很多 MyBatis 的 SQL 注入问题,不是出在 where id = ? 这种普通条件上,而是出在更不起眼的地方:排序字段、排序方向、表名、列名、动态 SQL 片段。
比如后台列表接口经常会有这样的需求:
GET /users?page=1&size=20&sortBy=createTime&order=desc前端希望传一个排序字段,后端按这个字段排序。很多人第一反应是把参数直接塞进 Mapper:
XML
<select id="pageUsers" resultType="User">
select id, username, created_at
from user
order by ${sortBy} ${order}
</select>这段代码看起来简单,甚至在测试环境跑得很好。但它真正的问题是:你把 SQL 结构的一部分交给了外部输入。
#{} 解决的是值,不是 SQL 结构
MyBatis 里 #{} 和 ${} 的区别,不能只记成"一个安全、一个不安全"。更准确地说:
| 写法 | 作用 | 典型场景 |
|---|---|---|
| #{} | 生成 PreparedStatement 参数占位符 | 查询条件、插入值、更新值 |
| ${} | 字符串替换,直接拼进 SQL | 动态列名、表名、排序片段等 SQL 结构 |
例如:
XML
where username = #{username}最终会接近:
java
where username = ?数据库把它当成一个"值"处理,用户传入 tom' or '1'='1 也只是一个字符串值。
但排序字段不能这么写:
java
order by #{sortBy}这通常会变成:
java
order by ?数据库不会把 ? 当作列名解析,而是把它当成一个值。结果要么报错,要么排序逻辑不符合预期。
于是很多人改成 ${sortBy}。功能是好了,风险也来了:
java
sortBy=created_at desc, id desc -- 甚至更糟的输入,都可能被直接拼进 SQL。是否能执行多语句取决于数据库、驱动和连接配置,但风险本身已经成立:外部输入影响了 SQL 结构。
动态排序的正确边界:外部参数只做"选择",不能做"拼接"
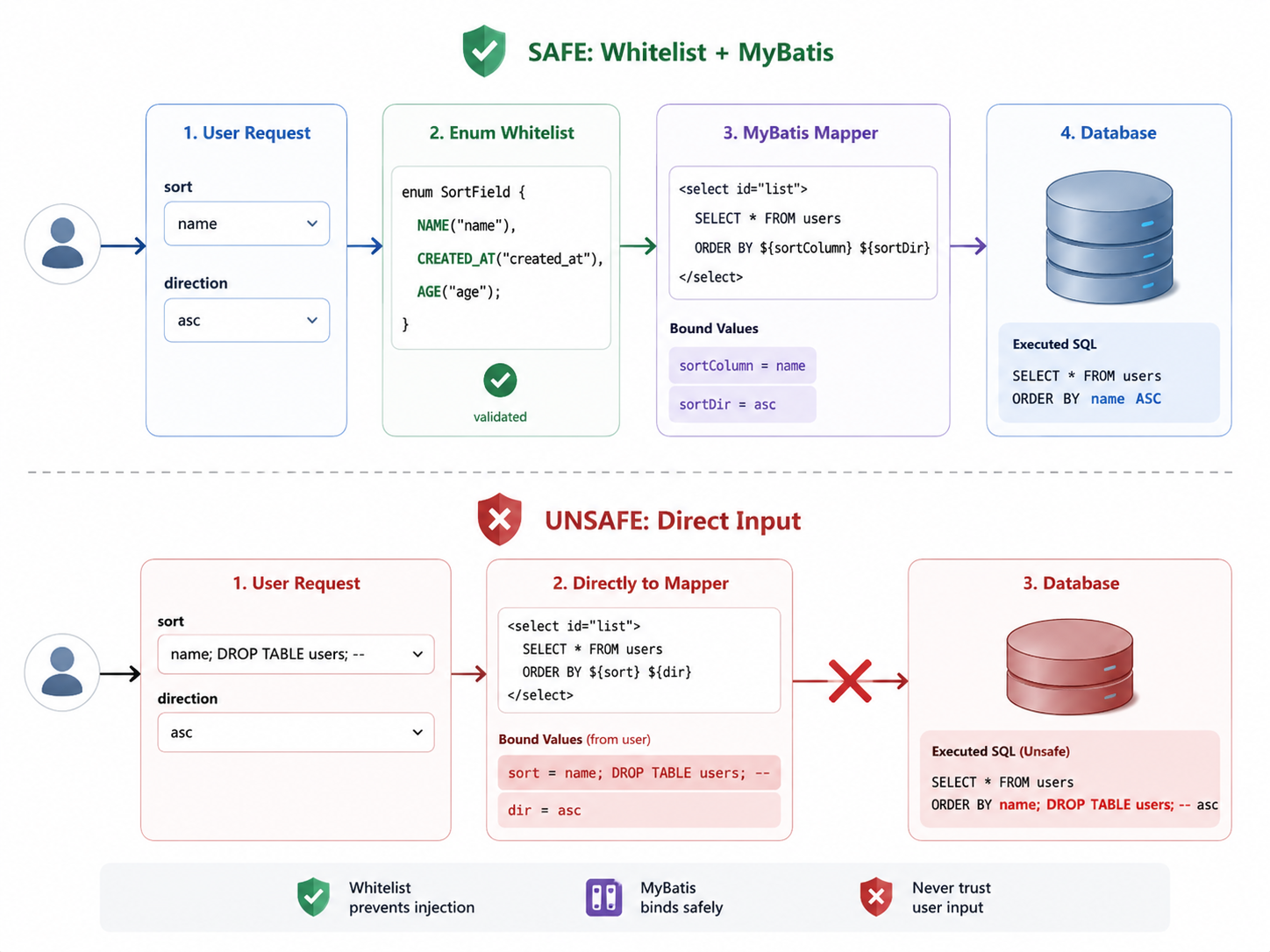
处理动态排序时,比较稳妥的做法是:前端传业务字段名,后端用白名单映射成数据库列名。
不要让前端直接传 created_at,更不要让前端传 u.created_at desc。前端可以传 createTime,后端决定它对应哪个列。
java
public enum UserSortField {
CREATE_TIME("createTime", "created_at"),
USERNAME("username", "username"),
ID("id", "id");
private final String requestName;
private final String column;
UserSortField(String requestName, String column) {
this.requestName = requestName;
this.column = column;
}
public static String toColumn(String requestName) {
for (UserSortField field : values()) {
if (field.requestName.equals(requestName)) {
return field.column;
}
}
