有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主。
1 项目整体介绍
这套项目围绕重庆主城区二手房市场展开,核心目标不是简单展示几张房价图,而是把"数据采集、数据清洗、可视化分析、机器学习预测、影响因素解释"串成一条完整的项目链路。项目数据来自公开房源平台,覆盖江北、渝北、南岸、巴南、沙坪坝、九龙坡、渝中等主城区,最终整理出约二点一万条有效房源记录,字段包括小区名称、成交价格、建筑面积、套内面积、所在楼层、户型结构、房屋用途、建筑类型、装修情况、房屋朝向、房屋年限、抵押信息等。
从展示效果看,这个项目比较适合用于数据分析、机器学习、房地产价格预测、大数据可视化等方向。它既能体现爬虫采集和数据治理能力,也能体现模型训练和结果解释能力。对于毕业设计或课程项目来说,单独做一个预测模型往往显得单薄,而本项目把前端数据展示、后端数据处理和算法评估结合起来,整体完成度会更高。
项目最终形成的内容包括房源市场画像、不同属性下的价格差异、小区价格对比、区域平均价格分布、建成时间趋势、小区名称词云、相关性分析、特征重要性分析以及多模型预测对比。读者可以通过图表快速了解重庆二手房市场的结构,也可以通过模型结果看到不同算法在房价预测任务中的表现差异。
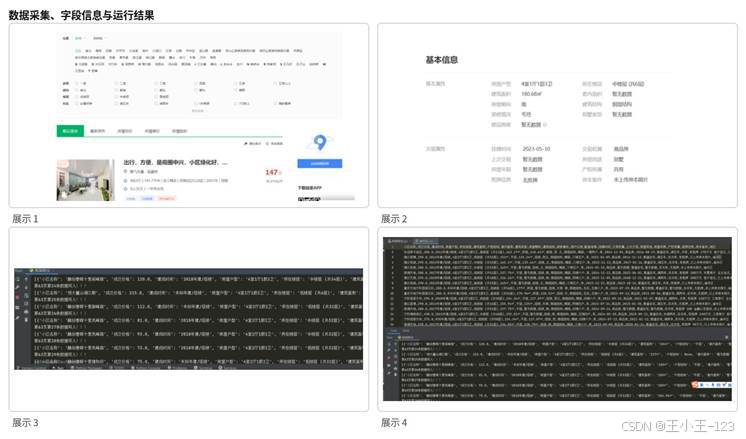
图1 数据采集、字段信息与采集结果展示
2 数据采集与清洗流程
2.1 数据采集设计
项目首先从数据源入手,利用 Python 编写爬虫程序,对多个主城区页面进行分区采集。采集时先分析网页结构,再使用 XPath 定位房源字段,并通过 requests 发送请求获取页面内容。为了让数据覆盖更充分,每个区域按页进行循环采集,并将结果分批写入 CSV 文件。这样即使中途网络波动或程序中断,也不容易造成前面已经采集的数据丢失。
在实际运行中,房源网站通常会有反爬策略,因此程序加入了请求头模拟、异常捕获、延时重试、邮件提醒等机制。一旦出现页面异常、人机验证或请求失败,程序会暂停并记录状态,便于后续继续采集。这部分内容能很好地体现项目的工程细节,不只是拿现成数据做分析,而是从真实网页数据开始构建完整流程。
2.2 数据预处理思路
拿到原始数据后,并不能直接建模。项目对多个 CSV 文件进行了合并、去重、缺失值处理和字段标准化。比如"建筑面积"和"套内面积"需要从文本中提取数值,"所在楼层"需要拆出具体楼层和楼总高,"房屋户型"可以转换为总房间数,"梯户比例"可以进一步拆成电梯数和单层总户数。
对于抵押信息、房屋朝向、小区名称等文本字段,也进行了规则化处理。抵押信息被整理为无抵押、业主自还、客户偿还等类别;房屋朝向只保留主要方向,减少类别过多带来的稀疏问题;小区名称去除特殊符号,方便后续词云和编码。处理完成的数据同步保存为 Excel,并可写入 MySQL,为后续可视化和模型调用提供统一数据基础。
