听说YOLO 和U-Net,也是好几年了,对于这两个熟悉的陌生人我是想用的时候才用一下,可能是和老派视觉库合作太久了吧。下面就来记录一下老人新手使用U-Net.
(1) 了解U-Net

然后我又在想YOLO和U-Net 有什么不同,不都是要做检测的嘛。
具体如下:

看看同一张图两者输出的结果:
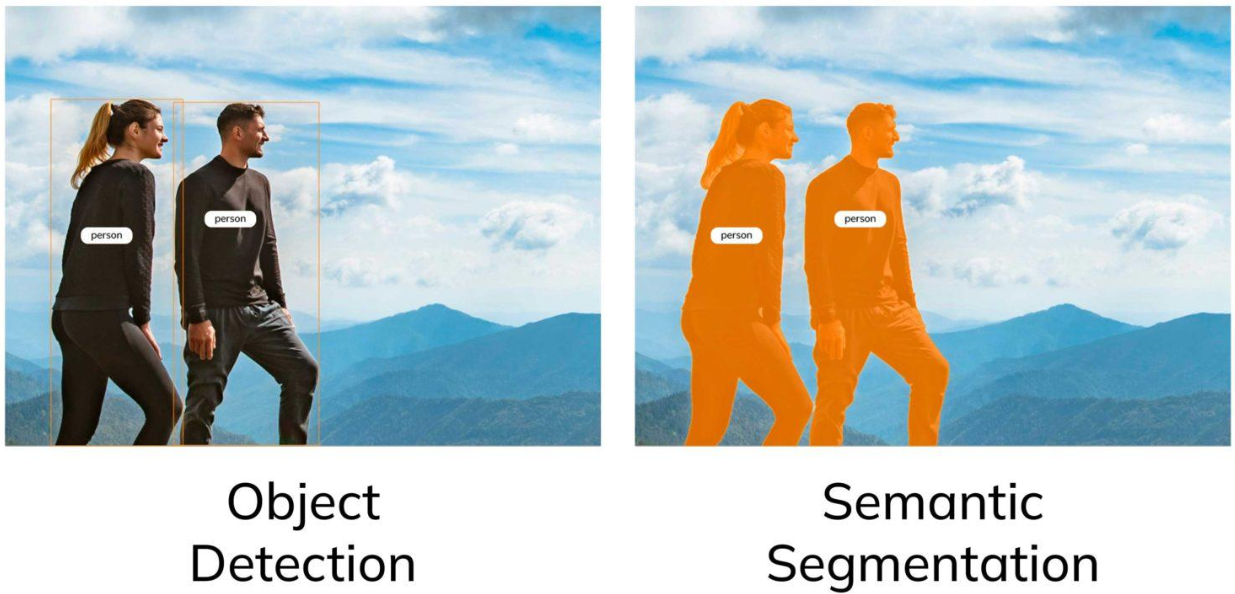
YOLO大哥只需要框出来就行,U-Net 还得分割出具体轮廓。这是检测和分割的具象差异了吧。
看起来如果我只需要统计一张图上有多少个毛孔,那YOLO其实就够了,如果我还需要分析毛孔的大小(直径/体素/面积),那我还是得用U-Net分割。
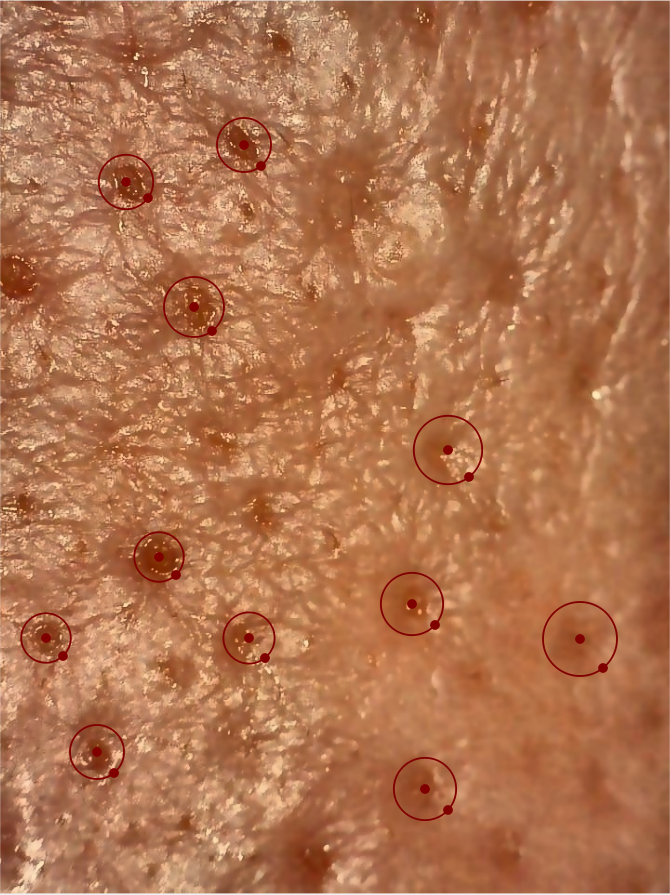
比较遗憾,我做标注用的还是标准的圆,并不止是圈出毛孔,还包括了些许外围。此时我就在想,U-net 的标注图应该怎么构建呢?因为他分割的是物体本身,对于形态不固定的物体怎么才能使得标注只包含需要的前景?这个问题可能要困扰我一段时间。新手尴尬期。。。到现在我更加认可yolo的矩形标注,其实就是告诉模型目标在框里。
看看这个标注,我只能把肉眼非常确定的毛孔圈出来。而且我发现labelme 有个确定,如果把标注形状画的超出了图像边界,必然要卡死。还有如果导入图片有中文名也是要卡死的。
(2) 训练模型
这个其实就是完整的过程。可以概括为如下步骤:
①收集数据: 收集需要做分割的图像数据
②数据预处理
这一步还蛮关键的,如果肉眼上看图中目标和背景之间有比较好的对比差异,那模型学习的效果也更好。
所以我们在这一步应该要做一些去噪、提升目标和背景的差异,还有最重要的一步就是统一好所有图像的分辨率。
这样确保送到标注软件中的图规格一致。
③图像标注
这一块很重要,尽量把最确定的标记出来,标记出优质的。我用的labelme,用文件夹的方式加载,每标注一张图就保存然后自然过度到下一张,直到标注完所有。
④基于标注输出的json 文件和其对应的原始图像生成mask 图
这一步跟yolo 的处理真的非常不同。