return CREATE_TIME.column;
}
}排序方向也一样,不要把 asc / desc 原样交给 SQL:
java
public enum SortDirection {
ASC, DESC;
public static String normalize(String value) {
if ("asc".equalsIgnoreCase(value)) {
return "ASC";
}
return "DESC";
}
}Service 层做转换:
java
@Service
public class UserQueryService {
private final UserMapper userMapper;
public UserQueryService(UserMapper userMapper) {
this.userMapper = userMapper;
}
public List<User> pageUsers(UserPageQuery query) {
String sortColumn = UserSortField.toColumn(query.sortBy());
String direction = SortDirection.normalize(query.order());
return userMapper.pageUsers(
query.keyword(),
sortColumn,
direction,
query.offset(),
query.size()
);
}
}Mapper 里只接收后端已经处理过的安全片段:
java
public interface UserMapper {
List<User> pageUsers(@Param("keyword") String keyword,
@Param("sortColumn") String sortColumn,
@Param("direction") String direction,
@Param("offset") int offset,
@Param("size") int size);
}XML 可以这样写:
XML
<select id="pageUsers" resultType="com.example.User">
select id, username, created_at
from user
<where>
<if test="keyword != null and keyword != ''">
username like concat('%', #{keyword}, '%')
</if>
</where>
order by ${sortColumn} ${direction}
limit #{size} offset #{offset}
</select>这里仍然用了 {},但它和最初的写法有本质区别:{sortColumn} 和 ${direction} 不再来自用户原始输入,而是来自后端枚举白名单。
为什么不建议把白名单写在 XML 里
也可以在 XML 里用 <choose> 做白名单:
XML
<choose>
<when test="sortBy == 'username'">
order by username
</when>
<when test="sortBy == 'createTime'">
order by created_at
</when>
<otherwise>
order by created_at
</otherwise>
</choose>这种方式能避免 ${},适合字段很少的简单场景。但真实项目里,我更倾向于把排序映射放到 Java 代码里,原因有三个。
