_{i=1}^{n} \frac{|D_i|}{|D|} H(D_i)H(D∣A)=−i=1∑n∣D∣∣Di∣H(Di)
=−∑i=1n∣Di∣∣D∣∑k=1K∣Dik∣∣Di∣log∣Dik∣∣Di∣= -\sum_{i=1}^{n} \frac{|D_i|}{|D|} \sum_{k=1}^{K} \frac{|D_{ik}|}{|D_i|} \log \frac{|D_{ik}|}{|D_i|}=−i=1∑n∣D∣∣Di∣k=1∑K∣Di∣∣Dik∣log∣Di∣∣Dik∣
-
AAA :当前正在用来做划分的特征(例如"颜色")。
-
nnn :特征 AAA 包含的不同取值个数 。例如,颜色有"红色"和"绿色"两种,则 n=2n=2n=2。
-
DiD_iDi :根据特征 AAA 的取值,将总体 DDD 划分出的第 iii 个样本子集 。例如,所有"红色"苹果组成的集合就是 D1D_1D1。
-
∣Di∣|D_i|∣Di∣ :子集 DiD_iDi 的样本个数。
-
∣Di∣∣D∣\frac{|D_i|}{|D|}∣D∣∣Di∣ :第 iii 个子集的样本数占总体样本数的比例,即这个分支的权重。样本越多的分支,在计算总体条件熵时的权重越大。
-
H(Di)H(D_i)H(Di) :子集 DiD_iDi 自身的经验熵(即计算单独这一个分支里,数据有多混乱)。
-
DikD_{ik}Dik :这是在子集 DiD_iDi 中,同时属于类别 CkC_kCk 的样本集合。即被特征A划分到第 iii 个分支后,标签又是第 kkk 类的样本"。
-
∣Dik∣|D_{ik}|∣Dik∣ :子集 DikD_{ik}Dik 的样本个数。
-
∣Dik∣∣Di∣\frac{|D_{ik}|}{|D_i|}∣Di∣∣Dik∣ :在第 iii 个分支(子集)中,第 kkk 类标签所占的比例(概率)。
-
-
计算信息增益
g(D,A)=H(D)−H(D∣A)g(D, A) = H(D) - H(D|A)g(D,A)=H(D)−H(D∣A)
- H(D)H(D)H(D) :划分前的经验熵(表示最初的混乱程度/不确定性)。
- H(D∣A)H(D|A)H(D∣A) :按照特征 AAA 划分后的经验条件熵 (表示已知特征 AAA 后的混乱程度)。
- g(D,A)g(D, A)g(D,A) :特征 AAA 带来的信息增益 。值越大,说明特征 AAA 消除不确定性的能力越强,用它来做树的节点越合适。
(4).结合"挑苹果"实例理解
- 在根节点的最初,我们先假设信息熵为最大,表示我们对于这个苹果一无所知。
- 到叶节点时假设信息熵为0,表示我们非常确定。
- 我们希望尽可能少的次数就能判断出苹果的好坏。也就是希望每个判断节点都能让信息熵下降地快一点。
- 怎么度量下降得快不快呢? ------信息增益
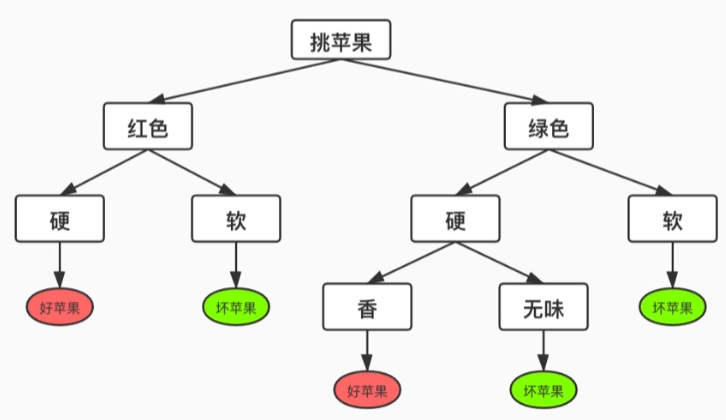
以图中按"颜色" (特征 A) 挑选苹果的决策树为例:
初始状态 H(D)H(D)H(D):一无所知时的不确定性
在最顶层的根节点,面对的是全部 10 个苹果(5 个好,5 个坏)。此时我们完全不知道随便拿出一个是好是坏,不确定性达到峰值。
H(P)=−∑i=1npilogpi=−P(A)logP(A)+P(B)logP(B)H(P) = -\sum_{i=1}^{n} p_i \log p_i = -P(A) \\log P(A) + P(B) \\log P(B)H(P)=−i=1∑npilogpi=−P(A)logP(A)+P(B)logP(B)
