
♌博主名称:鱼子星_
✅数据结构专栏:【数据结构】
✅算法竞赛专栏:【算法竞赛】
前言
上一篇文章我们讲解了各种常见的排序算法的原理、实现过程以及使用场景,包括但不限于插入排序的进阶希尔排序、快速排序的三种实现方法、归并排序巧妙的分治思想......但是排序算法的知识深度还不止于此,接下来就带大家拓展两种较难的排序算法:快速排序和归并排序。
目录
- 快速排序
- 归并排序
-
- 文件归并排序
-
- [1. 概述](#1. 概述)
- [2. 算法框架](#2. 算法框架)
- [3. 实现要点](#3. 实现要点)
- [4. 代码实现](#4. 代码实现)
-
- [4.1 辅助函数:堆排序相关](#4.1 辅助函数:堆排序相关)
- [4.2 数据生成与文件操作](#4.2 数据生成与文件操作)
- [4.3 文件归并核心算法](#4.3 文件归并核心算法)
- [4.4 主函数与整体流程](#4.4 主函数与整体流程)
- [4.5 算法复杂度分析](#4.5 算法复杂度分析)
- 非递归归并排序
-
- [1. 算法原理](#1. 算法原理)
- [2. 代码实现](#2. 代码实现)
- [3. 关键步骤解析](#3. 关键步骤解析)
- [4. 性能对比](#4. 性能对比)
- 总结
快速排序
快排的那点事
快速排序可以说是很多初学者的噩梦,因为快速排序算法原理的特性,衍生出来了多种多样的快速排序的实现方式:三路划分、自省排序、挖坑法......但是一个算法被创造出来的意义就是能提高时空效率,所以接下来就讲解两种能提高快排时间稳定性的实现方式:三路划分 和自省排序。
快速排序之三路划分
前面我们讲过快速排序在一般情况下时间复杂度为 O ( n log n ) O(n\log n) O(nlogn),但是当数据集合有大量相同元素或者本身就有序的时候,快速排序递归层数会到达 n 层,使得其时间复杂度增加到 O ( n 2 ) O(n^2) O(n2)。虽然通过随机选择 key 可以提升快速排序的时间效率,但是当遇到集合大量重复元素时,使用之前的快排方式还是力不从心。
三路划分就是针对当数据集合中有大量重复元素时快排效率低下的问题。因为快速排序划分区间的原理就是将小于 key 的元素都放在 key 的左边,大于 key 的元素放在其右边,但是等于 key 值的元素却没有准确规定放哪里,而三路划分就是除了前面的规定外将所有等于 key 的元素都放在集合的中间,此时就相当于是将区间划分成了三部分。
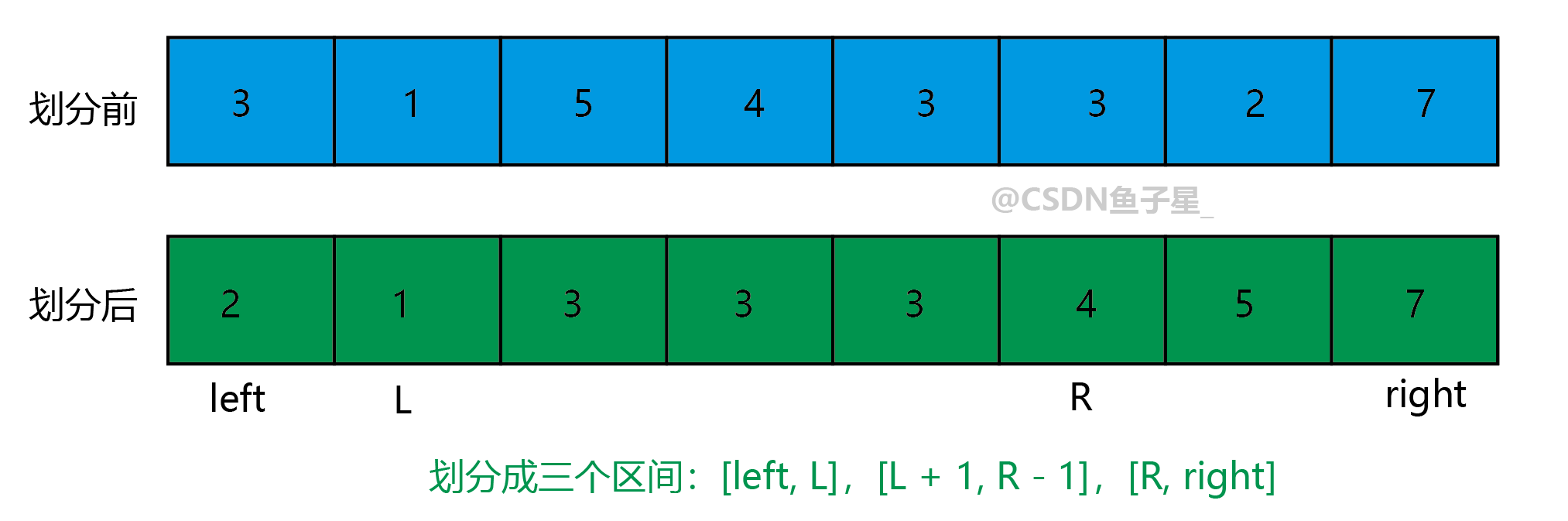
此时待排序的区间就只剩下了 l e f t , L left, L left,L 和 R , r i g h t R, right R,right。这个方法解决了快速排序因为重复元素而变得效率低下的缺点(当数据集合只有一个元素时时间复杂度甚至只有 O ( n ) O(n) O(n))。
Code
c
void _QuickSort01(int* arr, int left, int right)
{
// 递归终止条件:区间无效或只有一个元素
if (left >= right) {
return;
}
// 选择最左边的元素作为基准值
int key = arr[left];
// 初始化三个指针:
// L:小于key区域的右边界(初始为left-1)
// R:大于key区域的左边界(初始为right+1)
// cur:当前遍历指针(初始为left)
int L = left - 1, R = right + 1, cur = left;
// 遍历整个区间
while (cur < right)
{
if (arr[cur] < key)
{
// 当前元素小于key,将其交换到小于区域
Swap(&arr[cur++], &arr[++L]);
}
else if (arr[cur] == key)
{
