摘要
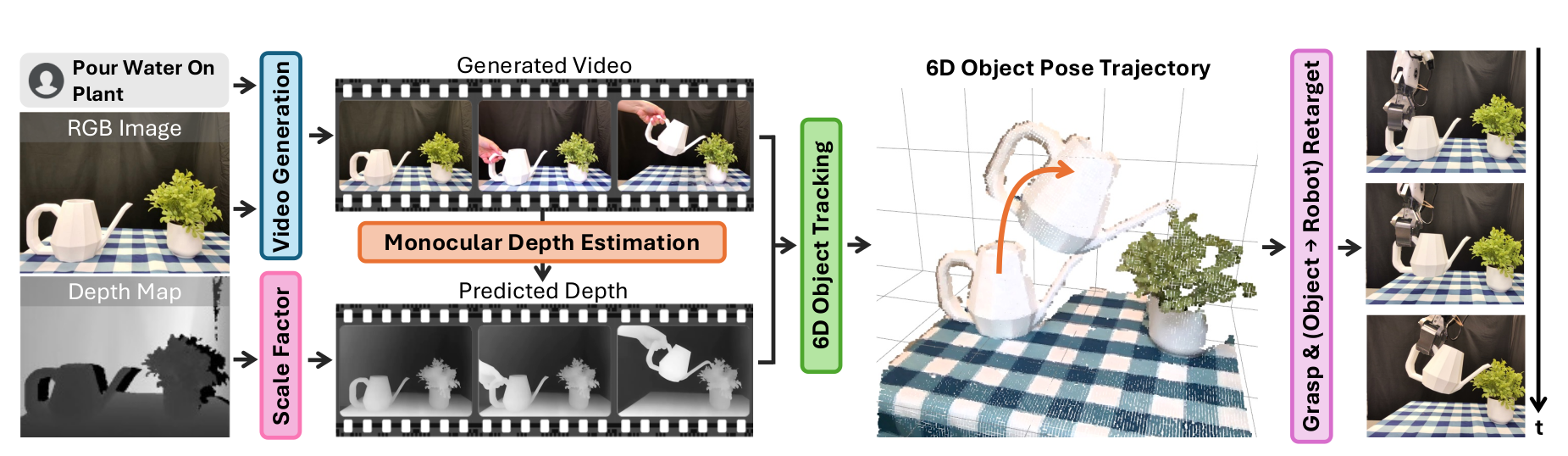
本文提出 RIGVid(Robots Imitating Generated Videos),一个使机器人能够仅通过模仿 AI 生成的视频来执行复杂操作任务的系统,无需任何物理演示或机器人特定训练。
核心流程:
- 给定语言指令和初始场景图像,视频扩散模型生成潜在演示视频
- VLM 自动过滤掉不符合指令的生成结果
- 6D 位姿跟踪器从视频中提取物体轨迹
- 轨迹以具身无关的方式重定向到机器人
实验结果:
- 过滤后的生成视频与真实演示视频效果相当
- 性能随生成质量提升而提高
- 相比 VLM 的关键点预测方法(如 ReKep)和替代轨迹提取方法均有显著优势
1. 研究背景与动机
1.1 传统视频模仿学习的局限
| 方法类型 | 代表工作 | 主要问题 |
|---|---|---|
| 公开视频数据集 | Bahl et al., Ye et al. | 域差距大,需适配机器人具身 |
| 特定演示采集 | Bahl et al., Kareer et al. | 数据采集耗时,需对齐视角和形态 |
1.2 视频生成的机遇与挑战
机遇:SORA、Kling 等模型可从语言和图像输入生成逼真视频
挑战:生成视频可能存在:
- 物体几何扭曲
- 物理不合理的交互
- 场景动态不真实
1.3 核心研究问题
机器人能否仅通过模仿生成的视频来执行真实世界操作任务,无需任何额外监督或任务特定训练?
