一、FakeShield: Explainable Image Forgery Detection and Localization via Multi-modal Large Language Models
论文地址: https://arxiv.org/pdf/2410.02761
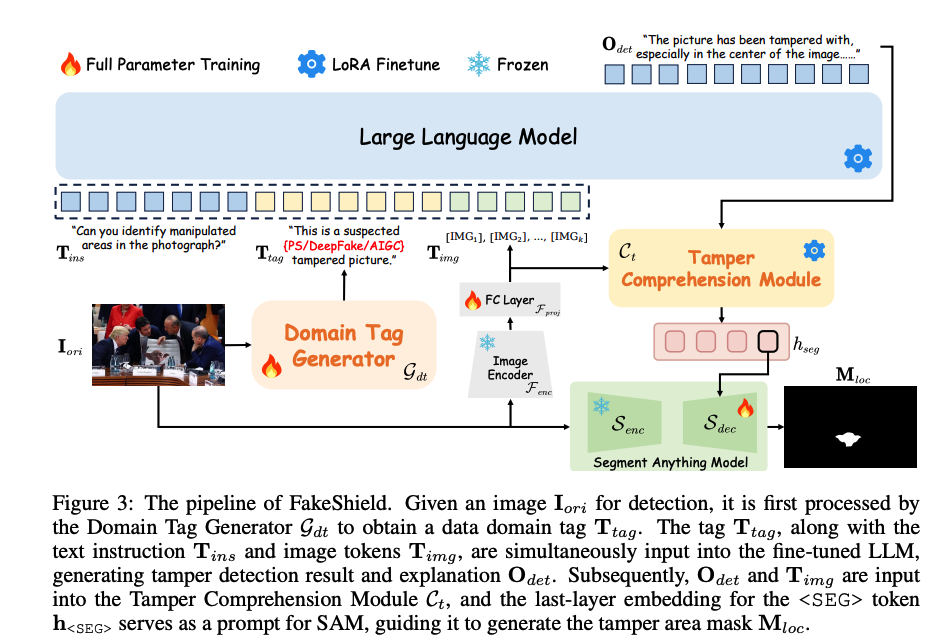
FakeShield 处理图像的步骤如下:
- 领域标签生成 (Domain Tag Generator): 输入图像首先通过一个分类器,识别出它属于哪种潜在的篡改领域(PhotoShop、DeepFake 或 AIGC)。这一步能有效缓解不同篡改手法带来的数据分布冲突。
- 视觉-文本推理: 将识别出的领域标签 、图像产生的视觉 Token 以及用户指令 共同输入给微调过的 LLM。
- 输出判定依据: LLM 输出检测结果(真/假)、篡改区域的文字定位描述以及判定理由(如" fighter jets 的阴影缺失,不符合物理规律")。
- 篡改理解模块 (TCM): 该模块作为中间件,将 LLM 生成的长篇文本描述与视觉特征对齐,并提取出一个专门的分割 Token(
<SEG>)的嵌入向量。 - 引导 SAM 生成掩码: 将该向量作为提示词(Prompt)输入给 SAM (Segment Anything Model) 的解码器,引导其在原图上生成精确的篡改掩码
技术优势
- 缓解黑盒问题: 与只给出 0 或 1 结果的模型不同,FakeShield 能告诉用户它为什么觉得这张图是假的。
- 泛化能力强: 通过领域标签引导策略,它能同时处理从传统的 Photoshop 篡改到最新的 AIGC 图像修改。
- 高精度定位: 利用 TCM 模块增强了分割模型理解复杂长描述的能力,从而比传统的分割方法更精准地锁定篡改区
二、TextShield-R1: Reinforced Reasoning for Tampered Text Detection
论文地址:https://arxiv.org/html/2602.19828v1
TextShield-R1 的具体实施方案可以分为以下四个关键步骤:
- OCR 文本感知(感知层) :
- 首先通过专门的 OCR 引擎提取图像中的所有文本内容。
- 将这些文本特征作为"锚点"与原始图像的视觉 Token 进行对齐,确保模型能"看清"每一个微小的文字细节。
- 构建思维链提示(推理层) :
- 设计引导语,要求模型不仅给出真伪结论,还要从字体一致性、物理光影、语义逻辑三个维度进行逐步分析。
- GRPO 强化学习优化(训练层) :
- 模型会针对同一个样本生成多个推理路径(Group)。
- 系统根据掩码准确率(IoU) 逻辑合理性给予奖励,通过不断博弈,让模型学会像专家一样审视文字伪造痕迹。
- 生成取证报告(输出层) :
- 输出最终的检测结果,并自动生成精确的篡改掩码(Heatmap)以及详细的判定理由。
虽然 OCR (负责看清文字)和 大模型 (负责逻辑推理)是它的两大核心支柱,但 TextShield-R1 真正的"灵魂"在于它引入了类似 DeepSeek-R1 的强化学习机制 (GRPO)。简单来说,它的方案结构是这样的:
- 感知器 (OCR):像眼睛,把图片里模糊细小的文字转成模型能懂的文本。
- 大脑 (大模型):作为推理主体,负责思考和分析。
- 进化器 (GRPO 强化学习) :这是最关键的!它不只是简单的"调用"模型,而是通过不断的自我博弈和奖励反馈,训练模型学会像法务专家一样去审视字体、光影和逻辑矛盾。
所以,它更像是一个经过特种训练的、带助视器的推理专家,而不仅仅是两者的简单堆砌。
三、MIRROR: Manifold Ideal Reference ReconstructOR for Generalizable AI-Generated Image Detection
论文地址:https://arxiv.org/pdf/2602.02222
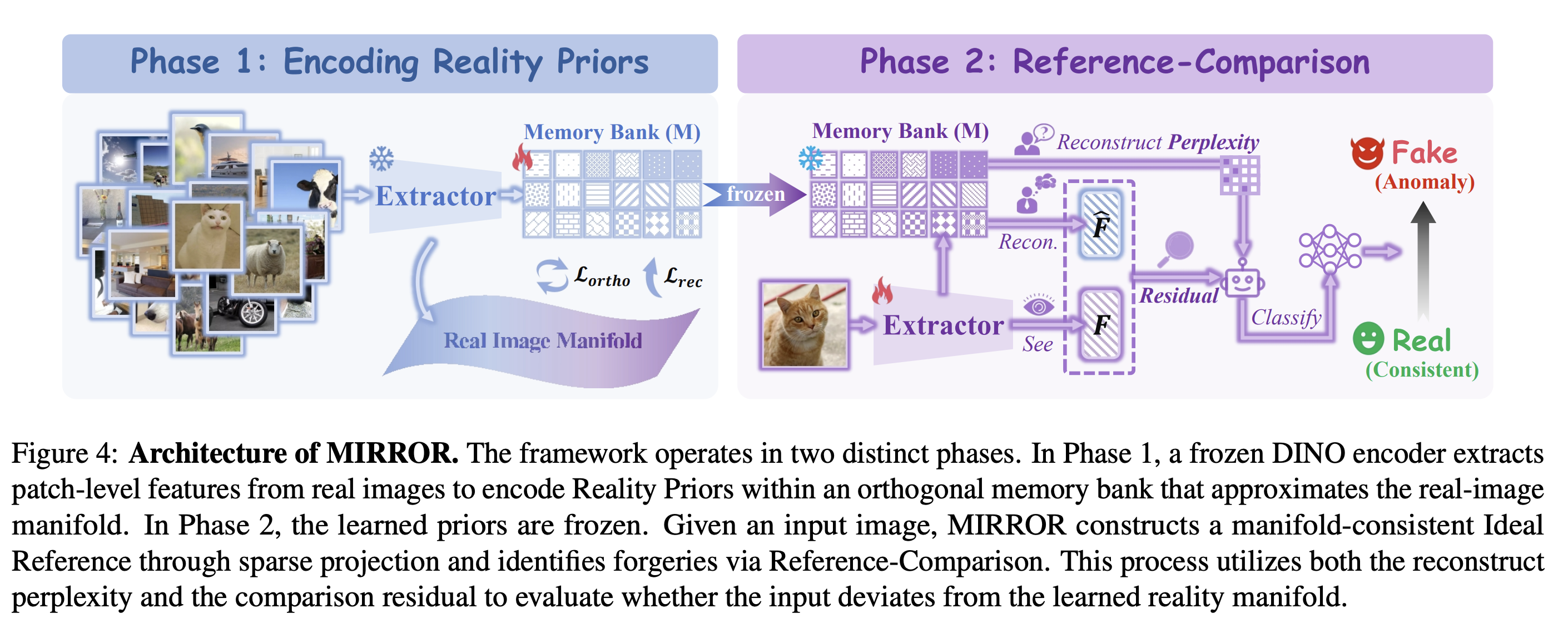