=−510log510+510log510=1= -\\frac{5}{10} \\log \\frac{5}{10} + \\frac{5}{10} \\log \\frac{5}{10} = 1=−105log105+105log105=1
此时的经验熵为:H(D)=1H(D) = 1H(D)=1。
引入特征 A 后的状态 H(D∣A)H(D|A)H(D∣A):知道"颜色"后的不确定性
现在,得知了苹果的"颜色"特征,并将 10 个苹果分成了两拨:
- 左侧红色分支 (D1D_1D1): 分配到了4个苹果。包含1个好苹果,3个坏苹果 。这4个红苹果内部依然存在不确定性,记作 H(D1)H(D_1)H(D1)。
- **右侧绿色分支 (D2D_2D2)😗*分配到了6个苹果。包含 4个好苹果,2个坏苹果 。这 6个绿苹果内部的不确定性记作 H(D2)H(D_2)H(D2)。
此时,整体的经验条件熵 H(D∣A)H(D|A)H(D∣A),就是按颜色分开后,这两个分支不确定性的加权平均(数量越多的分支,在总体里的权重越大):
H(D∣A)=410H(D1)+610H(D2)H(D|A) = \frac{4}{10} H(D_1) + \frac{6}{10} H(D_2)H(D∣A)=104H(D1)+106H(D2)
信息增益 g(D,A)g(D, A)g(D,A)就是不确定性下降了多少。将最初的混乱程度 H(D)H(D)H(D),减去按照颜色分拨之后的总混乱程度 H(D∣A)H(D|A)H(D∣A),得到的差值就是信息增益:
g(D,A)=H(D)−H(D∣A)g(D, A) = H(D) - H(D|A)g(D,A)=H(D)−H(D∣A)
总结:一开始面对一筐苹果,你完全猜不透好坏(此时 H(D)H(D)H(D) 最大,最懵)。
现在你引入了"颜色"这个特征,把苹果按红绿分开。分开后你发现规律了:红苹果里坏的概率很大(3/4),绿苹果里好的概率很大(4/6)。你心里对苹果好坏的判断突然清晰了不少,整体的"懵圈程度"下降了(H(D∣A)H(D|A)H(D∣A) 变小了)。
原先的懵圈程度,减去现在的懵圈程度,这个下降的幅度,就是"颜色"这个特征给你带来的"信息增益"。 信息增益越大,说明按"颜色"来挑选苹果这个决策越明智!
4.信息增益比定义
(1).作用
如果以信息增益为划分依据,存在偏向选择取值较多的特征,信息增益比是对这一问题进行矫正。
(2).公式
信息增益比:特征 AAA 对训练数据集 DDD 的信息增益比 gR(D,A)g_R(D, A)gR(D,A) 定义为其信息增益 g(D,A)g(D, A)g(D,A) 与训练数据集 DDD 关于特征 AAA 的值熵 HA(D)H_A(D)HA(D) 之比:
gR(D,A)=g(D,A)HA(D)g_R(D, A) = \frac{g(D, A)}{H_A(D)}gR(D,A)=HA(D)g(D,A)
其中,分母 HA(D)H_A(D)HA(D) 的计算公式为:
HA(D)=−∑i=1n∣Di∣∣D∣log2∣Di∣∣D∣H_A(D) = -\sum_{i=1}^{n} \frac{|D_i|}{|D|} \log_2 \frac{|D_i|}{|D|}HA(D)=−i=1∑n∣D∣∣Di∣log2∣D∣∣Di∣
(3).原理
为什么它能矫正"偏向取值较多的特征"?