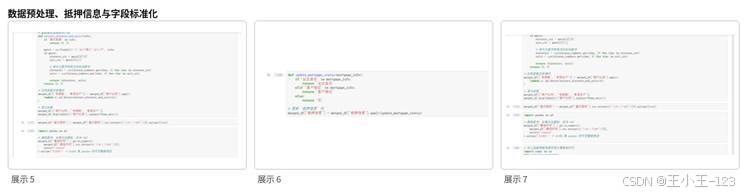
图2 数据预处理、字段标准化与抵押信息处理展示
3 房源市场可视化分析
3.1 价格差异分析
在价格分析部分,项目从房间数、房屋用途、户型结构、建筑类型、楼层、装修和朝向等维度观察二手房成交价格差异。整体来看,住宅类房源仍然是市场主力,普通住宅的均价明显高于公寓、商业和商住两用房源,说明重庆主城区购房需求仍然以居住属性为核心。
从户型结构看,复式、联层等改善型产品均价更高,平层和错层更接近普通刚需或改善需求。建筑类型中,板楼价格表现较好,主要原因在于户型方正、采光和通风条件较好。装修方面,精装修和高标准装修房源更容易形成溢价,而简装房源总价较低,说明购房者更愿意选择能够快速入住、后期投入少的房子。
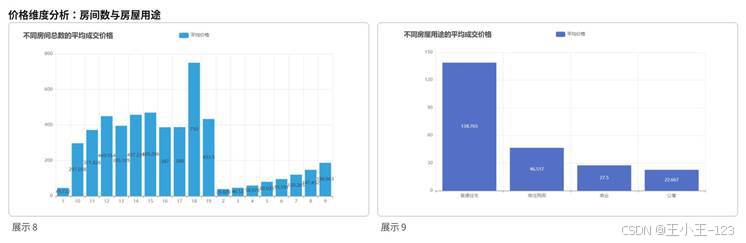
图3 房间数与房屋用途对成交价格的影响
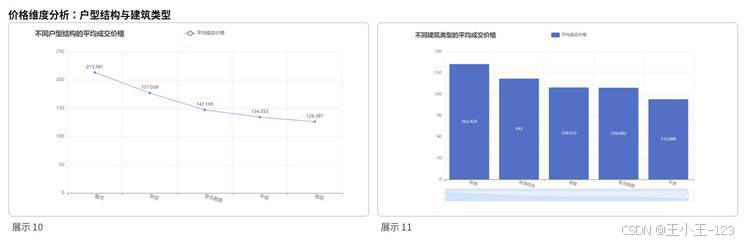
图4 户型结构与建筑类型价格对比

图5 楼层、装修和朝向维度的价格分析
3.2 房源属性画像
除了价格本身,房源属性也是理解市场结构的重要入口。项目统计了产权所属、抵押信息、房本备件、房屋年限、房屋用途、户型结构、建筑类型、楼层和装修情况。结果显示,重庆二手房市场中独立产权房源占比更高,交易手续相对清晰;多数房源无抵押,说明市场中可直接交易的房源占据主流。
从房屋年限看,满五年的房源数量较多,这类房源通常交易税费压力更小,也更容易被购房者接受。房屋用途上,普通住宅占据绝对优势,公寓、商业和商住两用类房源数量较少。户型结构方面,平层房源是挂牌主体,复式、联层和错层相对较少,特殊户型虽然可能有更高单价或总价,但流通量并不高。
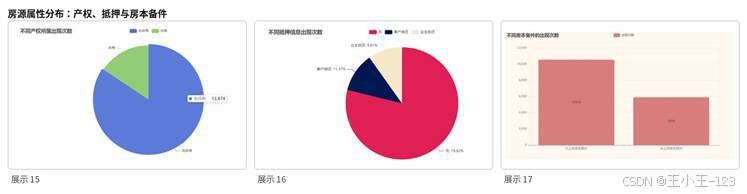
图6 产权、抵押与房本备件分布
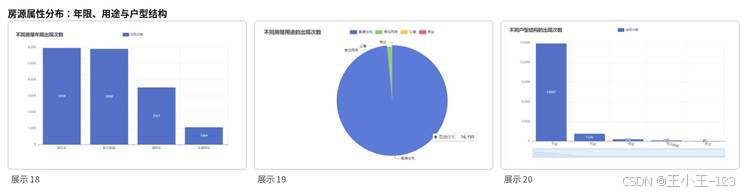
图7 房屋年限、用途与户型结构分布
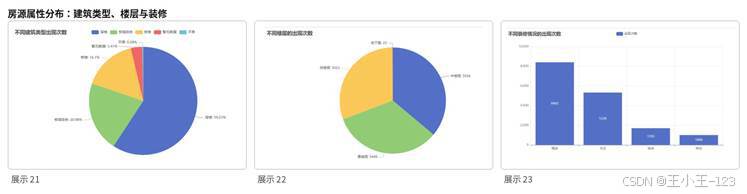
图8 建筑类型、楼层与装修情况分布
4 小区、区域与文本分析
4.1 小区多维度对比
小区维度能把宏观的房价问题落到具体房源场景中。项目对抵押金额最高的小区、平均成交价格最低的小区、平均价格最高的小区以及总建筑面积较大的小区进行了排序展示。高价小区往往位于核心地段、江景资源稀缺区域或品牌房企项目,具有更强的地段和品质溢价。低价小区则多与区位、房龄、配套成熟度等因素相关。