MIRROR 分为两个阶段运行,旨在构建一个稳定的现实先验模型并进行一致性校验:
第一阶段:编码现实先验(流形构建)
- 特征提取 :使用预训练且冻结的 DINO 编码器(如 DINOv3)从真实图像中提取补丁级(patch-level)特征。
- 记忆库构建 :构建一个包含 K 个正交原型向量的学习型离散记忆库(Memory Bank),用于捕捉真实图像中稳定的纹理和语义模式。
- 稀疏投影 :利用交叉注意力机制结合 Top-k 稀疏约束 ,将输入特征投影到由记忆库定义的子空间中,构建出流形一致的"理想参考"(Ideal Reference)。
- 训练目标 :该阶段仅在真实图像上训练,通过最小化重构误差并强制原型正交来确保记忆库能准确反映真实图像分布。
第二阶段:基于参考比较的检测
- 冻结先验:冻结第一阶段学到的记忆库和投影模块,确保检测逻辑独立于具体的伪造分布。
- 信号提取 :
- 重构困惑度(Reconstruct Perplexity):表征当输入缺乏典型真实世界模式时,检索原型的不确定性。
- 比较残差(Comparison Residual):计算原始特征与"理想参考"之间的差异,量化那些无法被真实流解释的细节。
- 最终判定:将上述两种信号融合后输入分类头,输出图像的伪造概率
核心创新点
- 范式转型(Paradigm Shift) :不同于传统方法去"追逐"不断进化的生成伪影,MIRROR 转向验证图像是否符合稳定的现实世界规律,将检测定义为一种基于先验的一致性验证过程。
- 理想参考重构(Ideal Reference Reconstruction):引入稀疏线性组合策略,即使输入是合成图像,也能强制生成一个"如果该图是真实的应该长什么样"的参考基准,从而放大伪造区域的偏差。
- 离散记忆库与正交原型:通过学习一个由正交向量组成的记忆库来明确建模真实图像流形,这种方法比传统的黑盒特征提取器更具解释性,且能有效减少冗余。
- 残差引导的可解释性:MIRROR 直接根据重构残差生成热力图,能够精准定位物理规律违背(如光影不一致、几何畸变)的区域,这与人类专家的审美校验逻辑高度相似。
- Human-AIGI 基准测试 :提出了首个包含"人类不可感知子集"(Human-Imperceptible subset)的评估基准,用于量化算法何时能真正跨越"超人分界点"(Superhuman Crossover),替代人类专家审核。
四、Spot the Fake: Large Multimodal Model-Based Synthetic Image Detection with Artifact Explanation
论文地址:https://arxiv.org/pdf/2503.14905
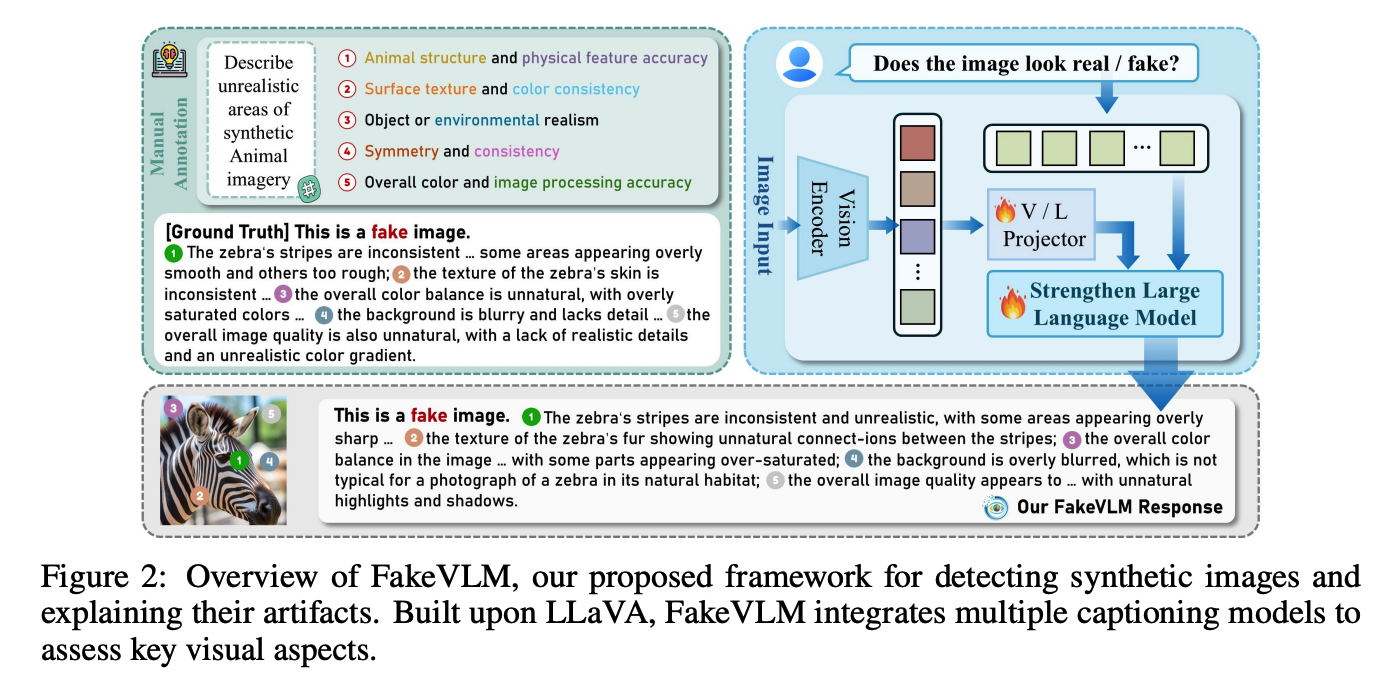
核心内容是针对 AI 生成图像(AIGC)的检测与可解释性分析 。它提出了一个名为 FakeVLM 的专用多模态大模型和配套的 FakeClue 数据集
FakeVLM 模型:基于 LLaVA 架构开发的一个专门用于合成图像检测的多模态大模型。它不仅能判断图片真伪(真或假),还能用自然语言详细说明图片里的"破绽"(伪影),例如光影不自然、边缘模糊或几何畸变等 。
FakeClue 数据集 :包含超过 10 万张图像的大规模数据集,涵盖了动物、人类、物体、风景、卫星图像、文档和人脸篡改等 7 大类别。该数据集利用多个高性能大模型(如 Qwen2-VL, InternVL)进行自动标注,并由另一个模型进行结果汇总,确保了标注的准确性与逻辑一致性
其他改进点:
从"结果输出"转向"解释引导" (Paradigm Shift);
为不同类别设计了专门的 **Label Prompt:**检测人脸时重点看鼻孔几何形状和皮肤纹理;检测卫星图时重点看建筑轮廓和道路连接情况;
多智能体协作标注:采用 Qwen2-VL、InternVL 和 Deepseek 三个模型共同出具"鉴定报告",再由 Qwen2-VL 作为聚合器(Magg)提取共同点、剔除冗余信息,从而获得高质量、层级化(纹理、几何、光照)的取证依据。