需要读标注输出的json 并把json中记录的位置在mask 图中标白,而背景为黑,也就是生成目标和背景mask,且与原图分辨率一致。
这里我不想用官方的 labelme2voc.py 文件了,因为太繁琐了,依赖项很多,要pip一堆。还不如自己直接用openCV 生成;
附上我的json 转mask 的py 代码:
cpp
import json
import numpy as np
import cv2
import os
# ==========================================
# 👇 【在此处配置您的文件夹路径】👇
# 请将下面的路径替换为您存放图片和JSON的文件夹绝对路径
# 注意:Windows路径中可以使用双反斜杠 \\ 或者正斜杠 /
# =============这是我的json和图像存储路径=============================
INPUT_DIR = r"D:\VS_programm\Skin_UNet\images_for_labelme"
# ==========================================
def convert_json_to_mask(input_dir):
"""将指定文件夹下的JSON文件批量转换为Mask掩膜图"""
# 检查传入的文件夹是否存在
if not os.path.isdir(input_dir):
print(f"错误: 指定的路径 '{input_dir}' 不存在!请检查代码中的 INPUT_DIR 配置。")
return
# 在输入文件夹下自动创建一个 'masks' 子文件夹用于存放结果
mask_dir = os.path.join(input_dir, "masks")
os.makedirs(mask_dir, exist_ok=True)
# 获取文件夹下所有的JSON文件
json_files = [f for f in os.listdir(input_dir) if f.endswith('.json')]
if not json_files:
print("警告: 指定的文件夹中没有找到任何 JSON 文件!")