假设我们有一个特征叫"苹果编号"(1号到10号)。
- 如果用这个特征来划分,每个分支只有 1 个苹果。此时条件熵 H(D∣A)=0H(D|A) = 0H(D∣A)=0(因为每个分支里就一个苹果,好坏是100%确定的)。
- 这会导致信息增益 g(D,A)g(D, A)g(D,A) 达到最大值!决策树会误以为"编号"是一个超级好的特征。但显然"编号"对泛化毫无用处。
为了惩罚这种"把数据切得太碎"的特征,我们引入了分母 HA(D)H_A(D)HA(D):
- 当一个特征取值非常多时,数据被切分得很散,此时算出来的特征自身的信息熵 HA(D)H_A(D)HA(D) 就会非常大。
- 在公式 gR=gHA(D)g_R = \frac{g}{H_A(D)}gR=HA(D)g 中,除以一个很大的数,就把原来虚高的信息增益给"压下来"了,起到了惩罚作用。
比如银行信贷用身份证划分这个例子
三.决策树的生成
1. ID3
输入:训练数据集 DDD,特征 AAA,阈值 ε\varepsilonε;
输出:决策树 TTT
- 若 DDD 中所有实例属于同一类 CkC_kCk,则 TTT 为单结点树,并将类 CkC_kCk 作为该结点的类标记,返回 TTT;
- 若 A=∅A = \emptysetA=∅,则 TTT 为单结点树,并将 DDD 中实例数最大的类 CkC_kCk 作为该结点的类标记,返回 TTT;
- 否则,计算 AAA 中各特征对 DDD 的信息增益,选择信息增益最大的特征 AgA_gAg;
- 如果 AgA_gAg 的信息增益小于阈值 ε\varepsilonε,则置 TTT 为单结点树,并将 DDD 中实例数最大的类 CkC_kCk 作为该结点的类标记,返回 TTT;
- 否则,对 AgA_gAg 的每一个可能值 aia_iai,依 Ag=aiA_g = a_iAg=ai 将 DDD 分割为若干非空子集 DiD_iDi,将 DiD_iDi 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树 TTT,返回 TTT;
- 对第 iii 个子结点,以 DiD_iDi 为训练集,以 A−{Ag}A - \{A_g\}A−{Ag} 为特征集,递归地调用步(1)~步(5),得到子树 TiT_iTi,返回 TiT_iTi。
2. C4.5
就是把ID3的信息增益换成了信息增益比
输入:训练数据集 DDD,特征 AAA,阈值 ε\varepsilonε;
输出:决策树 TTT
- 若 DDD 中所有实例属于同一类 CkC_kCk,则 TTT 为单结点树,并将类 CkC_kCk 作为该结点的类,返回 TTT;
- 若 A=∅A = \emptysetA=∅,则 TTT 为单结点树,并将 DDD 中实例数最大的类 CkC_kCk 作为该结点的类,返回 TTT;
- 否则,计算 AAA 中各特征对 DDD 的信息增益比,选择信息增益比最大的特征 AgA_gAg;
- 如果 AgA_gAg 的信息增益小于阈值 ε\varepsilonε,则置 TTT 为单结点树,并将 DDD 中实例数最大的类 CkC_kCk 作为该结点的类标记,返回 TTT;
- 否则,对 AgA_gAg 的每一个可能值 aia_iai,依 Ag=aiA_g = a_iAg=ai 将 DDD 分割为若干非空子集 DiD_iDi,将 DiD_iDi 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树 TTT,返回 TTT;
- 对结点 iii,以 DiD_iDi 为训练集,以 A−{Ag}A - \{A_g\}A−{Ag} 为特征集,递归地调用步(1)~步(5),得到子树 TiT_iTi,返回 TiT_iTi。
3. CART 算法(分类树部分)
核心思想:把 ID3/C4.5 的信息熵换成了"基尼指数(Gini Index)",并且 CART 默认生成的是二叉树。注:在 CART 算法中,用过的特征可以再用!