这项工作的改进在于通过大规模专业化数据微调 和解释性任务驱动 ,成功将大模型从一个"泛泛而谈"的助手转变为一个高性能、可解释的图像取证专家,填补了通用大模型在精细伪影感知上的短板。
五、AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models
论文地址:https://arxiv.org/pdf/2507.02664
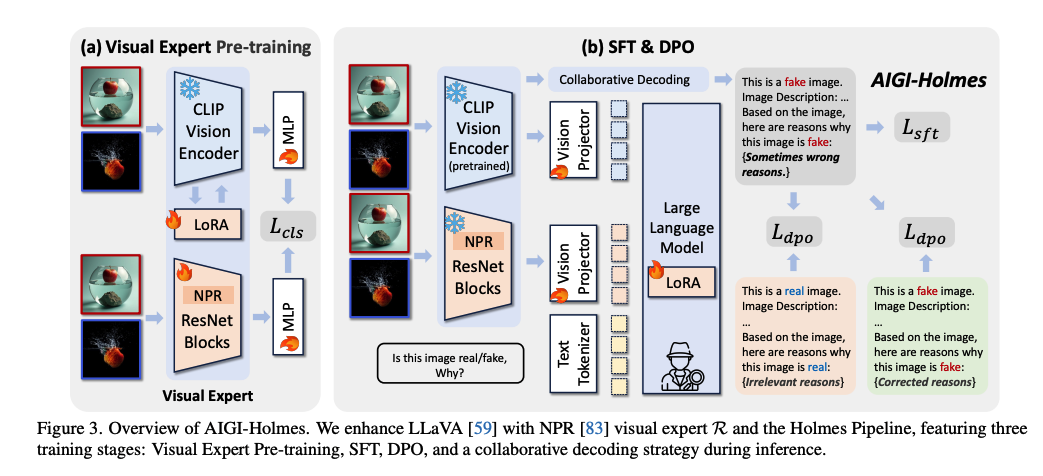
这篇论文介绍了一个名为 AIGI-Holmes 的框架,旨在通过多模态大语言模型(MLLM)实现可解释且泛化性强的 AI 生成图像(AIGI)检测。它不仅能准确判断图像是否由 AI 生成,还能像侦探福尔摩斯一样提供人类可验证的证据和理由。
以下是该研究的核心内容、重点创新点及具体的流程步骤:
- 主要内容
该研究针对现有 AI 图像检测技术存在的两个关键问题------缺乏可解释性(黑盒模型) 对新型生成技术泛化性差,提出了一个完整的解决方案。其核心是利用 MLLM 的常识理解和语言生成能力,对视觉内容进行语义层面的分析,从而识别出物理不一致、解剖学错误或纹理伪影等痕迹。
- 重点创新点
- Holmes-Set 数据集 :构建了首个包含丰富解释的大规模数据集,包括含有语义标注的 Holmes-SFTSet (6.5万张图)和符合人类偏好的 Holmes-DPOSet(用于对齐训练)。
- 多智能体陪审团(Multi-Expert Jury)标注法:引入了一种高效的自动标注方法,通过多个 MLLM 专家(如 Qwen2-VL, InternVL2 等)进行结构化解释生成,并结合专家模型过滤和交叉评估来确保数据质量。
- 三阶段训练管线(Holmes Pipeline):不同于仅进行微调的常规方法,它系统性地集成了视觉专家预训练、监督微调(SFT)和直接偏好优化(DPO)。
- 协同解码(Collaborative Decoding)策略:在推理阶段,将视觉专家的底层感知与 MLLM 的高层语义推理相结合,通过调整 Logit 值来共同决策,显著提升了在未知领域(如最新出的 Flux.1 或 SD3.5 模型)的检测精度

六、ForenX: Towards Explainable AI-Generated Image Detection with Multimodal Large Language Models
论文:https://arxiv.org/pdf/2508.01402
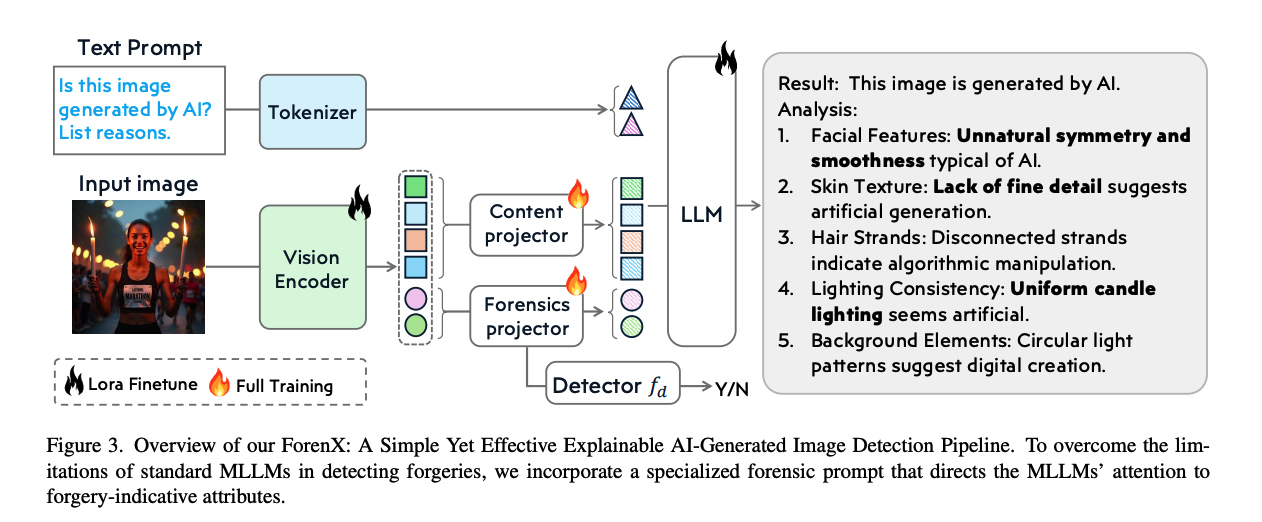
核心内容是关于如何利用多模态大语言模型(MLLM) 可解释的 AI 生成图像(AIGI)检测。它旨在解决传统分类器仅能输出"真/假"而无法提供人类可理解解释的"黑盒"问题,通过缩小模型检测与人类认知分析之间的差距,让模型像侦探一样给出具体的取证证据。
以下是该研究的重点创新点、具体流程步骤以及公式的深度解析:
重点创新点
- 取证提示词(Forensic Prompt):这是本文最核心的创新。它通过专门设计的输入,引导 MLLM 的注意力从通用的图像内容理解转向对**真实性(Authenticity)**及其相关线索(如物理规律、几何畸变等)的分析。
- ForgReason 数据集:构建了一个专门用于 AIGI 取证解释的数据集。它通过"LLM 代理 + 人工协作"的方式生成。标注不仅包含真伪,还包含精细的物理异常描述(如胡须分布不均、挂绳错位、缺乏支撑结构等)。
- 双阶段训练策略:有效解决了高质量人工标注稀缺的问题。先在大规模机器生成数据上预训练,再在少量精品人工标注数据上进行微调,显著提升了推理逻辑的"人味"。
ForenX 的工作流程主要分为以下几个环节:
- 特征提取与对齐 :使用预训练的 CLIP-ViT 提取图像特征 Fv。为了保证特征分布一致并降低训练不稳定性,这些特征同时被用作"图像内容表示"和"取证提示词"的构建基础。
- 取证提示词构建:将视觉特征映射到取证嵌入空间,并通过取证投影仪(Forensics Projector)将其转化为 LLM 可以理解的单词嵌入(Word Embedding)。
