一、工具简介
Tesseract OCR 是一款开源免费、支持离线运行的光学字符识别引擎,能够从图片中提取文字并转为可编辑、复制的文本内容。
它全面兼容 PNG、JPEG、GIF、BMP、TIFF 等主流图片格式,识别结果可导出为 TXT、PDF、HTML 等文件;内置上百种语言识别库,完美支持英文、简体中文等常用语种,图片清晰度越高,识别准确率越好。
目前市面上主流 OCR 工具还有 ABBYY FineReader、EasyOCR、百度智能云 OCR 等。对比而言,Tesseract OCR 核心优势为:完全免费、无需联网离线使用、支持 Windows/Linux/Mac 跨平台部署,同时支持自定义训练模型,可适配各类复杂场景的文字识别需求。
二、Tesseract OCR 安装包下载
1. 官方资源
- Windows 64 位安装包:`https://github.com/UB-Mannheim/tesseract/wiki
- 高精度语言包仓库(推荐使用):https://github.com/tesseract-ocr/tessdata_best
2. 百度网盘(整合包,推荐新手)
已打包好安装程序 + 全量语言包,直接解压即可使用
链接:https://pan.baidu.com/s/1KZI0aaTIJKhfVX7TIDrUTQ
提取码:amhi
文件名称:Tesseract-OCR.zip
三、系统环境变量配置
安装 / 解压完成后,必须配置两道环境变量,否则 Java 项目无法正常调用。
1. 新增 TESSDATA_PREFIX 变量(语言包目录)
该变量用于指定语言库 tessdata 所在路径,路径指向 tessdata 文件夹根目录。
- 变量名:
TESSDATA_PREFIX - 变量值:
E:\dev\OCR\Tesseract-OCR\tessdata
提示:请根据你实际的安装 / 解压路径修改。
2. 配置 Path 环境变量(程序执行目录)
将 Tesseract 主程序目录添加到系统 Path 中,示例:
E:\dev\OCR\Tesseract-OCR四、Java 项目集成(Tess4J)
Java 通过 Tess4J 框架调用 Tesseract 原生能力,下面提供完整依赖、工具类及使用说明。
1. 引入 Maven 依赖
在 pom.xml 中添加核心依赖:
xml
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.7.0</version>
</dependency>2. 通用 OCR 工具类
封装识别方法,增加参数优化、异常捕获、日志打印,适配中文 + 英文混合场景:
java
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
/**
* Tesseract OCR 图片文字识别工具类
*
* @Author:
* @Date:
*/
public class OCRUtils {
private static final Logger log = LoggerFactory.getLogger(OCRUtils.class);
/**
* 图片文字识别
* @param file 待识别图片文件
* @return 识别后的文本内容
*/
public static String ocr(File file) {
long startTime = System.currentTimeMillis();
log.info("开始执行图片OCR识别");
// 校验语言包环境变量