return
success_count = 0
for file_name in json_files:
base_name = os.path.splitext(file_name)[0]
# 1. 寻找同名的原始图片 (支持常见图片格式)
image_path = None
for ext in ['.jpg', '.png', '.jpeg', '.bmp']:
test_path = os.path.join(input_dir, base_name + ext)
if os.path.exists(test_path):
image_path = test_path
break
if not image_path:
print(f"跳过: 未找到与 {file_name} 对应的原始图像")
continue
# 2. 读取JSON数据并获取图像尺寸
json_path = os.path.join(input_dir, file_name)
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
img_height = data['imageHeight']
img_width = data['imageWidth']
# 3. 创建全黑的单通道掩膜图 (背景为0)
mask = np.zeros((img_height, img_width), dtype=np.uint8)
# 4. 遍历标注形状,将标注区域(圆形/多边形)填充为白色(255)
for shape in data['shapes']:
# 获取标注类型和坐标点
shape_type = shape.get('shape_type', 'polygon')
points = np.array(shape['points'], dtype=np.int32)
# 🌟 核心修复:专门处理 Labelme 的圆形标注
if shape_type == 'circle':
# Labelme的圆只记录了 [圆心点, 圆周上的点]
center = tuple(points[0])
# 计算两点之间的距离作为半径
radius = int(np.linalg.norm(points[0] - points[1]))
# 使用 cv2.circle 绘制实心圆 (-1表示填充)
cv2.circle(mask, center, radius, color=255, thickness=-1)
else:
# 其他情况(如多边形)默认按 fillPoly 处理
cv2.fillPoly(mask, [points], color=255)
# 5. 保存生成的Mask图到 masks 文件夹
save_mask_path = os.path.join(mask_dir, base_name + ".png")
cv2.imwrite(save_mask_path, mask)
success_count += 1
print(f"转换完毕!共成功处理 {success_count}/{len(json_files)} 个文件。")
print(f"Mask掩膜图已保存至: {mask_dir}")
if __name__ == "__main__":
convert_json_to_mask(INPUT_DIR)总之就这个么一段代码,我的标注图就转成对应的mask了,因为我只标注了肉眼非常确定是毛孔的位置,而且我避免了靠近边界不完整目标。
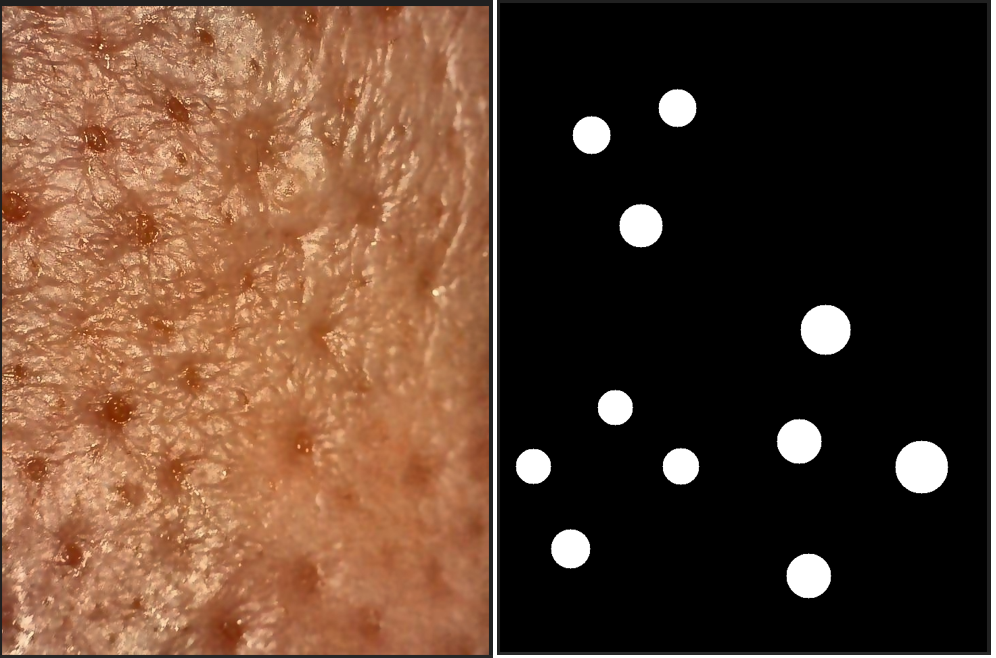
⑤构造训练集和测试集
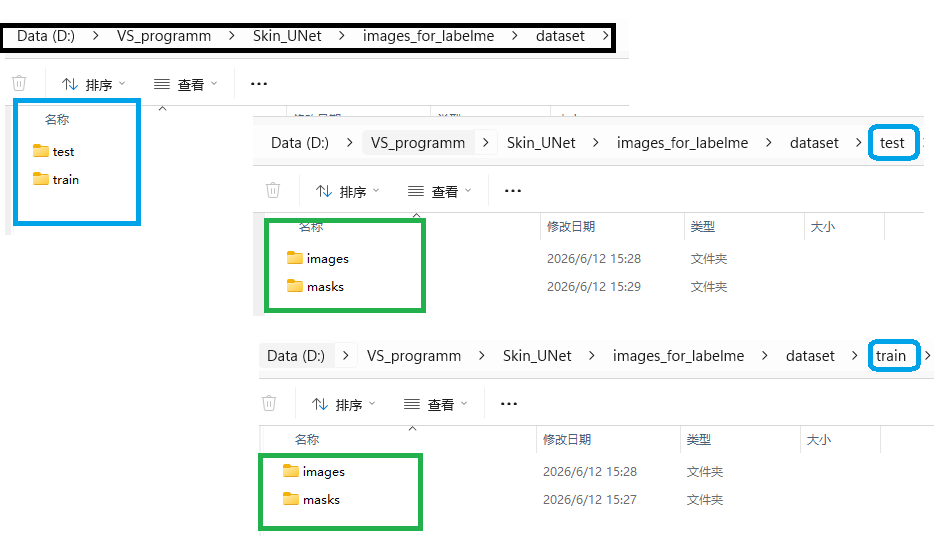
基于上一步生成的mask图及其对应的预处理后的图,需要按照比例归并到训练集train 和测试集 test 文件夹。注意并不是乱放的,一般训练集占比70%80%,而测试集占比20%30%。 还有train 和test文件夹中的图和mask是一一对应的匹配关系。千万不可张冠李戴。
⑥ 训练模型并调参
这里需要基于输出和测试结果进行调整和优化,使得随机测试和外加测试图上都可以得到一个比较好的识别结果为止。
附上我的训练代码train.py, 其调用了优化处理 dataset.py 和model.py
如下为 train.py的代码
cpp
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from dataset import SkinPoreDataset, get_transforms
from model import UNET
# ================= 关键配置区域 =================
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
LEARNING_RATE = 1e-4
EPOCHS = 50 # 训练轮数
BATCH_SIZE = 8
NUM_WORKERS = 2
PIN_MEMORY = True
LOAD_MODEL = False # 是否加载之前的模型继续训练
SAVE_MODEL = True
CHECKPOINT_DIR = "./checkpoints/"
TRAIN_IMG_DIR = r"D:\VS_programm\Skin_UNet\images_for_labelme\dataset\train\images"
TRAIN_MASK_DIR = r"D:\VS_programm\Skin_UNet\images_for_labelme\dataset\train\masks"
VAL_IMG_DIR = r"D:\VS_programm\Skin_UNet\images_for_labelme\dataset\test\images"
VAL_MASK_DIR = r"D:\VS_programm\Skin_UNet\images_for_labelme\dataset\test\masks"