// 当前元素等于key,直接跳过,留在中间区域
cur++;
}
else
{
// 当前元素大于key,将其交换到大于区域
Swap(&arr[cur], &arr[--R]);
}
}
// 递归排序小于key的区域
_QuickSort01(arr, left, L);
// 递归排序大于key的区域
_QuickSort01(arr, R, right);
}
void QuickSort(int* arr, int n)
{
// 三路划分快排
_QuickSort01(arr, 0, n - 1);
}快速排序之自省排序
自省排序的算法思想很简单:快速排序因为递归层数可能到达 n 层变得缓慢,自省排序就对快排的递归层数做一个记录,当快速排序递归的层数超过了某一个阈值 x,此时停止继续递归,直接使用时间复杂度稳定的堆排序。这个思路直接解决快排在特殊情况下效率低下的问题。同时自省排序也是 C++ STL 库中 sort 函数的底层实现方法。
那么阈值 x x x 要怎么界定呢?这其实已经有人实验过,当数据集合的元素个数为 n n n 时, x = 2 × log 2 n x = 2 \times \log_2 n x=2×log2n。
c
void _QuickSort02(int* arr, int left, int right, int x, int depth)
{
if (left >= right)
{
return;
}
if (depth > x)
{
HeapSort(arr + left, right - left + 1);
return;
}
// 使用三路划分快速排序
int key = arr[left];
int L = left - 1, R = right + 1, cur = left;
while (cur < right)
{
if (arr[cur] < key)
{
Swap(&arr[cur++], &arr[++L]);
}
else if (arr[cur] == key)
{
cur++;
}
else
{
Swap(&arr[cur], &arr[--R]);
}
}
_QuickSort02(arr, left, L, x, depth + 1); // 递归层数要加 1
_QuickSort02(arr, R, right, x, depth + 1); // 递归层数要加 1
}代码框架
- 判断区间是否有意义,无意义直接返回。
- 判断递归层数是否超过 x,如果超过了 x,说明此时快速排序遇到了特殊情况,此时直接改为堆排序给剩下的区间排序。
- 使用三路划分正常执行快排的逻辑。
- 继续递归来排序划分的区间,记得递归层数要加上 1。
归并排序
文件归并排序
1. 概述
- 文件归并排序的应用场景:文件归并排序适合待排序的数据量非常大的情况。当数据量大到内存放不下的时候,数据就只能存放在磁盘上(文件)。而在文件中的数据无法直接使用内排序算法来对数据进行排序,此时就需要使用文件归并排序。
- 与内存排序的区别与联系:文件归并排序虽然名字上是外排序,但是其本质还是需要借助内排序,只不过其因为数据量太大,数据只能放在文件中,并且需要进行多次内排序才能让所有数据元素有序。
- 核心思想 :分别创建两个文件
file1、file2,从原始文件data.txt中读取数据到内存中排序后放入两个文件,再让两个文件不断合并直到原始文件中的数据读取完毕。
2. 算法框架
- 预处理阶段 :打开原始文件
data.txt,区分文件file1、file2和合并文件mfile。写好一个适合的内排序算法方便后续排序。 - 归并阶段 :因为归并时
file1和file2内的数据都有序,所以归并两个文件的思路和合并两个升序数组是一样的。
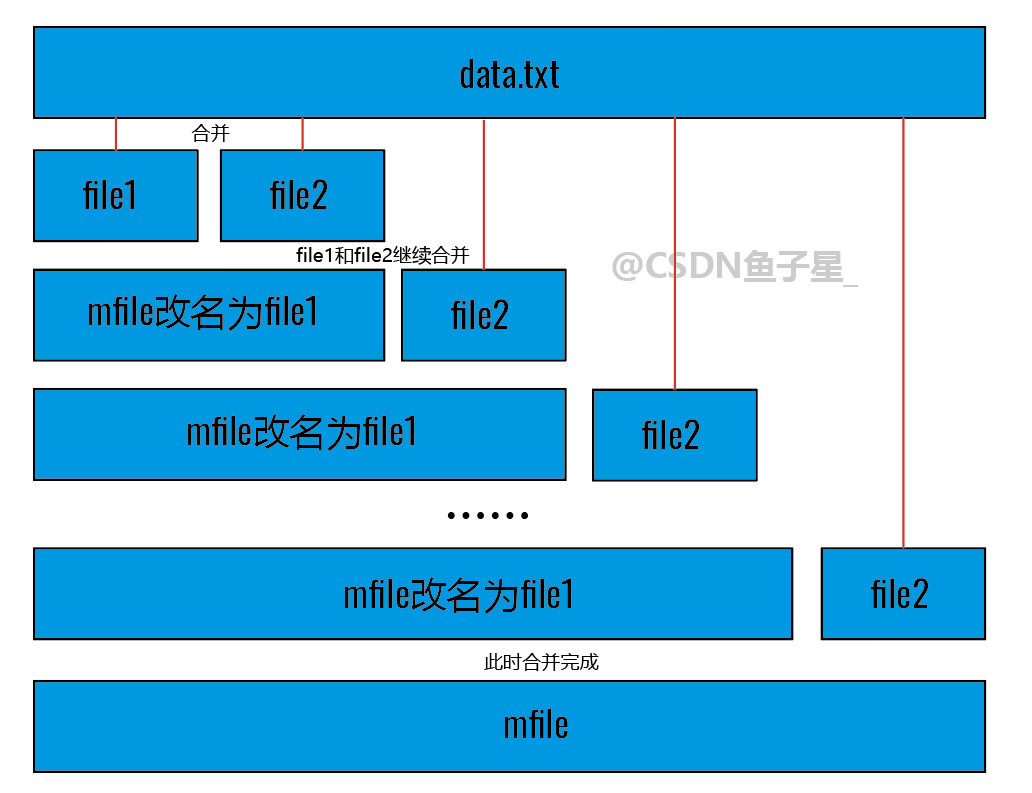
< 文件归并思路图解 > <文件归并思路图解> <文件归并思路图解>
3. 实现要点