这部分结果对购房决策很有参考价值。预算有限的用户可以关注低价小区的区位和未来发展潜力,改善型或投资型用户则可以关注高价小区的品牌、物业、景观资源和流通性。通过对小区进行排序,项目不仅能展示价格,还能把市场分层关系直观呈现出来。
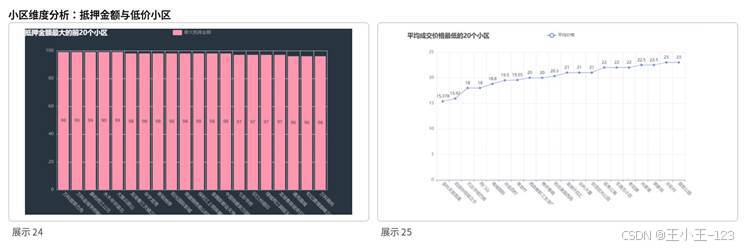
图9 小区抵押金额与低价小区对比
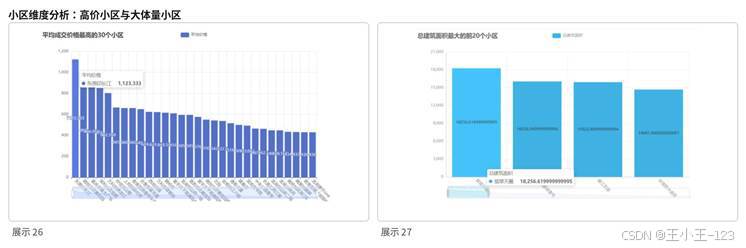
图10 高价小区与大体量小区对比
4.2 区域热力图与建成趋势
区域分析显示,重庆主城区房价呈现出比较明显的中心高、外围低格局。渝中区作为传统核心区,商业、交通和生活配套成熟,均价处于较高水平;江北区依托观音桥、江北嘴等板块,也有较强价格支撑;沙坪坝、南岸、九龙坡等区域处于中等水平;部分外围区域则体现出更强的性价比。
建成时间趋势也很有意思。2000 年以后,重庆主城区房源数量快速上升,2015 年到 2020 年前后达到一个明显高峰,之后新增房源数量有所放缓。这一变化与城市扩张、房地产开发节奏和存量市场转变有关。对购房者来说,建成时间不仅代表房龄,也影响小区配套、物业状态和后期维护成本。
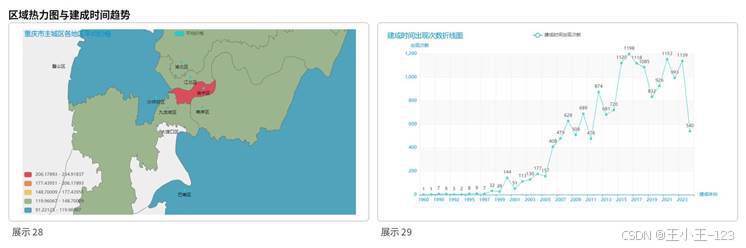
图11 区域平均价格热力图与建成时间趋势
4.3 小区名称词云
词云部分从小区名称中提取高频词,能够看出重庆房源命名和市场品牌特征。未分词词云中,"礼嘉""龙湖""悦庭""江城"等词较为突出,反映出热门板块、品牌房企和江景资源在市场中的存在感。分词后,"龙湖""万科""保利""协信""国际""公馆""府"等关键词更明显,说明品牌、品质和改善型标签对房源传播有一定帮助。
这类文本分析虽然不像模型预测那样直接给出价格结果,但能补充市场理解。很多楼盘名称本身就带有区域、景观、品牌和产品定位信息,把这些信息可视化后,更容易观察到重庆二手房市场的关键词结构。

图12 小区名称词云展示
5 房价预测模型构建
5.1 特征相关性与编码处理
进入建模阶段后,项目先对成交价格与各类特征进行相关性分析。结果显示,建筑面积与成交价格的相关性较强,套内面积也与价格高度相关,总房间数则处于中等相关水平。房屋年限与价格呈一定负相关,说明房龄越大,价格通常越低。区域、小区名称、建成时间、装修情况等变量虽然相关系数不一定都很高,但在复杂模型中仍然可能产生重要影响。
为了让不同模型都能正常训练,项目对类别特征进行了编码处理。CatBoost 可以直接处理类别型变量,不需要额外编码;但 XGBoost、LightGBM、随机森林和线性回归等模型需要将文本类别转换成数值。项目采用 Label Encoding 将房屋用途、建筑类型、产权所属等字段映射为整数,保证后续模型输入格式统一。