(1). 基尼指数定义
基尼指数: 在分类问题中,假设有 KKK 个类,样本点属于第 kkk 类的概率为 pkp_kpk,则概率分布的基尼指数定义为:
Gini(p)=∑k=1Kpk(1−pk)=1−∑k=1Kpk2Gini(p) = \sum_{k=1}^{K} p_k (1 - p_k) = 1 - \sum_{k=1}^{K} p_k^2Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
直观理解: 基尼指数表示在样本集合中一个随机选中的样本被分错的概率。
结论:基尼指数越小,数据集越纯(与信息熵的性质一致)。
(2). 数据集DDD的基尼指数
对于给定的样本集合 DDD,其基尼指数为:
Gini(D)=1−∑k=1K(∣Ck∣∣D∣)2Gini(D) = 1 - \sum_{k=1}^{K} \left( \frac{|C_k|}{|D|} \right)^2Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
(其中 CkC_kCk 是 DDD 中属于第 kkk 类的样本子集)
(3). 给定特征 AAA 的基尼指数 (Gini_index)
如果我们在特征AAA的条件下,将数据集DDD进行划分(以二分法为例,划分为 D1D_1D1 和 D2D_2D2),则在特征 AAA 的条件下,集合 DDD 的基尼指数定义为:
Gini_index(D,A)=∣D1∣∣D∣Gini(D1)+∣D2∣∣D∣Gini(D2)=∑P(A=a)⋅Gini(D∣A=a)Gini\_index(D, A) = \frac{|D_1|}{|D|} Gini(D_1) + \frac{|D_2|}{|D|} Gini(D_2) = \sum P(A=a) \cdot Gini(D|A=a)Gini_index(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)=∑P(A=a)⋅Gini(D∣A=a)
(4). 算法生成逻辑
- 递归的过程: 与 ID3/C4.5 类似,从根节点开始递归建树。
- 最优属性选择: 在所有可能的特征 AAA 以及它们所有可能的切分点中,选择使得划分后基尼指数 Gini_index(D,A)Gini\_index(D, A)Gini_index(D,A) 最小的特征及其切分点作为最优划分属性。
输入:训练数据集 DDD,停止计算的条件(如基尼指数阈值 ε\varepsilonε 或结点中样本个数下限);
输出:CART 决策树 TTT
- 若 DDD 中所有实例属于同一类 CkC_kCk,则 TTT 为单结点树,并将类 CkC_kCk 作为该结点的类,返回 TTT;
- 若特征集为空,或者DDD中所有样本在所有特征上取值相同,则TTT为单结点树,并将DDD中实例数最大的类CkC_kCk作为该结点的类,返回 TTT;
- 否则,遍历所有可能的特征 AAA 以及它们所有可能的切分点 aaa。对每一个特征AAA及其每一个切分点aaa,依特征AAA的取值是否等于aaa(即 A=aA = aA=a 或 A≠aA \neq aA=a),将数据集 DDD 划分为 D1D_1D1 和 D2D_2D2 两部分,并计算划分后的基尼指数 Gini_index(D,A)Gini\_index(D, A)Gini_index(D,A); (注:如果是连续特征,则按 A≤aA \le aA≤a 和 A>aA > aA>a 划分)
- 在所有的特征 AAA 及其所有切分点 aaa 中,选择基尼指数最小的特征及其切分点,分别记为最优划分特征 AgA_gAg 和最优切分点 aga_gag;
- 如果最优划分的基尼指数小于阈值 ε\varepsilonε(或者该结点的样本数小于设定阈值),则置 TTT 为单结点树,并将 DDD 中实例数最大的类 CkC_kCk 作为该结点的类标记,返回 TTT;
- 否则,依最优特征 AgA_gAg 和最优切分点 aga_gag,将 DDD 分割为两个子集 D1D_1D1 和 D2D_2D2。构建两个子结点,由结点及其子结点构成树 TTT;
- 对左右两个子结点,分别以 D1D_1D1 和 D2D_2D2 为训练集,保留所有候选特征,递归地调用步(1)~步(6),得到左子树 T1T_1T1 和右子树 T2T_2T2,返回 T1T_1T1 和 T2T_2T2。
四. 决策树的剪枝与过拟合
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据分类却没有那么准确,即容易出现过拟合现象。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化,这个过程称为剪枝(Pruning)。
1. 构建决策树的损失函数(纯经验损失)
如果不考虑树的复杂度,决策树在训练集上的损失函数定义为所有叶子节点的"不纯度"的加权和:
C(T)=∑t=1∣T∣N(t)⋅H(t)C(T) = \sum_{t=1}^{|T|} N(t) \cdot H(t)C(T)=t=1∑∣T∣N(t)⋅H(t)
- ∣T∣|T|∣T∣:表示决策树的叶子结点个数。
- ttt:表示树的某一个具体的叶子结点。
- N(t)N(t)N(t):是该叶子结点 ttt 内包含的样本个数。