- 文件读写优化 :将
file1和file2合并到文件mfile后,直接将mfile改名成file1,之后再执行之前的归并逻辑,这样可以省去文件反复的创建和删除操作。 - 稳定性与性能考量:每次读入内存中的数据不要太小,因为在磁盘上操作本身就很慢,所以尽可能一次读取多一些数据进入内存中排序,减少文件读写的操作。
4. 代码实现
文件归并排序的实现代码较长,我们将其拆分为几个关键部分进行详细解释。
4.1 辅助函数:堆排序相关
首先,我们实现了堆排序算法,用于对每个小文件内的数据进行排序。
c
// 交换两个整数的值
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
// 向下调整堆(大堆)
void down(int* arr, int parent, int n)
{
int child = parent * 2 + 1;
while (child < n)
{
// 选择较大的子节点
if (child + 1 < n && arr[child + 1] > arr[child])
{
child++;
}
// 如果子节点大于父节点,交换并继续向下调整
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
// 堆排序主函数
void HeapSort(int* arr, int n)
{
// 1. 建堆:从最后一个非叶子节点开始向下调整
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
down(arr, i, n);
}
// 2. 排序:将堆顶元素与末尾元素交换,然后调整堆
int end = n - 1;
while (end > 0)
{
Swap(&arr[0], &arr[end]);
down(arr, 0, end);
end--;
}
}代码解析:
Swap():简单的值交换函数down():向下调整堆,维护大顶堆性质HeapSort():完整的堆排序实现,时间复杂度 O(n log n),空间复杂度 O(1)
4.2 数据生成与文件操作
c
// 创建测试数据文件
void CreateData(int n)
{
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen fail");
exit(1);
}
// 生成 n 个随机整数并写入文件
for (int i = 0; i < n; i++)
{
int x = rand() + i; // 添加 i 确保数据不完全随机
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
// 从原始文件读取 m 个数据,排序后写入新文件
int ReadMDataToFile(FILE* fout, const char* file, int m)
{
int* tmp = (int*)malloc(sizeof(int) * m);
if (tmp == NULL)
{
perror("malloc fail");
exit(1);
}
int cnt = 0;
// 1. 从文件中读取 m 个数据
for (int i = 0; i < m; i++)
{
if (fscanf(fout, "%d", &tmp[i]) != EOF)
{
cnt++;
}
else {
break; // 文件已读完
}
}
// 2. 对读取的数据进行堆排序
HeapSort(tmp, cnt);
// 3. 将排序后的数据写入新文件
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen fail");
exit(1);
}
for (int i = 0; i < cnt; i++)
{
fprintf(fin, "%d\n", tmp[i]);