String tessdataPath = System.getenv("TESSDATA_PREFIX");
if (tessdataPath == null || tessdataPath.isBlank()) {
log.error("环境变量 TESSDATA_PREFIX 未配置,请检查!");
throw new RuntimeException("Tesseract 环境变量配置异常");
}
log.debug("当前语言包路径:{}", tessdataPath);
Tesseract tesseract = new Tesseract();
// 识别语言:chi_sim简体中文 + eng英文,按需删减
tesseract.setLanguage("chi_sim+eng");
// 页面分割模式:整张图片作为单个文本块(适配常规截图/图片)
tesseract.setPageSegMode(6);
// 引擎模式:混合引擎(LSTM+传统),综合识别精度最高
tesseract.setOcrEngineMode(3);
String result;
try {
result = tesseract.doOCR(file);
} catch (TesseractException e) {
log.error("OCR 识别失败", e);
throw new RuntimeException("图片文字识别异常", e);
}
long costTime = System.currentTimeMillis() - startTime;
log.info("OCR识别完成,耗时:{} 毫秒,识别结果:{}", costTime, result);
return result;
}
}3. 调用示例
java
public class TestMain {
public static void main(String[] args) {
// 传入本地图片文件
File imgFile = new File("C:\\Users\\86183\\Desktop\\test.png");
String text = OCRUtils.ocr(imgFile);
System.out.println("最终识别内容:\n" + text);
}
}五、参数说明 & 优化建议
-
setLanguage("chi_sim+eng")
chi_sim简体中文、
eng英文,纯中文场景可简写为
chi_sim -
setPageSegMode(6)
将整张图片视为一个完整文本块,适配绝大多数截图、文档图片;图片倾斜可改为 1,多段落图文可改为 3。
-
setOcrEngineMode(3)
启用 LSTM + 传统混合引擎,是目前识别精度、兼容性最优配置。
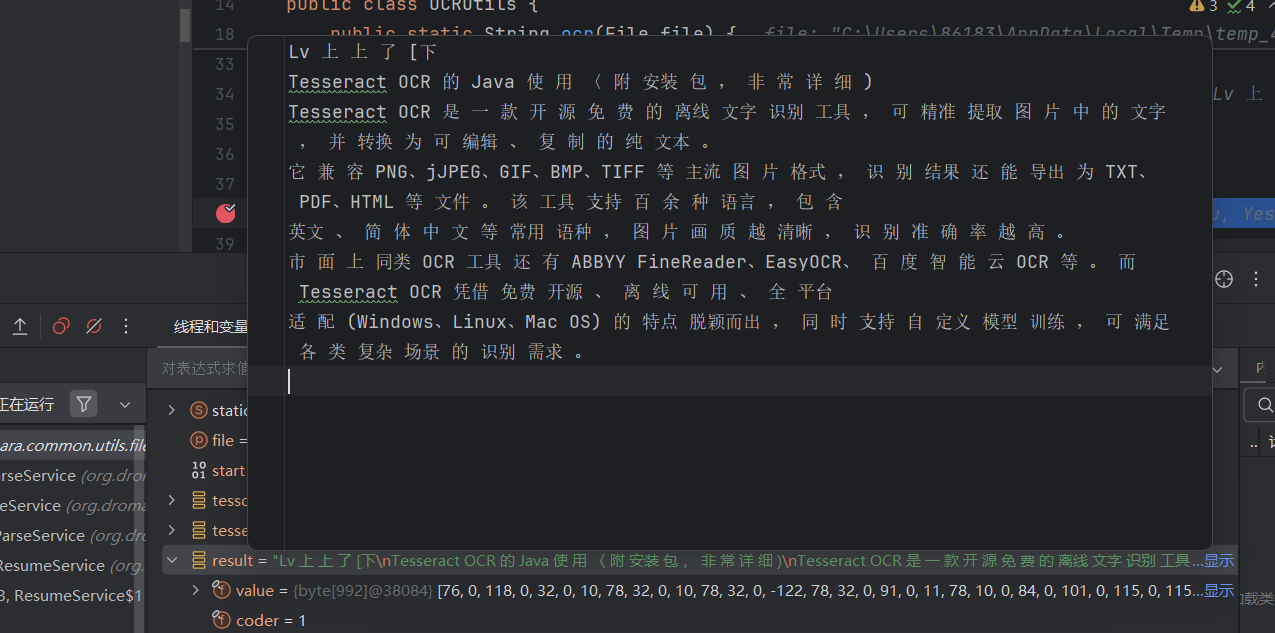
六、运行效果
配置完成后运行代码,即可成功提取图片内文字,识别效果参考:
七、常见问题排查
- 报错找不到 tesseract 程序:检查
Path环境变量是否配置正确; - 中文乱码 / 识别为空:检查
TESSDATA_PREFIX路径、是否放置chi_sim.traineddata中文语言包; - 识别精度低:替换
tessdata_best高精度语言包,同时保证原图清晰无模糊、倾斜。
题排查
- 报错找不到 tesseract 程序:检查
Path环境变量是否配置正确; - 中文乱码 / 识别为空:检查
TESSDATA_PREFIX路径、是否放置chi_sim.traineddata中文语言包; - 识别精度低:替换
tessdata_best高精度语言包,同时保证原图清晰无模糊、倾斜。