- H(t)H(t)H(t):是该叶子结点 ttt 的不纯度度量 (Impurity)。
- 注意:H(t)H(t)H(t) 是一个广义符号。在 ID3/C4.5 中,它是经验熵;在 CART 分类树中,它是基尼指数 Gini(t)Gini(t)Gini(t)。
注:如果训练目标仅仅是 minTC(T)\min_T C(T)minTC(T),模型会倾向于把每个叶子节点分到只有 1 个样本(此时无论算熵还是算基尼指数,H(t)H(t)H(t) 都等于 0,C(T)=0C(T)=0C(T)=0),从而导致严重的过拟合。
2. 决策树的正则化函数 (结构风险最小化)
为了防止过拟合,我们需要在损失函数中加入表示"树复杂度"的正则化惩罚项:
C(T)=∑t=1∣T∣N(t)⋅H(t)+λ⋅∣T∣C(T) = \sum_{t=1}^{|T|} N(t) \cdot H(t) + \lambda \cdot |T|C(T)=t=1∑∣T∣N(t)⋅H(t)+λ⋅∣T∣
其中:
- λ\lambdaλ :表示正则化超参数 (常写作 α\alphaα 或 λ\lambdaλ),用于控制惩罚力度,λ≥0\lambda \ge 0λ≥0。
- ∣T∣|T|∣T∣ :表示叶子结点个数 ,代表了树的整体复杂度。树越庞大,∣T∣|T|∣T∣ 越大。
核心机制与结论:
正则化函数本质上是在"模型对训练数据的拟合程度"与"模型的复杂度"之间进行权衡。
- 当 λ→+∞\lambda \to +\inftyλ→+∞ 时: 惩罚极其严厉。此时为了让损失函数最小,只能拼命压缩叶子节点的数量,树最终只保留根节点(变成单节点树)。
- 当 λ→0\lambda \to 0λ→0 时: 几乎没有惩罚。退化为只考虑经验损失,树会尽可能拟合数据集(容易过拟合)。
- 剪枝策略: 从整棵树开始,尝试剪掉某些子树。如果剪掉某棵子树后,整体的正则化损失函数 C(T)C(T)C(T) 变小了,那就说明剪裁是划算的,坚决剪掉!
五. 连续值属性的处理
现实任务中常会遇到连续属性(如温度、密度、收入等),决策树处理连续值的最经典策略是采用二分法(Bi-partition)。此方法在 C4.5 和 CART 算法中被广泛使用。
1. 连续值的离散化(寻找切分点)
给定样本集 DDD 和连续属性 AAA:
- 排序: 首先将属性 AAA 在 DDD 上出现的所有不同连续取值,按从小到大的顺序进行排列,记为 {a1,a2,...,an}\{a_1, a_2, \dots, a_n\}{a1,a2,...,an}。
- 取中点(生成候选阈值): 基于划分点 ttt 可将样本集 DDD 分为 Dt−D_t^-Dt−(取值 ≤t\le t≤t)和 Dt+D_t^+Dt+(取值 >t> t>t)两个子集。显然,对于相邻的属性取值 aia_iai 和 ai+1a_{i+1}ai+1 来说,在区间 [ai,ai+1)[a_i, a_{i+1})[ai,ai+1) 中任意取值所产生的划分结果是相同的。
因此,通常取相邻属性值的中点 作为候选划分点,候选划分点集合 TAT_ATA 定义为:
TA={ai+ai+12∣i=1,2,...,n−1}T_A = \left\{ \frac{a_i + a_{i+1}}{2} \mid i = 1, 2, \dots, n-1 \right\}TA={2ai+ai+1∣i=1,2,...,n−1}
(注:在工程优化中,为了减少计算量,通常只取目标标签发生改变的相邻值的中点作为候选切分点。)
2. 计算信息增益选定最优阈值
把每一个候选划分点 ttt 都看作是一个布尔属性(即取值为"≤t\le t≤t"和">t> t>t"两类):
像考察离散属性一样,遍历集合 TAT_ATA 中的每一个候选点,计算对应的信息增益(或基尼指数),选择使得纯度提升最大的点作为该连续属性的最优切分点。
信息增益计算公式变为:
g(D,A)=maxt∈TA(H(D)−(∣Dt−∣∣D∣H(Dt−)+∣Dt+∣∣D∣H(Dt+)))g(D, A) = \max_{t \in T_A} \left( H(D) - \left( \frac{|D_t^-|}{|D|} H(D_t^-) + \frac{|D_t^+|}{|D|} H(D_t^+) \right) \right)g(D,A)=t∈TAmax(H(D)−(∣D∣∣Dt−∣H(Dt−)+∣D∣∣Dt+∣H(Dt+)))
3. 核心特权:连续属性可重复使用
- 离散属性的消耗性: 在多叉树(如 ID3/C4.5)中,离散属性(如"颜色")用作划分节点后,在其后代节点中将不再可用。
- 连续属性的复用性: 与离散属性不同,一连续属性仍可以作为其后代结点的划分属性。
- 直观理解: 在父节点按"温度 ≤60\le 60≤60"切分后,在左子树中,依然可以针对剩下的样本继续按"温度 ≤45\le 45≤45"进行更细粒度的二次切分。
六. 缺失值的处理
在现实任务中,常会遇到不完整样本,即样本的某些属性值缺失。如果直接放弃不完整样本,会造成数据信息的极大浪费。C4.5算法引入了=="样本权值"==的概念来优雅地处理缺失值。
核心设定: 赋予每个样本 xxx 一个权重 wxw_xwx,初始状态下,所有样本的权重 wx=1w_x = 1wx=1。
1. 缺失属性的特征选择 (怎么算信息增益?)