}
fclose(fin);
free(tmp);
return cnt; // 返回实际读取的数据个数
}代码解析:
CreateData():生成包含 n 个整数的原始数据文件ReadMDataToFile():核心函数,完成"读取-排序-写入"流程- 从原始文件读取 m 个数据到内存
- 使用堆排序对内存中的数据进行排序
- 将排序结果写入新文件
- 返回实际读取的数据个数(可能小于 m)
4.3 文件归并核心算法
c
// 合并两个有序文件
void MergeFile(const char* mfile, const char* file1, const char* file2)
{
FILE* fin = fopen(mfile, "w");
if (fin == NULL)
{
perror("fopen fail");
exit(1);
}
// 打开两个输入文件
FILE* f1 = fopen(file1, "r");
FILE* f2 = fopen(file2, "r");
if (f1 == NULL || f2 == NULL)
{
perror("fopen fail");
exit(1);
}
// 归并逻辑:类似两个有序数组的合并
int x1 = 0, x2 = 0;
int ret1 = fscanf(f1, "%d", &x1);
int ret2 = fscanf(f2, "%d", &x2);
// 双指针归并
while (ret1 != EOF && ret2 != EOF)
{
if (x1 < x2)
{
fprintf(fin, "%d\n", x1);
ret1 = fscanf(f1, "%d", &x1);
}
else {
fprintf(fin, "%d\n", x2);
ret2 = fscanf(f2, "%d", &x2);
}
}
// 处理剩余数据
while (ret1 != EOF)
{
fprintf(fin, "%d\n", x1);
ret1 = fscanf(f1, "%d", &x1);
}
while (ret2 != EOF)
{
fprintf(fin, "%d\n", x2);
ret2 = fscanf(f2, "%d", &x2);
}
fclose(f1);
fclose(f2);
fclose(fin);
}代码解析:
MergeFile():实现两个有序文件的归并- 使用双指针技术,每次比较两个文件的当前元素
- 将较小的元素写入输出文件
- 处理完一个文件后,将另一个文件的剩余元素全部写入
4.4 主函数与整体流程
c
int main()
{
// 1. 生成原始数据文件
int n = 10000000; // 1000万条数据
CreateData(n);
// 2. 定义三个临时文件名
const char* file1 = "file1.txt";
const char* file2 = "file2.txt";
const char* mfile = "mfile.txt";
// 3. 打开原始数据文件
FILE* fin = fopen("data.txt", "r");
if (fin == NULL)
{
perror("fopen fail");
exit(1);
}
// 4. 初始化:创建两个有序小文件
int m = 1000000; // 每个小文件包含100万条数据
ReadMDataToFile(fin, file1, m);
ReadMDataToFile(fin, file2, m);
// 5. 多路归并主循环
while (1)
{
// 5.1 合并 file1 和 file2 到 mfile
MergeFile(mfile, file1, file2);
// 5.2 删除已合并的文件
remove(file1);
remove(file2);