# ===========================================
def train_fn(loader, model, optimizer, loss_fn, scaler):
loop = tqdm(loader)
for batch_idx, (data, targets) in enumerate(loop):
data = data.to(device=DEVICE)
targets = targets.to(device=DEVICE)
with torch.cuda.amp.autocast():
predictions = model(data)
loss = loss_fn(predictions, targets)
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
loop.set_postfix(loss=loss.item())
def main():
train_transform, val_transform = get_transforms()
train_dataset = SkinPoreDataset(TRAIN_IMG_DIR, TRAIN_MASK_DIR, transform=train_transform)
val_dataset = SkinPoreDataset(VAL_IMG_DIR, VAL_MASK_DIR, transform=val_transform)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=NUM_WORKERS, pin_memory=PIN_MEMORY)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=NUM_WORKERS, pin_memory=PIN_MEMORY)
model = UNET(in_channels=3, out_channels=1).to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
loss_fn = nn.BCEWithLogitsLoss() # 适合二分类分割
scaler = torch.cuda.amp.GradScaler()
if LOAD_MODEL:
checkpoint = torch.load(os.path.join(CHECKPOINT_DIR, "my_checkpoint.pth.tar"))
model.load_state_dict(checkpoint["state_dict"])
optimizer.load_state_dict(checkpoint["optimizer"])
for epoch in range(EPOCHS):
print(f"\nEpoch [{epoch+1}/{EPOCHS}]")
train_fn(train_loader, model, optimizer, loss_fn, scaler)
# 保存模型
if SAVE_MODEL:
checkpoint = {
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict(),
}
save_checkpoint(checkpoint, filename="my_checkpoint.pth.tar")
def save_checkpoint(state, filename="my_checkpoint.pth.tar"):
import os
os.makedirs(CHECKPOINT_DIR, exist_ok=True)
print("=> Saving checkpoint")
torch.save(state, os.path.join(CHECKPOINT_DIR, filename))
if __name__ == "__main__":
import torch.nn as nn
main()如下为 dataset.py的代码
cpp
import os
import torch
from torch.utils.data import Dataset
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch import ToTensorV2
class SkinPoreDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.transform = transform
# 获取所有图片文件名
self.images = [f for f in os.listdir(image_dir) if f.endswith(('.jpg', '.png', '.jpeg'))]
def __len__(self):
return len(self.images)
def __getitem__(self, index):
img_path = os.path.join(self.image_dir, self.images[index])
# 假设Mask文件名与原图一致,只是后缀可能是png
mask_name = os.path.splitext(self.images[index])[0] + ".png"
mask_path = os.path.join(self.mask_dir, mask_name)
# 读取图片
image = np.array(Image.open(img_path).convert("RGB"), dtype=np.uint8)
mask = np.array(Image.open(mask_path).convert("L"), dtype=np.uint8)
# 确保Mask只有0和1 (归一化)
mask[mask == 255] = 1.0
# 数据增强 (如果传入了transform)
if self.transform:
augmented = self.transform(image=image, mask=mask)
image = augmented["image"]