问题:如果在属性 AAA 上有样本缺失值,如何计算属性 AAA 的信息增益?
定义无缺失子集 D~\tilde{D}D~: 给定数据集 DDD,定义 D~\tilde{D}D~ 为 DDD 中在属性 AAA 上没有缺失值的样本子集。
基于 D~\tilde{D}D~,我们定义三个重要的比例:
-
ρ\rhoρ (无缺失样本比例): 无缺失值样本的权重之和,占总样本权重之和的比例。
ρ=∑x∈D~wx∑x∈Dwx\rho = \frac{\sum_{x \in \tilde{D}} w_x}{\sum_{x \in D} w_x}ρ=∑x∈Dwx∑x∈D~wx
-
p~k\tilde{p}_kp~k (无缺失样本中的类别比例): 在 D~\tilde{D}D~ 中,属于第 kkk 类(CkC_kCk)的样本权重占比。
p~k=∑x∈D~kwx∑x∈D~wx(1≤k≤∣Y∣)\tilde{p}k = \frac{\sum{x \in \tilde{D}k} w_x}{\sum{x \in \tilde{D}} w_x} \quad (1 \le k \le |\mathcal{Y}|)p~k=∑x∈D~wx∑x∈D~kwx(1≤k≤∣Y∣)
(注:∣Y∣|\mathcal{Y}|∣Y∣ 表示总共有多少个类别。显然有 ∑k=1∣Y∣p~k=1\sum_{k=1}^{|\mathcal{Y}|} \tilde{p}_k = 1∑k=1∣Y∣p~k=1)
-
r~v\tilde{r}_vr~v (无缺失样本中的特征取值比例): 在 D~\tilde{D}D~ 中,属性 AAA 取值为 ava^vav 的样本权重占比。
r~v=∑x∈D~vwx∑x∈D~wx(1≤v≤V)\tilde{r}v = \frac{\sum{x \in \tilde{D}^v} w_x}{\sum_{x \in \tilde{D}} w_x} \quad (1 \le v \le V)r~v=∑x∈D~wx∑x∈D~vwx(1≤v≤V)
(注:VVV 表示属性 AAA 总共有多少种可能的取值。显然有 ∑v=1Vr~v=1\sum_{v=1}^{V} \tilde{r}_v = 1∑v=1Vr~v=1)
新的信息增益计算公式:
Gain(D,A)=ρ×Gain(D~,A)Gain(D, A) = \rho \times Gain(\tilde{D}, A)Gain(D,A)=ρ×Gain(D~,A)
Gain(D~,A)=Ent(D~)−∑v=1Vr~vEnt(D~v)Gain(\tilde{D}, A) = Ent(\tilde{D}) - \sum_{v=1}^{V} \tilde{r}_v Ent(\tilde{D}^v)Gain(D~,A)=Ent(D~)−v=1∑Vr~vEnt(D~v)
-
Ent(D~)Ent(\tilde{D})Ent(D~)就是经验熵
直观理解:
算信息增益时,先只用那些"完好无缺"的样本(D~\tilde{D}D~)正常算一遍信息增益 。
算完之后,因为这个特征有缺失,我们要打个折扣 。打折的系数就是 ρ\rhoρ。缺失得越严重,ρ\rhoρ 越小,这个特征最终的信息增益就越低,也就越不容易被选为切分节点。
2. 缺失属性的样本划分 (遇到缺失样本怎么分叉?)
问题:如果已经决定按属性 AAA 进行划分,但样本 xxx 恰好在属性 AAA 上的值是缺失的,它该进入哪个子节点?