第一,排序字段通常和接口协议有关。createTime 是 API 字段,created_at 是数据库字段,把这层映射放在 Java 里更容易测试。
第二,很多列表接口会复用排序规则。枚举可以复用,XML 片段复制多了以后很难维护。
第三,Java 代码能更容易扩展权限控制。比如普通用户不允许按 last_login_ip 排序,管理员才允许,这种逻辑写在 Service 层更自然。
XML 应该负责 SQL 表达,外部输入的解释、校验和业务约束,最好在进入 Mapper 之前完成。
真实项目里还要多做两步
第一步是限制分页参数。很多人只盯着排序字段,却忽略了 size。
java
int size = Math.min(Math.max(query.size(), 1), 100);
int page = Math.max(query.page(), 1);
int offset = (page - 1) * size;limit #{size} 本身可以用参数绑定,但如果不限制大小,用户传一个很大的 size,照样可能拖垮查询。
第二步是避免"通用排序接口"过度膨胀。
有些项目会设计成:
XML
{
"sorts": [
{"field": "createTime", "order": "desc"},
{"field": "username", "order": "asc"}
]
}这种设计不是不能用,但要控制复杂度。每增加一个动态 SQL 维度,都意味着更多组合、更难预测的索引使用方式。后台管理系统可以适当开放,核心业务查询接口要更克制。
如果一个列表只有两三种常用排序,直接设计成明确枚举会更好:
java
public enum UserListSort {
LATEST,
NAME_ASC,
ID_DESC
}这比把任意字段排序能力暴露出去更稳。
一个容易忽略的性能问题
安全只是第一层。动态排序还有一个经常被低估的问题:索引不一定跟得上。
比如用户表有这些索引:
XML
idx_status_created_at(status, created_at)
idx_status_id(status, id)如果接口允许按 username、email、last_login_time 任意排序,某些组合就可能触发 filesort 或大范围扫描。SQL 没有注入,也可能变成慢 SQL。
所以排序白名单不仅是安全策略,也是性能策略。你开放哪些排序字段,本质上是在承诺这些查询路径可以被数据库稳定支持。
更工程化的做法是:每开放一个排序字段,都确认对应查询条件、排序字段和分页方式是否能被索引支撑。尤其是深分页场景,limit offset 本身就有代价,动态排序会让问题更明显。
别把 ${} 一棍子打死
MyBatis 官方文档里也明确提到,${} 可以用于动态替换列名这类场景。它不是绝对不能用,而是不能接收未校验的用户输入。
比较合理的判断标准是:
- 查询值、插入值、更新值:优先使用 #{}
- 列名、表名、排序方向:不能用 #{} 解决,需要白名单后再进入 SQL
- 任意 SQL 片段:默认不允许来自外部请求
- 复杂动态查询:优先在 Java 层建模,而不是让字符串一路传到 Mapper
MyBatis 的动态 SQL 能力很强,但越强的拼接能力,越需要明确边界。对 Java 后端来说,真正可靠的写法不是"永远不用 {}",而是让 {} 只接收系统内部生成的、可枚举的、安全的 SQL 片段。
具体 API 和版本可能会随 MyBatis、MyBatis Spring Boot Starter 版本变化,实际项目中应以官方文档为准。但"外部输入不能直接变成 SQL 结构"这条原则不会变。