mask = augmented["mask"]
# 增加通道维度 (H,W) -> (1,H,W),因为U-Net通常需要单通道Mask输入
mask = mask.unsqueeze(0)
return image, mask.float()
# 定义训练集和测试集的变换策略
def get_transforms():
train_transform = A.Compose([
A.Resize(height=256, width=256), # 统一尺寸
A.HorizontalFlip(p=0.5), # 随机水平翻转
A.VerticalFlip(p=0.5), # 随机垂直翻转
A.Rotate(limit=30, p=0.5), # 随机旋转
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # ImageNet标准化
ToTensorV2(),
])
val_transform = A.Compose([
A.Resize(height=256, width=256),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
])
return train_transform, val_transform如下为:model.py的代码
cpp
import torch
import torch.nn as nn
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, 1, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, 1, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
return self.conv(x)
class UNET(nn.Module):
def __init__(self, in_channels=3, out_channels=1, features=[64, 128, 256, 512]):
super(UNET, self).__init__()
self.ups = nn.ModuleList()
self.downs = nn.ModuleList()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 下采样部分 (Encoder)
for feature in features:
self.downs.append(DoubleConv(in_channels, feature))
in_channels = feature
# 瓶颈层 (Bottleneck)
self.bottleneck = DoubleConv(features[-1], features[-1]*2)
# 上采样部分 (Decoder)
for feature in reversed(features):
self.ups.append(
nn.ConvTranspose2d(feature*2, feature, kernel_size=2, stride=2)
)
self.ups.append(DoubleConv(feature*2, feature))
# 最终输出层
self.final_conv = nn.Conv2d(features[0], out_channels, kernel_size=1)
def forward(self, x):
skip_connections = []
for down in self.downs:
x = down(x)
skip_connections.append(x)
x = self.pool(x)
x = self.bottleneck(x)
skip_connections = skip_connections[::-1] # 反转列表以匹配上采样
for idx in range(0, len(self.ups), 2):
x = self.ups[idx](x)
skip_connection = skip_connections[idx//2]
# 处理尺寸不匹配的情况
if x.shape != skip_connection.shape:
x = nn.functional.interpolate(x, size=skip_connection.shape[2:])
concat_skip = torch.cat((skip_connection, x), dim=1)
x = self.ups[idx+1](concat_skip)
return self.final_conv(x)⑦测试模型并反馈调参模型
跑完上一步的训练以后就是跑预测了,如果预测结果不好,那说明需要调整参数,如果怎么调都不够好,那有可能是输入标注的不好。总之一切都有原因。慢慢调整和优化吧。
下面是我的预测代码 predict.py
cpp
import torch
import torchvision.transforms as transforms
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from model import UNET
import os
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
MODEL_PATH = "./checkpoints/my_checkpoint.pth.tar"
TEST_IMAGE_PATH = r"D:\VS_programm\Skin_UNet\images_for_labelme\dataset\test\images" # 指向测试集原图文件夹
OUTPUT_DIR = "./predictions"
def predict_and_save(image_path, model):
model.eval()
image = Image.open(image_path).convert("RGB")
