关键词:PyTorch、VelocityNet、Euler Sampler、minibatch OT、训练日志
目标:不讲大段文献,直接把一个能跑通的 Flow Matching 训练流程拆开
这篇文章做一件事:用 PyTorch 写一个最小版 Flow Matching。任务是把二维高斯噪声分布变成一个八簇分布。这个任务很小,但训练、采样、记录、画图的流程和大模型里的核心逻辑是一致的。
你可以把它当成 Flow Matching 的"最小骨架":
text
采样噪声 x0
采样数据 x1
随机时间 t
构造中间点 xt
计算速度标签 u
训练 vθ(xt,t)
用 Euler 从噪声积分到数据1. 环境准备
bash
conda create -n fm python=3.10 -y
conda activate fm
pip install torch numpy pandas matplotlib scipy文件结构建议如下:
text
flowmatching_2d/
├── train_2d_flow_matching.py
├── data/
└── assets/2. 构造二维数据分布
这里用八个高斯簇组成目标分布:
python
import math
import torch
def sample_data(n: int, device: str = "cpu") -> torch.Tensor:
centers = []
for k in range(8):
a = 2 * math.pi * k / 8
centers.append([2.0 * math.cos(a), 2.0 * math.sin(a)])
centers = torch.tensor(centers, dtype=torch.float32, device=device)
idx = torch.randint(0, 8, (n,), device=device)
return centers[idx] + 0.16 * torch.randn(n, 2, device=device)如果把目标分布画出来,它应该像一个由八个点云组成的圆环。
3. 写一个时间条件速度网络
Flow Matching 的模型输入是:
text
当前位置 xt
当前时间 t输出是:
text
当前位置应该移动的速度 vθ(xt,t)代码:
python
import math
import torch
from torch import nn
class TimeEmbedding(nn.Module):
def __init__(self, dim: int = 32):
super().__init__()
freqs = torch.exp(torch.linspace(math.log(1.0), math.log(1000.0), dim // 2))
self.register_buffer("freqs", freqs)