-
情况 1:样本 xxx 在属性 AAA 上无缺失。
正常处理,按照它的真实取值划入对应的子结点,并且样本权值 wxw_xwx 保持不变。
-
情况 2:样本 xxx 缺失属性 AAA 的值。
此时,我们让该样本同时进入所有子结点 !就像火影忍者里的"影分身",但分身出来的权重不再是 1。
进入取值为 ava^vav 的分支子节点时,该样本的权值调整为:
wx←r~v⋅wxw_x \leftarrow \tilde{r}_v \cdot w_xwx←r~v⋅wx
大白话解析(影分身之术):
假设我们在按"温度"分叉。对于已知温度的样本,60% 去了"高温"分支(即 r~1=0.6\tilde{r}_1 = 0.6r~1=0.6),40% 去了"低温"分支(即 r~2=0.4\tilde{r}_2 = 0.4r~2=0.4)。
这时来了一个不知道温度 的样本 xxx(初始权重为 1)。
决策树的做法是:把这个样本切成两份,让 0.6 个 xxx 走向高温分支 ,0.4 个 xxx 走向低温分支 。
这样,缺失值样本带着不同的概率权重,参与到了后续所有分支的学习中。
七. 集成学习与随机森林(Random Forest)
单棵决策树容易过拟合,且边界只能是横平竖直的阶梯。为了突破单模型的性能天花板,我们引入了集成学习。
1. 集成学习(Ensemble Learning)核心思想
集成学习的目标是通过构建并结合多个机器学习器如多棵决策树)来完成学习任务。
- 提升性能: "三个臭皮匠,顶个诸葛亮"。将多个弱学习器组合成一个强学习器,大幅提升整体的预测精度。
- 消除偏差: 利用模型之间的多样性(差异性)。不同的树会在不同的数据区域犯错,将它们组合起来可以相互抵消误差,使得最终的决策边界更加平滑且精准。
2. 随机森林的三大核心机制
随机森林 = 多棵决策树 + 随机性。 它通过以下三个核心步骤来保证每棵树都不一样(保证多样性):
(1). 自助采样 (Bootstrap Sampling) ------ 数据的随机性
每棵树的训练数据都不是全量数据,而是通过有放回的抽样构建出来的子数据集。
- 做法: 从原始的数据集中,每次随机抽取一个样本放入子集,再把这个样本放回原数据集(意味着下次还能被抽到)。重复这个过程,直到子数据集的数据量和原数据集数据量相同。
- 结果: 在构建出的子数据集中,有些原始样本会重复出现 ,而有些原始样本则从未被抽中。这保证了每棵树看到的训练数据都是有差异的。
(2). 待选特征的随机选取 ------ 属性的随机性
这是随机森林相比于普通"树的集合"最精妙的一笔。
- 做法: 在单棵决策树(如 CART)中,节点分裂时会遍历所有的特征寻找最优切分点。但在随机森林中,节点分裂时,会先从所有特征中随机抽取一部分特征(比如总共有 100 个特征,随机抽出 10 个),然后再在这 10 个特征中寻找最优分裂属性。
- 作用: 进一步强行让每棵树长得不一样,极大提升了系统的多样性,防止模型过度依赖某几个所谓的"强特征"。
(3). 多数表决 (Majority Voting) ------ 结果的整合
当成百上千棵各不相同的树都建好之后,预测阶段采用民主集中制。
- 分类问题: 少数服从多数。每棵树投出一票(如 Class 1),最终得票最多的类别就是整个森林的预测结果。
- 回归问题: 取平均值。把所有树输出的连续数值加起来求平均。
3. 随机森林的绝对优势
由于引入了双重随机性(数据随机 + 特征随机),随机森林拥有极佳的模型性质:
- 精度高,抗过拟合能力极强: 随机性完美抵消了单棵树容易死记硬背的缺陷。
- 分类和回归问题均适用: 灵活性极高。
- 无需交叉验证,无需保留测试集 (自带包外估计)
- 原理: 在进行 Bootstrap 有放回抽样时,数学上可以证明,有大约 36.8% 的原始样本从未被抽入某棵树的训练集中。
- 包外估计 (Out-of-Bag Estimate, OOB): 这 36.8% 没被抽中的数据(包外数据),天然就可以作为这棵树的"测试集"!因此,随机森林在训练的同时,就能用这些没有参与训练的数据来自己评估自己的性能,极其高效!