- 多源信息输入 :LLM 接收三个输入:文本提示词(Text Prompt) 、视觉内容(Visual Content) 取证提示词(Forensic Prompt)。
- 生成推理报告:模型最终输出检测结论(Yes/No)并提供详细的法医学分析理由(如面部过于平滑、光影不一致、背景元素异常等)
七、ForensicsSAM: Toward Robust and Unified Image Forgery Detection and Localization Resisting to Adversarial Attack
论文地址:https://arxiv.org/pdf/2508.07402
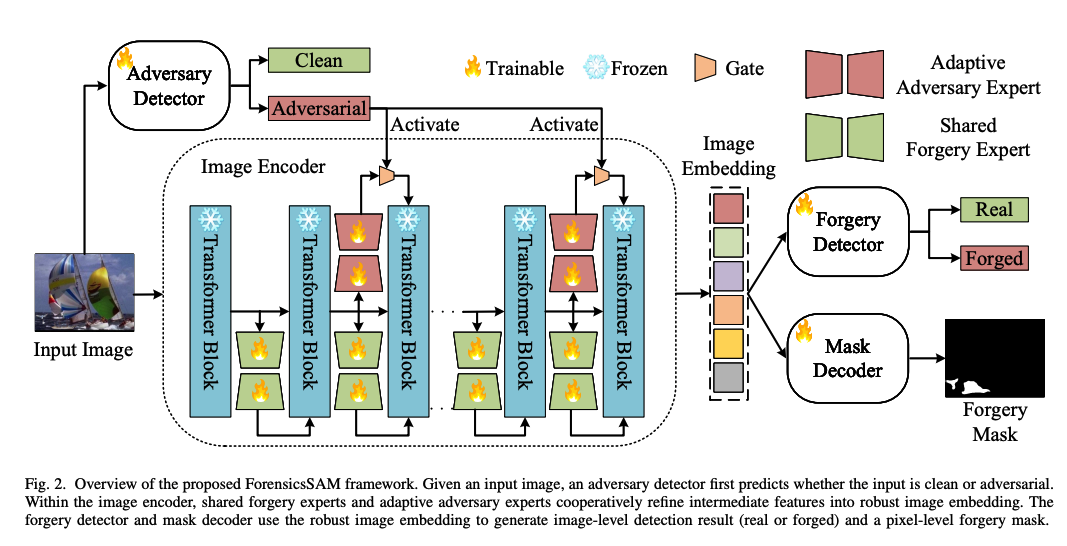
《ForensicsSAM》这篇论文的核心目标是让原本脆弱的图像取证模型(IFDL)能够抵抗"对抗攻击"。简单来说,对抗攻击就是给假图加上一层人类看不见、但能迷惑 AI 的"迷彩"噪声,让 AI 把假图看成真图。
为了让你更好理解,我们可以把这个框架想象成一个**"带有智能滤镜的数字化侦探"**。以下是结合具体例子的三大创新点解析:
- 创新点一:共享伪造专家 (Shared Forgery Experts) ------ 赋予模型"职业直觉"
- 痛点:基础大模型(如 SAM)虽然很懂图像结构,但它并不知道什么是"造假痕迹"(如剪切边缘的不连续)。它就像一个普通的摄影师,能看清物体,但分不清真伪。
- 做法 :在 SAM 的图像编码器中植入"伪造专家"模块(通过 LoRA 技术)。这些专家永远处于激活状态,专门负责盯着任何输入图像中的伪造蛛丝马迹。
- 例子 :
- 没有专家时:输入一张把"飞船"拼接到"漓江"上的图,SAM 只会觉得这是一张构图奇特的照片。
- 有了专家后:它能敏锐地捕捉到飞船边缘像素的异常,并输出带有伪造特征的图像嵌入(Embedding)。
- 创新点二:轻量化对抗检测器 (Adversary Detector) ------ 安装"烟雾报警器"
- 痛点:攻击者会添加一种特殊的"对抗噪声"。这种噪声不像随机噪点,它是经过精心设计的"结构化干扰",能让 AI 的判断逻辑发生偏转。
- 做法:设计一个基于 ResNet-18 的探测器。它不看图里画了什么,只负责检测图像中是否存在那种非自然的、专门针对 AI 的干扰模式,并给出一个"对抗分数"。
- 例子 :
- 当一张被添加了"迷彩"噪声的假图进入系统时,报警器立刻亮红灯(对抗分数 > 0.5),提醒系统:"这张图被人动过手脚,不要直接相信你的直觉!"。
- 创新点三:自适应对抗专家 (Adaptive Adversary Experts) ------ 开启"去干扰滤镜"
- 痛点:对抗噪声会导致模型内部的特征发生"偏移"(Feature Shifts),就像透过哈哈镜看东西,原本是方的看成了圆的,导致定位失败。
- 做法 :在全局注意力层中加入"对抗专家"。它们平时是关着的(为了不干扰正常图像的判断),只有当"报警器"发现对抗攻击时才动态开启,负责把被扭曲的特征"扶正"。
- 例子 :
- 在攻击下:正常的 AI 看到被攻击的假图,内部特征图会变得一片混乱,分不清哪里是背景哪里是物体。
- 开启专家后:这组专家像是一副"滤光镜",过滤掉干扰信号。如图 8 所示,开启专家后的特征图重新变得清晰,能够精准地圈出被篡改的飞船区域,而不再被背景噪声误导。
八、CLUE: Leveraging Low-Rank Adaptation to Capture Latent Uncovered Evidence for Image Forgery Localization
论文地址:https://arxiv.org/pdf/2508.07413
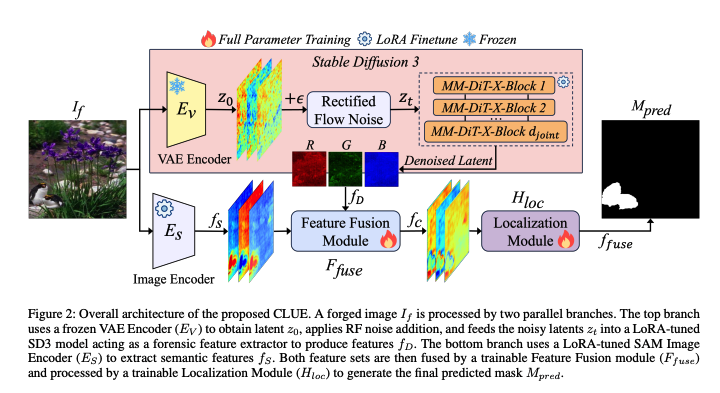
CLUE (Capture Latent Uncovered Evidence,捕捉潜藏证据)的图像篡改定位框架。其核心思想是将原本用于生成图像的扩散模型 Stable Diffusion 3 (SD3) 转化为一个高性能的取证特征提取工具。