def forward(self, t: torch.Tensor) -> torch.Tensor:
args = t[:, None] * self.freqs[None, :] * 2 * math.pi
return torch.cat([torch.sin(args), torch.cos(args)], dim=-1)
class VelocityNet(nn.Module):
def __init__(self, hidden: int = 64):
super().__init__()
self.temb = TimeEmbedding(32)
self.net = nn.Sequential(
nn.Linear(2 + 32, hidden), nn.SiLU(),
nn.Linear(hidden, hidden), nn.SiLU(),
nn.Linear(hidden, 2),
)
def forward(self, x: torch.Tensor, t: torch.Tensor) -> torch.Tensor:
return self.net(torch.cat([x, self.temb(t)], dim=-1))这里的 TimeEmbedding 和扩散模型里的 timestep embedding 作用类似:让网络知道当前处于生成过程的哪个阶段。
4. 训练目标怎么写
线性路径:
xt=(1−t)x0+tx1 x_t=(1-t)x_0+tx_1 xt=(1−t)x0+tx1
速度标签:
u=x1−x0 u=x_1-x_0 u=x1−x0
训练循环:
python
model = VelocityNet(hidden=64).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-3, weight_decay=1e-4)
for step in range(1, 1201):
x0 = torch.randn(batch_size, 2, device=device)
x1 = sample_data(batch_size, device=device)
t = torch.rand(batch_size, device=device)
xt = (1 - t[:, None]) * x0 + t[:, None] * x1
target_v = x1 - x0
pred_v = model(xt, t)
loss = ((pred_v - target_v) ** 2).mean()
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()注意:这里的模型不是预测最终点,也不是预测噪声,而是预测速度。
5. Euler 采样器
训练完成后,从噪声开始积分:
python
@torch.no_grad()
def euler_sample(model, n: int, steps: int, device: str = "cpu"):