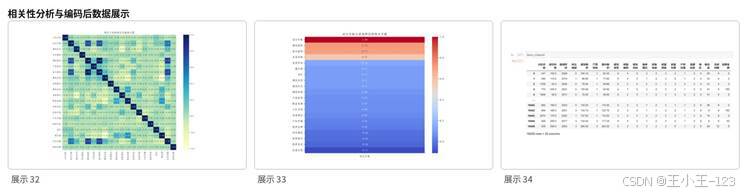
图13 相关性分析与特征编码展示
5.2 CatBoost 模型训练与预测效果
项目重点使用 CatBoost 回归模型进行房价预测。选择这个模型的原因很直接:二手房数据里有大量类别型字段,例如小区名称、区域、装修情况、建筑类型、房屋用途等。CatBoost 对类别特征支持较好,能够减少手动编码带来的信息损失,也能在非线性关系较强的数据中保持较好的泛化能力。
训练时,数据集按 8:2 划分为训练集和测试集,并设置随机种子保证结果可复现。模型迭代过程中使用 R² 作为主要评估指标,最终在测试集上取得较好的拟合效果。结果中,MSE 约为 729.55,RMSE 约为 27.01,MAE 约为 18.82,R² 约为 0.85。这个结果说明模型能够解释大部分价格波动,对复杂房源数据具有较强学习能力。
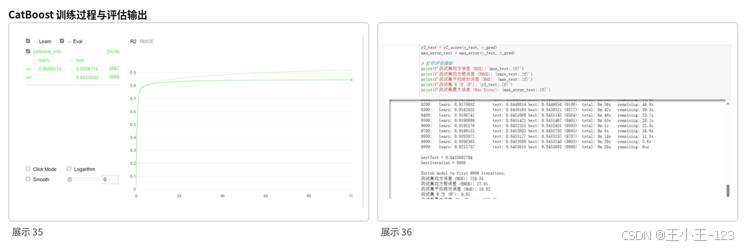
图14 CatBoost 训练过程与评估输出
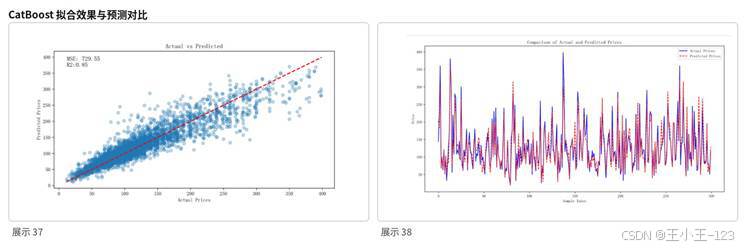
图15 CatBoost 拟合效果与预测对比
5.3 影响因素重要性分析
模型训练完成后,项目进一步输出特征重要性排序。建筑面积、套内面积、小区名称和地区是影响成交价格的核心变量。建筑面积和套内面积直接反映房屋空间价值,小区名称则包含品牌、物业、配套、圈层和地段等综合信息,地区变量体现城市空间差异。
装修情况、建成时间、总房间数、抵押金额等变量也有一定贡献。装修更好的房源往往能减少买家后期投入,建成时间越近通常代表房屋状态和配套条件更好,总房间数则反映家庭居住功能。相比之下,产权所属、抵押信息、房屋朝向等变量在整体预测中的权重较低,但在个别购房决策场景中仍可能产生影响。
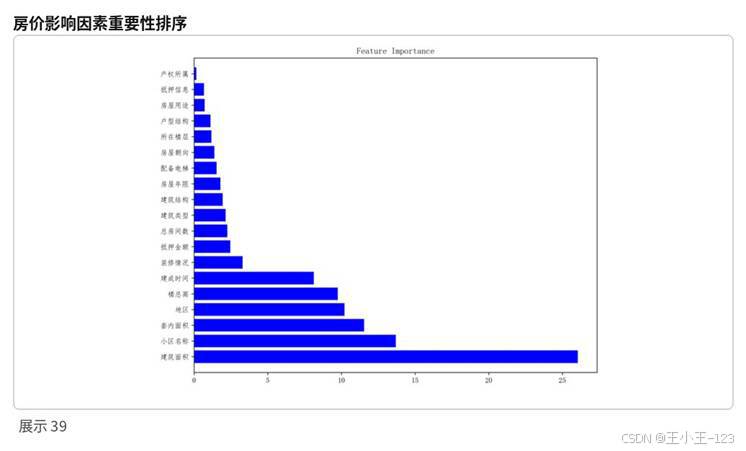
图16 房价影响因素重要性排序
6 多模型对比与项目亮点
为了避免只看单一模型,项目同时构建了线性回归、随机森林、XGBoost、LightGBM 和 CatBoost 等模型。线性回归作为基准模型,R² 约为 0.593,说明单纯线性关系无法很好解释房价变化。随机森林 R² 提升到约 0.809,可以捕捉一定的非线性关系。XGBoost 的 R² 约为 0.822,预测效果继续提升。LightGBM 的表现与 XGBoost 接近,训练效率较高。CatBoost 的 R² 约为 0.845,在本项目中综合表现最好。
6.1 模型评估结果概览
|--------------|------------|-----------|-----------|-----------|
| 模型 | MSE | RMSE | MAE | R² |