以下是该研究的主要内容、重点创新点、具体流程步骤以及公式的深度解析:
- 主要内容
该研究旨在解决当前篡改定位方法面临的两大瓶颈:泛化性差 (难以识别未知的生成技术)和鲁棒性不足(在社交网络压缩或后处理下失效)。CLUE 框架通过协同微调两个基础模型(SD3 和 SAM)来实现这一目标:利用 SD3 挖掘潜空间中的生成不一致性,利用 SAM 捕捉稳健的空间语义上下文,从而实现精确的像素级定位。
- 重点创新点
- 范式转型 (Repurposing SD3):首次提出将生成模型 SD3 重新配置为取证特征提取器。通过分析扩散模型内部的生成逻辑,从根本上区分"自然分布"与"篡改痕迹",而非仅仅依赖寻找特定的伪造伪影。
- 利用整流流(Rectified Flow)机制:巧妙地利用 SD3 的 RF 机制引入受控噪声。研究发现,通过向潜表示中注入不同强度的 RF 噪声,可以引导模型放大那些微小的、指示篡改的统计不一致性。
- 双基础模型协同适配 (Coordinated Adaptation) :利用 LoRA(低秩自适应) 技术同时对 SD3 和 SAM 两个大型模型进行参数高效的微调,实现了取证特征与空间语义信息的深度融合。
九、Propose and Rectify: A Forensics-Driven MLLM Framework for Image Manipulation Localization
论文地址:https://arxiv.org/pdf/2508.17976
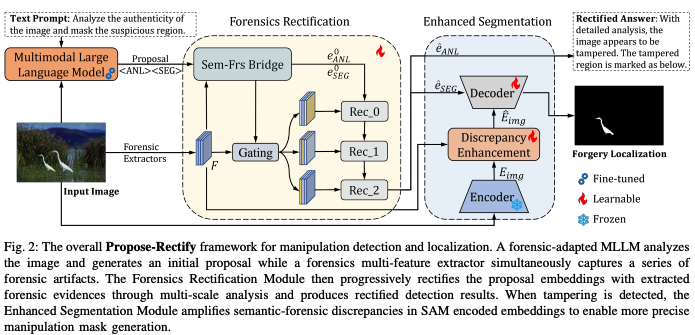
Propose-Rectify 的新型框架,旨在实现高精度的图像篡改检测与定位,。它通过将多模态大语言模型(MLLM)的高层语义推理能力与专门的取证技术分析相结合,解决了现有模型在捕捉微小取证痕迹和处理语义偏差方面的局限性,。
以下是该研究的核心内容、创新点、具体流程及公式深度解析:
- 主要内容
该研究提出了一个**"先提议,后修正"**(Propose-Rectify)的范式。首先利用微调后的 LLaVA 模型基于图像语义和上下文逻辑识别"可疑区域"并给出分析方案(提议阶段);随后利用多尺度取证特征分析对初始提议进行系统性验证和精细化调整(修正阶段);最后通过增强分割模块结合取证线索,利用 SAM(Segment Anything Model)实现像素级的篡改区域勾勒,,。
- 重点创新点
- Propose-Rectify 训练管线:打破了以往 MLLM 直接输出结果的黑盒模式,建立了从高层语义理解到低层技术特征分析的桥梁,减少了模型"幻觉"对取证结果的影响,。
- 取证修正模块 (FRM):引入了"分析引导的特征门控"机制,使模型能根据 MLLM 的初步分析,智能选择最相关的取证特征(如压缩噪声或边缘异常)进行多尺度校验,。
- 增强分割模块 (ESM):针对无明显语义边界的篡改(如缝隙填补),该模块通过放大"语义表现"与"取证特征"之间的差异,引导 SAM 生成更精准的掩码
3.应用实例
场景:处理一张包含"无缝拼接"的海鸥图像
- 初始提议 (Proposal):MLLM 观察到海鸥出现在内陆草地上,背景逻辑存疑,产生初始嵌入 eANL0,认为"这只鸟很可疑"。
- 特征门控 :FRM 接收到这个信号。根据公式 (3),它意识到由于图像分辨率高,需要重点检查边缘一致性,因此在特征图 F 中调高了 Sobel(边缘检测) 和 Np++(噪声指纹) 的权重。
- 多尺度验证 :
- 局部级:检测到海鸥羽毛边缘有微小的像素突变。
- 区域级:发现海鸥身体区域的 JPEG 压缩参数与背景草地不匹配。
- 结果修正:原本模糊的"海鸥可疑"猜想,在经过三轮公式 (6) 的修正后,嵌入向量变得包含具体的技术证据。
- 最终输出:系统以极高的置信度判定为"假图",并由于分割嵌入 eSEG 吸收了精准的边缘证据,最终生成的掩码完美贴合海鸥轮廓,没有冗余噪声
十、VERITAS: GENERALIZABLE DEEPFAKE DETECTION VIA PATTERN-AWARE REASONING