// 5.3 将合并结果重命名为 file1
rename(mfile, file1);
// 5.4 从原始文件读取下一批数据到 file2
int cnt = ReadMDataToFile(fin, file2, m);
// 5.5 如果已读完所有数据,结束循环
if (cnt == 0)
{
break;
}
}
fclose(fin);
// 最终结果保存在 file1 中
return 0;
}整体流程解析:
- 初始化阶段:生成原始数据,创建两个有序小文件
- 归并循环 :
- 合并 file1 和 file2 → mfile
- 删除旧的 file1 和 file2
- 将 mfile 重命名为 file1(作为新的归并结果)
- 从原始文件读取下一批数据到 file2
- 终止条件:当原始文件的所有数据都处理完毕时结束循环
- 最终结果:所有数据的有序版本保存在 file1 中
4.5 算法复杂度分析
- 时间复杂度:O(n log m),其中 n 是总数据量,m 是每个小文件的大小
- 空间复杂度:O(m),只需要内存存储一个小文件的数据
- 磁盘 I/O:每个数据平均被读写约 2-3 次
- 适用场景:数据量远大于可用内存时的高效外部排序
非递归归并排序
1. 算法原理
- 迭代替代递归的思想:归并排序的思想是先处理小区间的排序再处理大区间,可以照着这个思路从小区间到大区间使用迭代的方式来实现归并排序。
- 自底向上的归并策略 :初始时可以定义一个值
gap来代表要处理的区间长度,每处理完所有的区间就让gap *= 2,通过这样不断让处理的区间变大,当gap变为n时排序就完成了。 - 空间复杂度分析 :非递归实现归并排序一样需要借助临时的空间,所以空间复杂度和数据集合一样大: O ( n ) O(n) O(n)。
2. 代码实现
c
void MergeSortNoR(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
exit(1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += gap * 2)
{
int begin1 = i, end1 = begin1 + gap - 1;
int begin2 = i + gap, end2 = begin2 + gap - 1;
// 当区间为奇数时会遇到越界的情况,需要特判
if (begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
// 归并逻辑
int p1 = begin1, p2 = begin2, index = begin1;
while (p1 <= end1 && p2 <= end2)
{
if (arr[p1] < arr[p2])
{
tmp[index++] = arr[p1++];
}
else {
tmp[index++] = arr[p2++];
}
}
// 复制剩余元素
while (p1 <= end1)
{
tmp[index++] = arr[p1++];
}
while (p2 <= end2)
{
tmp[index++] = arr[p2++];
}
// 将归并结果拷贝回原数组
for (int j = begin1; j <= end2; j++)
{
arr[j] = tmp[j];
}
}
// 区间长度成倍增长
gap *= 2;
}
free(tmp);
tmp = NULL;
}3. 关键步骤解析
- 子区间大小的增长策略 :通过每次迭代
gap *= 2使得有序区间越来越大。 - 边界条件处理:当数据元素的个数为奇数时,每次两组两组的分最后会有一组长度为 1 的区间只有一个,此时需要直接跳过,让这个单个的区间和长度为 2 的区间合并。