| 线性回归 | 1918.35 | 43.80 | --- | 0.593 |
| 随机森林 | 902.59 | 30.04 | 20.74 | 0.809 |
| XGBoost | 839.05 | 28.97 | 20.21 | 0.822 |
| LightGBM | 911.92 | 30.20 | 21.28 | 0.807 |
| CatBoost | 729.55 | 27.01 | 18.82 | 0.845 |
从对比结果可以看出,树模型明显优于线性模型,说明房价与面积、区域、小区、装修、年限等因素之间并不是简单线性关系。CatBoost 的优势在于类别特征处理能力强,对二手房这种字段复杂、类别多、非线性强的数据更友好。这个对比过程能够让项目结论更有说服力,也方便后续继续扩展为线上预测服务。

图17 多种机器学习模型训练与预测输出展示
6.2 项目适合展示的功能点
整个项目可以拆成几个清晰模块:第一是数据采集模块,负责分区域爬取二手房源并落盘;第二是数据处理模块,负责字段清洗、缺失值处理、规则化转换和特征构造;第三是 EDA 可视化模块,负责价格对比、属性分布、区域热力图、小区排序和词云展示;第四是建模预测模块,负责模型训练、评估、预测结果可视化和特征重要性解释。
从成品呈现角度看,项目最大的优势在于"看得见"。用户不仅能看到模型指标,还能看到房源采集过程、字段结构、数据清洗代码、区域热力图、价格对比图、词云和模型输出结果。相比只提交一段训练代码,这种完整展示更容易体现项目工作量,也更容易让读者理解这个系统能解决什么问题。
如果后续继续完善,可以把模型封装成接口,前端输入区域、面积、户型、楼层、装修、建成时间等信息后,系统自动返回预测价格区间,并同步展示相似小区和主要影响因素。也可以接入定时采集任务,实现房源数据定期更新,让价格分析从静态报告升级为动态分析工具。
7 项目总结
重庆二手房价格受多种因素共同影响,单靠经验判断很难把复杂关系说清楚。这个项目用真实房源数据做基础,通过爬虫采集、数据清洗、可视化分析和机器学习建模,把房价影响因素拆解为可观察、可比较、可预测的指标。
从分析结果看,面积、小区、区域、建成时间和装修情况是比较关键的变量;从模型表现看,CatBoost 在类别特征较多的房价预测任务中表现更稳定;从展示价值看,项目图表丰富、模块完整,适合作为数据分析与机器学习结合型项目进行展示。
整体来看,这套项目既能展示数据处理能力,也能展示算法建模能力,还能通过大量可视化图表呈现市场特征。对于想做房地产数据分析、价格预测、大数据可视化或机器学习应用方向的同学来说,这个案例具有较强的参考价值和二次开发空间。
每文一语
真正有价值的项目,不只是跑出一个结果,而是能把数据背后的规律讲清楚、把模型落到真实场景里。