论文地址:https://arxiv.org/pdf/2508.21048
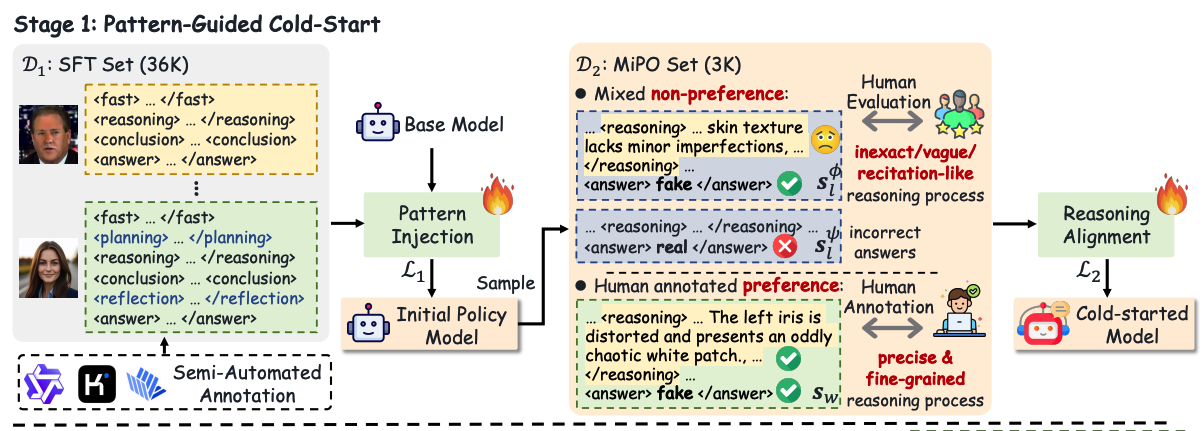
VERITAS,一种基于多模态大型语言模型(MLLM)的深度伪造检测器。与传统的思维链(CoT)不同,我们引入了模式感知推理,涉及"规划"和"自我反思"等关键模式,以模拟人类的取证过程。我们还提出了一种两阶段训练流程,将这种深度伪造推理能力无缝内化到当前的MLLM中。在HydraFake数据集上的实验表明,尽管之前的检测器在跨模型场景中表现出良好的泛化能力,但在未见过的伪造内容和数据领域却表现不佳。我们的VERITAS在不同领域外(OOD)场景中取得了显著成效,能够提供透明且忠实的检测输出。
HydraFake 数据集:构建了一个包含多样化伪造技术(如生成式换脸、面部重打光、自回归模型生成等)的大规模数据集,并设立了严苛的分层泛化评估协议
模式感知推理框架 :不同于传统的思维链(CoT),它提炼了五种人类思考模式:快速判断(Fast Judgement) 、规划(Planning) 、取证推理(Reasoning) 、自我反思(Self-reflection) 结论(Conclusion),以实现逻辑严密的整体推理。
第一阶段:模式引导的冷启动(Pattern-Guided Cold-Start):
- SFT(监督微调) :在 3.6万个样本上注入思维模式格式。使用标准的交叉熵损失,用于让模型初步学会按照特定的思维模式标签(如
<fast>,<planning>)生成内容。 - MiPO(推理对齐) :利用 3000 对偏好数据对齐模型推理,使其逻辑更符合人类专家标准。
这是一种改进的偏好优化。它拉大"优质推理过程 sw"与"劣质或错误推理过程 sl"之间的概率差距。防止模型生成模棱两可或机械重复的废话,显著提升解释的深度
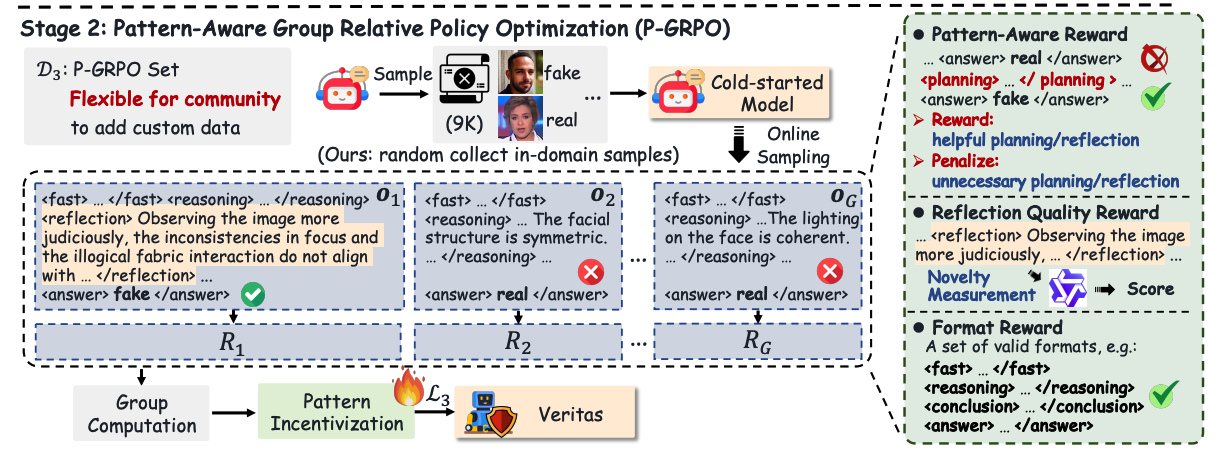
第二阶段:模式感知强化学习(P-GRPO):
通过强化学习,激励模型在面对复杂样本时自发地进行"规划"和"反思"
- 利用 9000 张在域图像进行在线探索。
- 系统会根据模型是否在推理中有效地使用了"规划"或"反思"来给出奖励,从而训练出能应对复杂样本的自适应推理能力
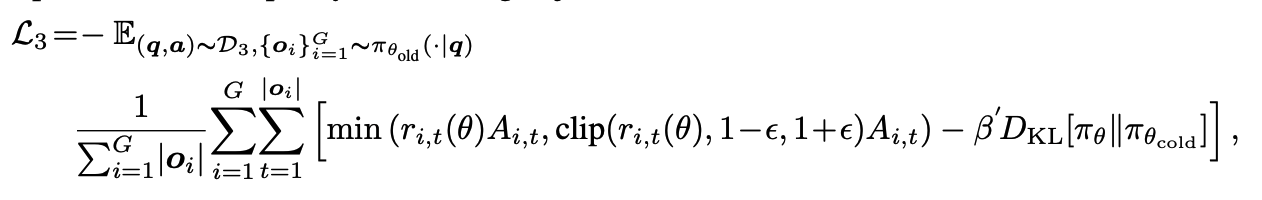
训练总损失:采用了类似 PPO 的裁剪(Clipping)机制,防止模型在单次更新中偏移太远。
KL 散度惩罚 ( DKL**)**:强制模型不要偏离第一阶段微调后的"冷启动模型"太远,以保持其基本的语言能力和逻辑
β′:控制偏离冷启动模型的惩罚强度,越小则允许模型进行越强的探索。
十一、StableGuard: Towards Unified Copyright Protection and Tamper Localization in Latent Diffusion Models
论文:https://arxiv.org/pdf/2509.17993
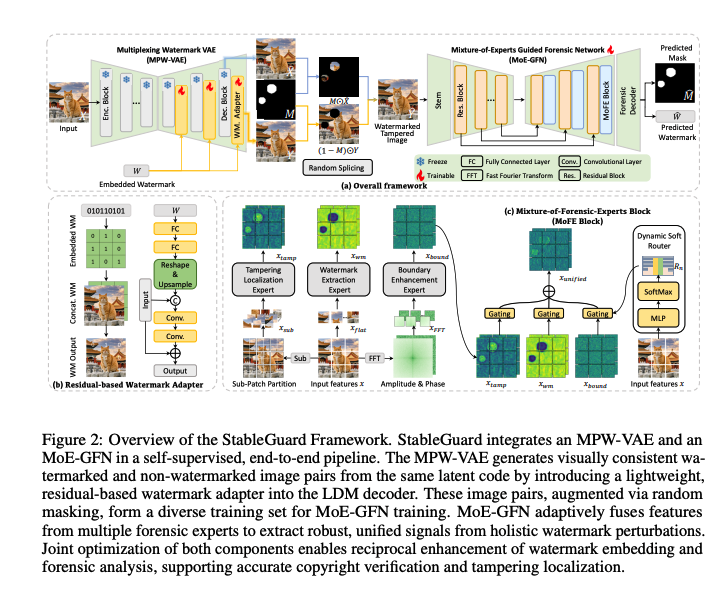
在 StableGuard 这个框架中,水印(Watermark)不再是我们在图片角落看到的半透明 Logo,而是一种埋藏在像素里的"数字化隐形指纹"。
简单来说,它有两个核心作用:
- 版权保护(证明"它是我的")
水印就像是图片的"数字化身份证"。
- 功能: 当一张图片被生成出来时,模型会自动把一段二进制编码(比如 0101...)嵌入到图片的像素中。
- 作用: 即使这张图被发到了网上,或者被别人保存了,只要通过配套的"水印提取专家"模块,就能把这段编码原封不动地取出来,从而证明这张图是由某个特定的 AI 模型生成的,或者是属于某个作者的版权。
- 篡改定位(证明"哪里被改了")
这是 StableGuard 最厉害的地方。水印被当成了一种像素级的"防伪封条"。
- 原理: 水印是均匀分布在整张图里的(研究中称为"全局分布")。
- 识别逻辑: 如果有人用 Photoshop 或者 AI 涂抹工具修改了图片的一部分(比如给猫加了个领结),那么被修改区域的水印信号就会被破坏或消失。