x = torch.randn(n, 2, device=device)
dt = 1.0 / steps
for i in range(steps):
t = torch.full((n,), i / steps, device=device)
x = x + dt * model(x, t)
return x这段代码对应的数学式是:
xt+Δt=xt+Δt⋅vθ(xt,t) x_{t+\Delta t}=x_t+\Delta t\cdot v_\theta(x_t,t) xt+Δt=xt+Δt⋅vθ(xt,t)
大模型中的 FlowMatchEuler scheduler,本质上也是围绕类似思想做更完整的工程包装。
6. 训练记录怎么看
训练时可以每隔一段保存 loss 和 ema_loss:
python
rows.append({
"step": step,
"loss": float(loss.detach().cpu()),
"ema_loss": running_loss,
})本次配套脚本输出的训练记录如下:
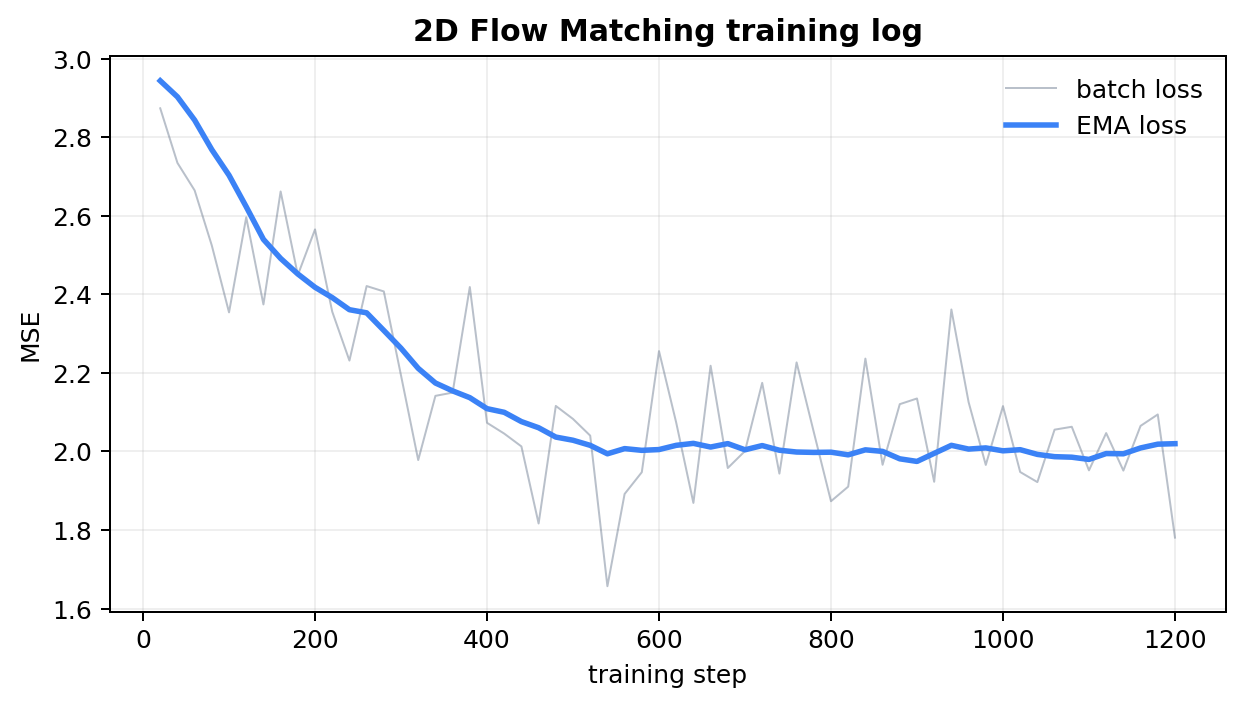
看 loss 时不要只看单个 batch 的上下跳动,更应该看 EMA 曲线。Flow Matching 的目标本身带有随机时间、随机噪声和随机配对,因此 batch loss 抖动很正常。
7. 采样结果怎么看
训练后,我们分别画出:
- 初始高斯噪声;
- 目标二维分布;
- Euler 32 步生成结果。
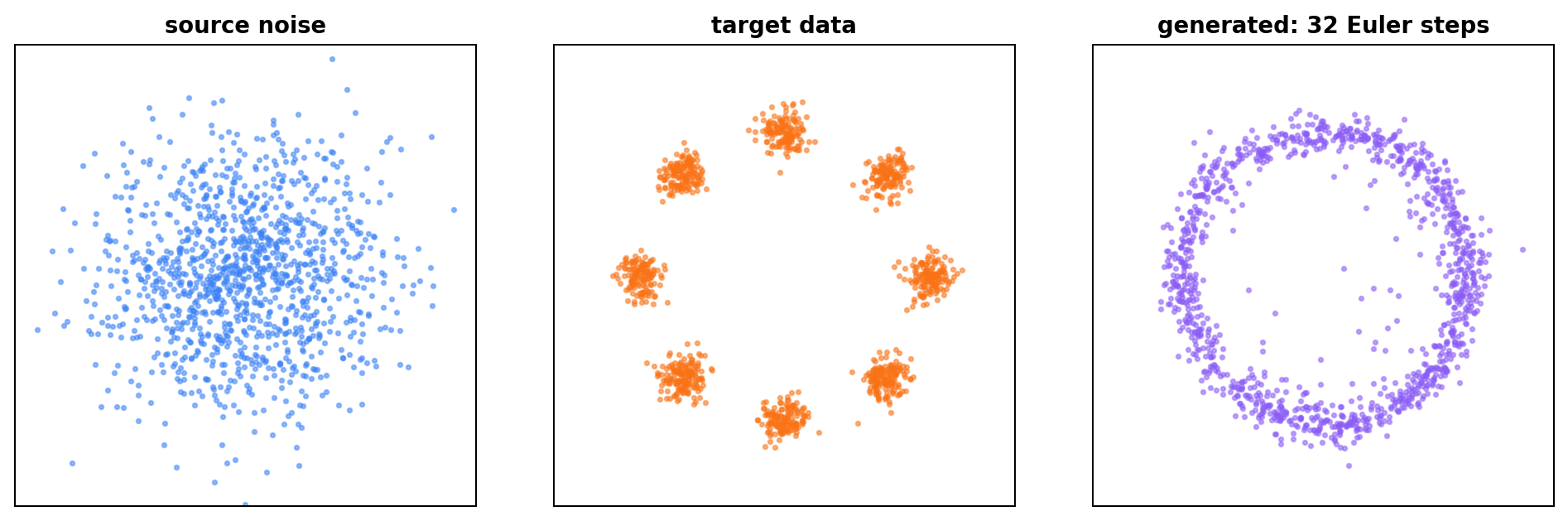
这张图能检查两件事:
- 模型是否已经学会把高斯噪声推向目标区域;
- 采样结果是否出现塌缩、发散或完全无结构。
二维任务里,独立配对常常会先学到整体外形,再逐渐学习更细的多峰结构。如果目标分布更复杂,可以考虑更强网络、更长训练、更合理的时间采样或 minibatch OT 配对。
8. 采样步数怎么影响结果
采样步数越多,ODE 积分通常越细,但速度也越慢。下面记录的是不同 Euler 步数下,生成点到最近目标中心的距离统计:
| Euler 步数 | 平均最近中心距离 | 90 分位最近中心距离 |
|---|---|---|
| 4 | 0.476 | 0.753 |
| 8 | 0.440 | 0.728 |
| 16 | 0.429 | 0.722 |
| 32 | 0.426 | 0.723 |
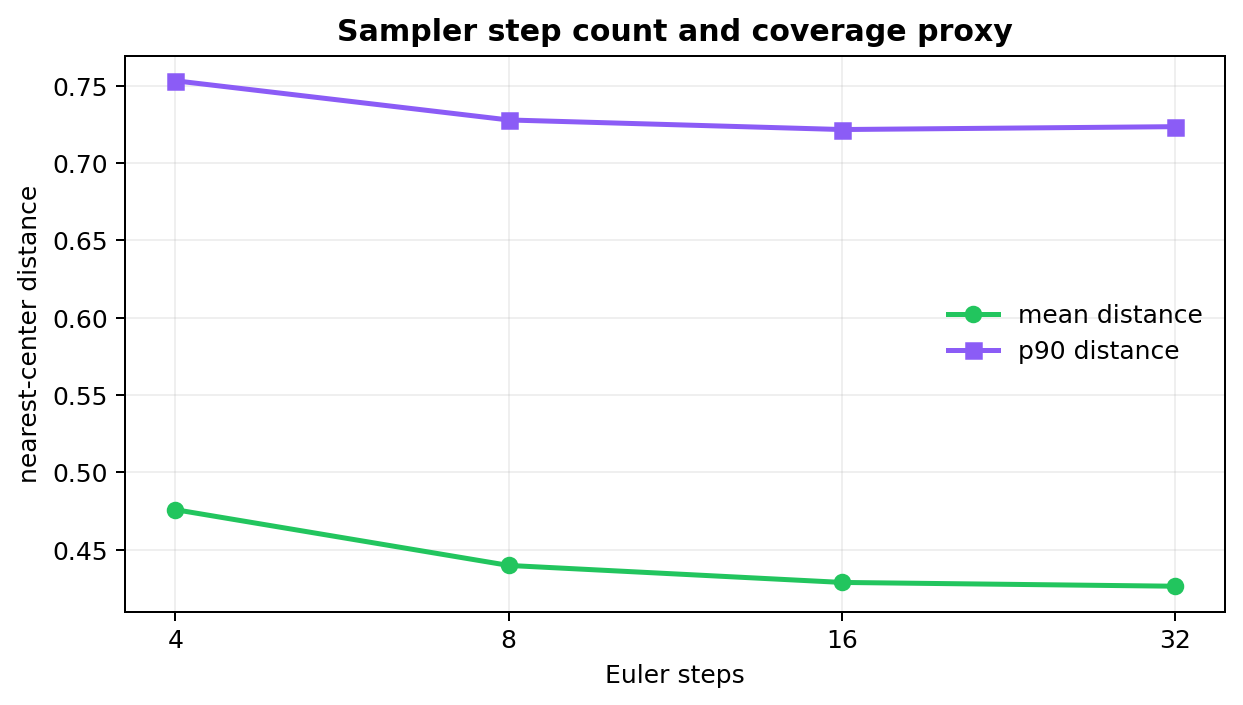
这个表说明一个常见现象:步数从很少增加到中等时,结果改善明显;继续增加步数,收益会变小。大模型调参时也类似,20、28、40 步之间的质量差异常常要和速度一起权衡。
9. 加入 minibatch OT 配对
独立配对最简单,但目标可能比较分散。可以在 batch 内用最小距离做一次配对,让噪声点和目标点更合理地对应。