- 空间优化技巧 :归并排序严格意义上有原地的归并可以使得空间复杂度达到 O ( 1 ) O(1) O(1),但是这样代码实现会很复杂,同时时间复杂度会升至 O ( n 2 ) O(n^2) O(n2),所以还是正常使用临时数组归并即可。
4. 性能对比
- 与递归版本的比较:非递归实现归并排序不需要调用函数的栈帧,减少了函数栈的空间开销。但是非递归实现归并排序代码会稍微复杂一点。
- 适用场景分析:非递归版本的归并排序适合待排序的数据量较大的时候,如果数据量很大,使用递归实现归并排序可能导致堆栈溢出。
总结
本篇文章讲解了快速排序与归并排序的拓展,每种排序对应两个不同的实现方法。快速排序的三路划分通过让与 key 相同的值放在数组中间 ,解决了快速排序遇到大量重复元素时间效率低下的问题。自省排序则是通过实时的判断快速排序递归的层数 ,当遇到 key 值没有选好时及时止损改为堆排序,使得快速排序的时间复杂度稳定在 O ( n l o g n ) O(nlogn) O(nlogn)。
文件归并排序和非递归实现归并排序其实都有一个共性就是处理数据量非常大的时候使用。不过文件归并排序是当数据量大到内存都装不下了会使用,非递归归并排序则是防止堆栈溢出。
文件归并排序属于是外排序,使用到了磁盘的空间,但是其排序的方式还是多次使用内排序来完成,通过将一部分数据放入内存中排序再放回文件中合并数据使得整体数据有序。非递归归并排序的是实现比递归版本更复杂,但是减少了栈帧的创建。
排序算法性能对比与使用场景
性能对比表格
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|---|
| 快速排序(标准) | O(n log n) | O(n²) | O(log n) | 不稳定 | 通用排序,数据随机分布 |
| 快速排序(三路划分) | O(n log n) | O(n log n) | O(log n) | 不稳定 | 大量重复元素的数据集 |
| 快速排序(自省排序) | O(n log n) | O(n log n) | O(log n) | 不稳定 | 需要保证最坏情况性能 |
| 归并排序(递归) | O(n log n) | O(n log n) | O(n) | 稳定 | 需要稳定排序,链表排序 |
| 归并排序(非递归) | O(n log n) | O(n log n) | O(n) | 稳定 | 大数据量,防止栈溢出 |
| 文件归并排序 | O(n log n) | O(n log n) | O(k) | 稳定 | 数据量超过内存容量 |
使用场景分析
1. 快速排序系列
- 标准快速排序:适用于大多数随机分布的数据,内存排序场景,对缓存友好。
- 三路划分快速排序:处理包含大量重复元素的数据集时效率显著提升,如统计数据的排序。
- 自省排序:当数据可能已经部分有序或需要保证最坏情况性能时使用,如系统库的排序实现。
2. 归并排序系列
- 递归归并排序:适用于需要稳定排序的场景,如对象按多个字段排序,或链表数据结构。
- 非递归归并排序:处理超大数据集时避免递归深度限制,适合嵌入式系统或栈空间有限的环境。
- 文件归并排序(外排序):数据量超过可用内存时使用,如数据库排序、大数据处理、日志文件分析。
选择建议
- 内存充足,数据随机:优先选择快速排序(标准或三路划分)。
- 需要稳定排序:选择归并排序。
- 数据量极大,超过内存:使用文件归并排序。
- 系统资源有限,担心栈溢出:使用非递归归并排序。
- 数据有大量重复值:使用三路划分快速排序。
- 需要保证最坏情况性能:使用自省排序或归并排序。
实际应用示例
- 数据库索引构建:通常使用归并排序,因为需要稳定且可处理大数据。
- 编程语言标准库:C++的std::sort使用自省排序,Java的Arrays.sort使用TimSort(归并排序变种)。
- 大数据处理框架:Hadoop/Spark在处理超出内存的数据时使用类似文件归并的算法。
- 游戏开发:实时排序小数据集常用快速排序,对缓存友好。