- 结果: 检测模型(MoE-GFN)会像侦探一样,通过扫描全图,发现哪块地方的"指纹"对不上了,从而精准地画出一个红框(掩码),告诉你:"看,这块地方被人动过手脚!"。
为什么这个水印"看不懂"?
你看不懂是很正常的,因为它是隐形的:
- 肉眼不可见: 研究通过微调 VAE 解码器,确保嵌入水印后的图片和原始生成的图片在视觉上几乎一模一样(保真度极高),人类肉眼根本分辨不出来。
- 分布广泛: 它不是贴在一个地方,而是像空气一样弥漫在整个图片的特征里,这样即使图片被剪裁或局部修改,剩下的部分依然能提取出完整的版权信息。
总结一下: 水印在这里既是**"身份证"(查版权),又是"监视器"**(找篡改区域)
具体原理请参考:StableGuard:如何将隐形取证功能直接植入 AI 图像生成过程 | Deep Paper
十二、ThinkFake: Reasoning in Multimodal Large Language Models for AI-Generated Image Detection
论文地址:https://arxiv.org/pdf/2509.19841
ThinkFake 的框架,旨在通过多模态大语言模型(MLLM)实现AI生成图像(AIGI)的检测与推理分析。
以下是其核心内容、创新点和具体流程步骤的详细解析:
- 主要内容
ThinkFake 解决了现有检测方法中存在的"黑盒"分类(缺乏解释)和泛化能力差(难以识别未见的生成模型)两大痛点。它不仅能判断一张图是真是假,还能像人类法医一样提供分步骤的逻辑推理过程。实验证明,ThinkFake 在 GenImage 基准测试中优于现有 SOTA 方法,并在挑战性的 LOKI 测试中展现了强大的零样本(Zero-shot)泛化能力。
- 重点创新点
- 推理导向的检测框架:不同于传统的二分类器,ThinkFake 利用 MLLM 的常识推理能力,生成包含技术评估、伪造指标分析和专家建议的结构化报告。
- 取证推理提示词 (Forgery Reasoning Prompt) :设计了专门的提示词,利用
<think>和<answer>标签引导模型进行思维链(CoT)推理,并强制要求以严格的 JSON 格式输出结果。- GRPO 强化学习策略 :采用了组相对策略优化 (GRPO) 算法进行训练。这种方法不需要额外的判别模型(Critic),而是通过组内奖励统计来优化模型,显著提升了模型的泛化性。
- 智能代理奖励 (Agentic Reward):引入了三个最先进的专家模型(UnivFD、NPR 和 AIDE)作为"虚拟专家",利用它们的分析结果(语义特征、频率特征、双流特征)来引导 MLLM 学习多维度的取证线索
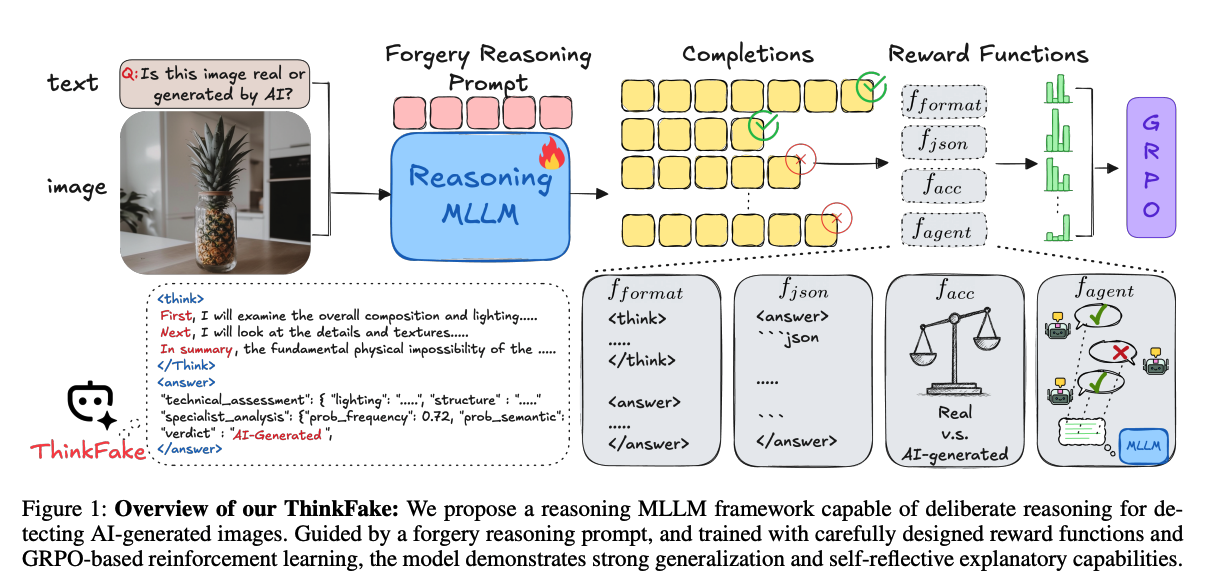
展示了 ThinkFake 框架的整体架构。该框架是一个基于推理的多模态大模型(MLLM)系统,旨在通过分步推理来检测 AI 生成的图像,并提供可解释的结构化报告。
以下是 Figure 1 中各关键部分的详细解释:
- 输入阶段 (Input)
- 文本 (Text):用户输入一个简单的问题,例如"这张图片是真实的还是 AI 生成的?"。
- 图像 (Image):待检测的图像输入到系统中。
- 核心处理流程
- 取证推理提示词 (Forgery Reasoning Prompt) :这是引导模型进行推理的核心,它通过特殊的标签(如
<think>和<answer>)以及严格的 JSON 格式要求,规范模型的思考过程和输出结构。 - 推理大模型 (Reasoning MLLM):ThinkFake 使用预训练的多模态大模型(如 Qwen2.5-VL-7B-Instruct)作为底座,执行深思熟虑的取证推理任务。
- 生成结果 (Completions):在强化学习训练阶段,模型会针对同一个问题生成一组(G 个)不同的回答。图中绿色的勾和红色的叉表示这些回答是否通过了后续奖励函数的筛选。
- 四大奖励函数 (Reward Functions)
为了在强化学习过程中优化模型,ThinkFake 设计了四个二进制奖励函数(满足为 1,不满足为 0):