安装依赖:
bash
pip install scipy核心代码:
python
from scipy.optimize import linear_sum_assignment
x0 = torch.randn(batch_size, 2, device=device)
x1 = sample_data(batch_size, device=device)
cost = torch.cdist(x0, x1).detach().cpu().numpy()
row, col = linear_sum_assignment(cost)
x0 = x0[row]
x1 = x1[col]然后继续使用同样的 Flow Matching loss:
python
t = torch.rand(batch_size, device=device)
xt = (1 - t[:, None]) * x0 + t[:, None] * x1
target_v = x1 - x0
loss = ((model(xt, t) - target_v) ** 2).mean()Conditional Flow Matching 和 OT-CFM 的一条重要工程经验就是:配对策略会改变速度目标的难度。 TorchCFM 项目中也提供了多种 Flow Matching 变体,包括 ConditionalFlowMatcher、ExactOptimalTransportConditionalFlowMatcher、TargetConditionalFlowMatcher 和 SchrodingerBridgeConditionalFlowMatcher。\^torchcfm
10. 常见错误排查
10.1 loss 一直不降
优先检查:
text
t 的 shape 是否正确
xt 是否真的混合了 x0 和 x1
target_v 是否写成 x1 - x0
model 输入是否包含 t
学习率是否过大10.2 采样结果全散掉
优先检查:
text
采样方向是否和训练时间方向一致
dt 正负号是否写反
steps 是否太少
模型是否训练时间不够10.3 图像模型中结果发灰或过曝
优先检查:
text
latent scaling factor 是否正确
VAE encode/decode 是否对应
scheduler 是否和模型训练目标匹配
guidance_scale 是否过高11. 这篇文章的核心结论
Flow Matching 的代码骨架很短:
text
构造路径 → 回归速度 → 积分采样真正的工程难点在于:数据分布复杂后,路径、时间采样、配对策略、loss weighting、网络结构和 scheduler 都会影响结果。
下一篇我们把视角切到实际应用:Stable Diffusion 3、FLUX 类 Flow Matching 模型在 Diffusers 里怎么用,参数怎么调,哪些坑不能踩。