2. 方法:RIGVid
2.1 系统概述
输入:
- 初始场景 RGB 图像
- 对应深度图
- 自由形式语言指令
输出:机器人 6-DoF 末端执行器轨迹
四个关键步骤:
| 步骤 | 功能 |
|---|---|
| 1. 视频生成与深度估计 | 生成场景和任务条件化的视频,用单目深度估计器预测深度 |
| 2. 6D 位姿轨迹提取 | 通过物体位姿跟踪器计算 6D 位姿 rollout |
| 3. 抓取与重定向 | 抓取物体,将位姿轨迹重定向到机器人 |
| 4. 闭环执行 | 实时跟踪物体位姿,处理扰动 |
2.2 视频生成与过滤
生成模型比较:
| 模型 | 特点 | 适用性 |
|---|---|---|
| Sora | 视觉震撼,但常改变场景布局、物体位置、相机视角 | ❌ 不适合 |
| Kling v1.5 | 较好地遵循语言指令,但有物理不合理行为 | ⚠️ 部分可用 |
| Kling v1.6 | 指令遵循和物理合理性大幅提升 | ✅ 最可靠 |
VLM 过滤机制:
- 从视频中均匀采样 4 帧,垂直拼接成视频摘要
- GPT-4o 判断指令描述的动作是否由可见手执行
- 最多尝试 5 次,全部失败则使用最后一次
过滤统计(Kling v1.6):
| 任务 | 通过率 |
|---|---|
| 倒水 | 83% |
| 掀盖子 | 66% |
| 放铲子 | 55% |
| 扫垃圾 | 45% |
2.3 物体位姿轨迹提取

主动物体识别:
- GPT-4o 识别最可能被操作的物体
- Grounding DINO 生成边界框
- SAM-2 生成分割掩码
位姿跟踪:
- 使用 FoundationPose(需要物体网格)
- 网格通过 BundleSDF 预计算(录制物体旋转视频)
- 应用平均滤波平滑位姿变化
深度估计与对齐:
- 单目深度估计存在尺度-偏移歧义
- 用第一帧的深度图对齐,计算仿射变换并应用到整个视频
2.4 物体到机器人的重定向
抓取:使用 AnyGrasp 在主动物体掩码周围执行最高分抓取
重定向:
- 假设抓取后末端执行器与物体之间固定变换
- 变换 = 物体相对于夹爪的位姿 × 夹爪相对于末端执行器的偏移
- 将固定变换应用到物体的整个位姿序列,得到末端执行器轨迹
关键优势:具身无关------更换机器人只需更新末端执行器到物体的变换
2.5 闭环执行与扰动恢复
实时跟踪:部署期间用 FoundationPose 实时更新物体 6D 位姿
扰动检测与恢复:
| 阈值 | 动作 |
|---|---|
| 位置偏差 > 3 cm | 回退到最后成功执行的轨迹点 |
| 方向偏差 > 20 度 | 重新对齐并继续执行 |
3. 实验设计
3.1 硬件平台
| 组件 | 规格 |
|---|---|
| 机械臂 | xArm7 |
| 相机 | Orbbec Femto Bolt(RGB-D) |
| 相机位置 | 机器人旁边 |
3.2 评估任务
| 任务 | 挑战 | 成功标准 |
|---|---|---|
| 倒水 | 深度变化小,需平滑轨迹 | 壶嘴位于植物上方 |
| 掀盖子 | 深度变化大(自上而下视角) | 盖子脱离锅 |
| 放铲子 | 薄物体、部分遮挡 | 铲头在锅中 |
| 扫垃圾 | 精确定位 + 上述所有挑战 | 垃圾接触簸箕底座 |
3.3 基线方法
| 基线 | 核心方法 | 与 RIGVid 的差异 |
|---|---|---|
| Track2Act | 初始图 + 目标图 → 2D 点轨迹 → PnP → 3D 位姿 | 只用首尾帧,无中间信息 |
| AVDC | 生成视频 → 光流 → 优化重建轨迹 | 依赖帧间光流,误差累积 |
| 4D-DPM | 3D 高斯泼溅 + 特征场跟踪 | 跟踪不稳定,计算慢 |
| Gen2Act | 生成视频 → 点跟踪 → PnP → 位姿 | 使用中间帧点跟踪 |
| ReKep | VLM 生成关键点约束 → 求解轨迹 | 紧凑抽象表示 |
4. 实验结果
4.1 视频质量对性能的影响
| 视频源 | 过滤 | 倒水 | 掀盖子 | 放铲子 | 扫垃圾 | 平均 |
|---|---|---|---|---|---|---|
| Sora | 无 | 0% | 0% | 0% | 0% | 0% |
| Kling v1.5 | 无 | 40% | 20% | 10% | 0% | 17.5% |
| Kling v1.6 | 无 | 80% | 60% | 50% | 20% | 52.5% |
| Kling v1.6 | 有 | 100% | 80% | 90% | 70% | 85% |
| 真实视频 | 有 | 100% | 90% | 90% | 80% | 90% |
关键发现:
- 视频质量与任务成功率正相关