- fformat**(推理格式奖励)** :强制要求模型的输出必须包含
<think>...</think>和<answer>...</answer>标签,确保推理过程可见。 - fjson**(JSON 格式奖励)**:确保答案部分是一个合规且可解析的 JSON 对象,这有助于提高答案提取的效率和结果的结构化程度。
- facc**(准确性奖励)**:通过对比模型预测的真伪标签与真实标签(Ground Truth),提供最直接的分类性能反馈。
- fagentic**(智能代理奖励)**:这是该框架的一大创新。它将模型对具体技术属性(如语义特征、频率特征等)的判断,与三个最先进的专家代理工具(UnivFD、NPR 和 AIDE)的输出进行对比,从而引导模型学习多维度的取证线索。
- 优化算法 (GRPO)
- 所有奖励信号汇总后,输入到 GRPO(组相对策略优化) 强化学习算法中。该算法无需单独的判别器网络(Critic),而是利用组内的奖励统计信息来优化模型,从而显著提升模型的泛化能力和自反思能力。
- 输出示例 (左下角展示)
- Figure 1 展示了模型输出的最终样貌:
- <think> 部分:展示了模型如何检查整体构图、细节和纹理,并总结物理上的不可能性的逻辑心路历程。
- <answer> 部分:以 JSON 格式列出技术评估(照明、结构等)、专家工具概率分析、最终裁决(Verdict)以及置信度分
十三、VIDGUARD-R1: AI-GENERATED VIDEO DETECTION AND EXPLANATION VIA REASONING MLLMS AND RL
论文地址:https://arxiv.org/pdf/2510.02282

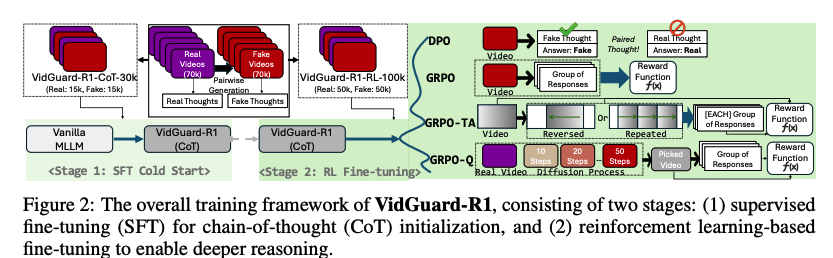
VidGuard-R1 的框架,它是首个利用**多模态大语言模型(MLLM)和 强化学习(RL)**技术,专门用于 AI 生成视频检测及可解释性推理 的系统。
以下是该研究的核心内容、创新点及具体流程步骤的详细解析:
- 主要内容
VidGuard-R1 旨在解决现有 AI 视频检测器仅提供"真/假"二进制结论且缺乏透明度的问题。该模型不仅能以高准确率识别视频真伪,还能通过**思维链(Chain-of-Thought, CoT)**详细解释其判断依据,例如分析运动一致性、光影表现、纹理伪影及是否违背物理常识。实验结果显示,该模型在多个基准测试中达到了 SOTA 性能,准确率超过 95%。
- 重点创新点
- 首个基于 GRPO 的视频检测器:首次将**组相对策略优化(Group Relative Policy Optimization, GRPO)**应用于 AI 视频取证领域。通过让模型探索并排名多条推理路径,促进其对视频物理一致性的深度理解。
- 专门的强化学习奖励模型 :
- 时域伪影奖励 (GRPO-TA):通过向视频注入倒放、重复等时域干扰,强制模型学习捕捉细微的时间不一致性。
- 扩散步骤感知的质量奖励 (GRPO-Q):利用不同扩散步骤(10-50步)生成的视频训练模型,使其能识别并量化生成质量的细微差异,而不仅仅是二元分类。
- "无捷径"高质量数据集 :构建了一个包含 14 万对真实/伪造视频的数据集,通过标准化分辨率、帧率及码率,迫使模型关注内在视觉写实性,而非元数据层面的统计差异(如时长差异导致的检测"捷径")
四种训练变体(图2中右侧分支):
- DPO (直接偏好优化):通过"成对想法"对比(将真实视频的 CoT 与伪造视频的 CoT 进行交换对比)来对齐人类偏好。
- 标准 GRPO:直接利用视频标签作为奖励信号,鼓励模型生成更准确的推理。
- GRPO-TA (时域伪影奖励) :通过向视频注入倒放 (Reversed) 或重复 (Repeated) 的时域干扰,强制模型学习捕捉细微的时间不一致性。
- GRPO-Q (质量感知奖励) :利用不同扩散步数 (Diffusion Steps)(如 10 步、20 步、50 步)生成的不同质量视频进行训练,使模型具备量化生成质量的能力