original_size = image.size # 获取原图尺寸 (宽, 高)
# 1. 预处理 (缩放到模型需要的 256x256)
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
img_tensor = transform(image).unsqueeze(0).to(DEVICE)
# 2. 模型预测
with torch.no_grad():
predictions = torch.sigmoid(model(img_tensor))
predictions = (predictions > 0.5).float()
# 3. 后处理:将 Mask 还原为原始分辨率
pred_np = predictions.squeeze().cpu().numpy()
# 核心修复:使用双线性插值将 256x256 的 Mask 放大回原图尺寸
pred_img_resized = Image.fromarray((pred_np * 255).astype(np.uint8))
pred_img_resized = pred_img_resized.resize(original_size, Image.BILINEAR)
# 再次二值化:因为插值放大后边缘可能会产生灰度过渡,这里重新把大于127的变白,否则变黑
final_mask_np = np.array(pred_img_resized)
final_mask_np[final_mask_np >= 127] = 255
final_mask_np[final_mask_np < 127] = 0
final_pred_img = Image.fromarray(final_mask_np.astype(np.uint8))
# 4. 保存结果
os.makedirs(OUTPUT_DIR, exist_ok=True)
save_name = os.path.basename(image_path)
final_pred_img.save(os.path.join(OUTPUT_DIR, f"pred_{save_name}"))
print(f"预测完成并已还原至原始分辨率: {os.path.join(OUTPUT_DIR, f'pred_{save_name}')}")
# 5. 可视化对比 (现在两张图尺寸完全一致了)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title("Original Image")
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(final_pred_img, cmap='gray')
plt.title("Predicted Mask (Original Size)")
plt.axis('off')
plt.show()
if __name__ == "__main__":
model = UNET(in_channels=3, out_channels=1).to(DEVICE)
if os.path.exists(MODEL_PATH):
checkpoint = torch.load(MODEL_PATH, map_location=DEVICE)
# 优化:因为保存时存的是字典,这里直接读取 "state_dict" 键,更加安全
model.load_state_dict(checkpoint["state_dict"])
print("模型加载成功!")
# 遍历测试文件夹进行预测
for img_name in os.listdir(TEST_IMAGE_PATH):
if img_name.endswith(('.jpg', '.png')):
full_path = os.path.join(TEST_IMAGE_PATH, img_name)
predict_and_save(full_path, model)
else:
print(f"错误: 找不到模型文件 {MODEL_PATH},请先运行 train.py")来看看我的预测结果,虽然看起来还不够理想,但是比我用传统CV 算法做的要好很多啊。而且我的输入其实也真不咋地。。。
后面再继续进一步优化,感觉希望就在眼前啊~

⑧把模型转成可以部署的onnx 格式
要部署,甚至脱离python部署,我就得把训练好得模型转成onnx 格式。
如下为export_onnx.py
cpp
import torch
from model import UNET
# 1. 加载训练好的模型权重
DEVICE = "cpu" # 导出时建议使用 CPU
model = UNET(in_channels=3, out_channels=1).to(DEVICE)
checkpoint = torch.load("./checkpoints/my_checkpoint.pth.tar", map_location=DEVICE)
model.load_state_dict(checkpoint["state_dict"])
model.eval() # 必须设置为评估模式
# 2. 构造一个虚拟输入(形状需与训练时一致)
dummy_input = torch.randn(1, 3, 256, 256, device=DEVICE)
# 3. 导出为 ONNX 格式
torch.onnx.export(
model,
dummy_input,
"skin_unet.onnx", # 导出的文件名
opset_version=11, # ONNX 算子集版本(推荐 11 或更高)
input_names=["input"], # 输入节点名称
output_names=["output"], # 输出节点名称
do_constant_folding=True # 开启常量折叠优化计算图
)
print("成功导出 skin_unet.onnx")今天先到此吧,正好有了更多得数据,后面再来一大波,总之感觉这个U-Net 还挺好玩的。。。