- 过滤后的 Kling v1.6 视频与真实视频表现相当
- 生成视频已可有效替代真实演示
4.2 RIGVid vs. ReKep(VLM 轨迹预测)
| 方法 | 平均成功率 |
|---|---|
| ReKep | 50% |
| RIGVid | 85% |
失败原因:ReKep 的关键点预测不准确(如盖子把手无关键点、铲子任务关键点聚在角落)
结论:视频生成提供的密集视觉监督比紧凑抽象表示更有效
4.3 轨迹提取方法对比
| 方法 | 倒水 | 掀盖子 | 放铲子 | 扫垃圾 | 平均 |
|---|---|---|---|---|---|
| Track2Act | 20% | 10% | 0% | 0% | 7.5% |
| AVDC | 50% | 30% | 20% | 30% | 32.5% |
| 4D-DPM | 60% | 40% | 20% | 20% | 35.0% |
| Gen2Act | 80% | 70% | 60% | 60% | 67.5% |
| RIGVid | 100% | 80% | 90% | 70% | 85.0% |
各类方法的失效模式:
| 方法 | 主要失效原因 |
|---|---|
| Track2Act | 预测轨迹偏离真实路径 |
| AVDC | 光流误差跨帧累积 |
| 4D-DPM | 跟踪不稳定、抖动 |
| Gen2Act | 物体旋转大时跟踪点丢失 |
4.4 深度估计的影响分析
| 配置 | 平均成功率 |
|---|---|
| 真实视频 + 真实深度 | 100% |
| 真实视频 + 生成深度 | 85% |
| 生成视频 + 生成深度 | 85% |
深度估计错误类型:
- 不准确:铲子靠近相机时深度仅变化 6.8 cm(远小于实际)
- 时序闪烁:连续三帧内深度变化 1.9 cm(物理上不可能)
结论:主要误差源是单目深度估计,而非视频生成本身
4.5 泛化能力
跨具身迁移:
- ALOHA 机器人(倒水):80% 成功率
- ALOHA 双臂(放鞋子到盒子):成功
扩展任务(无需物理演示,仅生成视频):
- 擦拭、混合、熨烫
- 扶正番茄酱瓶
- 拔充电器
- 旋转勺子倒豆子
5. 核心创新总结
| 创新点 | 说明 |
|---|---|
| 首个无需物理演示的生成视频模仿方法 | 仅靠生成视频完成真实世界操作 |
| VLM 自动过滤机制 | 高精度过滤不符合指令的视频(几乎无误报) |
| 6D 物体位姿轨迹提取 | 优于点跟踪、光流、特征场等方法 |
| 闭环执行与扰动恢复 | 实时跟踪 + 偏差检测 + 自动回退 |
| 具身无关的重定向 | 同一策略可迁移到不同机器人 |
| 深度估计误差分析 | 识别单目深度估计为主要瓶颈 |
6. 局限性与未来方向
| 局限性 | 未来方向 |
|---|---|
| 需要物体网格(FoundationPose) | 更快的 mesh-free 跟踪 |
| 单目深度估计不准确且闪烁 | 更好的深度预测模型或多目系统 |
| 视频生成计算成本高 | 更高效的生成模型或蒸馏 |
| 部分任务视频生成通过率低 | 改进视频生成模型的指令遵循能力 |
| 场景需简洁(无干扰物体) | 更鲁棒的生成模型 |
7. 与 ReKep 的本质区别
| 维度 | ReKep(VLM 直接预测) | RIGVid(视频生成) |
|---|---|---|
| 表示形式 | 关键点 + 约束 | 完整视频 |
| 信息密度 | 稀疏 | 密集 |
| 推理方式 | 求解优化问题 | 模仿学习 |
| 对 VLM 的要求 | 精确预测关键点坐标 | 判断视频是否有效 |
| 当前效果 | 50% 成功率 | 85% 成功率 |
核心洞察:视频生成虽然计算成本高,但其提供的密集视觉监督对于复杂操作任务至关重要。紧凑的抽象表示(如关键点)丢失了太多信息,导致 VLM 难以准确预测。
8. 结论
本文提出的 RIGVid 首次实现了仅通过生成视频即可让机器人执行真实世界操作任务,无需任何物理演示。
主要贡献:
- 端到端框架连接视频生成模型与机器人执行
- 证明高质量生成视频与真实视频作为模仿来源同样有效
- 6D 物体位姿跟踪优于多种替代轨迹提取方法
- 在倒水、掀盖子、放铲子、扫垃圾等任务上达到 85% 平均成功率
RIGVid 展示了生成式 AI 作为机器人训练数据来源的巨大潜力,为减少昂贵的数据采集需求提供了新路径。
9. 资源
- 🌐 项目主页:https://rigvid-robot.github.io/
- 📄 论文标题:Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
- 👨🔬 作者:Shivansh Patel, Shraddhaa Mohan, Hanlin Mai 等(UIUC + UC Irvine + Columbia)