之前的文章讲解了决策树分类的原理,这篇文章我们通过一个简单的实战案例来熟悉具体的决策树代码使用。
Sklearn中的决策树语法
Sklearn中使用决策树用到的函数为sklearn.tree.DecisionTreeClassifier(),官方文档链接为:
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#
DecisionTreeClassifier()函数的语法为:
py
DecisionTreeClassifier(criterion="gini",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
class_weight=None,
presort='deprecated',
ccp_alpha=0.0,
monotonic_cst=None) 常用的参数解释如下:
- criterion:划分的标准,gini为基尼系数,entropy为熵,默认参数为"gini"。
- splitter:分枝时变量选择方式 random:随机选择,best:选择最好的变量,默认参数为"best"。
- max_depth:树分枝的最大深度,为None时,树分枝深度无限制,默认参数为"None"。
- min_samples_split:节点分枝最小样本个数,节点样本>=min_samples_split时,允许分枝,如果小于该值,则不再分枝(也可以设为小数,此时参数表示总样本占比)
- min_samples_leaf:叶子节点最小样本数,左右节点都需要满足>=min_samples_leaf,才会将父节点分枝,如果小于该值,则不再分枝(也可以设为小数,此时为总样本占比)
- min_weight_fraction_leaf:叶子节点最小权重和,节点作为叶子节点,样本权重总和必须>=min_weight_fraction_leaf,否则不再分枝。为0时即无限制。
- max_features:限制每次分裂用多少特征,可以传入"整数","小数","None"(默认),"auto", "sqrt", "log2"
- random_state:训练过程中的随机种子。如果设定为非None值,则每次训练都会是一样的结果。
- max_leaf_nodes:最大叶子节点数。默认为None无限制。
- min_impurity_decrease:小数,默认0.0,控制节点分枝最小纯度增长量,当分枝后信息增益的增长小于设定的值时就停止分枝。
- class_weight:给不同类别设置权重,解决样本不均衡问题
- ccp_alpha:非负小数,默认0。剪枝时的alpha系数。默认0时即不剪枝
鸢尾花决策树分类
接下来使用鸢尾花数据集进行决策树分类
py
# 1. 导入需要的库
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.tree import export_graphviz
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report加载数据集并输出一下格式
py
# 2. 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
data=pd.DataFrame(iris.data)
data['Species']=y
data.head()
数据集中比较重要的两个字段是花瓣的长度和花瓣的宽度,所以建模时就只选择这两个特征。
py
X = data.iloc[:, 2:4] # 花瓣的长度和花瓣的宽度
y = data.iloc[:, -1]拆分数据集并建模
py
#建模
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=42)
tree_clf = DecisionTreeClassifier(max_depth=8, criterion='gini')
tree_clf.fit(X_train, y_train)查看分类的准确率:
py
y_test_hat = tree_clf.predict(X_test)
print('acc score: ', accuracy_score(y_test, y_test_hat))
print(tree_clf.feature_importances_)输出的结果为:
acc score: 1.0
[0.42338724 0.57661276]说明分类结果的准确率为100%,且两个特征的重要程度相差不大。
最后将决策树可视化出来
py
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示异常
plt.figure(figsize=(15, 10)) # 设置画布大小
plot_tree(
tree_clf,
filled=True, # 颜色填充
rounded=True, # 圆角节点
feature_names=X.columns, # 特征名称
class_names=iris.target_names, # 类别名称
fontsize=10 # 字体大小
)
plt.title("决策树可视化(花瓣长度+花瓣宽度)", fontsize=15)
plt.show()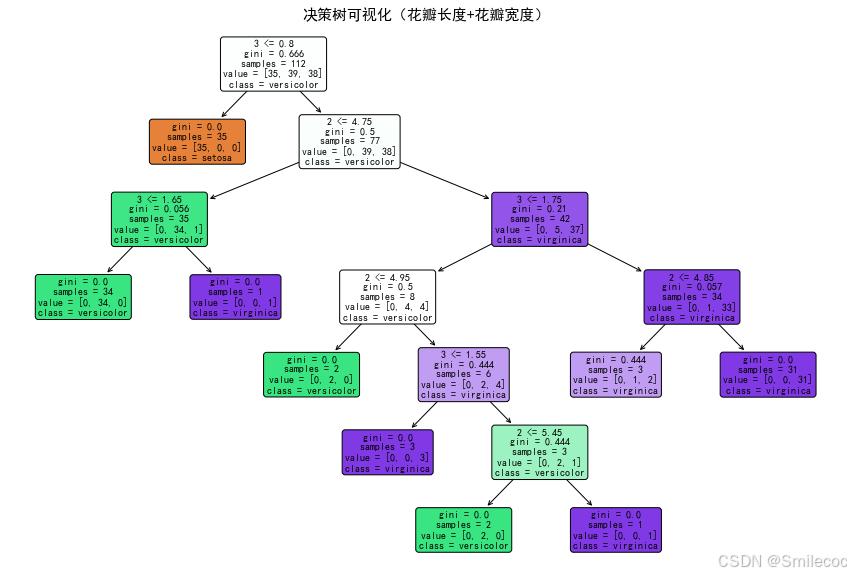
作者:Smilecoc的杂货铺